基于正視的人機交互方法與系統與流程
本發明涉及人機交互技術領域,特別是涉及基于正視的人機交互方法與系統。
背景技術:
人機交互是指人與設備之間使用某種對話語言,以一定的交互方式,為完成確定任務的人與設備之間的信息交換過程。
隨著科學技術的發展,人機交互技術的應用領域越來越寬廣,小如收音機的播放按鍵,大至飛機上的儀表板、或是發電廠的控制室,用戶都可以通過人機交互界面與系統交流,并進行操作。目前在人機交互技術中,主流的人機交互方式主要包括3種,第一種是傳統按鍵方式;第二種是特定語音詞激活方式,如:在對話前先說“小冰你好”,設備才識別后面所聽到的語音;第三種是“舉手發言”,即先用一個特定手勢動作來讓設備啟動語音識別。
上述人機交互方式,雖然在一定程度上可以實現人機交互功能,但是由于交互方式單一,需要預先設定一定特定手勢動作,交互過程并不十分自然,在一定程度上給用戶操作帶來不便。
技術實現要素:
基于此,有必要針對一般人機交互方式單一且不自然給用戶帶來不便操作的問題,提供一種人機交互方式多樣,且交互過程自然,給用戶帶來便捷操作的基于正視的人機交互方法與系統。
一種基于正視的人機交互方法,包括步驟:
獲取通過圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據;
通過圖像采集設備實時采集用戶當前圖像數據,將當前采集的圖像數據與正視圖像數據比較;
當當前采集的圖像數據和正視圖像數據一致時,判定用戶與設備處于相對正視狀態;
當用戶與設備處于相對正視狀態時,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作,所述計算機的視覺識別技術和語音識別技術包括人臉識別、語音識別、語義理解、手勢識別、唇語識別、聲紋識別、表情識別、年齡識別、卡片識別、人臉跟蹤、瞳孔識別以及虹膜識別。
一種基于正視的人機交互系統,包括:
獲取模塊,用于獲取通過圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據;
比較模塊,用于通過圖像采集設備實時采集用戶當前圖像數據,將當前采集的圖像數據與正視圖像數據比較;
判定模塊,用于當當前采集的圖像數據和正視圖像數據一致時,判定用戶與設備處于相對正視狀態;
控制模塊,用于當用戶與設備處于相對正視狀態時,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作,所述計算機的視覺識別技術和語音識別技術包括人臉識別、語音識別、語義理解、手勢識別、唇語識別、聲紋識別、表情識別、年齡識別、卡片識別、人臉跟蹤、瞳孔識別以及虹膜識別。
本發明基于正視的人機交互方法與系統,獲取通過圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據,采集用戶當前圖像數據,將當前采集的圖像數據與正視圖像數據比較,當一致時,判定用戶與設備處于相對正視狀態,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作。整個過程中,基于圖像采集設備采集的圖像數據進行正視判定,并以用戶與設備的正視狀態判定作為人機交互前提條件,確保當前用戶確實有人機交互需求,整個人機交互過程自然,另外采用包括人臉識別、語音識別、手勢識別、唇語識別、聲紋識別、表情識別、年齡識別、卡片識別、瞳孔識別以及虹膜識別的多種動作識別方式識別用戶下一步動作,能夠實現多樣式人機交互,給用戶帶來便捷操作。
附圖說明
圖1為本發明基于正視的人機交互方法第一個實施例的流程示意圖;
圖2為本發明基于正視的人機交互方法第二個實施例的流程示意圖;
圖3為本發明基于正視的人機交互系統第一個實施例的結構示意圖;
圖4為本發明基于正視的人機交互方法與系統具體應用場景示意圖。
具體實施方式
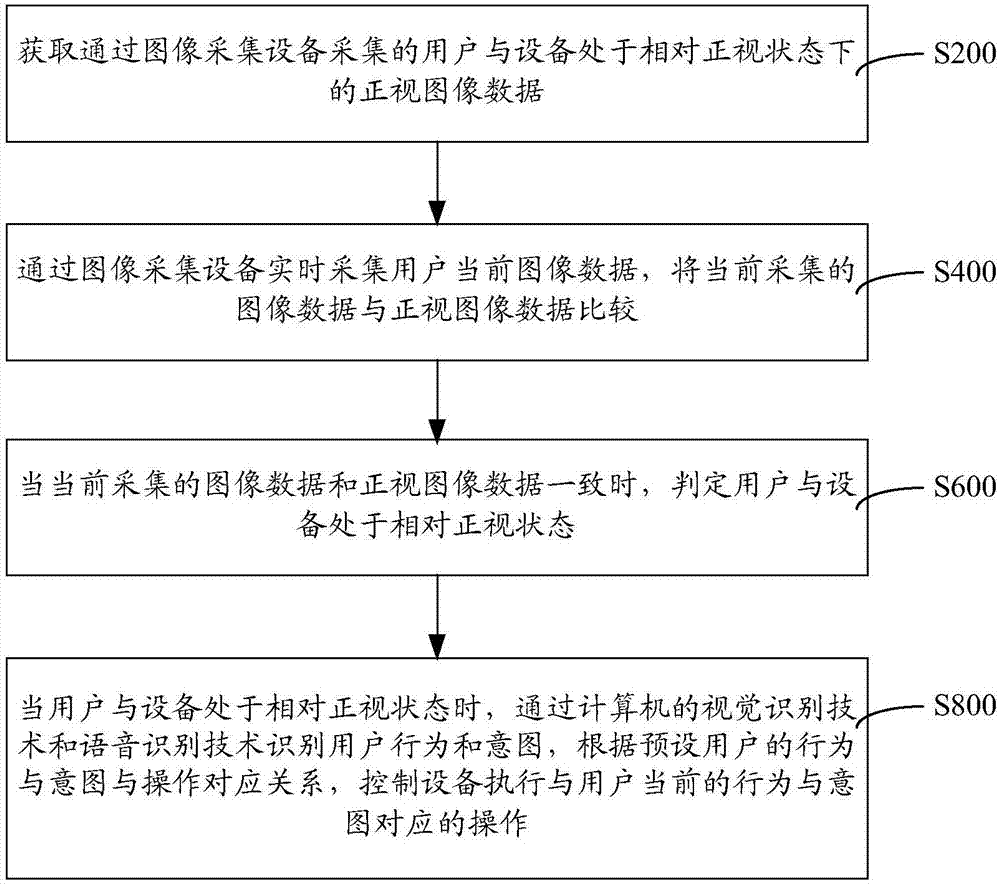
如圖1所示,一種基于正視的人機交互方法,包括步驟:
s200:獲取通過圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據。
設備具體來說可以為電視機、空調、電腦以及機器人等,另外設備還可以包括車載設備等。用戶與設備處于相對正視狀態是指用戶正視設備,例如當設備為電視機時,用戶正視電視機的狀態即為用戶與電視機處于相對正視狀態。由于圖像采集設備一般是無法設置于設備正中心的,所以圖像采集設備采集用戶與設備處于相對正視狀態下圖像時,從圖像采集設備角度看去用戶眼睛或用戶人臉并不是正對圖像采集設備的,一般會呈現一定的角度。為了有利于后續精準判定正視狀態,先獲取圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據。具體來說,用戶與設備處于相對正視狀態下的正視圖像數據可以是歷史記錄中采集好的數據,也可以是當場采集的數據。圖像采集設備可以是攝像頭等設備,在這里,用戶與設備處于相對正視狀態下的正視圖像數據是通過圖像采集設備采集的圖像采集設備可以設置于設備上,還可以設置設備的輔助設備或外圍設備上,例如當設備為電視機時,圖像采集設備可以設置于電視,也可以設置于與電視配套的機頂盒上。更具體來說,攝像頭拍攝的用戶與設備處于相對正視狀態下的正視圖像數據,進行圖像處理和圖像目標坐標換算之后即可確定設備和用戶人臉相對位置,即可以獲取用戶與設備處于相對正視狀態下用戶的人臉圖像數據。判定用戶與設備處于相對正視狀態可以選擇采用頭部姿態估計(headposeestimation)或者視線跟蹤(gazetracking)等技術來實現。
s400:通過圖像采集設備實時采集用戶當前圖像數據,將當前采集的圖像數據與正視圖像數據比較。
通過步驟s200中相同的圖像采集設備實時采集用戶當前圖像數據,并且將實時采集的圖像數據與步驟s200獲取的正視圖像數據比較,以判斷當前用戶與設備是否處于相對正視狀態。
s600:當當前采集的圖像數據和正視圖像數據一致時,判定用戶與設備處于相對正視狀態。
當步驟s200獲取的正視圖像數據與步驟s400實時采集的圖像數據一致時,即表明當前用戶與設備處于相對正視狀態。
s800:當用戶與設備處于相對正視狀態時,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作,所述計算機的視覺識別技術和語音識別技術包括人臉識別、語音識別、語義理解、手勢識別、唇語識別、聲紋識別、表情識別、年齡識別、卡片識別、人臉跟蹤、瞳孔識別以及虹膜識別。
用戶與設備處于相對正視狀態的前提下,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作。即只有判定用戶與設備處于相對正視狀態的前提下,設備才會啟動響應用戶操作,這樣,一方面避免誤操作,例如可以避免電視機錯誤啟動、錯誤切換電視機節目等;另一方面,由于用戶與設備處于相對正視狀態時,即有極大可能性用戶對設備進行操作,給用戶帶來便利。具體來說,計算機的視覺識別技術和語音識別技術主要可以包括人臉識別、人臉檢測、人臉跟蹤、語音識別、手勢識別、唇語識別、聲紋識別、表情識別、年齡識別、卡片識別、瞳孔識別以及虹膜識別等。采用上述豐富的計算機的視覺識別技術和語音識別技術能夠從人臉、語音、瞳孔、手勢等方面實現人機交互,更進一步豐富用戶生活,給用戶帶來便捷操作。
本發明基于正視的人機交互方法,獲取通過圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據,采集用戶當前圖像數據,將當前采集的圖像數據與正視圖像數據比較,當一致時,判定用戶與設備處于相對正視狀態,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作。整個過程中,基于圖像采集設備采集的圖像數據進行正視判定,并以用戶與設備的正視狀態判定作為人機交互前提條件,確保當前用戶確實有人機交互需求,整個人機交互過程自然,另外采用包括人臉識別、語音識別、手勢識別、唇語識別、聲紋識別、表情識別、年齡識別、卡片識別、瞳孔識別以及虹膜識別的多種動作識別方式識別用戶下一步動作,能夠實現多樣式人機交互,給用戶帶來便捷操作。
如圖2所示,在其中一個實施例中,步驟s800包括:
s820:對用戶與設備處于相對正視狀態的時間進行計時。
s840:當用戶與設備處于相對正視狀態的時間大于預設時間時,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作。
預設時間是事先設定的好的時間閾值,具體可以根據實際情況的需要進行設定,例如可以設定為2秒、3秒、5秒等。當步驟s600判定用戶與設備處于相對正視狀態下時,開始對用戶與設備處于相對正視狀態的時間進行計時,當用戶與設備處于相對正視狀態的時間大于預設時間時,表明很大概率用戶當前需要對顯示設定進行下一步操作,此時,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作,例如啟動設備。可以采用人臉識別、瞳孔識別以及虹膜識別等技術確定用戶與設備保持著相對正視狀態,即保持正視狀態也屬于用戶動作的一種。非必要的,在啟動設備之后,采用人臉識別技術,識別用戶身份,查找與用戶身份匹配的視頻圖像數據,控制設備顯示查找到的視頻圖像數據。在實際應用中,當設備為電視機時,計時用戶與電視機保持相對正視狀態的時間,即計時用戶正視電視機屏幕的時間,當用戶正視電視機的時間大于預設時間(例如2秒)時,啟動電視機,并識別用戶身份,查找與當前用戶喜好的電視機節目,控制電視機切換至該電視節目播放。
具體來說,在實際應用場景中,上述實施例為:“正視狀態”+時間,即用戶“正視”電視機達到一定時間,比如2秒鐘,可以認為用戶想看電視節目,電視機可以從待機開啟播放節目;電視機也可以跟用戶主動打招呼交流。還可以是:“正視狀態”+時間+“人臉識別”,即知道這個用戶是誰,可以播放這個用戶喜歡的節目;電視機還可以主動呼叫用戶,主動跟用戶交流。
在其中一個實施例中,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作的步驟包括:
步驟一:對用戶進行語音識別和唇語識別。
步驟二:當語音識別結果和唇語識別結果一致時,控制設備響應用戶的語音操作。
對設備前處于“正視狀態”的用戶進行唇語識別,同時對檢測到的語音信息進行語音識別。將唇語識別結果與語音識別結果比對,如果結果一致,可以判定該正視狀態用戶是在跟設備(電視機)對話,控制設備作出相應的響應,如果結果不一致,則設備不響應。
通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作的步驟包括:
步驟一:對所述用戶進行語音識別和語義理解。
步驟二:當語音識別結果和語義理解的結果與設備當前場景相符時,控制設備響應所述用戶的語音操作。
在本實施例中,還需要對用戶進行語音識別和語義理解,理解用戶意圖,當語音識別結果和語義理解的結果與設備當前場景相符時,控制設備響應所述用戶的語音操作。例如用戶在看電視時,如果說的話是:“我明天休息”,顯然不是操作電視機的,電視機不響應。如果用戶說的是“中央一臺”,則顯然是要切換到中央一臺。
在實際應用中,以設備為電視機為例對用戶a進行語音識別和唇語識別,即一方面采集用戶a發出的語音信息,另一方面基于正視狀態,對用戶a進行唇語識別,當語音識別和唇語識別結果一致時,判定用戶a是在跟電視機交互,控制電視機做出相應的響應,例如切換電視節目,調節電視音量等操作。
在其中一個實施例中,所述當所述當前采集的圖像數據和所述正視圖像數據一致時,判定用戶與設備處于相對正視狀態的步驟之前還包括:
步驟一:當偵測到用戶時,定位所述用戶的面部位置為音源位置;
步驟二:將聲音采集設備正對所述音源位置;
所述通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作的步驟包括:
通過所述聲音采集設備采集用戶聲音數據,當采集的用戶聲音數據中攜帶有語音操作指令時,提取所述語音操作指令,控制設備執行與所述語音操作指令對應操作。
當偵測到用戶時,將用戶面部位置定位為聲源位置,讓聲音采集設備正對該聲源位置,準備采集用戶聲音數據。具體來說,這個過程具體可以是基于人臉檢測和跟蹤技術檢測到用戶人臉的位置,定位該位置為音源位置。在后續操作中,在判定當前用戶與設備處于相對正視狀態時,采集用戶語音數據,進行語音識別,當采集的用戶語音數據中攜帶有語音操作指令時,提取語音操作指令,控制設備執行與語音操作指令對應操作。另外,偵測用戶可以通過人臉檢測、人臉跟蹤、人體檢測等偵測方法偵測,當偵測到人臉位置時,將用戶的面部位置設定為聲源位置。在實際應用中,聲音采集設備可以為陣列麥克風,將陣列麥克風正對音源位置,采集用戶語音數據,當采集的用戶語音數據中攜帶有語音操作指令(例如“下一頻道”)時,提取語音操作指令,控制設備執行與語音操作指令對應操作。更具體來說,在實際應用場景中,比如有幾個人看電視時,幾個人都是正視電視,如果幾個人同時說話,將來的陣列麥克風(像雷達一樣可以跟蹤多個目標)可以對多個音源錄音。通過人臉檢測等方式偵測用戶數量和位置,即為目標音源的數量和位置,給陣列麥克風提供目標音源的位置信息,結合人臉身份識別,可以實現同時采集多人的聲音,并區分是誰說的內容,當有用戶發出的聲音數據中攜帶有“下一頻道”的操作指令時,控制電視機切換至下一頻道。另外,還可以結合人臉身份識別針對用戶身份合法性進行識別,只有合法(擁有控制權的)用戶發出的聲音數據才會被采集,并進行后續操作。
本發明基于正視的人機交互方法,以正視狀態作為后續處理的“開關”,只有判定用戶與設備處于相對正視狀態,才會進行后續包括開啟錄音、或者開啟語音識別、或開啟語音識別結果在內的操作。
另外,在其中一個實施例中,所述當所述當前采集的圖像數據和所述正視圖像數據一致時,判定用戶與設備處于相對正視狀態的步驟之后還包括:
步驟一:接收用戶輸入的操作指令,所述操作指令包括非正視狀態操作指令和正視狀態操作指令。
步驟二:當偵測到用戶不再處于所述正視狀態時,響應用戶輸入的非正視狀態操作指令。
步驟三:當偵測到用戶再次進入所述正視狀態時,響應用戶輸入的正視狀態操作指令。
在實際應用中電視機接收用戶輸入的操作指令,具體可以是用戶通過遙控器或直接觸碰按鍵又或是點擊電視機上設置的觸摸顯示區域輸入操作指令,該操作指令分為非正視狀態操作指令和正視狀態操作指令,當偵測到用戶不再處于所述正視狀態時,響應用戶輸入的非正視狀態操作指令;當偵測到用戶再次進入所述正視狀態時,響應用戶輸入的正視狀態操作指令。例如通過語音指令或其它方式,讓電視機進入“錄背影”狀態,人從正視電視機轉為側視,電視機自動開啟錄像模式,人旋轉一圈,再正視電視機時停止錄像,并開啟視頻播放模式,播放剛才所錄視頻。
在其中一個實施例中,通過圖像采集設備實時采集用戶當前圖像數據的步驟之后還包括:
步驟一:獲取用戶正視設備時的圖像數據。
步驟二:比較用戶正視設備時的圖像數據和當前采集的圖像數據。
步驟三:當用戶正視設備時的圖像數據和當前采集的圖像數據一致時,啟動計算機的視覺識別技術和語音識別技術、和/或預設操作。
具體來說,只有當檢測到用戶正視設備時,才啟動預設對應的計算機的視覺識別和語音識別技術功能。檢測用戶是否正視設備可以采用比較用戶正視設備時的圖像數據和當前采集的圖像數據的方式進行,當一致時,表明當前用戶正視設備,啟動計算機的視覺識別和語音識別技術功能(例如手勢識別、人臉識別以及語音識別等);當不一致時,表明當前用戶尚未正視設備,不啟動計算機的視覺識別和語音識別技術功能。在實際應用中,以設備為空調為例,通過攝像頭實時采集用戶當前圖像數據,獲取用戶正視空調時的圖像數據;比較用戶正視空調時的圖像數據和當前采集的圖像數據,當兩者一致時,表明當前用戶正視于空調,啟動語音識別技術和人臉識別技術、手勢識別技術,語音識別技術用于識別用戶語音指令,人臉識別技術用于識別用戶身份,手勢識別技術用于識別用戶手勢指令。
如圖3所示,一種基于正視的人機交互系統,包括:
獲取模塊200,用于獲取通過圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據。
比較模塊400,用于通過圖像采集設備實時采集用戶當前圖像數據,將當前采集的圖像數據與正視圖像數據比較。
判定模塊600,用于當當前采集的圖像數據和正視圖像數據一致時,判定用戶與設備處于相對正視狀態。
控制模塊800,用于當用戶與設備處于相對正視狀態時,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作,計算機的視覺識別技術和語音識別技術包括人臉識別、語音識別、手勢識別、唇語識別、聲紋識別、表情識別、年齡識別、卡片識別、瞳孔識別以及虹膜識別。
本發明基于正視的人機交互系統,獲取模塊200獲取通過圖像采集設備采集的用戶與設備處于相對正視狀態下的正視圖像數據,比較模塊400采集用戶當前圖像數據,將當前采集的圖像數據與正視圖像數據比較,當一致時,判定模塊600判定用戶與設備處于相對正視狀態,控制模塊800通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作。整個過程中,基于圖像采集設備采集的圖像數據進行正視判定,并以用戶與設備的正視狀態判定作為人機交互前提條件,確保當前用戶確實有人機交互需求,整個人機交互過程自然,另外采用包括人臉識別、語音識別、手勢識別、唇語識別、瞳孔識別以及虹膜識別的多種動作識別方式識別用戶下一步動作,能夠實現多樣式人機交互,給用戶帶來便捷操作。
在其中一個實施例中,控制模塊800包括:
計時單元,用于對用戶與設備處于相對正視狀態的時間進行計時,當用戶與設備處于相對正視狀態的時間大于預設時間時,通過計算機的視覺識別技術和語音識別技術識別用戶行為和意圖,根據預設用戶的行為與意圖與操作對應關系,控制設備執行與用戶當前的行為與意圖對應的操作。
在其中一個實施例中,控制模塊800還包括:
查找控制單元,用于查找預設與用戶身份匹配的視頻圖像數據,控制設備顯示查找到的視頻圖像數據。
在其中一個實施例中,控制模塊800包括:
識別單元,用于對用戶進行語音識別和唇語識別;
控制單元,用于當語音識別結果和唇語識別結果一致時,控制設備響應用戶的語音操作。
在其中一個實施例中,控制模塊800包括:
定位單元,用于當偵測到用戶時,定位用戶的面部位置為音源位置;
調節單元,用于將聲音采集設備正對音源位置,采集用戶聲音數據;
提取控制單元,用于當采集的用戶聲音數據中攜帶有語音操作指令時,提取語音操作指令,控制設備執行與語音操作指令對應操作。
為了更進一步詳細解釋本發明基于正視的人機交互方法與系統的技術方案,下面將采用多個具體應用實例,模擬不同實際應用場景,并結合圖4進行說明,在下述應用實例中設備均為電視機。
獲取通過如圖4所示的攝像頭采集的用戶與電視機處于相對正視狀態下的正視圖像數據。
通過如圖4所示的攝像頭實時采集當前圖像數據,將實時采集的數據與用戶與電視機處于相對正視狀態下的正視圖像數據比較。
當一致時,判定用戶與電視機處于相對正視狀態。
應用實例一、正視狀態+時間
用戶正視電視機達到一定時間,比如2秒鐘,可以認為用戶想看電視節目,電視機可以從待機開啟播放節目,也可以跟用戶主動打招呼交流。
應用實例二、正視狀態+時間+人臉識別
知道這個用戶是誰,可以播放這個用戶喜歡的節目;電視機還可以主動呼叫用戶,主動跟用戶交流。
應用實例三、正視狀態+人臉身份識別+表情識別
顯然,知道用戶是誰,而且知道他的表情,可以主動跟該用戶交流,甚至提供相應的服務。如果是一個小孩對著電視機哭,電視機可以自動撥打媽媽的視頻電話,電視機上很快就可以出現媽媽的視頻,讓寶寶跟媽媽視頻交流。
應用實例四、正視狀態+人臉識別+語音識別
人臉識別確認現場只有一個用戶時,電視機可以把語音識別的結果視為該用戶對電視機所說,電視機作出相應回復和反饋。
應用實例五、正視狀態+人臉識別+唇語識別+語音識別
人臉識別確認現場有多個用戶時,判斷用戶是否“正視狀態”,檢測“正視”用戶的嘴唇變化,對正視用戶進行唇語識別;同時對檢測到的語音信息進行語音識別。將唇語識別結果與語音識別結果比對,如果結果一致,可以判定該正視用戶是在跟電視機對話,電視機作出相應的回應;如果結果不一致,則電視機不回應。
應用實例六、正視狀態+陣列麥克風+人臉識別(或者聲紋識別)
比如有幾個人看電視時,幾個人都是正視電視。如果幾個人同時說話,將來的陣列麥克風(像雷達一樣可以跟蹤多個目標)可以對多個音源錄音。正視識別可以確定目標有幾個,給陣列麥克風提供目標音源的位置信息,結合人臉身份識別,可以實現同時采集多人的聲音,并區分是誰說的內容。
應用實例七、應用于空調
用戶望著空調,空調管理系統通過頭部姿態估計確認用戶為“正視”狀態,空調啟動人臉識別——知道用戶是誰,打開并調節到用戶喜歡的狀態;空調啟動手勢識別——可以接受用戶的手勢操作;空調啟動錄音和語音識別--可以接受用戶的語音指令操作。
以上實施例僅表達了本發明的幾種實施方式,其描述較為具體和詳細,但并不能因此而理解為對發明專利范圍的限制。應當指出的是,對于本領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干變形和改進,這些都屬于本發明的保護范圍。因此,本發明專利的保護范圍應以所附權利要求為準。
- 還沒有人留言評論。精彩留言會獲得點贊!