一種固體廢棄物識別預測模型的識別預測方法及系統
本發明涉及固體廢棄物識別預測,具體為一種固體廢棄物識別預測模型的識別預測方法及系統。
背景技術:
1、固體廢棄物是指人類在各種日常活動中產生的固體廢棄物質,例如固體垃圾、食物、廢棄的工業制品和殘破器具等;而隨著人口增多這些固體廢棄物的數量也在逐年劇增,這些固體廢棄物除了會造成自然環境的破壞外,還會造成大量的資源浪費,因此固體廢棄物的回收利用工作也是目前較為主要的工作之一。
2、在所有固體廢棄物中,建筑活動產生的固體廢棄物占了我國固體廢棄物產出的主要組成部分,據統計我國每年約有18億噸的建筑固體廢棄物產出,包含了新建筑施工中的固體廢棄物、舊建筑拆除時的固體廢棄物和建筑裝修時的固體廢棄物;而這些固體廢棄物的轉化率極低,而在實際施工中這些建筑固體廢棄物垃圾有著極高的資源回收價值,可以通過收集、分離和再加工的方式進行資源可循環利用;例如石料可以轉換成再生骨料,用于生產再生磚、砂漿和路基的鋪墊等。
3、而目前對于這些建筑活動產生的固體廢棄物的難點在于,需要對這些固體廢棄物識別進行回收,以達到對環境的整理和資源的分類回收目的,因此采用了多種對于建筑固體廢棄物的識別問題進行改善,例如cn202211251505.6提出的一種固體廢棄物識別方法,通過rgb三通道得到的顏色聚合向量的顏色分布混淆度進行計算識別;cn202110345854.3提出的基于多策略增強的遙感影像固體廢棄物識別方法及系統,通過多策略增強關鍵點目標識別網絡對遙感圖像的深度學習識別的遙感圖像結果進行篩選;cn202110695615.0提出固體廢棄物的識別方法、裝置、電子設備及存儲介質,利用地物空間信息提升了固體廢棄物在光譜信息上的識別精度。
4、然而目前的方法僅解決識別精度差的問題,但是由于都是基于靜態的現有圖像,缺少對建筑固體廢棄物數量的動態分析結果,無法衡量各地區建筑固體廢棄物產出的具體數量;而且建筑固體廢棄物的種類過多,在回收的過程分離的過程中無法衡量可回收材料的具體數量,難以對后續這些可回收材料進行詳細的規劃處理工作。
5、為了能夠實現動態的建筑固體廢棄物數量的分析,以便于對建筑固體廢棄物的回收管理和規劃,本發明提出一種固體廢棄物識別預測模型的識別預測方法及系統。
技術實現思路
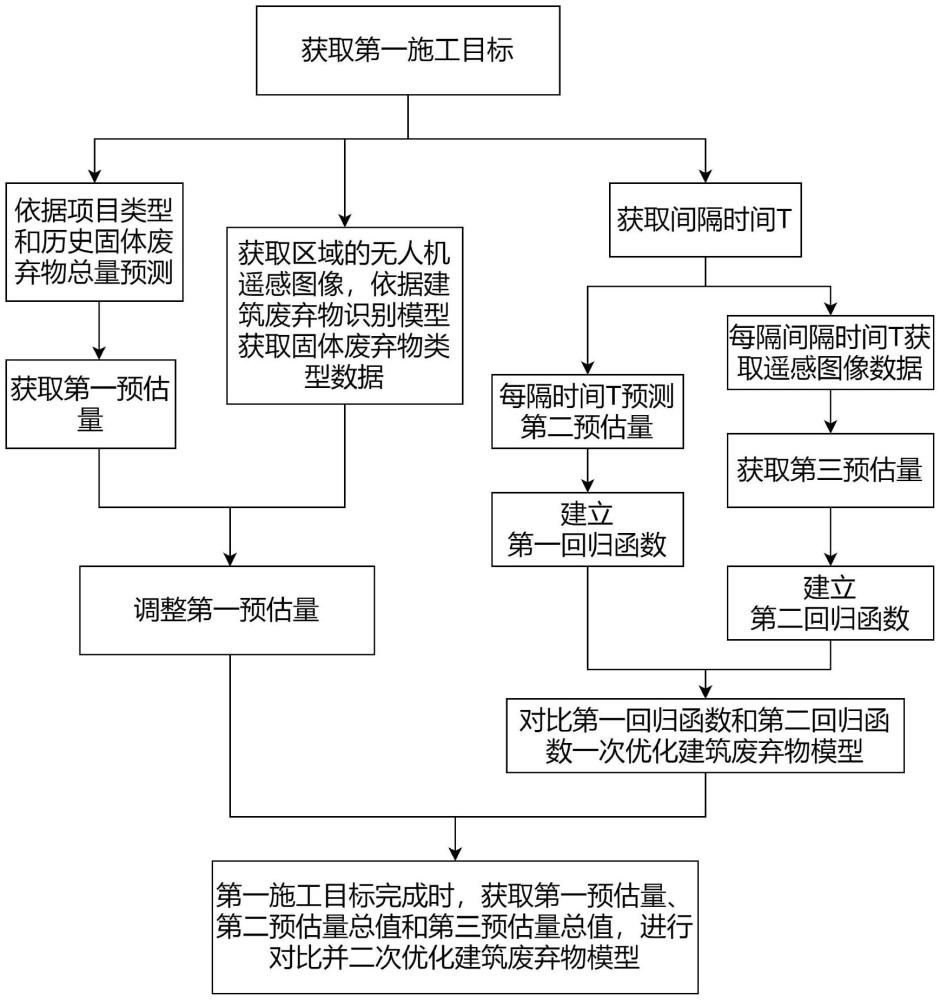
1、本發明的目的在于提供一種固體廢棄物識別預測模型的識別預測方法及系統,通過第一施工目標的項目類型和歷史固體廢棄物總量進行預測,獲取固體廢棄物的第一預估量;依據遙感圖像和廢棄物識別模型的特征識別結果對模型中未識別的固體廢棄物進行添加,調整第一預估量;依據廢棄物的集中清理時間t,每隔t時間的預測建筑廢棄物量獲取第二預估量,依據圖像特征獲取第三預估量,依據第二預估量和第三預估量建立對應的回歸函數并依據相似度計算結果對廢棄物預測模型進行優化;當第一施工目標完成時,依據第一預估量、第二預估量和第三預估量的偏差值對廢棄物預測模型進行進一步優化;以實現建筑固體廢棄物數量的動態分析,并提升準確率。
2、為實現上述目的,本發明提供如下技術方案:
3、一種固體廢棄物識別預測模型的識別預測方法,包括:
4、獲取選定區域的第一施工目標,依據所述第一施工目標獲取項目類型,依據所述項目類型和歷史固體廢棄物總量輸入建筑廢棄物預測模型,獲取固體廢棄物的第一預估量;
5、所述項目類型包括室內裝修、新建筑物建設或舊建筑物拆除;所述項目類型還包括項目對應的施工面積、施工材料和施工預計時間;
6、所述歷史固體廢棄物總量為對應所述項目類型的歷史固體廢棄物總量參考數據;
7、進一步地,所述建筑廢棄物預測模型包括廢棄物數據處理單元、廢棄物數據特征獲取單元、廢棄物數據預測輸出單元和廢棄物數據特征存儲單元;
8、所述廢棄物數據處理單元依據所述項目類型提取的所述歷史固體廢棄物總量數據,并按照時間順序進行排序、數據標簽生成和數據預處理,生成廢棄物預輸入數據;所述廢棄物預輸入數據為多維時序數據,大小為n*m,包括n個標簽數據,即每個1*m的時序數據對應1個所述標簽數據;
9、所述廢棄物數據特征獲取單元提取所述廢棄物預輸入數據的時序特征和所述歷史固體廢棄物總量間的數據關系,生成廢棄物關聯特征數據;
10、其中,所述廢棄物數據特征獲取單元包含長特征提取單元和短特征提取單元;所述長序列特征數據和所述短序列特征數據的輸出結果均為所述廢棄物關聯特征數據;
11、所述長特征提取單元由一維卷積神經網絡、lstm模型和attention機制組成,包括兩部分;第一部分為8層所述一維卷積神經網絡和4層所述attention機制,每層所述一維卷積神經網絡為1*5的卷積核,每2層一維卷積神經網絡后添加1層所述attention機制;所述第一部分特征計算后,生成第一特征,所述第一部分的特征提取如下:
12、
13、其中,wfei為第i層所述attention機制計算后的特征數值,exp[]為歸一化計算,h()為權值計算,為2層所述一維卷積的計算結果,an為attention機制的權值生成數量;
14、第二部分為8個lstm單元;所述第一特征經過所述第二部分的記憶門、遺忘門和輸出門,生成第二特征;所述第二特征為長序列特征數據;所述長序列特征數據用于提取第一預估量特征;
15、所述短特征提取單元所述長特征提取單元由一維卷積神經網絡和lstm模型組成,包括兩部分;第三部分為4層所述一維卷積神經網絡,每層所述一維卷積神經網絡為1*3的卷積核,所述第三部分特征計算后,生成第三特征;第四部分為4個lstm單元;所述第三部分特征計算后輸入到第四部分的記憶門、遺忘門和輸出門,進行時序特征計算,生成第四特征;所述第四特征為短序列特征數據;所述短序列特征數據用于提取第二預估量特征;
16、所述廢棄物數據預測單元依據所述廢棄物關聯特征數據和項目類型數據進行預測,獲取廢棄物排放預測數據;所述廢棄物數據預測單元則是通過gru模型進行預測;
17、所述廢棄物數據特征存儲單元將所述廢棄物數據特征獲取單元計算的所述數據關系的參數和權重進行存儲,生成廢棄物特征參數;
18、獲取所述選定區域無人機的遙感圖像,依據所述遙感圖像獲取所述第一施工目標的固體廢棄物類型數據,依據所述固體廢棄物類型數據和歷史固體廢棄物總量對所述第一預估量進行調整;
19、進一步地,所述第一預估量進行調整為依據遙感圖像對無法識別的新固體廢棄物進行特征添加,所述特征添加包括新固體廢棄物的紋理特征值、rgb色彩梯度特征值、像素比例特征值和邊緣梯度離散特征值;
20、所述特征添加為所述建筑廢棄物識別模型的特征訓練和模型參數生成;
21、所述建筑廢棄物預測模型依據所述項目類型、所述歷史固體廢棄物總量和新固體廢棄物量進行所述第一預估量的預測,對未添加所述新固體廢棄物量的所述第一預估量進行調整;
22、其中,所述建筑廢棄物識別模型包括廢棄物圖像預處理單元、廢棄物特征融合識別單元、廢棄物圖像特征提取單元和廢棄物圖像計算輸出單元;
23、所述廢棄物圖像預處理單元依據所述遙感圖像進行特征增強、圖像去噪和圖像旋轉后劃分圖像數據集并通過rgb色彩梯度處理、邊緣梯度處理、灰度處理和圖像分割放大,生成多種廢棄物輸入圖像;所述多種廢棄物輸入圖像包括rgb色彩梯度廢棄物輸入圖像、邊緣梯度廢棄物輸入圖像和灰度廢棄物輸入圖像;
24、所述廢棄物特征融合識別單元將多個不同的所述廢棄物特征數據進行特征融合并識別廢棄物,生成廢棄物識別候選數據;所述廢棄物圖像特征提取單元對每種所述廢棄物輸入圖像進行特征提取,獲取多個不同的廢棄物特征數據;
25、所述廢棄物圖像特征提取單元則是基于改進后的yolov5模型進行識別,所述yolov5模型包括backbone特征提取單元、neck網絡特征增加表達單元、head網絡模型預測單元和物體位置、類別與得分單元;本發明對所述backbone特征提取單元進行了改進,在所述backbone特征提取單元圖像提取前,本文添加了三個圖像特征預處理層和一個特征融合層,三個所述圖像特征預處理層分別輸入所述rgb色彩梯度廢棄物輸入圖像、所述邊緣梯度廢棄物輸入圖像和所述灰度廢棄物輸入圖像;所述圖像特征預處理層采用了一層3*3的卷積層和一層cbs層,所述cbs層包括一層卷積層、一層bn層和一層silu激活函數;
26、將三層所述圖像特征預處理層的輸出特征輸入到所述特征融合層中,進行特征拼接融合并壓縮,獲取所述yolov5模型的標準輸入大小后輸入所述backbone特征提取單元;所述特征融合層為所述廢棄物特征融合識別單元;
27、所述特征融合拼接將所述輸出特征進行橫向拼接,所述橫向拼接如下:
28、
29、其中,所述為第一個大小為m*n的所述輸出特征,所述為第二個大小為m*n的所述輸出特征,所述為第三個大小為m*n的所述輸出特征,所述am,3n為拼接后大小為m*3n的拼接特征,表示為特征拼接;
30、所述廢棄物圖像計算輸出單元依據所述廢棄物識別候選數據計算所述廢棄物數量,生成多種廢棄物數量數據并輸出或直接輸出廢棄物圖像識別結果;
31、依據建筑固體廢棄物的集中清理時間獲取時間間隔t,將所述第一施工目標的施工進程數據和所述固體廢棄物類型數據輸入所述建筑廢棄物預測模型獲取第二預估量;每隔t時間預測所述第二預估量,每隔t時間通過所述遙感圖像和建筑廢棄物識別模型獲取集中清理處的建筑固體廢棄物圖像數據,并分析得到所述集中清理處的圖像變化數據獲取第三預估量;依據所述第二預估量建立第一回歸函數,依據所述第三預估量建立第二回歸函數,依據所述第一回歸函數和所述第二回歸函數的對比結果一次優化所述建筑廢棄物預測模型;
32、進一步地,獲取相同t時間間隔下的所述第一回歸函數和所述第二回歸函數并計算相似度,若相似度小于相似度閾值,對所述建筑廢棄物預測模型進行優化;所述相似度計算如下:
33、
34、
35、其中,rs為相似度,為所述第二回歸函數第i個點的第三預估量值,為所述第一回歸函數第i個點的第二預估量值,kf依據最小二乘法計算獲取的所述第一回歸函數與所述第二回歸函數的近似比例函數,max()為最大值,fax為兩個回歸函數的歐幾里得距離,faxn為第n個歐幾里得距離,為所述第二回歸函數第i個點的橫坐標,為所述第一回歸函數第i個點的橫坐標,為所述第一回歸函數第n個點的第二預估量值;
36、當所述第一施工目標完成時,獲取所述第二預估量總值和所述第三預估量總值與所述第一預估量進行對比,依據對比結果的偏差值二次優化所述建筑廢棄物預測模型;
37、進一步地,依據所述偏差值或回歸函數的相似度進行優化,具體為:
38、若為所述偏差值,則獲取所述第二預估量或所述第三預估量與所述第一預估量的所述偏差值,若所述偏差值大于偏差閾值,則將所述第二預估量或所述第三預估量作為新的訓練數據帶入所述建筑廢棄物預測模型訓練優化模型的權重參數;
39、若為所述相似度,則獲取所述第一回歸函數和所述第二回歸函數并計算相似度,若相似度小于相似度閾值,則將所述第三預估量作為新的訓練數據帶入所述建筑廢棄物預測模型訓練優化模型的權重參數;
40、本發明還提出一種固體廢棄物識別預測模型的識別預測系統,包括第一預估量獲取模塊、第二預估量獲取模塊、第三預估量獲取模塊、第一預估量調整模塊、回歸函數對比優化模塊和偏差值優化模塊,具體為:
41、第一預估量獲取模塊,獲取選定區域的第一施工目標,依據所述第一施工目標獲取項目類型并結合歷史固體廢棄物總量輸入建筑廢棄物預測模型,獲取固體廢棄物的第一預估量;
42、第二預估量獲取模塊,獲取所述選定區域無人機的遙感圖像,依據所述遙感圖像獲取所述第一施工目標的固體廢棄物類型數據,將所述第一施工目標的施工進程數據和所述固體廢棄物類型數據輸入所述建筑廢棄物預測模型獲取第二預估量;
43、第三預估量獲取模塊,依據建筑固體廢棄物的集中清理時間獲取時間間隔t,每隔t時間預測所述第二預估量,每隔t時間通過所述遙感圖像和建筑廢棄物識別模型獲取集中清理處的建筑固體廢棄物圖像數據,并分析得到所述集中清理處的圖像變化數據獲取第三預估量;
44、第一預估量調整模塊,依據所述固體廢棄物類型數據和歷史固體廢棄物總量獲取偏差值并對所述第一預估量進行調整;
45、回歸函數對比優化模塊,依據所述第二預估量建立第一回歸函數,依據所述第三預估量建立第二回歸函數,依據所述第一回歸函數和所述第二回歸函數的對比結果一次優化所述建筑廢棄物預測模型;
46、進一步地,獲取相同t時間間隔下的所述第一回歸函數和所述第二回歸函數并計算相似度,若相似度小于相似度閾值,則將所述第三預估量作為新的訓練數據帶入所述建筑廢棄物預測模型訓練優化模型的權重參數;所述相似度計算如下:
47、
48、
49、其中,rs為相似度,為所述第二回歸函數第i個點的第三預估量值,為所述第一回歸函數第i個點的第二預估量值,kf依據最小二乘法計算獲取的所述第一回歸函數與所述第二回歸函數的近似比例函數,max()為最小值,fax為兩個回歸函數的歐幾里得距離,faxn為第n個歐幾里得距離,為所述第二回歸函數第i個點的橫坐標,為所述第一回歸函數第i個點的橫坐標,為所述第一回歸函數第n個點的第二預估量值;
50、偏差值優化模塊,所述第一施工目標完成時,所述第二預估量總值和所述第三預估量總值分別對比所述第一預估量,依據對比結果的偏差值二次優化所述建筑廢棄物預測模型;
51、進一步地,偏差值的優化過程為獲取所述第二預估量或所述第三預估量與所述第一預估量的所述偏差值,若所述偏差值大于偏差閾值,則將所述第二預估量或所述第三預估量作為新的訓練數據帶入所述建筑廢棄物預測模型訓練優化模型的權重參數。
52、與現有技術相比,本發明的有益效果為:
53、1、為了能夠實現動態的建筑固體廢棄物預測,通過獲取第一施工目標的項目類型以便于了解項目需要的材料數據,并結合歷史固體廢棄物總量進行對應,生成對應數據集通過廢棄物預測模型進行預測,獲取第一預估量;同時廢棄物預測模型也能夠基于第一施工目標的不同階段進行實時階段的固體廢棄物量的預測,在保證能夠預測固體廢棄物量預測的同時,完成各個階段的實時預測,為后續的回收管理提供數據基礎。
54、2、為了提升動態預測的準確度,通過獲取固體廢棄物的圖像數據,將圖像數據經過多種方法的預處理提升識別的準確度,以便于通過圖像數據實時了解真實的固體廢棄物排放量,便于對廢棄物預測模型的預測結果進行優化,提升預測的準確度;同時也能夠對歷史固體廢棄物中未記錄的固體廢棄物進行數據的添加、訓練和數據的生成,進一步提升了廢棄物預測模型的預測全面性和準確性,以實現更全面的動態建筑廢棄物量預測,提升后續回收管理的數據準確度。
55、3、為了進一步提升動態預測的準確性,通過建筑廢棄物排放階段,實時獲取圖像數據計算獲取實際的建筑廢棄物的第三預估量,也通過廢棄物預測模型預測排放階段的固體廢棄物的第二評估量,通過第三預估量和第二預估量的回歸線性函數的相似度,能夠了解不同階段的廢棄物預測模型的預測準確度,并對其進行實時的優化,以實現動態的模型預測準確度提升,進一步提升了后續模型預測的準確度,同時也能夠對第一預估量進行優化,進一步提升模型預測結果,實現不同階段的動態固體廢棄物的預測結果,以便于為回收管理工作提供更全面的數據基礎。
- 還沒有人留言評論。精彩留言會獲得點贊!