一種基于皮爾遜相似度和FP?Growth的圖審專家推薦方法與流程
本發明屬于推薦算法和關聯規則挖掘技術領域,特別涉及一種基于皮爾遜相似度和FP-Growth的圖審專家推薦方法,主要用于計算項目審查專家組合的支持度,即契合度,進而使得專家協同審查效率提高,并以此增加歷史項目審查專家集數據的使用價值。
背景技術:
項目審查專家推薦算法對項目審查領域中實現項目審查專家高效的遴選有重要的作用和意義。傳統的項目審查專家組由人工選擇的方式已經不能滿足項目審查領域的需求。近年來針對不同的推薦系統的需求,研究者提出了相應的個性化推薦方案,如基于內容推薦,協同過濾,關聯規則,效用推薦,組合推薦等。
馮萬利,朱全銀等人已有的研究基礎包括:Wanli Feng.Research of theme statement extraction for chinese literature based on lexical chain.International Journal of Multimedia and Ubiquitous Engineering,Vol.11,No.6(2016),pp.379-388;Wanli Feng,Ying Li,Shangbing Gao,Yunyang Yan,Jianxun Xue.A novel flame edge detection algorithm via a novel active contour model.International Journal of Hybrid Information Technology,Vol.9,No.9(2016),pp.275-282;劉金嶺,馮萬利.基于屬性依賴關系的模式匹配方法[J].微電子學與計算機,2011,28(12):167-170;劉金嶺,馮萬利,張亞紅.初始化簇類中心和重構標度函數的文本聚類[J].計算機應用研究,2011,28(11):4115-4117;劉金嶺,馮萬利,張亞紅.基于重新標度的中文短信文本聚類方法[J].計算機工程與應用,2012,48(21):146-150.;朱全銀,潘祿,劉文儒,等.Web科技新聞分類抽取算法[J].淮陰工學院學報,2015,24(5):18-24;李翔,朱全銀.聯合聚類和評分矩陣共享的協同過濾推薦[J].計算機科學與探索,2014,8(6):751-759;Quanyin Zhu,Sunqun Cao.A Novel Classifier-independent Feature Selection Algorithm for Imbalanced Datasets.2009,p:77-82;Quanyin Zhu,Yunyang Yan,Jin Ding,Jin Qian.The Case Study for Price Extracting of Mobile Phone Sell Online.2011,p:282-285;Quanyin Zhu,Suqun Cao,Pei Zhou,Yunyang Yan,Hong Zhou.Integrated Price Forecast based on Dichotomy Backfilling and Disturbance Factor Algorithm.International Review on Computers and Software,2011,Vol.6(6):1089-1093;朱全銀,馮萬利等人申請、公開與授權的相關專利:馮萬利,邵鶴帥,莊軍.一種智能冷藏車狀態監測無線網絡終端裝置:CN203616634U[P].2014;朱全銀,胡蓉靜,何蘇群,周培等.一種基于線性插補與自適應滑動窗口的商品價格預測方法.中國專利:ZL 2011 1 0423015.5,2015.07.01;朱全銀,曹蘇群,嚴云洋,胡蓉靜等,一種基于二分數據修補與擾亂因子的商品價格預測方法.中國專利:ZL 2011 1 0422274.6,2013.01.02;李翔,朱全銀,胡榮林,周泓.一種基于譜聚類的冷鏈物流配載智能推薦方法.中國專利公開號:CN105654267A,2016.06.08。
皮爾遜積矩相關系數:
皮爾遜積矩相關系數(Pearson product-moment correlation coefficient)用于度量兩個變量X和Y之間的相關,其值介于-1與1之間。在自然科學領域中,該系數廣泛用于度量兩個變量之間的相關程度。
關聯規則算法:
基于關聯規則的推薦更常見于電子商務系統中,并且也被證明行之有效,其實際的意義為購買了一些物品的用戶更傾向于購買另一些物品,基于關聯規則的推薦系統的首要目標是挖掘出關聯規則,也就是那些同時被很多用戶購買的物品集合,這些集合內的物品可以相互進行推薦。基于關聯規則的推薦系統一般轉化率比較高,因為當用戶已經購買了頻繁集合中的若干項目后,購買該頻繁集合中的其他項目的可能性更高。然而挖掘項目集合的關聯規則計算量較大,同時也存在用戶數據的稀疏性問題,降低了推薦的準確率。
FP-Growth算法:
FP-Growth算法是韓家煒等人在2000年提出的關聯分析算法,它采取如下分治策略:將提供頻繁項集的數據庫壓縮到一棵頻繁模式樹(FP-tree),但仍保留項集關聯信息。FP-tree是一種特殊的前綴樹,由頻繁項頭表和項前綴樹構成。FP-Growth算法基于以上的結構加快整個挖掘過程。FP-Growth算法較挖掘關聯規則的頻繁項集算法中的Apriori算法而言,采用分治策略對數據庫進行挖掘,不產生候選項集,它采用FP-Tree存放數據庫的重要信息,只需掃描兩次數據庫,然后將關鍵的信息以FP-Tree的形式存放在內存中,避免了多次掃描數據庫帶來的巨大開銷。
技術實現要素:
發明目的:傳統的項目審查專家組是人工選擇出來的,就會存在這樣的問題:選出的專家組并沒有審查過類似規模的項目,會浪費大量時間;選出來的專家組成員之間契合度不高,導致項目審查效率較低。針對傳統方法存在的問題,本發明通過綜合分析歷史項目審查專家集和歷史綜合項目記錄集,采用一種基于皮爾遜相似度和FP-Growth的圖審專家推薦方法,為待審查項目推薦契合度最高的審查專家組。
技術方案:本發明提出一種基于皮爾遜相似度和FP-Growth的圖審專家推薦方法,包括如下步驟:
步驟1:對待審查項目和綜合項目記錄集中的項目屬性進行歸一化預處理,所述待審查項目和綜合項目通過綜合項目類型、綜合項目類型的分支項目類型和項目屬性表示,具體方法為:
步驟1.1:定義綜合型項目類型、分支項目類型和項目屬性;
步驟1.2:記錄綜合項目記錄集項目屬性中各項數據的最大值和最小值;
步驟1.3:對綜合項目記錄集和待處理項目項目屬性的數據進行歸一化處理,具體公式為:
Anorm=(A-Amin)/(Amax-Amin)
式中,Amax和Amin分別為項目屬性各項數據的最大值和最小值,A為歸一化前的數據,Anorm為歸一化后的數據。
步驟2:通過皮爾遜相似度方法對歸一化后的數據集處理得出與待審查項目規模最接近的十個項目,并抽取十個項目的審查專家,所述審查專家通過研究的分支項目類型和審查項目記錄表示,具體方法為:
步驟2.1:定義圖審專家數據集和已審查項目記錄集,所述圖審專家數據用專家編號和專家研究的分支項目類型表示,所述圖審專家數據集用項目編號和圖審專家編號表示;
步驟2.2:根據項目編號對已審查項目記錄集中的專家進行整合,得到審查不同項目的工程項目審查專家集;
步驟2.3:計算待審查項目與綜合項目記錄集中各項目的相似度,具體公式為:
式中,simi為待審查項目與第i個項目的相似度,Xj和Yij分別為待審查項目和第i個項目的項目屬性數據集元素;和分別為待審查項目和第i個項目的項目屬性數據的均值;
步驟2.4:對相似對進行排序,提取前十個項目對應的項目編號及對應的審查專家集,即得預選圖審專家集。
步驟3:根據待審查的綜合項目的分支項目類型和圖審專家研究方向,對抽取出的專家進行組合,得到所有備選組合專家集,具體方法為:
步驟3.1:從預選圖審專家集中剔除有審查任務的專家;
步驟3.2:從步驟3.1得到的專家集中選擇研究分支項目類型與待審查項目分支項目類型相同的圖審專家,并將專家按照分支項目類型表示;
步驟3.3:若步驟3.2得到的專家集存在待審查項目某分支類型沒有專家,則針對該項目分支類型,從所有圖審專家數據集中尋找審查該分支項目類型且沒有工作任務的專家加入;
步驟3.4:從步驟3.3得到的專家集對應的每個分支項目類型中至少抽取一個專家,即得所有備選組合專家集。
步驟4:使用FP-Growth方法對歷史項目審查專家集處理,得到圖審專家組合頻繁項集;
步驟5:利用組合頻繁項集通過每種專家組合自適應契合度方法計算每種備選專家組合集的支持度,最終支持度最大即契合度最高的專家組合集即為參與待審查項目的專家集,具體方法為:
步驟5.1:以一種備選組合專家集為例,該專家集共有n個專家,從備選組合專家集中抽取1位專家,共有種抽取方式,從備選組合專家集中抽取2位專家,共有種抽取方式,以此類推,一直抽取到n為專家,共有種抽取方式,即所有的抽取結果組合成Subset集,Subset包含集合數量為初始化備選組合專家集的契合度SValue為0;
步驟5.2:遍歷Subset,若Subset中的一種抽取后的專家組合在圖審專家組合頻繁項集中,則步驟5.1中備選組合專家集的契合度應加上該抽取后的專家組合對應頻繁項集中的頻數與該抽取后的專家組合中的專家數的乘積,即:
SValue=SValue+f*k
式中,SValue為備選組合專家集的契合度,f為抽取后的專家組合對應頻繁項集中的頻數,k為抽取后的專家組合中的專家數的乘積,遍歷結束,即得到步驟5.1中備選組合專家集的最終契合度;
步驟5.3:通過步驟5.1、5.2方法計算所有備選組合專家集的契合度,最終契合度最高的備選組合專家集即為參與待審查項目的專家集。
本發明采用上述技術方案,具有以下有益效果:本發明方法利用綜合項目記錄集和歷史項目審查專家集,有效的推薦了一種契合度最高的圖審專家組合,提高了審查的效率,具體的:本發明利用專家審查項目歷史記錄進行數據挖掘,發現專家之間的組合關系和契合度,采用皮爾遜相似度算法得到與待審查項目相似的歷史項目審查專家集,抽取該專家集中沒有審查任務的專家,并依據待審查的綜合項目的分支項目和專家審查方向對處理后的專家進行組合,使得每種組合包含的專家均為審查過與待審查項目類似的專家。此外,本發明創造性地提出了一種專家組合契合度算法用于計算每種專家組合的契合度,契合度最高的專家組即為最終推薦的待審查項目的專家組,提高了審查的效率。
附圖說明
圖1為圖審專家推薦方法整體流程圖;
圖2為項目和審查專家相關數據預處理和關聯規則方法流程圖;
圖3為項目相關數據歸一化處理和相似度計算方法流程圖;
圖4為專家組合方法流程圖;
圖5為選取所有備選專家組合中契合度最高的專家組和的方法流程;
圖6為每種專家組合自適應契合度方法流程。
具體實施方式
下面結合具體實施例,進一步闡明本發明,應理解這些實施例僅用于說明本發明而不用于限制本發明的范圍,在閱讀了本發明之后,本領域技術人員對本發明的各種等價形式的修改均落于本申請所附權利要求所限定的范圍。
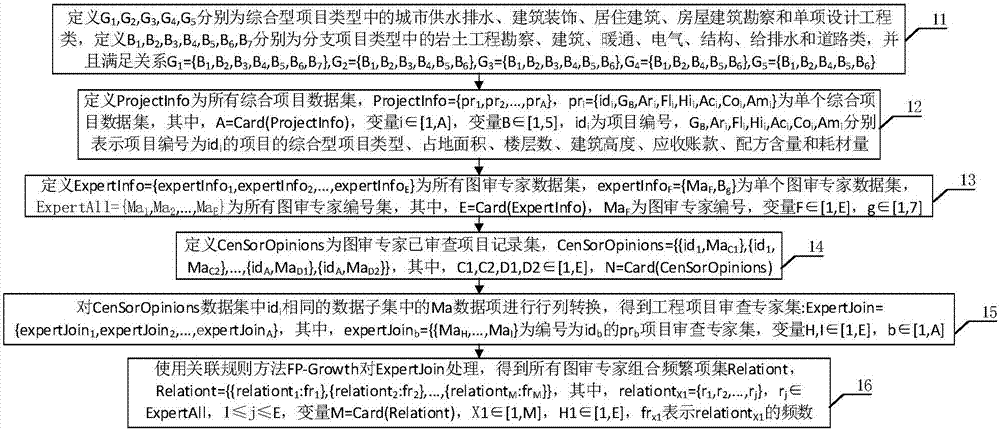
步驟1:對待審查項目和綜合項目記錄集中的項目屬性進行歸一化預處理,所述待審查項目和綜合項目通過綜合項目類型、綜合項目類型的分支項目類型和項目屬性表示,具體的如圖2所示:
步驟1.1:定義G1,G2,G3,G4,G5分別為綜合型項目類型中的城市供水排水、建筑裝飾、居住建筑、房屋建筑勘察和單項設計工程類,定義B1,B2,B3,B4,B5,B6,B7分別為分支項目類型中的巖土工程勘察、建筑、暖通、電氣、結構、給排水和道路類,并且滿足關系:
G1={B1,B2,B3,B4,B5,B6,B7},G2={B1,B2,B3,B4,B5,B6},G3={B1,B2,B3,B4,B5,B6},G4={B1,B2,B4,B5,B6},G5={B1,B2,B4,B5,B6}
步驟1.2:定義ProjectInfo為所有綜合項目數據集,ProjectInfo={pr1,pr2,...,prA},pri={idi,GB,Ari,Fli,Hii,Aci,Coi,Ami}為單個綜合項目數據集,其中,A=Card(ProjectInfo),函數Card()用于計算集合元素數量,變量i∈[1,A],變量B∈[1,5],idi為項目編號,GB,Ari,Fli,Hii,Aci,Coi,Ami分別表示項目編號為idi的項目的綜合型項目類型、占地面積、樓層數、建筑高度、應收賬款、配方含量和耗材量;
步驟1.3:定義HP為待處理項目,綜合型項目類型為HPType,項目數據集HPInfo={HPType,HAr,HFl,HHi,HAc,HCo,HAm},其中,HAr,HFl,HHi,HAc,HCo,HAm分別為HP項目的占地面積、樓層數、建筑高度、應收賬款、配方含量和耗材量;
步驟1.4:定義Armin,Flmin,Himin,Acmin,Comin,Ammin分別為步驟1.2中的ProjectInfo中Ar,Fl,Hi,Ac,Co,Am的最小值,Armax,Flmax,Himax,AcMax,Comax,Ammax分別為步驟1.2中的ProjectInfo中Ar,Fl,Hi,Ac,Co,Am的最大值,定義循環變量P,用來遍歷步驟1.2中的ProjectInfo,P賦初值為1;
步驟1.5:當循環變量P≤A時,則轉至步驟1.6;否則執行步驟1.8;
步驟1.6:ArP=(ArP-Armin)/(Armax-Armin),FlP=(FlP-Flmin)/(Flmax-Flmin),HiP=(HiP-Himin)/(Himax-Himin),AcP=(AcP-Acmin)/(Acmax-Acmin),CoP=(CoP-Comin)/
(Comax-Comin),AmP=(AmP-Ammin)/(Ammax-Ammin);即對綜合項目記錄集中的數據的歸一化處理;
步驟1.7:令P=P+1,轉至步驟1.5;
步驟1.8:HAr=(HAr-Armin)/(Armax-Armin),HFl=(HFl-Flmin)/(Flmax-Flmin),HHi=(HHi-Himin)/(Himax-Himin),HAc=(HAc-Acmin)/(Acmax-Acmin),HCo=(HCo-Comin)/(Comax-Comin),HAm=(HAm-Ammin)/(Ammax-Ammin);即對待審查項目的數據的歸一化處理。
步驟2:通過皮爾遜相似度方法對歸一化后的數據集處理得出與待審查項目規模最接近的十個項目,并抽取十個項目的審查專家,所述審查專家通過研究的分支項目類型和審查項目記錄表示,具體的如圖3所示:
步驟2.1:定義ExpertInfo={expertInfo1,expertInfo2,...,expertInfoE}為所有圖審專家數據集,expertInfoF={MaF,Bg}為單個圖審專家數據集,ExpertAll={Ma1,Ma2,...,MaE}為所有圖審專家編號集,其中,E=Card(ExpertInfo),MaF為圖審專家編號,變量F∈[1,E],g∈[1,7],Bg為編號為MaF圖審專家研究的分支項目類型;
步驟2.2:定義CenSorOpinions為圖審專家已審查項目記錄集,CenSorOpinions={{id1,MaC1},{id1,MaC2},...,{idA,MaD1},{idA,MaD2}},其中,C1,C2,D1,D2∈[1,E],N=Card(CenSorOpinions);
步驟2.3:對步驟2.2中的CenSorOpinions數據集中idi相同的數據子集中的Ma數據項進行行列轉換,得到工程項目審查專家集:
ExpertJoin={expertJoin1,expertJoin2,...,expertJoinA},其中,expertJoinb={{MaH,...,MaI}為編號為idb的prb項目審查專家集,變量H,I∈[1,E],b∈[1,A];
步驟2.4:定義循環變量R,用來遍歷步驟1.2中的所有綜合項目數據集ProjectInfo,X={HAr,HFl,HHi,HAcc,HCo,HAm},simR為步驟1.2中的ProjectInfo中的綜合項目prR與待處理項目HP的相似度,Sim為相似度集,其中,R∈[1,A],R賦初值為1,idR為單個綜合項目prR的項目編號,Sim賦初值為
步驟2.5:當循環變量R≤A,則執行步驟2.6;否則轉至步驟2.9;
步驟2.6:Y={ArR,FlR,HiR,AcR,CoR,AmR},其中,
步驟2.7:其中,Xr1,Yr1分別表示X,Y中的第r1個數據項,分別表示X,Y中元素的平均值,分別表示X,Y中元素的平均值,Sim=Sim∪{idR,simR};
步驟2.8:令R=R+1,轉至步驟2.5;
步驟2.9:得到Sim={{id1,sim1},{id2,sim2},...,{idA,simA}}后進行排序,得到有序相似度集Simi={{idj1,aj1},{idj2,aj2},...,{idjA,ajA}},其中,aj1≥aj2≥...≥ajA,{idjt,ajt}∈Sim,jt,j1,j2,jA∈[1,A],SimProject={{idj1,aj1},{idj2,aj2},...,{idj10,aj10}};
步驟2.10:定義Forecast為預選圖審專家集,并賦初值為定義循環變量V,用來遍歷步驟2.9中的SimProject,V賦初值為1,定義變量T為預選的圖審專家編號;
步驟2.11:當循環變量V≤10時,則執行步驟2.12;否則轉至步驟2.14;
步驟2.12:令項目審查專家集expertJoinjV為項目編號為idjV的審查專家集,預選圖審專家集
步驟2.13:令V=V+1,轉至步驟2.11;
步驟2.14:得到預選圖審專家集Forecast={Mam1,Mam2,...,Mamn},其中,Mami為預選圖審專家集Forecast中的第i個數據項,Mami∈ExpertAll,mi∈[1,E]。
步驟3:根據待審查的綜合項目的分支項目類型和圖審專家研究方向,對抽取出的專家進行組合,得到所有備選組合專家集,具體的如圖4所示:
步驟3.1:定義Work為有審查任務的圖審專家集,Work={Mau1,Mau2,...,Maun},預選圖審專家集Forecast=Forecast-Work,其中,Maui為Work中的第i個數據項,Maui∈ExpertAll,ui∈[1,E];
步驟3.2:定義綜合型項目類型GN2={E1,E2,...,EZ},GN2={E1,E2,...,EZ}為待參與綜合型項目類型GN2審查的圖審專家集,其中,EJ為待參與分支項目類型EJ審查的圖審專家集,EJ賦初值為GN2=HPtype,即綜合型項目類型GN2為步驟2.1中的待處理項目HP的綜合型項目類型HPtype,Z=Card(GN2),Z∈[5,7],J∈[1,Z];
步驟3.3:定義循環變量Num1,Num2分別用來遍歷步驟3.2中的GN2和步驟3.1中的Forecast,并都賦初值為1,Num3=Card(Forecast),ENum1為步驟3.2中的GN2圖審專家集中第Num1個分支項目類型,MaNum2為步驟3.1中的Forecast中第Num2個圖審專家編號;
步驟3.4:當循環變量Num1≤Z時,則執行步驟3.5;否則轉至步驟3.17;
步驟3.5:當循環變量Num2≤Num3時,則執行步驟3.6;否則轉至步驟3.10;
步驟3.6:令BNum4為編號MaNum2專家研究的分支項目類型,{MaNum2:BNum4}∈ExpertInfo,其中,Num4∈[1,7];
步驟3.7:當BNum4==ENum1時,即編號MaNum2專家研究的分支項目類型與GN2圖審專家集中第Num1個分支項目類型,則執行步驟3.8;否則轉至步驟3.9;
步驟3.8:步驟3.2中的GN2圖審專家集中的第Num1個數據項目ENum1=ENum1∪MaNum2;
步驟3.9:令Num2=Num2+1,轉至步驟3.5;
步驟3.10:當時,則執行步驟3.11;否則轉至步驟3.16;
步驟3.11:定義循環變量c,用于遍歷步驟1.3中的ExpertInfo,ExpertInfo中的第c個數據項expertInfoc={Mac,ty},其中,ty為編號Mac專家審查的分支項目類型,c賦初值為1;
步驟3.12:當循環變量c≤E時,則執行步驟3.13;否則執行步驟3.16;
步驟3.13:當并且ty==ENum1時,則執行步驟3.14;否則執行步驟3.15;
步驟3.14:ENum1=ENum1∪Mac;
步驟3.15:令c=c+1,轉至步驟3.12;
步驟3.16:令Num1=Num1+1,轉至步驟3.4;
步驟3.17:得到GN2={E1,E2,...,EZ},EJ={MaJ1,MaJ2,...,MaJnu},nu=Card(EJ),J∈[1,Z]
步驟3.18:定義ExportCom為所有備選審查HP的圖審專家組合集,定義Com為其中一種備選審查HP的圖審專家組合集;
步驟3.19:定義ComN3={Q1,Q2,...,QN5},ExportCom={Com1,Com2,...,ComN6},SN3為ComN3的支持度,SC={S1,S2,...,SN6}為支持度集,其中,QN7表示ComN3中的第N7個圖審專家編號,QN7為EN7中任意一個元素,EN7為步驟3.17中的GN2中第N7個數據項,1≤N7≤Z,N5=Z,1≤N3≤N6,N3賦初值為1,定義End為最終審查步驟2.1中的HP項目的圖審專家集,End賦初值為
步驟4:使用FP-Growth方法對歷史項目審查專家集處理,得到圖審專家組合頻繁項集,具體的:使用關聯規則方法FP-Growth對步驟2.5中的工程項目審查專家集ExpertJoin處理,得到所有圖審專家組合頻繁項集Relationt,Relationt={{relationt1:fr1},{relationt2:fr2},...,{relationtM:frM}},其中,relationtX1={r1,r2,...,rj},rj∈ExpertAll,1≤j≤E,變量M=Card(Relationt),X1∈[1,M],H1∈[1,E],frx1表示relationtX1的頻數。
步驟5所有備選專家組合中契合度最高的專家組合的方法流程步驟51到步驟5.8,具體的如圖5示:
步驟5.1:步驟3.19中的N3用于遍歷步驟3.19中所有備選組合專家集ExportCom,步驟3.19中的N6為ExportCom的子集個數;
步驟5.2:當N3≤N6時,
步驟5.3:將步驟3.19中的ComN3賦值給步驟X1即步驟5.4.1到步驟5.4.14中的ExpertHandle,Relationt賦值給步驟5.4中的Rel;
步驟5.4:執行步驟X1,即步驟5.4.1到步驟5.4.14;
步驟5.5:將步驟X1,即步驟5.4.1到步驟5.4.14執行結果SValue賦值給SN3,SN3為步驟3.19中的SC中第N3個元素;
步驟5.6:N3=N3+1;
步驟5.7:令SN4為SC中最大的值,ComN4的支持度為SN4,其中,N4∈[1,N6];
步驟5.8:得到最終審查HP項目的圖審專家集End={K1,K2,...,KZ},即End=ComN4,Work=Work∪End,其中,1≤q≤Z;
步驟5.4:合頻繁項集通過每種專家組合自適應契合度方法計算每種備選專家組合集的支持度,最終支持度最大即契合度最高的專家組合集即為參與待審查項目的專家集,具體的如圖6示:
步驟5.4.1:定義圖審專家組合集ExpertHandle={Ma1,Ma2,...,MaNu},SValue為ExpertHandle的支持度,所有圖審專家組合頻繁項集Rel={{rel1:f1},{rel2:f2},...,{relM1:fM1}},其中,Nu=Card(ExpertHandle),M1=Card(Rel),SValue賦初值為0;
步驟5.4.2:定義Subset={Sub1,Sub2,...,SubNu},Sub1={Su11,Su12,...,Su1n1},Su1n1={dkh},Sub2={Su21,Su22,...,Su2n2},Su2n2={dki,dkj},SubNu={SuNu1},SuNu1={dk1,dk2,...,dkNu},其中,dkh,dki,dkj,dk1,dk2,...,dkNu∈ExpertHandle,即Subset為從ExpertHandle中抽取的專家并組合后的所有的組合結果,Sub1為從ExpertHandle中任意抽取1個專家組成的n1=Nu個組合結果集,Sub2為從ExpertHandle中任意抽取2個專家組成的個組合結果集,SubNu為從ExpertHandle中抽取Nu個專家組成僅一個組合結果集;
步驟5.4.3:定義循環變量index1,用于遍歷Subset,其中,index1賦初值為1;
步驟5.4.4:當循環變量index1≤Nu時,則執行步驟5.4.5;否則執行步驟5.4.14;
步驟5.4.5:定義循環變量index2,用于遍歷Subindex1,其中,Suindex1index2為從Subindex1中取出的第index2個集合,index2賦初值為1;
步驟5.4.6:當循環變量時,則執行步驟5.4.7;否則執行步驟5.4.13;
步驟5.4.7:定義循環變量index3,用于遍歷Rel,定義{relindex3:findex3}為Rel第index3個集合,其中,變量index3賦初值為1;
步驟5.4.8:當循環變量index3≤M1時,則執行步驟5.4.9;否則執行步驟5.4.12;
步驟5.4.9:當Suindex1index2=relindex3時,則執行步驟5.4.10;否則執行步驟5.4.11;
步驟5.4.10:SValue=SValue+findex3*index1,即SValue的值更新為SValue的值加上指定的專家組合頻數與該專家組合專家數量的乘積;
步驟5.4.11:index3=index3+1,轉至步驟5.4.8;
步驟5.4.12:index2=index2+1,轉至步驟5.4.6;
步驟5.4.13:index1=index1+1,轉至步驟5.4.4;
步驟5.4.14:得到SValue。
其中,皮爾遜相似度方法是通過對項目屬性預處理后的數據集進行數據分析,FP-Growth方法對歷史項目審查專家集處理,得到圖審專家組合頻繁項集,專家組合契合度方法根據頻繁項集計算每種專家組合的支持度,即專家組合契合度。
通過PF-Growth方法對65536條歷史項目審查專家記錄進行關聯規則挖掘,得到圖審專家組合頻繁項集;對20061條綜合項目記錄進行數據壓縮和預處理,采用皮爾遜相似度方法并抽取與待審查項目規模最接近的十個項目的審查專家,使得抽取出來的專家均為審查過與待審查項目類似的專家;本發明方法在實際應用中較人工推薦的專家組合結果相似度達到82.13%,采納率達到97.25%。
- 還沒有人留言評論。精彩留言會獲得點贊!