一種基于多核CPU的分布式集群系統及數據連接方法與流程
本發明涉及計算機技術領域,尤其涉及一種基于多核cpu的分布式集群系統及數據連接方法。
背景技術:
互聯網技術和相關應用的飛速發展帶來了數據的爆炸式增長,數據庫規模從千比特(kb)、兆比特(mb)級飛躍到吉比特(gb)、太比特(tb)級甚至到皆比特(eb)、佑比特(zb)級,海量的數據給數據分析相關工作帶來了巨大的挑戰,其中連接查詢又是大規模數據分析中最重要和最基本操作之一,其性能直接關系到數據庫的查詢效率。
現有技術中提出了一種將哈希連接應用于大規模集群計算的方法,該方法利用mpi(message-passing-interface消息傳遞接口)和rdma(remotedirectmemoryaccess,遠程直接數據存取)技術,在超大規模計算機集群上進行哈希連接操作,使得數據可以直接通過網絡進行傳遞而不對操作系統造成任何影響,消除了外部存儲器復制和文本交換操作。這種算法使得哈希連接在計算機集群系統上得以更高效地應用,大大提高了計算機處理海量數據的能力。
然而,這種方法提高了集群系統整體的并行處理能力,重點在于利用rdma技術降低了計算機間的數據交流代價,而沒有挖掘單個處理節點的并行處理能力。但隨著多核cpu的普及和并行處理技術的成熟,單機系統的并行處理能力已不容小視,單個處理節點的性能提升也將對整個集群系統的提升有著巨大的推動作用。
技術實現要素:
本發明要解決的技術問題是,針對現有大規模集群數據處理方法沒有挖掘單個處理節點的并行處理能力的缺陷,提供一種基于多核cpu的分布式集群系統及數據連接方法,將映射規約模型應用于多核cpu上,將單機的多線程并行連接算法與已有的分布式集群系統上的并行運算模型相結合,提高分布式集群系統的計算能力。
本發明第一方面,提供了一種基于多核cpu的分布式集群系統,包括:
映射服務器,包括至少一臺具有多核cpu的計算機,用于在映射任務的進程內部啟動n個映射線程,并以所述映射服務器中每個核心作為一個對應計算節點對所述n個映射線程進行并行計算;其中每個映射線程從共享內存預先分配的緩沖區中讀取對應的數據分片vi,1≤i≤n,記錄源表的連接屬性和查詢屬性,生成鍵值對,并對所述連接屬性建立各自的哈希表;
規約服務器,包括至少一臺具有多核cpu的計算機,用于在規約任務的進程內部啟動m個規約線程,并以所述規約服務器中每個核心作為一個對應計算節點對所述m個規約線程進行并行計算;其中每個規約線程用于查找所述哈希表,從多個哈希表中分別獲取屬于自己的中間數據集,并對所述中間數據集進行比較連接。
在根據本發明所述的基于多核cpu的分布式集群系統中,所述映射服務器預先將輸入數據分成n等份,并分別存儲至n個緩沖區,使每個映射線程對應一個緩沖區。
在根據本發明所述的基于多核cpu的分布式集群系統中,所述分布式集群系統內計算機之間的數據遷移采用遠程直接數據存取方式,并采用消息傳遞接口進行編程實現通信。
在根據本發明所述的基于多核cpu的分布式集群系統中,所述映射服務器還用于對映射服務器的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對映射線程進行并行處理。
在根據本發明所述的基于多核cpu的分布式集群系統中,所述規約服務器還用于對規約服務器的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對規約線程進行并行處理。
本發明第二方面,提供了一種基于多核cpu的分布式集群系統的數據連接方法,所述基于多核cpu的分布式集群系統包括映射服務器和規約服務器,且所述映射服務器包括至少一臺具有多核cpu的計算機,所述規約服務器包括至少一臺具有多核cpu的計算機,所述數據連接方法包括:
映射步驟,在映射任務的進程內部啟動n個映射線程,并以所述映射服務器中每個核心作為一個對應計算節點對所述n個映射線程進行并行計算;其中每個映射線程從共享內存預先分配的緩沖區中讀取對應的數據分片vi,1≤i≤n,記錄源表的連接屬性和查詢屬性,生成鍵值對,并對所述連接屬性建立各自的哈希表;
規約步驟,在規約任務的進程內部啟動m個規約線程,并以規約服務器中每個核心作為一個對應計算節點對所述m個規約線程進行并行計算;其中每個規約線程用于查找所述哈希表,從多個哈希表中分別獲取屬于自己的中間數據集,并對所述中間數據集進行比較連接。
在根據本發明所述的基于多核cpu的分布式集群系統的數據連接方法中,所述映射步驟還包括:預先將輸入數據分成n等份,并分別存儲至n個緩沖區,使每個映射線程對應一個緩沖區。
在根據本發明所述的基于多核cpu的分布式集群系統的數據連接方法中,所述分布式集群系統內計算機之間的數據遷移采用遠程直接數據存取方式,并采用消息傳遞接口進行編程實現通信。
在根據本發明所述的基于多核cpu的分布式集群系統的數據連接方法中,所述映射步驟還包括對映射服務器的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對映射線程進行并行處理。
在根據本發明所述的基于多核cpu的分布式集群系統的數據連接方法中,所述規約步驟還包括對規約服務器的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對規約線程進行并行處理。
實施本發明的基于多核cpu的分布式集群系統系統及數據連接方法,具有以下有益效果:本發明將單機的多線程并行連接算法與分布式集群系統上的并行運算模型相結合,使得多核計算機更能有效利用其硬件資源,最大限度地挖掘集群系統的運算潛能,發揮出更多的性能優勢;進一步地,本發明在單機系統上應用多線程并行操作時,為了避免共用內存產生的操作競爭,采用了預先劃分數據片,每個線程獨占一個緩存區的方式來避免線程間產生競爭,這種方式較之于傳統的加鎖方式,減小了開銷。
附圖說明
圖1為根據本發明優選實施例的基于多核cpu的分布式集群系統的結構圖;
圖2為根據本發明優選實施例的基于多核cpu的分布式集群系統的數據連接方法示意圖。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明的一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動的前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
哈希連接(hashjoin)是連接操作中廣泛使用的一種簡單高效的算法,在映射規約(mapreduce)計算框架中一個完整的hashjoin包括映射(map)、混洗(shuffle)和規約(reduce)三個階段。本發明在多核cpu中,可采用多線程的方式完成每一個階段,提高了cpu的利用率。混洗(shuffle)用于將數據從映射端輸出到規約端。
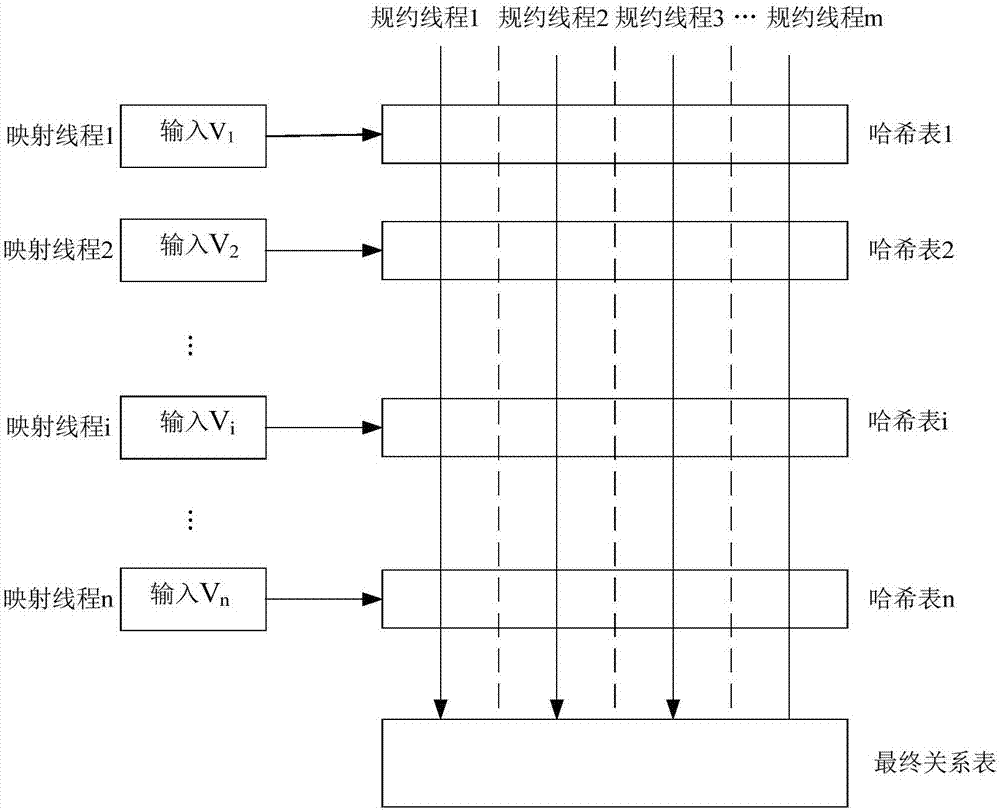
請參閱圖1,為根據本發明優選實施例的基于多核cpu的分布式集群系統的結構圖。如圖1所示,該實施例提供的基于多核cpu的分布式集群系統包括:映射服務器100和規約服務器200。下面結合參閱圖2對本發明的系統進行詳細描述,該圖2為根據本發明優選實施例的基于多核cpu的分布式集群系統的數據連接方法示意圖。
映射服務器100包括至少一臺具有多核cpu的計算機。映射服務器100用于在映射任務的進程內部啟動n個映射線程,如圖2中映射線程1至映射線程n,并以映射服務器100中每個核心作為一個對應計算節點對這n個映射線程進行并行計算。其中每個映射線程從共享內存預先分配的緩沖區中讀取對應的數據分片,例如映射線程i從預先分配的緩沖區中讀取對應的數據分片vi,1≤i≤n,n為映射線程的總數。映射線程在讀取各自的數據分片后記錄源表的連接屬性和查詢屬性,生成鍵值對,并對連接屬性建立各自的哈希表。如圖2中映射線程1至映射線程n分別獨立建立了哈希表1至哈希表n。也就是說,在多線程連接操作過程中,映射任務(maptask)在其進程內部啟動n個線程,又稱為規約線程,通過這n個規約線程并行地進行連接操作來實現映射(map)端連接操作的多線程化。即在映射(map)階段中,每個線程維護一個獨立的哈希表,并行地從任務隊列中取出任務,對元組在連接屬性上做哈希運算,并存入到對應的哈希桶中。
由于所有線程共享同一內存,因此在讀取數據時存在嚴重的競爭。為了避免競爭,本發明在映射操作前首先對數據進行預處理:假設共有n個映射線程同時工作,則將輸入數據分成n等份,并維護n個緩沖區,每個映射線程獨占一個緩沖區。這是一種空間換時間的策略,既避免了多個線程間的讀沖突,而且較之于傳統的加鎖操作節省了同步開銷。
規約服務器200包括至少一臺具有多核cpu的計算機。該規約服務器200與映射服務器100連接,使得映射服務器100產生哈希表的數據可通過例如混洗(shuffle)操作傳輸到規約服務器200。用于在規約任務的進程內部啟動m個規約線程,如圖2中規約線程1至規約線程n,并以規約服務器中每個核心作為一個對應計算節點對這m個規約線程進行并行計算。其中每個規約線程用于查找映射服務器100建立的所有哈希表,如哈希表1至哈希表n,從所有哈希表中分別獲取屬于自己的中間數據集,并對該中間數據集進行比較連接。多個規約線程在運行完成后得到最終關系表。也就是說,在規約(reduce)階段,每個規約任務(reducetasek)從存儲著多個哈希表的中間緩沖區中分別拉取屬于自己的中間數據集,對中間數據集進行排序、連接等規約操作。
因此,本發明在整個數據連接過程中,映射服務器100和規約服務器200的每個核心都被當作一個對應計算節點進行并行計算,并且多個線程共享同一內存,降低了數據間的通信代價。
在本發明中,分布式集群系統內各個計算機之間的數據遷移可以采用遠程直接數據存取(rdma,remotedirectmemoryaccess)方式,并采用消息傳遞接口(mpi,message-passing-interface)進行編程實現通信。使得數據可以直接通過網絡進行傳遞而不對操作系統造成任何影響,消除了外部存儲器復制和文本交換操作,加快了集群系統的運算速度。
在本發明更優選的實施例中,映射服務器100還可以對映射服務器100的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對映射線程進行并行處理。例如發現有新任務到達時,首先判斷是否當前集群是否有空閑cpu核可以利用,如果沒有,則回到線程繼續等待;如果有可以利用的空閑核資源,則將新任務加上任務名后連同數據一起打包到計算節點請求計算,更新平臺總空閑資源cpu核數為當前集群中空閑資源cpu核數減去該任務占用核數。同樣地,規約服務器200也可以對規約服務器200的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對規約線程進行并行處理。
本發明還提供了一種基于多核cpu的分布式集群系統的數據連接方法,其中基于多核cpu的分布式集群系統如前所述,包括映射服務器100和規約服務器200,且映射服務器100包括至少一臺具有多核cpu的計算機,規約服務器200包括至少一臺具有多核cpu的計算機。該基于多核cpu的分布式集群系統的數據連接方法包括:
(1)映射步驟:由映射服務器100在映射任務的進程內部啟動n個映射線程,并以映射服務器100中每個核心作為一個對應計算節點對所述n個映射線程進行并行計算;其中每個映射線程從共享內存預先分配的緩沖區中讀取對應的數據分片vi,1≤i≤n,記錄源表的連接屬性和查詢屬性,生成鍵值對,并對所述連接屬性建立各自的哈希表。優選地,該映射步驟還包括:預先將輸入數據分成n等份,并分別存儲至n個緩沖區,使每個映射線程對應一個緩沖區。
(2)規約步驟:由規約服務器200在規約任務的進程內部啟動m個規約線程,并以規約服務器200中每個核心作為一個對應計算節點對所述m個規約線程進行并行計算;其中每個規約線程用于查找所述哈希表,從多個哈希表中分別獲取屬于自己的中間數據集,并對中間數據集進行比較連接。
在本發明更優選的實施例中,映射步驟中還可以對映射服務器100的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對映射線程進行并行處理。同樣地,規約步驟中也可以對規約服務器200的集群中空閑資源cpu核數進行采集統計,并實時更新空閑資源cpu核數,對規約線程進行并行處理。并且分布式集群系統內計算機之間的數據遷移采用遠程直接數據存取方式,并采用消息傳遞接口進行編程實現通信。
綜上所述,本發明將單機的多線程并行連接算法與分布式集群系統上的并行運算模型相結合,使得多核計算機更能有效利用其硬件資源,最大限度地挖掘集群系統的運算潛能,發揮出更多的性能優勢。對于每一臺計算機,將cpu上的每個核心或者硬件線程都當作一個對應計算節點,在映射規約(mapreduce)框架下進行多線程并行計算充分利用了每臺計算機的儲存能力和多核cpu的并行處理能力,提高了對每個計算節點的利用率;對于整個集群系統,采用mpi和rdma技術進行通信,消除外部存儲器的存儲、復制和交換操作。二者結合,大大提高了整個集群系統的運算能力。進一步地,本發明在單機系統上應用多線程并行操作時,為了避免共用內存產生的操作競爭,采用了預先劃分數據片,每個線程獨占一個緩存區的方式來避免線程間產生競爭,這種方式較之于傳統的加鎖方式,減小了開銷。
應該理解地是,本發明的基于多核cpu的分布式集群系統以及其數據連接方法的實現原理與過程相同,因此對基于多核cpu的分布式集群系統的實施例的具體描述也適用于基于多核cpu的分布式集群系統的數據連接方法。
最后應說明的是:以上實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的精神和范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!