一種面向區塊鏈多級智能合約的數據遷移方法與流程
本發明涉及區塊鏈技術、智能合約、緩存及多線程技術,尤其涉及一種多級智能合約升級時的數據遷移方法。
背景技術:
區塊鏈技術,區塊鏈是一種新型去中心化協議,能安全地存儲數字貨幣交易或其他數據,信息不可偽造和篡改,區塊鏈上的交易確認由區塊鏈上的所有節點共同完成,由共識算法保證其一致性,區塊鏈上維護一個公共的賬本,用于存儲區塊鏈網絡上所有用戶的余額,公共賬本位于存儲區塊上任何節點可見,從而保證其不可偽造和篡改。
智能合約,區塊鏈上的智能合約是指由solidity編寫和編譯并運行與區塊鏈上的一串二進制代碼,我們可以通過智能合約實現在區塊鏈上的數據存儲、讀寫以及一些邏輯操作,因此一些基于區塊鏈的應用是利用智能合約完成的。
緩存及多線程技術,緩存是指當程序需要讀取數據時,事先將需要讀取的數據置于緩存中,程序優先從緩存讀取數據。由于緩存的運行速度比內存塊很多,所以緩存可以極大加快程序讀取數據速度。多線程是指程序在進行一些計算比較密集的操作時,采用多線程來處理,充分利用cpu核心數,提高cpu效率。
技術實現要素:
本發明的目的是針對現有區塊鏈技術的不足,提供一種面向區塊鏈多級智能合約的數據遷移方法。
由于區塊鏈本身的特性,一般使用智能合約的區塊鏈應用上線以后,如果要應用的版本需求需要更新,就意味著得重新部署合約,并生成新的合約地址。之后系統將使用新的合約,由于舊的數據不能被摒棄,此時就需要將舊的合約數據遷移到新的合約中。
本發明的目的是通過以下技術方案來實現:在不改變區塊鏈合約數據的情況下,確保安全高效的將舊有的合約數據遷移到新的合約中,尤其涉及有調用關系的多級合約數據遷移情況,包括如下步驟:
1)對于有多個合約相互調用的智能合約系統,使用樹狀模型逐級遷移合約數據,樹狀模型中父節點合約調用子節點合約;
2)部署頂層節點的合約,遷移頂層合約除子節點合約地址以外的數據;
3)判斷當前合約所在節點是否為葉子節點,若當前節點不是葉子節點,則讀取當前節點的子節點的合約地址,對子合約重復進行該判斷;若當前節點是葉子節點,進入步驟4);
4)部署葉子節點的新合約并遷移該合約的數據,存儲葉子節點的合約地址;
5)遍歷所有合約節點,若合約所在節點的所有子節點的數據遷移完畢,開始部署新的當前合約,遷移合約數據并存儲所有子節點合約的新地址;否則,讀取沒有完成數據遷移的子合約地址,進行步驟3);
6)重復進行步驟3)到步驟5),直至當前合約所在節點為頂層節點,遷移頂層合約的所有子合約的合約地址參數。
進一步地,所述的步驟1)中對于有相互調用的多個合約構造樹狀模型,首先應構造樹狀模型明確合約間的調用關系,其中父節點合約中有調用子節點合約方法,其中一個合約可以調用多個子合約,一個子合約可以被多個合約調用。
進一步地,所述的步驟2)中,合約遷移時會部署新的合約,每一個合約都有唯一的合約地址。遷移頂層合約數據時應當除去舊的合約地址,只有所有子節點合約數據全部遷移完畢后,父節點合約才開始數據遷移,合約地址的遷移應當以新部署的合約為主。
進一步地,在調用合約方法遷移合約數據前需要將私鑰緩存,基于區塊鏈本身的特性,每次調用智能合約方法時都需要私鑰進行簽名,而私鑰通常被加密為一個私鑰文件存在。因此,可以將私鑰文件事先解密存放在緩存中,基于緩存文件的高效讀取速度,調用合約方法時效率更高。
進一步地,在遷移合約數據時,由于合約數據遷移時會不斷執行合約的讀寫操作,可以采用多線程的方法來充分利用cpu的核心數。這樣合約數據遷移方法可以支持區塊鏈上的大數量級的數據遷移,并確保在新的合約系統中有效使用舊合約的相關數據。
本發明的有益效果是:本發明在面向區塊鏈多級智能合約的數據遷移中構造合約調用樹狀模型來安全遷移合約數據,以及在遷移數據時利用緩存和多線程的技術,實現了復雜智能合約的數據遷移。對于一般的沒有調用關系的智能合約的數據遷移,做法是直接調用舊合約的get方法和新合約的set方法即可完成數據遷移,但是對于有調用關系的多個合約的數據遷移,直接遷移數據會破壞原有的合約調用關系。為保證合約數據及其調用邏輯完整的遷移到新部署的合約系統,本發明在多級智能合約數據遷移中使用樹狀模型調整合約遷移時的順序及遷移內容的選擇,并且利用私鑰緩存和多線程智能合約讀寫技術進一步完善合約數據遷移效率,這樣即使是復雜的智能合約系統也可以完整遷移到新的合約系統而無需擔心其調用邏輯被破壞。本發明有效地解決了面向多級智能合約的數據遷移問題。
附圖說明
圖1是本發明多級智能合約數據遷移方法的步驟流程圖;
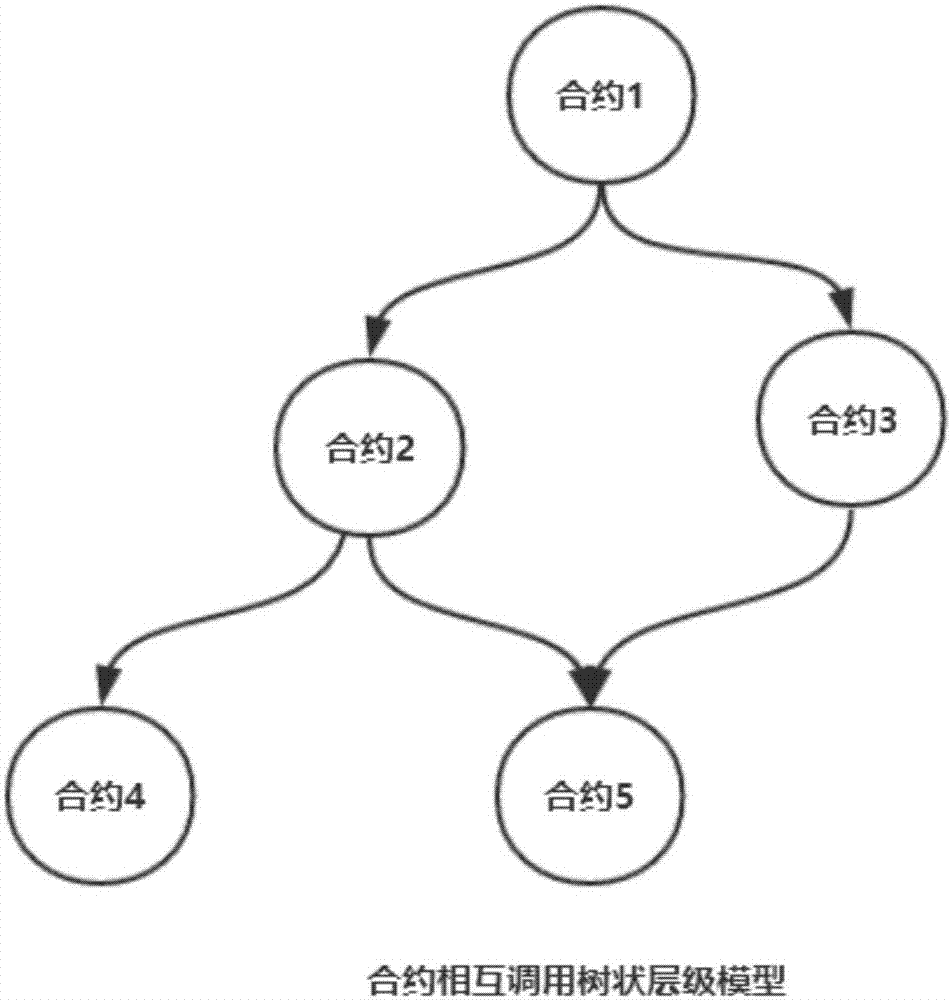
圖2是本發明實施例的多級智能合約的樹狀模型圖;
圖3是本發明實施例的合約數據遷移具體過程圖。
具體實施方式
下面根據附圖和具體實施例詳細描述本發明,本發明的目的和效果將變得更加明顯。
如圖1所示,本發明方法,包括如下步驟:
1)對于有多個合約相互調用的智能合約系統,如圖2所示,使用樹狀模型逐級遷移合約數據,樹狀模型中父節點合約調用子節點合約;
2)部署頂層節點的合約,遷移頂層合約除子節點合約地址以外的數據;
3)判斷當前合約所在節點是否為葉子節點,若當前節點不是葉子節點,則讀取當前節點的子節點的合約地址,對子合約重復進行該判斷;若當前節點是葉子節點,進入步驟4);
4)部署葉子節點的新合約并遷移該合約的數據,存儲葉子節點的合約地址;
5)遍歷所有合約節點,若合約所在節點的所有子節點的數據遷移完畢,開始部署新的當前合約,遷移合約數據并存儲所有子節點合約的新地址;否則,讀取沒有完成數據遷移的子合約地址,進行步驟3);
6)重復進行步驟3)到步驟5),直至當前合約所在節點為頂層節點,遷移頂層合約的所有子合約的合約地址參數。
進一步地,所述的步驟1)中對于有相互調用的多個合約構造樹狀模型,首先應構造樹狀模型明確合約間的調用關系,其中父節點合約中有調用子節點合約方法,其中一個合約可以調用多個子合約,一個子合約可以被多個合約調用。
進一步地,所述的步驟2)中,合約遷移時會部署新的合約,每一個合約都有唯一的合約地址。因此,遷移頂層合約數據時應當除去舊的合約地址,并且只有所有子節點合約數據全部遷移完畢后,父節點合約才開始數據遷移,合約地址的遷移應當以新部署的合約為主。
進一步地,如圖3所示,在調用合約方法前需要將私鑰緩存,基于區塊鏈本身的特性,每次調用智能合約方法時都需要私鑰進行簽名,而私鑰通常被加密為一個私鑰文件存在。因此,可以將私鑰文件事先解密存放在緩存中,基于緩存文件的高效讀取速度,調用合約方法時效率更高;
進一步地,如圖3所示,在遷移合約數據時采用多線程的方法執行合約方法,由于合約數據遷移時會不斷執行合約的讀寫操作,可以采用多線程的方法來充分利用cpu的核心數。這樣合約數據遷移方法可以支持區塊鏈上的大數量級的數據遷移,并確保在新的合約系統中有效使用舊合約的相關數據。
下面用一個具體的智能合約遷移實例來說明具體的實施方式:
模擬一個面向多級區塊鏈智能合約的數據遷移,如圖2所示,合約1中有兩個變量contract1addrs[]和contract2addrs[]分別存儲了所有合約2的地址和所有合約3的地址。合約2中也有兩個變量contract3addrs[]和contract4addrs[]分別存儲了所有合約4的地址和所有合約5的地址。合約3中也有變量contract5addrs[]存儲所有合約5的地址。
首先,在正式遷移合約數據前,我們判斷該智能合約系統是一個有相互調用關系的多級智能合約系統。通過合約調用關系的樹狀模型(圖2所示),可以知道合約1調用合約2和合約3,合約2調用合約4和合約5,合約3調用合約5。根據步驟2)、步驟3)、步驟4)和步驟5),首先部署新的合約4和合約5,并遷移合約數據,存儲新合約的地址。此時,合約2和合約3的所有子節點合約已經遷移完畢,部署新的合約2和合約3,遷移除合約地址外的所有數據,最后存儲新的合約4和合約5的地址。最后一步,合約1的所有子節點合約全部遷移完成,部署新的合約1,遷移除合約地址外的所有數據,存儲新的合約2和合約3的地址。到此,該多級智能合約系統的數據遷移完畢。
- 還沒有人留言評論。精彩留言會獲得點贊!