視網膜病變程度等級檢測系統及方法與流程
本發明涉及計算機技術領域,尤其涉及一種視網膜病變程度等級檢測系統及方法。
背景技術:
根據對發達國家超過9300萬勞動力人口的調查,糖尿病性視網膜病變是導致眼睛失明的一個首要因素,目前,針對糖尿病性視網膜病變的識別通常需要對眼部圖像進行特征提取(例如,眼部血管結構,視神經盤,視網膜中心凹槽等特征的提取),特征提取的算法復雜運行性能差,同時,難以對患者的視網膜病變程度進行精細化識別,識別精度難以達到要求。
技術實現要素:
本發明的主要目的在于提供一種視網膜病變程度等級檢測系統及方法,旨在簡單有效地對患者的視網膜病變程度進行精細化識別。
為實現上述目的,本發明提供的一種視網膜病變程度等級檢測系統,所述視網膜病變程度等級檢測系統包括:
識別模塊,用于在收到待識別的視網膜病變圖片后,對收到的視網膜病變圖片利用預先確定的識別模型進行識別,并輸出識別結果;其中,所述預先確定的識別模型為預先通過對標注有不同視網膜病變程度等級的預設數量樣本圖片進行訓練得到的卷積神經網絡模型;
確定模塊,用于根據預先確定的識別結果與視網膜病變程度等級的映射關系,確定輸出的識別結果對應的視網膜病變程度等級。
優選地,所述預先確定的識別模型的訓練過程如下:
a、為各個預設的視網膜病變程度等級設定對應的預設數量的樣本圖片,為每個樣本圖片標注對應的視網膜病變程度等級;
b、將各個樣本圖片進行圖片預處理以獲得待模型訓練的訓練圖片;
c、將所有訓練圖片分為第一比例的訓練集和第二比例的驗證集;
d、利用所述訓練集訓練所述預先確定的識別模型;
e、利用所述驗證集驗證訓練的識別模型的準確率,若準確率大于或者等于預設準確率,則訓練結束,或者,若準確率小于預設準確率,則增加各個視網膜病變程度等級對應的樣本圖片數量并重新執行上述步驟b、c、d、e。
優選地,所述步驟b包括:
將各個樣本圖片的較短邊長縮放到第一預設大小以獲得對應的第一圖片,在各個第一圖片上隨機裁剪出一個第二預設大小的第二圖片;
根據各個預先確定的預設類型參數對應的標準參數值,將各個第二圖片的各個預先確定的預設類型參數值調整為對應的標準參數值,以獲得對應的第三圖片;
對各個第三圖片進行預設方向的翻轉操作,及按照預設的扭曲角度對各個第三圖片進行扭曲操作,以獲得各個第三圖片對應的第四圖片,將各個第四圖片作為待模型訓練的訓練圖片。
優選地,所述深度卷積神經網絡模型包括輸入層和多個網絡層,所述網絡層包括卷積層、池化層、全連接層及分類器層,各個所述網絡層對應的激活函數f(x)為:
f(x)=max(α*x,0)
其中,α為預設的泄漏率,x表示所述深度卷積神經網絡模型中神經元的一個數值輸入。
優選地,各個所述網絡層對應的交叉熵h(p,q)為:
h(p,q)=h(p)+dkl(p||q)
其中,p,q為兩個概率分布,h(p)為概率分布p的期望,h(p)=-σx∈xp(x)logp(x),x為概率分布p的樣本空間x中任意一個樣本,p(x)表示樣本x被選取的概率;dkl(p||q)的表達式為
優選地,所述預先確定的識別模型的打分函數
其中,
優選地,各個所述網絡層對應的交叉熵損失函數l(x,
其中,x表示模型的輸入,
wi+1=wi+δwi+1
其中,δwi+1表示在i+1時刻權值矩陣的更新增量,α為勢能項,β為權值衰減系數,γ為模型的學習率,wi表示在i時刻權值矩陣狀態值,di表示第i批輸入,
優選地,所述預先確定的識別模型包括至少一個全連接層,所述預先確定的識別模型中的各權重的初始值從預設的權重范圍進行隨機采樣確定,所述全連接層的連接權重被丟棄的概率設置為第一預設值,所述交叉熵損失函數中的權值衰減系數設置為第二預設值,所述交叉商損失函數中的勢能項設置為第三預設值。
此外,為實現上述目的,本發明還提供一種視網膜病變程度等級的檢測方法,所述方法包括以下步驟:
在收到待識別的視網膜病變圖片后,對收到的視網膜病變圖片利用預先確定的識別模型進行識別,并輸出識別結果;其中,所述預先確定的識別模型為預先通過對標注有不同視網膜病變程度等級的預設數量樣本圖片進行訓練得到的卷積神經網絡模型;
根據預先確定的識別結果與視網膜病變程度等級的映射關系,確定輸出的識別結果對應的視網膜病變程度等級。
優選地,所述預先確定的識別模型的訓練過程如下:
a、為各個預設的視網膜病變程度等級設定對應的預設數量的樣本圖片,為每個樣本圖片標注對應的視網膜病變程度等級;
b、將各個樣本圖片進行圖片預處理以獲得待模型訓練的訓練圖片;
c、將所有訓練圖片分為第一比例的訓練集和第二比例的驗證集;
d、利用所述訓練集訓練所述預先確定的識別模型;
e、利用所述驗證集驗證訓練的識別模型的準確率,若準確率大于或者等于預設準確率,則訓練結束,或者,若準確率小于預設準確率,則增加各個視網膜病變程度等級對應的樣本圖片數量并重新執行上述步驟b、c、d、e。
本發明提出的視網膜病變程度等級檢測系統及方法,通過基于標注有不同視網膜病變程度等級的預設數量樣本圖片進行訓練得到的深度卷積神經網絡模型來對收到的視網膜病變圖片進行識別,并根據識別結果確定對應的視網膜病變程度等級。由于只需根據預先訓練得到的深度卷積神經網絡模型對收到的視網膜病變圖片進行識別,無需對眼部圖像進行復雜的特征提取運算,更加簡單,且能根據識別結果確定對應的不同視網膜病變程度等級,能有效地對患者的視網膜病變程度進行精細化識別。
附圖說明
圖1為本發明視網膜病變程度等級的檢測方法一實施例的流程示意圖;
圖2為本發明視網膜病變程度等級檢測系統10較佳實施例的運行環境示意圖;
圖3為本發明視網膜病變程度等級檢測系統一實施例的功能模塊示意圖。
本發明目的的實現、功能特點及優點將結合實施例,參照附圖做進一步說明。
具體實施方式
為了使本發明所要解決的技術問題、技術方案及有益效果更加清楚、明白,以下結合附圖和實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
本發明提供一種視網膜病變程度等級的檢測方法。
參照圖1,圖1為本發明視網膜病變程度等級的檢測方法一實施例的流程示意圖。
在一實施例中,該視網膜病變程度等級的檢測方法包括:
步驟s10、在收到待識別的視網膜病變圖片后,對收到的視網膜病變圖片利用預先確定的識別模型進行識別,并輸出識別結果;其中,所述預先確定的識別模型為預先通過對標注有不同視網膜病變程度等級的預設數量樣本圖片進行訓練得到的深度卷積神經網絡模型。
本實施例中,視網膜病變程度等級檢測系統接收用戶發出的包含待識別的視網膜病變圖片的視網膜病變程度等級檢測請求,例如,接收用戶通過手機、平板電腦、自助終端設備等終端發送的視網膜病變程度等級檢測請求,如接收用戶在手機、平板電腦、自助終端設備等終端中預先安裝的客戶端上發送來的視網膜病變程度等級檢測請求,或接收用戶在手機、平板電腦、自助終端設備等終端中的瀏覽器系統上發送來的視網膜病變程度等級檢測請求。
視網膜病變程度等級檢測系統在收到用戶發出的視網膜病變程度等級檢測請求后,利用預先訓練好的識別模型對收到的待識別的視網膜病變圖片進行識別,識別出收到的待識別的視網膜病變圖片在識別模型中的識別結果。該識別模型可預先通過對大量標注有不同視網膜病變程度等級的預設數量樣本圖片進行識別來不斷進行訓練、學習、驗證、優化等,以將其訓練成能準確識別出不同視網膜病變程度等級對應的標注的模型。例如,該識別模型可采用深度卷積神經網絡模型(convolutionalneuralnetwork,cnn)模型等。
步驟s20、根據預先確定的識別結果與視網膜病變程度等級的映射關系,確定輸出的識別結果對應的視網膜病變程度等級。
在利用預先訓練好的深度卷積神經網絡模型對收到的視網膜病變圖片進行識別獲取到識別結果后,可根據預先確定的識別結果與視網膜病變程度等級的映射關系,確定輸出的識別結果對應的視網膜病變程度等級,確定的視網膜病變程度等級即為收到的視網膜病變圖片所對應的視網膜病變程度等級。例如,在一種實施方式中,所述識別結果包括第一識別結果(例如,標注為“0”)、第二識別結果(例如,標注為“1”)、第三識別結果(例如,標注為“2”)、第四識別結果(例如,標注為“3”)及第五識別結果(例如,標注為“4”),所述視網膜病變程度等級包括第一等級、第二等級、第三等級、第四等級及第五等級。可預先確定不同識別結果與視網膜病變程度等級的映射關系,如所述第一識別結果對應第一等級,第二識別結果對應第二等級,第三識別結果對應第三等級,第四識別結果對應第四等級,第五識別結果對應第五等級。例如,具體地,第一等級可以對應正常和輕度的非增殖性糖尿病視網膜病變,該第一等級對應的視網膜病變圖片表現為僅有個別血管瘤,硬性滲出,視網膜出血等。第二等級可以對應無臨床意義黃斑水腫的非增殖性糖尿病視網膜病變,該第二等級對應的視網膜病變圖片表現有微血管瘤,硬性滲出,視網膜出血,袢狀或串珠狀靜脈。第三等級可以對應有臨床意義的黃斑水腫(csme)的非增殖性糖尿病視網膜病,該第三等級對應的視網膜病變圖片表現黃斑區及其附近有視網膜增厚,并有微血管瘤,軟性滲出,視網膜出血。第四等級可以對應非高危險期的增生性視網膜病,該第四等級對應的視網膜病變圖片表現為視乳頭外區有新生血管形成,其他區域內視網膜微血管形成的增殖型改變。第五等級可以對應高危險期的增生性視網膜病,該第五等級對應的視網膜病變圖片表現為視乳頭區有新生血管形成,玻璃體或視網膜前出血。
這樣,在利用預先訓練好的識別模型對收到的視網膜病變圖片進行識別獲取到識別結果后,即可根據獲取到的不同識別結果確定對應的不同視網膜病變程度等級,從而實現對多種細化的視網膜病變程度等級的準確識別。
本實施例通過基于標注有不同視網膜病變程度等級的預設數量樣本圖片進行訓練得到的深度卷積神經網絡模型來對收到的視網膜病變圖片進行識別,并根據識別結果確定對應的視網膜病變程度等級。由于只需根據預先訓練得到的深度卷積神經網絡模型對收到的視網膜病變圖片進行識別,無需對眼部圖像進行復雜的特征提取運算,更加簡單,且能根據識別結果確定對應的不同視網膜病變程度等級,能有效地對患者的視網膜病變程度進行精細化識別。
進一步地,在其他實施例中,所述預先確定的識別模型的訓練過程如下:
a、為各個預設的視網膜病變程度等級(如第一等級、第二等級、第三等級、第四等級及第五等級,或輕微、輕度、中度、重度等)準備對應的預設數量的樣本圖片,為每個樣本圖片標注對應的視網膜病變程度等級;
b、將各個樣本圖片進行圖片預處理以獲得待模型訓練的訓練圖片。通過對各個樣本圖片進行圖片預處理如縮放、裁剪、翻轉及/或扭曲等操作后才進行模型訓練,以有效提高模型訓練的真實性及準確率。例如在一種實施方式中,對各個樣本圖片進行圖片預處理可以包括:
將各個樣本圖片的較短邊長縮放到第一預設大小(例如,640像素)以獲得對應的第一圖片,在各個第一圖片上隨機裁剪出一個第二預設大小(例如,256*256像素)的第二圖片;
根據各個預先確定的預設類型參數(例如,顏色、亮度及/或對比度等)對應的標準參數值(例如,顏色對應的標準參數值為a1,亮度對應的標準參數值為a2,對比度對應的標準參數值為a3),將各個第二圖片的各個預先確定的預設類型參數值調整為對應的標準參數值,獲得對應的第三圖片,以消除作為醫學圖片的樣本圖片在拍攝時外界條件導致的圖片不清晰,提高模型訓練的有效性;例如,將各個第二圖片的亮度值調整為標準參數值a2,將各個第二圖片的對比度值調整為標準參數值a3;
對各個第三圖片進行預設方向(例如,水平和垂直方向)的翻轉,及按照預設的扭曲角度(例如,30度)對各個第三圖片進行扭曲操作,獲得各個第三圖片對應的第四圖片,各個第四圖片即為對應的樣本圖片的訓練圖片。其中,翻轉和扭曲操作的作用是模擬實際業務場景下各種形式的圖片,通過這些翻轉和扭曲操作可以增大數據集的規模,從而提高模型訓練的真實性和實用性。
c、將所有訓練圖片分為第一比例(例如,50%)的訓練集、第二比例(例如,25%)的驗證集;
d、利用所述訓練集訓練所述預先確定的識別模型;
e、利用所述驗證集驗證訓練的識別模型的準確率,若準確率大于或者等于預設準確率,則訓練結束,或者,若準確率小于預設準確率,則增加各個視網膜病變程度等級對應的樣本圖片數量并重新執行上述步驟b、c、d、e,直至訓練的識別模型的準確率大于或者等于預設準確率。
進一步地,在其他實施例中,所述預先確定的識別模型即深度卷積神經網絡模型包括輸入層和多個網絡層,所述網絡層包括卷積層、池化層、全連接層及分類器層,可選的,深度卷積神經網絡模型還可以包括具有隨機丟棄某些連接權重機制的網絡層(即dropout層),該網絡層的作用是提升模型的識別精度。
在一種具體的實施方式中,所述深度卷積神經網絡模型由1個輸入層,11個卷積層,5個池化層,1個具有隨機丟棄某些連接權重機制的網絡層(即dropout層),1個全連接層,1個分類器層構成。該深度卷積神經網絡模型的詳細結構如下表1所示:
表1
其中:layername表示網絡層的名稱,input表示網絡的數據輸入層,conv表示模型的卷積層,conv1表示模型的第1個卷積層,maxpool表示模型的最大值池化層,maxpool1表示第一個基于最大值池化層,dropout表示具有隨機丟棄某些連接權重機制的網絡層,avgpool5表示第5個池化層但采用取均值方式進行池化,fc表示模型中的全連接層,fc1表示第1個全連接層,softmax表示softmax分類器層;batchsize表示當前層的輸入圖像數目;kernelsize表示當前層卷積核的尺度(例如,kernelsize可以等于3,表示卷積核的尺度為3x3);stridesize表示卷積核的移動步長,即做完一次卷積之后移動到下一個卷積位置的距離;outputsize表示網絡層輸出特征映射的尺寸。需要說明的是,本實施例中池化層的池化方式包括但不限于meanpooling(均值采樣)、maxpooling(最大值采樣)、overlapping(重疊采樣)、l2pooling(均方采樣)、localcontrastnormalization(歸一化采樣)、stochasticpooling(隨即采樣)、def-pooling(形變約束采樣)等等。
進一步地,在其他實施例中,為了提高模型的識別精度,各個所述網絡層(例如,卷積層、池化層、具有隨機丟棄某些連接權重機制的網絡層、全連接層及分類器層等)對應的激活函數f(x)為:
f(x)=max(α*x,0)
其中,α為泄漏率,x表示該深度卷積神經網絡模型中神經元的一個數值輸入。在本實施例的一個優選實施方式中,將α設定為0.5。經過相同測試數據集的對比測試,相較于其他現有的激活函數,通過本實施例的激活函數f(x),該深度卷積神經網絡模型的識別準確率大約有3%的提升。
進一步地,在其他實施例中,為了提高模型的識別精度,各個所述網絡層(例如,卷積層、池化層、具有隨機丟棄某些連接權重機制的網絡層、全連接層及分類器層等)對應的交叉熵h(p,q)為:
h(p,q)=h(p)+dkl(p||q)
其中,p,q為兩個概率分布,h(p)為概率分布p的期望,h(p)=-∑x∈xp(x)logp(x),x為概率分布p的樣本空間x中任意一個樣本,p(x)表示樣本x被選取的概率;dkl(p||q)的表達式為
進一步地,為了保證模型訓練的效率和準確性,各個所述網絡層對應的交叉熵損失函數l(x,
其中,x表示模型的輸入,
wi+1=wi+δwi+1
其中,δwi+1表示在i+1時刻權值矩陣的更新增量,α為勢能項,β為權值衰減系數,γ為模型的學習率,wi表示在i時刻權值矩陣狀態值,di表示第i批輸入,
本實施例中,交叉熵可在神經網絡(機器學習)中作為損失函數,例如,p表示真實標記的分布,q則為訓練后的模型的預測標記分布,交叉熵損失函數可以衡量p與q的相似性,以保證模型訓練的準確性。而且,交叉熵作為損失函數在梯度下降時能避免均方誤差損失函數學習速率降低的問題,因此,能保證模型訓練的效率。
進一步地,在其他實施例中,所述深度卷積神經網絡模型包括至少一個全連接層,所述預先確定的識別模型中的各權重的初始值從預設的權重范圍(例如,(0,1)權重范圍)進行隨機采樣確定,所述全連接層的連接權重被丟棄(dropout)的概率設置為第一預設值(例如,0.5),所述交叉商損失函數中的權值衰減系數設置為第二預設值(例如,0.0005),所述交叉商損失函數中的勢能項設置為第三預設值(例如,0.9)。
進一步地,在其他實施例中,所述預先確定的識別模型的打分函數
其中,
本實施例中通過打分函數
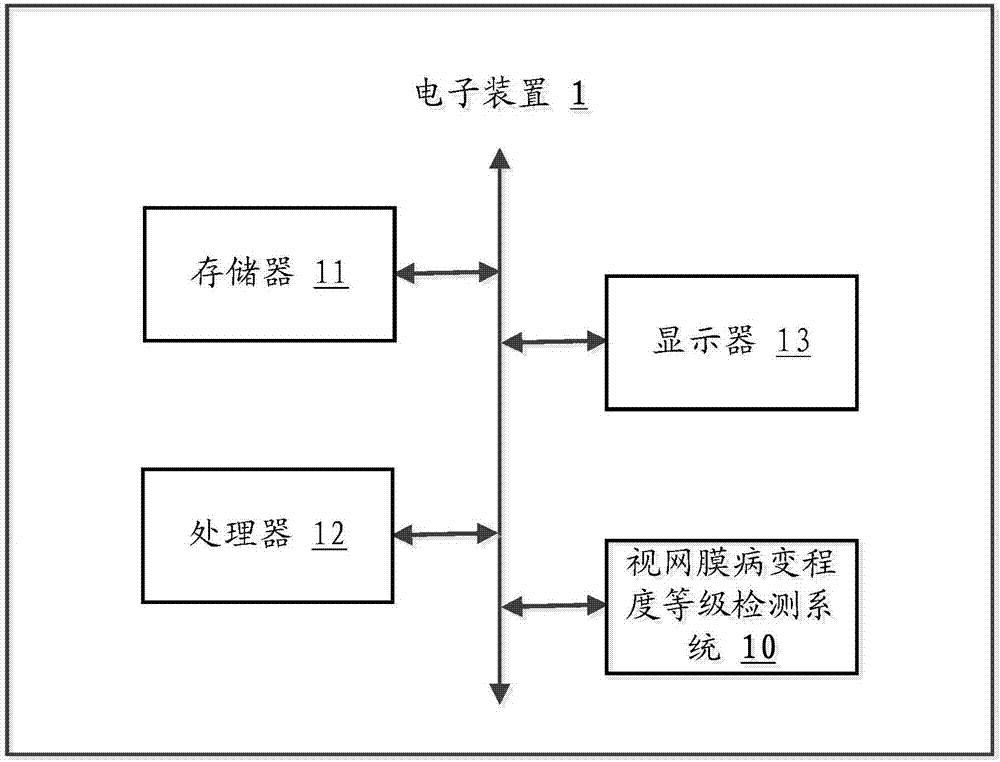
本發明進一步提供一種視網膜病變程度等級檢測系統。請參閱圖2,是本發明視網膜病變程度等級檢測系統10較佳實施例的運行環境示意圖。
在本實施例中,所述的視網膜病變程度等級檢測系統10安裝并運行于電子裝置1中。該電子裝置1可包括,但不僅限于,存儲器11、處理器12及顯示器13。圖2僅示出了具有組件11-13的電子裝置1,但是應理解的是,并不要求實施所有示出的組件,可以替代的實施更多或者更少的組件。
所述存儲器11在一些實施例中可以是所述電子裝置1的內部存儲單元,例如該電子裝置1的硬盤或內存。所述存儲器11在另一些實施例中也可以是所述電子裝置1的外部存儲設備,例如所述電子裝置1上配備的插接式硬盤,智能存儲卡(smartmediacard,smc),安全數字(securedigital,sd)卡,閃存卡(flashcard)等。進一步地,所述存儲器11還可以既包括所述電子裝置1的內部存儲單元也包括外部存儲設備。所述存儲器11用于存儲安裝于所述電子裝置1的應用軟件及各類數據,例如所述視網膜病變程度等級檢測系統10的程序代碼等。所述存儲器11還可以用于暫時地存儲已經輸出或者將要輸出的數據。
所述處理器12在一些實施例中可以是一中央處理器(centralprocessingunit,cpu),微處理器或其他數據處理芯片,用于運行所述存儲器11中存儲的程序代碼或處理數據,例如執行所述視網膜病變程度等級檢測系統10等。
所述顯示器13在一些實施例中可以是led顯示器、液晶顯示器、觸控式液晶顯示器以及oled(organiclight-emittingdiode,有機發光二極管)觸摸器等。所述顯示器13用于顯示在所述電子裝置1中處理的信息以及用于顯示可視化的用戶界面,例如應用菜單界面、應用圖標界面等。所述電子裝置1的部件11-13通過系統總線相互通信。
請參閱圖3,是本發明視網膜病變程度等級檢測系統10較佳實施例的功能模塊圖。在本實施例中,所述的視網膜病變程度等級檢測系統10可以被分割成一個或多個模塊,所述一個或者多個模塊被存儲于所述存儲器11中,并由一個或多個處理器(本實施例為所述處理器12)所執行,以完成本發明。例如,在圖3中,所述的視網膜病變程度等級檢測系統10可以被分割成識別模塊01、確定模塊02。本發明所稱的模塊是指能夠完成特定功能的一系列計算機程序指令段,比程序更適合于描述所述視網膜病變程度等級檢測系統10在所述電子裝置1中的執行過程。以下描述將具體介紹所述識別模塊01、確定模塊02的功能。
參照圖3,圖3為本發明視網膜病變程度等級檢測系統一實施例的功能模塊示意圖。
在一實施例中,該視網膜病變程度等級檢測系統包括:
識別模塊01,用于在收到待識別的視網膜病變圖片后,對收到的視網膜病變圖片利用預先確定的識別模型進行識別,并輸出識別結果;其中,所述預先確定的識別模型為預先通過對標注有不同視網膜病變程度等級的預設數量樣本圖片進行訓練得到的卷積神經網絡模型。
本實施例中,視網膜病變程度等級檢測系統接收用戶發出的包含待識別的視網膜病變圖片的視網膜病變程度等級檢測請求,例如,接收用戶通過手機、平板電腦、自助終端設備等終端發送的視網膜病變程度等級檢測請求,如接收用戶在手機、平板電腦、自助終端設備等終端中預先安裝的客戶端上發送來的視網膜病變程度等級檢測請求,或接收用戶在手機、平板電腦、自助終端設備等終端中的瀏覽器系統上發送來的視網膜病變程度等級檢測請求。
視網膜病變程度等級檢測系統在收到用戶發出的視網膜病變程度等級檢測請求后,利用預先訓練好的識別模型對收到的待識別的視網膜病變圖片進行識別,識別出收到的待識別的視網膜病變圖片在識別模型中的識別結果。該識別模型可預先通過對大量標注有不同視網膜病變程度等級的預設數量樣本圖片進行識別來不斷進行訓練、學習、驗證、優化等,以將其訓練成能準確識別出不同視網膜病變程度等級對應的標注的模型。例如,該識別模型可采用深度卷積神經網絡模型(convolutionalneuralnetwork,cnn)模型等。
確定模塊02,用于根據預先確定的識別結果與視網膜病變程度等級的映射關系,確定輸出的識別結果對應的視網膜病變程度等級。
在利用預先訓練好的深度卷積神經網絡模型對收到的視網膜病變圖片進行識別獲取到識別結果后,可根據預先確定的識別結果與視網膜病變程度等級的映射關系,確定輸出的識別結果對應的視網膜病變程度等級,確定的視網膜病變程度等級即為收到的視網膜病變圖片所對應的視網膜病變程度等級。例如,在一種實施方式中,所述識別結果包括第一識別結果(例如,標注為“0”)、第二識別結果(例如,標注為“1”)、第三識別結果(例如,標注為“2”)、第四識別結果(例如,標注為“3”)、及第五識別結果(例如,標注為“4”),所述視網膜病變程度等級包括第一等級、第二等級、第三等級、第四等級及第五等級。可預先確定不同識別結果與視網膜病變程度等級的映射關系,如所述第一識別結果對應第一等級,第二識別結果對應第二等級,第三識別結果對應第三等級,第四識別結果對應第四等級,第五識別結果對應第五等級。例如,具體地,第一等級可以對應正常和輕度的非增殖性糖尿病視網膜病變,該第一等級對應的視網膜病變圖片表現為僅有個別血管瘤,硬性滲出,視網膜出血等。第二等級可以對應無臨床意義黃斑水腫的非增殖性糖尿病視網膜病變,該第二等級對應的視網膜病變圖片表現有微血管瘤,硬性滲出,視網膜出血,袢狀或串珠狀靜脈。第三等級可以對應有臨床意義的黃斑水腫(csme)的非增殖性糖尿病視網膜病,該第三等級對應的視網膜病變圖片表現黃斑區及其附近有視網膜增厚,并有微血管瘤,軟性滲出,視網膜出血。第四等級可以對應非高危險期的增生性視網膜病,該第四等級對應的視網膜病變圖片表現為視乳頭外區有新生血管形成,其他區域內視網膜微血管形成的增殖型改變。第五等級可以對應高危險期的增生性視網膜病,該第五等級對應的視網膜病變圖片表現為視乳頭區有新生血管形成,玻璃體或視網膜前出血。
這樣,在利用預先訓練好的識別模型對收到的視網膜病變圖片進行識別獲取到識別結果后,即可根據獲取到的不同識別結果確定對應的不同視網膜病變程度等級,從而實現對多種細化的視網膜病變程度等級的準確識別。
本實施例通過基于標注有不同視網膜病變程度等級的預設數量樣本圖片進行訓練得到的深度卷積神經網絡模型來對收到的視網膜病變圖片進行識別,并根據識別結果確定對應的視網膜病變程度等級。由于只需根據預先訓練得到的深度卷積神經網絡模型對收到的視網膜病變圖片進行識別,無需對眼部圖像進行復雜的特征提取運算,更加簡單,且能根據識別結果確定對應的不同視網膜病變程度等級,能有效地對患者的視網膜病變程度進行精細化識別。
進一步地,在其他實施例中,所述預先確定的識別模型的訓練過程如下:
a、為各個預設的視網膜病變程度等級(如第一等級、第二等級、第三等級、第四等級及第五等級,或輕微、輕度、中度、重度等)準備對應的預設數量的樣本圖片,為每個樣本圖片標注對應的視網膜病變程度等級;
b、將各個樣本圖片進行圖片預處理以獲得待模型訓練的訓練圖片。通過對各個樣本圖片進行圖片預處理如縮放、裁剪、翻轉及/或扭曲等操作后才進行模型訓練,以有效提高模型訓練的真實性及準確率。例如在一種實施方式中,對各個樣本圖片進行圖片預處理可以包括:
將各個樣本圖片的較短邊長縮放到第一預設大小(例如,640像素)以獲得對應的第一圖片,在各個第一圖片上隨機裁剪出一個第二預設大小(例如,256*256像素)的第二圖片;
根據各個預先確定的預設類型參數(例如,顏色、亮度及/或對比度等)對應的標準參數值(例如,顏色對應的標準參數值為a1,亮度對應的標準參數值為a2,對比度對應的標準參數值為a3),將各個第二圖片的各個預先確定的預設類型參數值調整為對應的標準參數值,獲得對應的第三圖片,以消除作為醫學圖片的樣本圖片在拍攝時外界條件導致的圖片不清晰,提高模型訓練的有效性;例如,將各個第二圖片的亮度值調整為標準參數值a2,將各個第二圖片的對比度值調整為標準參數值a3;
對各個第三圖片進行預設方向(例如,水平和垂直方向)的翻轉,及按照預設的扭曲角度(例如,30度)對各個第三圖片進行扭曲操作,獲得各個第三圖片對應的第四圖片,各個第四圖片即為對應的樣本圖片的訓練圖片。其中,翻轉和扭曲操作的作用是模擬實際業務場景下各種形式的圖片,通過這些翻轉和扭曲操作可以增大數據集的規模,從而提高模型訓練的真實性和實用性。
c、將所有訓練圖片分為第一比例(例如,50%)的訓練集、第二比例(例如,25%)的驗證集;
d、利用所述訓練集訓練所述預先確定的識別模型;
e、利用所述驗證集驗證訓練的識別模型的準確率,若準確率大于或者等于預設準確率,則訓練結束,或者,若準確率小于預設準確率,則增加各個視網膜病變程度等級對應的樣本圖片數量并重新執行上述步驟b、c、d、e,直至訓練的識別模型的準確率大于或者等于預設準確率。
進一步地,在其他實施例中,所述預先確定的識別模型即深度卷積神經網絡模型包括輸入層和多個網絡層,所述網絡層包括卷積層、池化層、全連接層及分類器層,可選的,深度卷積神經網絡模型還可以包括具有隨機丟棄某些連接權重機制的網絡層(即dropout層),該網絡層的作用是提升模型的識別精度。
在一種具體的實施方式中,所述深度卷積神經網絡模型由1個輸入層,11個卷積層,5個池化層,1個具有隨機丟棄某些連接權重機制的網絡層(即dropout層),1個全連接層,1個分類器層構成。該深度卷積神經網絡模型的詳細結構如下表1所示:
表1
其中:layername表示網絡層的名稱,input表示網絡的數據輸入層,conv表示模型的卷積層,conv1表示模型的第1個卷積層,maxpool表示模型的最大值池化層,maxpool1表示第一個基于最大值池化層,dropout表示具有隨機丟棄某些連接權重機制的網絡層,avgpool5表示第5個池化層但采用取均值方式進行池化,fc表示模型中的全連接層,fc1表示第1個全連接層,softmax表示softmax分類器層;batchsize表示當前層的輸入圖像數目;kernelsize表示當前層卷積核的尺度(例如,kernelsize可以等于3,表示卷積核的尺度為3x3);stridesize表示卷積核的移動步長,即做完一次卷積之后移動到下一個卷積位置的距離;outputsize表示網絡層輸出特征映射的尺寸。需要說明的是,本實施例中池化層的池化方式包括但不限于meanpooling(均值采樣)、maxpooling(最大值采樣)、overlapping(重疊采樣)、l2pooling(均方采樣)、localcontrastnormalization(歸一化采樣)、stochasticpooling(隨即采樣)、def-pooling(形變約束采樣)等等。
進一步地,在其他實施例中,為了提高模型的識別精度,各個所述網絡層(例如,卷積層、池化層、具有隨機丟棄某些連接權重機制的網絡層、全連接層及分類器層等)對應的激活函數f(x)為:
f(x)=max(α*x,0)
其中,α為泄漏率,x表示該深度卷積神經網絡模型中神經元的一個數值輸入。在本實施例的一個優選實施方式中,將α設定為0.5。經過相同測試數據集的對比測試,相較于其他現有的激活函數,通過本實施例的激活函數f(x),該深度卷積神經網絡模型的識別準確率大約有3%的提升。
進一步地,在其他實施例中,為了提高模型的識別精度,各個所述網絡層(例如,卷積層、池化層、具有隨機丟棄某些連接權重機制的網絡層、全連接層及分類器層等)對應的交叉熵h(p,q)為:
h(p,q)=h(p)+dkl(p||q)
其中,p,q為兩個概率分布,h(p)為概率分布p的期望,h(p)=-∑x∈xp(x)logp(x),x為概率分布p的樣本空間x中任意一個樣本,p(x)表示樣本x被選取的概率;dkl(p||q)的表達式為
進一步地,為了保證模型訓練的效率和準確性,各個所述網絡層對應的交叉熵損失函數l(x,
其中,x表示模型的輸入,
wi+1=wi+δwi+1
其中,δwi+1表示在i+1時刻權值矩陣的更新增量,α為勢能項,β為權值衰減系數,γ為模型的學習率,wi表示在i時刻權值矩陣狀態值,di表示第i批輸入,
本實施例中,交叉熵可在神經網絡(機器學習)中作為損失函數,例如,p表示真實標記的分布,q則為訓練后的模型的預測標記分布,交叉熵損失函數可以衡量p與q的相似性,以保證模型訓練的準確性。而且,交叉熵作為損失函數在梯度下降時能避免均方誤差損失函數學習速率降低的問題,因此,能保證模型訓練的效率。
進一步地,在其他實施例中,所述深度卷積神經網絡模型包括至少一個全連接層,所述預先確定的識別模型中的各權重的初始值從預設的權重范圍(例如,(0,1)權重范圍)進行隨機采樣確定,所述全連接層的連接權重被丟棄(dropout)的概率設置為第一預設值(例如,0.5),所述交叉商損失函數中的權值衰減系數設置為第二預設值(例如,0.0005),所述交叉商損失函數中的勢能項設置為第三預設值(例如,0.9)。
進一步地,在其他實施例中,所述預先確定的識別模型的打分函數
其中,
本實施例中通過打分函數
需要說明的是,在本文中,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者裝置不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者裝置所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括該要素的過程、方法、物品或者裝置中還存在另外的相同要素。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到上述實施例方法可借助軟件加必需的通用硬件平臺的方式來實現,當然也可以通過硬件來實現,但很多情況下前者是更佳的實施方式。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質(如rom/ram、磁碟、光盤)中,包括若干指令用以使得一臺終端設備(可以是手機,計算機,服務器,空調器,或者網絡設備等)執行本發明各個實施例所述的方法。
以上參照附圖說明了本發明的優選實施例,并非因此局限本發明的權利范圍。上述本發明實施例序號僅僅為了描述,不代表實施例的優劣。另外,雖然在流程圖中示出了邏輯順序,但是在某些情況下,可以以不同于此處的順序執行所示出或描述的步驟。
本領域技術人員不脫離本發明的范圍和實質,可以有多種變型方案實現本發明,比如作為一個實施例的特征可用于另一實施例而得到又一實施例。凡在運用本發明的技術構思之內所作的任何修改、等同替換和改進,均應在本發明的權利范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!