人工智能客服機器人的問題解答方法及系統與流程
本發明涉及人工智能領域,特別涉及一種人工智能客服機器人的問題解答方法及系統。
背景技術:
目前,最廣泛的客服聊天機器人,使用了傳統nlp(naturelanguageprocessing,自然語言處理)技術,對問題進行關鍵字提取,然后進行聚類,并在答案集合中進行匹配。在匹配的結果中,進行短文本相似度計算,針對每個候選答案給出一個分值,排序后取前n個返回給用戶。
由于語言表達的多樣性、語義理解的困惑度,特別是中文的歧義等現象非常常見,導致了nlp技術的解答準確率比較低,而且由于自然語言處理中的上下文復雜性,這種技術的解答準確率是受到嚴重限制的。同時這種技術的語料庫的維護成本相當高,需要人工給出很多的標注,對詞的聚類也需要投入大量的人工,因此在企業實際應用中,在企業和用戶兩方面都沒有得到很好的反饋。
技術實現要素:
本發明要解決的技術問題是為了克服現有技術中客服聊天機器人使用的nlp技術解答準確率低,語料庫的維護成本高,導致用戶體驗度低的缺陷,提供一種人工智能客服機器人的問題解答方法及系統。
本發明是通過下述技術方案來解決上述技術問題:
一種人工智能客服機器人的問題解答方法,其特點在于,所述問題解答方法包括以下步驟:
s1、接收整段問題信息,對所述整段問題信息進行多卷積,并且提取若干個主要特征信息;
s2、對若干個主要特征信息進行下采樣處理,并且從若干個主要特征信息提取若干個目標特征信息;
s3、根據若干個目標特征信息并基于人工智能分類算法輸出問題類型信息;
s4、根據所述問題類型信息查詢對應類型的語料庫;
s5、從所述整段問題信息中提取問題序列文本信息,從對應類型的語料庫中的若干個解答信息中分別提取若干個解答序列文本信息,將所述問題序列文本信息分別與若干個解答序列文本信息進行匹配,并且生成相似度列表,所述相似度列表用于表征所述問題序列文本信息分別與若干個解答序列文本信息之間的相似度;
s6、輸出所述相似度列表中相似度最高的解答序列文本信息所對應的解答信息。
較佳地,在步驟s1中,基于cnn(convolutionalneuralnetwork,卷積神經網絡)模型對所述整段文本信息進行多卷積,并且提取若干個主要特征信息;
在步驟s3中,所述人工智能分類算法為softmax算法(機器學習算法)。
較佳地,在步驟s5中,基于bi-lstm模型(雙向長短時記憶模型)及cnn模型,從所述整段問題信息中提取問題序列文本信息,從對應類型的語料庫中的若干個解答信息中分別提取若干個解答序列文本信息。
較佳地,在步驟s5中,采用cosine(余弦)算法將所述問題序列文本信息分別與若干個解答序列文本信息進行匹配。
較佳地,在步驟s5中,生成所述相似度列表之后,對所述相似度列表中的若干個解答序列文本信息以相似度從高到低的順序進行排列,并且選取前五個解答序列文本信息;
在步驟s6中,輸出前五個解答序列文本信息中相似度最高的解答序列文本信息所對應的解答信息,還分別輸出其余四個解答序列文本信息所對應的解答信息對應的問題信息。
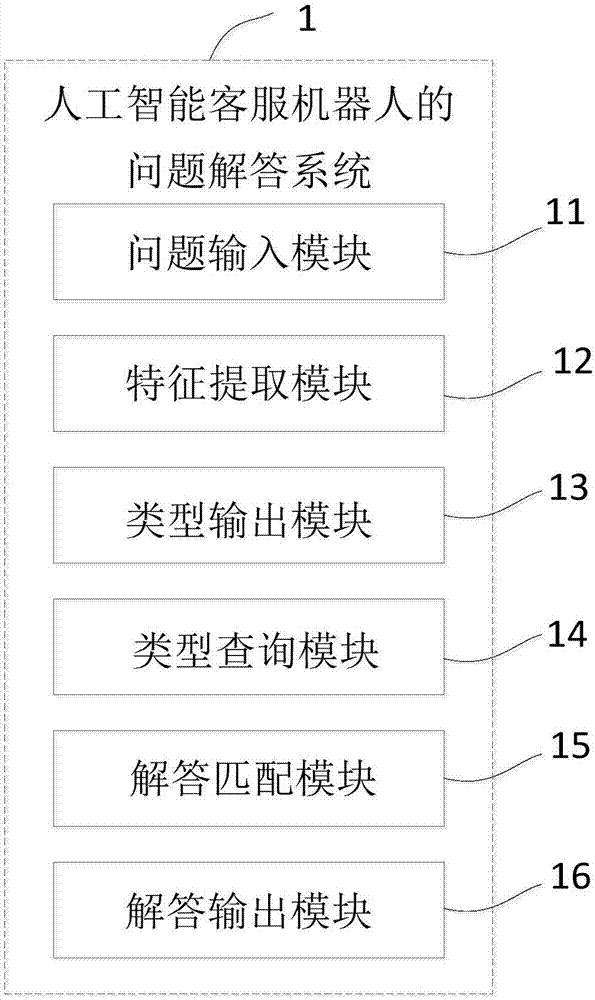
一種人工智能客服機器人的問題解答系統,其特點在于,所述問題解答系統包括問題輸入模塊、特征提取模塊、類型輸出模塊、類型查詢模塊、解答匹配模塊及解答輸出模塊;
所述問題輸入模塊用于接收整段問題信息,并且將所述整段問題信息發送至所述特征提取模塊;
所述特征提取模塊用于對所述整段問題信息進行多卷積,并且提取若干個主要特征信息,所述特征提取模塊還用于對若干個主要特征信息進行下采樣處理,并且從若干個主要特征信息提取若干個目標特征信息,所述特征提取模塊還用于將若干個目標特征信息發送至所述類型輸出模塊;
所述類型輸出模塊用于根據若干個目標特征信息并基于人工智能分類算法輸出問題類型信息;
所述類型查詢模塊用于根據所述問題類型信息查詢對應類型的語料庫;
所述解答匹配模塊用于從所述整段問題信息中提取問題序列文本信息,從對應類型的語料庫中的若干個解答信息中分別提取若干個解答序列文本信息,將所述問題序列文本信息分別與若干個解答序列文本信息進行匹配,并且生成相似度列表,所述相似度列表用于表征所述問題序列文本信息分別與若干個解答序列文本信息之間的相似度;
所述解答輸出模塊用于輸出所述相似度列表中相似度最高的解答序列文本信息所對應的解答信息。
較佳地,所述特征提取模塊用于基于cnn模型對所述整段文本信息進行多卷積,并且提取若干個主要特征信息;
所述人工智能分類算法為softmax算法。
較佳地,所述解答匹配模塊用于基于bi-lstm模型及cnn模型,從所述整段問題信息中提取問題序列文本信息,從對應類型的語料庫中的若干個解答信息中分別提取若干個解答序列文本信息。
較佳地,所述解答匹配模塊用于采用cosine算法將所述問題序列文本信息分別與若干個解答序列文本信息進行匹配。
較佳地,所述解答匹配模塊用于生成所述相似度列表之后,對所述相似度列表中的若干個解答序列文本信息以相似度從高到低的順序進行排列,并且選取前五個解答序列文本信息;
所述解答輸出模塊用于輸出前五個解答序列文本信息中相似度最高的解答序列文本信息所對應的解答信息,還分別輸出其余四個解答序列文本信息所對應的解答信息對應的問題信息。
在符合本領域常識的基礎上,上述各優選條件,可任意組合,即得本發明各較佳實例。
本發明的積極進步效果在于:
本發明提供的人工智能客服機器人的問題解答方法及系統使用深度學習模型,極大地提高了人工智能客服機器人的解答準確率,降低了語料庫的維護成本,從而較好地滿足在企業實際應用中的各項要求,提高了用戶體驗度。
附圖說明
圖1為本發明較佳實施例的人工智能客服機器人的問題解答方法的流程圖。
圖2為本發明較佳實施例的人工智能客服機器人的問題解答系統的結構示意圖。
圖3為本發明較佳實施例中的分布式容器化部署的示意圖。
具體實施方式
下面通過實施例的方式進一步說明本發明,但并不因此將本發明限制在所述的實施例范圍之中。
如圖1所示,本實施例提供的人工智能客服機器人的問題解答方法包括以下步驟:
步驟101、接收整段問題信息,對整段問題信息進行多卷積,并且提取若干個主要特征信息。
在本實施例中,所述問題解答方法采用兩級的深度學習模型,第一級trigger模型(深度學習的常用模型)負責對輸入問題進行分類,從而為第二級的模型選擇提供依據。第二級的qa模型(深度學習的常用模型)負責對該分類下的問題進行答案匹配并輸出結果。
在本步驟中,人工智能客服機器人接收用戶輸入的問題后,即整段問題信息,并且準備進行問題的分類工作。
在本步驟中,基于cnn模型對所述整段文本信息進行多卷積,并且提取若干個主要特征信息。
步驟102、對若干個主要特征信息進行下采樣處理,并且從若干個主要特征信息提取若干個目標特征信息。
在本步驟中,對若干個主要特征信息進行下采樣處理,從而進一步提取若干個目標特征信息。在本實施例中,并不具體限定主要特征信息及目標特征信息的提取數量,均可根據實際情況及實際算法來提取。
步驟103、根據若干個目標特征信息并基于softmax算法輸出問題類型信息。
步驟104、根據所述問題類型信息查詢對應類型的語料庫。
在本步驟中,根據輸出的問題類型信息來查詢對應類型的語料庫,例如,當用戶輸入旅游相關問題,問題類型信息可以為“簽證類”、“自由行類”、“團隊游類”等,接下來查詢并匹配相應類型的簽證語料庫、自由行語料庫、團隊游語料庫等,當然本實施例中并不具體限定語料庫的類型,均可根據實際情況來自行設定。
步驟105、從整段問題信息中提取問題序列文本信息,從對應類型的語料庫中的若干個解答信息中分別提取若干個解答序列文本信息,將問題序列文本信息分別與若干個解答序列文本信息進行匹配,并且生成相似度列表。
在本步驟中,基于bi-lstm模型及cnn模型,從所述整段問題信息中提取問題序列文本信息,從對應類型的語料庫中的若干個解答信息中分別提取若干個解答序列文本信息。
在本步驟中,采用cosine算法將所述問題序列文本信息分別與若干個解答序列文本信息進行匹配。
在本步驟中,所述相似度列表用于表征所述問題序列文本信息分別與若干個解答序列文本信息之間的相似度。
在本實施例中,采用了qa模型的混合模型,即bi-lstm模型和cnn模型的混合模型,充分利用了bi-lstm模型對序列文本的解析能力,同時通過雙向計算,大大提高了模型的穩定性和多特征綜合提取。在級聯cnn模型的基礎上,摒棄了softmax層,選擇了cosine算法對向量進行比較,從而輸出相似度。
步驟106、對相似度列表中的若干個解答序列文本信息以相似度從高到低的順序進行排列,并且選取前五個解答序列文本信息。
在本步驟中,雖然僅示出選取前五個解答序列文本信息的方案,但是并不具體所選取的解答序列文本信息的數量,也可根據實際情況進行或多或少的調整。
步驟107、輸出前五個解答序列文本信息中相似度最高的解答序列文本信息所對應的解答信息,還分別輸出其余四個解答序列文本信息所對應的解答信息對應的問題信息。
在本實施例中,在人工智能客服機器人訓練階段中,首先需要對語料庫進行技術整理,整理出相應的問答分類,并歸入各分類的對應語料庫。送入模型進行訓練。切出其中的10%作為測試數據集,并在訓練完成后進行測試驗證。驗證通過后,即可進行實際提問,并得到相應的回答分類。
如圖3所示,在人工智能客服機器人實施階段中,由于深度模型依賴的實施環境和運行環境都較復雜,本實施例中采用了分布式容器化部署,結果證明其對于系統監控、loadbalance(負載均衡)及穩定性都提供了很好的保障,mesos為開源分布式資源管理框架,是分布式系統的內核,docker為虛擬機容器。
在本實施例中,所述問題解答方法應用人工智能的深度學習模型,可以在以下幾個方面獲得顯著的效果:
1、由于深度學習模型的模型層數較深,對于語言的解析更加全面且多層次;
2、多深度模型混合,可以從更多方面根據各自特性綜合對同一問答對進行分析,大幅度提升了準確率;
3、由于深度學習模型的本質屬于機器學習,所以伴隨著語料庫樣本的不斷增加,模型準確率和召回率可以不斷提升,并達到和保持在一個高可用的基準上;
4、由于深度學習模型的特性是端到端的學習,因此不需要對語料進行關鍵字提取、聚類、關鍵字匹配等步驟,大大減少了該環節的人工成本和技術成本;
5、應用深度學習模型后,對于多國語言的訓練和模型輸出也會變得更通用和低成本,而這一點在傳統nlp技術上是無法實現或者代價很大。
如圖2所示,本實施例還提供一種人工智能客服機器人的問題解答系統1,包括問題輸入模塊11、特征提取模塊12、類型輸出模塊13、類型查詢模塊14、解答匹配模塊15及解答輸出模塊16。
在本實施例中,人工智能客服機器人的問題解答系統1采用兩級的深度學習模型,第一級trigger模型(深度學習的常用模型)負責對輸入問題進行分類,從而為第二級的模型選擇提供依據。第二級的qa模型(深度學習的常用模型)負責對該分類下的問題進行答案匹配并輸出結果。
問題輸入模塊11用于接收整段問題信息,并且將所述整段問題信息發送至特征提取模塊12。在本實施例中,人工智能客服機器人接收用戶輸入的問題后,即整段問題信息,并且準備進行問題的分類工作。
特征提取模塊12用于基于cnn模型對所述整段文本信息進行多卷積,并且提取若干個主要特征信息,特征提取模塊12還用于對若干個主要特征信息進行下采樣處理,并且從若干個主要特征信息提取若干個目標特征信息,特征提取模塊12還用于將若干個目標特征信息發送至類型輸出模塊13。在本實施例中,并不具體限定主要特征信息及目標特征信息的提取數量,均可根據實際情況及實際算法來提取。
類型輸出模塊13用于根據若干個目標特征信息并基于softmax算法輸出問題類型信息。
類型查詢模塊14用于根據所述問題類型信息查詢對應類型的語料庫。在本實施例中,根據輸出的問題類型信息來查詢對應類型的語料庫,例如,當用戶輸入旅游相關問題,問題類型信息可以為“簽證類”、“自由行類”、“團隊游類”等,接下來查詢并匹配相應類型的簽證語料庫、自由行語料庫、團隊游語料庫等,當然本實施例中并不具體限定語料庫的類型,均可根據實際情況來自行設定。
解答匹配模塊15用于基于bi-lstm模型及cnn模型,從所述整段問題信息中提取問題序列文本信息,從對應類型的語料庫中的若干個解答信息中分別提取若干個解答序列文本信息,采用cosine算法將所述問題序列文本信息分別與若干個解答序列文本信息進行匹配,并且生成相似度列表,所述相似度列表用于表征所述問題序列文本信息分別與若干個解答序列文本信息之間的相似度。
在本實施例中,采用了qa模型的混合模型,即bi-lstm模型和cnn模型的混合模型,充分利用了bi-lstm模型對序列文本的解析能力,同時通過雙向計算,大大提高了模型的穩定性和多特征綜合提取。在級聯cnn模型的基礎上,摒棄了softmax層,選擇了cosine算法對向量進行比較,從而輸出相似度。
解答匹配模塊15還用于生成所述相似度列表之后,對所述相似度列表中的若干個解答序列文本信息以相似度從高到低的順序進行排列,并且選取前五個解答序列文本信息。在本實施例中,雖然僅示出選取前五個解答序列文本信息的方案,但是并不具體所選取的解答序列文本信息的數量,也可根據實際情況進行或多或少的調整。
解答輸出模塊16用于輸出前五個解答序列文本信息中相似度最高的解答序列文本信息所對應的解答信息,還分別輸出其余四個解答序列文本信息所對應的解答信息對應的問題信息。
在本實施例中,在人工智能客服機器人訓練階段中,首先需要對語料庫進行技術整理,整理出相應的問答分類,并歸入各分類的對應語料庫。送入模型進行訓練。切出其中的10%作為測試數據集,并在訓練完成后進行測試驗證。驗證通過后,即可進行實際提問,并得到相應的回答分類。
如圖3所示,在人工智能客服機器人實施階段中,由于深度模型依賴的實施環境和運行環境都較復雜,本實施例中采用了分布式容器化部署,結果證明其對于系統監控、loadbalance(負載均衡)及穩定性都提供了很好的保障,mesos為開源分布式資源管理框架,是分布式系統的內核,docker為虛擬機容器。
在本實施例中,人工智能客服機器人的問題解答系統1應用人工智能的深度學習模型,可以在以下幾個方面獲得顯著的效果:
1、由于深度學習模型的模型層數較深,對于語言的解析更加全面且多層次;
2、多深度模型混合,可以從更多方面根據各自特性綜合對同一問答對進行分析,大幅度提升了準確率;
3、由于深度學習模型的本質屬于機器學習,所以伴隨著語料庫樣本的不斷增加,模型準確率和召回率可以不斷提升,并達到和保持在一個高可用的基準上;
4、由于深度學習模型的特性是端到端的學習,因此不需要對語料進行關鍵字提取、聚類、關鍵字匹配等步驟,大大減少了該環節的人工成本和技術成本;
5、應用深度學習模型后,對于多國語言的訓練和模型輸出也會變得更通用和低成本,而這一點在傳統nlp技術上是無法實現或者代價很大。
本實施例提供的人工智能客服機器人的問題解答方法及系統使用深度學習模型,極大地提高了人工智能客服機器人的解答準確率,降低了語料庫的維護成本,從而較好地滿足在企業實際應用中的各項要求,提高了用戶體驗度。
在現有nlp技術下,已有問答的解答準確率僅為72%,而理想情況下的深度模型的解答準確率為100%;現有nlp技術在開放問題句式下的解答準確率為43%,而理想情況下的深度模型在語料庫僅數千條的情況下,開放問題句式的解答準確率可達到70%以上,并且伴隨語料庫的增加還可以獲得較大的提升。
雖然以上描述了本發明的具體實施方式,但是本領域的技術人員應當理解,這僅是舉例說明,本發明的保護范圍是由所附權利要求書限定的。本領域的技術人員在不背離本發明的原理和實質的前提下,可以對這些實施方式做出多種變更或修改,但這些變更和修改均落入本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!