一種基于效用函數的面向大數據處理的公平資源調度方法與流程
本發明涉及數據分析集群中的資源分配和作業調度領域,尤其涉及公平性的資源調度分配與截止時間,吞吐量,利用率等系統性能指標相結合的調度,具體涉及一種基于效用函數的面向大數據處理的公平資源調度方法。
背景技術:
在大數據處理的調度算法中,公平性是最被關注的調度目標。其中,最大最小公平算法能夠為各用戶與作業隊列之間提供很好的性能隔離,所以被很多大數據分析平臺所采用。但保障公平性往往意味著系統服務質量與系統性能的下降,如何基于公平性原則提高系統的服務質量與系統性能是當前需要迫切解決的問題。隨著數據分析集群的迅速發展,各種各樣的作業擁有不同的截止時間(deadline)方面的服務需求,一般來說,交互式作業和流數據作業對于截止時間的要求較高,而批處理作業由于待處理的工作量比較大,通常對于截止時間的界定比較寬松。為了保障各類作業的截止時間都能夠被滿足,最近截止時間優先的算法(earliest-deadline-first)被廣泛應用在各類調度算法中。在這樣一種作業調度方式下,交互式作業和流數據作業通常被優先調度,而批處理作業由于長時間獲取不到系統資源產生了“饑餓”,同時,作業之間的公平性也得不到保障。所以,單純用一個截止時間的指標不足以衡量不同作業之間輕重緩急的程度,系統的公平性效率也得不到很好的描述。
效用函數能夠標識各類作業隨著時間在推移過程中對于系統的重要程度的變化情況。通常,越早完成的作業對于系統產生的效用越高,越接近或超過其截止時間,作業的效用函數下降得越快。由于交互式作業和流數據作業對于截止時間的要求較高,硬性效用函數可以用來表示該類任務,在系統時間超過作業截止時間時,作業的效用瞬間下降到0或者負數值。而批處理作業由于對于截止時間的要求比較寬松,可以采用軟性效用函數,在超出作業截止時間之后也能夠產生一部分系統效用。由于效用函數的上述特性,其在處理器和網絡調度等領域中經常被用來取代單一的截止時間指標,各種作業的性質都能夠在這個函數框架下得到靈活和準確的描述,同時,公平性調度中權重的概念也能夠在效用函數中得到很好的體現。進一步考慮,作業的截止時間之所以得不到保障通常由于當前系統的負載較高,系統中的共享資源不能夠滿足所有作業的需求。所以,在保證系統資源分配公平性與優先調度比較緊急的作業的同時,提高系統的吞吐量和利用率是保障作業截止時間的重要途徑。離線版的多資源利用率問題可以規約為np-hard的背包問題,所以我們考慮采用在線版本的最大資源點乘法設計貪心調度算法。
技術實現要素:
發明目的:為了克服現有技術中存在的不足,本發明提供一種基于效用函數的面向大數據處理的公平資源調度方法,能在公平調度的基礎上,有效地保證系統性能的隔離性,提高系統資源的利用率,減少違反服務質量保證的作業比例。
技術方案:為實現上述目的,本發明中的基于效用函數的面向大數據處理的公平資源調度方法,包括以下步驟:
步驟(1):對于數據分析集群中的每一個作業,獲取其作業基本數據,所述作業基本數據包括:作業權重、有向無環圖、資源需求、運行時間、截止時間和作業的時間窗口;
步驟(2):對于某一作業,根據作業的時間窗口和程序接口(api)性質確定其是否為流數據處理作業,若不是流數據處理作業,則根據運行時間與預設的閾值進行比較來判斷其作業類型,運行時間小于或等于預設的閾值為交互式作業;運行時間大于預設的閾值為批處理作業;;
步驟(3):對流數據作業采用離線預約的方式進行資源分配;
步驟(4):對于其他作業,調度流數據處理作業預約之后的剩余資源。
其中,步驟(3)中對流數據作業采用離線預約的方式進行資源分配,包括以下步驟:
(31)對于所有的流數據處理作業,各自按照最大資源點乘法排列其內部任務的執行順序;
(32)對于所有已經確定內部執行順序的作業劃分執行區間,單個作業執行區間的開始時間為上個流數據處理作業的數據輸出結束時間,執行區間的結束時間為下一個流數據處理作業的數據輸入開始時間,按照執行區間的由長至短依次為流數據處理作業預約資源。
其中,步驟(32)中對于執行區間長度相同的流數據處理作業,先對所有作業按照運行時間長度進行排序,先按照時間方向從前向后調度,然后從相反方向調度,如此類推反復改變時間方向直至所有流數據處理作業得到資源的預約。在每個方向上的調度方式均為:在所有待預約的作業中,按照作業運行時間的長度,依次對作業進行預約,直到達到執行區間所能允許調度的最多作業。
其中,步驟(4)中對于其他作業,調度流數據處理作業預約之后的剩余資源,包括以下步驟:
(41)根據其作業權重、運行時間和截止時間特征創建其各自的效用函數,使用當前作業調用完成的預期時間點的效用函數的值除以該作業的剩余的松弛時間求出其效用密度,松弛時間通過剩余的截止時間減去剩余的完成時間來計算,然后對效用密度按照從大到小的順序進行排列;
用作業在當前正在系統當中運行的任務數除以作業的權重值得到作業的公平性平衡程度,并對各作業的公平性平衡程度按照從小到大的順序進行排序;
選擇符合條件的作業放入待調度作業池,所述符合條件是指對于某個作業,該作業的效用密度在所有作業中的排列次序不大于預先給定的截止時間系數值與作業總數的乘積向上取整之后的數值,且該作業的公平性平衡程度在所有作業中的排列次序不大于預先給定的公平性系數與作業總數的乘積向上取整之后的數值;
(42)在進行在線調度時,丟棄預期效用小于或等于0的失效作業,從作業池中選擇滿足不超出當前可分配資源條件并且資源點乘法結果最大的任務進行調度。
有益效果:本發明中基于效用函數的面向大數據處理的公平資源調度方法,對流數據作業采用離線預約的方式,對交互式和批處理作業采用在線調度的方式來確定資源分配和作業調度的結果,利用了不同作業類型的特點,同時,在保證系統資源分配的公平性的基礎上,考慮以截止時間作為主要的服務質量的指標進行約束,同時統籌兼顧了系統的資源利用率和吞吐量的提高。本發明方法將效用函數作為衡量作業重要性的指標,能夠更加完善、準確以及滿足用戶公平性,提高作業服務質量,系統的總體處理能力以及整體效用。
附圖說明
圖1為本發明中基于效用函數的面向大數據處理的公平資源調度方法的流程圖;
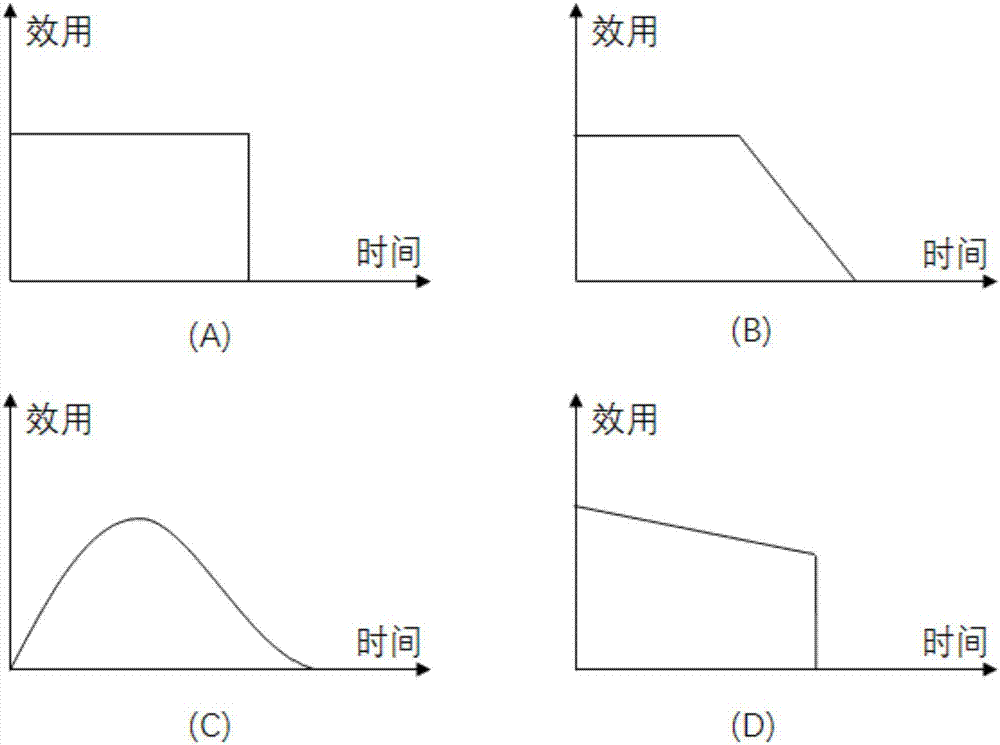
圖2為作業效用函數的示意圖;圖2(a)為一種硬性效用函數,圖2(b)為一種軟性效用函數,圖2(c)為另一種軟性效用函數,圖2(d)為另一種硬性效用函數;
圖3為實施例中流數據處理、交互式和批處理作業的有向無環圖;
圖4為圖3中作業調度的結果圖。
具體實施方式
下面結合實例對本發明做進一步的詳細說明,本實例對本發明不構成限定。
圖1中基于效用函數的面向大數據處理的公平資源調度方法,對三種不同的作業采用離線預約和在線調度兩種不同的方式來確定資源分配和作業調度的結果。具體包括以下步驟:
(1)對于大數據系統(數據分析集群)中的每一個作業,獲取其作業基本數據,所述作業基本數據包括:作業權重、表征作業內部任務相互依賴關系的有向無環圖、資源需求、運行時間、作業的截止時間、作業的時間窗口等;
每一個作業的基本情況對應一組相應的特征向量,作業的截止時間如果在用戶和服務提供商的sla合同中沒有明確給出,則通過用戶反饋的方法進行自動標定。
(2)對于某一作業,根據其時間窗口和api性質確定其是否為流數據處理作業,若不是流數據處理作業,則根據其運行時間與預設的閾值進行比較判斷其作業類型,運行時間小于或等于預設的閾值為交互式作業;運行時間大于預設的閾值為批處理作業;
流數據處理作業的時間窗口通常為用戶設定的較為規整的數值,因此判斷作業是否為流數據處理作業的方式包括:作業運行是否具有穩定的時間窗口(外來的流數據輸入間隔)以及是否經由流數據處理特定的程序接口(api)提交作業。
(3)對流數據作業采用離線預約的方式進行資源分配,具體包括以下步驟:
(31)對于所有的流數據處理作業,對所有的流數據處理作業分別按照最大資源點乘法排列其內部任務的執行順序;系統資源將扣除之前已經預約完成的任務所需求的資源,扣除的結果將作為后續任務的調度算法中最大點乘法計算的基礎。
(32)對于所有已經確定內部執行順序的作業劃分執行區間,單個作業執行區間的開始時間為上個流數據處理作業的數據輸出結束時間,執行區間的結束時間為下一個流數據處理作業的數據輸入開始時間。系統優先為執行區間較長的流數據處理作業預約資源。
用戶提交的時間窗口通常比較規整,所以可以預期相當比例的流數據處理作業在同一個執行區間內執行,并且每一個執行區間內的作業調度安排形成了離線版本的背包問題。對于執行區間相同的流數據處理作業,可以同時預約調度。仿照背包問題的貪心求解方法,即:先把所有作業按照運行時間長度進行排序,第一次先從前向后調度,優先調度時間最長的作業,若當前執行區間尚未結束,則依次選擇次長的任務在上一作業結束完成時間之后調度,直到執行區間再也容納不下額外的作業時間長度;第二次調度從后向前調度,同樣的,先把尚未預約資源的作業按照運行時間長度進行排序,優先調度時間最長的作業放置在執行區間的末尾,若當前執行區間尚未結束,則依次選擇次長的任務在上一作業結束開始時間之前調度,直到執行區間所能允許調度的最多作業;依次類推,反復改變時間方向,直至為所有流數據處理作業預約到系統資源。
對于流數據處理作業的調度方式先考慮各作業之間不同時執行,便于系統的資源能夠在執行時間段內被平均地分攤;在此基礎上,因為首末兩端的資源經常得不到預約,所以通過反復改變時間方向來預約資源,便于為后面的交互式作業和批處理作業的執行預留比較合理而均勻的資源空間。
(4)對于其他作業,調度流數據處理作業預約之后的剩余資源。
(41)對于后兩類作業根據其權重、運行時間和截止時間的特征創建其各自的效用函數,使用當前作業調用完成的預期時間點的效用函數的值除以該作業的松弛時間(剩余的截止時間-剩余的完成時間)求出其效用密度,對效用密度按照從大到小的順序進行排列,根據用戶給定的截止時間系數κ(0≤κ≤1)值篩選當前κ比例的作業放入待調度作業池。
創建效用函數指的是:先將作業按照交互式作業和批處理作業分類成為軟性和硬性的效用函數,然后由系統管理員選擇當前系統所使用的兩種效用函數模型,在模型里面根據完成時間等關鍵值生成具體函數。比如一個硬性的直線函數(圖2a),設定前一段縱坐標的值(效用值)等于作業的完成時間乘以權重值,而效用值降為0的點在橫坐標上等于作業的截止時間。
另外,對于所有的系統作業,也可以按照其公平性的平衡程度,設定公平性系數μ(0≤μ≤1),將各作業的公平性平衡程度按照從小到大進行排序,選出總體比例不大于公平性系數的作業放入作業池。公平性的平衡程度計算一般是用作業在當前正在系統當中運行的任務數除以作業的權重值,比值越小表示對該作業分配的資源越不公平。
亦或者,通過截止時間系數和公平性系數共同選擇,即,能夠進入作業池的作業滿足以下條件:該作業的效用密度在所有作業中的排列次序不大于預先給定的截止時間系數值與作業總數的乘積向上取整之后的數值,且該作業的公平性平衡程度在所有作業排列次序不大于預先給定的公平性系數與作業總數的乘積向上取整之后的數值。例如:系統當中有3個作業,截止時間比例為60%,則3*60%=1.8≈2,取排列次序為前兩個的作業進入系統作業池。
公平性系數μ和系統截止時間系數κ越接近0表示該項指標的約束力越大,越接近1表示該項指標的約束力越小。
(42)在進行在線調度時,從作業池中選擇滿足不超出可分配資源條件并且當前資源點乘法結果最大的任務進行調度,并丟棄當前等待隊列中預期效用小于或等于0的失效作業。
上述預期效用指的是把當前作業按照最大分布度調度到系統當中去,在預期完成時間點的效用值。如果小于0,也就是說無論怎么調度都已經不會對系統產生正向效用了。步驟(42)的處理可以使得部分未能夠預期在截止時間前完成的硬性效用函數的交互式作業提前被丟棄,而部分拖延時間較長的軟性效用函數的批處理作業同樣會被丟棄,避免系統在這些已經失效的作業上浪費資源。
上述資源點乘法指的是:兩個資源向量相乘的值,比如當前系統剩余可分配資源的向量為a=(a1,b1,c1),作業所需求的資源向量為b=(a2,b2,c2),則a·b=a1a2+b1b2+c1c2,這個就是資源向量點乘法。本發明中基于效用函數的面向大數據處理的公平資源調度方法中,采用離線預約的方式預先確定流數據處理作業需要的資源,然后采用在線調度的方式對于交互式作業和批處理作業進行調度,本實施例結合圖3中各作業的運行時間t以及資源需求比例r來對本發明方法做具體的解釋。
圖3當中,設流數據處理作業st、st′、st″的窗口時間(執行區間)大小均為4s,所以可以根據步驟(31)的要求將各個作業內部的任務進行緊湊的順序排列,由于st′、st″都是單任務作業,所以排列很簡單,而st是多任務工作,st中包含了四個任務,分別為st1、st2、st3和st4,st3需要在任務st1執行完畢后才能執行,任務st4需要在st2、st3執行完畢后才能執行。假設當前系統資源中的資源向量為(1,1),則st2所需求的資源向量為(0.2,0.5),st1所需求的資源向量為(0.4,ε),ε為幾乎為0的數,按照最大資源點乘法則,優先分配st2的資源,由于0.2+0.4<1,所以在執行st2的同時可以執行st1,st2的運行時間t為1s,st1的運行時間t為0.3,且st3所需求的資源向量為(ε,0.4),所以,st1執行完畢后可繼續執行st3,這樣st1、st3都可以與st2并行調度,對相應作業的運行時間進行了壓縮,在三個任務完成之后最后調度st4,最終,st的運行時間為1.5s。
由于三個流數據處理任務均處于同一執行區間,st′的運行時間t最長為2s,所以按照步驟(32)的要求,先預定st′的資源,其次是運行時間t為1.5s的st。此時,由于st″的運行時間t是0.8s,如果接著st的后面調度就會超出4s的執行區間的結束時間,所以st″從反方向的末尾端向前安排預留資源。
對于交互式作業和批處理作業,采用在線調度的方式。先確定其相應的效用函數。如圖2所示,a和d為兩種硬性效用函數,一旦系統時間到達作業截止時間,那么作業的效用立刻衰減為0,而b和c為軟性效用函數,作業效用在截止時間到達后仍然可以產出較少的系統效用,需要指出的是c類函數是一種特殊情況,遞增部分表示當前作業的輸入數據沒完全輸入進系統之前該作業執行完成的效用情況。在本發明中,結合各類作業的性質,交互式作業考慮采用硬性效用函數,而批處理作業則使用軟性效用函數。如圖3所示,其中的交互式作業in和in′均采用a類效用函數,設定其截止時間為2s,截止時間之前的效用值為0.5。而批處理任務ba采用b類效用函數,設定其截止時間為20s,截止時間之前的效用值為4.5,截止時間之后的效用函數是斜率為-0.5的直線段,直到效用降低到0為止。
假設在0s的時候,共有6個交互式作業in′,6個交互式作業in,1個批處理作業ba到達系統。在2s的時候,共有2個交互式作業in′,2個交互式作業in作業到達系統。由于交互式作業都是單任務作業,所以對于同一時間釋放的作業來說,系統在選擇哪個作業去執行都是等價的,任選它們中的同一時間釋放的作業執行即可。但為了辨認不同時間釋放的作業,設定0s釋放的作業為in0s以及in′0s,而第2s釋放的作業為in2s以及in′2s。由于交互式作業只包含一個任務,所以我們可以設定第0s釋放的作業in0s中的任務為in1-0s,in′0s中的任務為in′1-0s;而第0s釋放的作業in2s中的任務為in1-2s,in′2s中的任務為in′1-2s(如圖4所示)。
在系統時間為0s的時候,共有6個交互式作業in0s,6個交互式作業in′0s,1個批處理作業ba到達當前系統,in0s與in′0s的截止時間都是2s,而ba的截止時間是20s。假設用戶設置系統的截止時間系數κ為0.85,公平系數μ為0,根據步驟(41),表示系統當中效用密度按照從大到小排列次序為前12
系統時間為1s時,由于當前系統中的作業只剩下2個in0s作業,2個in′0s作業,1個sb作業,由于當前交互式處理任務數量減少,則從大到小排列次序為前5
系統時間為2s時,由于in0s作業的預期效用(預計在2.5s時才能完成)為0,所以0s提交的兩個inos作業均被丟棄。此時,新到達了2個in2s作業和2個in′2s作業。由于當前的作業個數是5,截止時間系數是0.85,類似1s時間點處的計算所有作業都被放入作業池中,并且此時ba2和ba3都可以被系統調度。此時以及按照步驟(42),如圖4所示,在2s時,除去預約資源的剩余資源是(0.4,0.5),in2s的資源點乘法計算結果是0.3*0.5,in′2s的資源點乘法計算結果是0.3*0.4,而ba2的資源點乘法為0.4*0.4,ba3的資源點乘法為0.1*0.4+0.4*0.5,此時雖然ba3的資源點乘最大,但是,在2.3s的時候,系統當中的資源為(0.8,0.1),而ba3的運行時間為1.5s,當其運行到2.3s時會發生資源不足的情況,所以我們選擇資源點乘法次多的ba2進行調度,空余資源可以分配給in中的任務,2.5s之后,st1和st3都已運行完成,此時ba3也可以進行調度,并同時按資源點乘所計算的順序運行in′1-2s,in1-2s以及in′1-2s三個任務。可以看到所有任務都在4s之前得到了調度。所以,調度過程的時間跨度(makespan)為4s,整個過程的兩種系統資源平均利用率均達到了80%以上。
本發明方法將系統中的流數據處理、交互式和批處理任務區別對待,首先將對時間要求比較敏感的流數據處理任務按照緊湊的部署方式在執行區間內均勻地進行系統資源的預約,其次為了保障作業的公平性和截止時間的要求,使用效用函數的方式對作業進行建模,并使用公平性系數和截止時間系數對系統的作業池進行篩選。最后利用最大資源點乘法貪心調度當前最合適的任務,提高系統的利用率。因此,最終的調度能夠在保證系統公平性的基礎上保證截止時間,以及吞吐量兩方面的需求,提高系統的總體性能。并且這樣的調度方式更加準確完備地符合當前大數據處理中多用戶各種各樣的個性化配置,能夠以可插拔式的設計理念與現代流行的資源調度平臺相結合。
以上詳細描述了本發明的優選實施方式,但是,本發明并不限于上述實施方式中的具體細節,在本發明的技術構思范圍內,可以對本發明的技術方案進行多種等同變換,這些等同變換均屬于本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!