圖像的識別方法及裝置與流程
本發明涉及圖像處理技術領域,具體而言,涉及一種圖像的識別方法及裝置。
背景技術:
黑色素瘤皮膚癌是世界上最快速增長和最致命的癌癥之一,占皮膚癌死亡的75%。早期診斷對于治療這種疾病非常重要,因為它可以在早期階段很容易治愈。為了改善這種疾病的診斷,引入皮膚鏡檢查以協助皮膚科醫生進行臨床檢查,因為它是一種無創性皮膚成像技術,可為臨床醫生提供高質量的皮膚損傷視覺感受。與傳統的宏觀(臨床)圖像相比,更少的表面反射,更深層次的細節和更低的篩選誤差使得皮膚鏡檢查圖像獲得更好的可見度和識別精度。由于黑色素瘤比非黑色素瘤皮膚癌更致命,癌癥與非癌性黑色素瘤皮膚鏡檢查圖像之間的區別已經引起了極大關注。臨床上,已經開發了幾種啟發式方法,例如“abcd”規則,menzies方法和“cash”,以增強臨床醫生辨別黑色素瘤與良性的能力。然而,即使對于經驗豐富的專業人士,皮膚病變的正確診斷也是非常重要的。此外,通過人眼目視檢查進行的皮膚鏡診斷通常是費力、耗時和主觀的。因此,準確性不佳,再現性差,仍然是診斷這種疾病的問題。
為了解決這些問題,目前提出了許多用于自動皮膚鏡像分析的算法,大多數主要集中在特征提取,無論是隱含的還是明確的,都假設輸入圖像包含完整的病變對象。然而皮膚鏡檢圖像可能并不總是包含整個病變區域,或者病變區域僅占據圖像的一小部分。針對惡性皮膚病變和良性皮膚病變圖像之間的類內和類間差異較大,現有方法中通過人工標注的特征所提供的診斷性能仍不能令人滿意,尤其現有方法不僅包含復雜而繁瑣的程序,而且費力、耗時和主觀,導致臨床實踐中的普遍性和適用性差。
技術實現要素:
有鑒于此,本發明實施例的目的在于提供一種圖像的識別方法及裝置,以改善上述問題。為了實現上述目的,本發明采取的技術方案如下:
第一方面,本發明實施例提供了一種圖像的識別方法,所述方法包括:對獲取到的待識別圖像進行圖像增強,獲得圖像增強后的待識別圖像;根據預設的深度殘差神經網絡對所述圖像增強后的待識別圖像進行特征提取,獲得特征信息;對所述特征信息進行fisher向量編碼,獲得fisher特征向量;根據預設的分類器及所述特征向量對所述待識別圖像進行識別,獲得識別結果。
第二方面,本發明實施例提供了一種圖像的識別裝置,所述裝置包括:圖像增強單元、特征提取單元、編碼單元和識別單元。圖像增強單元,用于對獲取到的待識別圖像進行圖像增強,獲得圖像增強后的待識別圖像。特征提取單元,根據預設的深度殘差神經網絡對所述圖像增強后的待識別圖像進行特征提取,獲得特征信息。編碼單元,用于對所述特征信息進行fisher向量編碼,獲得fisher特征向量。識別單元,用于根據預設的分類器及所述特征向量對所述待識別圖像進行識別,獲得識別結果。
本發明實施例提供了一種圖像的識別方法及裝置,對獲取到的待識別圖像進行圖像增強,獲得圖像增強后的待識別圖像;再根據預設的深度殘差神經網絡對所述圖像增強后的待識別圖像進行特征提取,獲得特征信息;對所述特征信息進行fisher向量編碼,獲得fisher特征向量;然后根據預設的分類器及所述特征向量對所述待識別圖像進行識別,獲得識別結果,以此實現利用深度殘差神經網絡和fisher向量編碼,對待識別的圖像提取更多的判別特征,再進行分類處理,根據分類結果快速識別出所述待識別的圖像,操作簡單,更高效、更準確,適用性強。
本發明的其他特征和優點將在隨后的說明書闡述,并且,部分地從說明書中變得顯而易見,或者通過實施本發明實施例了解。本發明的目的和其他優點可通過在所寫的說明書、權利要求書、以及附圖中所特別指出的結構來實現和獲得。
附圖說明
為了更清楚地說明本發明實施例的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,應當理解,以下附圖僅示出了本發明的某些實施例,因此不應被看作是對范圍的限定,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他相關的附圖。
圖1為一種可應用于本申請實施例中的電子設備的結構框圖;
圖2為本發明第一實施例提供的圖像的識別方法的流程圖;
圖3為本發明第一實施例提供的圖像的識別方法中的步驟s200的詳細流程圖;
圖4為本發明第二實施例提供的圖像的識別裝置的結構框圖。
具體實施方式
下面將結合本發明實施例中附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。通常在此處附圖中描述和示出的本發明實施例的組件可以以各種不同的配置來布置和設計。因此,以下對在附圖中提供的本發明的實施例的詳細描述并非旨在限制要求保護的本發明的范圍,而是僅僅表示本發明的選定實施例。基于本發明的實施例,本領域技術人員在沒有做出創造性勞動的前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
應注意到:相似的標號和字母在下面的附圖中表示類似項,因此,一旦某一項在一個附圖中被定義,則在隨后的附圖中不需要對其進行進一步定義和解釋。同時,在本發明的描述中,術語“第一”、“第二”等僅用于區分描述,而不能理解為指示或暗示相對重要性。
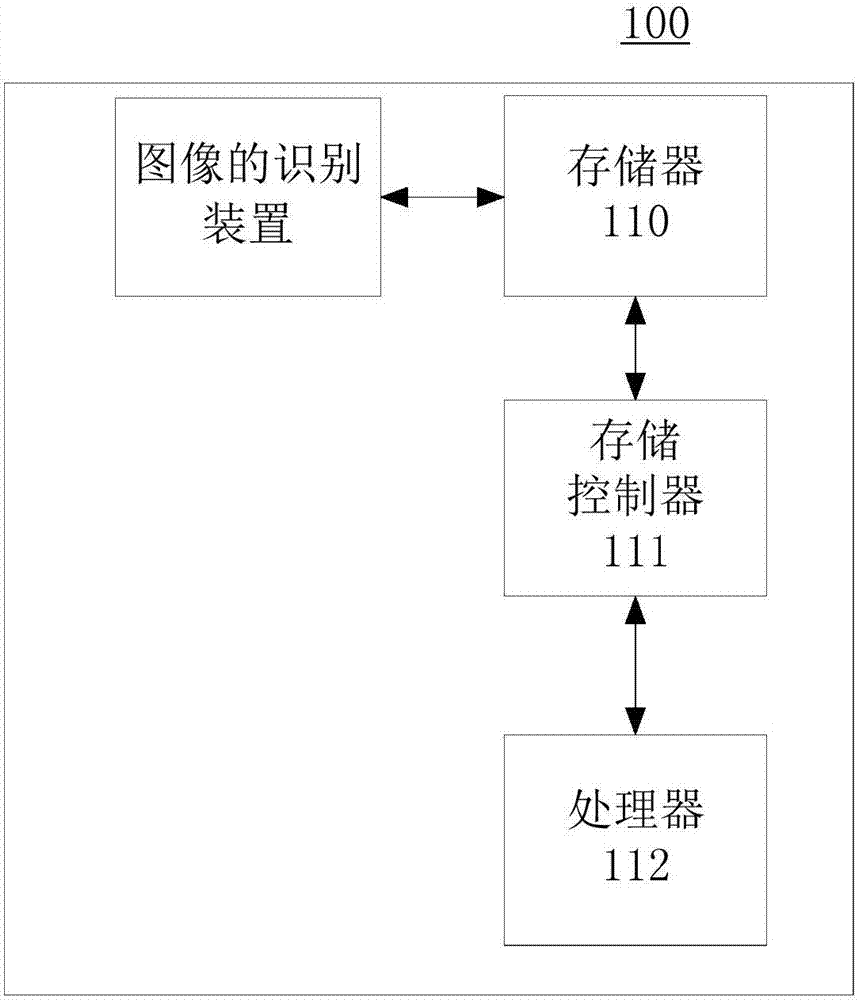
請參閱圖1,圖1示出了一種可應用于本申請實施例中的電子設備100的結構框圖。該電子設備100可以作為用戶終端,也可以作為服務器。所述用戶終端可以個人電腦(personalcomputer,pc)、平板電腦、智能手機、個人數字助理(personaldigitalassistant,pda)等終端設備。如圖1所示,電子設備100可以包括存儲器110、存儲控制器111、處理器112和圖像的識別裝置。
存儲器110、存儲控制器111、處理器112各元件之間直接或間接地電連接,以實現數據的傳輸或交互。例如,這些元件之間可以通過一條或多條通訊總線或信號總線實現電連接。圖像的識別方法分別包括至少一個可以以軟件或固件(firmware)的形式存儲于存儲器110中的軟件功能模塊,例如所述圖像的識別裝置包括的軟件功能模塊或計算機程序。
存儲器110可以存儲各種軟件程序以及模塊,如本申請實施例提供的圖像的識別方法及裝置對應的程序指令/模塊。處理器112通過運行存儲在存儲器110中的軟件程序以及模塊,從而執行各種功能應用以及數據處理,即實現本申請實施例中的圖像的識別方法。存儲器110可以包括但不限于隨機存取存儲器(randomaccessmemory,ram),只讀存儲器(readonlymemory,rom),可編程只讀存儲器(programmableread-onlymemory,prom),可擦除只讀存儲器(erasableprogrammableread-onlymemory,eprom),電可擦除只讀存儲器(electricerasableprogrammableread-onlymemory,eeprom)等。
處理器112可以是一種集成電路芯片,具有信號處理能力。上述處理器可以是通用處理器,包括中央處理器(centralprocessingunit,簡稱cpu)、網絡處理器(networkprocessor,簡稱np)等;還可以是數字信號處理器(dsp)、專用集成電路(asic)、現成可編程門陣列(fpga)或者其他可編程邏輯器件、分立門或者晶體管邏輯器件、分立硬件組件。其可以實現或者執行本申請實施例中的公開的各方法、步驟及邏輯框圖。通用處理器可以是微處理器或者該處理器也可以是任何常規的處理器等。
第一實施例
請參閱圖2,本發明實施例提供了一種圖像的識別方法,所述方法包括:
步驟s200:對獲取到的待識別圖像進行圖像增強,獲得圖像增強后的待識別圖像。
為了保證對待識別的圖像提取的特征的準確性,作為一種實施方式,請參閱圖3,所述步驟s200可以包括子步驟s201、子步驟s202和子步驟s203。
子步驟s201:基于預設的尺度調整規則及獲取到的待識別圖像,獲得調整后的待識別圖像。
由于利用深度殘差神經網絡(deepresidualneuralnetwork,resnet)來提取特征,通常使用固定和平方大小的圖像作為輸入圖像,例如227×227或224×224大小的圖像。因此,可以將圖像裁剪大小并且裁剪成所需的尺寸以進行訓練或者特征提取。然而,獲取到的圖像分辨率可能存在巨大變化,范圍為從最小尺存(722×542)到最大尺寸(4288×2848)。將這些圖像直接調整大小并將其裁剪成所需尺寸會導致對象失真和實質性信息的丟失。此外,在遷移任務中,預設的深度殘差神經網絡可能并不完全適應未知數據的分布。在這種情況下,將皮膚圖像調整到所需的相同尺寸會導致重要的信息丟失。另外保持圖像的長寬比是有益的,因為空間信息被更好地保存。因此,采取相對較大的(與224×224相比)和非正方形的圖像作為輸入。可以將圖像沿著最短邊調整到一個統一的尺度(以下簡稱為“s”),同時保持縱橫比。
進一步地,基于子步驟s201,具體地,所述預設的尺度調整規則包括將圖像的短邊調整到第一預設值,并將調整所述圖像的長邊調整到第二預設值,使得調整后的圖像的短邊和長邊的比與所述圖像的短邊和長邊的比不變。圖像的短邊和長邊的比是有益的,圖像的短邊和長邊的比不變,可以保存圖像的重要信息,如圖像的空間信息。在本實施例中,將獲取到的待識別圖像的短邊調整到第一預設值,并將調整所述獲取到的待識別圖像的長邊調整到第二預設值,使得調整后的待識別圖像的短邊和長邊的比與所述獲取到的待識別圖像的短邊和長邊的比不變,以獲得調整后的待識別圖像。
例如,所述第一預設值s可以為448,所述獲取到的待識別圖像的大小為722×542,即所述待識別圖像的短邊為542,長邊為722,可以將圖像的短邊542調整到第一預設值448;為了保持圖像的短邊和長邊的比,則第二預設值為722÷(542÷448)=597,并將調整所述獲取到的待識別圖像的長邊722調整到第二預設值597,使得調整后的待識別圖像的短邊和長邊的比與所述獲取到的待識別圖像的短邊和長邊的比不變,以獲得調整后的待識別圖像,大小為597×448。
子步驟s202:對所述調整后的待識別圖像進行歸一化,獲得歸一化后的待識別圖像。
為了標準化圖像的光照,基于子步驟s202,通過減去在單個圖像上計算出的通道平均強度值(表示為per-img-mean)來對每個皮膚圖像進行歸一化。具體地,給定一張圖像t,計算歸一化后的圖像tnorm:
公式(1)中,u(tr)為紅色通道的平均像素值,u(tg)為綠色通道的平均像素值,u(tg)為藍色通道的平均像素值。在本實施例中,根據公式(1)對所述調整后的待識別圖像進行歸一化,獲得歸一化后的待識別圖像。
子步驟s203:基于預設的圖像增強規則及所述歸一化后的待識別圖像,獲得多個增強后的待識別圖像。
進一步地,為了更進一步地提高本發明實施例提供的圖像的識別方法的高效性,可以進行圖像增強。所述預設的圖像增強規則包括將所述歸一化后的圖像旋轉預設角度后,根據預設的像素偏移范圍,在旋轉后的圖像上添加像素平移操作,獲得增強后的圖像;根據不同的預設角度,重復上述步驟,獲得多個增強后的圖像。所述預設角度可以0-360度內的任意值,例如可以為0度、90度、180度或270度,所述預設的像素偏移范圍為-10和10像素之間。
例如,將所述歸一化后的待識別圖像旋轉0度后,根據預設的像素偏移范圍,在旋轉后的待識別圖像上添加像素平移-9像素操作,獲得第一個增強后的待識別圖像;根據不同的預設角度,重復上述步驟,將所述歸一化后的待識別圖像旋轉90度后,根據預設的像素偏移范圍,在旋轉后的待識別圖像上添加像素平移-5像素操作,獲得第二個增強后的待識別圖像;將所述歸一化后的待識別圖像旋轉180度后,根據預設的像素偏移范圍,在旋轉后的待識別圖像上添加像素平移9像素操作,獲得第三個增強后的待識別圖像;將所述歸一化后的待識別圖像旋轉270度后,根據預設的像素偏移范圍,在旋轉后的待識別圖像上添加像素平移5像素操作,獲得第四個增強后的待識別圖像,以此獲得四個增強后的待識別圖像。
步驟s210:根據預設的深度殘差神經網絡對所述圖像增強后的待識別圖像進行特征提取,獲得特征信息。
基于步驟s210,具體地,將所述多個增強后的待識別圖像以前向傳播的方式通過所述預設的深度殘差神經網絡后,分別提取在所述預設的深度殘差神經網絡中各自第l卷積層的深層特征信息,再將所述各自第l卷積層的深層特征信息進行整合,以獲得所述多個增強后的待識別圖像對應的深層特征信息。
在本實施例中,基于步驟s200,根據獲取到的待識別圖像,記為t,獲得了四個增強后的待識別圖像,分別記為t1,t2,t3,t4,每個增強后的待識別圖像的大小可以為448×597或597×448;再將四個增強后的待識別圖像即為t1,t2,t3,t4以前向傳播的方式通過所述預設的深度殘差神經網絡后,在所述深度殘差神經網絡的第l卷積層中,獲得
分別提取在所述預設的深度殘差神經網絡中各自第l卷積層的深層特征信息,再將所述各自第l卷積層的深層特征信息進行整合,根據表達式(2),得到一組深層特征信息fl:
表達式(3),獲得所述多個增強后的待識別圖像對應的深層特征信息fl。
步驟s220:對所述特征信息進行fisher向量編碼,獲得fisher特征向量。
進一步地,從層中提取的每個局部深層卷積特征是指輸入圖像中的一個小區域,并反映該區域的局部不同。這類似于傳統的局部描述符(sift)。由于每個圖像包含一組深層特征信息,使用fisher向量(fishervector,fv)編碼方法將這些局部深層表示聚合為單個圖像表達(fv表達),這可以被認為是bof模型的變體。從fisher核導出的fv編碼對于編碼局部特征是有效的,并且在圖像識別中表現出優異的性能。
進行fisher向量編碼,需要指定深層特征信息fl的概率分布f(如p(f│λ))(生成模型)。為了實現這一點,采用流行的高斯混合模型(gmm),它可以很好地近似任意連續分布函數,可對深度特征的概率分布進行建模(生成過程)。gmm是概率密度函數的參數估計模型,被視為“概率視覺單詞詞匯表”。
基于預先建立的gmm模型,對于所述多個增強后的待識別圖像對深層特征信息fl,gmm聚類的第一和第二差分為:
其中,
作為一種實施方式,在進行fisher向量編碼之前,需要后的更多的高斯向量來獲得高維深度特征信息的分布,通過主成分分析(pca)來降低深度特征信息的維度,進而降低fisher特征向量的維度。
作為另一種實施方式,對于所述fisher特征向量通過l2范數和功率歸一化處理,獲得改進的fisher特征向量,進行下一步的計算。
步驟s230:根據預設的分類器及所述特征向量對所述待識別圖像進行識別,獲得識別結果。
所述預設的分類器為預設的基于卡方核的svm分類器。將所述fisher特征向量通過所述預設的基于卡方核的svm分類器,獲得分類結果,根據分類結果獲得識別結果。在本實施例中,所述待識別的圖像可以為但不限于皮膚圖像。所述待識別的圖像還可以為風景圖像、人物圖像、動物圖像等任意類型的圖像。
例如,黑色素瘤與非黑色素瘤(良性)之間的類內和類間差異較大,由于黑色素瘤比非黑色素瘤皮膚癌更致命,癌癥與非癌性黑色素瘤皮膚鏡檢查圖像之間的區別已經引起了極大關注。優選地,所述皮膚圖像可以為黑色素瘤皮膚圖像,根據分類結果,識別出該皮膚圖像為黑色素瘤或非黑色素瘤(良性)。根據識別結果選擇診斷,早期診斷對于治療這種疾病非常重要,因為它可以在早期階段很容易治愈。
此外,在步驟s210之前,所述方法還可以包括:建立預設的深度殘差神經網絡。
一方面,深度殘差神經網絡的主要特點在于引入殘差連接,能夠在訓練非常深的網絡時解決降級問題。已經證明,殘差連接可以加速深度網絡的收斂,提高網絡深度,來保持準確率的增加。一般來說,深度殘差網絡由一組殘差塊組成,每個塊由幾個堆疊的卷積層組成(將修正線性單元(relu)層和批量歸一化層作為卷積層附屬)。具有恒等映射的殘差塊可以表示為:
hl+1=relu(hl+f(hl,wl))(7)
公式(7)中,hl、hl+1分別為第l個殘差塊的輸入和輸出;relu為修正線性單元函數,relu(x)=max(0,x),relu是一個簡單的激活函數,大于0就輸出原始值否則輸出0;f為殘差映射函數,殘差單元每個層都是一個轉換函數,卷積層conv就是矩陣相乘,批處理層batchnorm是對輸入進行均值方差的轉換,wl為塊的參數。具體地,當f(hl,wl)的通道(尺寸)和hl不相等時,輸出是3維張量,尺寸表示第一、第二維度,通道數表示第三維度,通常應用線性投影φ來匹配尺寸,因此,公式(7)可以進一步轉換為:
hl+1=relu(φ(hl)+f(hl,wl))(8)
在本實施例中,利用了兩個具有不同深度的resnet模型(resnet-50和resnet-101),并且殘差網絡都在imagenet上進行了預先訓練。結構的詳細信息如表1所示,為了簡單起見,殘差塊表示為resblock,卷積層被表示為conv。可以以2016年國際燒傷協會大會挑戰賽皮膚病變的皮膚圖像數據集的圖像為訓練數據,建立深度殘差神經網絡模型,得到訓練之后的模型即預設的深度殘差神經網絡。
表1為resnet模型(resnet-50和resnet-101)的詳細信息
再一方面,在步驟s220之前,所述方法還包括建立gmm模型、建立基于卡方核的svm分類器。
建立gmm模型,獲取到2016年國際燒傷協會大會挑戰賽皮膚病變的大量皮膚圖像數據集,設總共有a張皮膚圖像,對每一張皮膚圖像,執行步驟s200-步驟s210,類似內容,這里不再贅述,獲得所述a張皮膚圖像各自對應的一組深層特征信息fil:
表達式(9)中,fil為第i張皮膚圖像在第l卷積層對應的一組深層特征信息。
從卷積層中提取的每個深層特征信息是指輸入圖像中的一個小區域,并反映該區域的局部不同。這類似于傳統的局部描述符(sift)。由于每個圖像包含一組深度特征,使用fv編碼方法將這些局部深層表示聚合為單個圖像表達(fv表達),這可以被認為是bof模型的變體。從fisher核導出的fv編碼對于編碼局部特征是有效的,并且在圖像識別中表現出優異的性能。
進行fisher向量編碼,需要指定深層特征信息fl的概率分布f(如p(f│λ))(生成模型)。為了實現這一點,采用流行的高斯混合模型(gmm),它可以很好地近似任意連續分布函數,可對深度特征的概率分布進行建模(生成過程)。gmm是概率密度函數的參數估計模型,被視為“概率視覺單詞詞匯表”。假設gmm在
公式(10)中,λ={πk,μk,σk,k=1,2…k}表示gmm模型的參數。gmm模型中,每個高斯分量表示一個視覺單詞(聚類),包括先驗概率
獲取gmm模型,將公式(10)、(11)、(12)帶入相應地公式(4)和公式(5),對所述特征信息
進一步地,建立基于卡方核的svm分類器即支持向量機(supportvectormachine,svm)分類器。雖然線性核對于分類是有效的,但非線性核傾向于產生更好的性能,卡方核應用于圖像分類有著優越性。基于訓練集中獲取的fisher特征向量,卡方核的svm分類器的決策函數為:
公式(13)中,κ<xi,x>表示第i個訓練特征向量xi和測試特征向量x的卡方核函數,d(xi,x)為相應地卡方平均聚類;yi∈{-1,+1}表示類別標簽;αi和b是學習參數;t表示訓練樣本的數量;γ為內核的均勻度,可以設置為1。訓練集中獲取的fisher特征向量可以經過l2歸一化。在目標函數中采用了標準hinge損失,并且優化問題可以最大化為公式(14):
公式(14)中,參數c用于減少損失,為常數。在svm訓練過程中,由于隨機雙坐標上升算法(sdca求解器)效率高,收斂速度快,因而采用它來最小化正則化損失。以此獲得訓練后的卡方核的svm分類器,以便作為預設的分類器供分類。
本發明實施例提供了一種圖像的識別方法,對獲取到的待識別圖像進行圖像增強,獲得圖像增強后的待識別圖像;再根據預設的深度殘差神經網絡對所述圖像增強后的待識別圖像進行特征提取,獲得特征信息;對所述特征信息進行fisher向量編碼,獲得fisher特征向量;然后根據預設的分類器及所述特征向量對所述待識別圖像進行識別,獲得識別結果,以此實現利用深度殘差神經網絡和fisher向量編碼,對待識別的圖像提取更多的判別特征,再進行分類處理,根據分類結果快速識別出所述待識別的圖像,操作簡單,更高效、更準確,適用性強。
第二實施例
請參閱圖4,本發明實施例提供了一種圖像的識別裝置300,所述裝置300包括:圖像增強單元310、特征提取單元320、編碼單元330和識別單元340。
圖像增強單元310,用于對獲取到的待識別圖像進行圖像增強,獲得圖像增強后的待識別圖像。
作為一種實施方式,所述圖像增強單元310可以包括調整子單元311、歸一化子單元313和圖像增強子單元314。
調整子單元311,用于基于預設的尺度調整規則及獲取到的待識別圖像,獲得調整后的待識別圖像。
作為一種實施方式,調整子單元311可以包括邊調整子單元312。
邊調整子單元312,用于將獲取到的待識別圖像的短邊調整到第一預設值,并將調整所述獲取到的待識別圖像的長邊調整到第二預設值,使得調整后的待識別圖像的短邊和長邊的比與所述獲取到的待識別圖像的短邊和長邊的比不變,以獲得調整后的待識別圖像。
歸一化子單元313,用于對所述調整后的待識別圖像進行歸一化,獲得歸一化后的待識別圖像。
圖像增強子單元314,用于基于預設的圖像增強規則及所述歸一化后的待識別圖像,獲得多個增強后的待識別圖像。
作為一種實施方式,圖像增強子單元314可以包括旋轉子單元315。
旋轉子單元315,用于將所述歸一化后的待識別圖像旋轉預設角度后,根據預設的像素偏移范圍,在旋轉后的待識別圖像上添加像素平移操作,獲得增強后的待識別圖像;根據不同的預設角度,重復上述步驟,獲得多個增強后的待識別圖像。
特征提取單元320,用于根據預設的深度殘差神經網絡對所述圖像增強后的待識別圖像進行特征提取,獲得特征信息。
作為一種方式,特征提取單元320可以包括特征提取子單元321。
特征提取子單元321,用于將所述多個增強后的待識別圖像以前向傳播的方式通過所述預設的深度殘差神經網絡后,分別提取在所述預設的深度殘差神經網絡中各自第l卷積層的深層特征信息,再將所述各自第l卷積層的深層特征信息進行整合,以獲得所述多個增強后的待識別圖像對應的深層特征信息。
編碼單元330,用于對所述特征信息進行fisher向量編碼,獲得fisher特征向量。
識別單元340,用于根據預設的分類器及所述特征向量對所述待識別圖像進行識別,獲得識別結果。
需要說明的是,本實施例中的各單元可以是由軟件代碼實現,此時,上述的各單元可存儲于存儲器110內。以上各單元同樣可以由硬件例如集成電路芯片實現。
本發明實施例提供的圖像的識別裝置300,其實現原理及產生的技術效果和前述方法實施例相同,為簡要描述,裝置實施例部分未提及之處,可參考前述方法實施例中相應內容。
在本申請所提供的幾個實施例中,應該理解到,所揭露的裝置和方法,也可以通過其它的方式實現。以上所描述的裝置實施例僅僅是示意性的,例如,附圖中的流程圖和框圖顯示了根據本發明的多個實施例的裝置、方法和計算機程序產品的可能實現的體系架構、功能和操作。在這點上,流程圖或框圖中的每個方框可以代表一個模塊、程序段或代碼的一部分,所述模塊、程序段或代碼的一部分包含一個或多個用于實現規定的邏輯功能的可執行指令。也應當注意,在有些作為替換的實現方式中,方框中所標注的功能也可以以不同于附圖中所標注的順序發生。例如,兩個連續的方框實際上可以基本并行地執行,它們有時也可以按相反的順序執行,這依所涉及的功能而定。也要注意的是,框圖和/或流程圖中的每個方框、以及框圖和/或流程圖中的方框的組合,可以用執行規定的功能或動作的專用的基于硬件的系統來實現,或者可以用專用硬件與計算機指令的組合來實現。
另外,在本發明各個實施例中的各功能模塊可以集成在一起形成一個獨立的部分,也可以是各個模塊單獨存在,也可以兩個或兩個以上模塊集成形成一個獨立的部分。
所述功能如果以軟件功能模塊的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:u盤、移動硬盤、只讀存儲器(rom,read-onlymemory)、隨機存取存儲器(ram,randomaccessmemory)、磁碟或者光盤等各種可以存儲程序代碼的介質。需要說明的是,在本文中,諸如第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
以上所述僅為本發明的優選實施例而已,并不用于限制本發明,對于本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。應注意到:相似的標號和字母在下面的附圖中表示類似項,因此,一旦某一項在一個附圖中被定義,則在隨后的附圖中不需要對其進行進一步定義和解釋。
以上所述,僅為本發明的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉本技術領域的技術人員在本發明揭露的技術范圍內,可輕易想到變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應所述以權利要求的保護范圍為準。
需要說明的是,在本文中,諸如第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
- 還沒有人留言評論。精彩留言會獲得點贊!