一種水體溶解氧預測方法及裝置與流程
本發明涉及水處理技術領域,更具體地,涉及一種水體溶解氧預測方法及裝置。
背景技術:
溶解氧作為水質的一項重要參數,在工廠化水產養殖、日光溫室水培種養中扮演著重要的角色,它很大程度上決定了魚類的生長狀態,所以預測溶解氧的變化趨勢可以為養殖人員的決策提供重要參考,減小養種植風險。
水體溶解氧受到很多因素影響,包括:物理、化學、生物和人為因素。而一些復雜的水循環系統,例如,魚菜共生系統,包括水產養殖、水處理和水培三部分,是一種魚、菜和生物菌三者共生的復合種養系統,該系統不僅對溶解氧的要求很高,而且還極易受到氣象環境、水質參數和生物量的綜合影響。因此,溶解氧的預測極為困難,十分迫切的需要可以應對復雜多變的循環水系統水體溶解氧預測的解決方案。
現有的水體溶解氧預測方法包括:步驟1、獲取并存儲一個時間段內的魚菜共生系統的環境數據及溶解氧數據;步驟2、用歸一化方法對所述環境數據進行數據標準化預處理,獲得模糊神經網絡溶解氧預測控制模型的訓練數據集;步驟3、根據訓練數據集,獲取模糊神經網絡溶解氧預測控制模型;步驟4、將當前溶解氧含量的實時數據輸入模糊神經網絡溶解氧預測控制模型,得到水中的溶解氧含量的預測結果。
但是現有的水體溶解氧預測方法存在預測收斂速度慢、預測精度低以及效率低等問題,而且無法精準快速的處理因環境等外界因素所帶來的數據波動大等問題。
技術實現要素:
針對上述的技術問題,本發明提供一種水體溶解氧預測方法及裝置。
第一方面,本發明提供一種水體溶解氧預測方法,包括:將預測樣本輸入通過訓練基于k-means聚類法分類識別的訓練樣本建立的預測模型,獲得未來第一預設時間段內的溶解氧預測值。
其中,所述方法進一步包括:s1,獲取水質數據、氣象數據及生物量數據各自與溶解氧數據的相關系數,并根據所述相關系數選取模板樣本;s2,通過k-means聚類法按照所述第一預設時間段對所述模板樣本進行分類,在所述分類的模板樣本中識別出與所述預測樣本相似的模板樣本作為訓練樣本;s3,對所述訓練樣本進行訓練,以建立預測模型。
其中,在所述s1之前還包括s0,采集并存儲第二預設時間段內的溶解氧數據、水質數據、氣象數據以及生物量數據。
其中,在所述s0之后、所述s1之前包括:采用線性插值法對所述水質數據進行處理,采用均值平滑法對所述生物量數據進行處理,以及采用小波變化法對所述氣象數據進行處理。
其中,在所述s0之后、所述s1之前還包括:對處理后的所述水質數據、所述氣象數據以及所述生物量數據分別進行歸一化處理。
其中,所述s1進一步包括:根據皮爾森相關系數法獲取所述水質數據、所述氣象數據及所述生物量數據各自與所述溶解氧數據的相關系數。
其中,所述s2中在所述分類的模板樣本中識別出與所述預測樣本相似的模板樣本作為訓練樣本進一步包括:根據基于歐式距離和夾角余弦原理獲取的相似度,在所述分類的模板樣本中識別出與所述預測樣本相似的模板樣本作為訓練樣本。
其中,所述s3中對所述訓練樣本進行訓練進一步包括:采用模糊神經網絡對所述訓練樣本進行訓練。
第二方面,本發明提供一種水體溶解氧預測裝置,包括:預測模塊,用于將預測樣本輸入通過訓練基于k-means聚類法分類識別的訓練樣本建立的預測模型,獲得未來第一預設時間段內的溶解氧預測值。
其中,所述裝置還包括:獲取模塊,用于獲取水質數據、氣象數據以及生物量數據各自與溶解氧數據的相關系數,并根據所述相關系數選取模板樣本;處理模塊,用于通過k-means聚類法按照所述第一預設時間段對所述模板樣本進行分類,在所述分類的模板樣本中識別出與所述預測樣本相似的模板樣本作為訓練樣本;模型建立模塊,用于對所述訓練樣本進行訓練,以建立預測模型。
本發明提供的一種水體溶解氧預測方法及裝置,采用相關系數選取模板樣本,然后采用k-means聚類法按照第一預設時間段對模板樣本進行分類,并在分類的模板樣本中識別出與預測樣本相似的模板樣本作為訓練樣本,再對訓練樣本進行訓練和預測,以建立預測模型,最后將預測樣本輸入預測模型,以獲得預測時刻后一段時間內的溶解氧預測值。該預測方法具有較高的預測精度及較強的適應度,并且在預測穩定性和精度上,有較好的魯棒性和復雜線性映射能力,特別適合于易受環境等外界因素影響的魚菜共生系統的水體溶解氧預測。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作一簡單地介紹,顯而易見地,下面描述中的附圖是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例提供的水體溶解氧預測方法的流程圖;
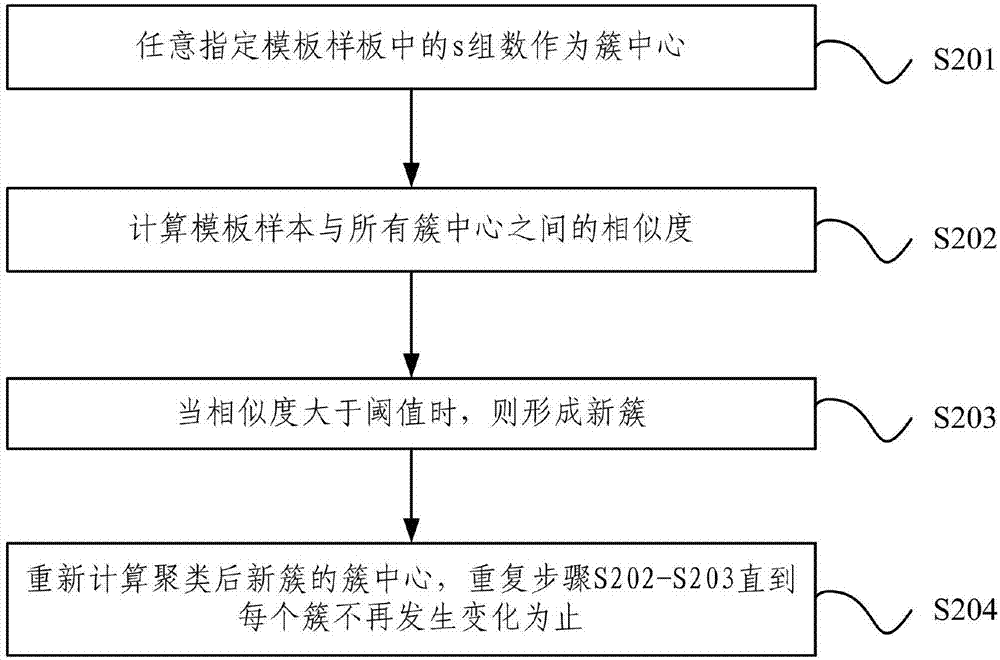
圖2為圖1中所述通過k-means聚類法對所述模板樣本進行分類的流程圖;
圖3為本發明另一實施例提供的水體溶解氧預測方法中模糊神經網絡的拓撲結構示意圖;
圖4為本發明實施例提供的水體溶解氧預測裝置的結構圖。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
圖1為本發明實施例提供的水體溶解氧預測方法的流程圖,如圖1所示,該方法包括:s1,獲取水質數據、氣象數據及生物量數據各自與溶解氧數據的相關系數,并根據所述相關系數選取模板樣本;s2,通過k-means聚類法按照第一預設時間段對所述模板樣本進行分類,在所述分類的模板樣本中識別出與所述預測樣本相似的模板樣本作為訓練樣本;s3,對所述訓練樣本進行訓練,以建立預測模型;s4,將預測樣本輸入所述預測模型,獲得未來第一預設時間段內的溶解氧預測值。
其中,相關系數是用以反映變量之間相關關系密切程度的統計指標。
其中,k-means聚類法是硬聚類算法,是典型的基于原型的目標函數聚類方法的代表,它是數據點到原型的某種距離作為優化的目標函數,利用函數求極值的方法得到迭代運算的調整規則。k-means算法以歐式距離作為相似度測度,它是求對應某一初始聚類中心向量v最優分類,使得評價指標j最小。
在本發明實施例中將該水體溶解氧預測方法應用于魚菜共生系統,但并不用于限制本發明的保護范圍。具體地,在預測魚菜共生系統中水體的溶解氧時,先獲取水質數據、氣象數據及生物量數據各自與溶解氧數據的相關系數,例如,溶解氧與魚菜共生系統中水溫的相關系數為0.43、溶解氧與魚菜共生系統中氣溫的相關系數為0.34、溶解氧與魚菜共生系統中魚的質量的相關系數為0.21等等。然后將獲取到的相關系數按照大小進行排列,根據需要選取靠前的影響因子作為模板樣本,例如,選取前6種或者8種影響因子作為模板樣本。這樣在保證準確性的基礎上,可以提高溶解氧的預測效率。
魚菜共生系統屬于循環水系統,受水質變化影響較大,因此加水對系統的影響與其他因素的影響不在同一量級,所以需要將加水率單獨算作一個重要影響因子權重。加水率會對溶解氧數據的規律帶來較為明顯的變化,為了避免預測時這種多變情況導致溶解氧的預測精度下降、收斂速度變慢等問題,采用了k-means聚類方法按照第一預設時間段將模板樣本進行智能化分類,例如,將第一預設時間段設置為一天。如圖2所示,s201,任意指定n個模板樣本中的s個模板樣本作為簇中心;s202,計算模板樣本與所有簇中心之間的相似度;s203,確定模板樣本的歸屬,當相似度大于閾值則形成新簇;s204,重新計算聚類后新簇的簇中心,重復步驟s202-s203直到每個簇不再發生變化為止。通過k-means聚類的方法,將模板樣本按不同等級的相似度分為n個類型,每個類型中有s組數據。將模板樣本進行分類可以優化模板樣本的結構性,將模板樣本優化成幾種不同相似度的類型,例如,劃分為蓄水初期、蓄水中期和蓄水后期幾種類型。便于選取與預測樣本具有高相似度的模板樣本作為后續訓練的訓練樣本,從而提高預測的精準度。
按照上面獲取模板樣本的方法獲取預測時刻前第一預設時間段內的數據作為預測樣本,例如,預測時刻為2017年3月30日12點30分,則可以獲取2017年3月30日12點30分前一天的數據作為預測樣本。然后在分類后的模板樣本中識別出與預測樣本相似的模板樣本作為訓練樣本,并對該訓練樣本進行訓練以建立預測模型。最后將預測樣本輸入到預測模型中,從而獲得預測時刻后第一預設時間段內的溶解氧預測值,例如,獲得2017年3月30日12點30分后一天的溶解氧預測值。
本發明實施例與現有技術相比,采用相關系數選取模板樣本,然后采用k-means聚類法按照第一預設時間段對模板樣本進行分類,并在分類的模板樣本中識別出與預測樣本最為相似的模板樣本作為訓練樣本,再對訓練樣本進行訓練以建立預測模型,最后將預測樣本輸入預測模型,以獲得未來第一預設時間段內的溶解氧預測值。該預測方法具有較高的預測精度及較強的適應度,并且在預測穩定性和精度上,有較好的魯棒性和復雜線性映射能力,特別適合于易受環境等外界因素影響的魚菜共生系統的水體溶解氧預測。
在上述實施例的基礎上,在所述s1之前還包括s0,采集并存儲第二預設時間段內系統中的溶解氧數據、水質數據、氣象數據以及生物量數據。所述水質數據包括:電導率、ph值、水溫和氨氮;所述氣象數據包括:氣溫、濕度、光照強度和二氧化碳;所述生物量數據包括:系統中魚的質量、菜的質量以及投喂量。
具體地,在對水體溶解氧進行預測時,首先要采集與溶解氧有關的數據,即對第二預設時間段內的溶解氧數據、水質數據、氣象數據以及生物量數據進行采集,例如,可以采集2017年3月1日12:00至2017年3月30日12:00這一段時間的數據。選取某魚菜共生系統,系統外圍搭建有遠程無線監控系統,用來監測魚菜共生系統水質周邊的氣象數據,監控系統中的環境監測傳感器對氣象數據進行實時數據采集,采集到的氣象數據包括:氣溫、濕度、光照強度和二氧化碳。
魚菜共生系統中安裝有有線水質參數采集裝置,采集裝置中的水質監測傳感器用于在線實時對水質參數進行全方位監測,采集到的水質數據包括:電導率、ph值、水溫和氨氮。使用魚菜標記法和生物量測量儀對生物每段時間的生物量數據進行記錄,記錄的生物量數據包括:魚的質量、菜的質量以及投喂量。并對采集到的溶解氧數據、水質數據、氣象數據以及生物量數據進行存儲,以供后續對溶解氧進行預測。例如,可以每隔30分鐘采集一次數據,并將各個點位采集到的數據通過可靠的通訊手段匯總并儲存到匯聚節點處,以實現對系統全方位數據采集工作,保證了數據技術方案的科學嚴謹性,降低因考慮不周全而導致的系統參數預測準確性。
在上述實施例的基礎上,在所述s0之后、所述s1之前包括:采用線性插值法對所述水質數據進行處理,采用均值平滑法對所述生物量數據進行處理,以及采用小波變化法對所述氣象數據進行處理。
由于采集設備侵蝕導致傳感器老化、性能下降、數據傳輸線路故障等原因;人為因素如增氧、清理系統雜物等,常常會給采集設備所采集的數據帶來干擾,甚至數據丟失的情況,使得監測到的水質數據、氣象數據出現異常波動。魚菜共生系統是一個復雜多變的系統,多參數會相互影響,作用機理復雜,噪聲和水質數據混雜交織,難以區分。上述原因導致采集到的數據中常有部分丟失和不可無視的噪聲。若使用監測采集的原始數據直接用于溶解氧預測,將嚴重影響預測精度和可靠性,甚至完全誤判。為此本發明實施例采用了幾種快速有效的方法來數據進行修復處理。
使用線性插值法對水質數據進行修復處理,其具體公式如下:
生物量數據具有時序性和延續性的特點,前后相鄰時刻數據正常情況不會發生劇烈跳變,因此可以采用均值平滑法對生物量數據進行平滑處理,保證數據的連續完整。
由于氣象數據變化幅度大,且傳輸距離長,空氣介質不穩定,因此,采用信號處理中常使用到的小波變換法來剔除冗余信息和噪聲數據的干擾,本發明實施例中采取對連續變量a,b和t施加不同的離散化條件,使連續小波及其變換進行離散化處理,具體如下:
則得到
使用比較典型的小波變化法對采集到的氣象數據進行數據修復和數據降噪處理,進一步增加數據的可靠性。
然后計算處理后的水質數據、氣象數據和生物量數據各自與溶解氧的相關系數,然后根據計算得到的相關系數選取合適的模板樣本。
在本發明實施例中,通過采用線性插值法對所述水質數據進行處理,采用均值平滑法對所述生物量數據進行處理,以及采用小波變化法對所述氣象數據進行處理,提高模板樣本的可靠性,進而提高溶解氧預測的準確性。
在上述實施例的基礎上,在所述s0之后、所述s1之前還包括:對處理后的所述水質數據、所述氣象數據以及所述生物量數據分別進行歸一化處理。
為避免各種數據的量級差異,先采樣歸一化方法對處理后的水質數據、氣象數據以及生物量數據進行無量綱化處理,將其歸一映射在[0,1]的區間內,利用公式:
然后將歸一化后的水質數據、氣象數據以及生物量數據各自對溶解氧求取相關系數,根據相關系數的大小關系,選取合適的數據作為模板樣本,這樣可以提高溶解氧的預測效率。
在上述實施例的基礎上,所述s1進一步包括:根據皮爾森相關系數法獲取所述水質數據、所述氣象數據及所述生物量數據各自與所述溶解氧數據的相關系數。
其中,皮爾森相關系數(pearsoncorrelationcoefficient)也稱皮爾森積矩相關系數(pearsonproduct-momentcorrelationcoefficient),是一種線性相關系數。皮爾森相關系數是用來反映兩個變量線性相關程度的統計量。相關系數用r表示,其中n為樣本量,分別為兩個變量的觀測值和均值。r描述的是兩個變量間線性相關強弱的程度。r的絕對值越大表明相關性越強。
具體地,在對采集到的水質數據、氣象數據及生物量數據進行歸一化處理后,則需要獲取水質數據、氣象數據及生物量數據各自與溶解氧數據的相關系數,在本發明實施例中采用皮爾森相關系數法獲取相關系數,將水質數據、氣象數據及生物量數據分別代入如下公式,
然后參照計算出的各數據參數與溶解氧的相關系數值,對數據進行篩選,本發明實施例中選取前六種數據參數作為模板樣本數據,例如選取的前六種數據為濕度、氨氮、光照強度、水溫、氣溫和投喂量。再根據選取的模板樣本對水體溶解氧進行預測,這樣可以提高溶解氧預測的效率。
以下對本發明實施例進行舉例說明,但并不用于限制本發明的保護范圍。以采集的2017年3月1日12:00至2017年3月30日12:00的數據作為第二預設時間內采集的數據,這里的數據包括:溶解氧數據、水質數據、氣象數據以及生物量數據,以每30分鐘采集的數據作為一組數據。水質數據包括電導率、ph值、水溫和氨氮;所述氣象數據包括:氣溫、濕度、光照強度和二氧化碳;所述生物量數據包括:系統中魚的質量、菜的質量以及投喂量。并采用線性插值法對所述水質數據進行處理,采用均值平滑法對所述生物量數據進行處理,以及采用小波變化法對所述氣象數據進行處理,提高數據的準確性和穩定性。再對處理后的所述水質數據、所述氣象數據以及所述生物量數據分別進行歸一化處理,以便后續進行相關系數的計算。
然后采用皮爾森相關系數法獲取溶解氧數據與水質數據、氣象數據以及生物量數據之間各自的相關系數。將水質數據、氣象數據及生物量數據分別代入如下公式,
經計算得到其各自與溶解氧的相關系數值,結果如下表:
數據參數與溶解氧的相關系數
表1
然后參照計算出的各數據參數與溶解氧的相關系數表,對數據進行篩選,本發明實施例中選取前六種數據參數作為模板樣本數據,即前六種數據為濕度、氨氮、光照強度、水溫、氣溫和投喂量,那么模板樣本中包含有每隔30分鐘采集一次的濕度、氨氮、光照強度、水溫、氣溫和投喂量這六種數據,總共采集30天,即模板樣本中共有8640個數據,每組數據有6個數據參數,因此構成1440組數。
再通過k-means聚類法按照第一預設時間段對得到的模板樣本進行分類,例如這里的第一預設時間段為一天,采用一天共48組數據量為一簇,即u={x1,x2,…,xn},u為8640個總數據,xn為第n天的樣本數據。每天48個時刻的采集數據構成一天的樣本數據x,同時每個樣本數據中有6種參數,為此可以使用數據矩陣表示為:
其中xi為第i天的樣本,m為數據參數,t為采集時刻,其中t=48。任意指定這1440組數中的一個48組數作為簇中心;計算模板樣本與所有簇中心之間的相似度(距離);確定模板樣本歸屬,當相似度大于閾值則形成新簇;重新計算聚類后所得簇的簇中心,重復步驟2~3直到每個簇不再發生變化為止。這樣按不同的相似度值進行分類,得到不同的聚類結果,即分為幾種不同相似度的類型,例如,劃分為:加水區類型、趨于穩定區的類型、穩定區的類型等。
按照獲取模板樣本的方法獲取預測時刻前第一預設時間段內的預測樣本,例如,獲取2017年3月30日12:00前一天的數據作為預測樣本。然后在分類后的模板樣本中識別出于預測樣本最為相似的模板樣本作為訓練樣本,再對訓練樣本進行訓練以建立預測模塊,再將預測樣本輸入建立好的預測模型中,則輸出2017年3月30日12:00后一天的水體溶解氧預測結果。
在上述實施例的基礎上,所述s2中在所述分類的模板樣本中識別出與所述預測樣本相似的訓練樣本進一步包括:根據基于歐式距離和夾角余弦原理獲取的相似度,在所述分類的模板樣本中識別出與所述預測樣本相似的訓練樣本。
其中,歐氏距離(euclideanmetric)(也稱歐幾里得度量)是一個通常采用的距離定義,指在m維空間中兩個點之間的真實距離,或者向量的自然長度(即該點到原點的距離)。在二維和三維空間中的歐氏距離就是兩點之間的實際距離。
具體地,在采用k-means聚類法對得到的模板樣本進行分類后,各聚類后的模板樣本中心按照平均公式計算:
dxy=αdxy+βdcosxy
式中樣本x和樣本y在i時刻、j數據參數的數值分別用xij、yij表示,且xij和yij均在[0,1]之間。樣本中第j個數據參數的權值用σj表示;α和β為歐式距離dxy和夾角余弦dcosxy的權重系數,相似度統計量由值系數和形系數兩項共同決定。α+β=1,不同蓄水時間段的取值會不同,大量新水加入時,α應取1,否則接近0。然后按照歐式距離和夾角余弦計算得到相似度,再按照相似度選取與預測樣本(即,預測時刻前第一預設時間段內的預測樣本)最相似的模板樣本作為訓練樣本,并對該訓練樣本進行訓練和預測,以建立預測模型。最后將預測樣本輸入到建立好的預測模型中,即可輸出預測時刻后一段時間的水體溶解氧預測結果,例如,預測時刻后一天的溶解氧預測結果。
在本發明實施例中,通過采用歐式距離及夾角余弦原理和中心點計算公式來識別出與預測樣本相似的模板樣本作為訓練樣本,可以精確地在模板樣本中識別出與預測樣本相似的模板樣本,提高水體溶解氧預測的精確性。
在上述實施例的基礎上,所述s3中對所述訓練樣本進行訓練進一步包括:采用模糊神經網絡對所述訓練樣本進行訓練。
其中,模糊神經網絡就是模糊理論同神經網絡相結合的產物,它匯集了神經網絡與模糊理論的優點,集學習、聯想、識別、信息處理于一體。
具體地,在采用模糊神經網絡對訓練樣本進行訓練和預測時,需要先建立模糊神經網絡系統,在本發明實施例中選定模糊神經網絡系統為三層,包括:輸入層,隱含層和輸出層,網絡的拓撲結構如圖3所示;由于本發明實施例的訓練樣本中包括6個數據參數,故輸入層采用6維輸入模式;輸出層采用一個單輸出模式;隱含層神經元14個,輸入層和隱含層之間的激活函數為f。
對與預測樣本相似的模板樣本進行劃分,取其五分之四作為訓練數據,剩下的五分之一作為預測數據,利用模糊神經網路對訓練數據進行訓練,訓練后通過預測數據進行反向修正;取1440組數據中的前五分之四組數據作為訓練數據,即取前1152組數據作為訓練數據,剩余288組作為預測數據。將與預測樣相似的模板樣本按照系統構建的六維輸入模式放入模糊神經網絡系統的輸入層;將與之對應的溶解氧數據樣本放入系統構建的單輸出模式的輸出層。然后通過模糊神經網絡對1152組數據進行訓練,不斷反饋循環修正參數;利用288組數據進行預測仿真,檢驗預測結果的準確性;最終訓練出成型的神經網絡模型。
將預測時刻前第一預設時間段內的預測樣本,例如,2017年3月30日12:00前一天內的數據作為預測樣本,即預測樣本有48組數據,將這48組數據輸入建立好的神經網絡模型中,即可輸出2017年3月30日12:00后一天的水體溶解氧預測結果。
在本發明實施例中,通過采用模糊神經網絡對所述訓練樣本進行訓練以建立預測模型,再將預測樣本輸入預測模型中,即可輸出未來一段時間的溶解氧預測結果,以達到能夠準確預測水體溶解氧的目的。
圖4為本發明實施例提供的水體溶解氧預測裝置的結構圖,如圖4所示,該裝置包括:獲取模塊401、處理模塊402、模型建立模塊403和預測模塊404。獲取模塊401用于獲取水質數據、氣象數據及生物量數據各自與溶解氧數據的相關系數,并根據所述相關系數選取模板樣本;處理模塊402用于通過k-means聚類法按照第一預設時間段對所述模板樣本進行分類,并在所述分類的模板樣本中識別出與所述預測樣本相似的模板樣本作為訓練樣本;模型建立模塊403用于對所述訓練樣本進行訓練,以建立預測模型;預測模塊404用于將所述預測樣本輸入所述預測模型,以獲得未來第一預設時間段內的溶解氧預測值。
在本發明實施例中將該水體溶解氧預測裝置應用于魚菜共生系統中,但并不用于限制本發明的保護范圍。具體地,在預測魚菜共生系統中水體的溶解氧時,先通過獲取模塊401獲取水質數據、氣象數據及生物量數據各自與溶解氧數據的相關系數,例如,溶解氧與魚菜共生系統中水溫的相關系數為0.43、溶解氧與魚菜共生系統中氣溫的相關系數為0.34、溶解氧與魚菜共生系統中魚的質量的相關系數為0.21等等。然后將獲取到的相關系數按照大小進行排列,獲取模塊401根據需要選取靠前的影響因子作為模板樣本,例如,選取前6種或者8種影響因子作為模板樣本。這樣在保證準確性的基礎上,可以提高溶解氧的預測效率。
魚菜共生系統屬于循環水系統,受水質變化影響較大,因此加水對系統的影響與其他因素的影響不在同一量級,所以需要將加水率單獨算一重要影響因子權重。加水率會對溶解氧數據的變化規律帶來較為明顯的變化,為了避免預測時這種多變情況導致溶解氧的預測精度下降、收斂速度變慢等問題,處理模塊402采用k-means聚類方法按照第一預設時間段將模板樣本進行智能化分類,例如,第一預設時間段為一天,如圖2所示。將模板樣本進行分類可以優化模板樣本的結構性,將模板樣本優化成幾種不同相似度的類型,便于處理模塊402在分類的模板樣本中識別出與預測樣本具有高相似度的模板樣本作為后續訓練的訓練樣本,從而提高預測的精準度。
獲取模塊401還用于獲取預測時刻前第一預設時間段內的預測樣本,例如,預測時刻為2017年3月30日12點30分,則可以獲取2017年3月30日12點30分前一天的數據作為預測樣本。然后處理模塊402在分類好的模板樣本中識別出與預測樣本相似的模板樣本作為訓練樣本,模型建立模塊403在對該訓練樣本進行訓練和預測,以建立預測模型。最后預測模塊404將預測樣本輸入到預測模型中,從而獲得預測時刻后第一預設時間段內的溶解氧預測值,例如,獲得2017年3月30日12點30分后一天的溶解氧預測值。
本發明實施例與現有技術相比,通過獲取模塊采用相關系數選取模板樣本,然后處理模塊采用k-means聚類法按照第一預設時間段對模板樣本進行分類,在分類的模板樣本中識別出與預測樣本最為相似的模板樣本作為訓練樣本,模型建立模塊再對訓練樣本進行訓練以建立預測模型,最后預測模塊將預測樣本輸入預測模型,以獲得未來第一預設時間段內的溶解氧預測值。該預測裝置具有較高的預測精度及較強的適應度,并且在預測穩定性和精度上,有較好的魯棒性和復雜線性映射能力,特別適合于易受環境等外界因素影響的魚菜共生系統的水體溶解氧預測。
上述各實施例提供的水體溶解氧預測方法及裝置,采用相關系數選取模板樣本,這是利用了主成分分析的方法,提高溶解氧的預測效率。然后采用k-means聚類法對模板樣本進行智能化分類,優化模板樣本的結構性,將模板樣本優化成幾種不同相似度的類型。之后采用歐式距離及夾角余弦原理和中心點計算公式來完成預測樣本的分類識別功能,精確地在模板樣本中尋找出與預測樣本相似的模板樣本最為訓練樣本,降低了因外界不可抗逆的條件對系統帶來的誤差因素,從而提高了預測的適應性和精準度。
最后應說明的是:以上實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的精神和范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!