疾病的快速輔助定位方法與流程
本發明涉及臨床診斷系統,具體涉及一種疾病的快速輔助定位方法。
背景技術:
在罕見疾病的臨床診斷中,一個常見的問題便是如何根據患者的表型信息快速準確地分析出其罹患的具體的疾病類型。表型診斷就是通過比較患者表型和所有已知疾病記錄的表型間的相似程度,跟患者越相似的疾病可能性越大,因此精確地計算記錄的疾病表型和患者間的表型間的相似程度是成功診斷的關鍵。
由于各種外界原因,比如患者間的遺傳和環境等個體差異、臨床醫生的知識結構差異等,臨床診斷時患者的表型描述不可能跟疾病的已知表述完全一致,在現實場景中,經常出現以下問題:1)數據不完整(只包括部分表型);2)噪音(跟真實疾病無關的表型,即提供了錯誤的表型);3)不準確描述(表型描述過于寬泛,不具有區分度)。
技術實現要素:
針對現有技術中的上述不足,本發明提供的疾病的快速輔助定位方法解決了實際場景中表型數據不完備、帶有噪音和描述不夠準確引起疾病定位不準確的問題。
為了達到上述發明目的,本發明采用的技術方案為:
提供一種疾病的快速輔助定位方法,其包括:
接收患者描述的罹患疾病的所有表型,并采用接收的所有表型構建患者描述表型集;
獲取表型注釋數據庫中具有患者描述的表型的所有疾病;
查找每種疾病所對應的表型,并采用每種疾病所對應的表型分別構建相關疾病表型集;
計算患者描述表型集與每個相關疾病表型集的相似度:
其中,t1為患者描述表型集;t2為相關疾病表型集;sim(t1,t2)為集合t1與集合t2之間的相似度;t1和t2疾病所對應的兩種不同的表型;sim(t1,t2)為表型t1和t2之間的相似度;
比較患者描述表型集與所有相關疾病表型集的相似度,相似度值越大,則患者罹患當前相似度對應疾病的概率越大。
本發明的有益效果為:本方案通過獨特的算法計算患者表型與所有已知疾病的相似度,能夠很好地排除患者描述表型數據不完備、帶有噪音和描述不夠準確等帶來的不確定性;將采用本方案的方法與現有通過相似度定位疾病的resnik、jc和lin方法在同等模擬環境下進行模擬實驗,通過數據對比,本方案抗外界干擾因素明顯高于現有技術中采用相似度的三種方法。
附圖說明
圖1為本發明疾病的快速輔助定位方法一個實施例的流程圖。
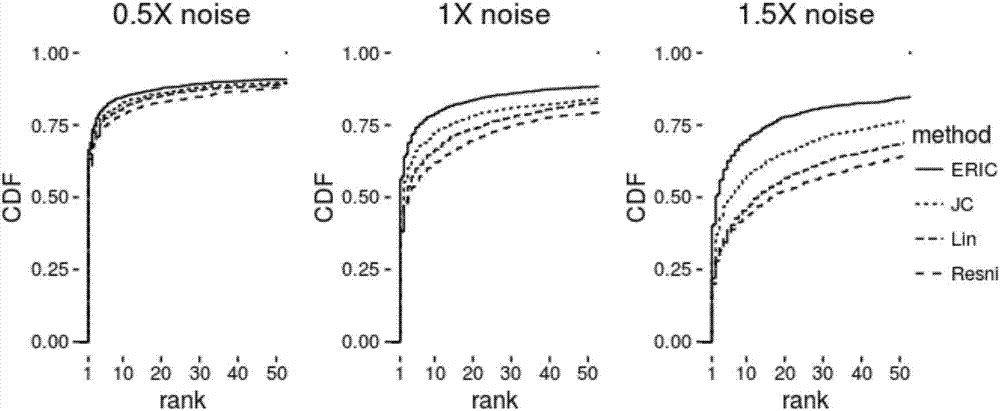
圖2為模擬測試時,添加0.5倍,1倍和1.5倍噪音后,本方案與現有技術中的resnik、jc和lin方法抵抗噪音干擾時的效果圖。
圖3為模擬測試時,先抽取50%表型,然后分別替換其中的30%、50%和90%的表型作為每個表型對應的任意一個祖先表型后,本方案與現有技術中的resnik、jc和lin方法抵抗不精確描述時的效果圖。
圖4為模擬測試時,先抽樣50%的表型,不精確部分表型,在添加不同程度的噪音后,本方案與現有技術中的resnik、jc和lin方法抵抗混合效應時的效果圖。
具體實施方式
下面對本發明的具體實施方式進行描述,以便于本技術領域的技術人員理解本發明,但應該清楚,本發明不限于具體實施方式的范圍,對本技術領域的普通技術人員來講,只要各種變化在所附的權利要求限定和確定的本發明的精神和范圍內,這些變化是顯而易見的,一切利用本發明構思的發明創造均在保護之列。
參考圖,圖1示出了本發明疾病的快速輔助定位方法一個實施例的流程圖。如圖1所示,該方法100包括步驟101至步驟104。
在步驟101中,接收患者描述的罹患疾病的所有表型;為了便于后面患者罹患疾病的相似度與數據庫中疾病的相似度計算,此處將患者描述的所有表型構建成一個集合,即采用接收的所有表型構建患者描述表型集。
在本發明的一個實施例中,表型注釋數據庫為從人類表型本體官方網站獲得的罕見疾病和每種罕見疾病對應的表型構建而成。
由于數據集中的所有疾病及每種疾病的相關表型均來自于全球權威機構,而不是自己從各種數據網址收集整理而來,更助于后面準確定位疾病的準確性和可靠性。
在步驟102中,獲取表型注釋數據庫中具有患者描述的表型的所有疾病,此處的疾病的所有表型中至少包括一種患者描述的表型。
在步驟103中,查找每種疾病所對應的表型,此處為便于后續相似度計算,同理也可以將每種疾病所對應的表型分別構建成一個集合,即采用每種疾病所對應的表型分別構建相關疾病表型集。
在步驟104中,計算患者描述表型集與每個相關疾病表型集的相似度:
其中,t1為患者描述表型集;t2為相關疾病表型集;sim(t1,t2)為集合t1與集合t2之間的相似度;t1和t2疾病所對應的兩種不同的表型;sim(t1,t2)為表型t1和t2之間的相似度;
在本發明的一個實施例中,表型t1和t2之間的相似度sim(t1,t2)的具體算法為:
sim(t1,t2)=2ic(tmica)-min(ic(t1),ic(t2))
其中,tmica為表型t1和t2的最大信息量共同祖先節點;ic(tmica)為兩個表型t1和t2共同的祖先tmica的信息量;ic(t1)和ic(t2)分別為表型t1和t2的信息量;min(ic(t1),ic(t2)表示取ic(t1)和ic(t2)兩者中最小值。
實施時,優選表型的信息量的具體算法為:
ic(t)=log(n/nt)
其中,n為從表型注釋數據庫獲取的所有疾病的數量;t為疾病所對應的表型;nt為具有表型t的疾病數量;ic代表每個表型的信息量。
在步驟105中,比較患者描述表型集與所有相關疾病表型集的相似度,相似度值越大,則患者罹患當前相似度對應疾病的概率越大。
在本發明的一個實施例中,該疾病的快速輔助定位方法還包括對患者描述表型集與所有相關疾病表型集的相似度按照疾病的維度進行排序,并輸出排序結果。
通過輸出的排序結果,用戶可以動態地增減或修改描述的表型,以達到罹患疾病的精確定位。
下面選取dddg2p(developmentdisordergenotype–phenotypedatabase數據庫(https://decipher.sanger.ac.uk)對現有技術中resnik、jc和lin與本方案的方法(下面用eric表示)進行模擬測試。
其中,dddg2p(developmentdisordergenotype–phenotypedatabase數據庫包含了大約25000個疾病和表型間的對應關系,包括1300種發育相關的疾病和大約4000個人類表型本體(hpo)表型術語。
噪音對比測試
由于個體遺傳和環境等差異,臨床患者還可能表現出跟真實疾病記錄無關或者不一致的表型(噪音),我們采用如下步驟生成帶噪音的患者描述表型集。
首先,每種疾病我們隨機抽取50%的表型,每種疾病抽樣10次,添加0.5倍,1倍和1.5倍的噪音,計算帶噪音抽樣表型跟每個疾病所有表型的相關疾病表型集的相似性,如果目標疾病(真實表型數據來源的疾病)的排名越靠前則說明抗噪音能力越好。
通過模擬測試輸出的圖像(參考圖2)可以發現抵抗噪音能力依次為:eric>jc>lin>resnik,可見本方案提供的方法(eric)比其它方法更能抵抗噪音的影響。
參見表1,在1.5倍噪音時,排名前5的疾病,eric依次能比jc、lin和resnik多13.8%,23.3%和25.7%。
表11.5倍噪音時真實疾病排名
不精確描述測試
臨床上患者描述疾病的表型可能比較寬泛,不精確,因此我們還需要模擬不精確描述的影響。同樣先抽取50%表型,然后分別替換其中的30%、50%和90%的表型作為每個表型對應的任意一個祖先表型。
通過模擬測試輸出的圖像(參考圖3)可以發現eric和resnik抵御不精確描述的能力比較一致,且都優于jc和lin方法。
參見表2,在90%的不精確描述時,排名前5的疾病eric和resnik比jc和lin多大約8%。
表290%不精確描述時的真實疾病排名
混合效應測試
真實的臨床使用時,會同時受到噪音和不精確描述的影響。為了評估這種混合效應的影響,我們抽樣50%的表型,然后分別替換其中50%的表型作為每個表型對應的任意一個祖先表型,之后再添加1倍的噪音進行模擬測試。
通過模擬測試分別計算相似度后,我們發現eric仍然是表現最好的,測試數據參考圖4和表3。
表31倍和50%不精確描述時真實疾病排名
綜上所述,本方案通過獨特的計算方式計算的相似度確定為某種疾病的方式與現有的resnik、jc和lin相比,具有更好的抗噪聲性能,更能容忍不精確表型描述帶來的干擾。
- 還沒有人留言評論。精彩留言會獲得點贊!