基于稀疏表示的改進耦合字典學習的腦部CT/MR圖像融合方法與流程
本發明涉及圖像處理技術領域,特別是涉及基于稀疏表示的改進耦合字典學習的腦部ct/mr圖像融合方法。
背景技術:
在醫學領域,醫生需要對同時具有高空間和高光譜信息的單幅圖像進行研究和分析,以便于對疾病進行準確診斷和治療。這種類型的信息僅從單模態圖像中無法獲取,例如,ct成像能夠捕捉人體的骨結構,具有較高的分辨率,而mr成像能夠捕捉人體器官的軟組織如肌肉、軟骨、脂肪等細節信息。因此,將ct和mr圖像的互補信息相融合以獲取更全面豐富的圖像信息,可為臨床診斷和輔助治療提供有效幫助。
目前應用于腦部醫學圖像融合領域比較經典的方法是基于多尺度變換的方法:離散小波變換(dwt)、平穩小波變換(swt)、雙樹復小波變換(dtcwt)、拉普拉斯金字塔(lp)、非下采樣contourlet變換(nsct)。基于多尺度變換的方法能很好地提取圖像的顯著特征,但是對圖像誤配準敏感,傳統的融合策略也使得融合結果無法保留源圖像的邊緣、紋理等細節信息。隨著壓縮感知的興起,基于稀疏表示的方法被廣泛用于圖像融合領域,并取得了極佳的融合效果。yang.b等使用冗余的dct字典稀疏表示源圖像,并使用“選擇最大”的規則融合稀疏系數。dct字典是一種由dct變換形成的隱式字典,易于快速實現,但是其表示能力有限。m.elad等提出k-svd算法用于從訓練圖像中學習字典。與dct字典相比,學習的字典是一種自適應于源圖像的顯式字典,具有較強的表示能力。學習的字典中將僅從自然圖像中采樣訓練得到的字典稱為單字典,單字典可以表示任意一幅與訓練樣本類別相同的自然圖像,但對于結構復雜的腦部醫學圖像,使用單字典既要表示ct圖像又要表示mr圖像,難以得到精確的稀疏表示系數。b.ophir等提出小波域上的多尺度字典學習方法。即在小波域上對所有子帶分別使用k-svd算法訓練得到所有子帶對應的子字典。多尺度字典有效地將解析字典和學習的字典的優勢相結合,能夠捕捉圖像在不同尺度和不同方向上包含的不同特征。但是所有子帶的子字典也是單字典,使用子字典對所有子帶進行稀疏表示仍然難以得到精確的稀疏表示系數,并且分離的字典學習時間效率較低。yu.n等提出基于聯合稀疏表示的圖像融合方法兼具去噪功能。這種方法是對待融合的源圖像本身進行字典學習,根據jsm-1模型提取待融合圖像的公共特征和各自特征,再分別組合并重構得到融合圖像。這種方法由于是對待融合源圖像本身訓練字典所以適用于腦部醫學圖像,可以得到精確的稀疏表示系數。但是對于每對待融合的源圖像都需要訓練字典,時間效率低,缺乏靈活性。
技術實現要素:
本發明實施例提供了基于稀疏表示的改進耦合字典學習的腦部ct/mr圖像融合方法,可以解決現有技術中存在的問題。
一種基于稀疏表示的改進耦合字典學習的腦部ct/mr圖像融合方法,該方法包括:
預處理階段:對于已經配準的腦部ct/mr源圖像ic,ir∈rmn,rmn表示具有m行n列的向量空間,使用步長為1的滑動窗把源圖像ic,ir分別分割為
其中,
融合階段:使用coefromp算法求解
其中,||α||0表示稀疏系數α中非零元素的個數,ε表示允許偏差的精度,df表示字典dc和dr融合后得到的融合字典;
將稀疏系數的l2范數作為源圖像的活躍度測量,則稀疏系數
均值
其中,
重建階段:對所有的圖像塊都執行預處理階段和融合階段以得到所有圖像塊的融合結果,對于每個塊向量
優選地,在融合階段中,所述融合字典通過以下方法計算獲得:
使用高質量ct和mr圖像作為訓練集,從訓練集中采樣得到向量對{xc,xr},定義
在字典學習代價函數基礎上加入支撐完整的先驗信息,交替地更新dc,dr和a,對應的訓練優化問題如下:
其中,a是xc和xr的聯合稀疏系數矩陣,τ是聯合稀疏系數矩陣a的稀疏度,⊙表示點乘,掩膜矩陣m由元素0和1組成,定義為m={|a|=0},等價于如果a(i,j)=0則m(i,j)=1,否則為0,引入輔助變量:
則式(1)可以等價的轉化為:
式(3)的求解過程分為稀疏編碼和字典更新兩個步驟:
首先,在稀疏編碼階段,隨機矩陣初始化字典
分別對聯合稀疏系數矩陣a中每一列的非零元素進行處理,而保持零元素完備,則式(4)可以轉換為下式:
式中,
其次,在字典更新階段,式(3)的優化問題轉化為:
則式(6)的補償項寫為:
式中,
最后,循環執行稀疏編碼和字典更新這兩個階段,直至達到預設的迭代次數為止,輸出一對耦合的dc和dr字典。
優選地,使用以下方法對字典dc和dr進行融合:
lc(n)和lr(n),n=1,2,…,n分別代表ct字典和mr字典的第n個原子的特征指標,融合公式表示如下:
此處設λ=0.25。
本發明實施例提供的基于稀疏表示的改進耦合字典學習的腦部ct/mr圖像融合方法,能分別對正常腦部、腦萎縮和腦腫瘤三組腦部醫學圖像進行融合,多次實驗結果表明本發明提出的icdl方法與基于多尺度變換的方法、傳統稀疏表示的方法、基于k-svd字典學習的方法以及多尺度字典學習的方法相比,不僅提高了腦部醫學圖像融合的質量,而且有效降低了字典訓練的時間,能為臨床醫療診斷提供有效幫助。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例提供的基于稀疏表示的改進耦合字典學習的腦部ct/mr圖像融合方法流程圖;
圖2為作為訓練集的高質量的ct和mr圖像;
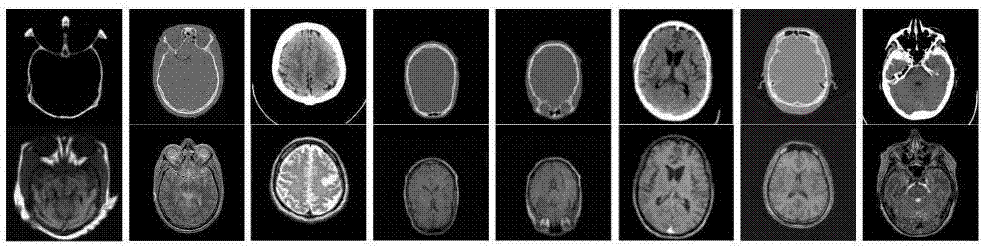
圖3為正常腦部的ct/mr融合結果,其中a為ct圖像,b為mr圖像,c為dwt(離散小波變換)圖像,d為swt(平穩小波變換)圖像,e為nsct(非下采樣contourlet變換)圖像,f為srm(傳統稀疏表示方法)圖像,g為srk(基于k-svd字典學習方法)圖像,h為mdl(基于多尺度字典學習方法)圖像,i為本發明使用的icdl(improvedcoupleddictionarylearning)圖像;
圖4為腦萎縮的ct/mr融合結果;
圖5為腦腫瘤的ct/mr融合結果。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
參照圖1,本發明實施例中提供的基于稀疏表示的改進耦合字典學習的腦部ct/mr圖像融合方法,該方法包括以下步驟:
步驟100,預處理階段:對于已經配準的腦部ct/mr源圖像ic,ir∈rmn,rmn表示具有m行n列的向量空間,使用步長為1的滑動窗把源圖像ic,ir分別分割為
其中,
步驟200,融合階段:使用coefromp算法求解
其中,||α||0表示稀疏系數α中非零元素的個數,ε表示允許偏差的精度,df表示字典dc和dr融合后得到的融合字典,其具體計算方法如下:
使用圖2所示的高質量ct和mr圖像作為訓練集,從訓練集中采樣得到向量對{xc,xr},定義
本發明的耦合字典訓練使用改進的k-svd算法,該算法在傳統的字典學習代價函數基礎上加入支撐完整的先驗信息,交替地更新dc,dr和a,對應的訓練優化問題如下:
其中,a是xc和xr的聯合稀疏系數矩陣,τ是聯合稀疏系數矩陣a的稀疏度,⊙表示點乘,掩膜矩陣m由元素0和1組成,定義為m={|a|=0},等價于如果a(i,j)=0則m(i,j)=1,否則為0。因此a⊙m=0能使a中所有零項保持完備。引入輔助變量:
則式(3)可以等價的轉化為:
式(5)的求解過程分為稀疏編碼和字典更新兩個步驟。
首先,在稀疏編碼階段,隨機矩陣初始化字典
分別對聯合稀疏系數矩陣a中每一列的非零元素進行處理,而保持零元素完備,則式(6)可以轉換為下式:
式中,
其次,在字典更新階段,式(5)的優化問題可以轉化為:
則式(8)的補償項可以寫為:
式中,
最后,循環執行稀疏編碼和字典更新這兩個階段,直至達到預設的迭代次數為止,輸出一對耦合的dc和dr字典。然后使用以下方法對字典dc和dr進行融合:
lc(n)和lr(n),n=1,2,…,n分別代表ct字典和mr字典的第n個原子的特征指標,由于腦部ct和mr圖像是對應于人體同一部位由不同成像設備獲取的圖像,因此兩者之間一定存在著公共特征和各自特征。本發明提出將特征指標相差較大的原子看作各自特征,使用“選擇最大”規則融合。特征指標相差較小的原子看作公共特征,使用“平均”的規則融合,公式表示如下:
此處設λ=0.25,根據醫學圖像的物理特性,使用信息熵作為特征指標。這種方法將稀疏域和空間域的方法結合起來,考慮了醫學圖像的物理特性計算字典原子的特征指標,與稀疏域的方法相比,具有更加明確的物理意義。
由于字典更新階段同時更新字典和稀疏表示系數的非零元素,使得字典的表示誤差更小且字典的收斂速度更快。在稀疏編碼階段,考慮到每次迭代時都忽略前一次迭代的表示,coefromp算法提出利用上次迭代的稀疏表示殘差信息進行系數更新,從而更快地得到所要求問題的解。
計算得到融合字典df后,將稀疏系數的l2范數作為源圖像的活躍度測量,則稀疏系數
均值
其中,
步驟300,重建階段:對所有的圖像塊都執行上述兩個步驟以得到所有圖像塊的融合結果。對于每個塊向量
為驗證本發明方法的有效性,選取三組已經配準的腦部ct/mr圖像進行融合,分別為正常腦部ct/mr如圖3中a和b所示,腦萎縮ct/mr如圖4中a和b所示,腦腫瘤ct/mr如圖5中a和b所示,圖片大小均為256×256。選取的對比算法有:離散小波變換(dwt)、平穩小波變換(swt)、非下采樣contourlet變換(nsct)、傳統稀疏表示的方法(srm)、基于k-svd字典學習的方法(srk)、基于多尺度字典學習的方法(mdl),融合結果分別見圖3中c、d、e、f、g、h,圖4中c、d、e、f、g、h和圖5中c、d、e、f、g、h。
基于多尺度變換的方法中,對于dwt和swt方法,分解水平都設為3,小波基分別設為“db6”和“bior1.1”。nsct方法使用“9-7”金字塔濾波器和“c-d”方向濾波器,分解水平設為{22,22,23,24}。基于稀疏表示的方法中滑動步長為1,圖像塊大小均為8×8,字典大小均為64×256,誤差ε=0.01,稀疏度τ=6,icdl方法使用改進的k-svd算法,執行6個多重字典更新周期(duc)和30次迭代。
由圖3-5可以看出,dwt方法的融合圖像邊緣紋理模糊,圖像信息失真且存在塊效應;與dwt方法相比,swt和nsct方法的融合質量相對較好,圖像的亮度、對比度、清晰度有了很大的提升,但仍存在邊緣亮度失真,軟組織和病灶區域存在偽影的問題;srm和srk方法較基于多尺度變換的方法圖像的骨組織和軟組織更加清晰,偽影也有所減少,能很好地識別病灶區域;mdl方法與srm和srk方法相比能保留更多的細節信息,圖像質量取得進一步的改善,但仍有部分偽影存在;本發明提出的icdl方法在圖像的亮度、對比度、清晰度和細節的保持度上都優于其他方法,融合圖像沒有偽影,骨組織、軟組織和病灶區域顯示清晰,有助于醫生診斷。
本領域內的技術人員應明白,本發明的實施例可提供為方法、系統、或計算機程序產品。因此,本發明可采用完全硬件實施例、完全軟件實施例、或結合軟件和硬件方面的實施例的形式。而且,本發明可采用在一個或多個其中包含有計算機可用程序代碼的計算機可用存儲介質(包括但不限于磁盤存儲器、cd-rom、光學存儲器等)上實施的計算機程序產品的形式。
本發明是參照根據本發明實施例的方法、設備(系統)、和計算機程序產品的流程圖和/或方框圖來描述的。應理解可由計算機程序指令實現流程圖和/或方框圖中的每一流程和/或方框、以及流程圖和/或方框圖中的流程和/或方框的結合。可提供這些計算機程序指令到通用計算機、專用計算機、嵌入式處理機或其他可編程數據處理設備的處理器以產生一個機器,使得通過計算機或其他可編程數據處理設備的處理器執行的指令產生用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的裝置。
這些計算機程序指令也可存儲在能引導計算機或其他可編程數據處理設備以特定方式工作的計算機可讀存儲器中,使得存儲在該計算機可讀存儲器中的指令產生包括指令裝置的制造品,該指令裝置實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能。
這些計算機程序指令也可裝載到計算機或其他可編程數據處理設備上,使得在計算機或其他可編程設備上執行一系列操作步驟以產生計算機實現的處理,從而在計算機或其他可編程設備上執行的指令提供用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的步驟。
盡管已描述了本發明的優選實施例,但本領域內的技術人員一旦得知了基本創造性概念,則可對這些實施例作出另外的變更和修改。所以,所附權利要求意欲解釋為包括優選實施例以及落入本發明范圍的所有變更和修改。
顯然,本領域的技術人員可以對本發明進行各種改動和變型而不脫離本發明的精神和范圍。這樣,倘若本發明的這些修改和變型屬于本發明權利要求及其等同技術的范圍之內,則本發明也意圖包含這些改動和變型在內。
- 還沒有人留言評論。精彩留言會獲得點贊!