訓練文本處理方法、裝置、電子設備、存儲介質及計算機程序產品與流程
本技術涉及自然語言處理,尤其涉及一種訓練文本處理方法、裝置、電子設備、存儲介質及計算機程序產品。
背景技術:
1、相關技術中,大語言模型可以針對用戶的需求生成文本,然而,模型處理過程中可能會產生幻覺,導致生成的文本與需求不符,在回復用戶提出的問題時,存在輸出內容的準確性低的問題。
技術實現思路
1、為解決相關技術問題,本技術實施例提供一種訓練文本處理方法、裝置、電子設備、存儲介質及計算機程序產品。
2、本技術實施例的技術方案是這樣實現的:
3、本技術實施例提供了一種訓練文本處理方法,所述方法包括:
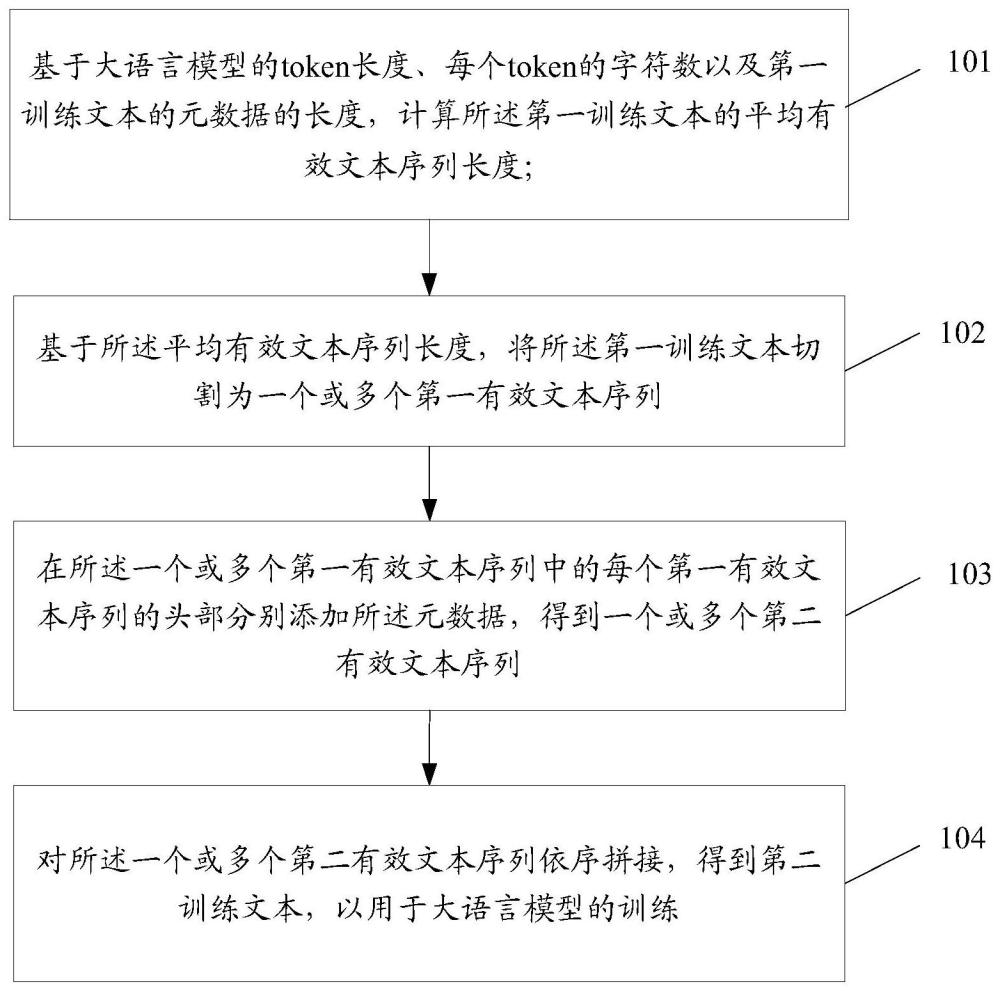
4、基于大語言模型的令牌(token)長度、每個token的字符數以及第一訓練文本的元數據的長度,計算所述第一訓練文本的平均有效文本序列長度;
5、基于所述平均有效文本序列長度,將所述第一訓練文本切割為一個或多個第一有效文本序列;
6、在所述一個或多個第一有效文本序列中的每個第一有效文本序列的頭部分別添加所述元數據,得到一個或多個第二有效文本序列;
7、對所述一個或多個第二有效文本序列依序拼接,得到第二訓練文本,以用于大語言模型的訓練。
8、上述方案中,所述基于大語言模型的token長度、每個token的字符數以及第一訓練文本的元數據的長度,計算所述第一訓練文本的平均有效文本序列長度,包括:
9、根據所述第一訓練文本中每個token的字符數,確定每個字符在對應token中的字符占比的第一平均值;
10、計算所述token長度與所述第一平均值的第一乘積;
11、將所述第一乘積與所述元數據的長度的差值確定為所述平均有效文本序列長度。
12、上述方案中,所述基于所述平均有效文本序列長度,將所述第一訓練文本切割成一個或多個第一有效文本序列,包括:
13、在所述第一訓練文本的長度小于或等于所述平均有效文本序列長度的情況下,將所述第一訓練文本確定為一個第一有效文本序列;和/或,
14、在所述第一訓練文本的長度大于所述平均有效文本序列長度的情況下,將所述第一訓練文本切割為多個第一有效文本序列。
15、上述方案中,所述將所述第一訓練文本切割為多個第一有效文本序列,包括:
16、基于第一切割點對應的第一長度與第二長度確定第二切割點,并將所述第二切割點與所述第一訓練文本的首部之間的文本切割為第一個第一有效文本序列;其中,所述第一長度表征所述第一切割點至第一文本段的段首的距離;所述第二長度表征所述第一切割點至所述第一文本段的段尾的距離;所述第一文本段表征所述第一切割點所在的文本段;所述第一切割點處于與所述第一訓練文本的首部距離所述平均有效文本序列長度的位置上;
17、在切割出第一個第一有效文本序列之后,對第三訓練文本循環執行以下操作,直至第三訓練文本切割完畢,其中,第三訓練文本表征所述第一訓練文本中仍未切割為第一有效文本序列的文本:
18、在第三訓練文本的長度小于或等于所述平均有效文本序列長度的情況下,將第三訓練文本確定為一個第一有效文本序列;
19、在第三訓練文本的長度大于所述平均有效文本序列長度的情況下,基于第一計數值與第二計數值的比較結果,將第三切割點所在文本段的段首或段尾確定為第四切割點,并將所述第四切割點與第三訓練文本的首部之間的文本切割為一個第一有效文本序列;其中,所述第一計數值表征已切割出的第一有效文本序列的個數與所述平均有效文本序列長度的乘積;所述第二計數值表征已切割出的第一有效文本序列的字符總數;所述第三切割點處于與第三訓練文本的首部距離所述平均有效文本序列長度的位置上。
20、上述方案中,所述基于第一切割點對應的第一長度與第二長度確定第二切割點,包括:
21、在所述第一長度小于所述第二長度的情況下,將所述第一文本段的段首確定為第二切割點;和/或,
22、在所述第一長度大于所述第二長度的情況下,將所述第一文本段的段尾確定為第二切割點。
23、上述方案中,所述將所述第三切割點所在文本段的段首或段尾確定為第四切割點,包括:
24、在所述第二計數值小于所述第一計數值的情況下,將第三切割點所在文本段的段尾確定為第四切割點;
25、在所述第二計數值大于所述第一計數值的情況下,將第三切割點所在文本段的段首確定為第四切割點;
26、在所述第二計數值等于所述第一計數值的情況下,如果所述第三長度小于所述第四長度,將第三切割點所在文本段的段首確定為第四切割點,如果所述第三長度大于所述第四長度,將第三切割點所在文本段的段尾確定為第四切割點。
27、在所述計算所述第一訓練文本的平均有效文本序列長度之前,所述方法還包括:
28、基于設定的自然語言模板,將所述第一訓練文本的元數據進行格式化處理。
29、本技術實施例還提供了一種訓練文本處理裝置,包括:
30、計算單元,用于基于大語言模型的token長度、每個token的字符數以及第一訓練文本的元數據的長度,計算所述第一訓練文本的平均有效文本序列長度;
31、切割單元,用于基于所述平均有效文本序列長度,將所述第一訓練文本切割為一個或多個第一有效文本序列;
32、添加單元,用于在所述一個或多個第一有效文本序列中的每個第一有效文本序列的頭部分別添加所述元數據,得到一個或多個第二有效文本序列;
33、拼接單元,用于對所述一個或多個第二有效文本序列依序拼接,得到第二訓練文本,以用于大語言模型的訓練。
34、本技術實施例還提供了一種電子設備,包括:
35、第一處理器及第一通信接口;其中,
36、所述第一處理器,用于:
37、基于大語言模型的token長度、每個token的字符數以及第一訓練文本的元數據的長度,計算所述第一訓練文本的平均有效文本序列長度;
38、基于所述平均有效文本序列長度,將所述第一訓練文本切割為一個或多個第一有效文本序列;
39、在所述一個或多個第一有效文本序列中的每個第一有效文本序列的頭部分別添加所述元數據,得到一個或多個第二有效文本序列;
40、對所述一個或多個第二有效文本序列依序拼接,得到第二訓練文本,以用于大語言模型的訓練。
41、本技術實施例還提供了一種電子設備,包括:第一處理器和用于存儲能夠在處理器上運行的計算機程序的第一存儲器,
42、其中,所述第一處理器用于運行所述計算機程序時,執行上述任一方法的步驟。
43、本技術實施例還提供了一種存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現上述任一方法的步驟。
44、本技術實施例還提供了一種計算機程序產品,包括計算機程序,所述計算機程序在被處理器執行時實現上述任一方法的步驟。
45、在本技術實施例中,在對大語言模型進行訓練之前,基于大語言模型的token長度、每個token的字符數以及第一訓練文本的元數據的長度,計算出第一訓練文本的平均有效文本序列長度,再基于平均有效文本序列長度,將第一訓練文本切割為一個或多個第一有效文本序列,之后為每個第一有效文本序列的頭部分別添加元數據,得到一個或多個第二有效文本序列,依序拼接第二有效文本序列得到第二訓練文本,將第二訓練文本用于大語言模型的訓練,保證了為訓練文本添加元數據的同時不會破壞原有的文本語義。基于上述方案中得到的訓練文本來訓練大語言模型,相比于相關技術,大語言模型在訓練時能夠關聯到更多的信息,生成更符合用戶需求語境的文本,提升了輸出內容的準確性。
- 還沒有人留言評論。精彩留言會獲得點贊!