一種基于多視角圖模型的餐具檢測和識別方法與流程
本發明涉及一種機器視覺的餐具檢測和識別方法,尤其涉及一種基于多視角圖模型的檢測和識別方法。
背景技術:
隨著服務機器人硬件成本的下降和相關理論技術的不斷成熟以及人們的需求,餐廳服務機器人已經開始應用于餐廳幫助人們回收餐具。餐廳服務機器人需要應用計算機視覺技術,實時檢測并識別出餐桌中不同的餐具類別。并根據餐具中的內容(如有無食物),進行后續處理(如收拾餐具)任務。餐具檢測和識別主要根據采集圖像中餐具、食物的位置和輪廓,對餐具、食物進行分割,并識別出其具體類別。目前,基于計算機視覺的餐具、食物檢測和識別方法主要為單視角檢測和識別,存在檢測不準確和識別率低等問題,因此,本發明提出基于多視角圖模型的餐具檢測和識別方法,用來提高檢測效果和識別率。
技術實現要素:
本發明提供了一種基于多視角圖模型的餐具檢測和識別方法,利用多視角圖模型的學習框架將餐具檢測和識別結合成統一的框架,首先利用多視角圖模型檢測圖像中的餐具,然后利用多視角特征融合學習新特征進行餐具的識別。
采用多視角圖模型進行圖像的餐具檢測,利用超像素點在多個視角下的特征構建圖模型,然后再學習每個超像素點是餐具所在位置的置信度,從而更準確的檢測出餐具。采用多視角融合算法進行特征融合,構建更強區分性的特征,有利于提高識別率。在多視角圖模型構建中,利用指數型權值參數,避免出現多視角的權值系數為零,使得各個視角特征能夠相互補充。在餐具檢測中,既考慮了餐具種子節點的作用,同時考慮了背景種子節點的作用,以加大背景和餐具的差異性。在餐具分割過程中,沒有直接在彩色圖像中提取餐具,而是先在二值圖像上確定餐具的最小外接矩,然后在對應的彩色圖像上進行分割,從而降低算法復雜度、提高分割效果。
附圖說明
為了更清楚的說明本發明的實施例或現有技術的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖做一簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
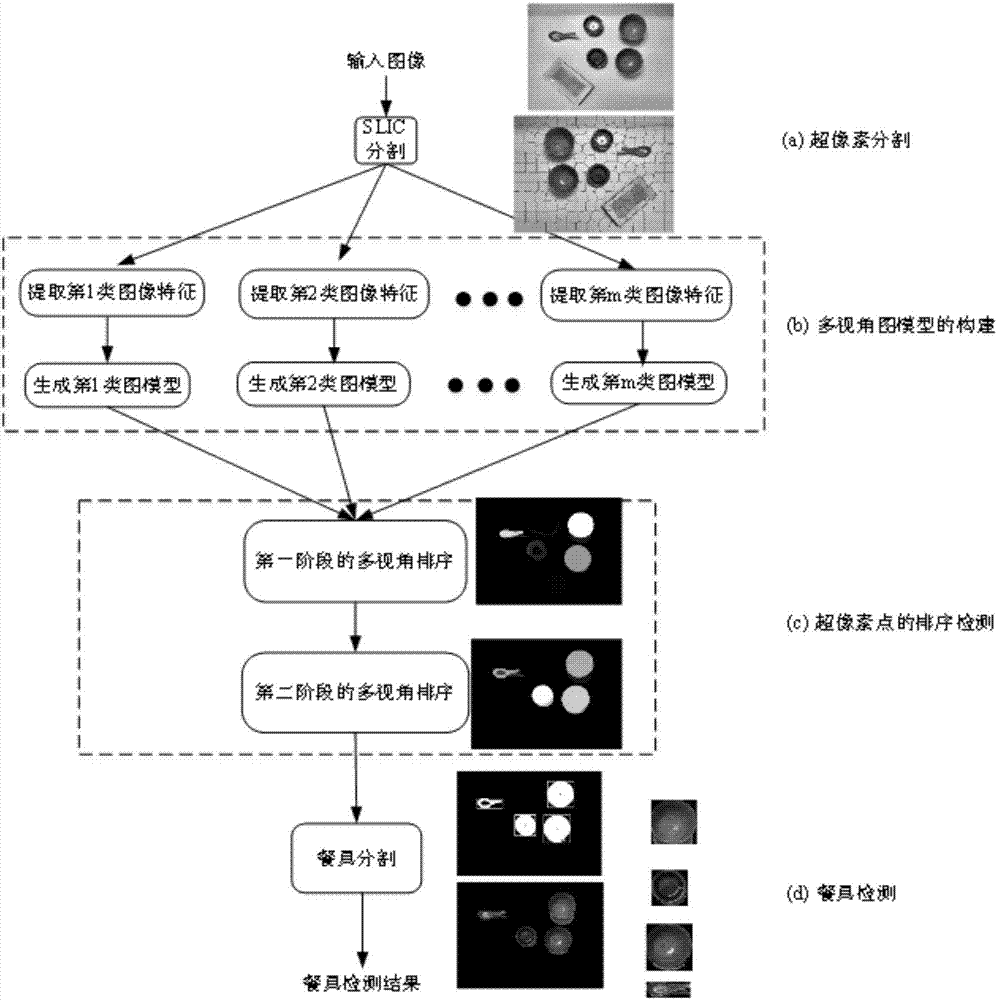
圖1為本發明基于多視角圖模型的餐具檢測算法流程圖
圖2為本發明基于多視角特征融合的餐具識別流程圖
圖3為本發明餐具分割示意圖
圖4為本發明餐具檢測效果示意圖
圖5為本發明算法和單視角排序算法多個餐具時檢測效果對比示意圖
具體實施方式
為使本發明的實施例的目的、技術方案和優點更加清楚,下面結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚完整的描述:
本發明縮略語和關鍵術語定義:
slic:simplelineariterativeclustering,簡單線性迭代聚類算法
svm:supportvectormachine,支持向量機
hsv:huesaturationvalue,hsv顏色模型
mds:multipledimensionalscaling,多維縮放
如圖1~5所示:一種基于多視角圖模型的餐具檢測和識別方法,主要包括以下步驟:
圖像的超像素分割是將圖像中大量的像素點分割成少量的整體性超像素點,這種分割也是對圖像內容的一種初步分割過程。
simplelineariterativeclustering(slic)算法是一種簡單有效的線性迭代聚類算法,slic算法采用接近人眼視覺感知特性的lab顏色空間進行超像素點的分割,定義圖像中像素點的總個數為n,超像素分割的步驟為:
(1)先將整幅圖像平均分割成k個部分,每部分均為s×s的小區域,其中,
(2)初始化每個小區域的中心為ck=[lk,ak,bk,xk,yk]t,其中(xk,yk)為該小區域中梯度最小的點即f(x+1,y)+f(x,y+1)-2f(x,y)最小的點;
(3)根據式
(4)當新的中心ck與舊的中心ck的位置距離小于一個很小的閾值時輸出超像素分割的結果,否則重復步驟(2)~(3);
本發明使用hsv顏色直方圖[4]和顏色矩[4]這兩種特征分別構建超像素點間的多視角圖模型。
對于
以圖像中所有的超像素點為圖模型的節點,通過超像素點間的位置關系確定節點間是否存在連接邊。
此外,為了更好的利用圖像的邊緣信息,規定圖像邊緣部分的超像素點都是互相連接的。
以此策略確定出圖模型的所有連接邊,而邊權值則可以通過超像素點之間特征向量的高斯核函數進行計算:
其中,
在第一階段的目標檢測過程中,假設圖像邊緣的超像素點是背景信息,所以在該階段的相似性學習過程中,設定初始的相似性值y=[y1,y2,…,yn]t。
設定圖像上邊界的超像素節點對應的初始相似性值為1;其它所有的超像素節點設置為0。假設多視角圖模型學習得到的相似性值為f,則多視角排序算法的目標優化函數可以表示成:
該式可以進一步轉化成如下的矩陣形式
其中,α(t)是每個視角下近鄰矩陣的權重系數,參數μ>0是平衡目標函數中平滑約束項和擬合約束項,||·||2表示向量的2范數,tr(·)表示矩陣的跡。l(t)=d(t)-w(t)是第t個視角下近鄰矩陣所對應的的拉普拉斯矩陣,
對于該多視角圖模型的求解過程可以通過分別迭代求解其中的兩個參數f和α,在迭代求解過程中先初始化這兩個參數,先固定參數α,求解更新參數f,再固定參數f,求解更新參數α,以此迭代,直到參數f與上一次迭代的結果小于給定的閾值。求得f和α的解析解,采用迭代的方法進行求解,具體的迭代方法如下:
(1)計算每個視角下的近鄰矩陣w(t)(1≤t≤m),初始化α(t)=1/m,f=y,
(2)當
(3)
(4)利用
更新近鄰矩陣的權值參數α;
(5)返回相似性得分向量f。
其中,輸入為通過hsv、顏色矩獲得的近鄰矩陣w(t)和初始相似性特征向量y=[y1,y2,…,yn]t;若yi為上邊界的節點,則初始相似值為1,其它所有的超像素節點設置為0。參數γ用來調節各個視角之間的權重,參數μ為調節式
利用上述方法迭代得到超像素點之間的相似性值為ft,第i個超像素點為目標的相似值可以表示成:
st(i)=1-ft(i),i=1,2,…,n(4)
同樣的,可以分別將圖像的下邊界、左邊界和右邊界作為背景信息節點,設定相應的初始相似性特征向量,然后再利用多視角圖模型的排序算法進行學習,依次分別確定出其對應的目標相似值sb(i)、sl(i)和sr(i),然后將這四個相似值進行整合得到整體的檢測結果:
s1(i)=st(i)sb(i)sl(i)sr(i),i=1,2,…,n(5)
在第二階段的目標檢測過程中,設定兩個所述相似性f閾值t1和t2,設定t1為界定為餐具的相似度閾值,t2為界定為背景的相似度閾值,初始的相似性向量
其中i=1,2,…,n,對該向量進行標準化生成初始的相似性值。
然后再利用式(3)中的方法學習超像素之間的相似性
將第二次檢測的結果進行二值化,閾值設定為所有超像素點相似性值的平均值,大于平均值的超像素點取為1,小于平均值的取為0,得到二值化圖像。將二值化圖像與輸入圖像相乘,得到餐具檢測圖像。比如:根據f值的大小,餐具對應的種子點t1比較大,如果圖像灰度值范圍是0~1,那么這個t1大概是0.8左右,根據這個閾值設定,重新排序之后f大的那部分就可以認為是餐具。
對餐具檢測圖像進行圖像分割得到最終的待識別的餐具圖像,餐具分割的步驟為:
(1)在二值圖像上用區域增長法確定連通域,并確定每個連通域的最左、最右、最上、最下四個點,并以這四個點確定連通域的外接矩形(矩形邊平行于坐標軸);
(2)記錄每個連通區域外接矩的坐標,并在對應的彩色圖像中提取外接矩內的餐具;
圖像中餐具的識別
圖像中的餐具識別的作用是能夠確定餐具的具體類別,通過已訓練好的svm分類器對該餐具進行測試,輸出該餐具的具體類別標簽。
定義n1個圖像樣本在m1個不同視角下的視覺特征分別記為
選擇利用hsv顏色直方圖和mds[5]特征進行不同視角下的特征提取。
以每個圖像作為圖模型的節點,圖像特征向量之間的距離作為圖模型的連接邊,建立多視角圖模型,其中圖模型連接邊的權值可以通過高斯核函數進行計算:
其中,
假設融合后的新特征是y,比如一個檢測目標餐具的多個視角的特征的集合,對于多視角特征的融合學習,需要考慮到不同視角在特征描述中的重要性。
因此,為了平衡這些近鄰關系在特征融合過程中的作用,為每個視角下的近鄰關系
式(9)能夠進一步轉換成如下矩陣的形式:
由于多視角特征融合算法中包含兩個參數
對優化函數
由于拉普拉斯矩陣
其中,矩陣
(ky-fan定理):如果矩陣m∈rn×n是對稱矩陣,其前k個最小特征值分別λ1≤λ2≤...≤λk
這些特征值對應的特征向量是u=[u1,u2,…,uk]那么就有
而且,z的最優解可以表示成z*=uq,其中q是任意的正交矩陣。
下面用迭代的方法求參數
(1)計算每個視角下的近鄰矩陣
(2)重復步驟(3)和步驟(4)直到收斂;
(3)計算
(4)利用
多視角特征融合方法主要是為了得到獨特性和區分性更強的圖像特征,然后利用訓練集圖像的融合特征訓練一個svm[6]分類模型。
svm是通過尋找最優的線性超平面,使得所有樣本到該超平面有盡可能大的幾何間隔,因為當超平面距離數據點的間隔越大時,分類結果的確信度就越大。為了尋找這樣的超平面函數wtx+b=0,這種最大間隔分類器的目標函數可以定義為:
式(15)中的
對上式求解可得
svm的具體訓練過程為:
(1)取訓練集中的任意兩類物體樣本
(2)求解w和b,其中
(3)再次任意選擇兩類不同的訓練樣本,重復步驟(2)和步驟(3),直到任意兩類訓練樣本都訓練出一個函數f(x);
(4)svm的測試階段:假設樣本的特征向量為y,帶入每個函數f(x)中,確定每個函數對該樣本的分類標簽,通過投票的方法選擇標簽得票最多的類別作為該樣本的最終類別。
實施例
為了驗證本發明的可行性和有效性,在matlab2014a軟件平臺進行了若干實驗測試。圖4是本發明對單個餐具的檢測效果,從結果可以看出本發明能很好的檢測出餐具的具體位置,同時能夠準確的確定餐具的輪廓,并且可以將背景設置為黑色,排除背景對識別過程干擾。
為了進一步驗證本發明的餐具檢測效果,選用多個餐具進行實驗測試,圖5為本發明算法和單視角的餐具檢測效果對比,其中(a)為攝像機拍攝的圖片,(b)為單視角排序第二階段的檢測圖,(c)為本文算法第二階段的檢測圖,(d)為單視角最終的餐具檢測圖,(e)為本發明算法最終的餐具檢測圖。第一組圖中,單視角排序檢測出了3個餐具,本發明算法檢測出了4個;第二組圖中,單視角排序檢測出了3個餐具,本發明算法檢測出了5個餐具;第三組圖中,單視角排序檢測出了3個餐具,本發明算法檢測出了4個餐具;第四組圖中,單視角排序和本文算法都檢測出了四個餐具,但是本發明算法的檢測效果要優于單視角排序;第五組圖中,單視角排序檢測出了3個餐具,本發明算法檢測出了4個餐具。通過對比,本發明算法在復雜環境下的餐具檢測效果要好于單視角排序算法。
為了驗證本發明的餐具分割算法的有效性,進行了大量實驗。,圖3可以看出本發明算法具有良好的分割效果。
為了驗證本發明中特征融合方法在餐具識別中的有效性,在真實數據集中進行了若干實驗,數據集總共有20種不同的餐具,每種餐具呈現不同的角度生成100幅圖像。在表1中,選擇每類圖像中都抽取5、10、…、50幅圖像作為訓練集,其余作為測試集,進行餐具識別實驗。從表1結果可見,隨著訓練樣本的增多,餐具識別的準確率也逐漸提高。當該數據集中的訓練樣本選擇50幅時,單視角中的hsv和mds的識別準確率分別能達到0.974和0.945。而本發明算法在餐具識別過程中具有更強的區分性,識別率能達到0.983,高于單視角下的餐具識別效果。
表1本發明算法和單視角算法在svm分類器中的識別結果
以上所述,僅為本實施例較佳的具體實施方式,但本實施例的保護范圍并不局限于此,任何熟悉本技術領域的技術人員在本實施例揭露的技術范圍內,根據本實施例的技術方案及其發明構思加以等同替換或改變,都應涵蓋在本實施例的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!