僵尸網站的檢測方法與流程
本發明涉及計算機技術領域,尤其涉及一種僵尸網站的檢測方法。
背景技術:
伴隨著互聯網的發展,網站數量急劇增多。截至2016年12月,中國域名總數為4228萬個,其中“.cn”域名總數為2061萬個,占中國域名總數比例為48.7%,“.中國”域名總數為47.4萬個。中國網站總數為482萬個,年增長14.1%,其中“.cn”下網站數為259萬個,網頁數量2360億,年增長11.2%。
在互聯網信息時代,政府、企業包括個人都熱衷建立自己的網站,但后續缺乏相應的管理維護,信息長期不更新,導致大部分的網站都處于睡眠狀態,沒有生機和活力且不被搜索引擎收錄,最終成為我們熟知的僵尸網站。
早起的僵尸網站主要指政府網站,從1998年以來,我國各級政府開始陸續建設政府網站,十幾年下來,這些網站確實起到不少積極作用。然而,由于某些網站工作人員的不負責任或不作為,有時,當民眾點開“便民服務”欄目,結果不是顯示“內容正在建設”,就是“無法打開該頁面”,或者是“千篇一律的神回復”——你的問題正在研究,請耐心等,然而等待近半年,還是同樣的回答;有的甚至是答非所問。這樣,大大損害了政府形象,降低政府網站的公信力,也損傷國人參政、議政的熱情。
對于企業或者個人網站,因長期的缺乏維護管理,成為黑客攻擊的對象,變為僵尸網絡的病蟲載體,嚴重影響了互聯網網絡安全,同時也增加了各個地方互聯網管理辦公室對本行政領域內的網站管理的難度。
如何從眾多的網站中有效的識別出僵尸網站,是對僵尸網站有效管理的前提。目前對僵尸網站的識別主要還是基于人工的方式進行,以屬地執法機構來說,主要依賴人工對備案的屬地網站進行逐個篩選,或借助簡單的技術對網站進行檢測,查看該網站是否正常返回信息來進行初步判斷。這些方式或多或少可解決部分問題,但均存在一定的不足:
1)單存的人工方式識別,勢必造成識別效率低下,人工成本高企等問題;
2)簡單進行網站訪問,查看返回信息的方式在網絡帶寬異常,或者網站維護期間等情況下也會造成相應的誤判;
3)人工對單一網站無法做到每一個欄目都關注到,導致部分網站僵尸欄目一直存在于網絡上的問題。
技術實現要素:
本發明要解決的技術問題是提供一種僵尸網站的檢測方法。
為了解決上述技術問題,本發明采用的技術方案是,僵尸網站的檢測方法,包括以下步驟:
(1)網絡信息收集和索引
使用網絡信息采集雷達采集網站發布的互聯網信息,且互聯網信息為html格式,運用網頁預處理算法對正文中的標題、發表時間、正文進行數據提取,重點對發表時間進行多種校驗,保證提取的時間的正確性;而后將提取后的數據發送到索引模塊,索引模塊在對上述字段進行分詞處理后,建立倒排索引,實現文本的檢索;
(2)網站可用性檢測
基于上述采集引擎,實現對網站可用性的檢測,主要是對網站在檢測時間段內是否可訪問、網站頁面鏈接是否可訪問、網站頁面鏈接的響應時間三方面內容進行監測,綜合不可訪問次數比例進行打分,該分數作為后續僵尸網站檢測時的網站可用性權重;
(3)網站信息更新檢測
基于所采集的數據,考慮每一個網站的欄目設置、及信息來源各個欄目數量等指標,在給定的時間段內按照預先設定的評判標準對網站的更新頻率進行加權計算,對每個網站的信息更新指數進行打分,該分數作為后續僵尸網站檢測時的網站信息更新頻率權重;
(4)網站綜合打分及僵尸網站判定
根據用戶設定的統計時間間隔,計算出每個時間段各個網站的可用性、網站信息更新情況;然后對每個時間段內的網站按照預先設定的標準進行加權打分;根據計算的網站綜合打分對網站是否是僵尸網站進行檢測,利用設定好的網站指標對網站進行判別。
作為優選,在步驟(1)中,所述網頁預處理算法包括以下步驟:
對網頁中的內容進行預處理時,會創建一個預處理對象,預處理對象調用本地自然語言解析腳本對網頁中的正文進行信息預處理,特別地對網頁中的時間文本進行處理。
作為進一步優選,本地自然語言解析腳本包含了對自然語言的噪音的過濾、信息的歸約以及變換。
本發明的有益效果是:
通過采集相應網站信息,進行信息抽取和索引后,使用既定的網站評價指標(網站可用性、網站信息更新頻率等)對網站是否僵尸網站進行檢測,實現了對網站是否僵尸網站的有效判別。
附圖說明
下面結合附圖和具體實施方式對本發明作進一步詳細的說明。
圖1是本發明實施例的網頁信息采集和索引結構圖。
圖2是本發明實施例的網站可用性檢測結構圖。
圖3是本發明實施例的索引倒排表結構。
具體實施方式
一、網頁信息采集和索引
如圖1所示,該采集過程具體步驟如下:
1、規劃好要檢測的網站,并將網站入口加入到檢測隊列中去。
2、選取一個網站入口進行下載,抽取相關正文url后,將其放入到待下載隊列中。
3、從待下載隊列中選取一個url進行下載,完成后識別出相關的網頁編碼,并按照預先設定的模板進行標題、發文時間、作者、正文、點擊數、回復數、是否轉載等關鍵字段的抽取。
4、將抽取后的標題、正文文本、時間、作者、點擊數、回復數、是否轉載字段直接發送到索引模塊。同時將站點名、站點host、發文時間、板塊字段信息發送到站點統計分析模塊。
索引過程具體步驟如下:
5、接收到采集模塊發送信息后,分詞組件對標題和正文文本進行分詞處理,把文檔分詞一個一個單獨的詞元,并去掉標點符號和停用詞。
6、語言處理組件對詞元進行處理,對于英語單詞,變成小寫;單詞變成詞根形式。
7、索引組件對處理后的詞建立詞典,對詞典按字母順序進行排序,并按照詞->文檔列表的結構建立倒排表。倒排表結構如圖3所示(圖中數字為文檔編號)。
二、網站可用性檢測
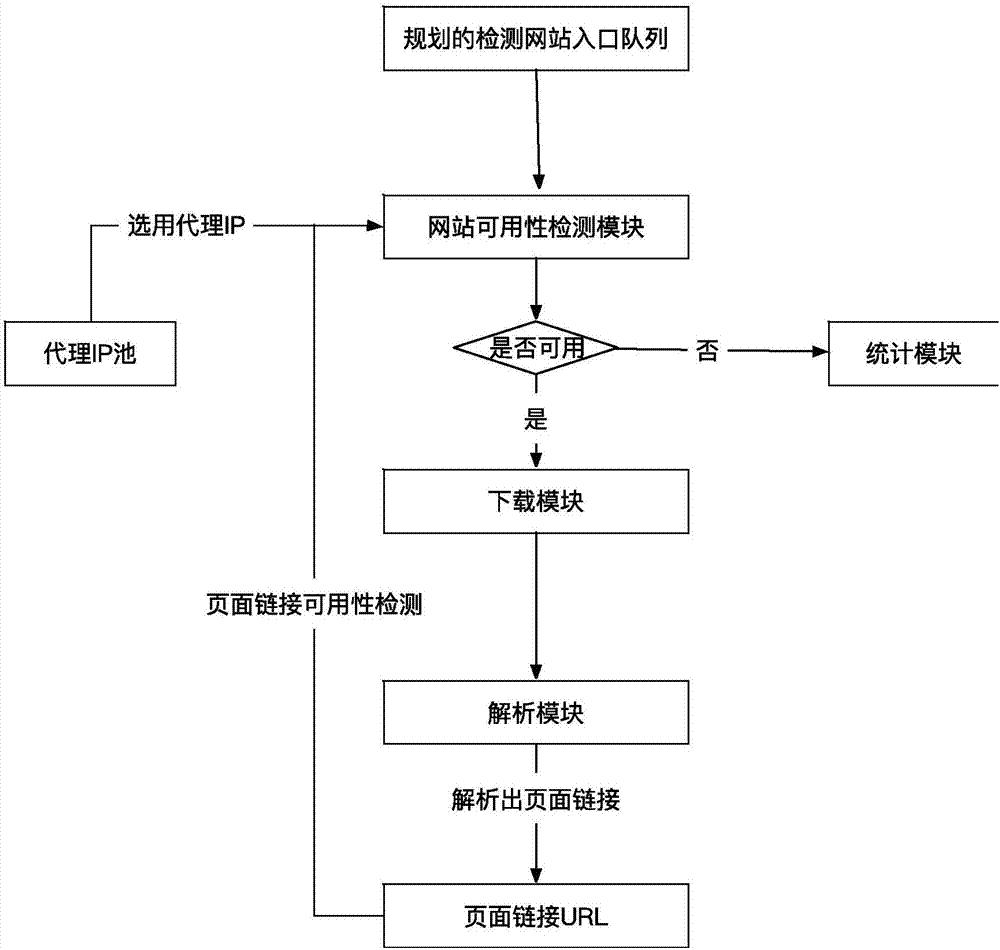
如圖2所示,該過程需完成對預規劃的站點進行掃描,具體過程如下:
8、從規劃的檢測網站隊列中選取相關網站入口進行檢測,使用代理ip機制,通過http監控,采用固定頻率模擬用戶請求被檢測的網站,實時獲取站點的響應狀態和請求詳情,精準探測出待檢測網站的各種異常,對于異常響應輸送給統計模塊進行相關后續統計分析。
9、對檢測的網站入口是可用的,加入下載隊列,抽取相關url,放入掃描隊列中,采用步驟8中的方法判斷頁面中鏈接可用性。
10、而后將該網站的掃描結果傳給站點檢測分析模塊,對網站可用性進行判斷。
統計模塊對網站可用性檢測模塊發來的相關信息進行統計,主要分如下幾個方面:
1)待檢測網站在http監控掃描周期(一個周期為七天,每天的每個整點訪問一次,累計24次)中,在間隔訪問中無法訪問的次數達到或超過3次得100分、24次中有8次訪問超過15秒響應得100分,其他情況(無法訪問次數小于3次或者24次中小于8次訪問超過15秒響應)每次累加5分處理;
2)在頁面鏈接url可用性上進行檢測,首頁上的鏈接(包括圖片、附件、外部鏈接等)無法訪問或訪問超過15秒的個數占總頁面鏈接數超過10%得100分,其他頁面(非首頁)的鏈接(包括圖片、附件、外部鏈接等)無法訪問或訪問超過15秒的個數占總頁面鏈接數超過10%得50分、超過20%得100分,其他情況每次累計0.5分處理。
三、網站信息更新檢測
統計模塊基于對待檢測網站采集的數據,考慮每一個網站的欄目設置、及信息來源各個欄目數量等指標,在給定的時間段內按照預先設定的評判標準對對網站的更新頻率進行加權計算,對每個網站的信息更新指數進行打分。主要有以下兩個方面:
1)統計待檢測站點超過30天沒有更新信息的所有板塊數量(n),規劃的待檢測站點的所有板塊數量(n),若
2)統計待檢測站點在30天內未更新信息的所有板塊數量(n),規劃的待檢測站點的所有板塊數量(n),若
四、網站綜合打分及僵尸網站判定
綜合二、三步驟計算得到到網站可用性打分及網站信息更新指數打分,將得分相加得到網站綜合打分。綜合打分超過80分即可判定為僵尸網站。
以上所述的本發明實施方式,并不構成對本發明保護范圍的限定。任何在本發明的精神和原則之內所作的修改、等同替換和改進等,均應包含在本發明的權利要求保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!