一種應用的推薦方法、裝置及計算機可讀介質與流程
本發明涉及通信技術領域,尤其涉及一種應用的推薦方法、裝置及計算機可讀介質。
背景技術:
隨著互聯網信息量的膨脹以及電子商務的迅速發展,信息過載問題卻愈發嚴重。無論是信息消費者還是信息生產者都遇到了很大的挑戰:一方面,對于信息消費者來說,他們越來越難從海量的數據中快速準確的找到對自己有價值的信息;而另一方面,對于信息生產者來說,他們很難讓自己生產的信息在海量數據中脫穎而出,讓信息消費者關注到自己。
如何解決這個問題?推薦系統由此應運而生,它是解決這一類問題的重要工具。推薦系統的任務就是聯系信息消費者和信息生產者,一方面幫助信息消費者發現對自己有用的信息,另一方面幫助信息生產者生產的信息能夠方便快捷的展現在對該信息感興趣的信息消費者面前,從而實現信息消費者和信息生產者兩者的雙贏局面。
slopeone算法兩種常用的實現方式:weightedslopeone和bi-polarslopeone,其缺點在于算法在計算過程沒有考慮到相似度問題。且根據文獻的研究明,相較于傳統的協同過濾算法,當數據變得比較稀疏時,slopeone算法并不算優秀。
此外,由于應用中心的數據量非常大,其包括應用名稱,標簽,應用描述,圖標,下載量,以及用戶的操作歷史包括,下載,評論,評分以及熱度排行等等。slopeone協同過濾是要將所有物品屬性以及用戶操作歷史行為數據進行相應的矩陣運算,在數據不變的情況下,服務器集群要將所有數據計算出來有一定的困難。
技術實現要素:
本發明實施例提供了一種應用的推薦方法、裝置及計算機可讀介質,旨在無論數據稠密或稀疏,都能提高應用推薦的精度,提升用戶體驗。
有鑒于此,本發明實施例第一方面,提供了一種應用的推薦方法,所述應用的推薦方法包括以下步驟:
獲取所有用戶在應用中心的操作歷史數據,并據此生成主矩陣a;
計算所述主矩陣a的近似矩陣ak;
通過所述近似矩陣ak獲取用戶相似度矩陣;
結合所述用戶相似度矩陣和用基于閾值的動態鄰居選擇方法獲取特定用戶的鄰居用戶合集;
根據所述特定用戶在應用中心的操作歷史數據及所述鄰居用戶合集計算所述特定用戶對目標應用的預測評分;
根據所述預測評分生成應用推薦列表。
在一種可能的設計中,所述計算所述主矩陣a的近似矩陣ak包括:
通過奇異值分解所述主矩陣a,得到第一矩陣u、第二矩陣∑、第三矩陣v;
計算維度k,并據此得到第一子矩陣uk、第二子矩陣∑k、第三子矩陣vk;
所述近似矩陣ak為所述第一子矩陣uk、第二子矩陣∑k及所述第三子矩陣vk的倒置矩陣的乘積。
在一種可能的設計中,所述計算維度k包括:若所述主矩陣a是一個n×m的矩陣,則k與n或m中值較小的一個相等。
在一種可能的設計中,所述通過所述近似矩陣ak獲取用戶相似度矩陣包括:
通過以下公式得到用戶相似度矩陣:
其中,simij表示用戶i和用戶j的相似度。
在一種可能的設計中,所述通過所述近似矩陣ak獲取用戶相似度矩陣包括:
利用余弦相似度公式獲取應用之間的相似度;
結合所述應用之間的相似度計算所述用戶相似度矩陣。
在一種可能的設計中,所述根據所述特定用戶在應用中心的操作歷史數據及所述鄰居用戶合集計算所述特定用戶對目標應用的預測評分包括:
定義所述特定用戶的已評分應用集合為ru,所述主矩陣a中對應用itemi的評分為auseri;由以下公式計算集合ru中每個應用itemj和目標應用itemi的均差值disij;
計算預測評分reui,其中numij表示所述鄰居用戶合集中應用itemi和itemj均有評分的用戶數目:
本發明實施例第二方面提供了一種應用的推薦裝置,所述應用的推薦裝置包括:存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的應用的推薦程序,所述應用的推薦程序被所述處理器執行時實現如權利要求1至5中任一項所述的應用的推薦方法的步驟。
在一種可能的設計中,所述根據所述特定用戶在應用中心的操作歷史數據及所述鄰居用戶合集計算所述特定用戶對目標應用的預測評分時,所述應用的推薦程序被所述處理器執行時以實現以下步驟:
定義所述特定用戶的已評分應用集合為ru,所述主矩陣a中對應用itemi的評分為auseri;由以下公式計算集合ru中每個應用itemj和目標應用itemi的均差值disij;
計算預測評分reui,其中numij表示所述鄰居用戶合集中應用itemi和itemj均有評分的用戶數目:
本發明實施例第三方面提供了一種計算機可讀介質,所述計算機可讀介質存儲有應用的推薦程序,所述計算機可讀存儲介質上存儲有應用的推薦程序,所述應用的推薦程序被處理器執行時實現如權利要求1至5中任一項所述的應用的推薦方法的步驟。
在一種可能的設計中,所述根據所述特定用戶在應用中心的操作歷史數據及所述鄰居用戶合集計算所述特定用戶對目標應用的預測評分時,所述應用的推薦程序被所述處理器執行時以實現以下步驟:
定義所述特定用戶的已評分應用集合為ru,所述主矩陣a中對應用itemi的評分為auseri;由以下公式計算集合ru中每個應用itemj和目標應用itemi的均差值disij;
計算預測評分reui,其中numij表示所述鄰居用戶合集中應用itemi和itemj均有評分的用戶數目:
本發明提供的應用的推薦方法、裝置及計算機可讀介質能夠在一定程度上解決大數據矩陣計算量的問題,同時提高推薦的精確度。
附圖說明
圖1為本發明一種應用的推薦方法一個實施例的示意圖;
圖2為本發明一種應用的推薦方法另一個實施例的示意圖;
圖3為本發明一種應用的推薦方法另一個實施例的示意圖;
圖4是本發明實施例的對某一特定用戶預測評分排前十的應用的示意圖;
圖5是本發明實施例的對某一應用的預測得分和實際得分的方差結果示意圖;
本發明目的的實現、功能特點及優點將結合實施例,參照附圖做進一步說明。
具體實施方式
應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
在后續的描述中,使用用于表示元件的諸如“模塊”、“部件”或“單元”的后綴僅為了有利于本發明的說明,其本身沒有特定的意義。因此,“模塊”、“部件”或“單元”可以混合地使用。
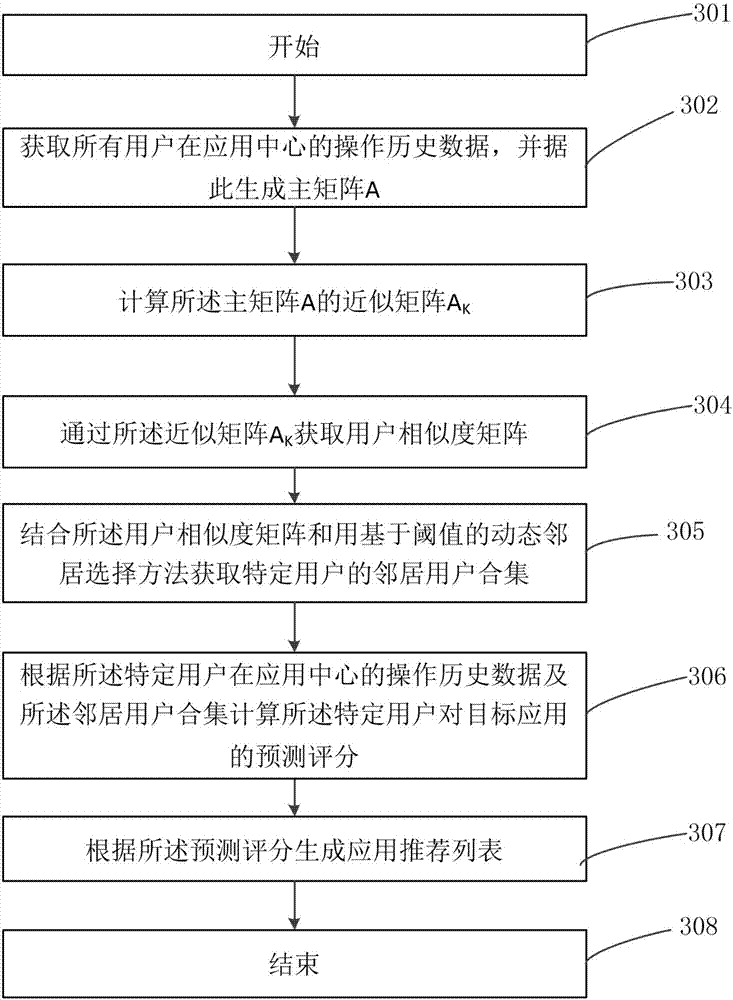
請參閱圖1,圖1為本發明一種應用的推薦方法,所述應用的推薦方法包括以下步驟:
301、開始;
302、獲取所有用戶在應用中心的操作歷史數據,并據此生成主矩陣a;
一般地,一個終端對應一個用戶;當然若應用中心是設有賬號的,也可以是一個終端對應多個用戶;終端需要上傳用戶在應用中心的操作歷史數據;用戶的操作歷史數據包括對應于的下載、評論、評分等;在具體實施時,將應用名稱結合其對應的所有用戶的操作歷史數據生成主矩陣a即可;在本發明的另一實施例中主矩陣還可以加入應用標簽、應用描述、圖標、下載量以及熱度排行等數據信息;
303、計算所述主矩陣a的近似矩陣ak;
304、通過所述近似矩陣ak獲取用戶相似度矩陣;
305、結合所述用戶相似度矩陣和用基于閾值的動態鄰居選擇方法獲取特定用戶的鄰居用戶合集;
306、根據所述特定用戶在應用中心的操作歷史數據及所述鄰居用戶合集計算所述特定用戶對目標應用的預測評分;
307、根據所述預測評分生成應用推薦列表;
308、結束。
可選地,在上述圖1對應的實施例的基礎上,本發明實施例提供的應用的推薦方法另一個可選實施例中,在執行計算所述主矩陣a的近似矩陣ak的步驟時,如圖2所示,具體包括:
401、開始;
402、通過奇異值分解所述主矩陣a,得到第一矩陣u、第二矩陣∑、第三矩陣v;
矩陣的特征值分解可以得到特征值與特征向量,特征向量可以用來描述矩陣的特性,但是它只是對方陣而言的,在現實的世界中,大部分矩陣都不是方陣。而奇異值分解是一個能適用于任意的矩陣的一種分解的方法。
奇異值分解可以用如下公式表達:
a=uσvt
其中,a是一個n*m的矩陣,那么得到的u是一個n*n的方陣(里面的向量是正交的,u里面的向量稱為左奇異向量),σ是一個n*m的矩陣(除了對角線的元素都是0,對角線上的元素稱為奇異值),vt(v的轉置)是一個n*n的矩陣,里面的向量也是正交的,v里面的向量稱為右奇異向量);
在具體計算時,可以先將主矩陣a的進行轉置得到at,將會得到一個方陣,我們用這個方陣求特征值可以得到:
(ata)vi=λvi
這里得到的v,就是我們上面的右奇異向量。此外我們還可以得到:
這里的σ就是上面說的奇異值;u就是左奇異向量;
403、計算維度k,并據此得到第一子矩陣uk、第二子矩陣∑k、第三子矩陣vk;
一般地,若所述主矩陣a是一個n×m的矩陣,則k與n或m中值較小的一個相等;
404、所述近似矩陣ak為所述第一子矩陣uk、第二子矩陣∑k及所述第三子矩陣vk的倒置矩陣的乘積;
對于第二矩陣σ,保留其中k個最大的奇異值,得到一個新的維度為k×k,k×n的第二子矩陣矩陣σk。相應的,通過刪除第一矩陣u以及第三矩陣v相應的行或列,得到維度分別為m×k的第一子矩陣uk和第三子矩陣vk,然后對矩陣a重構;令
405、結束。
通過上述分析可以得到,奇異值可以表示一個給定矩陣與比其秩低的矩陣的接近程度。通過這種矩陣的分解,可以找到矩陣a的一個近似簡化矩陣。
可選地,在上述圖1或圖2對應的任一實施例的基礎上,本發明實施例提供的應用的推薦方法另一個可選實施例中,在通過所述近似矩陣ak獲取用戶相似度矩陣時,包括:
通過以下公式得到用戶相似度矩陣:
其中,simij表示用戶i和用戶j的相似度。
可選地,在上述圖1或圖2對應的任一實施例的基礎上,本發明實施例提供的應用的推薦方法另一個可選實施例中,在通過所述近似矩陣ak獲取用戶相似度矩陣時,如圖3所示,包括:
501、開始;
502、利用余弦相似度公式獲取應用之間的相似度;
更具體地,可以采取以下公式獲取應用之間的相似度:
503、結合所述應用之間的相似度計算所述用戶相似度矩陣;
也就是說,在計算用戶相似度矩陣時,需要考慮到應用之間的相似度;
504、結束。
需要說明的是,若主矩陣a是一個n*m的矩陣,則近似矩陣ak同樣也是一個n*m的矩陣,如果將近似矩陣中的每一行作為對應用戶的特征,利用余弦相似性,可以得到一個m*m的用戶相似度矩陣。
可選地,在上述的任一實施例提供的應用的推薦方法的基礎上,本發明實施例提供的應用的推薦方法另一個可選實施例中,在通過所述近似矩陣ak獲取用戶相似度矩陣時,包括:
定義所述特定用戶的已評分應用集合為ru,所述主矩陣a中對應用itemi的評分為auseri;由以下公式計算集合ru中每個應用itemj和目標應用itemi的均差值disij;
計算預測評分reui,其中numij表示所述鄰居用戶合集中應用itemi和itemj均有評分的用戶數目:
本發明還提供一種應用的推薦裝置,所述應用的推薦裝置包括:存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的應用的推薦程序,所述應用的推薦程序被所述處理器執行時實現本發明任一實施例提供的應用的推薦方法的步驟。
更具體地,所述應用的推薦程序被所述處理器執行以實現以下步驟:
獲取所有用戶在應用中心的操作歷史數據,并據此生成主矩陣a;
一般地,一個終端對應一個用戶;當然若應用中心是設有賬號的,也可以是一個終端對應多個用戶;終端需要上傳用戶在應用中心的操作歷史數據;用戶的操作歷史數據包括對應于的下載、評論、評分等;在具體實施時,將應用名稱結合其對應的所有用戶的操作歷史數據生成主矩陣a即可;在本發明的另一實施例中主矩陣還可以加入應用標簽、應用描述、圖標、下載量以及熱度排行等數據信息;
計算所述主矩陣a的近似矩陣ak;
通過所述近似矩陣ak獲取用戶相似度矩陣;
結合所述用戶相似度矩陣和用基于閾值的動態鄰居選擇方法獲取特定用戶的鄰居用戶合集;
根據所述特定用戶在應用中心的操作歷史數據及所述鄰居用戶合集計算所述特定用戶對目標應用的預測評分;
根據所述預測評分生成應用推薦列表。
在本發明的一個實施例中,當執行計算所述主矩陣a的近似矩陣ak時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
通過奇異值分解所述主矩陣a,得到第一矩陣u、第二矩陣∑、第三矩陣v;
矩陣的特征值分解可以得到特征值與特征向量,特征向量可以用來描述矩陣的特性,但是它只是對方陣而言的,在現實的世界中,大部分矩陣都不是方陣。而奇異值分解是一個能適用于任意的矩陣的一種分解的方法。
奇異值分解可以用如下公式表達:
a=uσvt
其中,a是一個n*m的矩陣,那么得到的u是一個n*n的方陣(里面的向量是正交的,u里面的向量稱為左奇異向量),σ是一個n*m的矩陣(除了對角線的元素都是0,對角線上的元素稱為奇異值),vt(v的轉置)是一個n*n的矩陣,里面的向量也是正交的,v里面的向量稱為右奇異向量);
在具體計算時,可以先將主矩陣a的進行轉置得到at,將會得到一個方陣,我們用這個方陣求特征值可以得到:
(ata)vi=λvi
這里得到的v,就是我們上面的右奇異向量。此外我們還可以得到:
這里的σ就是上面說的奇異值;u就是左奇異向量;
計算維度k,并據此得到第一子矩陣uk、第二子矩陣∑k、第三子矩陣vk;
一般地,若所述主矩陣a是一個n×m的矩陣,則k與n或m中值較小的一個相等;
所述近似矩陣ak為所述第一子矩陣uk、第二子矩陣∑k及所述第三子矩陣vk的倒置矩陣的乘積;
對于第二矩陣σ,保留其中k個最大的奇異值,得到一個新的維度為k×k,k×n的第二子矩陣矩陣σk。相應的,通過刪除第一矩陣u以及第三矩陣v相應的行或列,得到維度分別為m×k的第一子矩陣uk和第三子矩陣vk,然后對矩陣a重構;令
在本發明的一個實施例中,當通過所述近似矩陣ak獲取用戶相似度矩陣時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
通過以下公式得到用戶相似度矩陣:
其中,simij表示用戶i和用戶j的相似度。
在本發明的一個實施例中,當通過所述近似矩陣ak獲取用戶相似度矩陣時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
利用余弦相似度公式獲取應用之間的相似度;
更具體地,可以采取以下公式獲取應用之間的相似度:
結合所述應用之間的相似度計算所述用戶相似度矩陣;
也就是說,在計算用戶相似度矩陣時,需要考慮到應用之間的相似度;
需要說明的是,若主矩陣a是一個n*m的矩陣,則近似矩陣ak同樣也是一個n*m的矩陣,如果將近似矩陣中的每一行作為對應用戶的特征,利用余弦相似性,可以得到一個m*m的用戶相似度矩陣。
在本發明的一個實施例中,當通過所述近似矩陣ak獲取用戶相似度矩陣時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
定義所述特定用戶的已評分應用集合為ru,所述主矩陣a中對應用itemi的評分為auseri;由以下公式計算集合ru中每個應用itemj和目標應用itemi的均差值disij;
計算預測評分reui,其中numij表示所述鄰居用戶合集中應用itemi和itemj均有評分的用戶數目:
本發明還提供一種計算機可讀介質,其特征在于,所述計算機可讀存儲介質上存儲有應用的推薦程序,所述應用的推薦程序被處理器執行時實現本發明任一實施例提供的應用的推薦方法的步驟。
更具體地,所述應用的推薦程序被所述處理器執行以實現以下步驟:
獲取所有用戶在應用中心的操作歷史數據,并據此生成主矩陣a;
一般地,一個終端對應一個用戶;當然若應用中心是設有賬號的,也可以是一個終端對應多個用戶;終端需要上傳用戶在應用中心的操作歷史數據;用戶的操作歷史數據包括對應于的下載、評論、評分等;在具體實施時,將應用名稱結合其對應的所有用戶的操作歷史數據生成主矩陣a即可;在本發明的另一實施例中主矩陣還可以加入應用標簽、應用描述、圖標、下載量以及熱度排行等數據信息;
計算所述主矩陣a的近似矩陣ak;
通過所述近似矩陣ak獲取用戶相似度矩陣;
結合所述用戶相似度矩陣和用基于閾值的動態鄰居選擇方法獲取特定用戶的鄰居用戶合集;
根據所述特定用戶在應用中心的操作歷史數據及所述鄰居用戶合集計算所述特定用戶對目標應用的預測評分;
根據所述預測評分生成應用推薦列表。
在本發明的一個實施例中,當執行計算所述主矩陣a的近似矩陣ak時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
通過奇異值分解所述主矩陣a,得到第一矩陣u、第二矩陣∑、第三矩陣v;
矩陣的特征值分解可以得到特征值與特征向量,特征向量可以用來描述矩陣的特性,但是它只是對方陣而言的,在現實的世界中,大部分矩陣都不是方陣。而奇異值分解是一個能適用于任意的矩陣的一種分解的方法。
奇異值分解可以用如下公式表達:
a=uσvt
其中,a是一個n*m的矩陣,那么得到的u是一個n*n的方陣(里面的向量是正交的,u里面的向量稱為左奇異向量),σ是一個n*m的矩陣(除了對角線的元素都是0,對角線上的元素稱為奇異值),vt(v的轉置)是一個n*n的矩陣,里面的向量也是正交的,v里面的向量稱為右奇異向量);
在具體計算時,可以先將主矩陣a的進行轉置得到at,將會得到一個方陣,我們用這個方陣求特征值可以得到:
(ata)vi=λvi
這里得到的v,就是我們上面的右奇異向量。此外我們還可以得到:
這里的σ就是上面說的奇異值;u就是左奇異向量;
計算維度k,并據此得到第一子矩陣uk、第二子矩陣∑k、第三子矩陣vk;
一般地,若所述主矩陣a是一個n×m的矩陣,則k與n或m中值較小的一個相等;
所述近似矩陣ak為所述第一子矩陣uk、第二子矩陣∑k及所述第三子矩陣vk的倒置矩陣的乘積;
對于第二矩陣σ,保留其中k個最大的奇異值,得到一個新的維度為k×k,k×n的第二子矩陣矩陣σk。相應的,通過刪除第一矩陣u以及第三矩陣v相應的行或列,得到維度分別為m×k的第一子矩陣uk和第三子矩陣vk,然后對矩陣a重構;令
在本發明的一個實施例中,當通過所述近似矩陣ak獲取用戶相似度矩陣時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
通過以下公式得到用戶相似度矩陣:
其中,simij表示用戶i和用戶j的相似度。
在本發明的一個實施例中,當通過所述近似矩陣ak獲取用戶相似度矩陣時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
利用余弦相似度公式獲取應用之間的相似度;
更具體地,可以采取以下公式獲取應用之間的相似度:
結合所述應用之間的相似度計算所述用戶相似度矩陣;
也就是說,在計算用戶相似度矩陣時,需要考慮到應用之間的相似度;
需要說明的是,若主矩陣a是一個n*m的矩陣,則近似矩陣ak同樣也是一個n*m的矩陣,如果將近似矩陣中的每一行作為對應用戶的特征,利用余弦相似性,可以得到一個m*m的用戶相似度矩陣。
在本發明的一個實施例中,當通過所述近似矩陣ak獲取用戶相似度矩陣時,所述應用的推薦程序被所述處理器執行以實現以下步驟:
定義所述特定用戶的已評分應用集合為ru,所述主矩陣a中對應用itemi的評分為auseri;由以下公式計算集合ru中每個應用itemj和目標應用itemi的均差值disij;
計算預測評分reui,其中numij表示所述鄰居用戶合集中應用itemi和itemj均有評分的用戶數目:
需要說明的是,本發明中用戶在應用中心的操作歷史數據可以以評分的形式進行表現,用戶在應用中心的操作歷史數據包括用戶停留該應用的時間、一天內開啟的次數、對該應用進行的操作等。
下面結合具體的實例,進一步說明本發明:
在具體實施時,根據上述任一實施例提供的步驟構建模型,導入用戶、用戶在應用中心的操作歷史數據;得出各應用的評分,并將排名在前的應用推薦給用戶。請參照圖4,圖4是對某一特定用戶預測評分排前十的應用;更具體地,第一列為用戶編碼,第二列為應用軟件編碼,第三列為預測用戶得分;本實施例中,用戶編碼為65722,其對應的預測評分排前十的應用即為第二列編碼對應的應用。
請參照圖5,本發明將用戶已安裝的其中一個應用進行屏蔽后,實施本發明提供的技術方案,將屏蔽的應用的預測得分與根據用戶歷史操作數據得出的實際得分進行方差的計算,本實施例中得出的方差為4.10e-6,趨近于零;可見,本發明得出的預測得分具有較高的準確率。
本發明實施例提供的應用的推薦方法、裝置及計算機可讀介質,通過奇異值分解對用戶評分矩陣進行降維,使得其在計算應用中心推薦超大數據量時能夠占用較少的服務器資源,能夠在一定程度上解決大數據矩陣計算量的問題,縮短計算時間,同時提高了應用推薦精度。
需要說明的是,在本文中,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者裝置不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者裝置所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括該要素的過程、方法、物品或者裝置中還存在另外的相同要素。
上述本發明實施例序號僅僅為了描述,不代表實施例的優劣。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到上述實施例方法可借助軟件加必需的通用硬件平臺的方式來實現,當然也可以通過硬件,但很多情況下前者是更佳的實施方式。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質(如rom/ram、磁碟、光盤)中,包括若干指令用以使得一臺終端(可以是手機,計算機,服務器,空調器,或者網絡設備等)執行本發明各個實施例所述的方法。
上面結合附圖對本發明的實施例進行了描述,但是本發明并不局限于上述的具體實施方式,上述的具體實施方式僅僅是示意性的,而不是限制性的,本領域的普通技術人員在本發明的啟示下,在不脫離本發明宗旨和權利要求所保護的范圍情況下,還可做出很多形式,這些均屬于本發明的保護之內。
- 還沒有人留言評論。精彩留言會獲得點贊!