一種大數據處理方法及系統與流程
本發明涉及大數據處理技術領域,特別涉及一種大數據處理方法及系統。
背景技術:
近年來,互聯網的發展越來越迅速,使用互聯網的人也越來越普及,人們在使用互聯網進行日常的活動的時候,例如網購,查看節目,信息,商品都會產生大量的數據,而這些數據對于電子商務網站或者互聯網媒體類網站來說是非常寶貴的,利用這些大數據的處理處理能得到非常寶貴的商業價值。
大數據廣泛應用于互聯網各項應用中,對網站的價值意義重大,通過海量數據處理和云計算的實現,可以最大化幫助互聯網媒體類網站廣告系統和電子商務類網站大數據商品推送系統得到最大化的提升。互聯網媒體類網站大數據廣告根據用戶閱讀偏好推送,針對海量數據的云計算,通過各種廣告形式推送到網站瀏覽用戶電子商務類網站大數據商品推送給在線購買者,通過處理用戶點擊行為、購買行為、產品相關性、偏好及使用時間規律推送相應的商品及促銷信息。
大數據的出現,正在引發全球范圍內深刻的技術與商業變革。在技術上,大數據使從數據當中提取信息的常規方式發生了變化。在搜索引擎和在線廣告中發揮重要作用的機器學習,被認為是大數據發揮真正價值的領域。在海量的數據中統計處理出人的行為、習慣等方式,最大程度幫助廣告主找到精準潛在客戶,從而提升廣告效果和后續購買操作。
但是當前大數據應用存在著諸多的缺點,例如:1、數據的處理需要基于海量的數據積累。目前大數據需要根據數以百萬計的用戶及其歷史行為進行處理,而絕大部分的平臺或企業缺乏大數據依托,往往是小數據、中數據,此外行為習慣、購買記錄、閱讀記錄等數據也比較匱乏;2、數據處理需要強大的軟硬件支持。目前大數據的計算有較高的門檻,所以大數據的計算還不是很普及。現在大數據計算主要有下面兩類生態圈:開源大數據生態圈和商用大數據生態圈;3、數據處理需要依賴大量專業人士的解碼。大數據的行為模型,需要有較強的數學統計要求、計算機建模要求,目前國內還缺乏此類人才。比如需要掌握數據庫管理系統的使用能力、概率統計學等;4、數據處理結果還存在誤判。大數據的處理結果往往不具備實時性、針對性,原始數據采樣精準度和統計方法的差異性,以及建模結構性錯誤,都會導致處理有誤。此外不同的使用場景也會帶來完全不同的結果。
技術實現要素:
本發明實施例的目的在于提供一種大數據處理方法及系統,依托云計算能夠對大數據進行分布式數據挖掘,可以有效挖掘網站用戶行為數據,并實時有效地做云計算處理。
為達到上述目的,本發明實施例公開了一種大數據處理方法,方法包括:
根據用戶以往歷史瀏覽、購買記錄等行為進行數據采集;
利用hadoop分布式模式,對所述數據采集模塊采集到的數據進行過濾,得到的完整且不重復的數據;
將所述數據過濾模塊過濾后的完整且不重復的數據,轉化為計算機語言并存儲在數據庫中;
調用所述數據庫中存儲的信息,并利用云計算處理調用出的所述數據庫中的數據。
為達到上述目的,本發明實施例還公開了一種大數據處理系統,所述系統包括:
大數據采集模塊,所述數據采集模塊用于根據用戶以往歷史瀏覽、購買記錄等行為進行數據采集;
大數據過濾模塊,所述數據過濾模塊用于利用hadoop分布式模式,對所述數據采集模塊采集到的數據進行過濾,得到的完整且不重復的數據;
編譯模塊,用于將所述數據過濾模塊過濾得到的完整且不重復的數據,轉化為計算機語言;
數據庫,所述數據過濾模塊過濾得到的完整且不重復的數據經過所述編譯模塊轉化的計算機語言能夠存儲在所述數據庫中;
操作系統,通過所述操作系統,可以調用所述數據庫中存儲的數據信息;
云計算模塊,所述云計算模塊能處理所述數據庫中的數據。
可選的,所述數據處理系統還可以包括:
網絡服務器,通過所述網絡服務器能將多個所述數據庫中的數據連接起來,提供更大的數據。
可選的,所述操作系統為linux操作系統。
可選的,所述網絡服務器為apache網絡服務器。
可選的,所述數據庫為mysql數據庫。
可選的,所述編譯模塊為perl、php或者python編程語言。
可選的,所述數據采集模塊采集的數據通過所述云計算進行分布式的數據挖掘,以此有效地挖掘出所需要的數據。
可選的,所述數據處理系統還可以包括:
storm拓撲結構架構,通過所述拓撲結構架構在不需要專業人員的情況下可實時矯正數據處理的偏差。
可選的,所述數據處理系統還可以包括:
mapreduce功能的簡單storm拓撲結構,所述mapreduce功能的簡單storm拓撲結構可實時矯正數據處理的偏差。
可見,本發明實施例提供的一種大數據處理方法及系統,根據大數據處理系統能夠提升網站的廣告傳播的精準度和商城商品展示的精準度;通過大數據系統處理技術使得平臺能迅速了解用戶的行為習慣和偏好,并在其使用過程中實時動態交互,讓感興趣的廣告及商品在恰當的時間以友好的網站形式進行展示,解決了傳統廣告和商品展示不精準的問題;解決了國內企業在軟硬件上的缺陷,以及操作人員的經驗不足,幫忙平臺克服原始數據凌亂、大數據模型建模、數據處理及預測等問題,提供實時且相對有效的數據支持;依托云計算能夠對大數據進行分布式數據挖掘,可以有效挖掘網站用戶行為數據,并實時有效地做云計算處理;并且,其中包含的storm拓撲結構可在不需要專業人員的情況下實時矯正數據處理偏差。
當然,實施本發明的任一產品或方法并不一定需要同時達到以上所述的所有優點。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例提供的一種大數據處理方法的流程示意圖。
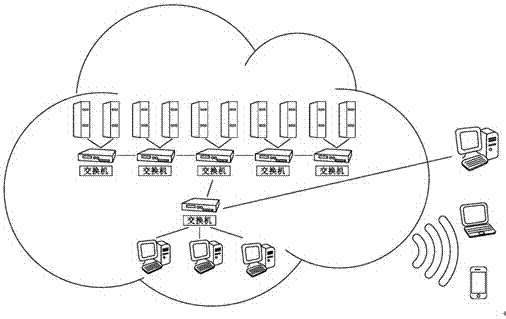
圖2為本發明實施例提供的一種分布式數據挖掘示意圖。
圖3為本發明實施例提供的一種storm拓撲結構架構示意圖。
圖4為本發明實施例提供的一種mapreduce功能的簡單storm拓撲結構示意圖。
圖5為本發明實施例提供的一種hadoop云框架配置方案示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
參見圖1,圖1為本發明實施例提供的一種大數據處理方法的流程示意圖,可以包括如下步驟:
s101,根據用戶以往歷史瀏覽、購買記錄等行為進行數據采集;
s102,利用hadoop分布式模式,對所述數據采集模塊采集到的數據進行過濾,得到的完整且不重復的數據;其中,hadoop分布式模式為現有技術,本發明實施例在此不對其進行贅述;
s103,將所述數據過濾模塊過濾后的完整且不重復的數據,轉化為計算機語言并存儲在數據庫中;
s104,調用所述數據庫中存儲的信息,并利用云計算處理調用出的所述數據庫中的數據。
大數據處理系統應用在一些電子商務類網站上,例如應用在a商城上。其中a商城大數據處理系統主要包含對用戶以往歷史瀏覽、購買記錄等行為進行大量及時的處理,形成龐大的商城動態數據倉庫,根據購買偏好和采購頻率,通過數據挖掘及時推送用戶商品信息,自動定期發送包括edm、短信、站內信等多種形式的商品廣告信息。還有,大數據處理系統同時也是作為考核商城產品熱度和布局的依據,熱門常用的產品通過系統處理可以自動排序到最顯眼的位置。根據用戶訪問通道(通常是通過ip地址判斷或賬號判斷,嚴格遵守安全保密原則),網站內的推薦產品、熱門產品會隨著用戶的操作而快速更新調整,匹配用戶感興趣的商品,從而最大程度提升網站商品的精準銷售。為了實現a商城大數據處理系統的功能,本發明提供的一種大數據處理系統采用分布式計算架構(lamp),lamp框架包括:linux操作系統,apache網絡服務器,mysql數據庫,perl、php或者python編程語言,所有組成產品均是開源軟件,是國際上成熟的架構框架。和java/j2ee架構相比,lamp具有web資源豐富、輕量、安全等特點,與微軟的.net架構相比,lamp具有通用、跨平臺、高性能優勢。同時商城數據實時備份、事務處理效應快速、擁有完備的數據處理功能。再通過云計算形式,處理大規模并行(mpp)數據庫、分布式數據庫等,可以快速、大量、精準的處理商城用戶的購買習慣,推送相匹配的產品以多樣化的形式展現在購買者的視覺中,從而有效促進商品購買的概率和頻率。
大數據處理系統應用在一些互聯網媒體類網站上,例如應用在a網站上。其中a網站大數據處理系統,尤其是a網站大數據廣告系統,能自動提升付費廣告客戶在網站上最大程度匹配潛在客戶,通過大量用戶行為數據處理,通過云計算處理在短時間內為瀏覽網站的客戶推送相關聯的廣告信息。從而促進在線用戶對感興趣類別的廣告進行瀏覽、點擊查看等后續行為,是實現廣告價值最大化的一門核心互聯網技術。同時a網站廣告系統還支持互聯網絕大多數廣告形式,包括文字鏈、圖片廣告、視頻廣告等。擁有健全的廣告排期機制,能精準統計廣告pv、點擊效果、數據統計等。具備廣告客戶競價體系,可按照cpc、cpm、cpa、cps、cpv等多種形式進行收費。為了實現a網站大數據廣告系統的功能,本發明提供一種大數據處理系統采用分布式計算架構(lamp),lamp框架包括:linux操作系統,apache網絡服務器,mysql數據庫,perl、php或者python編程語言,所有組成產品均是開源軟件,是國際上成熟的架構框架。和java/j2ee架構相比,lamp具有web資源豐富、輕量、安全等特點,與微軟的.net架構相比,lamp具有通用、跨平臺、高性能優勢。同時通過云計算形式,處理大規模并行(mpp)數據庫、分布式數據庫等,可以快速、大量、精準的處理廣告信息并多樣化的展示在用戶面前。
根據圖2所示的分布式數據挖掘,分布式數據挖掘依托云計算的分布式處理、分布式數據庫(paas)和云存儲、虛擬化技術(iaas)。通過移動端、pc端來展現云計算呈現數據效果。可以有效挖掘網站用戶行為數據,并實時有效的做云計算處理,反饋用戶感興趣的廣告信息和商品。
隨著云時代的來臨,大數據也吸引了越來越多的關注。大數據通常用來形容一個公司創造的大量非結構化數據和半結構化數據,這些數據在下載到關系型數據庫用于處理時會花費過多時間和金錢。大數據處理常和云計算聯系到一起,因為實時的大型數據集處理需要像mapreduce一樣的框架來向數十、數百或甚至數千的電腦分配工作。
大數據需要特殊的技術,以有效地處理大量的在經過時間內容納的數據。適用于大數據的技術,包括大規模并行處理(mpp)數據庫、數據挖掘電網、分布式文件系統、分布式數據庫、云計算平臺、互聯網和可擴展的存儲系統。
根據圖3所示的storm拓撲結構架構,使用快速高效的storm架構,可實時矯正大數據處理的偏差,而且不需要專業的人員就可以得出較為精準的數據結果。storm不只是一個傳統的大數據處理系統,它是復雜事件處理(cep)系統的一個示例。cep系統通常分類為計算和面向檢測,其中每個系統都可通過用戶定義的算法在storm中實現。值得一提的是,storm的一個最主要的特點在于它注重容錯和管理。storm實現了有保障的消息處理,所以每個元組都會通過storm拓撲結構進行全面處理;如果發現一個元組還未處理,它會自動從噴嘴處重放。storm還實現了任務級的故障檢測,在一個任務發生故障時,消息會自動重新分配以快速重新開始處理。storm包含比hadoop更智能的處理管理,流程會由監管員來進行管理,以確保資源得到充分使用。
具體的,storm還實現了一種數據流模型,其中數據持續地流經一個轉換實體網絡,如圖3所示。一個數據流抽象地稱為一個流(流源,streamsource),一個流是一個無限的元組序列(元組流,tuplestream)。元組就像一種使用一些附加的序列化代碼來表示標準數據類型(比如整數、浮點和字節數組)或用戶定義類型的結構。每個流由一個惟一id定義,這個id可用于構建數據源和接收器(sink)的拓撲結構。流起源于噴嘴(消息源,spout),噴嘴將數據從外部來源流入storm拓撲結構中。并且,spout可以發射元組流給消息處理者(bolt),bolt可以執行過濾、聚合、查詢數據庫等操作,而且可以一級一級的進行處理元組流,并可以進行流轉換(streamtransformation)。
根據圖3所示mapreduce功能的簡單storm拓撲結構。針對普通的平臺或企業,采用更為簡單的storm模型,可以更好的適應中小數據流的處理,具有更為廣闊的應用領域。接收器(或提供轉換的實體)稱為螺栓。螺栓實現了一個流上的單一轉換和一個storm拓撲結構中的所有處理。螺栓既可實現mapreduce之類的傳統功能,也可實現更復雜的操作(單步功能),比如過濾、聚合或與數據庫等外部實體通信。典型的storm拓撲結構會實現多個轉換,因此需要多個具有獨立元組流的螺栓。噴嘴和螺栓都實現為系統中的一個或多個任務。
值得一提的是,可使用storm為詞頻輕松地實現mapreduce(映射歸約)功能。如圖4中所示,噴嘴生成文本數據流,螺栓實現map(映射)功能(令牌化一個流的各個單詞)。來自“map”螺栓的流然后流入一個實現reduce(歸約)功能的螺栓中(以將單詞聚合到總數中)。
根據圖5所示的hadoop云框架配置方案,其主要闡述云計算的實現,通過云端的配置實現高效的數據處理。hadoopmapreduce采用master(主盤)/slave(從盤)結構。master是整個集群的唯一的全局管理者,功能包括:作業管理、狀態監控和任務調度等,即mapreduce中jobtracker(作業控制器)。slave負責任務的執行和任務狀態的回報,即mapreduce中的tasktracker(任務執行器)。
hadoop的核心是使用java語言編寫的,但支持使用各種語言編寫的數據處理應用程序。最新的應用程序的實現采用了更加深奧的路線,以充分利用現代語言和它們的特性。
具體的操作步驟如下:首先使用了五臺機器來實現hadoop框架。
ip依次為:
192.168.1.199(master)
192.168.1.200(slave)
192.168.1.201(slave)
192.168.1.202(slave)
192.168.1.203(slave)
首先登錄119服務器:
[root@localhost~]#uname-ar
linuxlocalhost2.6.18-92.el5#1smptuejun1018:49:47edt2008i686
i686i386gnu/linux
保證計算機名的全局唯一性:
hadoop1.test.com-----192.168.1.203
hadoop2.test.com-----192.168.1.202
hadoop3.test.com-----192.168.1.201
hadoop4.test.com-----192.168.1.200
hadoop5.test.com-----192.168.1.199
設置hostname:
hostnamehadoop5.test.com
[root@localhost~]#vi/etc/hosts
127.0.0.1localhost.localdomainlocalhos
192.168.1.199hadoop5.test.com
[root@localhost~]#uname-ar
linuxhadoop5.test.com2.6.18-92.el5#1smptuejun1018:49:47edt
2008i686i686i386gnu/linux
[root@localhost~]#vi/etc/sysconfig/network
networking=yes
networking_ipv6=no
#hostname=localhost.localdomain
hostname=hadoop5.test.com
gateway=192.168.1.254
無密碼的ssh登錄的設置:
建立master到每一臺slave的ssh受信證書。由于master將會通過ssh啟動所有slave的hadoop,所以需要建立單向或者雙向證書保證命令執行時不需要再輸入密碼。在master和所有的slave機器上執行:ssh-keygen-trsa。
執行此命令的時候,看到提示只需要回車。然后就會在/root/.ssh/下面產生id_rsa.pub的證書文件,通過scp將master機器上的這個文件拷貝到slave上(記得修改名稱),例如:
scproot/.ssh/id_rsa.pubroot@192.168.1.200:/root/.ssh/authorized_keys
建立authorized_keys文件即可,可以打開這個文件看看,也就是rsa的公鑰作為key,user@ip作為value。此時可以試驗一下,從masterssh到slave已經不需要密碼了。由slave反向建立也是同樣。為什么要反向呢,其實如果一直都是master啟動和關閉的話那么沒有必要建立反向,只是如果想在slave也可以關閉hadoop就需要建立反向。
具體地實現互聯網媒體類網站廣告推送和電子商務網站商品展示的步驟如下:
(a)通過數據采集模塊采集用戶以往歷史瀏覽、購買記錄等行為信息;
(b)將所采集到的信息通過轉化,轉化為計算機語言存儲在數據庫中;及
(c)用戶在點擊網頁時根據云計算對所述數據庫中的信息進行分布式數據挖掘,反饋用戶感興趣的廣告信息和商品。
其中步驟(b)中包括步驟:
(b.1)將采集到的信息通過一編譯模塊轉化為計算機語言;
(b.2)轉化為計算機語言的信息存儲在一數據庫中;
(b.3)多個所述數據庫中的信息通過一網絡服務器相連接,實現大數據的形成;及
(b.4)通過一操作系統隨時調用所采集到的信息。
其中在步驟(b)中所述操作系統優選為linux操作系統,所述網絡服務器優選為apache網絡服務器,所述數據庫優選為mysql數據庫,所述編譯模塊優選為perl、php或者python編程語言。
綜上所述,大數據處理系統是結合了當前大數據技術的各種解決方案基礎上,形成簡潔高效的技術處理手段。適用于中小企業、媒體平臺、電商平臺,性價比較高,可以滿足日常經營所需的數據處理支持,幫助企業更好的獲得收益。
可見,本發明實施例提供的一種大數據處理方法及系統,根據大數據處理系統能夠提升網站的廣告傳播的精準度和商城商品展示的精準度;通過大數據系統處理技術使得平臺能迅速了解用戶的行為習慣和偏好,并在其使用過程中實時動態交互,讓感興趣的廣告及商品在恰當的時間以友好的網站形式進行展示,解決了傳統廣告和商品展示不精準的問題;解決了國內企業在軟硬件上的缺陷,以及操作人員的經驗不足,幫忙平臺克服原始數據凌亂、大數據模型建模、數據處理及預測等問題,提供實時且相對有效的數據支持;依托云計算能夠對大數據進行分布式數據挖掘,可以有效挖掘網站用戶行為數據,并實時有效地做云計算處理;并且,其中包含的storm拓撲結構可在不需要專業人員的情況下實時矯正數據處理偏差。
需要說明的是,在本文中,諸根據第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
本說明書中的各個實施例均采用相關的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。尤其,對于裝置實施例而言,由于其基本相似于方法實施例,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
本領域普通技術人員可以理解實現上述方法實施方式中的全部或部分步驟是可以通過程序來指令相關的硬件來完成,所述的程序可以存儲于計算機可讀取存儲介質中,這里所稱得的存儲介質,根據:rom/ram、磁碟、光盤等。
以上所述僅為本發明的較佳實施例而已,并非用于限定本發明的保護范圍。凡在本發明的精神和原則之內所作的任何修改、等同替換、改進等,均包含在本發明的保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!