一種基于XCS?LBP特征以及級聯AKSVM的行人檢測算法的制作方法
本發明涉及一種基于單目視覺的前方行人檢測算法,該方法采用混合特征提取和級聯分類器相結合的方法對視頻圖像中的行人進行檢測,屬于圖像處理和機器視覺領域,可應用于準確高效的檢測出前方行人,可以實時性的提醒駕駛員避讓行人,減少交通事故的發生,是先進駕駛輔助系統中重要的一環。
背景技術:
道路交通事故給人民生命財產和國民經濟帶來了巨大損失,而交通事故很大程度上由于駕駛員精力不集中造成的,車輛擦碰行人的事故屢見不鮮。由此可見,及時檢測出前方行人并做出預警作為高級駕駛輔助系統中的一部分具有非常重要的意義。
加強道路安全是當今智能車領域需要著重關注的問題,先進駕駛輔助系統(adas)是加強道路安全的芽接技術。為了更方便的駕駛車輛,人們開發了先進駕駛輔助安全系統(adas)。行人檢測的提出旨在通過車輛前置攝像頭捕捉到的視頻分析車輛前方有沒有行人,如果檢測到行人就給司機發出危險信號,提醒司機減速或剎車,避免交通事故的發生。
最近,用于行人檢測的技術涌現出來,比如使用紅外攝像機,激光傳感器,單眼攝像機,或者是激光傳感器和單眼攝像機配合使用等等。有許多因素制約著機器視覺在行人檢測方向的發展,使得該技術具有挑戰性。比如行人的服裝外表具有多樣性,行人姿勢和所處位置的多樣性,可變光照條件,非結構化的環境以及行人身體部位的遮擋等問題,利用機器感知技術進行行人檢測是一項極具挑戰性的任務。而且,在先進駕駛輔助系統(adas)中,使用的是在路途中行駛的攝像機,攝像機拍攝到的背景在運動,周圍的環境是動態變化的,利用機器視覺進行行人檢測,提高檢測精度減少誤檢率是一種很大的難題。
另外,對行人檢測來說,檢測速度是另一個重要的指標,如果一個算法應用于行人檢測中時需要太多計算時間,無論這種算法的精確度有多高,都不能應用于實際的行人檢測系統中。因此,在行人檢測領域,不僅要考慮檢測精度,還要考慮計算時間。
大多數行人檢測方法包含兩部分:特征提取和分類。對于特征提取,許多已經發表的研究是基于外觀特征的,包括haar-like特征,局部二進制模式(lbp),gabor濾波器以及hog等特征。特別是hog特征提取應用非常廣泛,hog特征算法最早是有法國的dalal等提出的一種解決人體目標檢測的圖像描述子,引起學術界廣泛的關注。對于分類器,一種線性支持向量機(linsvm)是最流行的分類器之一,大量的研究工作都是基于linsvm進行行人檢測的。然而,線性支持向量機(linsvm)的檢測性能可能不適合一些非線性分類環境,比如行人具有多特征性,應該從多個角度進行檢測。
本發明克服了以前檢測算法的不足,采用xcs-lbp方法和自適應背景混合模型進行前景檢測,然后應用hog特征算法得到最準確的特征集,這樣比一般的特征提取方法得到更準確的特征集;然后,利用獲得的特征對分類器進行訓練,本文采用快速有效的級聯aksvm,并引入了著名的遺傳算法,通過遺傳算法決定最佳的aksvm級聯序列。這樣既保證了精確度,又提高了行人檢測的快速性。
技術實現要素:
本發明的目的是克服現有技術的上述不足,提出了一種基于xcs-lbp以及級聯aksvm的行人檢測算法,該方法能夠準確有效地檢測出不同運動狀態以及不同環境下的行人,綜合考慮了檢測精度以及檢測速率。為此,本發明采用如下的技術方案:
1.從訓練視頻幀中獲取檢測圖像并進行灰度化;
2.xcs-lbp特征處理;
3.hog特征提取;
4.用遺傳算法得到最優aksvm級聯序列并對其進行訓練;
5.獲取測試數據集并重復1-3步;
6.利用第4步得到的分類器對第5步得到的數據進行測試。
本發明具有如下技術特點:
1.實時性好。本發明利用機器視覺和遺傳算法來確定最佳aksvm級聯序列,可以大大提高行人檢測的快速性,減少檢測時間,檢測速率影響整個高級駕駛輔助系統的性能。
2.準確性高。本發明在檢測過程中,采用了自適應背景混合模型以及xcs-lbp方法和hog特征提取相結合,大大提高檢測精度,減少誤檢率。
3.能夠對不同天氣和不同場景下的行人進行檢測,減少遮擋問題帶來的困擾。
附圖說明
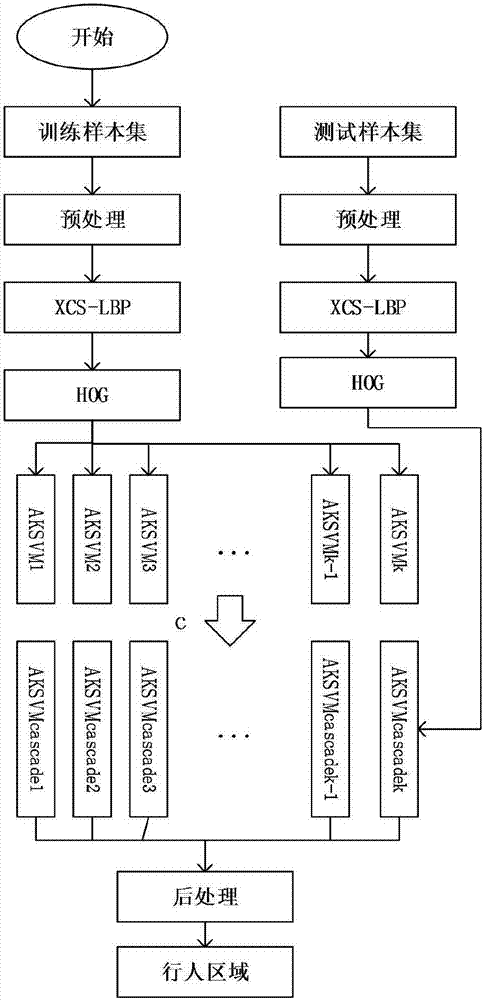
圖1:本發明總體方案流程圖。
圖2:實驗用到的inria正負樣本數據集
圖3:實驗用到的caltech正負樣本數據集
圖4:xcs-lbp原理圖
圖5:分類器的級聯形式
圖6:aksvm的染色體編碼
具體實施方式
本發明的流程圖如圖1所示,對于行人檢測問題,訓練樣本和測試樣本一般是尺寸歸一化后的灰度或彩色行人/非行人圖片,或者是視頻文件,如果是視頻文件,則需要對視頻文件進行幀處理得到圖像文件。這里的樣本類別就是行人/非行人的標記集合。然后對訓練樣本集進行預處理,一般是為了實現去除干擾,提高圖像質量等目的,但是這一步并不是必須的。然后對樣本進行特征提取,本發明中首先提取xcs-lbp特征,然后,進一步得到hog特征,最后使用提取的特征訓練分類器。這里我使用級聯aksvm分類器,并使用遺傳算法實現aksvm分類器的級聯序列。檢測過程就是利用訓練好的分類器對提取的檢測圖像特征進行分類判別,然后進行后續處理過程,后續處理主要是對檢測所得的信息進行融合。
1.圖像樣本集獲取
本實驗采用的數據是比較經典的inria數據集,部分數據如圖2所示和caltech數據集,部分數據如圖3所示,這兩個經常使用,研究者比較認可的數據集。
(1)inria數據集
inriaperson數據集是dalal等人在完美解決mit數據集的基礎上提出的。inriaperson數據集集中體現出人體的非剛體性、行人外觀多樣性、復雜背景、光照變化、尺度變化、遮擋等諸多行人檢測的研究難點。由于hog特征的巨大影響力,inriaperson數據集成為目前使用最為廣泛靜態圖像行人數據集。所以我選擇該數據集。
inriaperson數據集除了區分訓練集與測試集外,每一部分都涵蓋了負樣本圖像。其中,訓練集由614張正樣本和1218張不含行人的負樣本圖像組成,有2416個行人目標;測試集由288張正樣本和453張負樣本圖像組成,含行人589人。而且,inria附帶給出了所有正樣本的標注文件,這些標注對訓練和測試極為關鍵。
(2)caltech數據集
caltechperson數據集是目前規模較大的行人數據庫,采用車載攝像頭拍攝,約10個小時左右,視頻的分辨率為640×480,30幀/秒。標注了約250000幀(約137分鐘),有35000個矩形框,2300個行人,另外還對矩形框之間的時間對應關系及其遮擋的情況進行標注。數據集分為set00-set10,其中set00-set05是訓練數據集,set06-set10是測試數據集。
2.預處理
如果數據集是視頻文件,則將其轉換為圖像文件對檢測器的實現來說更有利。預處理過程是對圖像做簡單加工處理,使得檢測結果更好。預處理過程不是必須經歷的過程。包括三部分內容,a.幀變換;b.圖像灰度化;c.前景檢測。
a.幀變換
針對先進輔助駕駛系統,最直接的數據來源是從車輛的前置攝像頭獲取的視頻文件,因此,需要將從攝像頭獲取的視頻首先轉換成幀,視頻幀中的每個實例都是從該視頻中獲取。第一幀被轉換為灰度圖像,并將這第一幀轉換后的圖像設置為背景參考圖像。我們可以定義要讀的幀的間隔,這個成像設備按照特定的速率或頻率顯示連續的圖像就稱為幀。
b.圖像灰度化
為了從rgb圖像中得到灰度圖像,我們很容易通過添加每個像素的rgb值得到像素的亮度或者強度。可以通過求平均的方法。
grayscale=(r+g+b)/3(1)
根據rgb顏色的波長貢獻,圖像就形成了。紅色比藍色和綠色的波長更大,因此,我們必須通過加權的方法減少紅色對圖像的貢獻率,增加綠色貢獻率。
newgrayscale=(0.3*r)+(0.59*g)+(0.11*b)(2)
c.前景檢測
前景檢測是通過使用第一幀作為參考背景圖像并且自適應變換參考圖像實現的。
background=(1-α)*currentframe+(α*background)(3)
differenceimage=currentframe-background(4)
根據這一規則,他只會處理圖像中包含相關信息的部分。因此,前景檢測使得問題數據集不會再做進一步處理。根據閾值的設置,差分圖像就轉換成了二值圖像。它取代了原始圖像中的所有像素,將像素值大于閾值的用“1”代替(也就是二值圖像中的白色),其他所有像素用“0”代替。利用otsu法計算全局圖像閾值。通過這種方法選擇的閾值將黑白像素區分開。相機和背景沒有相對運動,因此,這種方法適合前景檢測。
3.xcs-lbp紋理特征提取
xcs-lbp算子是在lbp算子和cs-lbp算子的基礎上提出的,集合了兩個算子的優勢。lbp算子應用比較廣泛,屬于區域算子。lbp算子被廣泛用在特征提取上的優勢有很多,它具有多尺度特征、旋轉不變性、計算簡單等優點,最重要的一點就是它對光照變化及陰影的適應性強。
lbp算子的原理可以描述如下,對于圖像中的每個像素點c=(x,y),與其領域半徑為r的p個鄰域點的灰度值進行比較,計算出lbp紋理特征值,其表達式實現如式(5)所示。
其中,gc為中心點的灰度值;gi為鄰域點灰度值;t為閾值;p為鄰域點的個數,一般選取4或者8。
cs-lbp算子相對于lbp算子性能有所提高,采用中心對稱的思想提取紋理特征,大大降低了提取的紋理特征的維數。cs-lbp紋理算子的特征值通過計算以中心像素為對稱的像素對的鄰域像素值得到,其實現形式如式(6)所示。
其中,gi+p/2是以gc為中心與gi點中心對稱的像素點灰度值。
xcs-lbp算子結合了lbp算子和cs-lbp算子的優勢,提取的紋理信息更加細致,抗噪能力更強。其實現形式由式(7)表示為:
xcs-lbp的原理圖如圖4所示。
4.hog特征
方向梯度直方圖(histogramoforientedgradient,hog)特征最早是由法國研究員dalal等于2005年,在國際計算機視覺與模式識別會議(cvpr)上發表,它是一種在計算機視覺和圖像處理中用來進行物體檢測的特征描述子,是目前計算機視覺、模式識別領域很常用的一種描述圖像局部紋理的特征。它的本質是統計圖像局部區域的梯度方向信息來作為該局部圖像區域的表征。
hog特征提取算法一般包含六部分,圖像灰度化;標準化gamma空間;計算圖像每個像素的梯度(包括大小和方向);將圖像分割為小的cell單元格;為每個單元格構建梯度方向直方圖;把單元格組合成大的塊(block),塊內歸一化梯度直方圖。由于前面步驟中已經對圖像進行灰度化,降噪等預處理,直接對xcs-lbp特征提取后得到的圖像計算其每個像素的梯度,然后進行后續處理。
a.圖像梯度計算
圖像梯度計算不僅能夠捕獲輪廓,人影和一些紋理信息,還能進一步弱化光照的影響。計算圖像橫坐標和縱坐標方向的梯度,并據此計算每個像素位置的梯度方向值。
水平方向的邊緣算子為[-1,0,1],垂直方向的邊緣算子為[-1,0,1]t。用[-101]分別對圖像的水平方向v和垂直方向h進行卷積運算,分別得到水平方向梯度gv(x,y)和垂直方向梯度gh(x,y),如果是彩色圖,則需要分別計算出r、g、b3個顏色分量的梯度值。本發明的公式如下:
gv(x,y)=l(x+1,y)-l(x-1,y)(8)
gh(x,y)=l(x,y+1)-l(x,y-1)(9)
再分別求像素點(x,y)的幅度值和梯度方向角度,g(x,y)表示幅度值,α(x,y)表示梯度方向角度,用表達式表示為:
g(x,y)=(g2v(x,y)+g2h(x,y))1/2(10)
b.將圖像分割為小的cell單元格,并構建梯度方向直方圖
把經過上述處理后的圖像分割成若干個8×8像素的單元格cell,圖像梯度方向[-π/2,π/2]平均劃分為9個區間(稱為bin),在每一個cell內,計算所有像素點在各個方向bin區間的梯度幅值(用vk(x,y)表示),得到一個9維的特征向量。
c.把單元格組合成大的塊(block),塊內歸一化梯度直方圖
塊(block)是單元格的集合,本發明采用每四個單元格(2*2)構成一個block,用block對窗口進行掃描,其步長為cell,串聯所有的block就得到人體特征,若用64*128大小的訓練圖像時,cell為8*8大小,則窗口可以劃分為64/8*128/8=8*16個cell。
對塊內歸一化梯度直方圖可以增強特征對陰影、光照等的不敏感性。本發明采用l2范數歸一化,計算公式如下:
其中v*為歸一化后的hog特征向量,v表示歸一化前block中36個特征向量,||v||k表示v的k范數,這里取ε=0.001,以防止分母為0。
5.級聯aksvm
a.支持向量機(svm)
支持向量機是vapnik等人在多年研究統計學理論的基礎上對線性分類器提出了另一種設計準則,其原理也從線性可分說起,然后擴展到線性一個有監督的學習模型,通常用來進行模式識別、分類以及回歸分析。
其基本實現原理可簡單介紹為,假設一個訓練數據集
f(x)=wtφ(x)+b(16)
其中w表示權重,b∈r表示偏差。svm的訓練可以闡述為使兩個類之間差值最大化的優化問題。這個優化問題可以在對偶空間內表示為:
其中
其中sυ={i|α(i)>0}是一組支持向量。當式(18)中的內核為非線性時,內核支持向量機(ksvm)比linsvm性能更好。然而,由于式(18)的計算需要花費大量時間,ksvm不能應用于行人檢測中。因此,linsvm在行人檢測中應用更為廣泛。
b.級聯svm
最近,yu等人提出一種線性支持向量機(linsvm)的級聯形式,該級聯形式是基于多實例修剪(mip)實現的,提高了linsvm的計算速度。其基本思想是將linsvm的輸出表示為智能維數分類器的求和,并將該linsvm分解成一個多弱分類器的組合。我們用t表示級聯的階段數,linsvm的決策函數f(x)就被分解為t個弱分類器qj(x),用數學表達式表示如下:
其中,w=[w1,w2,...,wn]t是式(16)中的權重,
然后,結束最初的t個階段后的臨時svm可以由式(22)給出。
最終得到的svm可以表示為:
使用boosting方法的弱分類器級聯實現概述如表1所示。
表1
c.級聯aksvm實現
附加核(ak)被定義為維分量的求和,其表達式如下所示:
其中,x={x1,x2,...,xn}∈rn,z={z1,z2,...,zn}∈rn。附加核(ak)包括線性核κlin,交叉核κik,廣義的交叉核κgik以及χ2核
從式(18),可以得到帶有附加核的svm的決策函數:
其中,
hn(xn)是xn∈r的一維函數,α(i),y(i)由式(17)中給出,值得注意的是,一維函數hn(xn)可以對所有可能的xn∈r預先計算,計算結果可以存儲在一個數組或者查找表(lut)中,用數學表達式表示為:
hn(xn)≈lutn(xn)(31)
式(29)表示的aksvm的決策函數可以由n個不同的查找表lut的和計算得到,這使得不管從訓練階段得到多少個支持向量機,aksvm的計算都變得非常簡單。此外,aksvm可以很好的匹配級聯實現,因為它通過使用lut,僅僅需要和linsvm類似的計算成本。因此,aksvm可以被分解為t個弱分類器,這里t滿足(t<<n),其決策函數可以表示為;
其中,
分類器的級聯形式如圖5所示,其中j是弱分類器qj(x)的索引,u(j)可以如下公式表示:
因此,aksvm的級聯實現依然可以用表1中的步驟表示,只需要將式
其中τ={1,2,3,...,t},tneg表示在aksvm級聯實現中,訓練樣本中負樣本被拋棄的平均階段。需要注意的是,這個決定順序的方法不影響訓練的準確性,而且減少了拒絕時間或者隨后的平均檢測時間。這個問題屬于組合問題,通過ga算法來實現。
為了決定aksvm中弱分類器的順序,我們應用了整數編碼的基因遺傳算法,本發明中應用的染色體c包含t個元素,編碼為c=[c1,c2,...,ct]并且有
cs=τs(36)
其中t是弱分類器的數量,然后染色體表示弱分類器qj(·)的順序,每個染色體一對一映射到序列{1,2,...,t}。最初,每個基因被隨機生成1到t之間不重復的整數。其中的一個染色體編碼如圖6所示。第s個基因表示哪一個弱分類器被放在第s階段。如果cs=j,它意味著第j個弱分類器qj(·)用在第s階段。因此,當給出一個染色體c時,該染色體可以被解碼為aksvm的級聯形式,如公式(37)所示。
其中,ft(x)是通過前t階段時aksvm的輸出,在級聯實現的過程中,每個階段的閾值由(38)式計算得到,它使得訓練樣本的錯誤率最小。
滿足
根據得到的閾值θt和每個階段的分類器ft(x),利用aksvm的級聯可以有效地計算測試集,如表2所示。
表2:使用序列c的級聯aksvm計算評價概述
6.后處理
后處理是融合檢測所得信息的過程,主要包括窗口區域預測,非極大值抑制等。我采用的是非極大值抑制算法。
貪心非極大值抑制算法的基本思想是每次貪心算法選擇檢查分數最高的初始檢測窗口,主要步驟如下:
①將初始檢測窗口按檢測分數從高到低排序。
②將第一個初始檢測窗口作為當前抑制窗口。
③非極大值抑制。將所有檢測分數比當前抑制窗口低的初始窗口作為被抑制窗口。計算當前抑制窗口與被抑制窗口的重合面積比率:面積的交/面積的并。剔除重合面積比率高于設定閾值的窗口。
④如果只剩最后一個初始檢測窗口則結束,否則按照排好的順序,取下一個未被抑制的窗口作為抑制窗口,轉到步驟③。
- 還沒有人留言評論。精彩留言會獲得點贊!