基于大數據分析的盾構施工地面沉降預測系統和方法與流程
本發明屬于工業大數據
技術領域:
,尤其涉及地鐵盾構施工領域的地面沉降預測,具體是一種基于大數據分析技術的盾構施工地面沉降預測系統和方法,可用于對盾構施工過程中地面沉降量的預測。
背景技術:
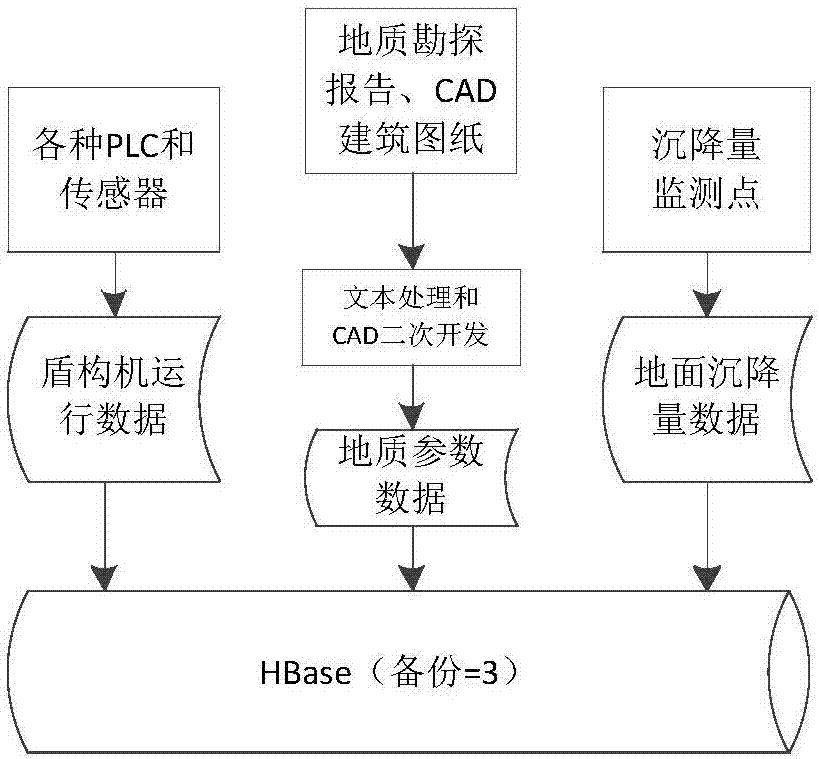
:隨著地鐵建設規模的不斷擴大,用于地鐵隧道施工的盾構挖掘設備得到的大量使用。盾構機是一種結構復雜的大型機電液控一體化設備,同時由于盾構施工環境相對惡劣,地質環境復雜多變,所以在施工過程中會產生很多問題,其中對地鐵施工影響較為嚴重的就是地面沉降。地面沉降是指在盾構施工中,由于地層物質被挖出,隧道周圍地層土體的應力狀態和原本穩定的結構狀態將發生重分布,引起地層移動而導致不同程度地面的隆起或沉降。而對地面沉降的預測就是要提前發現地面沉降問題,利用某種方法及時預測出地面沉降量,將可能出現的重大施工事故進行及時預警和匯報,提高施工質量。關于地面沉降預測模型的建立,傳統方法通常是在單機、串行模式下進行模型訓練,當面對海量數據時,由于數據量巨大,數據的存儲和處理,會暴露出容錯性差、速度慢、效率低等問題。這與盾構地面沉降預測所要求的實時性、快速性以及準確性相悖。同時,傳統方法所使用的數據量較小,這對所建立預測模型的準確性具有較大影響。隨著地鐵施工規模的不斷擴大,日益增長的海量盾構施工數據,使傳統分析方法面臨數據量巨大而帶來的難以解決的速度和效率問題,嚴重影響盾構施工數據的存儲能力和處理速度,進而影響盾構施工過程中的地面沉降量實時預測。同時,傳統方法只能處理小樣本數據,進而會降低預測模型的預測準確性。技術實現要素:本發明針對現有技術的不足,提出一種具有海量數據存儲、冗余能力和實時、高效計算能力的基于大數據分析技術的地面沉降預測系統和方法。本發明是一種基于大數據分析技術的盾構施工地面沉降預測系統,依據數據走向依次包括有數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊,所述數據收集模塊,包括有地質數據收集子模塊、盾構機運行數據收集子模塊和地面沉降量數據收集子模塊,負責進行地面沉降量預測所需數據的收集;其特征在于,還設有大數據平臺模塊,大數據平臺模塊包括hadoop平臺子模塊和spark平臺子模塊,spark平臺子模塊是基于hadoop平臺子模塊,大數據平臺模塊中的hadoop平臺子模塊分別與數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊之間進行雙向數據存儲交互;大數據平臺模塊中的spark平臺子模塊分別與數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊之間具有滿足spark編程范式的并行計算通道;所述數據預處理模塊,在spark平臺并行計算框架下,對數據集中的屬性進行缺失值填補、離群點檢測和歸一化處理;所述特征提取模塊在spark平臺并行計算框架下,采用pca降維算法進行特征提取;所述建立預測模型模塊是基于hadoop子模塊中的海量數據并在符合spark平臺子模塊的計算框架下,利用多節點誤差平均值去觸發誤差反饋過程,用連接權值向量的平均值向量作為最終預測模型的連接權值,形成預測模型,其中建立模型所需的輸入數據為地質參數數據和盾構機運行數據,輸出數據為盾構監測點沉降量數據;所述模型應用模塊是在大數據平臺模塊的基礎上,將建立預測模型模塊建立的預測模型進行功能封裝,并以api的形式提供模型接口,在盾構施工過程,盾構施工人員調用該模型接口,實現對盾構施工過程中地面沉降量的預測。本發明還是一種基于大數據分析技術的盾構施工地面沉降預測方法,在權利要求1-5所述的任一基于大數據分析技術的盾構施工地面沉降預測系統上實現,其特征在于,包括有如下步驟:(1)搭建大數據平臺:確定大數據平臺模塊中的節點拓撲結構,節點數量根據數據量大小進行確定,在各個網絡節點上按照需要配置相關環境,包含linux操作系統安裝、節點網絡配置、ssh無密碼登錄設置、安裝java程序,在以上配置環境基礎上,在各節點搭建hadoop平臺形成hadoop平臺子模塊和搭建spark平臺形成spark平臺子模塊,大數據平臺為地面沉降預測提供海量數據存儲與計算基礎,提高預測實時性;(2)收集盾構施工地面沉降預測所需數據:按照所需數據要求,在盾構機上、地面監測點和相應施工路線上布置相應傳感器,現場人員對盾構機運行數據、地面沉降量監測數據、地質參數數據進行收集,并將收集到的數據首先保存到本地文件系統或數據庫系統中,然后將其上傳到大數據平臺中的各節點上進行存儲,大數據平臺中的多節點提供存儲海量數據服務,其節點數量可以根據數據量情況進行拓展或收縮;(3)對收集數據進行預處理:利用均值填補法對數據集中缺失的數據進行填補以確保數據集的完整性,利用分箱法對數據集中的各屬性進行離群點探測并剔除其中的離群點,對數據集中的屬性進行歸一化處理,將屬性歸一化到[0,1]區間,得到高質量數據;(4)對數據集進行特征提取:在spark平臺子模塊運算框架下,利用pca降維算法,對預處理之后的非地面沉降量數據進行特征提取,按照特征值從大到小排序,選擇其中最大的k個特征值。將其對應的k個特征向量分別作為列向量組成特征向量矩陣數據集,根據該特征向量矩陣對數據集降維到含有k個特征的數據集,用該數據集作為建立預測模型模塊的輸入數據;(5)建立地面沉降預測模型:在spark平臺子模塊運算框架下,利用bp神經網絡算法,將特征提取之后的數據集作為輸入數據,地面沉降量數據作為輸出數據,訓練地面沉降預測模型;(6)將預測模型進行功能接口封裝:將訓練好的預測模型保存到hdfs文件系統中,并以api的形式提供該模型調用接口。(7)于施工過程中進行地面沉降預測:將以上基于大數據分析技術的盾構施工地面沉降預測系統中訓練好的模型部署到盾構機上,現場施工人員采集盾構施工實時數據,將施工實時數據上傳到基于大數據分析技術的盾構施工地面沉降預測系統中大數據平臺模塊中的hadoop平臺子模塊中,并對其進行預處理和特征提取,得到高質量數據作為預測模型輸入數據,調用預測模型功能接口并把輸入數據輸入到預測模型中,得到預測模型輸出結果即為前方地面最終沉降量大小,并將該沉降量值直觀反饋給施工人員,為施工人員提供決策支持。針對盾構施工過程中地面沉降量預測所面臨的問題,本發明基于大數據分析技術,具備為日益增長的盾構施工海量數據提供分布式、易拓展的海量數據存儲、冗余服務能力,并為地面沉降預測模型的建立提供高效、快速的計算框架,提高地面沉降預測模型的建立速度和效率。本發明與現有技術相比,具有以下優點:1.本發明針對地面沉降量預測,搭建了多節點大數據平臺,其中的主節點負責任務的分發,從節點負責任務的執行,大數據平臺模塊中的hadoop子模塊為海量盾構施工數據提供存儲和冗余能力,提高海量數據存儲能力和數據安全性;大數據平臺模塊中的spark子模塊為基于海量數據的預測模型建立提供了快速、高效和實時的計算框架,保證了預測模型建立的實時性,提高預測效率,同時,海量盾構施工數據為預測模型的準確性提供了基礎,保障了施工順利、安全進行。2.本發明建立預測模型的過程中,對模型訓練子模塊中的各節點的訓練誤差求其平均值,利用該平均值去觸發各節點誤差反向傳播過程,以此來調整各節點中的連接權值,該處理方式充分考慮到了各節點的誤差,將分散在各個并行節點的誤差統一到了一起作為總體誤差判斷標準,提高了預測模型的準確性。3.本發明建立預測模型的過程中,對模型訓練子模塊中各個節點中訓練好的bp神經網絡模型的連接權值向量進行匯總、求和并求出連接權值的平均值向量,該連接權值向量的平均值作為預測模型的連接權值向量,該處理方法充分考慮到了各個節點網絡的連接權值向量并將其匯總,避免了各個并行節點的孤立性,提高了預測模型的預測準確性。4.本發明方法在建立預測模型之前,對數據進行了數據預處理和特征提取,有效地減少了高維數據對分析過程的影響,避免弱相關因素對建模效果的干擾,提高了模型精度。5.本發明中的地質數據收集子模塊,使用文本處理技術和cad二次開發技術對地質勘探報告中的文本數據和cad圖紙中的點線面元素進行處理,進而獲取相應地質數據,解決了現階段地質數據依賴人工收集的問題,能夠自動化的獲取地質數據,提高地質數據采集效率。附圖說明圖1是本發明的系統架構示意圖;圖2是本發明中數據收集模塊示意圖;圖3是本發明中基于spark平臺的bp神經網絡模型建立流程圖;圖4是本發明中的地面沉降量具體預測方法;圖5是本發明中平臺搭建流程圖;圖6是本發明中大數據平臺模塊組件圖;圖7是本發明bp神經網絡訓練過程中訓練誤差變化圖;圖8是本發明地面沉降量真實值-預測值結果對比圖;圖9是兩種方法使用的時間對比結果圖。具體實施方式下面結合附圖和具體實施方式對本發明作詳細說明。實施例1:傳統盾構施工過程中對地面沉降量的預測處理方法面對海量盾構施工數據,不具備大規模數據存儲和處理能力,在對地面沉降進行預測時,速度慢、效率低和安全性差會直接影響到盾構施工過程中對地面沉降量的預測,進而降低施工質量,增大施工風險。本發明針對上述盾構施工中的地面沉降預測存在的問題,展開研究與探討,引入大數據分析技術,提出一種基于大數據分析技術的盾構施工地面沉降預測系統,本發明的系統中依據數據走向依次包括有數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊。數據收集模塊包括有地質數據收集子模塊、盾構機運行數據收集子模塊和地面沉降量數據收集子模塊,數據收集模塊負責進行地面沉降量預測所需數據的收集。參見圖1,本發明在數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊之前,先設有大數據平臺模塊,本發明的大數據平臺模塊包括hadoop平臺子模塊和spark平臺子模塊,spark平臺子模塊是基于hadoop平臺子模塊,大數據平臺模塊中的hadoop平臺子模塊分別與數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊之間進行雙向數據存儲交互,為數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊提供海量數據存儲。大數據平臺模塊中的spark平臺子模塊分別與數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊之間具有滿足spark編程范式的并行計算通道,為數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊提供并行計算框架。本發明中的數據預處理模塊,在spark平臺計算框架下,利用均值填補法對數據集中缺失的數據進行填補以確保數據集的完整性,然后利用分箱法對數據集中的各屬性進行離群點探測并剔除其中的離群點,最后對數據集中的屬性進行歸一化處理,將屬性歸一化到[0,1]區間,消除由于屬性量綱不同而帶來的數據不平衡。本發明中的特征提取模塊在spark平臺計算框架下,采用pca降維算法對數據集進行特征提取。本發明中的建立預測模型模塊是基于hadoop子模塊中的海量數據并在符合spark平臺子模塊的計算框架下,利用多節點誤差平均值去觸發誤差反饋過程,用各節點連接權值向量的平均值向量作為最終預測模型的連接權值,進而生成建立預測模型。本發明中的模型應用模塊是在大數據平臺模塊的基礎上,將建立預測模型模塊建立的預測模型進行功能封裝,并以api的形式提供該模型接口,在盾構施工過程,盾構施工人員調用該模型接口,實現對盾構施工過程中地面沉降量的預測。本發明中基于大數據分析的盾構施工地面沉降預測系統中的數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊都是基于大數據平臺模塊,大數據平臺模塊為以上模塊的數據提供海量存儲支持和快速、高效計算支撐,加快了以上各模塊的分析速度和效率,提高盾構施工過程中地面沉降量預測的實時性,有效避免事故發生。實施例2:基于大數據分析技術的盾構施工地面沉降預測系統的構成同實施例1,參照圖2,本發明中的數據收集模塊,包括有地質數據收集子模塊、盾構機運行數據收集子模塊和地面沉降量數據收集子模塊,地質數據收集子模塊通過文本處理技術和cad二次開發工具objectarx對專業地質勘探報告里的文本數據和施工圖紙里面的點線面元素進行地質參數數據抽取得到地質相關數據,例如:土質孔隙比、壓縮模量、滲透系數、內摩擦角等參數數據;盾構機運行數據收集子模塊,通過加裝在盾構機上的各傳感器和自帶傳感器進行盾構機運行數據采集得到盾構機運行數據;地面沉降量數據收集子模塊通過對地面沉降監測點進行監測來獲得地面沉降量數據,將以上數據上傳到大數據平臺模塊中的hbase中進行存儲。本發明的地質數據收集子模塊能夠解決獲取專業地質數據較為困難的問題,能夠自動化的提取文本和cad圖紙中的相應地質數據,提高數據收集效率。實施例3:基于大數據分析技術的盾構施工地面沉降預測系統的構成同實施例1-2,參照圖3,在spark并行編程模式下,本發明中的建立預測模型模塊,將盾構機運行數據和地質參數數據作為模型訓練的輸入,將地面沉降量作為模型訓練的輸出,用歷史數據建立預測模型;建立預測模型模塊按照數據流方向依次包含模型訓練子模塊、誤差處理子模塊、連接權值向量處理子模塊。模型訓練子模塊負責多節點模型訓練;誤差處理子模塊利用各節點訓練誤差的平均值去觸發各節點誤差反向傳播過程;連接權值向量處理子模塊用于計算預測模型中的連接權值向量,并用此結果形成地面沉降預測模型。實施例4:基于大數據分析技術的盾構施工地面沉降預測系統的構成同實施例1-3,參照圖3,本發明中的建立預測模型模塊中的誤差處理子模塊,包括兩部分內容,第一部分內容對模型訓練子模塊中的各節點的訓練誤差值求其平均值,第二部分內容利用訓練誤差平均值去觸發各節點誤差反向傳播過程,以此來調整各節點中的連接權值。實施例5:基于大數據分析技術的盾構施工地面沉降預測系統的構成同實施例1-4,參照圖3,本發明中的連接權值向量處理子模塊,對模型訓練子模塊中各個節點中訓練好的bp神經網絡模型的連接權值向量進行匯總、求和并求出連接權值的平均值向量,該連接權值向量的平均值作為預測模型的連接權值向量,形成地面沉降預測模型。誤差處理子模塊和連接權值向量處理子模塊將分散在各節點中單獨建立的模型結合在了一起,將原本割裂的各個訓練節點中的模型形成一個統一模型,該處理方式能有效擬合總體數據蘊含的內部關系,提高了建模效率與準確性。實施例6:本發明還是一種基于大數據分析技術的盾構施工地面沉降預測方法,在上述基于大數據分析技術的盾構施工地面沉降預測系統上實現,系統的構成同實施例1-5,參照圖4,盾構施工地面沉降預測方法包括有如下步驟:(1)搭建大數據平臺:確定大數據平臺模塊中的節點拓撲結構,節點數量根據數據量大小進行確定,其規模可進行擴展和收縮以提供不同規模需求的數據存儲服務,在各個網絡節點上按照需要配置相關環境,包含linux操作系統安裝、節點網絡配置、ssh無密碼登錄設置、安裝java程序,在以上配置環境基礎上,在各節點搭建基于hadoop和spark的大數據平臺為地面沉降預測提供海量數據存儲與并行計算基礎。(2)收集盾構施工地面沉降預測所需數據:通過地質數據收集子模塊收集地質勘探報告中的地質數據,盾構機運行數據收集子模塊收集通過傳感器采集的盾構運行狀態參數數據,地面沉降量收集子模塊通過施工線路上的地面沉降監測點收集地面沉降監測點數據,按照所需數據要求,在盾構機上、地面監測點和相應施工路線上布置相應傳感器,現場人員對盾構運行數據、地面沉降監測數據、地質數據進行收集,并將收集到的數據首先保存到本發明的本地文件系統或數據庫系統中,并將其上傳到大數據平臺中的各節點上進行存儲,大數據平臺中的多節點提供存儲海量數據服務,其節點數量可以根據數據量情況進行拓展或收縮。(3)對收集數據進行預處理:利用均值填補方法對數據集中缺失的數據進行填補以確保數據集的完整性,然后利用分箱法對數據集中的各屬性進行離群點探測并剔除其中的離群點,最后對數據集中的屬性進行歸一化處理,將屬性歸一化到[0,1]區間,得到高質量數據。(4)對數據集進行特征提取:在spark平臺子模塊運算框架下,利用pca降維算法,對預處理之后的數據進行特征提取,按照特征值從大到小排序,選擇其中最大的k個特征值。將其對應的k個特征向量分別作為列向量組成特征向量矩陣數據集,根據該特征向量矩陣對數據集降維到含有k個特征的數據集,用該數據集作為建立預測模型模塊的輸入數據。(5)建立地面沉降預測模型:在spark平臺子模塊運算框架下,利用bp神經網絡算法,將特征提取之后的數據集作為輸入數據,訓練地面沉降預測模型。(6)提供模型應用接口:將訓練好的預測模型保存到hdfs文件系統中,并以api的形式提供該模型調用接口。(7)于施工過程中進行地面沉降預測:將以上基于大數據分析技術的盾構施工地面沉降預測系統部署到盾構機上,現場施工人員采集盾構施工實時數據,將施工實時數據上傳到基于大數據分析技術的盾構施工地面沉降預測系統中大數據平臺模塊中的hadoop平臺子模塊中,對大數據平臺模塊中的hadoop平臺子模塊里存儲的數據經過預處理和特征提取之后得到高質量數據作為預測模型輸入數據,調用預測模型功能接口并把輸入數據輸入到預測模型中,得到預測模型輸出結果即為前方地面最終沉降量大小,并將該沉降量值直觀反饋給施工人員,為施工人員提供決策支持,以此來對地面沉降量做出預測。本發明的盾構施工地面沉降預測方法中的數據處理過程都運行在大數據平臺上,利用大數據平臺并行處理框架的高效資源調度和容錯處理能力,能夠保證每個數據處理步驟的準確性和快速性,提高建模效率,進而提高地面沉降預測的實時性工程應用價值。實施例7:基于大數據分析技術的盾構施工地面沉降預測系統的構成同實施例1-6,參見圖3,本發明的步驟(5)中的訓練地面沉降預測模型的過程包括有如下步驟:(5a)以流的形式,從大數據平臺中的hdfs或hbase中讀取訓練數據,加載到集群節點的內存中。(5b)根據配置要求,對訓練數據分塊形成rdd1、rdd2、…、rddn等分割形式。(5c)初始化各個節點worker的bp神經網絡結構,給相應的連接權值賦初值。(5d)進入map階段,將各個節點上的訓練數據帶入到網絡中進行訓練,得到各節點的訓練誤差分別為e1、e2、…、en。(5e)進入join階段,對各節點的訓練誤差進行匯總,并求出平均誤差值e。(5f)判斷誤差e是否滿足誤差要求,如果滿足:則匯總各個節點的權值向量w1、w2、…、wn,然后計算網絡結構權值的平均值向量w,利用該平均值向量w形成預測模型,并將該預測模型保存到大數據平臺模塊中hadoop平臺子模塊中的hdfs中;如果不滿足誤差要求:則觸發反饋過程,即根據各節點的訓練誤差e1、e2、…、en調整各個節點網絡中神經元的連接權值向量值w1、w2、…、wn,并重復步驟(5d)~(5f),進行新一輪的迭代過程,得到新的訓練誤差值,并進行訓練誤差匯總并求出平均誤差值,然后對平均誤差值進行判斷,反復迭代過程直至訓練平均誤差值滿足要求,模型訓練結束,退出循環迭代過程。下面將基于大數據分析技術的盾構施工地面沉降預測系統和方法融匯在一起,對本發明進一步說明:實施例8:基于大數據分析技術的盾構施工地面沉降預測系統的構成同實施例1-7,本發明用于解決盾構施工過程中的地面沉降量預測問題。同時考慮到未來隨著盾構規模的不斷擴大,可能會出現的盾構大數據應用場景,專門提出了一種基于大數據分析技術的地面沉降預測系統和方法。基于大數據并行處理技術和bp神經網絡算法,通過數據集成,然后進行數據預處理,進而對預處理后的數據進行特征提取,并在spark平臺下建立地面沉降量預測模型。根據本發明所述的系統和方法,實現基于大數據分析技術的地面沉降預測過程,包括有如下步驟:(1)確定大數據平臺模塊中的硬件節點拓撲結構,節點數量根據數據量大小進行確定,其規模可進行擴展和收縮以提供不同規模需求的數據存儲服務。本實施例的大數據平臺網絡節點拓撲結構如下表1所示,表1給出了包含四個服務器節點的拓撲結構,其中一個節點作為namenode,另外三個節點作為datanode,并且為了保證平臺的健壯性,將secondaryname部署在非namenode節點上。表1網絡節點拓撲結構節點ip屬性備注master.hadoop192.168.137.2namenodeslave1.hadoop192.168.137.3datanodesecondarynamenodeslave2.hadoop192.168.137.4datanodeslave3.hadoop192.168.137.5datenode大數據平臺中的各網絡節點配置如下表2所示,四臺節點計算機的配置相同。表2節點具體配置屬性參數內存容量1g硬盤空間20gcpu個數1linux系統版本centos-6.3jdk版本jdk-6u32hadoop版本hadoop-2.6.0spark版本spark-1.4.0參照圖5,具體平臺搭建流程,包含安裝linux系統安裝、節點網絡配置、ssh無密碼登錄配置、安裝java環境、配置hadoop、配置spark,并將搭建好的平臺進行初始化操作進而為與系統中的各模塊進行雙向數據和計算通道的連接建立提供基礎保障,形成基于大數據分析的盾構施工地面沉降預測系統。參照圖6,搭建好大數據平臺后,大數據平臺模塊包含如下組件:hdfs、hadoopyarn、hadoopmapreduce、spark、sparkstreaming等。(2)通過數據收集模塊中的地質數據收集子模塊收集地質勘探報告和cad圖中的地質數據,盾構機運行數據收集子模塊收集通過傳感器收集盾構運行狀態參數數據,地面沉降量收集子模塊通過施工線路上的地面沉降監測點收集地面沉降監測點數據,按照所需數據要求,在盾構機上、地面監測點和相應施工路線上布置相應傳感器,現場人員對盾構運行數據、地面沉降監測數據、地質數據進行收集,并將收集到的數據首先保存到本地文件系統或數據庫系統中,然后將其上傳到大數據平臺中的各節點上進行存儲,大數據平臺中的多節點提供存儲海量數據服務,其節點數量可以根據數據量情況進行拓展或收縮以應對不同規模的數據量。(3)利用均值填補方法對數據集中缺失的數據進行填補以確保數據集的完整性,然后利用分箱法對數據集中的各屬性進行離群點探測并剔除其中的離群點,最后對數據集中的非類別屬性進行歸一化處理,將屬性歸一化到[0,1]區間,得到高質量數據,該步驟是在spark平臺上進行并行運算,提高了運算速度。(4)對數據集進行特征提取:在spark平臺子模塊運算框架下,利用pca降維算法,對預處理之后的數據進行特征提取,按照特征值從大到小排序,選擇其中最大的k個特征值。將其對應的k個特征向量分別作為列向量組成特征向量矩陣,根據該特征向量矩陣對數據集降維到含有k個特征的數據集,用該數據集作為建立預測模型模塊的輸入數據,其具體步驟如下所示:(4a)假設有m條數據記錄,每個樣本有n個特征,那么每條數據可用向量(1)表示,數據集可用矩陣(2)表示如下:(4b)利用公式(3)計算出協方差矩陣:求出協方差矩陣c的特征值和特征向量。(4c)將特征向量對應特征值大小按照從左到右排列成矩陣,取前k個向量組成如下(4)所示的矩陣p:(4d)通過如下公式(5)將原數據集x降維到含有k個特征的數據集y:y=xp(5)(5)在spark平臺子模塊運算框架下,利用bp神經網絡算法,將特征提取之后的數據集作為輸入數據訓練地面沉降預測模型,其具體步驟如下所示:(5a)以流的形式,從大數據平臺中的hdfs或hbase中讀取訓練數據,加載到集群節點的內存中。(5b)根據配置要求,對訓練數據分塊形成rdd1、rdd2、…、rddn等分割形式。(5c)初始化各個節點worker的bp神經網絡結構,給相應的連接權值賦初值。(5d)進入map階段,將各個節點上的訓練數據帶入到網絡中進行訓練,得到各節點的訓練誤差分別為e1、e2、…、en。(5e)進入join階段,對各節點的訓練誤差進行匯總,并求出平均誤差值e。(5f)判斷誤差e是否滿足誤差要求,如果滿足:則匯總各個節點的權值向量w1、w2、…、wn,然后計算網絡結構權值的平均值向量w,利用該平均值向量w形成預測模型,并將該預測模型保存到大數據平臺模塊中hadoop平臺子模塊中的hdfs中;如果不滿足誤差要求:則觸發反饋過程,即根據各節點的訓練誤差e1、e2、…、e調整各個節點網絡中神經元的連接權值向量值w1、w2、…、wn,并重復步驟(5d)~(5f),進行新一輪的迭代過程,得到新的訓練誤差值,并進行訓練誤差匯總并求出平均誤差值,然后對平均誤差值進行判斷,反復迭代過程直至訓練平均誤差值滿足要求,模型訓練結束,退出循環迭代過程。(6)將訓練好的預測模型保存到hdfs文件系統中,并以api的形式提供該模型調用功能接口。(7)將以上基于大數據分析技術的盾構施工地面沉降預測系統部署到盾構機上,現場施工人員采集盾構施工實時數據,將施工實時數據上傳到基于大數據分析技術的盾構施工地面沉降預測系統中大數據平臺模塊中的hadoop平臺子模塊中,對大數據平臺模塊中的hadoop平臺子模塊里存儲的數據經過預處理和特征提取之后得到待預測地面沉降量所需數據作為預測模型輸入數據,調用預測模型功能接口并把輸入數據輸入到預測模型中,得到預測模型輸出結果即為前方地面最終沉降量大小,并將該沉降量值直觀反饋給施工人員,為施工人員提供決策支持,以此來對地面沉降量做出預測,現場施工員根據地面沉降量的大小及時調整相關參數,降低施工過程中的地面沉降風險,提高施工質量和施工效率。本發明為基于大數據的盾構施工過程中的地面沉降預測提供了一個完整、高效的數據分析和處理流程,為現場施工人員和工程管理人員提供了一個地面沉降預測平臺,按照系統中的模塊和預測方法施工人員可以對地面沉降量做出準確、快速預測,有效提高了施工效率和施工進度。下面通過試驗數據對本發明的技術效果再做說明:實施例9:基于大數據分析技術的盾構施工地面沉降預測系統的構成同實施例1-8,結合實驗數據對本發明系統中模塊和方法的技術效果說明如下:(1)通過數據收集模塊收集到實驗數據如下表3所示,數據來自武漢地鐵6號線一期工程,共有7個字段,865036條數據記錄,數據文件大小為815m。表3數據收集模塊收集到的原始數據舉例序號t1t2t3t4t5t6s111740201222.04180.218.3-31.421200012.63.81.9722.114.4-18.73954015.11131.97134.722.7-17.341100019.9133.82.05186.818.7-22.8…………………………………………8650331150017.81862.15258.222.2-28.18650341166019.91272.04181.918.5-25.98650351135020118.52.03180.117.9-29.78650361203020.4130.32.0419518.3-30.3注:t1、t2、t3、t4、t5、t6為輸入屬性;s為輸出屬性t1:盾構機千斤頂推力/knt2:盾構機推進速度/mm/mint3:變形模量/mpat4:注漿壓力/mpat5:凝聚力/kpat6:內摩擦角/°s:地面沉降量數據/mm(2)通過數據預處理模塊對以上收集到的表3所示數據進行數據預處理,利用均值填補法進行缺失值填補、并通過分箱法進行離群點檢測并將其剔除,最后進行歸一化處理,將其歸一化到[0,1]區間中,歸一化處理后的數據如下表4所示:表4數據預處理之后的數據序號t1t2t3t4t5t6s10.1140.9480.4690.3570.4820.5170.68120.1220.4740.0100.1070.0380.1690.88130.0470.6340.4340.1070.3540.9100.90340.0920.9420.5150.3920.5010.5530.817…………………………………………8617020.1070.8070.7170.750.7010.8660.7338617030.1120.9420.4880.3570.4870.5350.7688617040.1020.9480.4550.3210.4820.4820.7088617050.1230.9740.5010.3570.5240.5170.699(3)通過特征提取模塊,對表4所示數據中的t1、t2、t3、t4、t5、t6屬性進行特征提取,并選取前4個相關性較大的特征,特征提取之后的數據集如下表5所示:表5特征提取之后的數據序號k1k2k3k4s10.4890.9610.5430.6200.68120.5390.5020.0290.2470.88130.1260.7630.5290.2470.90340.2810.9510.6180.7040.817………………………………8617020.4570.8050.8720.8940.7338617030.4720.9570.5970.6200.7688617040.4350.9610.5320.4390.7088617050.5430.9740.6050.6200.699(4)利用表5所示特征提取之后的數據建立地面沉降預測模型,其中屬性k1、k2、k3、k4作為訓練模型的輸入屬性,屬性s作為訓練模型的輸出屬性,將其帶入到建立預測模型模塊中進行并行迭代計算,參照圖7,模型迭代過程中的預測結果相對誤差最終趨于平穩,當滿足誤差要求時,停止迭代過程,模型建立完畢,并將其模型進行封裝成接口,保存到hdfs中。(5)參照圖8,對以上建立好的模型進行地面沉降量預測測試,真實值為實際地面沉降量,預測值為對模型測試所得到的預測地面沉降量,對比真實值與預測值可得,該模型能夠準確地預測出地面沉降量大小。(6)參照圖9,對使用同一數據在相同配置的單節點計算機上進行地面沉降預測所用時間與使用本發明進行盾構地面沉降預測所用時間進行對比發現,使用本發明基于大數據分析技術的盾構施工地面沉降預測系統和方法,能夠極大縮短地面沉降預測時間,提高盾構施工過程中的地面沉降預測效率。結合實驗數據驗證可知,該基于大數據分析技術的盾構施工地面沉降預測系統和方法相比于傳統分析方法能夠準確、高效的預測出地面沉降量的大小,具有較大的實際工程價值。本發明主要用于解決現有技術在盾構施工大數據場景下,不能高效、及時對地面沉降進行預測的問題。該方法基于大數據處理技術和bp神經網絡算法,通過大數據平臺搭建、數據收集,然后進行數據預處理,進而對預處理后的數據進行特征提取,并在spark平臺下建立地面沉降量預測模型,并對模型進行封裝和以api的方式提供應用。簡而言之,本發明公開的一種基于大數據分析的盾構施工地面沉降預測系統和方法,主要解決現有技術在盾構施工大數據場景下,不能高效、及時對地面沉降進行預測的問題。本發明通過大數據平臺與數據收集模塊、數據預處理模塊、特征提取模塊、建立預測模型模塊和模型應用模塊進行數據交互與數據控制,形成地面沉降預測系統。預測方法步驟包括:搭建大數據平臺;收集盾構施工地面沉降數據;數據預處理;特征提取;建立地面沉降預測模型;預測模型功能接口封裝;于施工過程中進行地面沉降預測。本發明整個方案設計嚴謹、完整,有海量數據存儲與并行計算能力,地面沉降預測的效率和準確性高,用于地鐵施工地面沉降預測,保障工程質量和安全。以上描述僅是本發明具體實例,不構成對本發明的任何限制,顯然對于本領域的專業人員來說,在了解了本
發明內容和原理后,都可能在不背離本發明原理、結構的情況下,進行形式和細節上的各種修改和改變,但是這些基于本發明思想的修正和改變仍在本發明的權利要求保護范圍之內。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1