一種基于離子遷移譜的香精品牌識別本體模型構建方法與流程
本發明是計算機信息技術在領域的應用,具體是一種基于離子遷移譜的香精品牌識別本體模型構建方法。
背景技術:
質量保證(qualityassurance)指為使人們確信某一產品、過程或服務的質量所必須的全部有計劃有組織的活動。質量保證實踐被視為國際貿易的核心,特別是對食品和藥品。然而,許多流行的產品沒有被完全指定,質量保證成為一個更具挑戰性的事業。
隨著經濟的快速發展,人們的物質生活水逐漸提高,人們對質量的要求也越來越高。天然香精很容易被消費者接受,但其組成因氣候、種類和人為原因而改變。目前,在中國常用的是合成蘋果香精,在中國市場上,生產廠家生產數十種品牌的蘋果香精,價格和質量各不相同。但是,蘋果香精的鑒別,尤其是制造商的鑒別,已經投入了一點精力。相關生產技術不開放,缺乏國家標準給市場管理帶來困難。
目前,香精質量主要由感官評價和物理指標控制。前者以鼻為識別工具,受人員水平、身體狀況、環境等因素的影響,不能準確反映內在質量和質量波動。后者只能反映一些本質的一般特征,具有測試內容多、操作復雜、測試時間長、效率低等特點。由于香精的應用日益穩定,迫切需要開發一套合適的質量評價方法。
合成香精是一種包含十幾種成分的復雜混合物。因此,傳統的分析方法只能分析成分比較單一或成分不夠復雜的物品,不適合應用于質量評價。指紋技術是將光譜、色譜、質譜等技術作為一種檢測手段,可以反映樣品的系統特征而不是單個成分。這種技術特別適合于復雜樣品的質量評價。目前,指紋技術已被用于食品,藥品和其他產品的質量和安全監測,能夠使分析更加準確、可靠。
離子遷移譜(ims)是一種重要的分離氣相離子在大氣壓力下的分離技術,最早應用于軍事和航空安全領域。目前,離子遷移譜沒有分析錯誤的相關問題,到目前為止,很少有報道ims基于質量分析的物質。
本體(ontology)是近幾年計算機各領域關注的熱點,已經在自然語言處理、知識工程、智能信息集成、協同信息系統、知識管理、internet智能信息獲取等各方面得到深入研究。本體論是當今的一種新型的知識的表達方式,近年來在信息技術領域得到快速發展,它將信息經過整理加工、解釋和改造來形成結構化的知識表示方式,以便實現知識的共享和復用。
基于上述描述的情況,本發明將離子遷移譜應用到本體領域中,提出了一種基于離子遷移譜的香精品牌識別本體模型構建的方法,在對香精品牌識別相關理論分析的基礎上,建立一個科學合理的識別本體模型,使本文研究內容對香精品牌識別起到決策支持的作用。通過protege軟件在對傳統本體模型的研究基礎上構建了基于離子遷移譜的香精品牌識別本體模型。通過距離公式進行樣本間的相似度度量來實現樣本分類,基于對分類結果的分析,構建本體規則,通過推理機來實現規則推理,從而真正意義上起到對香精品牌的識別作用。
技術實現要素:
基于背景技術提出的問題,本發明提出了一種基于離子遷移譜的香精品牌識別本體構建方法。
1.一種基于離子遷移譜的香精品牌識別本體模型構建方法,其特征在于,所述方法包括:
s1通過離子遷移譜采集正負離子模式下樣本的數據;通過距離公式進行不同樣本之間的相似性度量;通過聚類分析,基于相似性度量,建立本體分類規則;
s2結合本體的概念,建立本體知識庫,構建一種基于離子遷移譜的香精品牌識別本體模型;
s3通過查詢功能,輸入食品安全領域的相關關鍵詞,查詢相關的概念以及相應的層次關系,從而了解食品安全的相關信息。
2如權利要求1所述的方法,其特征在于,s1的具體過程如下:
基于四個不同品牌的32個香精樣本,利用離子遷移譜采集樣本分別在正負離子模式下的譜圖,選取兩個具有代表性的頻重復試驗,為了排除溶劑峰和波動較小的影響,選取的光譜區域分別為正離子模式下10-17.5毫秒和負離子模式下7.5-15毫秒;
基于上述方法分別在正負離子模式下,采取余弦距離進行樣本的相似性度量;
根據樣本間的的相似度,對樣本的聚類,從而實現對四個不同品牌的香精樣本的分類;
基于上述計算得出的相似度值,各個樣本相似度的取值范圍,以及分類的結果,建立本體模型的規則庫。
3.如權利1所述方法,其特征在于,s2的具體步驟如下:
步驟1確定該本體模型所描述的對象為四個不同品牌的香精,明確建立該本體模型的目的是識別不同品牌的香精,以及所能解決的問題;
步驟2現有本體模型主要針對建筑、交通等領域,考察已有本體模型的重復利用性,參考已有的本體模型,結合所研究對象香精,進行綜合全面的考慮;
步驟3列出所研究香精領域本體的重要術語;
步驟4根據列出的重要術語,定義該本體模型中的類以及各類之間的層次關系,主要依據香精領域內的概念以及概念間的關系;
步驟5用owl本體語言定義屬性以及屬性間的關系,本體中的屬性主要包括數值型屬性和對象型屬性;定義屬性的類型、取值、取值的定義域、值域以及限制條件等;
步驟6根據利用距離公式進行的相似性度量結果,建立該本體模型規則;
步驟7將確定類的實例填充到本體之中,并對實例的屬性值等進行填充,此處的實例即為基于離子遷移譜采集的樣本。
本發明提出的一種基于離子遷移譜的香精品牌識別本體模型構建方法,是一個有效的模型,能夠對實現香精品牌識別知識的共享和復用,對香精品牌的識別起到了決策支持作用。
附圖說明
圖1為本發明提出的基于離子遷移譜的香精品牌識別本體模型構建的流程圖;
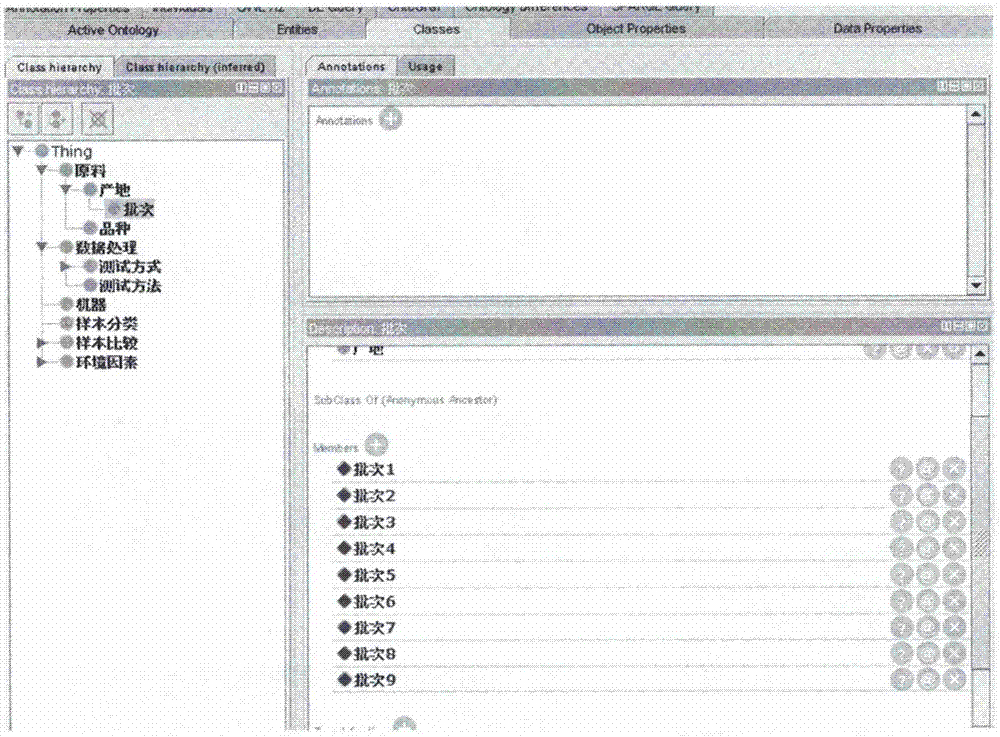
圖2為本發明本體模型中定義的類;
圖3為本發明類與類的層次關系圖;
圖4為本發明本體查詢示例圖。
具體實施方式
參照圖1,本發明提出了一種基于離子遷移譜的香精品牌識別本體模型構建方法,具體步驟如下:
1.一種基于離子遷移譜的香精品牌識別本體模型構建方法,其特征在于,所述方法包括:
s1通過離子遷移譜采集正負離子模式下樣本的數據;通過距離公式進行不同樣本之間的相似性度量;通過聚類分析,基于相似性度量,建立本體分類規則;
s2結合本體的概念,建立本體知識庫,構建一種基于離子遷移譜的香精品牌識別本體模型;
s3通過查詢功能,輸入食品安全領域的相關關鍵詞,查詢相關的概念以及相應的層次關系,從而了解食品安全的相關信息。
2.如權利要求1所述的方法,其特征在于,s1的具體過程如下:
基于四個不同品牌的32個香精樣本,利用離子遷移譜采集樣本分別在正負離子模式下的譜圖,選取兩個具有代表性的頻重復試驗,為了排除溶劑峰和波動較小的影響,選取的光譜區域分別為正離子模式下10-17.5毫秒和負離子模式下7.5-15毫秒;
基于上述方法分別在正負離子模式下,采取余弦距離進行樣本的相似性度量;
根據樣本間的的相似度,對樣本的聚類,從而實現對四個不同品牌的香精樣本的分類;
基于上述計算得出的相似度值,各個樣本相似度的取值范圍,以及分類的結果,建立本體模型的規則庫。
3.如權利1所述方法,其特征在于,s2的具體步驟如下:
步驟1確定該本體模型所描述的對象為四個不同品牌的香精,明確建立該本體模型的目的是識別不同品牌的香精,以及所能解決的問題;
步驟2現有本體模型主要針對建筑、交通等領域,考察已有本體模型的重復利用性,參考已有的本體模型,結合所研究對象香精,進行綜合全面的考慮;
步驟3列出所研究香精領域本體的重要術語;
步驟4根據列出的重要術語,定義該本體模型中的類以及各類之間的層次關系,主要依據香精領域內的概念以及概念間的關系;
步驟5用owl本體語言定義屬性以及屬性間的關系,本體中的屬性主要包括數值型屬性和對象型屬性;定義屬性的類型、取值、取值的定義域、值域以及限制條件等;
步驟6根據利用距離公式進行的相似性度量結果,建立該本體模型規則;
步驟7將確定類的實例填充到本體之中,并對實例的屬性值等進行填充,此處的實例即為基于離子遷移譜采集的樣本。
- 還沒有人留言評論。精彩留言會獲得點贊!