一種電視智能檢測用戶睡眠狀態的系統及方法與流程
本發明屬于計算機視覺、智能家居
技術領域:
,具體涉及一種基于計算機視覺的睡眠狀態估計系統及方法。
背景技術:
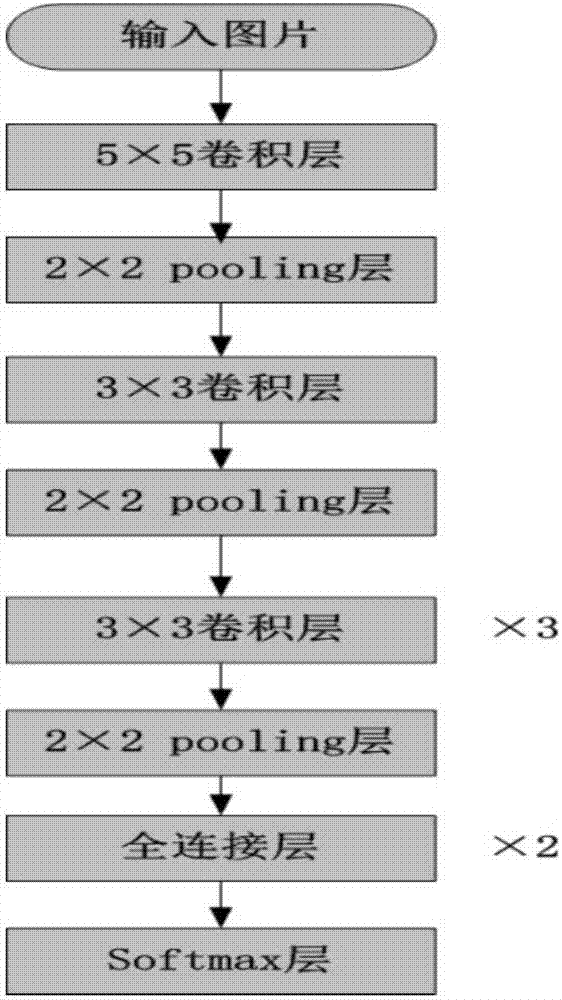
:智能家居,意為提升家居安全性、便利性、舒適性、藝術性,更加注重人機交互,為客戶提供更好的用戶體驗。而智能電視作為智慧家庭生活的中心,扮演重要角色。目前的智能電視除了觀看普通節目,還可以上網、娛樂通信。但這是僅僅是電視功能上的豐富,如何讓電視“讀懂”人類行為,做出相應“體貼”人類的決策,才是真正的智能電視。目前的疲勞檢測技術分成兩大類:a)基于生理參數的疲勞檢測技術。通過某些設備得出人的有關生理參數,如腦電圖(eeg)、眼電圖(eog)、心電圖(ecg)等,根據參數變化情況來判斷是否有疲勞產生;b)基于視覺特征的疲勞檢測技術。利用攝像機和模式識別等技術對視覺特征進行分類識別。當人感到疲勞時會出現眼瞼運動速度變慢、眼睛睜開幅度變小、眼睛凝視方向狹窄甚至閉眼等,有的會有頻繁點頭、打呵欠等,因此可以通過研究眼瞼眨動、眼球運動、頭部的位移面部表情等視覺特征進行疲勞檢測。在基于視覺特征的疲勞檢測技術中,有以下難點:a)如何先定位到人臉,進而精確定位到人眼部位;b)精確判斷人眼處于睜開還是閉合狀態;c)依據單位時間內閉眼次數,制定疲勞判斷標準。技術實現要素:為了解決上述技術問題,本發明將疲勞檢測技術應用于智能電視平臺,提供了一種時間復雜度低、精確度高的基于視覺特征的疲勞檢測系統及方法。本發明的系統所采用的技術方案是:一種電視智能檢測用戶睡眠狀態的系統,其特征在于:包括圖像采集模塊、人臉檢測模塊、人臉識別模塊、臉部追蹤模塊、人眼定位模塊、睜/閉眼識別模塊、疲勞檢測模塊、電視感應模塊;所述圖像采集模塊用于采集圖像;所述人臉檢測模塊用于對采集的第一幀圖像進行人臉檢測,找到臉部所在位置;所述人臉識別模塊用于對檢測到的人臉進行身份識別,獲取該人的疲勞參數;所述臉部追蹤模塊、人眼定位模塊、睜/閉眼識別模塊用于對第一幀之后的圖像中對人臉部分進行跟蹤并找到人眼部位,分割出人眼部位并對其進行睜/閉檢測;所述疲勞檢測模塊用于統計單位時間內閉眼幀數占總幀的比值perclos,通過perclos與疲勞參數進行比較,進行疲勞檢測;所述電視感應模塊依據不同的精神狀態,控制電視做出相應的感應行為。本發明的方法所采用的技術方案是:一種電視智能檢測用戶睡眠狀態的方法,包括以下步驟:步驟1:圖像采集;步驟2:人臉檢測;步驟3:人臉識別;步驟4:臉部追蹤;步驟5:人眼定位;步驟6:睜/閉眼識別;步驟7:疲勞檢測;步驟8:電視感應。本發明巧妙地將計算機視覺算法移植到電視平臺下,通過內嵌攝像頭捕獲人物的圖像,實現了疲勞狀態智能感應功能。本發明通過幾組實物實驗,分別從人臉識別、眼睛識別、疲勞檢測三個方面,層層遞進地驗證了本發明的可行性和實用性。本發明的系統框架對智能電視行業有很大的參考價值,為盡早實現心目中的智慧生活提供一個新思路。附圖說明圖1為本發明實施例的方法流程圖;圖2為本發明實施例的caffenet卷積神經網絡結構圖;圖3為本發明實施例的臉檢測識別圖示意圖;圖4為本發明實施例的睜/閉眼分類原理圖;圖5為本發明實施例的部分人臉數據集;圖6為本發明實施例的部分人臉數據集;圖7為本發明實施例的清醒/睡眠狀態下,三個單位時間的疲勞檢測結果示意圖。具體實施方式為了便于本領域普通技術人員理解和實施本發明,下面結合附圖及實施例對本發明作進一步的詳細描述,應當理解,此處所描述的實施示例僅用于說明和解釋本發明,并不用于限定本發明。為此考慮將計算機視覺算法運用于智能電視平臺,本發明提供了一種適用于智能電視的睡眠感應系統及方法。通過內嵌的攝像頭,捕捉人臉圖像并判斷人的精神狀態,依據不同的精神狀態,電視做出相應的決策。如當人將要睡著時,會自動調小音量和屏幕亮度;當人已進入睡眠狀態,將會自動關機。本發明提供的一種電視智能檢測用戶睡眠狀態的系統,一種電視智能檢測用戶睡眠狀態的系統包括圖像采集模塊(本實施例采用的是攝像頭)、人臉檢測模塊、人臉識別模塊、臉部追蹤模塊、人眼定位模塊、睜/閉眼識別模塊、疲勞檢測模塊、電視感應模塊;圖像采集模塊用于采集圖像;人臉檢測模塊用于對采集的第一幀圖像進行人臉檢測,找到臉部所在位置;人臉識別模塊用于對檢測到的人臉進行身份識別,獲取該人的疲勞參數;臉部追蹤模塊、人眼定位模塊、睜/閉眼識別模塊用于對第一幀之后的圖像中對人臉部分進行跟蹤并找到人眼部位,分割出人眼部位并對其進行睜/閉檢測;疲勞檢測模塊用于統計單位時間內閉眼幀數占總幀的比值perclos,通過perclos與疲勞參數進行比較,進行疲勞檢測;電視感應模塊依據不同的精神狀態,控制電視做出相應的感應行為。請見圖1,本發明提供的一種電視智能檢測用戶睡眠狀態的方法,包括以下步驟:步驟1:圖像采集;步驟2:人臉檢測;人臉檢測作為人臉識別的基礎和關鍵技術,目的是從輸入圖像中確定人臉的位置,大小等信息。本步驟中采用viola-jones人臉檢測方法。具體做法是用一個固定大小的窗口在輸入圖像進行滑動,窗口框定的區域會被送入到檢測器,去判斷是人臉窗口還是非人臉窗口。該檢測器的采用多個adaboost分類器級聯組成,其中用于訓練的正例樣本為人臉圖片,負例樣本為其他的非人臉的背景圖片,樣本提取的特征選用的是haar特征。由于訓練檢測器需要時間較長(多達幾十天),為省去訓練檢測器的時間,本實施例采用opencv自帶的基于haar特征的人臉級聯器——haarcascade_frontalface_alt.xml。步驟3:人臉識別;檢測出人臉部位后,需要對其人身份進行識別,獲取與之綁定的私人的疲勞參數。如果身份未被識別,則采用默認值進行疲勞檢測。這里采用基于caffenet卷積神經網絡的人臉識別算法。該網絡模型共有五組卷積池化層,兩組完全連接層,一組softmax層;前五組卷積池化層針對所給圖片進行特征提取,后面兩組全連接層針對所得圖片特征進行分類,關于各層卷積核等參數如圖2所示。人臉檢測和識別的效果如圖3所示。步驟4:臉部追蹤;考慮到viola-jones人臉檢測的方法需要對整張圖片進行滑窗操作,該操作需要遍歷整個圖像,很消耗時間。為保證實時性,考慮對第一幀之后的圖像,不再用人臉檢測的方法,而是利用目標追蹤的方法進行臉部追蹤。具體思想是,以第一幀檢測出的人臉部位作為模板,對第一幀之后的圖像利用tld(tracking-learning-detection)算法追蹤人臉模板。該算法主要由跟蹤、檢測、學習三個模塊組成,其中追蹤模塊假設相鄰視頻幀之間臉部的運動是有限的,且是可見的,以此來估計臉部的運動方向。當檢測出的臉部出現誤差時,用學習模塊對誤差進行評估,依據評估結果對臉部位置進行更新。步驟5:人眼定位;追蹤臉部位置后,下一步工作就是定位人眼的位置。采取縮小范圍的方式進行:先根據人臉的定位,將人臉的上半部分提取出來,人眼的位置一般處在人臉正面的1/3到1/2的位置。在人眼區域中可以觀察到,在豎直方向上,從上眼瞼到下眼瞼之間的眼白與瞳孔部分與周圍的皮膚有明顯的色差,梯度變化非常大,根據圖像的色度直方圖進行峰值判斷,在豎直方向上定位人眼。同理,在水平方向上也進行類似定位之后,就能精確地確定人眼的位置。步驟6:睜/閉眼識別;定位到人眼部位之后,需要對人臉狀態進行識別,即判斷睜眼或者閉眼兩種狀態。這里采用lbp算子對眼睛作特征描述,并結合adboost判斷眼睛開閉狀態。用訓練集中,睜眼正樣本和閉眼負樣本圖片各有100張。為了提高眼睛狀態判別的準確性和魯棒性,需使特征具有旋轉不變性,因此采用3層金字塔lbp對眼部進行特征描述。分類器如圖4所示。步驟7:疲勞檢測;臨床表明,當人處于疲勞狀態時,眨眼速度變慢,眼睛閉合時間變長,為此計算眼睛閉合幀數占總幀數的比值perclos,設定閾值t對人眼疲勞狀態進行判斷。每個人有不同的疲勞特征,因此每人的閾值選擇會有不同,如果是初期(第一次)測試,閾值t默認設為40%,否則按照數據庫中綁定的疲勞參數作為閾值t。疲勞檢測的主要過程如下:a.對定位好的人眼進行狀態識別,設睜、閉眼狀態表示為“+1”、“-1”,則眼睛狀態就是一個“+1”、“-1”的時間序列,保存當前人眼的狀態,便于統計眨眼的次數。b.每隔30秒統計檢測到的總幀數和閉眼的幀數,perclos就是時間序列中的“-1”所占的比例,由于視頻的采樣率是25幀/秒,如果對每一幀都拿來處理,計算量太大,且相鄰幀的人眼狀態變化很小,所以本文對視頻進行隔幀抓取,即每秒處理8張圖片,30秒內共計240張。c.根據perclos值對人的疲勞進行判斷。如果0=<perclos<t,表明人的狀態是清醒;如果t=<perclos<90%,表示處于疲勞狀態;如果90%=<perclos=<100%,表示處于睡眠狀態。步驟8:電視感應。人經過疲勞判斷后,有三種結果,分別是清醒,疲勞,睡眠。電視會依據不同的結果,做出相應的行為;分別是:若人的狀態是清醒,則電視正常工作;若人的狀態是疲勞,則電視自動調小音量和屏幕亮度;若人的狀態是睡眠,則電視關機。在缺乏電視平臺的前提下,沒有對電視“行為”進行實現,整個發明僅僅做到了疲勞檢測這一步,這些工作已經達到了預期的效果。本實施例涉及到兩個訓練樣本集,分別是用于人臉識別的人臉數據集,用于睜/閉眼識別的眼睛數據集。在人臉數據集包含jiang、hu、wang、zhou等四類,每類50張,共200張人臉圖像。此外,每類對應有各自的疲勞閾值。眼睛數據集包含睜/閉眼兩類,每類100張,共200張圖像。部分人臉數據集和眼睛數據集如圖5,6所示。本實施例中涉及到兩個分類器,分別是人臉識別模塊中神經網絡softmax分類器,和睜/閉眼識別模塊中adboost分類器。為驗證兩個識別算法的好壞,在上述數據集的基礎上,分別做了兩組實驗。第一組人臉識別實驗,混淆矩陣中的x軸和y軸分別表示圖像的類別,第i行j列的值表示第i類圖像被分類為第j類圖像的個數,混淆矩陣對角線上元素的值代表每類圖像的正確分類的個數。每類訓練樣本40張,測試樣本10張,表1和表2給出了實驗結果。結果表明,在該數據集下,本實施例的人臉識別算法正確率達(90%+90%+100%+80%)/4=90%。分析實驗結果高正確率的原因,一方面是樣本種類較少,而且每類之間的差異性較大;二方面也證明了本發明采用的基于神經網絡的人臉識別算法具有強魯棒性。表1.caffenet卷積神經網絡人臉測試集身份識別結果分布jiang9001zhou0901hu00100wang1108jiangzhouhuwang表2.人臉正確識別率jiangzhouhuwang90%90%100%80%第二組睜/閉眼識別實驗,每類訓練樣本70張,測試樣本30張,表3和表4給出了本實驗結果。平均分類正確率達(90%+93.3%)/2=91.7%,原因是有幾張睜眼照和閉眼照區別不大,利用adboost也難以區分開。表3.adboost分類器眼睛結果睜眼273閉眼228睜眼閉眼表4.adboost分類器對睜/閉眼情況識別準確率睜眼90%閉眼93.3%第三組實驗,是對整個系統疲勞檢測結果好壞的驗證。本實施例拍攝兩段視頻,視頻1是中測試人員是運動的,測試人員處于清醒狀態,眼睛長處于睜開狀態;視頻2是中測試人員是運動位移小,測試人員處于睡眠狀態,眼睛長處于閉狀態。每段視頻長度800幀左右,假設單位時間為240幀,則分別記下出每單位時間內測試人員眼睛處于睜開或者閉的次數,計算perclos,通過閾值判斷進行疲勞檢測。實驗中,清醒狀態下/睡眠狀態下,每個單位時間內檢測結果如圖8所示。每幀圖的左上方,由上到下分別記錄著單位時間內的幀序號,閉眼數,睜眼數,閉眼率,狀態;人臉部位用白色方框標記出;在白色方塊上面的字符,代表人臉識別的結果;眼睛部位由黑色方框標記出。實驗結果和預期的一樣,接近真實值。測試人員處于清醒狀態時,三個單位時刻疲勞檢測的結果均為清醒;測試人員處于睡眠狀態時,三個單位時刻疲勞檢測的結果均為睡眠。應當理解的是,本說明書未詳細闡述的部分均屬于現有技術。應當理解的是,上述針對較佳實施例的描述較為詳細,并不能因此而認為是對本發明專利保護范圍的限制,本領域的普通技術人員在本發明的啟示下,在不脫離本發明權利要求所保護的范圍情況下,還可以做出替換或變形,均落入本發明的保護范圍之內,本發明的請求保護范圍應以所附權利要求為準。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1