基于云平臺的生物信息分析系統的制作方法
本發明涉及一種基于云平臺的生物信息分析系統,屬于生物信息學分析技術領域。
背景技術:
隨著測序技術的快速發展,基因研究機構、醫學科研機構和公司產生了海量的生物學測序數據。但是眾所周知,實驗測序得到的原始數據并不能直接提供有價值的科學研究信息或疾病治療藥物的關聯信息,需要利用生物信息學分析技術對這些數據進行計算挖掘,從而給出清晰且易于導出結論的結果信息。生物信息學是在生命科學的研究中以計算機為主要研究工具對生物學數據進行存儲和計算分析,面對高通量測序所產生的海量數據,越來越多的研究人員或公司基于高性能計算機集群通過安裝各種生物信息分析軟件來進行計算分析。生物信息分析過程也是很多軟件和程序相互關聯,通過不同的步驟方法處理數據后得到最終的分析結果,由于生物信息軟件層出不斷、更新迭代,每個分析程序參數、文件格式、運行方式各異,研究人員不斷的要去研究新的軟件方法并在計算機或集群上安裝部署都變得十分復雜。海量數據的存儲、計算和傳輸共享也是研究者們快速訪問和分析數據中的難點。所以設計構建一種自動化擴展性好的生物信息云計算系統十分必要。
技術實現要素:
本發明的目的是解決目前生物信息分析軟件品類繁多,分析效率低下,自動擴展性差,大規模數據難于存儲共享和多樣化軟件程序構建部署分析流程復雜的技術問題。
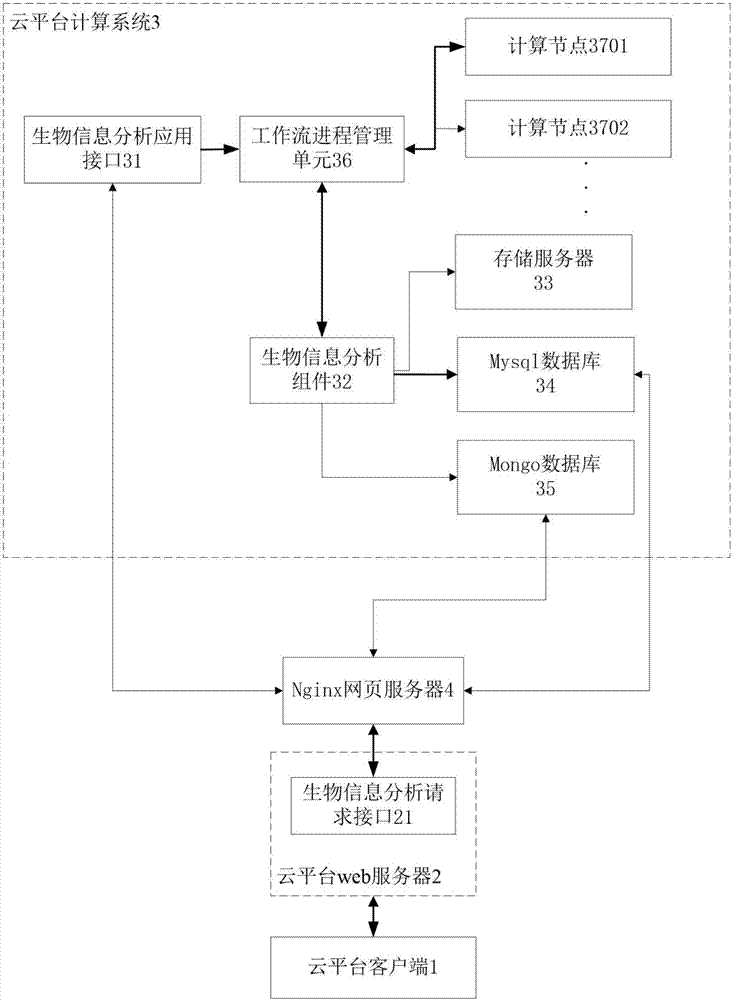
為實現以上發明目的,一方面,本發明提供一種基于云平臺的生物信息分析系統,包括云平臺客戶端、云平臺web服務器和云平臺計算系統;
所述云平臺客戶端和所述云平臺web服務器之間通過網絡收發信息,所述云平臺web服務器和所述云平臺計算系統之間通過nginx網頁服務器交換數據;
所述云平臺web服務器包括生物信息分析請求接口;
所述云平臺計算系統包括生物信息分析應用接口、生物信息分析組件、存儲服務器、mysql數據庫和mongo數據庫;
所述云平臺計算系統還包括若干計算節點,用于對生物信息進行分析計算;
所述生物信息分析請求接口通過所述nginx網頁服務器連接至所述生物信息分析應用接口,所述生物信息分析應用接口的輸出端通過工作流進程管理單元連接至所述生物信息分析組件的輸入端,所述生物信息分析組件的輸出端分別連接至所述存儲服務器、mysql數據庫和mongo數據庫;
所述生物信息分析請求接口向所述生物信息分析應用接口發出生物信息分析請求并發送參數;
所述存儲服務器用于存儲分析結果數據,所述mysql數據庫用于存儲分析記錄、狀態和日志信息,所述mongo數據庫用于存儲供所述云平臺客戶端展示的圖表數據。
進一步地,所述生物信息分析組件為即時模式分析組件或提交模式分析組件。
進一步地,所述提交模式分析組件包括工作流進程管理單元、分析模塊和文件組件;
所述分析模塊包括若干分析工具,各所述分析工具通過對應的工具代理與所述工作流進程管理單元進行通信;
所述工作流進程管理單元用于將不同的分析任務調度給不同的所述分析模塊;
所述文件組件用于使分析結果形成通用的生物信息數據格式。
進一步地,所述工作流進程管理單元通過slurm系統進行任務調度。
另一方面,本發明提供一種基于云平臺的生物信息分析方法,包括如下步驟:
在客戶端輸入用于分析的參數并向web服務器發出分析請求消息;
通過nginx網頁服務器接收請求消息后轉發至生物信息分析應用接口,解析參數;
判讀所述參數為即時計算型還是投遞計算型;
若為即時計算型,則直接在專用即時計算服務器上運行生物信息分析工作流;
若為投遞計算型,則將參數傳遞至計算節點服務器上運行生物信息分析工作流;
將生成的結果數據上傳到云平臺的存儲服務器和mongo數據庫;
將生物信息分析工作流的運行狀態實時存入mysql數據庫;
向web服務器返回分析成功的消息,web服務器從mongo數據庫獲取結果提供給客戶端。
進一步地,所述投遞計算型的分析工作流如下:
工作流進程管理單元獲取參數后,按照內部預先定義的邏輯關系,將參數傳遞到生物信息分析組件的各分析模塊,觸發各分析模塊的運行,各分析模塊之間通過協程監聽互相有依賴關系的分析模塊的運行狀態,以各分析模塊中的各分析工具為最小級別分析組件,將各分析工具通過slurm投遞到計算節點開始計算分析,同時不斷監聽和接收分析的狀態。
與現有技術相比,本發明的有益效果是:
本發明的分析程序模塊化,可組合復用,具有擴展性好的以自動化工作流運行的系統框架,解決了大規模數據難于存儲共享和多樣化軟件程序構建部署分析流程復雜的技術問題,分析效率大為提高,部署方便。
附圖說明
圖1是本發明系統的原理框圖;
圖2是生物信息分析組件的一個實施例原理框圖;
圖3是本發明方法的流程圖。
圖中,云平臺客戶端1;云平臺web服務器2;生物信息分析請求接口21;云平臺計算系統3;生物信息分析應用接口31;生物信息分析組件32;分析模塊322;工具代理3221;分析工具3222;文件組件323;存儲服務器33;mysql數據庫34;mongo數據庫35;工作流進程管理單元36;計算節點3701、3702…;nginx網頁服務器4。
具體實施方式
下面結合附圖和具體實施例對本發明作進一步說明。
實施例1
如圖1所示,本發明的基于云平臺的生物信息分析系統,包括云平臺客戶端1、云平臺web服務器2和云平臺計算系統3;
云平臺客戶端1和所述云平臺web服務器2之間通過網絡收發信息,云平臺web服務器2和所述云平臺計算系統3之間通過nginx網頁服務器4交換數據;
云平臺web服務器2包括生物信息分析請求接口21;
云平臺計算系統3包括生物信息分析應用接口31、生物信息分析組件32、存儲服務器33、mysql數據庫34和mongo數據庫35;
云平臺計算系統3還包括若干計算節點3701、3702等,用于對生物信息進行分析計算;云平臺計算系統3包含有分析各種不同生物信息的大規模計算節點,不同的分析組件被投遞到計算節點對生物信息進行分析計算;
生物信息分析請求接口21通過nginx網頁服務器4連接至生物信息分析應用接口31,生物信息分析應用接口31的輸出端通過工作流進程管理單元(wpm)36連接至生物信息分析組件32的輸入端,生物信息分析組件32的輸出端分別連接至存儲服務器33、mysql數據庫34和mongo數據庫35,mysql數據庫34和mongo數據庫35的輸出端分別通過nginx網頁服務器4連接至云平臺web服務器2;
生物信息分析請求接口21向生物信息分析應用接口31發出生物信息分析請求并發送參數;
存儲服務器33用于存儲分析結果數據,mysql數據庫34用于存儲分析記錄、狀態和日志信息,mongo數據庫35用于存儲供云平臺客戶端1展示的圖表數據。
優選地,生物信息分析組件32為即時模式分析組件或提交模式分析組件。
優選地,如圖2所示,提交模式分析組件32包括分析模塊322和文件組件323;
分析模塊322包括若干分析工具3222,各分析工具3222通過對應的工具代理3221與工作流進程管理單元36進行通信;不同的生物信息分析任務由不同功能的分析工具被投遞到單個或多個計算節點完成分析計算;
工作流進程管理單元36用于將不同的分析任務調度給不同的分析模塊222;
文件組件323用于使分析結果形成通用的生物信息數據格式并進行格式檢查。
優選地,工作流進程管理單元36通過slurm系統進行任務調度。
實施例2
如圖3所示,本發明的基于云平臺的生物信息分析方法,包括如下步驟:
s100:在客戶端向web服務器發出分析請求消息并輸入用于分析的參數;
s110:通過nginx網頁服務器接收請求消息后轉發至生物信息分析應用接口,解析參數;
s120:判讀參數為即時計算型還是投遞計算型;
s125:若為即時計算型,則直接在專用即時計算服務器上運行生物信息分析工作流;
s126:若為投遞計算型,則將參數傳遞至計算節點服務器上運行生物信息分析工作流;
s130:將生成的結果數據上傳到云平臺的存儲服務器和mongo數據庫;
s140:將生物信息分析工作流的運行狀態實時存入mysql數據庫;
s150:向web服務器返回分析成功的消息,web服務器從mongo數據庫獲取結果提供給客戶端。
優選地,投遞計算型的分析工作流如下:
工作流進程管理單元獲取參數后,按照內部預先定義的邏輯關系,將參數傳遞到生物信息分析組件的各分析模塊,觸發各分析模塊的運行,各分析模塊之間通過協程監聽互相有依賴關系的分析模塊的運行狀態,以各分析模塊中的各分析工具為最小級別分析組件,將各分析工具通過slurm投遞到計算節點開始計算分析,同時不斷監聽和接收分析的狀態。
本系統搭建在高性能集群中,是云平臺的后端數據存儲和分析計算系統,并通過nginx網頁服務器與云平臺的網絡端進行數據通訊,包括接收分析任務id和參數,發送分析計算狀態。
系統采用lustre可擴展并行文件系統存儲數據文件,為所有客戶機提供統一的命名空間,支持大規模高通量測序數據采集存儲、分析中間文件和結果文件存儲訪問,以及大量生物信息數據庫的存放,所有生物信息分析程序軟件可以統一安裝部署和特定的環境配置,數據和程序均可支持所有計算節點的統一訪問和調用。
系統中核心部分為自動化計算框架,包括以下部分:
nginx網頁服務器使用uwsgi協議接口進行客戶端與web框架應用之間的信息交換,響應云平臺網頁端的請求,本系統中采用web.py網絡框架來創建編寫生物信息分析計算應用接口。按照生物信息分析組件的模式組合分析計算工作流,實現后端數據在高性能集群上的自動化運算。
生物信息分析組件,包括流程(workflow)、模塊(moudule)、工具及其代理(tool,toolagent),以及定義生物信息數據格式的文件組件(file)。
工具是一個單一功能的生物信息分析組件,可調用一個或多個分析軟件、或自定義程序包,可以重復利用,實現一個分析功能。生物信息分析計算都是由工具為最小單位在計算節點上完成。由于計算節點屬于遠程服務器,因而需要一個工具代理負責與工具進行通信,工具與工具代理一一對應,通過網絡通信實現信息互通。
分析模塊完成一個特定的較復雜的分析功能,分析模塊中包含多個工具的組合,通過定義分析工具之間的運行邏輯來實現一個特定的分析功能。
流程完成一個完整的生信分析過程,通過定義運行邏輯,調用組合一系列的模塊和工具實現一套的分析流程方案。工具和模塊可以根據用戶的分析設計被復用在不同的流程中,從而實現一個分析應用一次打包反復使用的目的。
文件定義一種通用的生物信息數據格式,包含數據屬性和通用處理方法函數,工具、模塊之間通過在參數中設置輸入、輸出的文件對象傳遞數據,并進行格式驗證和文件處理通用方法的調用。
wpm工作流進程管理單元,系統通過wpm管理分析工作流的自動化運作。wpm監聽接收到的任務請求和參數,開啟一個進程運行工作流組件,并將參數傳遞給對應的工作流組件,流程組件中按照定義的邏輯關系,傳遞參數到其中的模塊和工具,觸發子組件的運行,并將工具投遞到計算節點開始計算分析,同時不斷監聽和接收運行的狀態。
slurm任務調度,系統中計算節點的任務運行調度采用了slurm系統來管理往計算節點的任務投遞,slurm是一種可用于大型計算節點集群的高度可伸縮容錯的集群管理器和作業調度系統。
數據庫系統,系統中將分析運行的狀態實時存入mysql數據庫,將分析計算結果數據按預先定義好的數據結構存入mongo數據庫,供網頁端服務器快速有效的獲取和查詢,實現云平臺的客戶端用戶快速直接的訪問數據。
為了提高用戶與數據快速、即時訪問的交互效率和體驗,本系統實現了兩種分析計算模式,一種是對于大規模數據分析運算耗時較長的任務采用提交模式,用戶不用等在客戶端,在客戶端點擊提交即可,運行完成前可隨時查看運行的進度。一種是對于小型數據或已處理后數據表進行耗時較短的分析時,系統自動判斷并使用即時模式,無需任務投遞,直接在專門配置的多個計算節點運行計算,并快速返回結果。
系統運行步驟如下:
1.云端web服務器通過客戶端瀏覽器提供給用戶網絡訪問平臺系統的方式,用戶在瀏覽器云平臺網站選擇生物信息分析應用,填寫參數提交后,客戶端將提交的數據通過網絡傳輸協議發送給web服務器,由nginx網頁服務器接收消息,nginx是一款面向性能設計的http服務器,支持高并發和高性能負載均衡,可并行接收數據請求,處理請求和返回響應。
2.nginx服務器接收到請求消息后,通過uwsgi接口將消息和參數傳遞給web.py框架中預先開發創建好的生物信息分析應用接口,由應用接口處理消息,對傳遞的參數進行解析和檢查后,開始啟動生物信息數據分析計算工作流;
3.wpm工作流進程管理啟動和管理分析工作流運行,wpm監聽接收到接口應用發起的任務請求和參數,通過應用類型參數判斷分析計算類型,包括兩種類型,一種是即時計算型,一種是投遞計算型,同時開啟一個進程運行工作流api,并將參數傳遞給對應的工作流;
4.如果接口應用是即時計算類型,計算耗時較短,工作流分析組件將直接在專用即時計算服務器上運行,生成的結果數據會上傳到平臺存儲服務器位置,同時將需要展示在客戶端網站的圖表數據存入生物信息分析mongo數據庫,供網頁端獲取展示,然后返回消息給web服務器,web服務器從數據庫獲取結果數據后展示給客戶端。用戶即可實時通過網絡查看分析結果。
5.如果接口應用是投遞計算類型,生物學數據需要經過較長時間(幾十分鐘到幾個小時不等),流程組件獲取參數后,按照內部預先定義的邏輯關系,傳遞參數到其中的模塊和工具,觸發子組件的運行,組件之間的通過協程監聽互相有依賴關系的模塊的運行狀態,到最小級別工具組件運行時,將工具通過slurm投遞到計算節點開始計算分析,同時不斷監聽和接收運行的狀態。工具的運行狀態通過工具代理與同一工作流中其他組件交換數據,運行當中會按照各組件自身的特性動態配置計算資源,并記錄運行狀態和進度、報錯等日志信息,如若出現連接或運行失敗,系統會根據預設的情況判斷是否調整配置重新計算,同時會不斷將運行進度狀態在數據庫中進行更新,web服務器端利用定時器獲取狀態后實時在頁面刷新進度,用戶可隨時跟蹤運行情況。計算運行結束后,結果數據會上傳到存儲服務器位置,同時將需要的數據存入生物信息分析mongo數據庫,返回消息給web服務器端,web服務器返回新的結果頁面,供用戶查看。
生物信息分析組件包括流程(workflow)、模塊(moudule)、工具及其代理(tool,toolagent),以及定義生物信息數據格式的文件組件(file)。流程是由模塊和工具根據具體的分析產品運行邏輯組合而成,模塊和工具之間具有依賴關聯關系,模塊或工具組件之間通過參數傳遞數據,包括輸入輸出文件參數和字段參數,輸入輸出文件參數需要預先定義一個該文件格式的文件組件,文件組件中會定義文件的屬性和方法,并對傳遞的文件格式進行檢查。組件之間的輸入輸出參數傳遞的是文件組件對象。在任務管理節點,一個流程中的組件包括模塊和工具代理,工具代理在啟動運行時通過slurm將任務投遞到計算節點對應的工具進行計算,并通過工具代理實時交換數據,工具代理給工具發送運行指令和計算所需參數,工具返回運行狀態和日志。一個組件如果依賴多個組件的計算結果,則需等待多個組件運行成功結束后自動激活運行。整個過程通過wpm流程管理進行監控和控制,從而實現分析系統的自動化運作。
以上述依據本發明的理想實施例為啟示,通過上述的說明內容,相關工作人員完全可以在不偏離本項發明技術思想的范圍內,進行多樣的變更以及修改。本項發明的技術性范圍并不局限于說明書上的內容,必須要根據權利要求范圍來確定其技術性范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!