數據異常檢測方法、裝置、設備及存儲介質與流程
本技術屬于信息安全,尤其涉及一種數據異常檢測方法、裝置、設備及存儲介質。
背景技術:
1、目前,為了實現對用戶數據的保護,通常需要對相關數據進行異常檢測,以在檢測到數據異常時及時進行處理,保障用戶設備和用戶數據的安全。
2、相關技術中,異常數據的檢測通常可以包括基于用戶主機的數據檢測以及基于網絡流量數據的異常檢測。在基于用戶主機的數據檢測中,通常需要獲取應用程序的系統調用數據,并通過特征提取的方式,將不定長的系統調用數據轉化為固定長度的特征向量,通過對特征向量的識別得到異常數據。
3、然而,相關技術中,在將不定長的系統調用數據轉化為固定長度的特征向量時,轉化方式具有一定的局限性,導致生成的特征向量與實際需求的特征向量不匹配,例如在轉化過程中產生特征冗余問題或者在轉化過程中舍棄了具有代表性的部分數據而影響到異常檢測的準確性。
技術實現思路
1、本技術實施例提供了一種數據異常檢測方法、裝置、設備及存儲介質,旨在改善對系統調用數據進行特征向量的轉化時存在冗余或準確性不足的問題。
2、第一方面,本技術實施例提供一種數據異常檢測方法,方法包括:
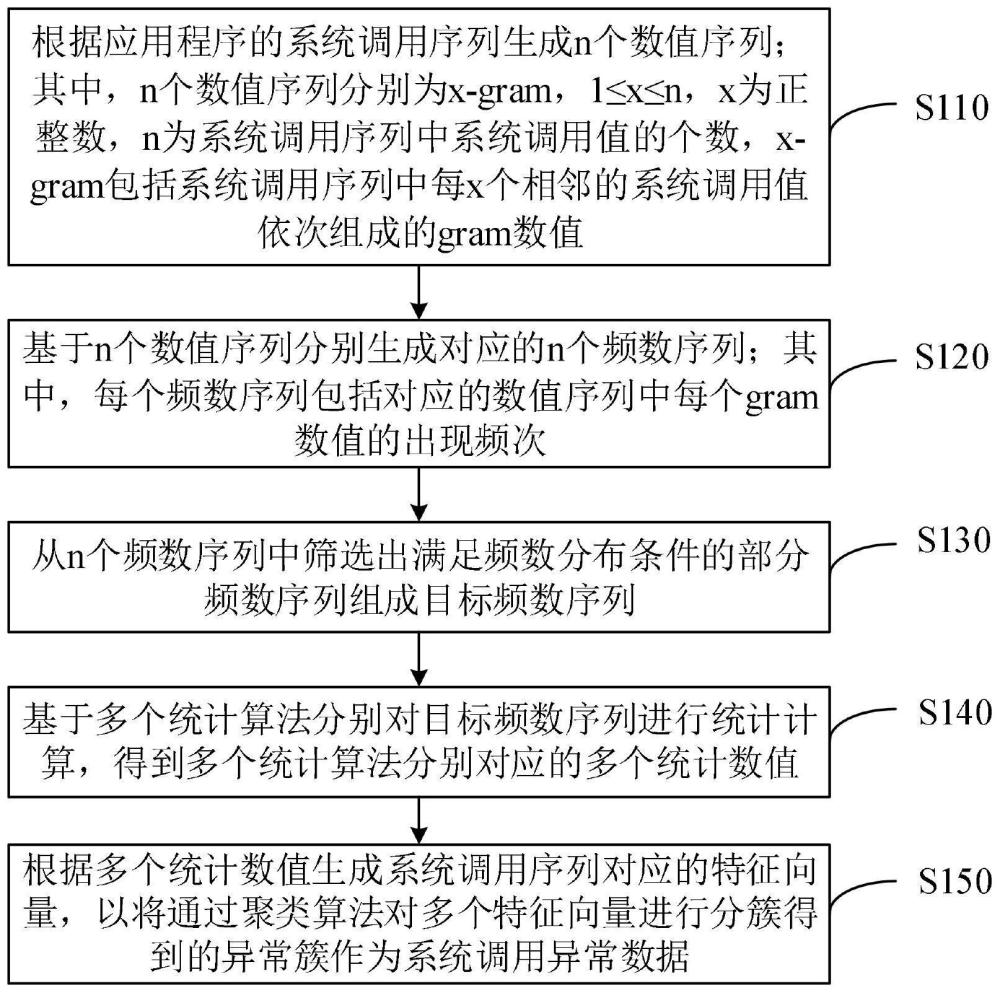
3、根據應用程序的系統調用序列生成n個數值序列;其中,n個數值序列分別為x-gram,1≤x≤n,x為正整數,n為系統調用序列中系統調用值的個數,x-gram包括系統調用序列中每x個相鄰的系統調用值依次組成的gram數值;
4、基于n個數值序列分別生成對應的n個頻數序列;其中,每個頻數序列包括對應的數值序列中每個gram數值的出現頻次;
5、從n個頻數序列中篩選出滿足頻數分布條件的部分頻數序列組成目標頻數序列;
6、基于多個統計算法分別對目標頻數序列進行統計計算,得到多個統計算法分別對應的多個統計數值;
7、根據多個統計數值生成系統調用序列對應的特征向量,以將通過聚類算法對多個特征向量進行分簇得到的異常簇作為系統調用異常數據。
8、在一些實施例中,基于n個數值序列分別生成對應的n個頻數序列,包括:
9、從n個數值序列的第1個數值序列開始,依次對每個數值序列中各個gram數值的出現頻次進行統計,得到每個數值序列對應的頻數序列。
10、在一些實施例中,從n個頻數序列中篩選出滿足頻數分布條件的部分頻數序列組成目標頻數序列,包括:
11、在生成第i個數值序列對應的第i個頻數序列后,獲取第i個頻數序列中1的出現頻次占比;
12、在第i個頻數序列中1的出現頻次占比達到比例閾值的情況下,根據第1個頻數序列至第i-1個頻數序列生成目標頻數序列。
13、在一些實施例中,基于多個統計算法分別對目標頻數序列進行統計計算,得到多個統計算法分別對應的多個統計數值,包括:
14、基于k個統計算法,分別對目標頻數序列進行統計計算,得到k個統計算法下分別對應的k個統計數值;其中,k個統計數值包括四分之一分位數、中位數、四分之三分位數、最大值、四分之一分位數與頻數和的比值、中位數與頻數和的比值、四分之三分位數與頻數和的比值、最大值與頻數和的比值、標準差、平均值、偏度、峰度、標準差以及信息熵中的至少兩個。
15、在一些實施例中,根據多個統計數值生成系統調用序列對應的特征向量之后,還包括:
16、獲取應用程序的多個系統調用序列分別對應的多個特征向量作為一般樣本集;
17、根據聚類算法對一般樣本集進行聚類劃分,得到多個簇;
18、從多個簇中識別出異常簇,以得到異常簇對應的多個系統調用序列。
19、在一些實施例中,聚類算法為具有噪聲的基于密度的迭代聚類算法;根據聚類算法對一般樣本集進行聚類劃分,得到多個簇,包括:
20、從一般樣本集中篩選出滿足核心樣本條件的核心對象樣本,生成核心對象樣本集;
21、從核心對象樣本集中擇一作為第一核心對象樣本,生成簇樣本集,以及根據第一核心對象樣本更新未訪問樣本集;其中,未訪問樣本集的初始化集合為一般樣本集;
22、以核心樣本條件對簇樣本集中的第一核心對象樣本進行遍歷篩選,從未訪問樣本集中篩選出子樣本集加入簇樣本集,并根據子樣本集更新未訪問樣本集,直至簇樣本集中的每個第一核心對象樣本均被遍歷篩選一次;
23、在簇樣本集中的每個第一核心對象樣本均被遍歷篩選一次的情況下,將簇樣本集作為一般樣本集的1個簇;
24、根據簇樣本集更新核心對象樣本集,并基于更新后的核心對象樣本集,返回執行步驟:從核心對象樣本集中擇一作為第一核心對象樣本,直至核心對象樣本集為空。
25、在一些實施例中,從核心對象樣本集中擇一作為第一核心對象樣本,生成簇樣本集,以及根據第一核心對象樣本更新未訪問樣本集,包括:
26、根據已進行聚類的簇數量確定簇樣本集的類別序號;
27、從核心對象樣本集中擇一作為第一核心對象樣本,生成簇樣本集;
28、從未訪問樣本集中篩除第一核心對象樣本。
29、在一些實施例中,以核心樣本條件對簇樣本集中的第一核心對象樣本進行遍歷篩選,從未訪問樣本集中篩選出子樣本集加入簇樣本集,并根據子樣本集更新未訪問樣本集,直至簇樣本集中的每個第一核心對象樣本均被遍歷篩選一次,包括:
30、將第一核心對象樣本加入簇核心對象隊列;
31、以核心樣本條件對簇核心對象隊列中的1個第一核心對象樣本進行篩選,從未訪問樣本集中篩選出子樣本集加入簇樣本集;
32、從未訪問樣本集中篩除子樣本集;
33、在子樣本集中包含至少1個核心對象樣本的情況下,將子樣本集中包含的核心對象樣本添加至簇核心對象隊列,并從簇核心對象隊列中篩除已經篩選的第一核心對象樣本;
34、在簇核心對象隊列包括至少1個第一核心對象樣本的情況下,返回執行步驟:以核心樣本條件對簇核心對象隊列中的1個第一核心對象樣本進行遍歷篩選,直至簇核心對象隊列中不包含第一核心對象樣本。
35、在一些實施例中,從一般樣本集中篩選出滿足核心樣本條件的核心對象樣本,生成核心對象樣本集,包括:
36、根據信息熵增益算法確定鄰域參數;鄰域參數包括鄰域半徑和最小對象數目;
37、針對一般樣本集中的每個樣本,利用樣本距離度量算法計算每個樣本在鄰域半徑內包含的其他樣本的數量;
38、將在鄰域半徑內包含的其他樣本的數量達到最小對象數目的樣本確定為核心對象樣本,生成核心對象樣本集。
39、第二方面,本技術實施例提供一種數據異常檢測裝置,裝置包括:
40、第一序列模塊,用于根據應用程序的系統調用序列生成n個數值序列;其中,n個數值序列分別為x-gram,1≤x≤n,x為正整數,n為系統調用序列中系統調用值的個數,x-gram包括系統調用序列中每x個相鄰的系統調用值依次組成的gram數值;
41、第二序列模塊,用于基于n個數值序列分別生成對應的n個頻數序列;其中,每個頻數序列包括對應的數值序列中每個gram數值的出現頻次;
42、第三序列模塊,用于從n個頻數序列中篩選出滿足頻數分布條件的部分頻數序列組成目標頻數序列;
43、統計模塊,用于基于多個統計算法分別對目標頻數序列進行統計計算,得到多個統計算法分別對應的多個統計數值;
44、生成模塊,用于根據多個統計數值生成系統調用序列對應的特征向量,以將通過聚類算法對多個特征向量進行分簇得到的異常簇作為系統調用異常數據。
45、第三方面,本技術實施例提供了一種數據異常檢測設備,設備包括:處理器以及存儲有計算機程序指令的存儲器;
46、處理器執行計算機程序指令時實現第一方面的數據異常檢測方法。
47、第四方面,本技術實施例提供了一種計算機可讀存儲介質,計算機可讀存儲介質上存儲有計算機程序指令,計算機程序指令被處理器執行時實現第一方面的數據異常檢測方法。
48、本技術實施例提供的數據異常檢測方法、裝置、設備及存儲介質,裝置可以獲取應用程序的系統調用序列,基于系統調用值的個數n,生成n個數值序列,并得到n個數值序列分別對應的n個頻數序列。基于n個頻數序列,可以通過頻數分布條件篩選出部分頻數序列以組成目標頻數序列。在得到目標頻數序列后,可以通過多個統計算法得到目標頻數序列對應的多個統計數值,多個統計數值組成的特征向量可以作為系統調用序列對應的特征向量。在對主機數據進行異常檢測的過程中,通過對各個系統調用序列分別對應的特征向量進行聚類劃分,可以得到包含異常簇的聚類結果,該異常簇即可作為系統調用異常數據。通過在特征向量的轉化過程中,根據頻數分布條件合理選擇目標頻數序列,能夠生成具有最大表示且不冗余的特征集合,改善特征向量轉化時容易存在冗余或者精準度不足的問題。
- 還沒有人留言評論。精彩留言會獲得點贊!