一種基于DBSCAN的風電機組運行狀態識別方法與流程
本發明屬于風力發電技術領域,涉及風電機組運行狀態識別方法,特別涉及一種基于dbscan的風電機組運行狀態識別方法。
背景技術:
風電機組運行環境復雜、運行工況多樣,從大量、多維、復雜的風電場運行歷史數據中識別正常運行數據、限功率運行數據、故障停機數據和其他異常原因造成的欠功率運行數據,對風電機組理論發電量的計算、故障診斷、風電功率預測的準確性等具有重要意義。現有的風電機組運行狀態識別方法,主要集中在對風電機組棄風數據的識別上,包括利用粘滯區間法剔除棄風數據、四分位和k-means聚類算法結合的棄風數據識別方法等。但此類方法在識別過程中人為設定數據區間,忽略了數據本身的分布特征,識別結果受到人為設定區間的影響,無法根據機組出力情況對實際的運行狀態進行區分,風電機組運行數據分類單一化、運行狀態識別不準確。
技術實現要素:
本發明的目的是解決現有技術中對風電機組運行數據分類單一化、運行狀態識別不準確的問題。提出一種基于dbscan的風電機組運行狀態識別方法,根據機組運行數據自身特征,對機組運行狀態識別分類。有利于提高風電機組功率預測、風電機組功率曲線建模、理論發電量計算、機組電量損失評估的準確性,并且為風電機組故障診斷提供數據支持。
本發明的技術方案是:一種基于dbscan的風電機組運行狀態識別方法,包括以下步驟:
步驟1:采集風電機組運行數據和風電機組的基本參數。
其中運行數據包括風速、功率、槳距角;基本參數包括風電機組的切入風速、額定風速、額定功率等。
步驟2:機組運行數據歸一化處理。
其中
式中x*——歸一化處理后的數據;
x——原始數據;
max——待處理數據的最大值;
min——待處理數據的最小值。
其中,針對風速、功率、槳距角的最大最小值設定見表1。
表1歸一化參數選擇
步驟3:根據風速、功率數據,篩選運行數據中的停機數據。
若風速v和功率p滿足:vin<v<vout且p=0時,將其判定為停機數據。
步驟4:將歸一化處理得到的風速、功率、槳距角數據(除已確定為停機的數據)作為dbscan模型的輸入數據,并對dbscan聚類的模型參數進行優化。dbscan聚類算法使用eps鄰域半徑和minpts來控制簇的生成,直接影響聚類效果。通過調整eps和minpts鄰域包含的最小數目,識別原始數據集中的內在特征與類別。
步驟5:根據步驟3和步驟4的數據分類結果,得到風電機組的運行狀態識別結果。
根據數據的分布特征,識別得到不同狀態下的運行數據。可將其分為正常運行數據、限功率運行數據、停機數據、其他非正常運行數據等。
其中采用dbscan聚類模型得到的分組中,限功率運行數據會受到實際中限功率程度不同分為幾類,可將其歸為一類作為限功率運行數據。
發明的效果
本發明采用了基于密度的聚類模型(dbscan)對風電機組運行狀態進行識別,dbscan模型根據輸入數據的分布特征將機組不同運行狀態下的數據進行分類,得到正常運行狀態、限功率運行狀態、停機狀態、其他非正常運行狀態下的數據集。該方法可將風電機組不同運行狀態下數據(正常運行數據、限功率數據、停機數據、非正常運行數據等)進行區分,有利于準確篩選風電機組功率預測的訓練樣本,有利于提高風電機組功率曲線建模、機組電量損失評估的準確性,并且該方法得到的非正常運行狀態數據有利于風電機組健康管理和故障診斷。
附圖說明
圖1為本發明基于dbscan的風電機組運行狀態識別方法的流程圖。
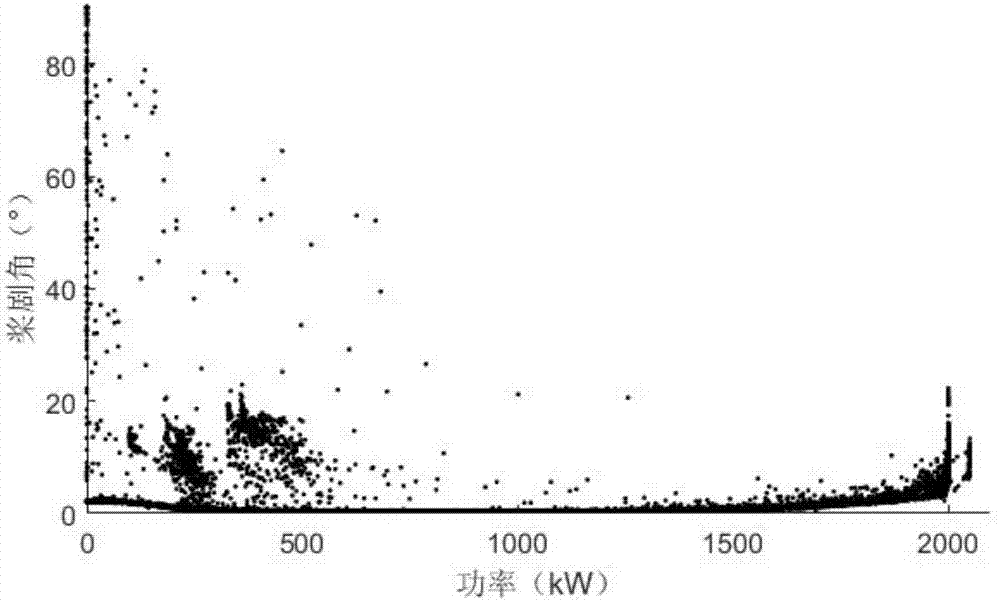
圖2為本發明具體實施例的原始數據功率-槳距角散點圖。
圖3為本發明具體實施例中識別得到的正常運行狀態下風速-功率散點圖。
圖4為本發明具體實施例中的功率-槳距角數據聚類結果。
圖5為本發明具體實施例的風速-功率數據聚類結果。
具體實施方式
以北方地區某風電場為例,全場共有24臺2mw機組,棄風現象較為嚴重。任意選擇其中一臺風電機組,提取2013年3月15日到2013年5月26日的運行數據進行算例分析。
步驟1:采集風電機組運行數據和風電機組的基本參數。
其中運行數據包括風速、功率、槳距角;風電機組的切入風速為3.5m/s、額定風速為12m/s、額定功率為2mw。
步驟2:機組運行數據歸一化處理。
數據主要包括scada系統采集的風速、功率、槳距角等信息,數據間隔為10分鐘。
其中
式中x*——歸一化處理后的數據;
x——原始數據;
max——待處理數據的最大值;
min——待處理數據的最小值。
其中,針對風速、功率、槳距角的最大最小值設定見表2。
表2歸一化參數選擇
步驟3:根據風速、功率數據篩選運行數據中的停機數據。
若風速v和功率p滿足:3.5m/s<v<25m/s且p=0時,將其判定為停機數據。
步驟4:將歸一化得到的風速、功率、槳距角數據(除已確定為停機的數據)作為dbscan模型的輸入數據,并對dbscan聚類的模型參數進行優化。
(1)確定eps鄰域半徑。
首先根據數據的實際分布情況、數據量進行調試選擇。若eps過小,將導致模型效率低,聚類結果過于分散,可能將大量正常運行數據分類為多個數據量較小的簇,而本應該同屬于一類的數據被誤識別為異常數據;若eps過大,則對異常數據的識別能力降低。注意:當eps取值小于0.01時,需要綜合考慮歸一化后數據的分辨率,如:數據的間隔距離等;選定的eps應能保證模型在效率和準確性方面得到較好的平衡。
(2)確定minpts數值。
minpts取值過大會導致核心點數量減少,使包含對象數量較少的自然簇被丟棄;若minpts過小則無法起到識別“噪點”的目的。
采用遍歷平面網格結點處eps和minpts數據的組合(根據數據量及分布情況,eps取值為0-0.1;minpts取值為1-10),統計正常運行數據簇的數據量k和分類個數m,通過觀察k和m值對minpts的敏感性,確定參數eps和minpts數值的可選范圍,并進一步將該區域網格細化,最終選擇到最合適的eps-minpts數值的組合。
步驟5:根據步驟3和步驟4的數據分類結果,得到風電機組不同運行狀態下的數據分組。
圖2為該時間段內功率-槳距角分布圖,由圖可以看出,原始數據中槳距角大部分都分布5°以下;但在此槳距角范圍之外,功率值呈現出兩個分布范圍(分別是功率值在300kw附近和500kw附近),此時槳距角數據多分布在0-20°的范圍內。在功率值達到額定功率附近時,圖中出現了功率值為2000kw和2100kw兩個數據帶,該情況可能是由于控制策略的不同造成輸出功率的差異。
采用dbscan聚類算法對功率-槳距角進行聚類分析,圖3為該方法識別出的核心點數據在風速-功率圖中的表示,圖4為聚類分析結果。圖4中顯示功率-槳距角數據集明顯被劃分為了五個主要部分:正常運行數據、三個不同程度的限功率數據、故障停機數據。圖5為該聚類結果在風速-功率散點圖中的展示。圖中所示,大部分數據都集中于功率曲線附近(黑色),識別為正常運行工況;限功率數據主要分為三個部分,在風速-功率散點圖中均呈橫向排布(紫色、綠色、淺藍色),本算例中限電主要將機組出力限定在100kw-500kw區域。
此外,圖5中還有部分由于故障停機導致出力為零的數據落在橫坐標上,利用故障時間來幫助區分工況類型,并評判機組的可靠性。除了識別出的主要運行工況外,dbscan將散落無規則分布的數據當做噪點識別出來。通過分析可知,該部分數據是由于控制不穩定或其他異常原因造成的。
對算例中數據集分類結果進行統計,該風電機組在所選時段的數據分類結果如表3所示。77.4%的時間機組處于“正常運行工況”,機組的出力水平達到理論值,輸出功率的情況體現了風電機組運行中能達到理論功率水平;2.22%處于“主動限電運行工況”,此時功率值被限定在某一水平,當風速增大時,通過控制槳距角使輸出功率維持在設定值附近;17.07%的時間風電機組處于“故障停機工況”,該風電機組在所選時間段內故障頻率較高,實際工作中對該機組運維效率有待提高;除此之外,由于槳距角控制不穩定、偏航等“性能異常工況”造成功率損失的時間達到3.31%。
表3聚類結果匯總
上述實施例對本發明的技術方案進行了詳細說明。顯然,本發明并不局限于所描述的實施例。基于本發明中的實施例,熟悉本技術領域的人員還可據此做出多種變化,但任何與本發明等同或相類似的變化都屬于本發明保護的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!