基于混合神經網絡和集成學習的非侵入式負荷識別算法的制作方法
本發明屬于數據挖掘與機器學習領域,尤其涉及一種基于混合神經網絡和集成學習的非侵入式負荷識別算法。
背景技術:
電器負荷監測有兩種方法:一種是侵入式負荷監測(ilm),另一種是非侵入式負荷監測(nilm)。傳統的侵入式負荷監測需要為家庭內部每個用電器安裝一個監測裝置以獲取用電器的數據,然后將獲取到的數據通過網絡傳送到終端,由終端進行統一的處理。這種方法的劣勢為監測設備本身就有一定的造價,而在使用過程中還要進行維護,這樣使得其安裝和維護的成本過高。與侵入式負荷監測相對應的就是非侵入式負荷監測,非侵入式負荷監測最大的優點就是只需要監測家庭總線數據,通過分析家庭總線的數據就可以知道家庭內部用電器的狀態,以達到監測的目的。非侵入負荷識別算法主要分為兩大類:一類是基于事件檢測的負荷識別算法,另一類是非事件檢測類識別負荷算法,這兩類算法中非事件檢測類算法的整體識別效果更好。傳統的基于神經網絡的負荷識別方法往往使用單一網絡,對樣本的特征提取效果不好,網絡訓練時間較長。其主要原因是負荷的使用是有時序特征的,負荷之間是有聯系的,產生了因引入諧波這種維度高信息含量不均衡的特征而導致識別效果下降的問題。
技術實現要素:
為了解決上述問題,本發明提出了一種基于混合神經網絡和集成學習的非侵入式負荷識別算法,包括
步驟1、數據處理:將公開數據集中的數據進行處理,得到模型的輸入數據;時域數據直接獲得,頻域數據需要經過傅里葉變換獲得;
步驟2、建立混合神經網絡模型:由循環神經網絡rnn和人工神經網絡ann混合的混合神經網絡hnn;混合神經網絡的模型為輸入層、一層循環神經網絡、多層人工神經網絡以及輸出層;經過訓練后,此模型對輸入的負荷信息進行識別;
步驟3、訓練及測試混合神經網絡模型:用公開數據集中的數據對步驟2中建立好的模型進行訓練及測試,獲得初步的識別結果,輸出各負荷識別結果;
步驟4、集成學習:從總特征集中選擇多個特征子集訓練多個基分類器,再將多個基分類器進行結合,以降低方差,提升最終識別的效果;用投票的方式確定最終負荷識別結果。
所述步驟1中數據處理包括
步驟101、采用網上公開的redd數據集,redd數據集包括6個家庭的用電數據,其中用電數據又分為三類:低頻數據,高頻數據和高頻原始數據;對于低頻數據和高頻數據并非完全符合期望目標,數據中存在缺測、亂序、不合理的情況;對于亂序數據,先對原始數據按時間戳進行排序;排序完成后,剔除數據中的異常點,由于低頻數據只有兩項即總線視在功率和各用電器視在功率,無法檢測是否含有異常點,所以僅剔除高頻數據中的異常點;所述剔除高頻數據異常點的方法為:根據高頻數據的記錄規則,兩個時間戳之差應近似等于周期數乘以1/60,如果兩者值相差較多則認為該條數據為不合理數據,將其舍去;
步驟102、所述算法采用的數據主要有兩種類型,分別為時域數據和頻域數據,后續的神經網絡訓練過程也是在數據中提取這兩部分的特征;從原始數據中就能直接獲得時域特征,而頻域數據需要通過傅里葉變換獲得;對于負荷識別來說,電壓、電流的諧波特征較功率諧波特征對實驗結果的提高更為明顯,采用電壓、電流的諧波特征作為頻域特征;為了提取用電器的這種諧波特征,采用非周期性離散信號離散時域傅里葉變換進行處理;
步驟103、對經步驟2處理后的數據進行歸一化處理,采取的歸一化方法為線性函數歸一化,當數據中某個值因異常而過大時會壓低歸一化后數據的整體均值,通過對各個維度的數據進行統計及畫圖觀察發現,各個維度99%的值均小于最大值的80%,在進行線性歸一化時,以最大值的80%替換原最大值。
所述步驟2中建立混合神經網絡模型包括
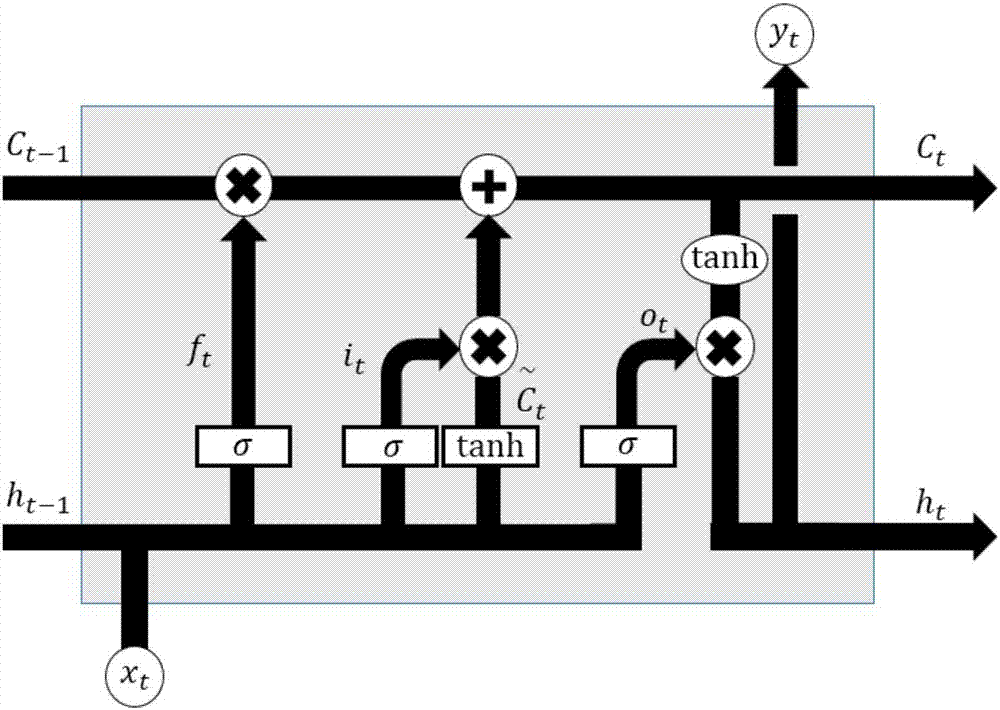
通過rnn和ann相結合構建混合神經網絡,選取的rnn網絡為長短期記憶網絡lstm;lstm的工作流程為:在t時刻將外界輸入xt和上一時刻的輸出yt-1作為新的輸入,輸入到lstm中;lstm先計算遺忘門forgetgate的值ft,以確定上一時刻的細胞狀態的值ct-1有多少保留到下一時刻;接下來計算本次輸入帶來多少新信息
ft=σ(wf[yt-1,xt]+bf)
it=σ(wi[yt-1,xt]+bi)
ot=σ(wo[yt-1,xt]+bo)
yt=ot*tanh(ct)
其中,σ為sigmoid激活函數,tanh為tanh激活函數;權重矩陣wf,wi,wo,wc和偏置bf,bi,bo,bc為學習參數;
通過lstm與ann相結合構建混合神經網絡hnn,其中lstm層用來負責從原始數據中提取時序特征,ann層根據lstm層傳遞過來的時序特征進行訓練,起到分類器的作用;混合網絡構建的方式為:最開始為輸入層,用來接受某一時間點的輸入特征;輸入層后面接一層lstm層,目的是在輸入特征的基礎上提取時序特征;在lstm層后接多層傳統神經網絡,起到分類器的作用;最后為輸出層,輸出每個用電器在該時間點處于開啟狀態的概率值,得到輸出后,再對每個用電器給予合理的閾值,將輸出概率值離散化為0,1值,得到最終的用電器開關預測結果;對于每層網絡來說,層節點個數不超30,由于lstm比ann的結構復雜,具有更多的參數值,同時訓練集的樣本數有限,為避免過擬合,只用單層lstm。
所述步驟3中訓練及測試混合神經網絡模型包括
將步驟1中處理好的數據輸入混合神經網絡模型,在輸入諧波特征數據過程中,每一個模型只輸入一類諧波數據,分別為3次、5次、7次諧波,建立三種帶有不同諧波特征輸入的模型,三個模型分別進行訓練、測試,測試得出的結果需要在下一步驟中進行投票得出最終識別結果。
所述步驟4中集成學習包括
通過從總特征集中選擇多個特征子集訓練多個基分類器,再將多個基分類器進行結合,以降低方差提升最終結果的效果;初期試驗直接將頻域特征引入算法,實驗結果并沒有得到明顯改善,反而有所下降。進一步分析得到,實驗結果下降是由于得到的頻域特征很多,不當的噪聲特征輸入導致模型預測準確率的下降。為解決這一問題,本發明擬借鑒集成學習中隨機森林的思想,通過集成學習的方式提高實驗效果。
集成學習即通過構建并結合多個學習模型來完成目標學習任務;考慮一個二分類問題y∈{0,1}其真實目標函數為f,假設基分類器的錯誤率為ε,即對每個基分類器hi有p(hi(x)≠f(x))=ε;
假設集成通過最常用的投票法將n個基分類器結合在一起,且當有半數以上的基分類器正確,則集成分類結果就正確;隨著集成中個體分類器數目n的增大,集成的錯誤率將呈指數級下降,最終趨近于0;
假設基分類器的錯誤率相互獨立,則集成的錯誤率為
在得到訓練數據后,由原特征集隨機生成多個特征子集,用每個子特征集單獨訓練一個混合神經網絡模型,對于一個新的樣本點,每個混合神經網絡模型都有一個輸出與之對應,由所有輸出采用投票的方式得到最終的結果。
由原特征集產生多個特征子集的過程中,每個特征子集均與原特征集共有相同的時域特征,僅在頻域特征上進行特征的隨機選擇,同時特征子集需滿足以下條件:(1)特征子集的并集為總特征集;(2)特征子集包含的頻域特征應均勻,不應該出現某一頻域特征在大多數特征子集中均出現,而某些頻域特征從未在任何特征子集中出現的情況,如不滿足上述條件則重新換分特征子集。
有益效果
與傳統人工神經網絡(ann)的識別結果、主要的算法性能評價指標準確率、精度、召回率等以及訓練測試時間對比,結果顯示在各類評價指標上本發明的混合神經網絡加集成學習的方法均高于傳統神經網絡,在訓練以及測試時間上高于傳統神經網絡。本發明還提出了一種基于集成學習思想的方法,通過從總特征集中選擇多個特征子集訓練多個基分類器,再將多個基分類器進行結合,以降低方差并提升最終結果的識別效果,成功解決了引入諧波特征對識別效果產生不良影響的問題。
附圖說明
圖1為本發明示意圖。
圖2為本發明lstm網絡示意圖。
圖3為本發明混合網絡示意圖。
圖4為本發明集成學習思想示意圖。
具體實施方式
下面結合附圖和具體實施方式對本發明作進一步的說明。
圖1為本發明示意圖。參照圖1所示,首先對需要進行識別的用戶數據進行處理,數據來源為redd數據集中house_3的數據。處理完成后獲得電壓、電流、功率等時域數據。然后通過非周期性離散信號離散時域傅里葉變換對數據進行處理,得到電壓、電流的3、5、7次諧波特征,此為頻域數據。接下來對數據進行歸一化處理,歸一化方法為線性函數歸一化。將處理好的數據輸入到由循環神經網絡(rnn)以及人工神經網絡(ann)混合而成的混合神經網絡中,訓練好的神經網絡會輸出各用電器的開關狀態。在建立混合神經網絡模型的時候,輸入的時域數據相同,但頻域數據分別為3、5、7次諧波,因此就建立了3個不同的混合網絡模型。在最終進行負荷預測時,將數據分別輸入三個不同的模型,將得到三種不同的結果。然后借助隨機森林思想,從總特征集中選擇多個特征子集訓練多個基分類器,再將多個基分類器進行結合,以降低方差提升最終結果的效果。對三個模型的輸出結果進行投票,最后得出識別結果。具體實現步驟如下:
步驟一:數據處理
本發明采用的數據集為網上公開redd數據集,redd數據集包括6個家庭的用電數據,其中用電數據又分為三類:低頻數據,高頻數據和高頻原始數據。對于低頻數據和高頻數據,由于監測儀器的故障等原因,使得所得到的數據并非完全符合期望目標,數據中存在缺測、亂序、不合理的情況。對于亂序數據,先對原始數據按時間戳進行排序。排序完成后,剔除數據中的異常點,由于低頻數據只有兩項(總線視在功率、各用電器視在功率),無法檢測是否含有異常點,所以僅剔除高頻數據中的異常點。剔除高頻數據異常點的方法如下:根據高頻數據的記錄規則,兩個時間戳之差應近似等于周期數乘以1/60,如果兩者值相差較多則認為該條數據為不合理數據,將其舍去。本發明中所采用的數據主要有兩種類型,分別為時域數據和頻域數據,后續的神經網絡訓練過程也是在數據中提取這兩部分的特征。從原始數據中就能直接獲得時域特征,如電壓、電流、功率。而頻域數據需要通過傅里葉變換獲得。
對于負荷識別來說,電壓、電流的諧波特征較功率諧波特征對實驗結果的提高更為明顯,所以本實驗中采用電壓、電流的諧波特征作為頻域特征。為了提取用電器的這種諧波特征,本發明采用非周期性離散信號離散時域傅里葉變換進行處理,快速傅里葉變換(fft)是其中效率較高的一種算法。快速傅里葉變換的公式為
其中x(n)為有限長離散信號,x(k)為變換到頻域的結果。
經過以上處理后,還需對實驗數據進行歸一化處理,本發明實驗中采取的歸一化方法為線性函數歸一化,該歸一化方法的結果會受最大、最小值的影響。當數據中某個值因異常而過大時會壓低歸一化后數據的整體均值。通過對各個維度的數據進行統計及畫圖觀察可以發現,各個維度99%的值均小于最大值的80%,所以這里在進行線性歸一化時,以最大值的80%替換原公式中的最大值。
步驟二:建立混合神經網絡模型
本發明通過rnn和ann相結合構建混合神經網絡,選取的rnn網絡為長短期記憶網絡(lstm)。lstm是rnn諸多形式中的一種,也是rnn中效果最好的一種。而與大多數rnn不同的是,lstm的記憶性非常強,記憶能力遠高于其它rnn結構。lstm結構如圖2所示,最上層為lstm的核心,是lstm記憶性的體現,用來記錄過去的信息,為細胞狀態值c。lstm的工作流程如下:在t時刻將本時刻的外界輸入xt和上一時刻的輸出yt-1作為新的輸入,輸入到lstm中。lstm先計算forgetgate的值ft,以確定上一時刻的細胞狀態的值ct-1有多少保留到下一時刻。接下來計算本次輸入帶來多少新信息
ft=σ(wf[yt-1,xt]+bf)
it=σ(wi[yt-1,xt]+bi)
ot=σ(wo[yt-1,xt]+bo)
yt=ot*tanh(ct)
其中σ為sigmoid激活函數,tanh為tanh激活函數。權重矩陣wf,wi,wo,wc和偏置bf,bi,bo,bc為學習參數。
人工神經網絡(ann)是一種模仿動物神經網絡行為特征,進行信息處理的數學模型。神經網絡方面的研究很早以前就已經出現了,經過長時間的發展與完善,到今天為止廣泛應用于各個領域解決各種各樣的實際問題。神經網絡模型是參照人體大腦中神經細胞的工作機制而建立的。神經網絡模型就是將許多個單一神經元聯結在一起,這樣一個神經元的輸出就可以是另一個神經元的輸入。神經網絡最左邊的一層叫做輸入層,最右的一層叫做輸出層。中間所有節點組成的一層叫做隱藏層,將中間節點稱為隱藏層的原因是觀察者不能在訓練樣本集中觀測到它們的值。用n來表示網絡的導數,假設n=3,將第l層記為ll,于是l1就為輸入層,輸出層是l3。本發明的神經網絡有參數(w,b)=(w(1),b(1),w(2),b(2)),其中
用
用
這樣就可以得到一種更簡潔的表示法。這里將激活函數f(i)擴展為用向量來表示,即f([z1,z2,z3])=[f(z1),f(z2),f(z3)],那么,上面的等式可以更簡潔地表示為:
z(2)=w(1)x+b(1)
a(2)=f(z(2))
z(3)=w(2)a(2)+b(2)
hw,b(x)=a(3)=f(z(3))
通過lstm與ann相結合構建混合神經網絡(hnn),其中lstm層用來負責從原始數據中提取時序特征,ann層根據lstm層傳遞過來的時序特征進行訓練,起到分類器的作用。應用lstm進行特征提取的優點在于,lstm的記憶長度會根據實際情況不斷調整,使得特征識別的范圍越來越精確,獲得更為有效的特征。混合網絡構建的方式如下:最開始為輸入層,用來接受某一時間點的輸入特征;輸入層后面接一層lstm層,目的是在輸入特征的基礎上提取時序特征;在lstm層后接多層傳統神經網絡,起到分類器的作用;最后為輸出層,輸出每個用電器在該時間點處于開啟狀態的概率值,示意圖如圖3。得到輸出后,再對每個用電器給予合理的閾值,將輸出概率值離散化為0,1值,得到最終的用電器開關預測結果。在本文的實驗中,對于每層網絡來說,層節點個數不超30即可取得較好的結果,由于lstm比ann的結構復雜,具有更多的參數值,同時訓練集的樣本數有限,為避免過擬合,實驗中只用單層lstm。
步驟三:混合神經網絡模型訓練及測試
本發明的實驗環境為linux環境,cpu為i7-930,主頻2.8ghz,顯卡為gtxtitanx,內存16g,混合網絡的實現應用keras深度學習框架,keras的backend為theano。將處理好的數據輸入混合神經網絡模型。在輸入諧波特征數據過程中,每一個模型只輸入一類諧波數據,分別為3次、5次、7次諧波,這樣就建立了三種帶有不同諧波特征輸入的模型,三個模型分別進行訓練、測試,測試得出的結果需要在下一步驟中進行投票得出最終識別結果。
步驟四:集成學習
在前期實驗中得知,當把諧波數據直接作為輸入引入到混合神經網絡中的識別結果并不好,由于得到的頻域特征很多,不當的噪聲特征輸入導致模型預測準確率的下降,為解決這一問題,本發明擬借鑒集成學習中隨機森林的思想,通過集成學習的方式提高實驗效果。
對于集成學習來說,分為bagging和boosting兩大類。這兩類的重點又在于降低偏差與方差。所以在選擇集成學習方法之前,應先弄清楚較差實驗效果的由偏差過高還是由方差過高引起的。通過分析訓練集準確率隨時間的變化可知,訓練集準確率隨著時間增長而收斂,說明對于訓練集來說模型已經充分訓練并收斂。當模型已經充分訓練時,對模型泛化誤差的影響主要來源于方差,所以為了降低方差,集成學習算法應采用bagging或隨機森林。由于本實驗要從連續的時間區段中提取時域特征,所以不能應用自助采樣法,也就不能使用bagging。從其它相關文獻中了解到,頻域特征在負荷識別算法中是一類很重要的特征,但直接將所有波段的頻域特征全都輸入模型中的實驗結果反而較差。本文借鑒了隨機森林算法,通過從總特征集中選擇多個特征子集訓練多個基分類器,再將多個基分類器進行結合,以降低方差提升最終結果的效果。
基于混合神經網絡模型的集成學習方法總體結構和流程如圖4所示,在得到訓練數據后,由原特征集隨機生成多個特征子集,用每個子特征集單獨訓練一個混合神經網絡模型。對于一個新的樣本點,每個混合神經網絡模型都有一個輸出與之對應,由所有輸出采用投票的方式得到最終的結果。
實驗中構建8個分類器,每個分類器除包含時域特征:電壓、電流、功率外,另隨機從頻域特征中選取3個諧波幅值作為輸入,訓練基分類器。實驗結果如下:
表1集成分類器和時頻特征的結果
表2訓練測試時間表
表3評價指標符號參考表
查準率p、查全率r與f1值分別定義為:
由于查準率和查全率會出現矛盾的情況,這時就需要綜合考慮它們,最常見的方法就是f-measure,當時就是最常見的f1值。f1值是查準率與查全率的調和平均,調和平均更重視較小值。
由結果可知本發明所提出的基于混合神經網絡和集成學習的非侵入式負荷識別算法對非侵入式負荷識別有較好的結果。與傳統神經網絡相比,雖然算法的執行時間稍長,但各類評價指標都高于傳統神經網絡。此算法在現實生產生活中有很高的價值。
- 還沒有人留言評論。精彩留言會獲得點贊!