模型訓練方法及ASR文本修正方法與流程
本發明涉及人工智能,尤其涉及一種模型訓練方法及asr文本修正方法。
背景技術:
1、隨著信息化時代的飛速發展和人工智能技術的不斷進步,電話中的非結構化數據可以產生巨大的信息價值,由于其便利性與匿名性,犯罪分子也會利用其進行通信信息詐騙。現有的技術方案會通過自動語音識別(asr)技術和自然語言理解(nlp)技術來對詐騙電話通話意圖進行自動化識別。然而,通用的asr技術在面向不同應用領域時,往往存在領域不匹配等問題,例如,對于電信詐騙領域,詐騙電話中往往包含一些特殊的信息,且不同類別的詐騙有不同的特點,比如詐騙分子冒充銀行工作人員稱被害人銀行卡存在異常,或冒充警察稱被害人存在違法行為等,這些電話中的關鍵信息在通用asr技術中均無法被重點識別,而且其識別性能總會受到說話者的發音、環境等因素的影響,同時,人們說的話有時也不完全符合語法規范,導致最終的語音識別結果容易出現錯誤,所以只有語音中的這些信息能夠在文本中更準確地呈現,才能夠提高語言識別模型的判斷準確度。
技術實現思路
1、本發明提供一種模型訓練方法及asr文本修正方法,用以解決現有技術中語音中的信息不能夠在文本中準確地呈現,導致語言識別模型的判斷準確度不高的缺陷。
2、本發明提供一種模型訓練方法,包括:
3、獲取第一數據集,所述第一數據集包括電話語音轉錄數據;
4、對所述第一數據集按照預設類別進行數據增強,得到第二數據集;所述預設類別包括多字、少字和錯字;
5、對所述第二數據集進行預處理,得到第三數據集;
6、根據所述第三數據集對bert模型進行訓練,得到訓練后的bert模型。
7、可選地,對所述第一數據集按照預設類別進行數據增強,包括:
8、確定第一數據集中文本的長度大于長度閾值的數據;
9、根據所述文本的長度確定一個隨機數,所述隨機數小于或等于預設比例長度,所述預設比例長度根據所述文本的長度確定,所述隨機數代表在所述文本中需要插入字的字數、或代表在所述文本中需要刪除字的字數、或代表在所述文本中被替換字的字數;
10、根據所述隨機數確定需要數據增強的位置;
11、當所述數據增強的類別為多字時,根據所述位置對所述文本進行插入;
12、當所述數據增強的類別為少字時,根據所述位置對所述文本進行刪除;
13、當所述數據增強的類別為錯字時,根據所述位置對所述文本進行替換。
14、本發明還提供一種asr文本修正方法,應用所述訓練后的bert模型,所述方法包括:
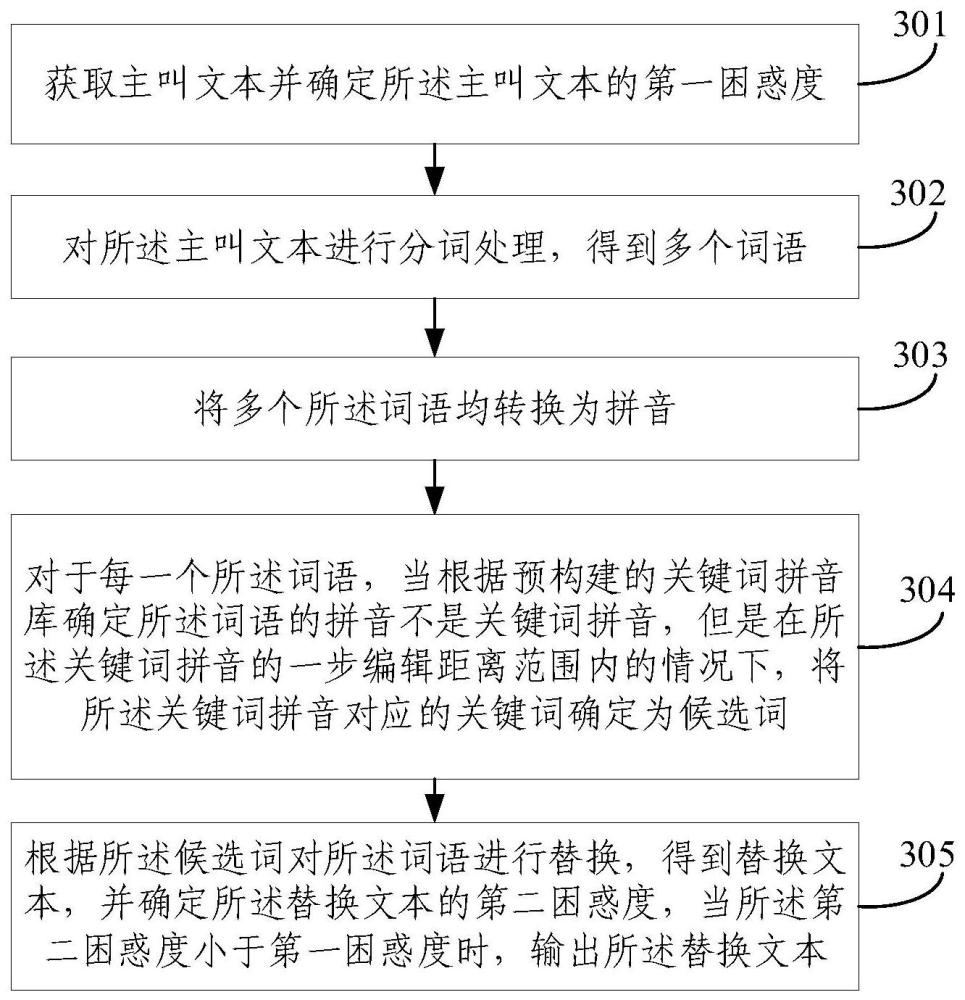
15、獲取主叫文本并確定所述主叫文本的第一困惑度;
16、對所述主叫文本進行分詞處理,得到多個詞語;
17、將多個所述詞語均轉換為拼音;
18、對于每一個所述詞語,當根據預構建的關鍵詞拼音庫確定所述詞語的拼音不是關鍵詞拼音,但是在所述關鍵詞拼音的一步編輯距離范圍內的情況下,將所述關鍵詞拼音對應的關鍵詞確定為候選詞;
19、根據所述候選詞對所述詞語進行替換,得到替換文本,并確定所述替換文本的第二困惑度,當所述第二困惑度小于第一困惑度時,輸出所述替換文本。
20、可選地,還包括:
21、獲取待修正領域的關鍵詞匯;
22、對每一個所述關鍵詞匯構建協調因子函數,得到關鍵詞庫;
23、確定所述關鍵詞庫中每一個關鍵詞的拼音,得到所述預構建的關鍵詞拼音庫。
24、可選地,還包括:
25、對于每一個所述詞語,當根據預構建的關鍵詞拼音庫確定所述詞語的拼音是關鍵詞拼音,但是不是關鍵詞的情況下,將所述詞語的所有同音詞均確定為候選詞。
26、可選地,根據所述候選詞對所述詞語進行替換,得到替換文本,并確定所述替換文本的第二困惑度,當所述第二困惑度小于第一困惑度時,輸出所述替換文本,包括:
27、根據所述候選詞逐個對所述詞語進行替換,得到多個所述替換文本,并確定每一個所述替換文本的第二困惑度;
28、在存在多個所述替換文本的所述第二困惑度小于第一困惑度、且小于第一困惑度的多個所述替換文本中均不存在所述關鍵詞庫中的詞匯的情況下,輸出最小的第二困惑度所對應的替換文本。
29、本發明還提供一種模型訓練系統,包括:
30、第一數據集獲取模塊,用于獲取第一數據集,所述第一數據集包括電話語音轉錄數據;
31、數據增強模塊,用于對所述第一數據集按照預設類別進行數據增強,得到第二數據集;所述預設類別包括多字、少字和錯字;
32、預處理模塊,用于對所述第二數據集進行預處理,得到第三數據集;
33、訓練模塊,用于根據所述第三數據集對bert模型進行訓練,得到訓練后的bert模型。
34、本發明還提供一種asr文本修正系統,應用所述訓練后的bert模型,所述系統包括:
35、主叫文本獲取模塊,用于獲取主叫文本并確定所述主叫文本的第一困惑度;
36、分詞模塊,用于對所述主叫文本進行分詞處理,得到多個詞語;
37、拼音轉換模塊,用于將多個所述詞語均轉換為拼音;
38、候選詞確定模塊,用于對于每一個所述詞語,當根據預構建的關鍵詞拼音庫確定所述詞語的拼音不是關鍵詞拼音,但是在所述關鍵詞拼音的一步編輯距離范圍內的情況下,將所述關鍵詞拼音對應的關鍵詞確定為候選詞;
39、替換文本輸出模塊,用于根據所述候選詞對所述詞語進行替換,得到替換文本,并確定所述替換文本的第二困惑度,當所述第二困惑度小于第一困惑度時,輸出所述替換文本。
40、本發明還提供一種電子設備,包括存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的計算機程序,所述處理器執行所述程序時實現所述模型訓練方法,或所述asr文本修正方法方法。
41、本發明還提供一種非暫態計算機可讀存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現所述模型訓練方法,或所述asr文本修正方法方法。
42、本發明提供的模型訓練方法及asr文本修正方法,通過獲取第一數據集,所述第一數據集包括電話語音轉錄數據;對所述第一數據集按照預設類別進行數據增強,得到第二數據集;所述預設類別包括多字、少字和錯字;對所述第二數據集進行預處理,得到第三數據集;根據所述第三數據集對bert模型進行訓練,得到訓練后的bert模型。然后進一步應用所述訓練后的bert模型:獲取詐騙電話的主叫文本并確定所述主叫文本的第一困惑度;對所述主叫文本進行分詞處理,得到多個詞語;將多個所述詞語均轉換為拼音;對于每一個所述詞語,當根據預構建的關鍵詞拼音庫確定所述詞語的拼音不是關鍵詞拼音,但是在所述關鍵詞拼音的一步編輯距離范圍內的情況下,將所述關鍵詞拼音對應的關鍵詞確定為候選詞;根據所述候選詞對所述詞語進行替換,得到替換文本,并確定所述替換文本的第二困惑度,當所述第二困惑度小于第一困惑度時,輸出所述替換文本。本發明通過預先構建數據增強后的數據集,并基于它進行bert模型的訓練,然后結合訓練后的bert模型和預構建的關鍵詞拼音庫能夠實現文本的替換修正,從而解決現有技術中語音中的信息不能夠在文本中準確地呈現,導致語言識別模型的判斷準確度不高的缺陷。
- 還沒有人留言評論。精彩留言會獲得點贊!