融合Boost模型的非平衡數據自適應采樣方法與流程
技術領域:
:本發明屬于大數據處理
技術領域:
,具體涉及一種融合boost模型的非平衡數據自適應采樣方法。
背景技術:
::目前,針對不平衡數據的處理已經成為大數據處理
技術領域:
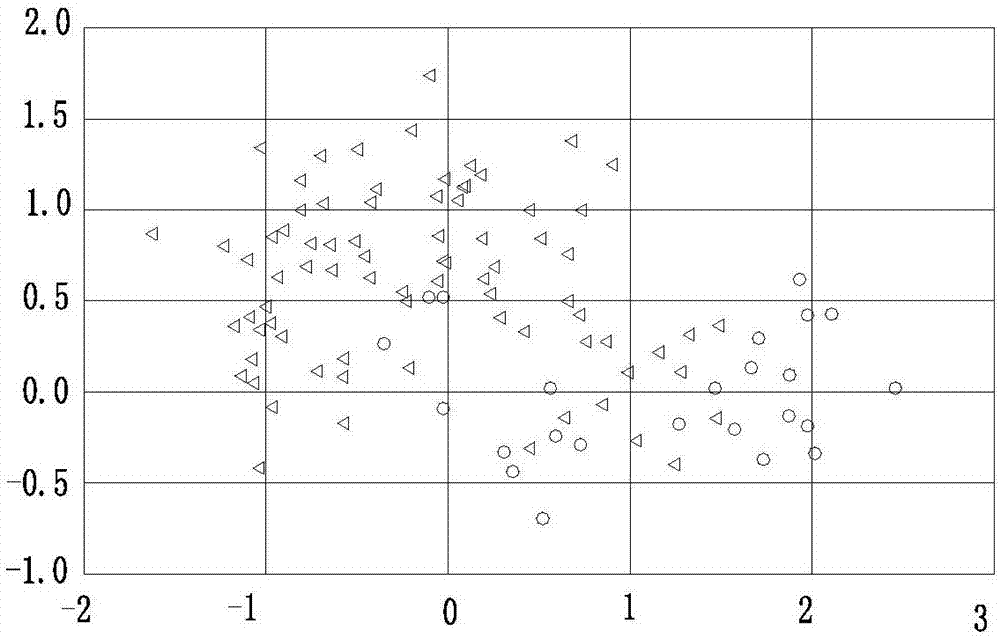
中的一個熱門研究主題。不平衡數據在研究與實際工作中往往難以避免,如醫學大數據、征信大數據、智能商業金融數據等等。而由于不平衡數據的類別樣本比例懸殊性,高維度數據的畸變性,導致了可用類別的信息在樣本結構和特征維度兩個層面被大類別信息掩蓋,使得之后的數據挖掘往往難以學習到目標信息。為優化數據分布,學術界著重研究欠采樣以及過采樣技術,以圖利用采樣技術縮減大類樣本或者擴充小類樣本。其中主要技術是:smote采樣技術以及其衍生算法、更多的融合算法。smote及其衍生等各鐘傳統的數據合成方式,雖然能有效生成小類樣本,但是其存在幾個主要的不足之處是1:將數據合成作為單獨的過程考慮,僅基于距離進行數據生成,有一定盲目性;2:對各類特征等同看待,使得主要特征被冗余特征干擾;3:算法目的單一,導致更復雜的數據冗余情況;4:生成的數據往往難以契合之后的識別要求,需要反復的隨機測試。李克文、楊磊等人發表的論文“基于rsboost算法的不平衡數據分類方法”(計算機科學,2015,tp181)中公開了一種將smote采樣和boost模型相結合進行不平衡數據集分類的方法。該方法首先使用smote算法增加少數類的數量后在保持數據分布的情況下對整數數據集進行隨機欠采樣,再與adaboost算法相結合對數據進行分類;其將采樣和分類作為串行的步驟,先用smote算法增加少數類的數量再隨機采樣從而減少數據集的規模,以增加模型識別精度的同時保證模型訓練速度。但是此算法只是算法的拼接,將smote算法加入到boost模型的訓練之前,以圖調整數據分布和規模后使用boost模型來提升分類準確度,其沒有從根本上解決不平衡數據采樣中存在的盲目性和重復性問題,同時不能規避傳統smote算法的諸多不足。雖然其采用adaboost模型有一定可取之處,但是針對不平衡數據采樣的盲目將導致數據性能的天花板。胡小生,溫菊屏等發表的論文“動態平衡采樣的不平衡數據集成分類方法”(智能系統學報,2016,tp181)中提出一種動態平衡數據采樣與boosting技術相結合的不平衡數據集成分類算法。其將smote算法嵌入到boosting模型學習的每一次迭代中,即每次迭代初始,綜合使用隨機欠采樣和smote過采樣技術平衡規模的訓練數據,然后進行相應子模型的訓練,最后將所有子模型組合投票進行。該方法雖然一定程度上將采樣融合到模型訓練中,有效提高了模型的分類準確度,但是,仍然存在的不足之處是,該方法本質上并沒有涉及到對于采樣技術的優化,而采樣技術的性能瓶頸正是目前解決不平衡問題的關鍵所在。該方法依然停留在傳統采樣技術的弊端上,得到的實際效果并沒有很大提高。技術實現要素::本發明所要解決的技術問題在于克服現有的技術缺陷,提供一種融合boost模型的非平衡數據自適應采樣方法,將模型對數據的認知加入到采樣中,提升了采樣過程中對于小類樣本的偏重,同時結合權重特征空間的位置關系,強化了數據生成的準確度以及適應性,有針對地提升了平衡化后數據的性能,同時有效解決了傳統采樣技術對特征信息的破壞以及在高維數據上的不適用問題。本發明所要解決的技術問題采用以下的技術方案來實現:采用boost模型學習當前數據,取得模型評分與特征權重;使用當前模型評分對特征權重進行更新;使用當前模型判定數據集中的pure數據集合、danger數據集合和noise數據集合;結合特征權重進行數據位置度量,獲取數據近鄰,同時判定基于加權特征空間距離的pure數據集合、danger數據集合和noise數據集合;將模型判定的三類數據集合和特征空間距離判定的三類數據集合相結合,生成小類樣本同時去除大類樣本;將新數據集加入模型學習。重復以上過程直至滿足自定義類別樣本占比,或者各類樣本數量基本穩定,則提前停止。其具體步驟如下:(1)算法初始化,即t=0情況(1a)boost模型初始化,即依據數據規模設定boost參數;(1b)特征權重初始化為等權重;(1c)數據特征類別初始化f,分為連續型特征和離散型特征;(1d)自定義各類別數據目標占比;(2)第t次迭代,訓練boost樹模型,然后獲取特征權重與當前模型的f-score評分,同時取得模型定義的pure、danger、noise數據集合;(2a)采用boost樹模型,用預定義參數以及當前數據進行模型的訓練;(2b)完成模型訓練后,采用weightedf-score對模型進行評分,得到當前模型的相應評分,同時獲取當前模型對特征重要性的評分,最終結合第t-1次迭代的特征權重,完成特征權重的更新;(2c)利用第t-1次和第t次模型的評分差,進行算法退出與否的判斷,具體為:若模型的評分有較大下降則退出算法;(2d)利用模型對當前數據集進行預測,分別取得danger數據集、pure數據集和noise數據集,分別定義如下:pure數據集:判別正確且判斷概率高于預定義閾值的樣本點集合;danger數據集:判定概率小于預定義閾值的樣本點集合;noise數據集:判錯且判定概率大于預定義閾值的樣本點集合;(3)計算樣本點在加權特征空間的位置關系,并依據距離位置關系定義danger、pure、noise數據集合;(3a)利用(2)中更新得到的特征權重,計算數據集在此加權特征空間中的距離;主要方法為:對于連續型特征計算加權歐氏距離,對于離散型特征采用函數f進行計算,其中f定義為兩個樣本點特征值于同類樣本對應特征中數值占比之差;(3b)使用(3a)中的距離度量方式,獲取樣本點之間的相應位置關系,并基于此位置關系定義danger數據集、pure數據集和noise數據集,分別為:pure數據集:樣本點的m個相鄰樣本點均與其同類;danger數據集:樣本點的m個相鄰樣本點有與其不同類;noise數據集:樣本點的m個相鄰樣本點小于與其不同類;(4)將(2)和(3)中分別得到的danger數據集、pure數據集和noise數據集進行融合,形成待刪除樣本點集合和用于生成新樣例的樣本點集合;(4a)采用集合運算的方式將(2)和(3)中得到的三類數據集分別進行融合,得到pure融合集、danger融合集以及noise融合集,分別定義如下:pure融合集:樣本點同屬于模型定義pure集和加權特征空間定義pure集;danger融合集:樣本點不屬于模型定義danger集,而屬于加權特征空間定義danger集;noise融合集:樣本點屬于模型定義noise集或者屬于加權特征空間定義noise集;(4b)完成上述融合方式后,利用融合數據集合生成待刪除數據集以及待生成新樣本點的數據集,分別定義如下:pure刪除集:屬于pure融合集,且標簽屬于大類的樣本點;noise刪除集:屬于noise融合集,且標簽屬于大類的樣本點;repeat刪除集:于加權特征空間中重疊的所有樣本點;pure創建集:屬于pure融合集且類標簽屬于小類的樣本點;danger創建集:屬于danger融合集,且標簽屬于小類的樣本點;(4c)由上述四個數據集出發,進行大類冗余數據的刪除以及新數據的合成;根據當前情況,從現有數據集中刪除包含在repeat數據集中的所有樣本點,并依據一定規則從現有數據集中刪除pure刪除集和noise刪除集中存在的樣本點;同時,由pure創建集和danger創建集中創建新的樣本點,具體辦法為:對于創建集中每一個樣本點,取得其加權特征空間的近鄰,利用此樣本點和其各個近鄰進行新樣本點的生成;生成新樣本點時,對不同類型特征做不同的處理,對于數值型特征直接取兩樣本點的均值,對于目錄型特征依據同類樣本當前特征值出現概率選擇兩樣本點特征值其一;(4d)為防止新生成樣本點過于密集導致之后數據整體性能的下降,在4(c)中使用兩個樣本點創建新樣本時,計算二者在加權特征空間中的距離;待新樣本點集合生成完畢后,按照每個樣本點對應的合成距離進行排序,選取對應距離最大的前一半新合成數據作為創建數據集加入到原數據集中;(5)判斷是否結束算法迭代,即判定各個類別是否滿足預期樣本數量,方法為:對于每一個類別計數其對應樣本數量,若一定程度上滿足預期數量,則將此類加入已符合要求類集合中,所有類均加入到此集合中時,則停止迭代,退出算法;或者當所有類中樣本當前數量穩定基本不再變化,則停止迭代,退出算法,否則執行(2),跳轉到第t+1次迭代過程;還包括以下步驟:a.加權特征空間的思想;使用模型學習當前數據后得到的特征評分作為數據特征的權重,度量數據在此加權特征空間的位置關系;b.步驟(2)和步驟(3)中的boost模型認知數據后定義數據集和加權特征空間定義數據集,具體為:boost模型學習數據后,按(2d)定義三類樣本集,基于boost模型特征評分的加權特征空間,按(3a)度量距離,然后按3(b)定義三類樣本集;c.步驟(4)中的多信息定義數據集的融合與多類型采樣集的生成;對boost模型定義三類數據集和加權特征空間定義三類數據集的融合,從而得到各類樣本刪除集與樣本創建集,具體為:將boost模型與加權特征空間定義的pure、danger、noise樣本集,按4(a)中所述進行相應融合,之后按照4(b)中所述分別得到各類刪除集與創建集;d.新樣本集合創建方式;由待創建樣本集中樣本點生成新的樣本點時采用特征類型相關的合成方式,在新樣本集合生成完畢后,使用樣本合成距離進行排序,選取合成距離大的一半作為新創建數據集加入到原數據集中;e.算法整體上采用模型信息和特征空間信息融合的方式進行迭代采樣,具體為:每一次迭代,進行模型對數據的學習和數據在加權特征空間位置關系的度量,結合當前信息指導采樣,這樣不斷整合信息進行迭代采樣,最終完成算法。本發明的有益效果為:1、由于本發明將boost模型的學習與不均衡數據的采樣作為一個整體進行處理,使得模型對樣本的學習和采樣互為補充,即模型學習到現有樣本的實際情況,為采樣提供數據中各類別的可學習情況與具體樣本點屬性,指導采樣的進行,而采樣所得新數據集提升模型的學習效果,二者作為一個整體反復迭代直至最優或者目標數據集。2、使用當前boost模型對特征進行評分,利用此特征評分作為權重度量樣本點在加權特征空間的位置關系,在高維數據中往往無關特征權重極小甚至為0,克服了冗余特征的干擾,同時降低數據維度,有利于樣本點位置關系的度量。3、在前述基礎上,本發明同時基于模型定義數據和加權特征空間位置關系定義數據,融合后形成多個不同角度的數據集,從而多角度獲取當前數據信息以引導非平衡數據集的采樣,克服了采樣的盲目性,使得采樣數據能不斷補充和優化當前數據集。4、本發明融合了傳統采樣技術的優勢,即加強并優化了smote及其衍生算法對小類的過采樣能力,同時兼顧了欠采樣技術和數據清理技術對冗余、重復數據的清理能力,使得算法在提高數據豐富度的同時,兼顧了數據的可識別度與精簡度。進一步地,本發明針對不同類型特征做出不同的處理,使得生成的新數據保持了原有數據特征的固有性質,同時又豐富了各類別樣本的信息含量,在保持特征屬性的同時極大提升數據性能。附圖說明:圖1為本發明的流程圖;圖2為二維原始數據分布圖;圖3為三維原始數據分布圖;圖4為傳統經典算法smote進行平衡性調整之后的二維數據分布圖;圖5為傳統經典算法smote進行平衡性調整之后的三維數據分布圖;圖6為傳統經典算法smote-borderline平衡性調整之后的二維數據分布圖;圖7為傳統經典算法smote-borderline平衡性調整之后的三維數據分布圖;圖8為本發明算法平衡后的二維數據分布圖;圖9為本發明算法平衡后的三維數據分布圖。具體實施方式:為了使本發明實現的技術手段、創作特征、達成目的與功效易于明白了解,下面結合具體圖示,進一步闡述本發明。采用boost模型學習當前數據,取得模型評分與特征權重;使用當前模型評分對特征權重進行更新;使用當前模型判定數據集中的pure數據集合、danger數據集合和noise數據集合;結合特征權重進行數據位置度量,獲取數據近鄰,同時判定基于加權特征空間距離的pure數據集合、danger數據集合和noise數據集合;將模型判定的三類數據集合和特征空間距離判定的三類數據集合相結合,生成小類樣本同時去除大類樣本;將新數據集加入模型學習。重復以上過程直至滿足自定義類別樣本占比,或者各類樣本數量基本穩定,則提前停止。其具體步驟如下:(1)算法初始化,即t=0情況(1a)boost模型初始化,即依據數據規模設定boost參數;(1b)特征權重初始化為等權重;(1c)數據特征類別初始化f,分為連續型特征和離散型特征;(1d)自定義各類別數據目標占比;(2)第t次迭代,訓練boost樹模型,然后獲取特征權重與當前模型的f-score評分,同時取得模型定義的pure、danger、noise數據集合;(2a)采用boost樹模型,用預定義參數以及當前數據進行模型的訓練;(2b)完成模型訓練后,采用weightedf-score對模型進行評分,得到當前模型的相應評分,同時獲取當前模型對特征重要性的評分,最終結合第t-1次迭代的特征權重,完成特征權重的更新;(2c)利用第t-1次和第t次模型的評分差,進行算法退出與否的判斷,具體為:若模型的評分有較大下降則退出算法;(2d)利用模型對當前數據集進行預測,分別取得danger數據集、pure數據集和noise數據集,分別定義如下:pure數據集:判別正確且判斷概率高于預定義閾值的樣本點集合;danger數據集:判定概率小于預定義閾值的樣本點集合;noise數據集:判錯且判定概率大于預定義閾值的樣本點集合;(3)計算樣本點在加權特征空間的位置關系,并依據距離位置關系定義danger、pure、noise數據集合;(3a)利用(2)中更新得到的特征權重,計算數據集在此加權特征空間中的距離;主要方法為:對于連續型特征計算加權歐氏距離,對于離散型特征采用函數f進行計算,其中f定義為兩個樣本點特征值于同類樣本對應特征中數值占比之差;(3b)使用(3a)中的距離度量方式,獲取樣本點之間的相應位置關系,并基于此位置關系定義danger數據集、pure數據集和noise數據集,分別為:pure數據集:樣本點的m個相鄰樣本點均與其同類;danger數據集:樣本點的m個相鄰樣本點有與其不同類;noise數據集:樣本點的m個相鄰樣本點小于與其不同類;(4)將(2)和(3)中分別得到的danger數據集、pure數據集和noise數據集進行融合,形成待刪除樣本點集合和用于生成新樣例的樣本點集合;(4a)采用集合運算的方式將(2)和(3)中得到的三類數據集分別進行融合,得到pure融合集、danger融合集以及noise融合集,分別定義如下:pure融合集:樣本點同屬于模型定義pure集和加權特征空間定義pure集;danger融合集:樣本點不屬于模型定義danger集,而屬于加權特征空間定義danger集;noise融合集:樣本點屬于模型定義noise集或者屬于加權特征空間定義noise集;(4b)完成上述融合方式后,利用融合數據集合生成待刪除數據集以及待生成新樣本點的數據集,分別定義如下:pure刪除集:屬于pure融合集,且標簽屬于大類的樣本點;noise刪除集:屬于noise融合集,且標簽屬于大類的樣本點;repeat刪除集:于加權特征空間中重疊的所有樣本點;pure創建集:屬于pure融合集且類標簽屬于小類的樣本點;danger創建集:屬于danger融合集,且標簽屬于小類的樣本點;(4c)由上述四個數據集出發,進行大類冗余數據的刪除以及新數據的合成;根據當前情況,從現有數據集中刪除包含在repeat數據集中的所有樣本點,并依據一定規則從現有數據集中刪除pure刪除集和noise刪除集中存在的樣本點;同時,由pure創建集和danger創建集中創建新的樣本點,具體辦法為:對于創建集中每一個樣本點,取得其加權特征空間的近鄰,利用此樣本點和其各個近鄰進行新樣本點的生成;生成新樣本點時,對不同類型特征做不同的處理,對于數值型特征直接取兩樣本點的均值,對于目錄型特征依據同類樣本當前特征值出現概率選擇兩樣本點特征值其一;(4d)為防止新生成樣本點過于密集導致之后數據整體性能的下降,在4(c)中使用兩個樣本點創建新樣本時,計算二者在加權特征空間中的距離;待新樣本點集合生成完畢后,按照每個樣本點對應的合成距離進行排序,選取對應距離最大的前一半新合成數據作為創建數據集加入到原數據集中;(5)判斷是否結束算法迭代,即判定各個類別是否滿足預期樣本數量,方法為:對于每一個類別計數其對應樣本數量,若一定程度上滿足預期數量,則將此類加入已符合要求類集合中,所有類均加入到此集合中時,則停止迭代,退出算法;或者當所有類中樣本當前數量穩定基本不再變化,則停止迭代,退出算法,否則執行(2),跳轉到第t+1次迭代過程;還包括以下步驟:a.加權特征空間的思想;使用模型學習當前數據后得到的特征評分作為數據特征的權重,度量數據在此加權特征空間的位置關系;b.步驟(2)和步驟(3)中的boost模型認知數據后定義數據集和加權特征空間定義數據集,具體為:boost模型學習數據后,按(2d)定義三類樣本集,基于boost模型特征評分的加權特征空間,按(3a)度量距離,然后按3(b)定義三類樣本集;c.步驟(4)中的多信息定義數據集的融合與多類型采樣集的生成;對boost模型定義三類數據集和加權特征空間定義三類數據集的融合,從而得到各類樣本刪除集與樣本創建集,具體為:將boost模型與加權特征空間定義的pure、danger、noise樣本集,按4(a)中所述進行相應融合,之后按照4(b)中所述分別得到各類刪除集與創建集;d.新樣本集合創建方式;由待創建樣本集中樣本點生成新的樣本點時采用特征類型相關的合成方式,在新樣本集合生成完畢后,使用樣本合成距離進行排序,選取合成距離大的一半作為新創建數據集加入到原數據集中;e.算法整體上采用模型信息和特征空間信息融合的方式進行迭代采樣,具體為:每一次迭代,進行模型對數據的學習和數據在加權特征空間位置關系的度量,結合當前信息指導采樣,這樣不斷整合信息進行迭代采樣,最終完成算法。結合附圖,對實現本發明的檢驗仿真描述如下。本發明可以通過以下仿真進一步說明:1:仿真條件本發明仿真的硬件環境是:cpuamdathlon(tm)ⅱx2280processor3.50ghz,8gb內存;軟件環境:ubuntu14.04,sublime3;數據集:數據集名稱樣本總量各類樣本數量特征維度隨機生成樣本1200:1001:25二維隨機生成樣本1800:1501:30三維germam數據集10001:7002:30020維2.仿真內容和結果分析:仿真1.通過隨機生成樣本的方式,生成附圖2、3中的二維仿真數據集和三維仿真數據集,其中二維仿真數據集類0和類1之比為:4:1,三維仿真數據集類0和類1之比為5:1。針對當前數據集,使用本文所述算法進行數據平衡性的調整,同時使用經典算法進行調整,完成對比。仿真實驗1的結果如圖2-9所示,附圖2-9圖像的類0樣本標為“圓點系”,類1樣本標為“三角形系”,同時在三維數據中,x,y軸均為數值化特征,z軸為離散化特征。圖4、5為smote平衡后的數據分布圖,圖6、7的smote-borderline平衡后的數據分布圖,本發明算法平衡后的數據分布圖為圖8、9;對比可以觀察到,本發明算法優點為1.擴充小類樣本點的同時,濾去合成樣本中的重復樣本,并去除了大類中冗余的樣本點;2.有效清除了“噪音點”,并清晰化數據分布邊界;3.在小類中合成樣本均勻,分布合理,有效提高小類樣本豐富度;4.保留原有特征結構;5.引導合成樣本點向決定小類樣本點分布的特征擴散。注:“噪音點”即為類0嵌入到類1區域的樣本點,類1嵌入到類0中的樣本點。仿真2:使用來自uci的真實數據集german,其中類1和類2的比為:3:1,其擁有20維特征。隨機取出類1樣本600個,類2樣本150個作為采樣集合,另外類1樣本100個,類2樣本150個作為采樣后的數據性能評價集。主要思路是:使用本發明算法以及經典算法中的smote、smote-borderline以及smote-tomeklinks算法對采樣集合進行數據的平衡性調整,在調整的數據集上訓練模型,然后使用訓練后模型對評價集進行預測,對類0和類1分別得到三類評分:precious、recall、f-score。以上過程重復10次,求取均值得到結果。本發明仿真實驗2結果見表1所示。顯然,通過表格中數據可以看到,本采樣算法得到的平衡數據性能更高,在維持大類可識別性性的情況下,極大程度地提升了小類的可識別力,使得平衡后數據擁有了更大的可實際使用價值和學習價值。上述兩個仿真實驗表明,本發明的方法為不平衡數據集的平衡化提供了一個有力的方法。經過本采樣算法平衡化后的數據在結構和性能上均有很高的提高,同時使得少數類的可識別性得到了關鍵的提升。以上顯示和描述了本發明的基本原理和主要特征和本發明的優點。本行業的技術人員應該了解,本發明不受上述實施例的限制,上述實施例和說明書中描述的只是說明本發明的原理,在不脫離本發明精神和范圍的前提下,本發明還會有各種變化和改進,這些變化和改進都落入要求保護的本發明范圍內。本發明要求保護范圍由所附的權利要求書及其等效物界定。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1