基于分區理論和知識圖譜的耕地塊深度學習快速提取方法
本發明涉及圖像處理,具體為基于分區理論和知識圖譜的耕地塊深度學習快速提取方法。
背景技術:
1、耕地,是人類賴以生存的基本資源和條件,具有保障糧食安全、滿足工業化和城市化用地需求及生態環境建設等功能。實時準確地監控耕地資源分布與變化是促進農業生產現代化的重要前提,同時也是宏觀農業政策制定、農業生產管理、農業資源保護與綠色可持續發展的急切需求。利用天空地多源遙感數據等遙感技術開展耕地監測,可以滿足大部分需求。隨著遙感數據源分辨率及可獲取性提升,遙感數據分類處理技術不斷改進,耕地遙感監測總體精度和時效性不斷提高。但現有的各種耕地監測方法大多適用于單一時空域,在進行大范圍耕地監測時,模型與方法的泛化能力弱,普適性相對不高。此外傳統的遙感信息提取方法,如最大似然、支持向量機、隨機森林等都是基于像元的分類,其分類結果往往會出現“椒鹽現象”,地塊的完整度、邊界信息及其提取精度相對較低。現有研究中,耕地信息提取在種植密集且單一的平原地區已經取得了良好的分類效果。然而耕地特點復雜多樣,尤其是丘陵山地地區地形起伏較大,地塊破碎度高,加之種植面積與地塊邊界形狀大小不一,導致空間異質性大,耕地信息提取困難加大。隨著影像空間分辨率的不斷提高,呈現出更為精細的地物光譜和空間等特征,可為丘陵山區不規則的耕地信息提供了數據支撐,此外,基于影像多光譜特征的深度學習方法為復雜條件下的影像分類提供了技術支撐。如何基于高分辨率影像進行破碎化地區耕地地塊的深度學習準確提取?是本技術解決的問題。本發明提出的tst-unet深度學習模型,可以精準獲取破碎化地塊細節邊緣精細信息,實現山區耕地的快速、智能化提取。
2、訓練樣本的數量和質量決定了監測模型的檢測精度,尤其是基于深度學習構建變化檢測模型,需要以海量的高精度遙感訓練樣本數據作為輸入。通過目視解釋和野外調研獲取樣本費時費力,效率較低。現階段研究往往直接使用已有的數據分類產品進行模型訓練,但由于相關數據集精度有限,導致深度學習泛化能力較差。缺乏足夠數量的高質量訓練樣本是限制深度語義分割網絡精度的一個主要因素。因此,如何快速獲取大區域高質量訓練樣本進行深度學習訓練?是本技術解決問題的重要組成部分。本發明提出一種基于分區理論的耕地知識圖譜數據庫建設方案,為深度學習提供支持和保障。
3、對中高辨率遙感數據耕地地塊提取而言,當前并無針對性的高質量深度學習訓練數據集;或已有的訓練數據集多基于目視解譯,制作效率低;或已有的深度語義分割網絡分割結果存在邊緣分割精度低等問題,限制了遙感數據的提取精度。
4、針對上述傳統方法復雜度高和效率低的缺陷與需求,就需要基于分區理論和知識圖譜的耕地塊深度學習快速提取方法。
技術實現思路
1、本發明的目的在于提供基于分區理論和知識圖譜的耕地塊深度學習快速提取方法。本發明構建了一套涉及大區域高質量訓練樣本制作以及耕地地塊深度語義分割學習提取的集成方法,基于此方法有助于加速深度學習技術在農業遙感領域的泛化應用與遷移能力。
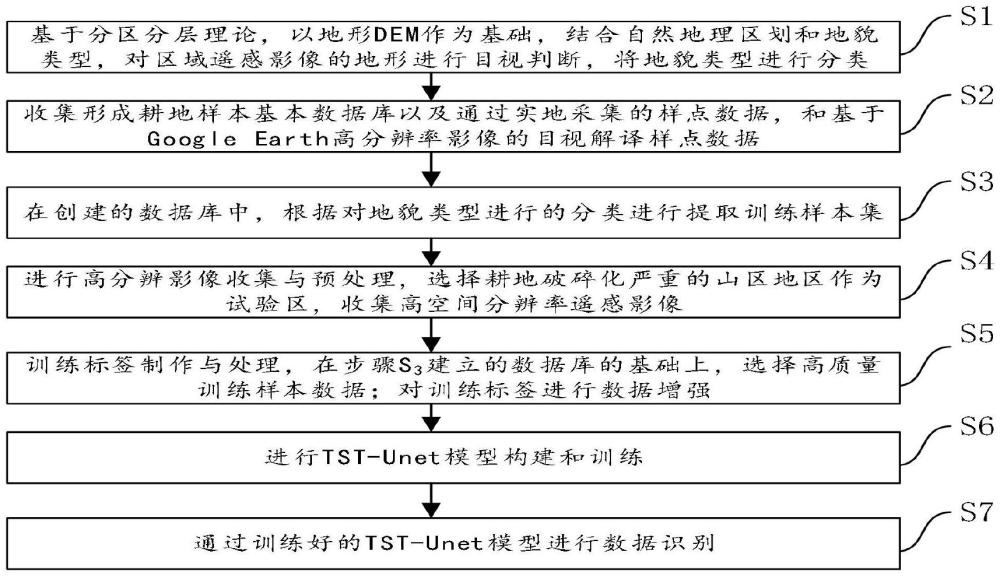
2、本發明是這樣實現的,本發明提供基于分區理論和知識圖譜的耕地塊深度學習快速提取方法,具體按以下步驟執行:
3、s1:基于分區分層理論,以地形dem作為基礎,結合自然地理區劃和地貌類型,對區域遙感影像的地形進行目視判斷,將地貌類型進行分類;判斷區域遙感影像,當中平原占主導地形,則判定該區域確定為地形單一區;當區域遙感影像中山地占主導地形,則判定該區域確定為地形復雜區。
4、s2:收集形成耕地樣本基本數據庫以及通過實地采集的樣點數據,和基于googleearth高分辨率影像的目視解譯樣點數據,將耕地樣本包括的tiff柵格數據和shp矢量數據兩種基本格式的數據基于arcgis軟件平臺創建數據庫;
5、形成耕地樣本基本數據庫具體包括數據平臺公開,例如國家農業科學數據中心、中國科學院資源環境科學數據中心、國家青藏高原科學數據中心等平臺的土地利用類型數據、不同科研單位已公開發表的土地利用數據產品,例如清華大學的中國1980-2015逐年30米土地覆蓋/土地利用數據集、武漢大學1990-2022年逐年30米土地利用數據集等。
6、s3:在創建的數據庫中,根據對地貌類型進行的分類進行提取訓練樣本集;
7、對地貌類型進行的分類地形包括單一區耕地地塊大,地形結構單一的地塊基于高時空分辨數據進行耕地數據提取,將創建的數據庫中的耕地樣本直接作為地形單一區耕地智能提取的訓練樣本集;
8、地形復雜區以創建的數據庫中的耕地樣本數據,利用隨機森林法,進行耕地和非耕地二分類。
9、s4:進行高分辨影像收集與預處理,選擇耕地破碎化嚴重的山區地區作為試驗區,收集高空間分辨率遙感影像;獲取研究區的高空間分辨率的光學遙感影像,利用遙感數據處理軟件進行幾何精校正,并基于地理坐標拼接完整覆蓋研究區;
10、·地形復雜區進行耕地和非耕地二分類具體按以下步驟執行:
11、·s4.1:進行特征因子構建,具體包括海拔、坡度和坡向、陰影特征,具體選取光譜特征、紋理特征、地形特征3大類特征組成原始的特征集;其中光譜特征包括不同波段的光譜特征及通過其中波段進行計算得到相關的指數特征,紋理特征采用灰度共生矩陣提取,通過計算圖像中相鄰一定距離兩像元之間的灰度關系特性,對這些像元點出現頻率進行統計,生成一個對稱的矩陣,如式(1);
12、p(i,j,δ,θ)={[(x,y),(x+dx,y+dy)]|f(x,y)=i,f(x+dx,y+dy=j)}????式(1)
13、·其中,f(x,y)代表需要用于生成灰度共生矩陣的圖像,(x,y)代表圖像中的某個點,(x+dx,y+dy)為(x,y)偏移后的對應像素點坐標,i代表(x,y)像素的灰度值,j代表(x+dx,y+dy)的灰度值,δ為偏移距離,θ為偏移方向,p(i,j,δ,θ)表示(x,y)在偏移距離為δ,偏移方向為θ時出現的概率;
14、·s4.2:進行特征優選,采用基于條件概率理論的距離作為衡量不同特征間的可分離程度,從原始數據中抽取部分通道圖層組成特征優選后的數據用作輸入分類器分類;如式(2);
15、
16、·s4.3:構建決策樹,選用cart算法構建決策樹分類器,設置隨機森林算法樹范圍為(0,1200),以5遞增,通過多次循環找到最高總體分類精度對應的樹的數量,將對應分類結果做為最終分類結果;
17、s4.4:進行人工校正,基于隨機森林獲得的臨時識別結果,參考地面調查數據、谷歌地球和高分2號衛星高分辨率數據,通過人工目視解譯對分類結果進行校正,包括去除誤報和校正漏分,對最終結果利用混淆矩陣、f1分數、用戶精度、生產者精度和整體精度指標評估精度。
18、s5:訓練標簽制作與處理,在步驟s3建立的數據庫的基礎上,選擇高質量訓練樣本數據;對訓練標簽進行數據增強;數據增強包括對訓練標簽數據進行隨機裁剪、翻轉、旋轉、色彩抖動、圖像移位。在保留原始特征不受破壞的前提下,生成新的樣本,有效增強模型的魯棒性和泛化性能。
19、s6:進行tst-unet模型構建和訓練;在模型中將transformer結構作為編碼器,對遙感影像進行特征提取,捕獲更長以來的特征,其中transformer編碼器由l層多頭自注意力和多層感知機組成。如式(3)-式(5);
20、z'l=msa(ln(zl-1))+zl-1?????式(3)
21、zl=mlp(ln(z'l))+z'l??????式(4)
22、
23、式中ln為層歸一化算法;為編碼圖像表示;為多頭自注意力,是注意力機制中的縮放因子;
24、進一步,增加一條裁剪編碼器分支,通過訓練一分為四的原始圖像,在編碼后將結果與原編碼器的結果相加后輸入解碼器,并與原編碼器的特征進行融合,最終輸出結果。
25、將原圖輸入cnn進行特征提取,進行了3層卷積下采樣,特征圖相較原圖縮小,變為原圖的1/2、1/4與1/8,分別獲得對應的特征矩陣,且每次下采樣過程包括一次卷積、正則化、relu激活、最大池化層。將下采樣后的圖像輸入嵌入式層,再輸入transformer層中循環12次中間高分辨率cnn特征層進行編碼與隱藏特征挖掘。
26、將特征層進行切片,提取高級的耕地地塊特征,在解碼過程對圖像進行上采樣中完成特征連接后進行深度可分離卷積代換,重復4次上采樣,最后再生成高級語義特征圖上1×1卷積層,生成耕地地塊結果的單個特征圖,完成遙感影像分割及耕地像素點的提取過程。
27、s7:通過訓練好的tst-unet模型進行數據識別。
28、進一步,本發明提供一種計算機可讀存儲介質,存儲介質存儲有計算機程序,所述計算機程序被主控制器執行時實現如上述中的任一項所述的方法。
29、與現有技術相比,本發明的有益效果是:
30、構建一套涉及大區域高質量訓練樣本制作以及耕地地塊深度語義分割學習提取的集成方法,基于此方法有助于加速深度學習技術在農業遙感領域的泛化應用與遷移能力;
31、解決了對已有的訓練數據集多基于目視解譯,制作效率低的問題;解決了已有的深度語義分割網絡分割結果存在邊緣分割精度低等問題,提高了遙感數據的提取精度。
- 還沒有人留言評論。精彩留言會獲得點贊!