基于連續功率譜分析的電力負荷預測優化方法與流程
本發明屬于電力系統
技術領域:
,具體涉及一種基于連續功率譜分析的電力負荷預測優化方法。
背景技術:
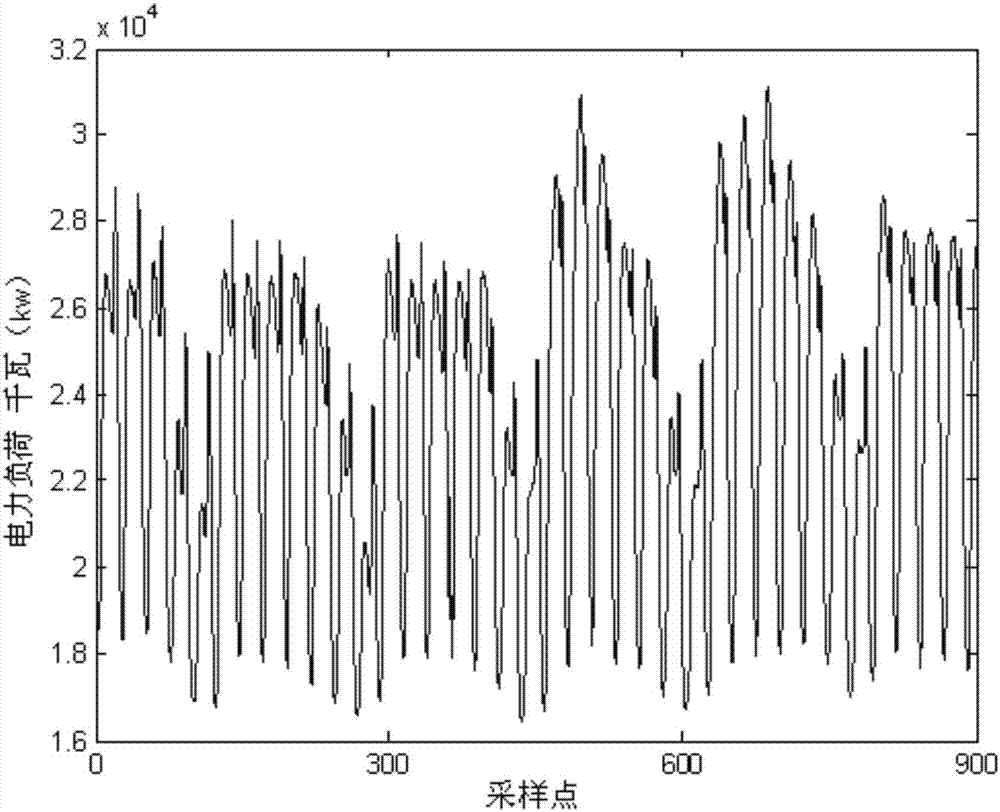
:電力系統負荷是指系統中所有用電設備消耗功率的總和,也稱電力系統綜合用電負荷。綜合用電負荷加上電網中的損耗和發電廠的廠用電,就是系統中所有發電機應發的總功率,也稱電力系統發電負荷。電力負荷是影響系統安全穩定運行的重要因素。電力負荷預測是指通過對電力負荷歷史記錄的分析研究,綜合考慮影響電力負荷變化的各種因素,如社會發展規劃、經濟狀況、氣象變化因素以及節假日等,對未來電力負荷的發展做出預先估計。電力負荷預測是電力系統規劃、計劃、調度、用電的依據。提高電力負荷預測技術水平,有利于制定合理的電源建設規劃,有利于合理安排電網運行方式和機組檢修計劃,有利于節煤、節油和降低發電成本,有利于計劃用電管理,有利于提高電力系統的經濟效益和社會效益。因此,電力負荷預測是實現電力系統管理現代化的重要內容之一。由于受天氣情況和人們社會活動等因素的影響,電力負荷數據存在大量的隨機性和非線性關系,影響電力負荷時間序列的因素可劃分為內在隨機因素和外在隨機因素,其中外在因素包括氣象、社會、經濟等,而內在因素是由電力系統內部非線性因素影響的結果,電力負荷是系統內在和外在隨機性影響因素共同作用的結果,其預測不準確的原因不僅僅是外在隨機因素的影響,更重要的是由系統內在動力學特征所決定。為此,涌現了多種預報方法,從一般統計模型,如arima時間序列模型、灰色模型等到各類智能模型,如神經網絡模型、支持向量機模型等等,算法的改進有望提高電力負荷的預報精度,但最根本的還是在于所使用的預測方法對于數據的學習和泛化性能。電力負荷受人類生產生活影響具有明顯的規律性,但這種規律性中又存在大量的隨機性,影響模型的學習和泛化能力。技術實現要素:為了解決上述技術問題,本發明旨在提供一種基于連續功率譜分析的電力負荷預測優化方法,通過連續功率譜分析,提取原始電力負荷時間序列中隱含的顯著周期序列并分離得到殘差序列,由于顯著周期序列占原序列比重大,并且規律性強,因此可以高精度預測,而殘差序列由于占原序列比重小因而誤差有限,從而保證了可以有效提高電力負荷預報的精度。實現上述技術目的,達到上述技術效果,本發明通過以下技術方案實現:一種基于連續功率譜分析的電力負荷預測優化方法,包括讀入原始采樣電力負荷時間序列,并按預報間隔要求將其轉換為平均電力負荷時間序列,然后計算出平均電力負荷時間序列的距平序列;采用連續功率譜分析方法,提取平均電力負荷時間序列的距平序列中隱含的顯著周期序列,并分離得到殘差序列;采用粒子群算法優化的bp神經網絡對顯著周期序列進行預測,獲得各顯著周期序列的預測結果;采用粒子群算法優化的rbf神經網絡對殘差序列的一階差分序列進行預測,后經差分反運算得到殘差序列的預測結果;將平均電力負荷時間序列的平均值與各顯著周期序列的預測結果以及殘差序列的預測結果相加獲得最終預測結果。進一步地,所述原始采樣電力負荷時間序列為p={p(i),i=1,2,...,n},其中n為原始電力負荷采樣點個數;所述平均電力負荷時間序列為p’={p’(j),j=1,2,...,m},其中m為按預報間隔要求轉換后的平均電力負荷序列的采樣點個數,p’的平均值為令所述平均電力負荷時間序列的距平序列為進一步地,所述顯著周期序列為{p1,p2,…,pk,…,pk},其中k為p中隱含的顯著周期序列的個數,pk={pk(1),pk(2),…,pk(m)},其中pk(1),pk(2),…,pk(m)分別為顯著周期序列pk的值;所述殘差序列為r=p-p1-p2-…-pk。進一步地,所述采用連續功率譜分析方法,提取平均電力負荷時間序列的距平序列中隱含的顯著周期序列,具體為:利用連續功率譜方法,分析平均電力負荷時間序列的距平序列的顯著周期帶,并利用快速傅立葉變換的頻域濾波方法提取各顯著周期帶對應的時間序列,從而獲得顯著周期序列。進一步地,所述采用基于粒子群算法優化的bp神經網絡對顯著周期序列進行預測的具體過程為:(1)依據kolmogorov定理,建立3層bp神經網絡模型,設輸入層神經元個數為i,隱含層神經元個數為h,輸出層神經元個數為o;其中,h=2*i+1,o=1;(2)確定需要優化的參數,包括:bp神經網絡的輸入層神經元個數i和訓練集的長度l,還包括:w=(w(1),w(2),...,w(q)),q=i*h+h*o+h+o,其中,w(1)~w(i*h)為bp神經網絡的輸入層至隱含層神經元的連結權值,w(i*h+1)~w(i*h+h*o)為bp神經網絡的隱含層至輸出層神經元的連結權值,w(i*h+h*o+1)~w(i*h+h*o+h)為bp神經網絡隱含層神經元的閾值,w(i*h+h*o+h+1)~w(i*h+h*o+h+o)為bp神經網絡輸出層神經元的閾值;(3)初始化種群x=(x1,x2,...,xq1),其中q1為粒子的總數,第i個粒子為xi=(ii,wi,li),粒子速度為vi=(vii,vwi,vli),其中ii、wi、li為參數i、w、l一組備選解;(4)根據群體中的每個粒子xi=(ii,wi,li)確定的參數,構造bp神經網絡訓練集的輸入和輸出矩陣,其中針對顯著周期序列pk及bp神經網絡輸入層神經元個數ii首先建立矩陣z1和z2,其中:針對待優化神經網絡訓練集長度l,z1中最后的li列作為訓練集的輸入矩陣itrain,z2中最后的li列作為訓練集的輸出矩陣otrain;將預報步長l作為測試步長,z1中最后的l列作為測試集的輸入矩陣itest,z2中最后的l列作為測試集的輸出矩陣otest;根據訓練集構造的bp神經網絡對測試集模擬結果的誤差平方和作為其適應度值,以適應度值最小為優化方向作為評價標準評判各個粒子的優劣,記錄粒子xi當前個體極值為pbest(i),取群體中pbest(i)最優的個體作為整體極值gbest;(5)群體中的每個粒子xi,分別對其位置和速度進行更新;式中:ω為慣性權重,c1、c2為加速度因子,g為當前迭代次數,r1、r2為分布于[0,1]的隨機數;(6)重新計算各個粒子此時的目標函數值,更新pbest(i)和gbest;(7)判斷是否達到最大迭代次數,如滿足則結束優化過程,獲得經粒子群算法優化得到的參數最優值為(ibest,wbest(wbest(1),wbest(2),...,wbest(q)),lbest),否則返回步驟(4);(8)按ibest、wbest(wbest(1),wbest(2),...,wbest(q))、lbest構造bp神經網絡訓練集z3和測試集z4并初始化bp神經網絡連結權值和閾值,其中:wbest(1)~wbest(i*h)為bp神經網絡的輸入層至隱含層神經元的連結權值的初始值,wbest(i*h+1)~wbest(i*h+h*o)為bp神經網絡的隱含層至輸出層神經元的連結權值的初始值,wbest(i*h+h*o+1)~wbest(i*h+h*o+h)為bp神經網絡隱含層神經元的閾值的初始值,wbest(i*h+h*o+h+1)~wbest(i*h+h*o+h+o)為bp神經網絡輸出層神經元的閾值的初始值,就此建立起bp神經網絡模型,經訓練后進行迭代的l步預測,并獲得對應的預測結果。進一步地,所述采用粒子群優化的rbf神經網絡對殘差序列的一次差分序列進行預測,具體過程為:(1)確定需優化參數,包括:rbf神經網絡輸入層神經元個數i和訓練集的長度l;(2)初始化種群其中q2為粒子的總數,第i個粒子為xi=(ii,li),粒子速度為其中ii,li為參數i、l一組備選解;(3)根據群體中的每個粒子確定的參數,構造rbf神經網絡訓練集的輸入和輸出矩陣,其中針對殘差序列r及rbf神經網絡輸入層神經元個數ii首先建立矩陣z5和z6,其中:針對待優化神經網絡訓練集長度l,z5中最后的li列作為訓練集的輸入矩陣itrain,z6中最后的li列作為訓練集的輸出矩陣otrain;將預報步長l作為測試步長,z5中最后的l列作為測試集的輸入矩陣itest,z6中最后的l列作為測試集的輸出矩陣otest;根據訓練集構造的rbf神經網絡對測試集模擬結果的誤差平方和作為其適應度值,以適應度值最小為優化方向作為評價標準評判各個粒子的優劣,記錄粒子xi當前個體極值為pbest(i),取群體中pbest(i)最優的個體作為整體極值gbest;(4)群體中的每個粒子xi,分別對其位置和速度進行更新;式中:ω為慣性權重,c1、c2為加速度因子,g為當前迭代次數,而r1、r2為分布于[0,1]的隨機數;(5)重新計算各個粒子此時的目標函數值,更新pbest(i)和gbest;(6)判斷是否達到最大迭代次數,如滿足則結束優化過程,獲得經粒子群算法優化得到的參數最優值為(ibest,lbest),否則返回步驟(3)。(7)按ibest和lbest構造rbf神經網絡訓練集z7和測試集z8,其中:就此建立起rbf神經網絡模型,經訓練后進行迭代的l步預測,并獲得對應的預測結果。進一步地,所述慣性權重ω=0.5,加速度因子c1=c2=1.49445。本發明的有益效果:(1)經連續功率譜分析提取的電力負荷顯著周期序列由于規律性強,因此可以高精度的進行預測,而且顯著周期序列在原電力負荷序列中所占比重較大,因此奠定了較高精度預測的基礎;剔除了周期信號后的殘差序列一方面由于在整體電力負荷序列中的比重不大,另一方面由于在處理的過程中進行了一次差分運算而變得平穩,其預測誤差相對有限,因此本發明所提出的將電力負荷序列經連續功率譜分析,分解為多個顯著周期序列和單個殘差序列,進而對各個顯著周期序列和殘差序列分別進行預測的方法可以大大提高整體預測效果。(2)針對神經網絡結構選擇不一對于預報性能的影響,本發明針對電力負荷序列分離出的顯著周期序列和殘差序列的特點,分別采用bp神經網絡和rbf神經網絡,并對于神經網絡的結構參數,訓練集規模采用粒子群算法進行優化,顯著改善了神經網絡的泛化性能,最終提高了預測精度。附圖說明圖1為本發明的基于連續功率譜分析的電力負荷預測優化方法的流程圖;圖2為原始電力負荷序列圖;圖3為平均電力負荷時間序列的距平序列的連續功率譜分析結果圖;圖4為平均電力負荷時間序列的距平序列提取的顯著周期序列及分離的殘差序列圖;圖5(a)為本發明方法的一步預測結果圖;圖5(b)為本發明方法的二步預測結果圖;圖5(c)為本發明方法的三步預測結果圖;圖6(a)為針對原始電力負荷序列建立粒子群優化rbf神經網絡一步預測結果圖;圖6(b)為針對原始電力負荷序列建立粒子群優化rbf神經網絡二步預測結果圖;圖6(c)為針對原始電力負荷序列建立粒子群優化rbf神經網絡三步預測結果圖圖7(a)為針對原始電力負荷序列建立的arima時間序列模型一步預測結果圖;圖7(b)為針對原始電力負荷序列建立的arima時間序列模型二步預測結果圖;圖7(c)為針對原始電力負荷序列建立的arima時間序列模型三步預測結果圖。具體實施方式為了使本發明的目的、技術方案及優點更加清楚明白,以下結合實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。下面結合附圖對本發明的應用原理作詳細的描述。本發明的一種基于連續功率譜分析的電力負荷預測優化方法,采用連續功率譜分析方法,提取電力負荷時間序列中隱含的顯著周期序列并分離得到殘差序列,采用基于粒子群算法優化的bp神經網絡對顯著周期序列進行預測,獲得各顯著周期序列的預測結果,采用粒子群算法優化的rbf神經網絡對殘差序列的一階差分序列進行預測,后經差分反運算得到殘差序列的預測結果,最后將平均電力負荷時間序列的平均值與各顯著周期序列的預測結果以及殘差序列的預測結果相加獲得最終預測結果。如圖1所示,具體地,包括以下步驟:s1,讀入原始采樣電力負荷時間序列,并按預報間隔要求將其轉換為平均電力負荷時間序列,然后計算出平均電力負荷時間序列的距平序列;所述原始采樣電力負荷時間序列為p={p(i),i=1,2,...,n},其中n為原始電力負荷采樣點個數;所述平均電力負荷序列為p’={p’(j),j=1,2,...,m},其中m為按預報間隔要求轉換后的平均電力負荷序列的采樣點個數,p’的平均值為令所述平均電力負荷時間序列的距平序列為s2,采用連續功率譜分析方法,提取平均電力負荷時間序列的距平序列中隱含的顯著周期序列,并分離得到殘差序列;所述顯著周期序列為{p1,p2,…,pk,…,pk},其中k為p中隱含的顯著周期序列的個數,pk={pk(1),pk(2),…,pk(m)},其中pk(1),pk(2),…,pk(m)分別為顯著周期序列pk的值;所述殘差序列為r=p-p1-p2-…-pk;因此,p=p1+p2+…+pk+r。上述的提取過程,具體如下:假設一離散時間序列為xt,其中t=0,1,...,n-1,共n個采樣點,時間間隔δt=1,應用連續功率譜估計方法,分析該離散時間序列的顯著周期帶,并利用傅立葉變換fft的頻域濾波方法提取各顯著周期帶對應的時間序列,具體包括以下步驟:(1)確定連續功率譜值首先計算xt連續功率譜粗譜估計值:其中:為h波數對應的連續功率譜粗譜估計值,h為波數,h=0,1,…m,m=n/8,r(τ)為時間序列xt的落后時間長度為τ的自相關系數:其中,和s分別為離散時間序列xt的平均值和標準差。為了消除粗譜估計值的小波動,對(1)式進行漢寧平滑,平滑后為連續功率譜值(即圖3實線所示)為:s0為0波數對應的連續功率譜值;sh為h波數對應的連續功率譜值,sm為m波數對應的連續功率譜值。(2)確定分析周期h波數對應的周期為:(即圖3橫坐標對應的周期點),本發明實施例中考慮m=n8,則(3)連續功率譜信度檢驗將式(3)所得連續功率譜值與紅噪音譜值進行比較,判斷其顯著性。假設式(3)所得連續功率譜值為某一非周期性過程譜值,h波數對應的連續功率譜值sh與平均紅噪音譜值之比遵從被其自由度ν去除的χ2分布:其中平均紅噪音譜值為:式中,為式(3)中計算所得的所有波數的連續功率譜值的平均值,r(1)為xt落后時間長度為1的自相關系數,而自由度ν為:本發明實施例選取在0.05顯著性水平下,當時,該波數的譜值是顯著的,則該周期波動是顯著的,為圖3中虛線檢驗線。(4)提取周期帶對應的時間序列周期帶的確定:取步驟(3)所選顯著連續功率譜值左右兩側各第一個低于紅噪音檢測線的周期點,組成周期帶,此周期帶為顯著周期帶,其中圖3中左側第一低于紅噪音檢測線的點定為周期帶的上界,圖3中右側第一低于紅噪音檢測線的點定為周期帶的下界。周期帶對應的時間序列的提取:本發明實施例采用中國科學院測量與地球物理研究所開發的地學數據處理程序庫whiggf90lib(wfl),通過應用該軟件的傅立葉變換fft的頻域濾波子程序,來提取周期帶對應的時間序列,該子程序為:callfft_filter(n,x,dt,per1,per2,fil_method,xout)其中n為總采樣點個數,x即為xt,dt為采樣時間間隔δt,per1為提取周期帶下界,per2為提取周期帶上界,fil_method為濾波類型,這里取“band”,指代為帶狀周期,xout為提取的顯著周期帶對應的時間序列。s3,采用基于粒子群優化的bp神經網絡對顯著周期序列進行預測,其具體過程為;(1)依據kolmogorov定理,一個3層bp神經網絡能夠實現對任意非線性函數進行逼近,因此,本發明實施例建立3層bp神經網絡模型,設輸入層神經元個數為i,隱含層神經元個數為h,輸出層神經元個數為o;其中,h=2*i+1,o=1;(2)確定需要優化的參數,包括:bp神經網絡的輸入層神經元個數i和訓練集的長度l,還包括:w=(w(1),w(2),...,w(q)),q=i*h+h*o+h+o,其中,w(1)~w(i*h)為bp神經網絡的輸入層至隱含層神經元的連結權值,w(i*h+1)~w(i*h+h*o)為bp神經網絡的隱含層至輸出層神經元的連結權值,w(i*h+h*o+1)~w(i*h+h*o+h)為bp神經網絡隱含層神經元的閾值,w(i*h+h*o+h+1)~w(i*h+h*o+h+o)為bp神經網絡輸出層神經元的閾值;(3)初始化種群x=(x1,x2,...,xq1),其中q1為粒子的總數,第i個粒子為xi=(ii,wi,li),粒子速度為vi=(vii,vwi,vli),其中ii、wi、li為參數i、w、l一組備選解;(4)根據群體中的每個粒子xi=(ii,wi,li)確定的參數,構造bp神經網絡訓練集的輸入和輸出矩陣,其中針對顯著周期序列pk及bp神經網絡輸入層神經元個數ii首先建立矩陣z1和z2,其中:針對待優化神經網絡訓練集長度l,z1中最后的li列作為訓練集的輸入矩陣itrain,z2中最后的li列作為訓練集的輸出矩陣otrain;將預報步長l作為測試步長,z1中最后的l列作為測試集的輸入矩陣itest,z2中最后的l列作為測試集的輸出矩陣otest;根據訓練集構造的bp神經網絡對測試集模擬結果的誤差平方和作為其適應度值,以適應度值最小為優化方向作為評價標準評判各個粒子的優劣,記錄粒子xi當前個體極值為pbest(i),取群體中pbest(i)最優的個體作為整體極值gbest;(5)群體中的每個粒子xi,分別對其位置和速度進行更新;式中:ω為慣性權重,c1、c2為加速度因子,g為當前迭代次數,r1、r2為分布于[0,1]的隨機數;(6)重新計算各個粒子此時的目標函數值,更新pbest(i)和gbest;(7)判斷是否達到最大迭代次數,如滿足則結束優化過程,獲得經粒子群算法優化得到的參數最優值為(ibest,wbest(wbest(1),wbest(2),...,wbest(q)),lbest),否則返回步驟(4);(8)按ibest、wbest(wbest(1),wbest(2),...,wbest(q))、lbest構造bp神經網絡訓練集z3和測試集z4并初始化bp神經網絡連結權值和閾值,其中:wbest(1)~wbest(i*h)為bp神經網絡的輸入層至隱含層神經元的連結權值的初始值,wbest(i*h+1)~wbest(i*h+h*o)為bp神經網絡的隱含層至輸出層神經元的連結權值的初始值,wbest(i*h+h*o+1)~wbest(i*h+h*o+h)為bp神經網絡隱含層神經元的閾值的初始值,wbest(i*h+h*o+h+1)~wbest(i*h+h*o+h+o)為bp神經網絡輸出層神經元的閾值的初始值,就此建立起bp神經網絡模型,經訓練后進行迭代的l步預測,并獲得對應的預測結果。s4,采用粒子群優化的rbf神經網絡對殘差序列的一階差分序列進行預測,具體過程為:(1)確定需優化參數,包括:rbf神經網絡輸入層神經元個數i和訓練集的長度l;(2)初始化種群其中q2為粒子的總數,第i個粒子為xi=(ii,li),粒子速度為其中ii,li為參數i、l一組備選解;(3)根據群體中的每個粒子xi(ii,li)確定的參數,構造rbf神經網絡訓練集的輸入和輸出矩陣,其中針對殘差序列r及rbf神經網絡輸入層神經元個數ii首先建立矩陣z5和z6,其中:針對待優化神經網絡訓練集長度l,z5中最后的li列作為訓練集的輸入矩陣itrain,z6中最后的li列作為訓練集的輸出矩陣otrain;將預報步長l作為測試步長,z5中最后的l列作為測試集的輸入矩陣itest,z6中最后的l列作為測試集的輸出矩陣otest;根據訓練集構造的rbf神經網絡對測試集模擬結果的誤差平方和作為其適應度值,以適應度值最小為優化方向作為評價標準評判各個粒子的優劣,記錄粒子xi當前個體極值為pbest(i),取群體中pbest(i)最優的個體作為整體極值gbest;(4)群體中的每個粒子xi,分別對其位置和速度進行更新;式中:ω為慣性權重,c1、c2為加速度因子,g為當前迭代次數,而r1、r2為分布于[0,1]的隨機數;(5)重新計算各個粒子此時的目標函數值,更新pbest(i)和gbest;(6)判斷是否達到最大迭代次數,如滿足則結束優化過程,獲得經粒子群算法優化得到的參數最優值為(ibest,lbest),否則返回步驟(3)。(7)按ibest和lbest構造rbf神經網絡訓練集z7和測試集z8,其中:就此建立起rbf神經網絡模型,經訓練后進行迭代的l步預測,并獲得對應的預測結果。s5,將平均電力負荷時間序列的平均值與各顯著周期序列的預測結果以及殘差序列的預測結果相加獲得最終預測結果。實施例二按照實施例一中的步驟s1-s5,取某電網采集的小時級別的原始電力負荷時間序列,具體參見圖2,由于本發明實例的目的為小時級別的短期預報,因此無需對原始電力負荷數據做任何調整就可以直接使用,即p’(i)=p(i),i=1,2,...,n。本實施例中取p’(i)前1680個點為訓練數據,預測其后的50個點,并以相對百分比誤差mape為指標考查算法的有效性,即:其中,y(i)和p’(i)分別為電力負荷預測值和采樣值,l為預測步長。圖3所示為平均電力負荷時間序列的距平序列p的連續功率譜分析結果,發現該電網電力負荷序列具有12和24小時為極值點的2個顯著周期帶,取其極值點左右兩側各第一個低于檢測線的周期點,組成周期帶,此周期帶為顯著周期帶,所述的檢測線為圖3中的虛線,在本實施例中,2個顯著周期帶分別為[21.8,26.7]和[11.4,12.6],采用傅立葉變換fft的頻域濾波的方法,提取此2個周期帶對應的時間序列,分別為p1、p2,并得到對應的殘差序列r,由此p=p1+p2+r,見圖4。可見,2個顯著周期序列的規律性極強,可以較高精度的預測;另一方面,雖然針對殘差的預測誤差不可避免,但經計算,殘差r的能量(方差)占比p的能量(方差)為28.56%,下降顯著,因此,針對殘差的預測誤差要遠遠小于直接對于p進行預測的誤差。雖然神經網絡具有強大的非線性擬合能力和快速的學習能力,但如何選擇恰當的神經網絡模型,確定神經網絡的結構、訓練集和測試集仍主要靠人工經驗或者試湊,其普適性較差。通過對提取的顯著周期序列分析發現,雖然其具有明顯的周期變化特點且序列光滑平順,但其中序列的振幅和相位隨時間細微的變化,更適合容錯能力較強的bp神經網絡,而殘差序列經一階差分后呈現圍繞0軸波動,更適合于rbf神經網絡,因此本發明實施例對提取的顯著周期序列p1、p2采用基于粒子群算法優化的bp神經網絡模型,而對于殘差序列r則采用基于粒子群算法優化的rbf神經網絡。對p1、p2采用基于粒子群算法優化的bp神經網絡模型,取輸入層神經元個數的范圍為[5,14],訓練集的長度為[50,1650],神經網絡權值和閾值的范圍為[-3,3],粒子群種群規模是50,迭代30次。對于r則采用基于粒子群算法優化的rbf神經網絡,取輸入層神經元個數的范圍為[5,20],訓練集的長度為[50,1650],粒子群種群規模是50,迭代30次。表1所示為進行3步預測時,針對顯著周期序列p1、p2和殘差r的輸入層神經元個數i和訓練集長度l兩個參數的優化結果,對于p1、p2建立的bp神經網絡權值和閾值的優化結果由于參數過多而不一一列出。表1本實施例進行了總預測步長為50的1步、2步和3步預測實驗,預測結果如圖5(a)-(c)所示,表2為預測誤差統計。可見,隨著預測步長的增加,整體預測精度有所下降,但總體誤差小于5%,預測結果較為滿意。表21步預測2步預測3步預測mape0.03990.04360.0434對比實驗1為了驗證本發明提出的優化策略對實驗結果的影響,對比實驗1對原始電力負荷序列p’直接進行一次差分運算,之后建立粒子群算法優化的rbf神經網絡,取輸入層神經元個數的范圍為[5,25],訓練集的長度為[50,1650],粒子群種群規模是50,迭代30次。表3所示為進行3步預測時,針對原始電力負荷序列p’建立的rbf神經網絡參數優化結果。表3同樣的,對比實驗1進行了總預測步長為50的1步、2步和3步預測實驗,預測結果如圖6(a)-(c)所示,表4為預測誤差統計,對比表2可見,其1~3步預測的平均誤差比表2增加了60.44%。表41步預測2步預測3步預測mape0.03950.07080.0933若不對p’進行一次差分運算,隨意選取rbf神經網絡的輸入層神經元個數i和訓練集長度l,最終的預測誤差差異會很大,本發明實施例選取兩組不同i和l對最終的預測誤差的影響加以說明,如表5所示。表5兩組不同參數的對比實驗其1~3步預測的平均誤差比表2增加了47.68%和170.61%。此組對比實驗效果不好顯示出神經網絡參數的選擇對于神經網絡的學習能力和泛化造成巨大的影響,使得直接采用神經網絡建模效果并不好。對比實驗2針對原始電力負荷序列建立差分自回歸移動平均模型(autoregressiveintegratedmovingaveragemodel,arima)模型。選取預測點前100個采樣數據點,通過aic準則定階法確定arima模型的結構,同樣的,對比實驗2進行了總預測步長為50的1步、2步和3步預測實驗,預測結果如圖7(a)-(c)所示,表6為預測誤差統計,對比表2可見,其1~3步預測的平均誤差比表2增加了136.25%。表61步預測2步預測3步預測mape0.01690.14860.1343綜上所述:經連續功率譜分析提取的電力負荷顯著周期序列規律性強,因此可以高精度的進行預測,而且顯著周期序列在原序列中所占比重較大,因此奠定了較高精度預測的基礎;剔除了顯著周期序列后的殘差序列由于在原序列中比重不大,因此預測誤差相對有限。本發明所提出的將電力負荷序列經連續功率譜分析,分解為多個顯著周期序列和單個殘差序列,進而對各個顯著周期序列和殘差序列分別進行預測的方法可以大大提高整體預測效果。以上顯示和描述了本發明的基本原理和主要特征和本發明的優點。本行業的技術人員應該了解,本發明不受上述實施例的限制,上述實施例和說明書中描述的只是說明本發明的原理,在不脫離本發明精神和范圍的前提下,本發明還會有各種變化和改進,這些變化和改進都落入要求保護的本發明范圍內。本發明要求保護范圍由所附的權利要求書及其等效物界定。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1