實體關系抽取方法及相關模型訓練方法、裝置及電子設備與流程
本技術涉及信息,尤其涉及一種實體關系抽取方法及相關模型訓練方法、裝置及電子設備。
背景技術:
1、實體關系抽取是醫療領域人工智能技術中一項關鍵任務,是指從醫療文本數據中自動識別和提取文本中的實體以及實體之間的關系的操作,例如,疾病類實體和癥狀類實體之間的關系、疾病類實體和治療措施類實體之間的關系等。實體關系抽取對于醫療領域的研究和應用具有重要的意義,可以為疾病診斷、藥物開發、臨床決策等下游人工智能任務提供幫助。
2、但是在醫療領域中實體之間的關系往往非常復雜。醫療領域涉及的知識面非常廣泛,包括疾病、藥物、手術等各種實體,而這些實體之間的關系往往是多層次、復雜且交織在一起的。例如,一個疾病可能需要多種藥物進行治療,而這些藥物之間可能存在相互作用的關系。此外,在醫療領域中,往往需要結合多個數據源進行分析,包括病歷、醫學文獻、醫學圖像等,這也會增加關系重疊的出現概率。因此,醫療領域關系抽取需要充分考慮醫學知識的復雜性和多層次性,處理好關系重疊問題。而現有面向醫療領域的實體關系抽取方法大都難以處理這種復雜的關系重疊問題,難以對較為相似的關系進行準確分類。
3、因此,如何提高醫療領域實體關系抽取準確性成為目前醫療領域實體關系抽取中亟待解決的技術問題。
技術實現思路
1、本技術實施例提供一種實體關系抽取方法及相關模型訓練方法、裝置及電子設備,以解決醫療領域實體關系抽取準確性的問題。
2、第一方面,本技術實施例提供了一種實體關系抽取模型訓練方法,包括:
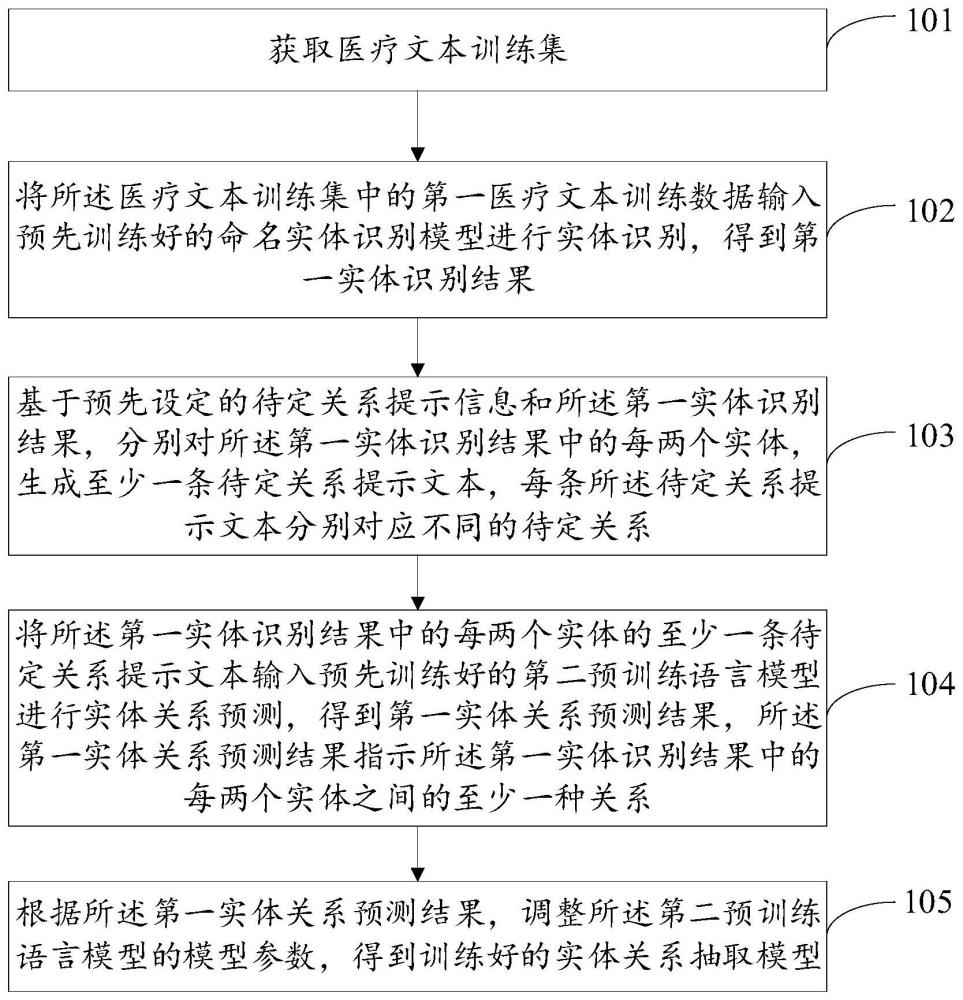
3、獲取醫療文本訓練集;
4、將所述醫療文本訓練集中的第一醫療文本訓練數據輸入預先訓練好的命名實體識別模型進行實體識別,得到第一實體識別結果,其中,所述命名實體識別模型是預先利用醫療文本訓練集中的第二醫療文本訓練數據對初始的命名實體識別模型進行訓練得到的;
5、基于預先設定的待定關系提示信息和所述第一實體識別結果,分別對所述第一實體識別結果中的每兩個實體,生成至少一條待定關系提示文本,每條所述待定關系提示文本分別對應不同的待定關系;
6、將所述第一實體識別結果中的每兩個實體的至少一條待定關系提示文本輸入預先訓練好的第二預訓練語言模型進行實體關系預測,得到第一實體關系預測結果,其中,所述第一實體關系預測結果指示所述第一實體識別結果中的每兩個實體之間的至少一種關系;
7、根據所述第一實體關系預測結果,調整所述第二預訓練語言模型的模型參數,以得到訓練好的實體關系抽取模型。
8、可選地,所述第二預訓練語言模型是預先利用所述醫療文本訓練集中的第三醫療文本訓練數據對第一預訓練語言模型進行訓練得到的,其中,對所述第一預訓練語言模型的訓練任務包括mlm任務和nsp任務。
9、可選地,所述命名實體識別模型的訓練過程包括:
10、對所述醫療文本訓練集中的第二醫療文本訓練數據生成實體標注;
11、將標注后的所述第二醫療文本訓練數據輸入初始的命名實體識別模型,以對所述第二醫療文本訓練數據進行編碼、特征提取和實體分類,并輸出第二實體識別結果,所述第二實體識別結果包括所述第二醫療文本訓練數據中的各個實體;
12、根據所述第二實體識別結果和生成的實體標注,使用損失函數計算模型損失,并基于所述模型損失調整所述初始的命名實體識別模型的模型參數,以得到訓練好的命名實體識別模型。
13、可選地,所述命名實體識別模型包括編碼層、注意力特征提取層和實體分類層;
14、所述將標注后的所述第二醫療文本訓練數據輸入初始的命名實體識別模型,以對所述第二醫療文本訓練數據進行編碼、特征提取和實體分類,并輸出第二實體識別結果,包括:
15、將標注后的所述第二醫療文本訓練數據輸入初始的命名實體識別模型,以分別通過所述編碼層對所述第二醫療文本訓練數據進行編碼,得到所述第二醫療文本訓練數據的文本序列表示,通過所述注意力特征提取層對所述第二醫療文本訓練數據的文本序列表示進行注意力特征提取,得到所述第二醫療文本訓練數據的注意力特征表示,以及通過所述實體分類層對所述第二醫療文本訓練數據的注意力特征表示和文本序列表示的拼接特征表示進行實體分類預測,輸出所述第二實體識別結果。
16、可選地,所述命名實體識別模型的編碼層為所述第二預訓練語言模型;
17、和/或,
18、所述注意力特征提取層包括特征提取層和span枚舉層,所述特征提取層采用雙向長短期記憶網絡bi-lstm;
19、所述通過所述注意力特征提取層對所述第二醫療文本訓練數據的文本序列表示進行注意力特征提取,包括:
20、通過所述特征提取層對所述第二醫療文本訓練數據的文本序列表示進行特征提取,得到所述第二醫療文本訓練數據的文本特征表示;
21、通過所述span枚舉層對所述第二醫療文本訓練數據的文本特征表示進行span注意力特征提取,得到所述第二醫療文本訓練數據的span注意力特征表示。
22、可選地,所述對所述醫療文本訓練集中的第二醫療文本訓練數據生成實體標注,包括:
23、對所述醫療文本訓練集中的第二醫療文本訓練數據進行預處理,所述預處理包括文本清洗和格式轉換;
24、采用多頭標注的方式對預處理后的所述第二醫療文本訓練數據進行實體位置標注,以得到所述第二醫療文本訓練數據中的各個實體的位置表示。
25、可選地,所述輸出第二實體識別結果之后,所述根據所述第二實體識別結果和生成的實體標注,使用損失函數計算模型損失之前,所述方法還包括:
26、采用邊界平滑機制對所述第二實體識別結果中的各個實體進行邊界平滑操作,以調整所述第二實體識別結果;
27、所述根據所述第二實體識別結果和生成的實體標注,使用損失函數計算模型損失,包括:
28、根據調整后的所述第二實體識別結果和生成的實體標注,使用損失函數計算模型損失。
29、第二方面,本技術實施例還提供一種實體關系抽取方法,包括:
30、獲取待識別的醫療文本數據;
31、將所述醫療文本數據輸入預先訓練好的命名實體識別模型進行實體識別,得到第三實體識別結果,其中,所述命名實體識別模型為第一方面所述的預先訓練好的命名實體識別模型;
32、基于預先設定的待定關系提示信息和所述第三實體識別結果,分別對所述第三實體識別結果中的每兩個實體,生成至少一條待定關系提示文本,每條所述待定關系提示文本分別對應不同的待定關系;
33、將所述第三實體識別結果中的每兩個實體的至少一條待定關系提示文本輸入預先訓練好的實體關系抽取模型進行實體關系預測,得到第二實體關系預測結果,其中,所述第二實體關系預測結果指示所述第三實體識別結果中的每兩個實體之間的至少一種關系,所述實體關系抽取模型為經第一方面所述的方法訓練得到的。
34、第三方面,本技術實施例還提供一種電子設備,包括:存儲器、處理器及存儲在存儲器上并可在處理器上運行的計算機程序,所述處理器執行所述計算機程序時實現如第一方面所述的實體關系抽取模型訓練方法中的步驟;或者實現如第二方面所述的實體關系抽取方法中的步驟。
35、第四方面,本技術實施例還提供一種計算機可讀存儲介質,所述計算機可讀存儲介質上存儲計算機程序,所述計算機程序被處理器執行時實現如第一方面所述的實體關系抽取模型訓練方法中的步驟;或者實現如第二方面所述的實體關系抽取方法中的步驟。
36、在本技術實施例中,通過利用預先訓練好的命名實體識別模型對醫療文本數據進行準確地實體識別,再采用基于提示學習的方法,利用預先訓練好的關系抽取模型對識別出的每兩個實體之間的多重可能的關系進行預測,進而能夠較為準確地抽取出醫療領域實體間的多重關系,很好地解決醫療領域實體的關系重疊問題。
- 還沒有人留言評論。精彩留言會獲得點贊!