一種城市路網機動車尾氣排放遙感監控系統的制作方法
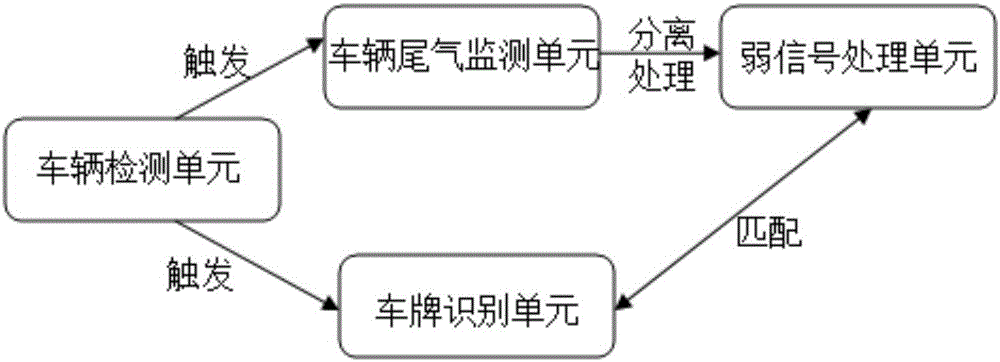
本發明具體涉及一種城市路網機動車尾氣排放遙感監控系統,屬于環境監測
技術領域:
。
背景技術:
:由于近年來全國機動車保有量迅猛增長,致使市區以及各地交通擁堵現象日趨嚴重,大氣環境質量也呈現出惡化趨勢,機動車排氣污染監控工作正面臨著嚴峻的挑戰。機動車尾氣是城市大氣環境污染的重要污染物,是城市空氣污染的主要源頭,在城市環境污染監測方面,機動車尾氣監測所占比例越來越高,已經成為環境保護與管理的重要組成部分。因此,有必要建立一套完善的系統,對機動車尾氣中有害氣體的排放進行監測和管理,同時加強對機動車尾氣污染的控制,對尾氣排放加大檢測和監管的力度。從2000年以來,環保部門對于機動車尾氣的監管不斷加強,一方面,通過提高排放標準加速老舊機動車淘汰的速度:機動車尾氣排放標準不斷提高,從歐I、歐II到國五標準,僅僅經過了10余年的時間。另一方面,機動車尾氣檢測手段和技術不斷發展,先后經歷雙怠速法、簡易工況法、模擬工況法、遙感監測法等階段,檢測設備也從手持式、便攜式、檢測場固定式發展到了車載移動式、路側固定式。其中,由于新興的遙感監測法具有檢測周期短、無需人工參與、準確度高與不影響交通的特點,已漸漸成為機動車尾氣檢測的重要技術手段,得到了業界的普遍認同。盡管如此,遙感監測法能解決的也僅僅是尾氣檢測的問題,對于城市機動車(尤其在用機動車)的整體管控問題,仍然不能完全解決。以下將從系統的角度,對機動車尾氣遙測設備、布點與組網算法、數據處理算法等方面進行文獻調研和比較,以詮釋本發明專利的創造性與優越性。對于汽油車尾氣遙測的相關技術方法,已有了一定的研究基礎。王鐵棟等在《機動車尾氣遙測技術和應用研究》(大氣與環境光學學報,2007年03期)與《基于可調諧半導體激光技術的機動車尾氣中CO、CO2遙測》(紅外與激光工程,2007年S1期)中提出了利用可調諧二極管激光吸收光譜(TDLAS)和差分吸收光譜(DOAS)技術可以實現對尾氣中CO、CO2、HC、NO和煙塵等污染物的實時測量,該文獻主要給出了尾氣遙測法的物理原理,對其實現方法敘述較少。發明專利《多車道機動車尾氣PM2.5遙測裝置》(申請號:201310655684.4)與《多車道機動車尾氣遙測裝置》(申請號:200910241681.X)通過對尾氣檢測單元、速度加速度檢測單元、風速風向檢測單元、路況識別單元、牌照記錄單元、控制單元等模塊的集成,實現了針對不同污染物的尾氣遙測設備,本質上是一種水平式尾氣遙測設備,要求短時間內只有一輛車通過監測點的條件,也就是說,對于交通流較大的多車道其適用性較差。發明專利《一種多車道機動車尾氣檢測系統》(申請號:201010568201.3)與《一種機動車尾氣檢測裝置》(申請號:201510897679.3)與針對固定水平式尾氣遙測設備無法適用于交通復雜路段的缺點進行了改進,增加了路面反射帶,利用垂直發射/接收的激光束,實現了真正意義上的固定垂直式尾氣遙測設備,各個車道的尾氣檢測相互獨立、互不干擾,可以適用于交通流大的多車道路段。但是,由于增加了路面反射帶,反射帶的清潔度將直接影響設備的精度,所以由之而來的反射帶的清潔與保養工作會無形中增加設備成本與人工成本。柴油車尾氣遙測的相關技術方法也同樣引起了人們的注意。發明專利《一種柴油車尾氣煙度圖像識別系統》(申請號:201210229911.2)提出了利用攝像機柴油車尾氣拍照,然后基于圖像處理技術計算出尾氣煙度。由于其結構也是一種固定水平式尾氣遙測設備,所以仍然會受到大車流量的制約。由于機動車尾氣遙測設備尚未在城市路網得到廣泛使用,對于遙測設備的布點選址問題,已有的研究很少。《一種城市路網機動車尾氣實時遙感監測基址選取方法》(申請號:201510214145.6)公開了一種在整個城市路網區域進行遙測設備的選址方法,該方法的目的是通過尾氣遙測設備的點位優化從而使得城市路網上的遙測設備可檢測到盡量多的車輛,該方法側重于個體車輛排放水平的普查,不適合例如重點車輛尾氣排放狀況排查、城市路網區域排放濃度估計等方面的研究。在環境監測領域內,與此相似的有空氣質量監測的布點選址問題,關于這一問題的研究較多。傳統的空氣質量監測的布點選址方法主要有:網格布點法、功能分區布點法、扇形布點法和同心圓多方位布點法。劉潘煒等在《區域空氣質量監測網絡優化布點方法研究》(中國環境科學,2010年07期)中以最大貼近度為優化目標,提出一種區域空氣質量監測網絡點位優化問題的整數規劃模型,并采用分支定界法進行求解。由于尾氣遙測設備是安裝在道路上的,該文獻中考慮的人口約束及空間覆蓋度約束不適用于本項目,而且目標函數也不同。萬開等在《網絡自動質控在空氣優化布點監測中的應用》(環境科學與技術,2010年6E期)中將固定和移動自動監測結合起來,使用網絡遠程質控技術實現空氣質量監測的優化布點,本質上還是網格布點法。然而我們所要進行安裝布設的遙測設備只是固定式的,該方法因此也不適用。發明專利《一種空氣質量監測站優化布點方法》(申請號:201610037653.6)公開了一種以克里金方差最小化為目標的空氣質量監測站優化布點方法,該方法考慮在研究區域內已經存在監測布點網絡的基礎上在該區域增加布點。而對于機動車尾氣遙感監測而言,這樣的網絡尚未形成,因此該發明所提供的方法無法適用于機動車尾氣遙測設備布點。由于空氣污染物濃度的影響因素復雜繁多,從長期或平均狀態來說,取決于城市的能源結構、交通和工業排放污染物的多少,但從短期或實時狀態而言,卻主要與當地、當時的氣象條件有關。這一系列的因素導致對空氣污染物濃度進行預報具有一定的挑戰性,因此目前國內外還沒有有效的技術方法對重污染過程進行準確的預報,高濃度污染的預報成為了國內外亟待克服的重要難題。發明專利《基于數值模式與統計分析結合的大氣重污染預報方法》(申請號:CN201310038573.9)提出了一種基于數值模式與統計分析結合的大氣重污染預報方法。該方法將數值預報方法與統計預報方法相結合,一定程度上克服了兩種預報方法單獨使用時存在的缺點,即數值預報方法對非重污染時段預報效果較好,但對由于復雜氣象條件導致污染物輸送、擴散、轉化的重污染時段預報誤差高達400%;而統計預報方法準確率和計算效率較高,但對歷史資料依賴性較強,并缺乏一定物理意義。發明專利《一種基于特征向量和最小二乘支持向量機的PM25濃度預測方法》(申請號:CN201410201739.9)、《一種基于多領域特征的城市空氣質量等級預測方法》(申請號:CN201410452557.9)與《一種空氣污染物濃度預測方法》(申請號:CN201510767342.0)均實現了依據歷史空氣污染物濃度監測數據對當前或未來某一時刻空氣污染物濃度進行預報,但是他們共有的問題是:預測方法較為復雜,對歷史數據的利用、整合有待加強,泛化能力及預報準確率都有待提高。機動車尾氣排放因子可反映機動車的排放水平,對機動車尾氣排放因子的傳統評估方法是建立影響機動車排放的參數與污染物排放之間的關系,稱之為排放因子模型。國外研究排放因子模型的時間較長,已經建立了MOBOLE、EMFAC、IVE、CMEM、COPERT等多個模型。而大部分都是通過臺架試驗的方法得到數據建立模型,由于實際道路情況復雜,這樣的模型無法真實反映在實際道路上行駛的機動車的尾氣排放。近年來,利用隧道試驗來評估排放因子的方法得到了廣泛的應用,該方法通過現場收集車流和氣象數據,測量隧道進出口污染物濃度,利用質量平衡計算出各種污染物的排放因子,從而反映出實際路況下機動車污染物的排放特性。但由此得到的往往是平均行駛速度下的排放因子或總測試時段內的平均排放因子,因此無法考察機動車行駛工況(不同瞬態車速和加/減速度)對排放特性及排放因子的影響。發明專利《一種基于機動車比功率的速度對車輛排放因子修正方法》(申請號:201510745166.0)根據車輛行駛速度計算機動車比功率,得到不同速度區間的比功率分布情況,并利用平均速度計算的修正系數對其進行修正。該方法在計算過程中不僅需要車輛的速度、加速度數據,還需要基本排放因子、MOVES數據庫中的排放率等數據的輸入,計算過程較復雜;另一方面,該方法只考慮行駛工況,并未將氣象條件對機動車尾氣排放的影響考慮在內。受經濟水平和科研能力的限制,我國空氣質量監測工作起步較晚,自上世紀七十年代開始到現在,經過四十多年的發展,目前我國很多省市已經建立起空氣質量監測系統,但針對道邊空氣污染物濃度的檢測仍存在很大的進步空間。其中的主要原因有:一、目前用于道邊空氣污染物濃度檢測的設備主要為空氣監測站,該設備價格昂貴,只能在城市內布設有限數量的站點,然而城市路網龐大,拓撲結構和周圍環境復雜,通過檢測設備實現城市各區域道邊空氣污染物濃度的實時預測可行性很低。二、基于設備全面檢測的低可行性,各國學者力圖通過預測方法來解決這個問題,目前國內外針對道邊空氣污染物濃度的研究中,采用的方法主要分兩大類:1、高斯模型以及后續的以高斯模型為基礎的一系列線源模型,如王煒等在《城市交通規劃理論及其應用》(東南大學出版社,1998年)所述,這類方法針對不同狀態的道路需采用不同的模型,且對復雜道路的模型準確性不高;2、基于神經網絡的道邊污染物濃度檢測,如楊忠振等在《基于神經網絡的道路交通污染物濃度預測》(吉林大學學報(工),2007年37期)所述,這類方法能通過識別輸入、輸出數據之間簡單的非線性關系,但在學習輸入、輸出數據內部之間更本質的特征映射方面有很大局限性,每個神經網絡只能表征一種污染物與輸入的關系,在實時性和遷移性上存在很大缺陷。雖然國內遙感監測法已經慢慢開始發展普及,但是其后續工作仍比較空白。雖然許多地方也建立了相關的數據平臺,但是數據存儲分散,不能有效地結合在一起,也沒有得到統一的管理。同時,得到的數據缺乏多樣性,與車主、實時天氣、當前路況信息等數據沒有緊密結合在一起。這些都給后續的數據分析和環保政策的提出造成了巨大的困難。因此,針對機動車遙測項目對數據方面的需求,迫切需要建立一套完整的數據中心平臺,實現與尾氣監控、數據處理一體化的數據中心,推動我國機動車尾氣遙測產業快速發展,為環境污染地域的聯防聯控和氮氧化物總量減排的政策提供強有力的技術支撐。技術實現要素:傳統的遙感監測法只能對其中極少部分車輛進行檢測,且各監測點分散,沒有實現網絡化、智能化、系統化、集成化,沒有充分利用各監測點數據的相互聯系,無法實現更高層面的監管,為有關部門提供決策依據或建議。本發明技術能克服上述缺點,真正發揮尾氣遙測設備的優勢,實現城市管理的網絡化、智能化解決問題,提供一種城市路網機動車尾氣排放遙感監控系統。本發明技術解決方案:一種城市路網機動車尾氣排放遙感監控系統,包括:遙測設備層、選址布點層與數據處理層;遙測設備層,實現對機動車尾氣中CO、CO2、NOx、HC濃度、以及不透光煙度的檢測,同時記錄機動車的速度、加速度與機動車牌照號碼,最終得到每輛通過監測點機動車的尾氣遙測數據及機動車屬性、行駛工況、檢測時間、氣象條件數據,并將尾氣遙測數據及機動車屬性、行駛工況、檢測時間、氣象條件數據傳輸到數據處理層;選址布點層,解決遙測設備層中機動車尾氣遙測設備在城市路網中的選址布點問題,能夠將路網拓撲、道路信息、氣象信息、交通信息及布點區域已有檢測器數量的數據作為輸入,實現有效檢測車輛數最大、車輛檢測差別性最小及道路覆蓋率最大的目標,根據性能指標的不同,為相關部門提供多種選址布點方案,采用選址布點層的選址布點方法,對遙測設備層中機動車尾氣遙測設備在城市路網中的布設點位進行優化,確保采集數據的完整性和多樣性,更好地服務于數據處理層的數據處理方法;數據處理層,實現對遙測設備層采集的機動車尾氣遙測數據及機動車屬性、行駛工況、檢測時間、氣象條件數據的存儲、分析與融合,結合車載診斷系統數據庫、便攜式排放測試系統數據庫、車檢所離線數據庫、交通信息數據庫與地理信息數據庫,對機動車尾氣遙測數據進行分析處理,實現機動車尾氣排放因子估計、機動車尾氣排放特征分析、道邊空氣污染物濃度估計、道邊空氣污染物濃度預測及城市全局環境預測,為環保部門的政策制定與執法提供科學依據。所述遙測設備層包括移動式尾氣遙測設備、水平式尾氣遙測設備和垂直式尾氣遙測設備三種設備,其中,水平式尾氣遙測設備和垂直式尾氣遙測設備都固定安裝在道路上,水平式尾氣遙測設備用于單車道的道路以及車流量少的多車道道路;垂直式尾氣遙測設備用于車流量大的多車道道路;移動式尾氣遙測設備在城市路網上進行巡邏,服務于需要臨時進行機動車尾氣檢測的道路,能夠應對突發狀況對尾氣檢測的需求,并增加城市路網的監測密度;三種設備分別用于城市路網上的不同道路,水平式尾氣遙測設備基于深度殘差學習網絡對柴油車尾氣煙度進行檢測,垂直式尾氣遙測設備使用路面反射的弱信號進行尾氣污染物成分與濃度的分析。所述垂直式尾氣遙測設備包括車輛檢測單元、尾氣檢測單元、弱信號處理單元和車牌識別單元四個部分;車輛檢測單元包括兩組激光發生器和接收器,兩組激光發生器以一定距離間隔安置于橫跨車道的龍門架上,發射激光垂直于車道,經路面反射后被龍門架上的激光接收器接收,當機動車行駛通過檢測區時,激光發射器發出的激光就會受到影響,使發射器-接收器之間的光路縮短,從而說明有機動車行駛進入檢測區,機動車在離開檢測區時會導致發射器-接收器之間的光路恢復到無車狀態,利用兩組激光器分別記錄的機動車進入、離開時刻差獲取機動車速度、加速度信息;同時輸出觸發信號觸發尾氣檢測單元對尾氣信息進行采集,觸發車牌識別單元對車牌信息進行采集;尾氣檢測單元,由多個安裝在橫跨車道的龍門架上垂直于路面的激光發射器構成,每個激光發射器以一定距離間隔安置,每個激光發射器均垂直向地面發射激光束,由于每個車道的激光接收器會受到不同車道激光的影響,每個激光接收器接收到的是混疊信號,通過對激光接收器混疊信號的分析,得到尾氣污染物成分與濃度的混疊數據,每個接收器的數據會被發送到弱信號處理單元進行弱信號提取與分離;弱信號處理單元,包括弱信號提取模塊和弱信號分離模塊,弱信號提取模塊根據弱信號與噪聲信號在頻率分布、覆蓋范圍、統計特性方面的差異,識別和提取出尾氣檢測單元數據的相關弱信號數據;弱信號分離模塊對弱信號提取模塊中提取出的相關弱信號數據進行分離處理,選擇線性瞬時混合模型作為弱信號的模型,采用獨立分量分析的方法對不同源的相互混疊的弱信號進行分離,最終獲取通過監測點的機動車尾氣污染物成分與濃度;車牌識別單元包括一臺攝像機與圖像處理模塊,當車輛檢測單元檢測到有機動車進入檢測區時,輸出觸發信號,使攝像機對車頭進行多次拍照,由圖像處理模塊進行照片的篩選與車牌照號碼的識別,完成檢測結果與車牌號之間的關聯,從而最終實現基于路面反射的垂直式機動車尾氣遙測。所述垂直式尾氣遙測設備中,車輛檢測單元中,所述獲取機動車速度、加速度信息的過程如下:機動車經過第一組激光發射裝置和第二組激光發射裝置的平均速度為vel1,vel2,其計算方法為速度加速度為其中,Ldis為兩組激光發射器間隔,記錄接收器1和接收器2下降沿出現的時刻為T1,T2,記錄接收器1和接收器2上升沿出現的時刻為T3,T4。所述垂直式尾氣遙測設備中,所述弱信號處理單元中,所述弱信號分離模塊,選擇線性瞬時混合模型作為弱信號的模型,假設N1個源信號s(t)被M1個檢測器接收后輸出混合信號x(t),線性瞬時混合模型可以表示為x(t)=Bs(t),其中是M1*1維觀測信號的向量,M1表示接收的檢測器的數目,是N1*1維相互獨立的源信號的向量,N1表示源信號的個數,B是一個M1*N1維的混合矩陣,其估計模型表示為y(t)=Wx(t),其中y(t)是對源信號s(t)的估計,W是一個M1*N1維的矩陣,稱之為分離矩陣;采用獨立分量分析的方法對不同源的相互混疊的弱信號進行分離,求解分離矩陣W,對源信號進行估計。所述垂直式尾氣遙測設備中,弱信號處理單元中,所述采用獨立分量分析的方法進行弱信號分離的步驟如下:步驟一、對提取到的數據進行預處理,包括數據中心化和白化處理,數據中心化,使輸出混合信號x中心化,具體做法是用x減去其均值向量E(x),將x轉化為零均值向量。白化處理,對x進行線性變換,使得x的各分量方差都為1,白化的目的就是降低輸入的冗余性,使得x(t)的各個分量不相關聯,通過預處理,有效地降低了求解的復雜度,減小了工作量,記預處理后的數據為z(t);步驟二、隨機地選擇一個初始向量W(N2),N2=1;N2表示迭代的次數;步驟三、W(N2+1)=E{zg(WT(N2)z)}-E{g′(WT(N2)z)}W(N2),其中非線性函數g取g(x)=x3,E表示均值,z為預處理后的數據,W為分離矩陣;步驟四:作正交歸一化處理,W(N2+1)=W(N2+1)/‖W(N2+1)‖其中‖·‖表示矩陣范數;步驟五:判斷W(N2)是否收斂,收斂則停止迭代得到W(N2),否則返回步驟三繼續迭代。所述遙測設備層的水平式尾氣遙測設備中,所述基于深度殘差學習網絡的柴油車尾氣煙度檢測方法包括以下步驟:步驟1、在選定的路段用CCD攝像機對經過的柴油車進行尾氣視頻記錄,通過圖像采集卡從尾氣視頻中獲取柴油車尾氣圖像;步驟2、在選定的路段中用汽柴一體化機動車尾氣遙測裝置直接測量柴油車的尾氣煙度,獲取柴油車尾氣圖像中車輛的尾氣煙度,將獲取的尾氣煙度作為相應柴油車尾氣圖像的標簽,柴油車尾氣圖像和相應的標簽構成柴油車尾氣煙度數據集;步驟3、構建20層深度殘差學習網絡,該網絡包含一個普通卷積層、一個池化層,八個殘差學習單元,一個平均池化層,一個全連接層;普通卷積層的作用是學習全局性特征,池化層pool1的作用是降低卷積層輸出的特征向量,同時改善結果,降低過擬合出現的可能性;八個殘差學習單元的作用是學習特征的同時提高精度,平均池化層的作用是對這一層的輸入進行降采樣操作,最后一個全連接層構成一個20分類器,對輸入的柴油車尾氣煙度圖像分類;所述八個殘差學習單元中的每一個殘差學習單元包含兩個殘差卷積層,每個殘差學習單元的輸入不僅包含上一個殘差學習單元的輸出,還包含上一個殘差學習單元的輸入,即構成了跨層連接的輸入輸出方式;普通卷積層的輸入為經過預處理的圖像,普通卷積層的輸出作為池化層的輸入,池化層的輸出為八個殘差學習單元中第一個殘差學習單元的輸入,殘差學習單元之間按照跨層連接的輸入輸出方式傳遞數據;池化層的輸入是最后一個殘差學習單元的輸入和輸出;全連接層的輸入是平均池化層的輸出;步驟4、對柴油車尾氣煙度數據集進行預處理,將預處理后的圖像作為深度殘差學習網絡的輸入,對深度殘差學習網絡進行訓練、驗證和測試,得到能夠精確檢測柴油車煙度的深度殘差學習網絡;步驟5、對于沒有安裝汽柴一體化機動車尾氣遙測裝置的路段,在道邊布設CCD攝像機以獲取柴油車尾氣圖像,并輸入到訓練完成的深度殘差學習網絡中,從而實現對柴油車尾氣煙度的檢測。所述一種基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中,所述步驟1,在選定的路段用CCD攝像機對經過的柴油車進行尾氣視頻記錄,用圖像采集卡從記錄的視頻中抽取出有含有柴油車尾氣的圖像,將這些圖像按照75%、10%、15%的比例分成訓練集,驗證集和測試集。所述一種基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中,所述步驟2具體如下:在選定的路段安裝汽柴一體化機動車尾氣遙測裝置,該裝置的激光模塊發出的檢測激光穿過道路上柴油機動車排放的尾氣,照射到另一側的光強檢測單元,光強檢測單元接收到因柴油車尾氣煙度受到削弱的激光,通過激光削弱程度可以得到柴油車尾氣煙度值,找到該柴油車尾氣煙度值對應的柴油車尾氣圖像,該柴油車尾氣煙度值即為對應的柴油車尾氣圖像的標簽。所述一種基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中,所述步驟3中,一個普通卷積層的卷積核大小為7*7;一個池化層的卷積核大小為2*2;八個殘差學習單元的卷積核大小為3*3;一個平均池化層的卷積核大小為2*2。所述一種基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中,所述步驟4中,首先對柴油車尾氣煙度數據集中進行預處理,具體包括對數據集中的柴油車尾氣圖像進行尺度增強、隨機采樣和減像素均值操作;然后將預處理后的圖像作為深度殘差學習網絡的輸入,對深度殘差學習網絡進行訓練、驗證和測試,得到能夠精確檢測柴油車煙度的深度殘差學習網絡,具體包括:將預處理后的圖像作為深度殘差學習網絡的輸入進行訓練,同時對驗證集進行過擬合檢查,即判斷深度殘差學習網絡對驗證集圖像處理的損失函數是否呈現先下降后反而上升的現象,當驗證集的損失函數不再下降時候,即可暫時停止訓練;將預處理后的測試集圖像作為訓練終止后的深度殘差學習網絡的輸入,將此時網絡的輸出與步驟2中的標簽值進行比較,若測試集精度超過99%,則訓練完成,否則,繼續訓練。所述選址布點層包括基于道路相似性的布點模塊、基于路網拓撲結構的布點模塊與基于特定車輛路線的布點模塊;基于道路相似性的布點模塊,使用一種基于道路相似性的機動車尾氣遙測設備布點方法來實現,充分考慮了道路特性、道邊環境與氣象因素,提取出其中關鍵的屬性進行聚類,采用層次聚類的方法對城市路網的不同路段進行聚類,能夠將任意數目的尾氣遙測設備進行優化布點;基于路網拓撲結構的布點模塊,使用一種基于圖論的機動車尾氣遙感監測設備布點算法來實現,以城市路網拓撲結構為主,輔以車流量等級,城市的區域功能信息,基于圖與超圖理論對問題進行建模,將遙測設備的布點選址問題轉化為最小橫貫問題,最終采用貪婪算法求解出布設尾氣遙測設備的路段集合;基于特定車輛路線的布點模塊,使用一種基于圖論與布爾代數的機動車尾氣遙測設備布點方法來實現,針對城市公交系統尾氣的普查進行尾氣遙測設備選址布點,首先基于超圖理論,將公交車運行路線轉化為公交路線超圖,然后用布爾代數的相關原理,確定尾氣遙測設備在城市路網中的布設位置;上述基于道路相似性的布點模塊、基于路網拓撲結構的布點模塊與基于特定車輛路線的布點模塊可單獨使用,也可組合使用,選擇標準取決于輸入信息的多少以及決策者對布設于城市路網的尾氣遙測設備的功能需求;在尾氣檢測信息、道路車流量信息、天氣信息和道路相關信息都可獲得的情況下采用基于道路相似性的布點模塊;在輸入信息只包含交通路網的拓撲結構和一些容易獲得的交通信息,包括路段所屬區域功能、交通流量的等級及是否建有天橋時,采用基于路網拓撲結構的布點模塊;需要對公交車這一種類的機動車進行重點監控時采用基于特定車輛路線的布點模塊。所述基于路網拓撲結構的布點模塊中,一種基于道路相似性的機動車尾氣遙測設備布點方法,包括以下步驟:步驟一:采集所需樣本數據并對樣本數據進行預處理,所述所需樣本數據是指用尾氣遙測設備獲得目標路網中每條路段一段時間內的尾氣檢測信息、道路車流量信息、天氣信息和道路相關信息;數據預處理包括數據清洗、數據規約和數據變換三個方面;步驟二:采用層次聚類的方法對步驟一中經過數據預處理處理后的樣本數據進行聚類分析;采用歐幾里德距離作為聚類距離的度量,首先將每個樣本都歸為一類,計算每兩個類之間的相似度,也就是樣本與樣本兩兩之間距離進行度量;然后把其中相似程度最高也就是距離最小的樣本聚成一類,循環重復相似性度量并進行最近類的合并,每次減少一類,最后直到所有的樣本被聚到一類中去,得到聚類結果;步驟三:根據步驟二中的聚類結果,繪制聚類譜系圖,將每一步聚類的結果直觀的顯示在聚類譜系圖上;步驟四:對所考察的路段賦予權重,代表路段的重要程度以及優先考慮程度,將任意數目的尾氣遙測設備對應相應數目的聚類結果,在聚類譜系圖上找到包含類數目等于對應數目的聚類結果,選取每個類中權重最大的路段布設尾氣遙測設備,最終得到將任意數目的尾氣遙測設備進行布點的方案。所述一種基于道路相似性的機動車尾氣遙測設備布點方法中,所述步驟一具體實現如下:(1)聚類前的樣本數據采集,將目標路網中的每條路段作為一個樣本,獲得每個樣本路段一段時間內的尾氣檢測信息、道路車流量信息、天氣信息和道路相關信息;其中:尾氣檢測信息,包括的數據項有:檢測設備編號,檢測時間,檢測的車牌號碼,車速,車輛加速度,車輛長度,CO2、CO、HC、NO濃度,煙度值,抓拍照片;道路車流量信息,包括的數據項有:道路名稱,時間,小型客車、中型客車不同類型車輛的車流量;天氣信息,包括的數據項有:時間,城市,天氣狀況,溫度,濕度,風速,PM2.5,PM10,AQI;道路相關信息,包括的數據項有:地理位置id,所在省份,所在城市,所在街道,連接方式,路旁植被面積,建筑物平均高度;(2)樣本數據預處理部分包括數據清洗、數據規約和數據變換三個方面;數據清洗,就是通過對數據的分析,找出缺失值、偏離過大的個別極端值進行丟棄處理;數據規約,刪除與所考慮問題不相關、弱相關或冗余的屬性,合并相同屬性,同時不斷的對相關屬性的選擇進行修改,以達到所要求的聚類效果;數據變換,將數據規約后的數據進行標準化處理,轉化為便于處理的適當格式,以適應聚類分析的需要。所述一種基于道路相似性的機動車尾氣遙測設備布點方法中,所述步驟二中,采用層次聚類的方法對步驟一中處理得到的樣本數據進行聚類分析具體包括以下步驟:(1)將步驟一中處理得到樣本中的每一個樣本都歸為一類,計算每兩個類之間的相似度,即對樣本與樣本兩兩之間的距離進行度量;度量樣本之間的相似性采用歐幾里德距離作為聚類距離的度量,歐幾里得距離如下:其中,d(i,j)表示歐幾里得距離,i和j為第i個樣本和第j個樣本的樣本標號,分別代表第i條路段和第j條路段,M4表示選取的相關屬性個數,相關屬性包括屬性合并后的污染物總濃度、煙度值、屬性合并后的總車流量、連接方式、路旁植被面積、建筑物平均高度,x表示相關屬性經過標準化后的數值,xi1表示第i個樣本的第1個屬性,xi2表示第i個樣本的第2個屬性,表示第i個樣本的第M4個屬性,xj1表示第j個樣本的第1個屬性,xj2表示第j個樣本的第2個屬性,表示第j個樣本的第M4個屬性;(2)把步驟(1)中相似程度最高也就是距離最小的兩個樣本聚成一類,假設為樣本N5和樣本M6,將樣本N5,M6合并為一新類,記為Cla1={N5,M6},新產生的類Cla1的相關屬性用路段N5,M6對應屬性的均值表示,即新類的屬性表示為其中,N5和M6為第N5個樣本和第M6個樣本的樣本標號,M4表示選取的相關屬性個數,x表示相關屬性經過標準化后的數值,表示第N5個樣本的第1個屬性,表示第N5個樣本的第M4個屬性,表示第M6個樣本的第1個屬性,表示第M6個樣本的第M4個屬性;(3)新類和其他類一起得到一個N4-1容量的樣本,計算樣本中所有樣本點每兩個之間的相似度,即兩兩之間的距離進行度量;將其中使得距離最小的兩個樣本聚成一類,記為Cla2,新產生的類Cla2的相關屬性用類中包含的兩個樣本的對應屬性的均值表示;(4)類似地,重復進行相似性度量和最近類的合并,每次減少一類,依次得到新類最后類的個數減少為1,所有的樣本被聚到一類中去,得到聚類結果。所述一種基于道路相似性的機動車尾氣遙測設備布點方法中,所述步驟三中,根據聚類過程繪制聚類譜系圖,橫坐標為1處代表第一次聚類的結果,橫坐標為2處代表第二次聚類的結果,依次類推,將每一步聚類的結果直觀的顯示在聚類譜系圖上,聚類譜系圖充分展示了聚類的每一步過程,讓從可視化的層面了解到每一步哪些路段被聚為一類,每一步聚類結束后不同類的數目和這些類中分別包含哪些路段。所述一種基于道路相似性的機動車尾氣遙測設備布點方法中,所述步驟四中,對所考察的路段賦予權重,權重綜合考慮該路段的設備布設成本、設備布設難易程度要素后確定,權重越大代表路段的重要程度越大以及優先考慮程度越高;假設需要將數目為M5的尾氣遙測設備進行,從聚類譜系圖找到對應類數目為M5的聚類結果,即第N4-M5次聚類后的結果,選取這M5個類中每個類的權重最大的路段布設尾氣遙測設備,最終得到對任意數目的尾氣遙測設備進行布點的方案。所述基于路網拓撲結構的布點模塊中,一種基于圖論的機動車尾氣遙測設備布點方法,包括以下步驟:步驟一:將城市交通路網依據拓撲結構和交通流方向抽象成一個有向圖,將交通路網信息抽象成一個數據矩陣,采用深度優先搜索算法找到所述有向圖中的所有有向回路;步驟二:將所有路段作為有向回路超圖的頂點,所有有向回路作為有向回路超圖的超邊,建立城市路網的有向回路超圖,簡化該有向回路超圖,得到簡單有向回路超圖,建立簡單有向回路超圖中頂點的加權度模型,尋找加權度模型中加權度最大的頂點,采用貪婪算法求出簡單有向回路超圖的最小橫貫,即為機動車尾氣遙感監測設備的布點路段;所述加權度是指融合了交通路網信息的簡單有向回路超圖的頂點的度,所述簡單有向回路超圖的最小橫貫是指能夠覆蓋簡單有向回路超圖所有邊的最小頂點集合。所述一種基于圖論的機動車尾氣遙測設備布點方法中,所述步驟一中,將交通路網信息抽象成一個數據矩陣,如下:其中,表示交通路網的所有路段,M7為路網中路段總數;表示路段的信息,包括路段所屬區域功能,交通流量的等級,是否建有天橋;N7為布點方法中所利用的路段信息種類;Rij,i=1,2,…,M7,j=1,2,…,N7表示將路段信息數字化后的具體數值。所述一種基于圖論的機動車尾氣遙測設備布點方法中,所述步驟一中,采用深度優先搜索算法找到所述有向圖中的所有有向回路的過程如下:(1)首先將城市交通路網依據拓撲結構和交通流方向抽象成一個有向圖,然后將有向圖轉換為線圖;(2)從步驟(1)中的線圖的一個初始頂點出發,沿著線圖的有向弧和不同的頂點尋找有向路徑,直到不存在有向弧到達下一個頂點,判斷是否存在有向弧回到初始頂點,若存在,表明檢測到一個圈;(3)退回步驟(2)中有向路徑的上一個頂點,沿著其他有向弧繼續拓展有向路徑,直到不存在有向弧到達下一個頂點,判斷是否存在有向弧回到初始頂點,若存在,表明檢測到一個圈;(4)重復步驟(3),直到退回初始頂點;(5)依次以其他頂點為初始頂點,重復步驟(2)(3)(4),線圖的所有圈即為原有向圖的所有有向回路。所述一種基于圖論的機動車尾氣遙測設備布點方法中,所述步驟二具體實現如下:(1)將所有路段作為有向回路超圖的頂點,所有有向回路作為有向回路超圖的邊,建立城市路網的有向回路超圖模型;(2)依次比較(1)中建立的有向回路超圖的兩條邊,判斷是否存在包含關系,若存在,則在有向回路超圖中刪去較長的那條邊,并且對刪除邊后的有向回路超圖重復此步驟,直到刪除邊后的有向回路超圖的任意兩條邊都不存在包含關系,即得到簡單有向回路超圖;(3)在步驟(2)得到的簡單有向回路超圖中建立頂點的加權度模型,尋找加權度模型中加權度最大的頂點,采用貪婪算法求出簡單有向回路超圖的最小橫貫。貪婪算法的求解過程如下:在簡單有向回路超圖中,刪除加權度模型中加權度最大的頂點及包含該頂點的所有邊,并且對刪除頂點和邊后的簡單有向回路超圖重復此步驟,直到簡單有向回路超圖為空,則刪除的頂點集合為簡單向回路超圖的最小橫貫,即機動車尾氣遙感監測設備的布點路段。所述一種基于圖論的機動車尾氣遙測設備布點方法中,所述步驟二中,簡單有向回路超圖中頂點的加權度模型的數學表達如下:其中,D*(i)表示簡單有向回路超圖頂點i的加權度,Rij為交通路網數據矩陣模型中的元素,i=1,2,…,M7,j=1,2,…,N7;rj為路段信息,r1表示路段所屬的區域功能,如果路段位于污染區域,則r1=0,否則r1=1,rjmax表示rj的最大值,watr,j表示各個路段信息的權值,滿足deg(i)表示簡單有向回路超圖中頂點i的度,degmax表示簡單有向回路超圖中所有頂點的度的最大值。所述基于特定車輛路線的布點模塊中,一種基于圖論與布爾代數的機動車尾氣遙測設備布點方法,包括以下步驟:步驟一:將公交車行駛路線抽象為公交路線超圖;步驟二:應用布爾代數相關理論求解公交路線超圖的所有極小橫貫集;步驟三:求解公交路線超圖的最小橫貫集,所述最小橫貫集是指所有極小橫貫集中基數最小的一個極小橫貫集,在本發明中最小橫貫集指最小監測路段集合,即需要布設尾氣遙測設備的路段的集合。所述一種基于圖論與布爾代數的機動車尾氣遙測設備布點方法中,所述步驟一具體實現如下:(1)以城市實際的交通道路網絡為基礎,將公交車行駛路線中經過的各路段抽象為超圖頂點,得到頂點集;(2)將公交車行駛線路抽象為超邊,超邊是頂點集的子集;(3)所有超邊的集合即為超圖,超圖由公交車行駛路線所得,稱之為公交路線超圖。所述一種基于圖論與布爾代數的機動車尾氣遙測設備布點方法中,所述步驟二具體實現如下:(1)對公交路線超圖中每個頂點設布爾變量χi,χi表示路段i是否布設尾氣遙測設備,若χi=1則表示此路段需要布設遙測設備;(2)公交路線超圖中每條邊按其所含頂點進行布爾加法,得到各條邊的布爾析取式,即:ψj表示第j條公交運行路線中包含的路段;(3)將所有邊的布爾析取式進行布爾乘法,得到公交路線超圖的布爾合取式,即:表示整個公交路線網中所有線路所含路段的全體,Nhy為公交路線超圖中超標數目;(4)對所得的合取式用布爾運算規律整理化簡,得到最簡的析取式,即:其中每個子式λt對應的頂點集是公交路線超圖的一個極小橫貫集,所有的λt構成公交路線超圖的所有極小橫貫集的集合表示與公交車每條運行路線都相交的路段全體。所述一種基于圖論與布爾代數的機動車尾氣遙測設備布點方法中,步驟三具體實現如下:(1)求各個極小橫貫集的基數,即所含頂點的個數;(2)確定基數最小的極小橫貫集,該極小橫貫集即為最小橫貫集,最小橫貫集中頂點所對應的路段即為需要布設尾氣遙測設備的路段,這些路段構成的集合為最小監測路段集合。所述數據處理層包括道邊空氣污染物濃度估計模塊、道邊空氣污染物濃度預報模塊、城市全局大氣環境預測模塊、機動車尾氣排放因子估計模塊與機動車尾氣排放特征分析模塊;道邊空氣污染物濃度估計模塊,使用一種基于重構深度學習的道邊空氣污染物濃度預測方法來實現,根據道邊空氣污染物的時空分布特點,基于重構深度學習方法對深度重構Elman模型進行訓練,當訓練完成后,輸入實時的路網信息、氣象信息和交通信息,即可獲得實時的道邊空氣污染物濃度估計值;道邊空氣污染物濃度預報模塊,使用一種基于LSTM-RNN模型的空氣污染物濃度預報方法來實現,根據歷史空氣污染物濃度數據,提出基于LSTM-RNN模型的預報方法,模型訓練完成后,該模型可預報當前或未來某一時刻的空氣污染物濃度;城市全局大氣環境預測模塊,使用一種基于CFD及多數據源的城市實時全局環境估計方法來實現,結合城市環境監測站點歷史數據、全球中尺度氣象預測結果、國家氣象數據、城市重點污染源數據、城市地理三維模型及機動車尾氣遙測設備的實時監測數據,利用流體力學CFD作為計算引擎,根據氣象信息自適應切換環境質量模式,采用多尺度網格離散化城市模型并引入多組分污染模型,實現城市全局大氣環境的實時預測;機動車尾氣排放因子估計模塊,使用一種基于MLP神經網絡的機動車尾氣排放因子估計方法來實現,利用機動車尾氣遙測設備采集的實際道路上的機動車尾氣排放數據以及其他相關數據建立機動車尾氣CO、HC及NO的排放因子數據庫,并據此建立針對于CO、HC和NO的MLP神經網絡模型,實現機動車尾氣排放因子的實時在線估計;機動車尾氣排放特征分析模塊,使用一種基于聚類分析的車輛尾氣排放特征分析處理方法來實現,采用灰色關聯分析方法從車輛類型、行駛工況、燃料類型、車輛使用年限、風速、氣溫中找出影響尾氣排放的主要影響因素,作為車輛尾氣排放特征分析的核心維度特征參數,利用基于密度的聚類算法對機動車進行尾氣排放貢獻程度的分類;上述五個模塊分別實現不同的數據分析功能,選擇不同的模塊即可實現不同的功能;可以單獨使用,也可以兩個或兩個以上組合作用;在需要獲得實時的道邊空氣污染物濃度估計值時,采用道邊空氣污染物濃度估計模塊;在根據歷史空氣污染物濃度數據預報當前或未來某一時刻的空氣污染物濃度時,采用道邊空氣污染物濃度預報模塊;在需要城市全局大氣環境的實時預測時,采用城市全局大氣環境預測模塊;在需要進行機動車尾氣排放因子的實時在線估計時,采用機動車尾氣排放因子估計模塊;在分析影響尾氣排放的主要影響因素,或對機動車進行尾氣排放貢獻程度的分類時采用機動車尾氣排放特征分析模塊。所述數據處理層中,所述道邊空氣污染物濃度估計模塊中,一種基于重構深度學習的道邊空氣污染物濃度實時預測方法包含以下步驟:步驟1:基于重構深度學習方法,根據道邊空氣污染物的時空分布特點,形成道路空氣污染物濃度數據集,構建深度重構Elman模型;所述道邊空氣污染物包括一氧化碳CO、二氧化碳CO2、氮氧化物NOx;所述深度重構Elman模型包括:主網絡和次網絡;主網絡具有前饋連接和反饋連接結構,含有局部記憶能力,主網絡依次由輸入層、承接層、中間層和輸出層構成;次網絡用于主網絡初始化,次網絡含有一個可視層和一個隱含層;步驟2:根據限制玻耳茲曼機的特征,從道邊空氣污染物濃度數據集中隨機選取部分數據,完成深度重構Elman模型的初始化;步驟3:采用梯度下降算法,對深度重構Elman模型進行訓練,得到能夠對道邊空氣污染物濃度進行實時預測的深度重構Elman模型,以實時的路網信息、氣象信息、交通信息因素作為Elman模型的輸入,Elman模型輸出為對應的實時道邊空氣污染物濃度;所述路網信息包括路段車道數、道路綠化程度、道路建筑物高度、建筑物與道邊距離;所述氣象信息包括溫度、濕度、天氣、風速和風向;所述交通信息車種比例、車流量、通過時間、停止時間和擁塞時間。所述一種基于重構深度學習的道邊空氣污染物濃度實時預測方法中,所述步驟2實現如下:(1)對道路空氣污染物濃度數據集中的數據進行歸一化處理,并將數據集按照60%、20%、20%的比例劃分為訓練集、驗證集、測試集;(2)對限制玻爾茲曼機設置重構誤差閾值,利用訓練集中的輸入數據對限制玻爾茲曼機進行訓練,其中可視層單元個數為14,隱含層單元個數為37,關于狀態的損失函數Jres(xpol,hpol,θ)為:其中,xpol,i為影響道邊空氣污染物濃度的因素之一,hpol,j為xpol,i的另一種表達,θrac={ωrac,i,j,αrac,i,βrac,j},αrac,i、βrac,j分別為可視單元和隱含單元的偏差向量,ωrac,i,j是權重矩陣,N9、L9分別為可視單元和隱含單元的數量;限制玻爾茲曼機參數的梯度求解方法如下:其中,prob(xpol,θ)是可視單元的概率,prob(hrac,j=1|xpol,θ)是隱含單元的條件概分布;(3)初始化Elman模型,其中用限制玻爾茲曼機中訓練好的矩陣ωrac初始化輸入層權重中間層權重和承接層權重用零矩陣初始化。所述一種基于重構深度學習的道邊空氣污染物濃度實時預測方法中,所述步驟3實現如下:(1)根據深度重構Elman模型的非線性狀態空間表達式計算第m次迭代輸出的道邊空氣污染物濃度yrac(m);(2)根據梯度下降算法計算道邊空氣污染物濃度損失函數Jrac,若污染物濃度損失函數的值小于初始化中設置的誤差閾值或者迭代次數值m大于等于初始化中設置的最大迭代次數,則訓練結束,進入步驟(5),否則進去步驟(3);(3)根據梯度下降算法計算道邊空氣污染物濃度損失函數關于深度重構Elman模型的權重參數的偏導數,計算方法如下:其中,Jrac(m)是道邊空氣污染物濃度損失函數,n表示輸入層的第n個單元,j表示輸出層的第j個單元,l表示中間層的第l個單元,表示隱含層的第個單元,m是迭代次數,是求偏導符號,是道邊空氣污染物濃度損失函數關于的偏導數,η1、η2、η3分別是的學習率,分別是深度重構Elman模型的中間層到輸出層權重參數、輸入層到中間層權重參數、承接層到中間層權重參數;(4)然后根據權重參數的偏導數對權重參數進行更新,更新規則如下:更新完畢后,返回步驟(1);(5)訓練結束,模型的權重參數確定,所得模型即為能夠對道邊空氣污染物濃度進行實時預測的深度重構Elman模型,將實時的路網信息、氣象信息、交通信息因素輸入到模型中,通過模型即可輸出預測的實時道邊空氣污染物濃度結果。所述數據處理層的道邊空氣污染物濃度預報模塊中,一種基于LSTM-RNN模型的空氣污染物濃度預報方法包含以下步驟:步驟一,首先收集目標城市較長時間內的空氣污染物濃度數據,作為歷史數據,并存入數據庫;步驟二,然后通過對收集到的歷史數據進行預處理,構造待訓練的LSTM-RNN(LongShort-TermMemory,長短時記憶)模型的訓練樣本數據、驗證樣本數據和測試樣本數據;步驟三,通過訓練樣本數據得到預先訓練的LSTM-RNN模型,然后通過構造的驗證樣本數據和測試樣本數據微調訓練得到的LSTM-RNN模型參數,通過進一步修正LSTM-RNN模型參數,提高LSTM-RNN模型精度,將該修正后的LSTM-RNN模型作為空氣污染物濃度預報模型;步驟四,將預處理后的目標城市較長時間內的空氣污染物濃度數據作為LSTM-RNN模型的輸入數據,通過LSTM-RNN模型對輸入數據進行學習,最終LSTM-RNN模型輸出得到當前或未來某一時刻的空氣污染物濃度預報的結果。所述一種基于LSTM-RNN模型的空氣污染物濃度預報方法中,所述步驟一中,收集目標城市較長時間內,即一年的空氣污染物濃度數據,選取與空氣污染物濃度有關的數據進行匯總,對于其中部分缺失的數據,采用平均值法填補缺失數據,并存入數據庫。所述一種基于LSTM-RNN模型的空氣污染物濃度預報方法中,所述步驟一中的平均值法為:采用缺失數據前N10個與后N10個數據取平均值的方法,N10表示前后取數的個數,取值為20-30個。所述一種基于LSTM-RNN模型的空氣污染物濃度預報方法中,所述步驟二中,構造待訓練的LSTM-RNN模型的訓練樣本數據:從數據庫中讀出目標城市的污染數據,進行歸一化處理,構成LSTM-RNN模型的輸入特征向量,并按照75%、15%、10%的比例劃分為訓練樣本數據、驗證樣本數據和測試樣本數據。所述一種基于LSTM-RNN模型的空氣污染物濃度預報方法中,步驟二中所述歸一化處理方法為min-max歸一化方法,對收集到的目標城市較長時間內的空氣污染物濃度數據做歸一化處理,使其值在0到1之間。所述一種基于LSTM-RNN模型的空氣污染物濃度預報方法中,所述步驟三中,LSTM-RNN模型采用具有1個輸入層、5個隱藏層,輸出層,使用identity函數來執行回歸。所述一種基于LSTM-RNN模型的空氣污染物濃度預報方法中,所述步驟三中的5個隱藏層采用LSTM(長短時記憶)單元,該單元具有三個門:輸入門表示是否允許采集的新的污染物濃度數據信息加入到當前隱藏層節點中,如果為1即門開,則允許輸入,如果為0,即門關,則不允許,這樣就可以摒棄掉一些沒用的輸入信息;遺忘門表示是否保留當前隱藏層節點存儲的歷史污染物濃度數據,如果為1即門開,則保留,如果為0,即門關,則清空當前節點所存儲的歷史污染物濃度數據;輸出門表示是否將當前節點輸出值輸出給下一層,即下一個隱藏層或者輸出層,如果為1,即門開,則當前節點的輸出值將作用于下一層,如果為0,即門關,則當前節點輸出值不輸出。所述一種基于LSTM-RNN模型的空氣污染物濃度預報方法中,所述隱藏層的LSTM單元具體公式表示如下:Hair,t=ottanh(ct)其中sig為邏輯sigmoid函數,xair表示LSTM-RNN模型的輸入特征向量,Φ、o、c、Hair分別表示輸入門(inputgate)、遺忘門(forgetgate)、輸出門(outputgate)、單元激活向量(cellactivationvectors),隱藏層,分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與輸入門之間的權重矩陣,Ωair,c,Φ分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與遺忘門之間的權重矩陣,Ωair,c,o分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與輸出門之間的權重矩陣,分別為LSTM-RNN模型的輸入特征向量、隱藏層單元與單元激活向量之間的權重矩陣,所述權重矩陣均為對角陣;βair,Φ、βair,o、βair,c分別為LSTM-RNN模型輸入門、遺忘門、輸出門、單元激活向量的偏差值,t作為下標時表示時刻,tanh為激活函數。所述數據處理層的城市全局大氣環境預測模塊中,一種基于CFD及多數據源的城市實時全局環境估計方法包含以下步驟:步驟一,提取城市三維模型數據,使用模型片段數簡化方法進行所述三維模型融合,并將地理信息映射到所述三維模型,生成具有地理信息的簡化城市三維模型;步驟二,選定城市的待求解區域,在待求解區域中,對第一步所得簡化城市三維模型進行六面體網格劃分,融入城市重點污染源GIS信息及城市主要街道GIS信息,然后使用多尺度網格劃分方法對重點污染源區域、主要街道進行細網格劃分,生成多尺度網格化城市三維模型;步驟三,使用Realizablek-ε湍流模型封閉城市大氣流場方程,加入太陽輻射方程,得到城市大氣流場控制方程;步驟四,將城市重點污染源的排放數據、機動車尾氣排放的實時數據通過匹配地理位置坐標點方法,映射到第二步所得城市三維模型重點污染源位置及主要街道位置所在處,生成城市重點污染源排放時空分布Q1j(ξ1,ξ2,ξ3,t),其中ξ1,ξ2,ξ3為坐標變量,t為時間變量;及主要街道尾氣污染物源濃度分布Q2j(ξ1,ξ2,t),融合城市環境監測站點污染物濃度數據,采用雙線性插值生成全局污染物濃度初步估計分布Yenv,j,使用污染物輸送方程綜合上述所述三種數據源,即Q1j(ξ1,ξ2,ξ3,t)、Q2j(ξ1,ξ2,t)和Yenv,j,得到實時污染物輸送模型;步驟五,將多數據源全國尺度風場、污染物分布數據及ECMWF氣象數據,作為城市模型求解區域時變邊界參數,利用大氣邊界層理論得到入流面、出流面、上邊界及下墊面邊界條件;步驟六,利用計算流體力學CFD求解器在第二步所得城市三維網格模型上對第三步所得流場控制方程及第四步污染物輸送模型離散化,按第五步的時變邊界條件,進行城市全局流場求解,得到無氣象因素實時環境質量分布;步驟七,結合城市氣象數據,針對不同降水氣象,包括降雪和降雨,對第六步CFD湍流模型計算所得無氣象因素實時環境質量分布的計算結果進行對應沉降作用處理,得到城市實時全局環境質量分布;步驟八,在第七步得到當前時刻城市實時全局環境質量分布當前時刻環境質量分布計算結果基礎上,載入下一時刻氣象數據,重點污染源排放數據,機動車尾氣排放數據,進行實時循環計算,生成城市實時全局環境質量分布動態估計。所述一種基于CFD及多數據源的城市實時全局環境估計方法中,所述步驟一中,提取城市三維模型數據,使用模型片段數簡化方法進行所述三維模型融合,并將地理信息映射到所述三維模型,生成具有地理信息的簡化城市三維模型的方法為:(1)使用3Dripper分析谷歌地球運行時DirectX數據流,導出帶有地理信息的三維城市建筑模型;(2)使用STL模型簡化技術合并步驟(1)所得三維城市建筑模型三角面,得到簡化城市建筑模型;(3)匹配步驟(2)所得三維城市建筑模型與地理信息特征點,將地理信息映射到三維城市建筑模型,生成具有地理信息的簡化城市三維模型。所述一種基于CFD及多數據源的城市實時全局環境估計方法中,所述步驟三中,使用Realizablek-ε湍流模型封閉城市大氣流場方程,Do模型描述太陽輻射,得到城市大氣流場控制方程的方法為:(1)采用Realizablek-ε湍流模型,即RKE模型對穩態不可壓縮連續性方程進行封閉,設定Realizablek-ε湍流模型參數:方程常數L11,湍動能及耗散率的湍流普朗特數σk,σε,得到湍流控制方程;(2)使用氣象數據中太陽輻照強度數值,確定當前入射輻射強度代入輻射傳熱方程,計算輻射對流場及溫度影響,聯合步驟(1)中湍流控制方程得到城市大氣流場控制方程組。所述一種基于CFD及多數據源的城市實時全局環境估計方法中,所述步驟四中,使用污染物輸送方程綜合三種數據源,得到污染物輸送模型的步驟為:(1)利用環保部及省市環保廳提供的國控重點企業監測公開信息中各企業排放數據,將重點污染源模型化為點源分布,指定污染源坐標,源強可定義污染源在模型中的位置及排放量,得到重點企業污染源的時空分布模式Q1j(ξ1,ξ2,ξ3,t),其中:i為污染來源種類,此處記企業污染源為i=1,j為污染物種類,Qj(ξ1,ξ2,ξ3,t)為某種污染物的源項;(2)根據配套開發的機動車尾氣檢測系統所得污染物數據,使用線性插值公式對介于監測點1,2之間的尾氣濃度進行插值,估計街道峽谷內尾氣成分濃度值,式中Q2j,1為相鄰兩個機動車尾氣檢測點所得污染物濃度數據,為插值點,監測點1,監測點2地理坐標值;將街道污染物濃度匹配城市模型對應街道,得到污染物濃度地圖,建立城市路道污染源濃度時空分布估計值,并視為線源,Q2j(ξ1,ξ2,t),并將其代入污染物輸送方程;(3)將城市以環境監測點為節點進行區域劃分,并利用環境監測點提供環境數據以監測點為頂點,對內部區域污染物濃度值進行雙線性插值,生成覆蓋城市的污染物濃度預估值Yenv,j,以其作為輸送過程初始場,及計算過程校正場;(4)針對主要污染物,包括PM2.5,氮氧化物,硫化物分別建立不同的組分輸送方程,具體某種組分Yj的輸送微分方程為:式中:ρ為流體密度,Yj為組分j的質量分數,Uj,i為組分j擴散速度在i方向的分量,Qj為組分源強,visj為組分擴散系數項,不同組分擴散系數不同,將步驟(1)所得重點企業污染源項Q1j(ξ1,ξ2,ξ3,t)、步驟(2)所得城市路道污染源項Q2j(ξ1,ξ2,t)、步驟(3)所得城市污染物濃度預估值Yenv,j代入上述組分輸送微分方程,通過計算實時生成污染物輸送模型。所述一種基于CFD及多數據源的城市實時全局環境估計方法中,所述步驟五中,將數據源全國尺度風場、污染物分布數據,及ECMWF氣象數據,作為城市模型求解區域時變邊界參數,利用大氣邊界層理論得到入流面、出流面、上邊界及下墊面邊界條件的步驟為:根據大氣邊界層理論,將ECMWF數據中高度第一層的數據作為上界邊界條件;建筑物及地面設置為固壁邊界條件;流入面邊界條件:以指數分布描述入流面大氣邊界層內風速隨高度變化情況其中u0為峽谷上方平行街道方向風速,ξ3為離地高度,ξ3,0為街道峽谷高度,loss為邊界層內速度損失指數,以入口大氣邊界層高度作為基準高度,對應ECMWF風速數據作為基準高度風速;設置出流面相對壓力為零,通過上述設定,得到入流面、出流面、上邊界及下墊面邊界條件。所述一種基于CFD及多數據源的城市實時全局環境估計方法中,所述步驟七中,結合城市氣象數據,針對不同氣象模式,對基于CFD及多數據源的城市實時全局環境估計方法的步驟六的計算結果進行沉降作用處理,得到城市實時全局環境質量分布的步驟為:實時對基于CFD及多數據源的城市實時全局環境估計方法的步驟七所得無氣象因素實時環境質量分布計算結果結合國家氣象中心實時氣象數據,針對不同降水氣象,包括降雪、降雨,不同污染物組分對污染物組分分布施加沉降作用,得到沖洗后污染物濃度值:Yj=Y0,je-phi(Rf),其中:Y0,j為降水前污染物濃度值,為沖洗系數,為降水量Rf的函數,沖洗系數參數L12,L13為經驗系數,與降水類型及污染物類型相關,對污染物組分空間分布Yj隨時迭代更新,得到城市實時全局環境質量分布。所述數據處理層的機動車尾氣排放因子估計模塊中,一種基于MLP神經網絡的機動車尾氣排放因子估計方法包括以下步驟:步驟1:利用機動車尾氣遙感監測設備采集的實際道路上的機動車尾氣排放數據,即機動車行駛時排放的CO2、CO、HC及NO的體積濃度,以及其他相關數據,所述其他相關數據包括:機動車的車型、速度與加速度,以及當前溫度、濕度、壓強、風向與風速;步驟2:對步驟1中采集到的機動車的尾氣排放數據進行預處理,并建立機動車尾氣CO、HC及NO的排放因子數據庫;步驟3:基于步驟2所得到的機動車尾氣CO、HC及NO的排放因子數據庫,以及步驟1中采集到的其他相關數據分別建立針對于CO、HC和NO的MLP神經網絡模型,依據MLP神經網絡模型即實現機動車尾氣排放因子的實時在線估計。所述一種基于MLP神經網絡的機動車尾氣排放因子估計方法中,所述步驟2中,對機動車尾氣排放數據進行預處理的方法如下:根據機動車尾氣遙感監測設備采集到的機動車行駛時排放的CO2、CO、HC及NO的體積濃度數據計算機動車尾氣CO、HC及NO的排放因子,方法如下:其中,CO(gL-1)、HC(gL-1)和NO(gL-1)分別指機動車尾氣CO、HC及NO的排放因子,單位是gL-1;Rat為機動車尾氣遙感監測設備采集到的CO與CO2體積濃度的比值;Rat′為機動車尾氣遙感監測設備采集到的HC與CO2體積濃度的比值;Rat″為機動車尾氣遙感監測設備采集到的NO與CO2體積濃度的比值;Mfuel為機動車燃油的摩爾質量;Dfuel為機動車燃油的密度。所述一種基于MLP神經網絡的機動車尾氣排放因子估計方法中,所述步驟3中,建立針對于CO、HC和NO的MLP神經網絡模型的方法如下:在進行MLP神經網絡模型構造之前,所有數據,包括速度、加速度、溫度、濕度、壓強、風向與風速及CO、HC和NO的排放因子,都需進行min-max歸一化。在min-max歸一化之后,將所有數據先按照車型分為四個數據集,即分別針對于輕型汽油車、重型汽油車、輕型柴油車和重型柴油車的數據集;每個數據集分為訓練集、驗證集和測試集,其中驗證集用來在訓練過程中檢查MLP神經網絡的性能,當性能達到最大值或開始減小的時候訓練終止,測試集用來評估訓練出的MLP神經網絡的性能;訓練集、驗證集和測試集數據所占比例分別為50%、25%、25%.使用上述所得的訓練集中的數據來訓練MLP神經網絡,采用的MLP神經網絡模型的結構為:一個輸入層、一個隱藏層和一個輸出層的三層結構;MLP神經網絡模型的輸入為速度、加速度、溫度、濕度、壓強、風向與風速,輸出為CO、HC或NO的排放因子,輸入層神經元數目為7個,輸出層神經元數目為1個,隱藏層神經元數目采用試驗法決定。所述數據處理層中,所述機動車尾氣排放特征分析模塊中,一種基于聚類分析的車輛尾氣排放特征分析處理方法包括如下步驟:(1)抽取機動車尾氣遙測數據;(2)對抽取的機動車尾氣遙測數據進行預處理;(3)對步驟(2)中的預處理后的數據,采用灰色關聯分析方法從車輛類型、行駛工況、燃料類型、車輛使用年限、風速、氣溫等諸多因素找出影響尾氣排放的主要影響因素,作為車輛尾氣排放特征分析處理的核心維度特征參數,實現尾氣污染物排放影響因素關聯特征選擇,得到影響尾氣排放的主要影響因素特征屬性;(4)根據步驟(3)得到的影響尾氣排放的主要影響因素特征屬性,采用基于密度的聚類算法對檢測車輛尾氣排放特征數據進行分類得到分群類別,并計算每個排放分群組別的排放得分,然后根據排放得分對分群組別排序,構建車輛尾氣排放特征分析處理模型,根據車輛尾氣排放特征分析處理模型對車輛尾氣排放進行分析處理。所述一種基于聚類分析的車輛尾氣排放特征分析處理方法中,所述步驟(1)中,抽取機動車尾氣遙測數據的過程如下:(11)從車輛檢測數據庫中獲取尾氣檢測表和車輛基本信息表,包括的數據項有:檢測設備編號,檢測時間,檢測的車牌號碼,車速,車輛加速度,車輛長度,CO2、CO、HC、NO濃度,煙度值,風速,風向,氣溫,濕度,氣壓,動態/靜態測量,數據有效性,抓拍照片,燃料類型,車輛登記日期屬性;(12)從道路車流量信息數據庫,獲取的數據項有:道路名稱,時間,小轎車、出租車、公交車、大客車、中輕型卡車及重型卡車這些不同類型車輛的車流量;(13)從天氣信息數據庫,獲取的數據項有:時間,城市,天氣狀況,溫度,濕度,風速,PM2.5,PM10,AQI。所述一種基于聚類分析的車輛尾氣排放特征分析處理方法中,所述步驟(2)中,機動車尾氣遙測數據預處理如下:通過對尾氣遙測數據的分析,找出缺失值、偏離過大的個別極端值進行丟棄處理,從原始數據中的眾多屬性中刪除與遙測記錄不相關冗余屬性,對遙測數據中的車型數據、燃料類型、數據有效性的非數值型數據進行量化處理,再根據車輛登記日期以及車輛檢測時間,構造車輛使用年限分級數據。所述一種基于聚類分析的車輛尾氣排放特征分析處理方法中,所述步驟(4)中,尾氣污染物排放影響因素關聯特征選擇如下:采用灰色關聯分析方法從車輛類型、行駛工況、燃料類型、車輛使用年限、風速、氣溫等諸多因素找出影響尾氣排放的主要影響因素,作為車輛尾氣排放特征分析處理的核心維度特征參數。所述一種基于聚類分析的車輛尾氣排放特征分析處理方法中,所述步驟(4)中,構建車輛尾氣排放特征分析處理模型如下:對步驟(3)得到的特征屬性采用基于密度的聚類算法對檢測車輛尾氣排放特征數據進行分類得到分群類別,利用層次分析法得到每個特征屬性權重,按式i=1,…Ncluster求得第i組分群的排放得分scorei,計算每個排放分群組別的排放得分,然后根據排放得分對分群組別排序。所述基于密度的聚類算法的過程如下:(1)輸入聚類數Ncluster,屬性數據集Ncluster為屬性數據集大小,密度參數N21,倍率參數N22;(2)從屬性數據集S中計算所有對象距離數據表distTable={dist(si,sj)},i=1,2,…Ndata,j=1,2,…Ndata;t≠j;對距離數據表從小到大排序得到距離排序數組Array;(3)通過Array的percent范圍內出現最多的數據點標記,得到初始點init,Array(percent)記為序列中值最小的percent比例部分,按式:Array(percent)={distArray1,distArray1,…,distArrayroughNum}得到,每一個distArray對應兩個不同數據點,其中,roughNum=percent×Ndata×(Ndata-1)/2;(4)根據初始點init計算出當前簇的Eps和初始MinPts,得到當前簇的以init為圓心的初始簇點;(5)計算當前簇的每一個點的密度,若大于MinPts,則標記為簇心點,簇心點的Eps范圍內的點標記為當前簇類;(6)根據當前簇心點的平均MinPts,更新MinPts,重復步驟(5)直到當前簇點個數不再增加;(7)從屬性數據集S中去掉當前簇的點,當前簇類加1,重復(2)~(6)直到當前簇標為Ncluster+1;(8)給每一個未被標記的數據點標記為與其相近最近標記點的簇標,最終聚類出Ncluster個數據簇,從而得到分群類別。本發明與現有技術相比的優點:(1)以往的機動車尾氣檢測技術,如雙怠速法、簡易工況法、模擬工況法等,其本質上都是一種離線的、接觸式的檢測方法,需要在專門的監測站進行實驗,具有成本高、周期長等缺點,難以實現在線的實時監測。而遙感監測法可以快速篩選出高排放車輛、豁免清潔車輛,因其具有不干擾車輛行駛、快速、低成本檢測車輛尾氣排放的特點,同時可避免工作人員與尾氣的近距離接觸而帶來的危害,非常適用于對整體車輛尾氣排放狀況數據的監測。這種實際道路工況下的排放量數據較之實驗室臺架測試的數據更加接近真實的排放,更具有科學性及代表性,不僅能為環保部門建立相關執法體系提供可靠的技術保障,而且能夠為政府部門的相關決策給出科學有效的數值依據,從而有效的降低城市機動車尾氣排放污染,提高城市空氣質量,改善人民生活環境。(2)傳統的遙感監測法只能對其中極少部分車輛進行檢測,且各監測點分散,沒有實現網絡化、智能化、系統化與集成化,沒有充分利用各監測點數據的相互聯系,無法實現更高層面的監管,從而為有關部門提供決策依據或建議。城市機動車尾氣排放監控系統能克服上述缺點,真正發揮機動車尾氣遙測設備的優勢,實現城市管理的網絡化、智能化。(3)本發明提出的一種城市路網機動車尾氣排放遙感監控系統由遙測設備層、選址布點層與數據處理層構成,遙測設備層可獲取行駛中機動車尾氣排放的實時數據;選址布點層采用各種選址布點方法,針對不同目標對遙測設備層中機動車尾氣遙測設備在城市路網中的布設點位進行優化,可確保采集數據的完整性和多樣性,可更好地服務于數據處理層的數據處理方法;數據處理層使用遙測設備層采集的數據,同時結合車載診斷系統數據庫、便攜式排放測試系統數據庫、車檢所離線數據庫、交通信息數據庫與地理信息數據庫,實現多種功能的數據分析。(4)水平式尾氣遙測設備,要求滿足短時間內只有一輛車通過監測點的條件,也就是說,對于交通流較大的多車道其適用性較差。相比之下,垂直式尾氣遙測設備的各個車道的檢測相互獨立,適用于城區路網車流量較大的路段,可以在短期內積累大量數據。已有的垂直式尾氣遙測設備,增加了路面反射帶的固定垂直式尾氣遙測設備,反射帶的清潔度將直接影響設備的精度,所以由之而來的反射帶的清潔與保養工作會無形中增加設備成本與人工成本。本發明所涉及的一種基于路面反射的垂直式機動車尾氣遙測設備基于路面反射的垂直式機動車尾氣遙測設備不需要額外安裝路面反射帶,直接用路面反射的弱信號進行尾氣污染物成分與濃度的分析,具有更廣的適用性。(5)本發明涉及的一種基于深度殘差學習網絡的柴油車尾氣煙度檢測方法,比于普通的深度神經網絡,它更容易優化,并且隨著層數的增多,它的性能表現逐漸提升。相比較于發明專利《一種柴油車尾氣煙度圖像識別系統》(申請號:201210229911.2)中直接使用圖像處理對柴油機煙度進行測量的方法,使用的深度殘差學習網絡,不必對視頻圖像進行煙霧區域的分割和提取,能夠保證圖像的全局性,提高了檢測的準確率,同時具有更強的泛化能力。(6)本發明涉及的一種基于道路相似性的機動車尾氣遙測設備布點方法,將有限的資源集中到高價值的部分,實現了效益最大化的目標。將任意數目的尾氣遙測設備進行優化布設使得布點方案更加靈活,一方面,避免了設備的閑置與資金的浪費,能夠使每臺遙測設備物盡其用;另一方面,能夠最大限度的獲得盡可能多的尾氣信息并對全路網尾氣信息做出預測。(7)本發明涉及的一種基于圖論與布爾代數的機動車尾氣遙測設備布點方法,特別針對公交車設計尾氣遙測設備布點方法,基于圖論與布爾代數理論將尾氣遙測設備的布點問題轉化為公交路線超圖的最小橫貫求解問題,再運用布爾運算的方法求出最小橫貫即得到布點方案,且算法簡單,更易操作。現在暫時沒有以公交車為應用背景的布點方法的研究,故本發明填補了現有技術在該應用背景下的技術空白,具有很大的實踐意義。(8)本發明涉及的一種基于圖論的機動車尾氣遙測設備布點方法,需要的信息更少,只利用了交通路網的拓撲結構和一些容易獲得的交通信息,比如路段的車流量等級,城市的區域功能,路段是否建有天橋等,即可獲得機動車尾氣遙感監測設備的布點路段;通過建立交通路網數據矩陣,將交通數據等模擬信息轉化為數字信息,更便于分析、分類和處理。(9)本發明涉及的一種基于LSTM-RNN模型的空氣污染物濃度預報方法,采用一種基于模型的空氣污染物濃度預報方法。與傳統方法相比,使用深度學習的方法對空氣污染物濃度進行預報,不必實時采用人工方法測量,節約了人力物力資源,同時使用單元能夠加強后面的時間節點對前面的時間節點感知力,可以實現對測量數據的充分利用,極大的提高了預測效率和準確度,同時具有較高的泛化能力,具有極大的社會價值和現實意義。(10)本發明涉及的一種基于重構深度學習的道邊空氣污染物濃度實時預測方法,考慮到目前道邊空氣污染物濃度實時預測的重要性和方法的重大局限性,不同于以往的簡單預測方法,基于道邊空氣污染物濃度的誘發因素的多樣性、以及歷史數據相關性特征,基于重構深度學習的具有歷史記憶能力的深度重構Elman模型,由于該模型具有深層特征映射和局部記憶能力,能夠學習到道邊空氣污染物濃度與其受影響因素之間的本質特征映射,能夠學習到路網信息(路段車道數、道路綠化程度、道路建筑物高度、建筑物與道邊距離)、氣象信息(溫度、濕度、天氣、風速、風向)、交通信息(車種比例、車流量、通過時間、停止時間、擁塞時間)等因素與道邊空氣污染物濃度之間的本質特征映射,并且能夠通過該模型實現對一氧化碳、二氧化碳、氮氧化物的更高精度得實時預測,且具有很好的遷移性。(11)傳統車輛尾氣檢測根據相關標準的限定閾值將車輛分為超標和不超標,分類比較粗糙。本發明涉及的一種基于聚類分析的車輛尾氣排放特征分析處理方法充分利用尾氣遙測設備積累點海量數據,并考慮車輛基本屬性數據,對檢測車輛進一步精確分類,劃分出不同排放水平,對車輛尾氣排放的不同分級采取針對性整治措施,從而可以對機動車進行有針對性的監測和管理。(12)本發明所涉及的一種基于MLP神經網絡的機動車尾氣排放因子估計方法,采用的機動車尾氣排放數據是由機動車尾氣遙感監測設備采集的實際道路上的數據,一方面,可真實反映機動車在實際工況下的排放水平,另一方面,實際道路結構復雜,便可獲得范圍較大的速度、加速度數據,同時可獲得在各種溫度、濕度、壓強、風向與風速情況下的機動車排放數據。使用人工神經網絡來建立機動車行駛工況及氣象條件和機動車尾氣排放因子之間的關系,由于行駛工況及氣象條件對排放因子的影響較為復雜,而人工神經網絡即使對輸入輸出之間的復雜非線性關系知之甚少,也可以在訓練過程中不斷接收輸入輸出數據,通過調整神經元之間的連接權值從而建立輸入輸出之間的內在關系。所使用的MLP神經網絡包含一個隱藏層,這種結構非常簡單,而且一個包含有足夠多神經元的隱藏層能表示所有非線性關系。(13)本發明所涉及的一種基于CFD及多數據源的城市實時全局環境估計方法,優點如下所示。1)精細性:現有大氣環境模式如models3模式等只針對中尺度(3km)以上環境質量進行估計,而本發明通過對城市進行三維建模,采用CFD計算方法,可實現精細化環境質量估計,空間分辨率可達50-100m;2)實時性:現有環境質量報告系統受限于環境監測站點數據更新頻率,針對街道瞬態污染濃度變化不能給出快速報告。而本方法使用配套機動車尾氣檢測系統能實時更新街道污染物濃度情況,從而實現實時全局污染物濃度估計。3)發明專利《一種城市風環境數字地圖制作及顯示方法》(公開號:CN105513133A)提出一種城市風環境地圖制作方法,但該發明只針對風環境進行城市微尺度的模擬監測,而沒有提出一個針對空氣質量及各種污染物組分分布分析的統一框架模式,更沒有考慮氣象因素作用對城市空氣環境的影響。而本方法通過引入城市主要污染源數據及街道污染物濃度實時數據,建立統一多組分輸送過程,從而能得到不同污染物的全局分布;4)準確性:現有城市環境質量檢測模式如高斯煙羽模型,或者箱模型等對擴散環境,如地表下墊面、風場等作了極大簡化,只能給出粗略結果。本方法通過對城市建模,并考慮城市風環境湍流效應,使用具有明確物理意義的Realizable模型處理城市風環境;綜合城市重點污染源數據,街道實時尾氣數據等多元數據,得到城市全局實時環境質量估計模式,在估計準確度上有了很大提升。附圖說明圖1為本發明系統的組成框圖;圖2為垂直式尾氣遙測設備系統結構圖;圖3為垂直式尾氣遙測設備的車輛檢測單元原理圖;圖4為垂直式尾氣遙測設備的尾氣檢測單元;圖5為基于深度殘差學習網絡的柴油車尾氣煙度檢測方法流程圖;圖6為基于深度殘差學習網絡的柴油車尾氣煙度檢測方法的殘差學習單元;圖7為基于深度殘差學習網絡的柴油車尾氣煙度檢測方法的20層深度殘差學習網絡;圖8為基于深度殘差學習網絡的柴油車尾氣煙度檢測方法的深度殘差學習單元跨層連接沒有卷積操作圖;圖9為基于道路相似性的機動車尾氣遙測設備布點方法流程圖;圖10為基于道路相似性的機動車尾氣遙測設備布點方法的實施實例聚類譜系圖示意圖;圖11為基于圖論的機動車尾氣遙測設備布點方法流程圖;圖12為基于圖論的機動車尾氣遙測設備布點方法的交通路網有向圖;圖13為基于圖論的機動車尾氣遙測設備布點方法的交通路網有向回路超圖;圖14為基于圖論與布爾代數的機動車尾氣遙測設備布點方法流程圖;圖15為基于圖論與布爾代數的機動車尾氣遙測設備布點方法的公交路線超圖極小橫貫、最小橫貫求解流程圖;圖16為基于重構深度學習的道邊空氣污染物濃度實時預測方法流程圖;圖17為基于重構深度學習的道邊空氣污染物濃度實時預測方法的深度重構Elman模型的結構示意圖;圖18為基于LSTM-RNN模型的空氣污染物濃度預報方法流程圖;圖19為基于LSTM-RNN模型的空氣污染物濃度預報方法的LSTM單元示意圖;圖20為基于LSTM-RNN模型的空氣污染物濃度預報方法的單隱藏層LSTM-RNN模型結構示意圖;圖21為基于LSTM-RNN模型的空氣污染物濃度預報方法的sigmoid激活函數示意圖;圖22為基于LSTM-RNN模型的空氣污染物濃度預報方法的tanh激活函數示意圖;圖23為基于LSTM-RNN模型的空氣污染物濃度預報方法的全連接與dropout連接對比示意圖,其中左圖為全連接方式,右圖為dropout連接方式;圖24為基于CFD及多數據源的城市實時全局環境估計方法流程圖;圖25為基于CFD及多數據源的城市實時全局環境估計方法的城市3維模型圖;圖26為基于CFD及多數據源的城市實時全局環境估計方法的合肥市重點企業廢氣監測地理圖;圖27為基于CFD及多數據源的城市實時全局環境估計方法的城市街道污染物濃度數據圖;圖28為基于CFD及多數據源的城市實時全局環境估計方法的城市全局環境質量分布圖;圖29為基于MLP神經網絡的機動車尾氣排放因子估計方法的流程圖;圖30為基于聚類分析的車輛尾氣排放特征分析處理方法流程圖。具體實施方式如圖1所示,本發明一種城市路網機動車尾氣排放遙感監控系統,包括遙測設備層、選址布點層與數據處理層;1.遙測設備層,實現對機動車尾氣中CO、CO2、NOx、HC濃度、以及不透光煙度的檢測,同時記錄機動車的速度、加速度與機動車牌照號碼,最終得到每輛通過監測點機動車的尾氣遙測數據及機動車屬性、行駛工況、檢測時間、氣象條件數據,并將尾氣遙測數據及機動車屬性、行駛工況、檢測時間、氣象條件數據傳輸到數據處理層;遙測設備層包括移動式尾氣遙測設備、水平式尾氣遙測設備和垂直式尾氣遙測設備三種設備,其中,水平式尾氣遙測設備和垂直式尾氣遙測設備都固定安裝在道路上,水平式尾氣遙測設備用于單車道的道路以及車流量少的多車道道路,基于深度殘差學習網絡對柴油車尾氣煙度進行檢測;垂直式尾氣遙測設備用于車流量大的多車道道路,使用路面反射的弱信號進行尾氣污染物成分與濃度的分析;移動式尾氣遙測設備在城市路網上進行巡邏,服務于需要臨時進行機動車尾氣檢測的道路,能夠應對突發狀況對尾氣檢測的需求,并增加城市路網的監測密度;三種設備分別用于城市路網上的不同道路。2.選址布點層,解決遙測設備層中機動車尾氣遙測設備在城市路網中的選址布點問題,能夠將路網拓撲、道路信息、氣象信息、交通信息及布點區域已有檢測器數量的數據作為輸入,實現有效檢測車輛數最大、車輛檢測差別性最小及道路覆蓋率最大的目標,根據性能指標的不同,為相關部門提供多種選址布點方案。采用選址布點層的選址布點方法,對遙測設備層中機動車尾氣遙測設備在城市路網中的布設點位進行優化,可確保采集數據的完整性和多樣性,可更好地服務于數據處理層的數據處理方法;所述選址布點層包括基于道路相似性的布點模塊、基于路網拓撲結構的布點模塊與基于特定車輛路線的布點模塊;基于道路相似性的布點模塊,使用一種基于道路相似性的機動車尾氣遙測設備布點方法來實現,充分考慮了道路特性、道邊環境與氣象因素,提取出其中關鍵的屬性進行聚類,采用層次聚類的方法對城市路網的不同路段進行聚類,能夠將任意數目的尾氣遙測設備進行優化布點;基于路網拓撲結構的布點模塊,使用一種基于圖論的機動車尾氣遙感監測設備布點算法來實現,以城市路網拓撲結構為主,輔以車流量等級,城市的區域功能信息,基于圖與超圖理論對問題進行建模,將遙測設備的布點選址問題轉化為最小橫貫問題,最終采用貪婪算法求解出布設尾氣遙測設備的路段集合;基于特定車輛路線的布點模塊,使用一種基于圖論與布爾代數的機動車尾氣遙測設備布點方法來實現,針對城市公交系統尾氣的普查進行尾氣遙測設備選址布點,首先基于超圖理論,將公交車運行路線轉化為公交路線超圖,然后用布爾代數的相關原理,確定尾氣遙測設備在城市路網中的布設位置;基于道路相似性的布點模塊適用于尾氣檢測信息、道路車流量信息、天氣信息和道路相關信息都可獲得的情況下的選址布點方案設計,基于路網拓撲結構的布點模塊適用于輸入信息只包含交通路網的拓撲結構和一些容易獲得的交通信息,包括路段所屬區域功能、交通流量的等級及是否建有天橋,基于特定車輛路線的布點模塊適用于需要對公交車這一種類的機動車進行重點監控時的選址布點方案設計。3.數據處理層,實現對遙測設備層采集的機動車尾氣遙測數據及機動車屬性、行駛工況、檢測時間、氣象條件數據的存儲、分析與融合,結合車載診斷系統數據庫、便攜式排放測試系統數據庫、車檢所離線數據庫、交通信息數據庫與地理信息數據庫,對機動車尾氣遙測數據進行分析處理,實現機動車尾氣排放因子估計、機動車尾氣排放特征分析、道邊空氣污染物濃度估計、道邊空氣污染物濃度預測及城市全局環境預測,為環保部門的政策制定與執法提供科學依據。數據處理層包括道邊空氣污染物濃度估計模塊、道邊空氣污染物濃度預報模塊、城市全局大氣環境預測模塊、機動車尾氣排放特征分析模塊與機動車尾氣排放因子估計模塊;道邊空氣污染物濃度估計模塊,使用一種基于重構深度學習的道邊空氣污染物濃度預測方法來實現,根據道邊空氣污染物的時空分布特點,基于重構深度學習方法對深度重構Elman模型進行訓練,當訓練完成后,輸入實時的路網信息、氣象信息和交通信息,即可獲得實時的道邊空氣污染物濃度估計值;道邊空氣污染物濃度預報模塊,使用一種基于LSTM-RNN模型的空氣污染物濃度預報方法來實現,根據歷史空氣污染物濃度數據,提出基于LSTM-RNN模型的預報方法,模型訓練完成后,該模型可預報當前或未來某一時刻的空氣污染物濃度;城市全局大氣環境預測模塊,使用一種基于CFD及多數據源的城市實時全局環境估計方法來實現,結合城市環境監測站點歷史數據、全球中尺度氣象預測結果、國家氣象數據、城市重點污染源數據、城市地理三維模型及機動車尾氣遙測設備的實時監測數據,利用CFD作為計算引擎,根據氣象信息自適應切換環境質量模式,采用多尺度網格離散化城市模型并引入多組分污染模型,實現城市全局大氣環境的實時預測;機動車尾氣排放因子估計模塊,使用一種基于MLP神經網絡的機動車尾氣排放因子估計方法來實現,利用機動車尾氣遙測設備采集的實際道路上的機動車尾氣排放數據以及其他相關數據建立機動車尾氣CO、HC及NO的排放因子數據庫,并據此建立針對于CO、HC和NO的MLP神經網絡模型,實現機動車尾氣排放因子的實時在線估計;機動車尾氣排放特征分析模塊,使用一種基于聚類分析的車輛尾氣排放特征分析處理方法來實現,采用灰色關聯分析方法從車輛類型、行駛工況、燃料類型、車輛使用年限、風速、氣溫中找出影響尾氣排放的主要影響因素,作為車輛尾氣排放特征分析的核心維度特征參數,利用基于密度的聚類算法對機動車進行尾氣排放貢獻程度的分類;上述五個模塊分別實現不同的數據分析功能,選擇不同的模塊即可實現不同的功能,道邊空氣污染物濃度估計模塊可獲得實時的道邊空氣污染物濃度估計值,道邊空氣污染物濃度預報模塊根據歷史空氣污染物濃度數據預報當前或未來某一時刻的空氣污染物濃度,城市全局大氣環境預測模塊可實現城市全局大氣環境的實時預測,機動車尾氣排放特征分析模塊可分析影響尾氣排放的主要影響因素,并對機動車進行尾氣排放貢獻程度的分類,機動車尾氣排放因子估計模塊可實現機動車尾氣排放因子的實時在線估計。下面分別對本發明上述所涉及的重要技術進行詳細說明。一、本發明中的遙測設備層涉及的一種垂直式尾氣遙測設備,如圖2所示,其具體實現方式如下:垂直式尾氣遙測設備包括車輛檢測單元、尾氣檢測單元、弱信號處理單元和車牌識別單元四個部分;車輛檢測單元包括兩組激光發生器和接收器,兩組激光發生器以一定距離間隔安置于橫跨車道的龍門架上,發射激光垂直于車道,經路面反射后被龍門架上的激光接收器接收,當機動車行駛通過檢測區時,激光發射器發出的激光就會受到影響,使發射器-接收器之間的光路縮短,從而說明有機動車行駛進入檢測區,機動車在離開檢測區時會導致發射器-接收器之間的光路恢復到無車狀態,利用兩組激光器分別記錄的機動車進入、離開時刻差獲取機動車速度、加速度信息;同時輸出觸發信號觸發尾氣檢測單元對尾氣信息進行采集,觸發車牌識別單元對車牌信息進行采集;尾氣檢測單元,由多個安裝在橫跨車道的龍門架上垂直于路面的激光發射器構成,每個激光發射器以一定距離間隔安置,每個激光發射器均垂直向地面發射激光束,由于每個車道的激光接收器會受到不同車道激光的影響,他們接收到的是混疊信號,通過對激光接收器混疊信號的分析,得到尾氣污染物成分與濃度的混疊數據,每個接收器的數據會被發送到弱信號處理單元進行弱信號提取與分離。弱信號處理單元,包括弱信號提取模塊和弱信號分離模塊,弱信號提取模塊根據弱信號與噪聲信號在頻率分布、覆蓋范圍、統計特性方面的差異,識別和提取出尾氣檢測單元數據的相關弱信號數據;弱信號分離模塊對弱信號提取模塊中提取出的相關弱信號數據進行分離處理,選擇線性瞬時混合模型作為弱信號的模型,采用獨立分量分析的方法對不同源的相互混疊的弱信號進行分離,最終獲取通過監測點的機動車尾氣污染物成分與濃度;車牌識別單元包括一臺攝像機與圖像處理模塊,當車輛檢測單元檢測到有機動車進入檢測區時,輸出觸發信號,使攝像機對車頭進行多次拍照,由圖像處理模塊進行照片的篩選與車牌照號碼的識別,完成檢測結果與車牌號之間的關聯,從而最終實現基于路面反射的垂直式機動車尾氣遙測。如圖3所示,車輛檢測單元包括兩組激光發生器和接收器;兩組激光發生器以一定距離間隔安置于橫跨車道的龍門架上,發射激光垂直穿射車道,經路面反射后被安裝在龍門架上的激光接收器接收,當機動車行駛通過檢測區時,激光發射器發出的激光就會受到影響,使發射器-接收器之間的光路縮短,從而說明有機動車行駛進入檢測區,同時觸發尾氣檢測單元對機動車尾氣進行檢測。機動車在離開檢測區時會導致發射器-接收器之間的光路恢復到無車狀態。利用兩組激光器分別記錄的機動車進入、離開時刻差可以獲取機動車速度、加速度信息。同時觸發尾氣檢測單元對尾氣信息進行采集,觸發車牌識別單元對車牌信息進行采集。完成機動車速度和加速度的計算如下:機動車經過第一組激光發射裝置和第二組激光發射裝置的平均速度為vel1,vel2,其計算方法為速度加速度為其中,Ldis為兩組激光發射器間隔,記錄接收器1和接收器2下降沿出現的時刻為T1,T2,記錄接收器1和接收器2上升沿出現的時刻為T3,T4。如圖4所示,尾氣檢測單元,由多個安裝在橫跨車道的龍門架上垂直于路面的激光發射器構成,每個激光發射器以一定距離間隔安置,每個激光發射器均垂直向地面發射激光束,由于每個車道的激光接收器會受到不同車道激光的影響,他們接收到的是混疊信號,通過對激光接收器混疊信號的分析,得到尾氣污染物成分與濃度的混疊數據,每個接收器的數據會被發送到弱信號處理單元進行弱信號提取與分離。所述弱信號處理單元由弱信號提取模塊和弱信號分離模塊組成;弱信號提取模塊根據弱信號與噪聲信號在頻率分布、覆蓋范圍、統計特性方面的差異,識別和提取出尾氣檢測單元數據的相關弱信號數據;弱信號分離模塊,選擇線性瞬時混合模型作為弱信號的模型,假設N1個源信號s(t)被M1個檢測器接收后輸出混合信號x(t),線性瞬時混合模型可以表示為x(t)=Bs(t),其中是M1*1維觀測信號的向量,M1表示接收的檢測器的數目,是N1*1維相互獨立的源信號的向量,N1表示源信號的個數,B是一個M1*N1維的混合矩陣,其估計模型表示為y(t)=Wx(t),其中y(t)是對源信號s(t)的估計,W是一個M1*N1維的矩陣,稱之為分離矩陣。采用獨立分量分析的方法對不同源的相互混疊的弱信號進行分離,求解分離矩陣W,對源信號進行估計。采用獨立分量分析的方法進行弱信號分離的步驟如下:步驟一:對提取到的數據進行預處理,包括數據中心化和白化處理,數據中心化,使輸出混合信號x中心化,具體做法是用x減去其均值向量E(x),將x轉化為零均值向量。白化處理,對x進行線性變換,使得x的各分量方差都為1,白化的目的就是降低輸入的冗余性,使得x(t)的各個分量不相關聯,通過預處理,有效地降低了求解的復雜度,減小了工作量,記預處理后的數據為z(t);步驟二:隨機地選擇一個初始向量W(N2),N2=1;N2表示迭代的次數;步驟三:W(N2+1)=E{zg(WT(N2)z)}-E{g′(WT(N2)z)}W(N2),其中非線性函數g取g(x)=x3,E表示均值,z為預處理后的數據,W為分離矩陣;步驟四:作正交歸一化處理,W(N2+1)=W(N2+1)/‖W(N2+1)‖其中‖·‖表示矩陣范數;步驟五:判斷W(N2)是否收斂,收斂則停止迭代得到W(N2),否則返回步驟三繼續迭代。利用y(t)=Wx(t)可以得到對源信號s的估計,經過上面的弱信號分離,就可以得到分離后的各個源尾氣污染物成分與濃度數據。再利用車牌識別單元中的圖像處理模塊進行照片的篩選與車牌照號碼的識別,完成檢測結果與車牌號之間的關聯,從而最終實現基于路面反射的垂直式機動車尾氣遙測。二、發明遙測設備層涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法,其具體實現方式如下:如圖5所示:1.在道路的一邊架設CCD高速攝像機。1.1)CCD攝像機對柴油車尾氣視頻進行記錄。它將被攝物體反射光線傳播到鏡頭,再經鏡頭聚焦到CCD芯片上,CCD根據光的強弱積聚相應比例的電荷,各個像素積累的電荷在視頻時序的控制下點外移,經過濾波、放大處理后,形成視頻信號輸出。視頻信號連接到監視器的視頻輸入端便可以看到與原始圖像相同的視頻圖像。1.2)用圖像采集卡將圖像信息采集到電腦中。將CCD攝像機記錄的視頻圖像可以經過圖像采集卡傳輸到電腦上,將這些圖像按照75%、10%、15%的比例分成三個部分,作為深度學習的訓練集,驗證集和測試集。具體做法是將采集到的100萬張柴油車尾氣圖片分成了訓練集(750000張共20類)、驗證集和測試集(共150000張20類),每個類別放在一個單獨的文件夾里。并且將所有的圖像,都生成了txt列表清單(train.txt和test.txt)。為之后的網絡訓練做準備。1.3)對于深度殘差網絡的訓練一般都是在caffe下進行的,所以在訓練之前本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法做如下操作。1.3.1)圖片準備:將采集到的100萬張柴油車尾氣圖片分成了訓練集(750000張共20類)、驗證集(100000張)和測試集(共150000張20類),每個類別放在一個單獨的文件夾里。并且將所有的圖片,都生成了txt列表清單(train.txt和test.txt)。為之后的網絡訓練做準備。1.3.2)導入caffe庫,并設定文件路徑。需要在caffe設定根目錄、訓練圖片列表、測試圖片列表、訓練配置文件、測試配置文件和參數文件的路徑。其中訓練圖片列表和測試圖片列表(train.txt和test.txt)在上一步中已經準備好了,其它三個文件,需自己編寫。1.3.3)生成配置文件(配置文件中存放的就是network)。配置文件實際上就是一些txt文檔,只是后綴名是prototxt,可以直接到編輯器里編寫,也可以用代碼生成。本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法直接在編輯器里編寫。1.3.4)生成參數文件solver。這個文件的生成也是可以在編輯器里編寫,或者可以用代碼生成。本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法在編輯器中編寫。2.在道路的另一邊架設汽柴一體化機動車尾氣遙測裝置。汽柴一體化機動車尾氣遙測裝置是來對柴油車的尾氣煙度做直接的測量,并作為深度學習網絡的標簽,用于對圖像的訓練。這里主要是利用汽柴一體化機動車尾氣遙測裝置中的柴油車煙度檢測單元測量柴油車的煙度,其原理是煙度光源發出的檢測激光穿過道路上柴油機動車排放的尾氣照射到另一側的柴油煙度吸收檢測單元上,并由吸收檢測第單元將接收到的光線的亮度數據,發送至數據處理工控機。尾氣數據處理工控機根據光線的亮度衰減分析得到柴油尾氣的煙度。3.構建深度殘差學習網絡。3.1)本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中使用20層深度殘差網絡如圖7所示。圖7中image表示輸入的圖像,第一個方框內7*7conv表示卷積層的卷積核為7*7;64表示特征映射的大小;/2表示這層的步長為2。下面每個方框中的內容與第一個方框的內容類似,如果沒有/2表示這一層的步長為1。圖7中pool1表示最大池化層,AvgPool9表示平均池化層。Fc10則表示20維全連接層。實線的跨層連接表示輸入輸出大小相同,虛線的跨層連接表示輸入輸出大小不相同。總的來說,這20層深度殘差學習網絡依次為一層卷積層,一層池化層,8個跨度為2的殘差學習單元,一個全局平均池化層和一個20維全連接層。3.1.1)網絡的前兩層分別是卷積核為7*7、步長為2的卷積層和一個池化層。3.1.2)深度殘差學習單元的構建主要包括跨層連接。如圖6是殘差學習單元的構建模塊,其中xres和yres是層的輸入和輸出向量,weightlayer是具有權重的卷積層,identity表示身份映射,relu表示激活函數,表示權重。函數fres代表學習的殘差函數,圖6所示有兩個層,消除了簡化符號的偏差。fres+xres的操作是是由快捷連接和增加的元素智能進行的。本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中構建的深度殘差學習模塊定義為:從公式(1)中涉及的快捷連接看出,殘差單元沒有額外的參數和復雜的計算,這樣在實際工程中能夠降低硬件成本。殘差函數fres層數的設計是靈活的,在本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中,fres是兩層的殘差函數。一般的網絡有兩種殘差單元,一種是前向通道和跨層連接都有卷積層,另一種前向通道有卷積,但是跨層連接沒有卷積,是直接連過來的。本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中20層深度殘差網絡的殘差單元的跨層連接沒有卷積單元如圖8所示。圖8是圖6殘差學習單元的具體化,圖8中Res2a,Res2b分別表示殘差學習單元的輸入,輸出;Res2a_relu,Res2b_relu和Res2b_branch2a_relu表示激活函數,Res2b_branch2a和Res2b_branch2b表示卷積層,Bn2b_branch2a與Scale2b_branch2a這兩層表示BN層,Bn2b_branch2b與Scale2b_branch2b這兩層也表示BN層。將殘差學習單元的其中前向通道的卷積核設置為3*3,每層卷積層根據卷積核的大小進行補零,讓卷積之后的圖像大小保持不變,就保證輸入輸出的大小是一樣了。并且如圖8所示每一個深度殘差模塊的具體構建都是從上一層的relu函數開始與下一層的卷積層連接,然后通過BN層將層的計算結果重新規范化,然后再加以放縮以保持層學習到的特征性質。之后是池化過程,池化之后使用relu函數激活就可以連接下一層了,由于本發明中使用2層的跨度,要注意在搭建網絡時主路的第二層卷積模塊是沒有relu的,relu在與殘差部分融合之后。3.1.3)在深度殘差學習模塊之后接一個全局平均池化層和的20維全連接層。最后通過softmax層來最小化輸出和目標的損失函數來驅動學習。3.2)20層深度殘差網絡主要包括卷積層、池化層、全連接層和一些跨層連接組成。3.2.1)卷積層中主要是通過一組濾波器和非線性層變換,提取出圖像的局部特征。其中每個神經元都是與前一層的局部感受區相連,這樣既減少了連接的數目,又符合生物學理論。因為人腦的每一個神經元對外界的感受是局部的,而且圖像的空間聯系也是局部的,每個神經元感受不同的局部區域,最后在高層將這些局部信息綜合起來就得到全局的信息。卷積層的輸入要么來源于輸入層,要么來源于采樣層。卷積層的map個數是在網絡初始化指定的,本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中map為64,而卷積層的map的大小是由卷積核和上一層輸入map的大小決定的,假設上一層的map大小是N3*N3、卷積核的大小是M3*M3,那該層的map大小計算公式是:(N3-M3+1)*(N3-M3+1)。3.2.2)池化層主要是將卷積之后的特征圖進行匯聚統計,它也叫降采樣層。在圖像經過卷積層后特征向量的維數一般很大,容易造成計算過擬合,并且還存在許多冗余信息,這些問題可以通過池化層解決。池化操作也符合圖像的局部相關性原理,一個圖像區域有用的特征極有可能在另一個區域同樣適用。本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中區域大小為2*2小區域的均值。(注意,卷積的計算窗口是有重疊的,而采用的計算窗口沒有重疊,卷積核是2*2,每個元素都是1/4,所以需要去掉計算得到的卷積結果中有重疊的部分。)3.2.3)全連接層是在使用神經網絡的時候,最標準的形式,任何神經元和上一層的任何神經元之間都有關聯,然后矩陣運算也非常簡單和直接。本發明中在網絡的最后使用了一層20維的全連接層,去學習更多的信息。3.2.4)關于網絡的跨層連接,當輸入輸出大小相同的時候,使用實心線的捷徑,身份快捷鍵(公式(1))可以直接使用。當尺寸增加時使用虛線快捷鍵,在本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中快捷方式仍然執行身份映射,用額外的零條目填充以便增加尺寸。該選項不會引入額外的參數。快捷鍵以兩個大小在功能地圖上進行,兩個選項進行2跨度。3.3)下表是本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法中深度殘差學習網絡的架構:4.使用構建好的深度殘差學習網絡按照以下步驟進行訓練、驗證和測試。4.1)將采集到訓練集的尾氣圖像進行預處理:按其短邊作等比縮放后按照[256,480]區間的尺寸隨機采樣進行尺度增強。隨機的從圖像或其水平鏡像采樣大小為224*224的剪裁圖像,并將剪裁結果作減像素均值操作。然后進行標準色彩增強,并初始化網絡權重。在每一個卷積之后和激活之前,采用了BN層。當訓練深度殘差網絡時,使用的隨機梯度下降法(SGD),batch大小為128,Momentum設置為0.9。基礎學習率設置從0.0001開始,中間根據結果多次改變學習率進行優化,當訓練集的損失函數和驗證集的損失函數滿足要求時候停止訓練。4.2)訓練集的圖像作為訓練輸入,驗證集在訓練網絡的過程中每迭代1000次進行一次測試,比較驗證集的損失函數和訓練集的損失函數。當驗證集的損失函數不再下降時候,即可暫時停止訓練。將預處理后的測試集圖像作為訓練終止后的深度殘差學習網絡的輸入,將此時網絡的輸出與步驟2中的標簽值進行比較,若測試集精度超過99%,則訓練完成,否則,繼續訓練。5.對于沒有安裝汽柴一體化機動車尾氣遙測裝置的路段,在道邊布設CCD攝像機以獲取柴油車尾氣圖像,并輸入到訓練完成的深度殘差學習網絡中,從而實現對柴油車尾氣煙度的檢測。至此,深度殘差網絡的測試完成,本發明涉及的基于深度殘差學習網絡的柴油車尾氣煙度檢測方法的結果優于之前所用方法的準確率,即將深度殘差學習網絡用于柴油車煙度的測量是一個很有前景的方法。三、本發明選址布點層涉及的基于道路相似性的機動車尾氣遙測設備布點方法,其具體實現方式如下:實施實例選取合肥市某地區某路網一段時間內的具體檢測數據,該路網包含路段數目為N4=10,利用聚類分析得到能夠將任意數目為M5的尾氣遙測設備進行優化布設的方案,如圖9所示,具體實現過程如下所示。步驟一:聚類前采集所需樣本數據并對樣本數據進行預處理。將目標路網中的每條路段作為一個樣本,獲得每個樣本路段一段時間內的具體尾氣檢測信息,包括的數據項有:檢測設備編號,檢測時間,檢測的車牌號碼,車速,車輛加速度,車輛長度,CO2、CO、HC、NO濃度,煙度值,抓拍照片等。道路車流量信息,包括的數據項有:道路名稱,時間,小型客車、中型客車及其它不同類型車輛的車流量。天氣信息,包括的數據項有:時間,城市,天氣狀況,溫度,濕度,風速,PM2.5,PM10,AQI。道路相關信息,包括的數據項有:地理位置id,所在省份,所在城市,所在街道,連接方式,路旁植被面積,建筑物平均高度。首先進行數據清洗,通過對數據的分析,找出缺失值、偏離過大的個別極端值進行丟棄處理,這步需要花費較多的時間。然后進行數據規約,刪除與所考慮問題不相關、弱相關或冗余的屬性(如溫度,濕度,風速,檢測的車牌號碼,車速,車輛加速度),合并類似屬性(小型客車、中型客車及其它不同類型車輛的車流量合并為車流量,CO2、CO、HC、NO濃度合并為污染物濃度),最終選取了其中M4=8個相關屬性(相關屬性包括屬性合并后的污染物總濃度、煙度值、屬性合并后的總車流量、連接方式、路旁植被面積、建筑物平均高度)。最后進行數據變換,將不同單位、不同數量級的數據進行標準化處理。步驟二:采用層次聚類的方法對步驟一中處理得到的樣本數據進行層次聚類分析具體包括以下步驟:(1)將步驟一中處理得到樣本中的每一個樣本都歸為一類,共計10個類,計算每兩個類之間的相似度,也就是計算樣本點兩兩之間的歐幾里德距離,得到距離矩陣如下:其中d表示歐幾里得距離。(2)選取對角線以下下三角中最小的元素為d(3,6),將路段3和路段6合并為一新類,記為Cla1={3,6},利用路段3和路段6的相關屬性重新計算得到新類Cla1的屬性。(3)新類和其他類一起可得到一個N4-1=9容量的樣本,計算新樣本中所有樣本點兩兩之間的距離,其中使得距離最小的為d(4,10),將路段4和路段10聚成一類,記為Cla2={4,10},類的數目減少為9個。利用路段4和路段10的相關屬性重新計算得到新類Cla2的屬性。(4)類似地,重復進行相似性度量和距離最小類的合并,每次減少一類,可以依次得到新類Cla3,Cla4,…,Cla9,在第9步聚類時,類的個數減少為1,所有的樣本被聚為一類,得到聚類結果。聚類結果如下表所示:聚類步數聚類選擇聚類結果13,61,2,4,5,7,8,9,10,{3,6}24,101,2,5,7,8,9,{3,6},{4,10}38,91,2,5,7,{8,9},{3,6},{4,10}4Cla2,Cla31,2,5,7,{3,6},{4,8,9,10}55,Cla41,2,7,{3,6},{4,5,8,9,10}67,Cla51,2,{3,6},{4,5,7,8,9,10}71,2{1,2},{3,6},{4,5,7,8,9,10}8Cla1,Cla7{1,2,3,6},{4,5,7,8,9,10}9Cla6,Cla8{1,2,3,4,5,6,7,8,9,10}步驟三:根據步驟二中的聚類結果繪制聚類譜系圖,將每一步聚類的結果直觀的顯示在聚類譜系圖上如圖10所示。橫坐標為1處代表第一次聚類的結果,包含9個類{{1},{2},{4},{5},{7},{8},{9},{10},{3,6}}。橫坐標為2處代表第二次聚類的結果,包含8個類{{1},{2},{5},{7},{8},{9},{4,10},{3,6}},依次類推。步驟四:對所考察的路段賦予權重,代表路段的重要程度以及優先考慮程度,權重綜合考慮該路段的設備布設成本、設備布設難易程度等要素后確定。路段1權重為4,路段2,3,4權重為3,路段5,6權重為2,路段7,8,9,10權重為1。假設需要將數目為M5=3的尾氣遙測設備布設到該路網中,從聚類譜系圖找到對應類數目為3的聚類結果,即第7次聚類后的結果為{{1,2},{3,6},{4,5,7,8,9,10}},選取這3個類中每個類的權重最大的路段{1,3,4}布設尾氣遙測設備,最終得到對尾氣遙測設備進行布點的方案為在路段1,路段3,路段4上布點。四、本發明選址布點層涉及的基于圖論的機動車尾氣遙測設備布點方法,其具體實現方式如下:如圖11所示,本發明涉及的基于圖論的機動車尾氣遙測設備布點方法的具體實現如下:步驟一:將城市交通路網依據拓撲結構和交通流方向抽象成一個有向圖,其中有向圖的頂點表示路網的交叉路口,有向圖的有向弧表示路網的一條單方向路段,有向弧的方向由該路段的交通流方向決定。將交通路網信息抽象成一個M7×N7的數據矩陣,如下:其中,表示交通路網的所有路段,M7為路網中路段總數;表示路段的信息,如路段所屬區域功能,交通流量的等級,是否建有天橋等,N7為布點方法中所利用的路段信息種類;Rij(i=1,2,…,M7,j=1,2,…,N7)表示將路段信息數字化后的具體數值。數字化的方法如下:如果路段位于工廠等污染區域,則r1=0,否則r1=1;路段車流量等級可分為L7個等級,用1,2,…,L7表示車流量從低到高;路段是否建有天橋,用1表示有天橋,0表示無天橋等。然后采用深度優先搜索算法找到交通路網有向圖中的所有有向回路,由于有向回路的搜索算法較復雜,而有向圈的算法易于實現,因此將交通路網有向圖中有向回路的搜索轉換為其線圖中有向圈的搜索。線圖也是一個有向圖,其頂點表示原有向圖的弧,線圖中兩個頂點相鄰當且僅當原有向圖中對應的兩條弧相鄰。有向圖D的線圖用D*表示,設D的有向弧集合為D*的頂點集合則為其中vi=ai,i=1,2,…,M7。在D*中搜索有向圈的過程如下:1、以v1為初始頂點,沿著不同的頂點尋找有向路徑直到從頂點不存在有向弧到達下一個頂點。2、檢驗是否存在有向弧若存在,判斷路徑長度是否大于設定值L8。如是,表明檢測到一個有效圈記為P1。3、退回沿著其他有向弧繼續拓展有向路徑,直到不存在有向弧到達下一個頂點。判斷是否存在有向弧回到初始頂點,若存在,判斷路徑長度是否大于設定值L8。如是,表明檢測到一個有效圈記為P2。4、退回到重復步驟3直到退回到v1。5、依次以為初始頂點,重復步驟1,2,3,4。至此找到了D*中的所有長度大于設定值L8的有向圈其中M8為有向圈的總數,也是D中有向回路的總數。需要說明的是,為了避免重復,即含有q個頂點的某一有向圈被重復檢測到q次,以vi為初始頂點找圈時無需訪問頂點vj(j≤i)。步驟二:建立城市路網的有向回路超圖模型I=(χatr,F),其中χatr是超圖I的頂點集合,其中的每個元素代表一條路段,F是超圖I的超邊集合,每個超邊代表一個有向回路。超圖I=(χatr,F)是簡單超圖當且僅當若則i=j。由于由實際交通路網的有向回路建模而來的超圖可能不是簡單超圖,首先進行簡化有向回路超圖I=(χatr,F)的操作,過程如下:1、令i=1,F′=F。2、令j=i+1,判斷Fi是否含于Fj,如是,將F′-Fj附給F′;否則判斷Fj是否含于Fi,如是,將F′-Fi附給F′。3、j增加1,重復第二步直到j|F|。4、i增加1,重復第二步和第三步直到i=|F|-1。然后尋找簡化后的有向回路超圖中加權度最大的頂點,采用貪婪算法求出該簡單超圖的最小橫貫,即為機動車尾氣遙感監測設備的布點路段集合。其中,簡單有向回路超圖中頂點的加權度的數學表達如下:其中,D*(i)表示簡單有向回路超圖中頂點i的加權度,Rij(i=1,2,…,M1,j=1,2,…,N7)為交通路網數據矩陣模型中的元素,rj(j=1,2,3,…,N7)為路段信息,r1表示路段所屬的區域功能,如果路段位于工廠等污染區域,則r1=0,否則r1=1,rjmax表示rj(j=1,2,3,…,N7)的最大值,watr,j(j=1,2,…,N7)表示各個路段信息的權值,滿足deg(i)表示簡單有向回路超圖中頂點i的度,degmax表示簡單有向回路超圖中所有頂點的度的最大值。采用貪婪算法求解該簡單超圖的最小橫貫的具體步驟為:1、令i=1,Tr為空集。2、創建一個空的頂點ti,尋找中具有最大的加權度的頂點賦給ti。將ti添加到集合Tr中。3、i增加1,令圖為刪除了選定頂點及包含該頂點的所有邊的圖重復步驟2直到為空集時結束。則集合Tr即為有向回路超圖的最小橫貫,也就是機動車尾氣遙感監測設備的布點路段。為方便說明,這里選取一個簡單的例子介紹本發明涉及的基于圖論的機動車尾氣遙測設備布點方法的具體過程。圖12為某城市部分交通路網抽象而成的有向圖D=(V,A),交通路網建模成有向圖的方法為:將交通路網中的交叉路口用頂點表示,交通路網中的路段用有向弧表示,這里的路段指交通流方向單一的路段,一條雙向行駛的道路建模成兩個方向相反的有向弧。圖12所示的有向圖包含7個頂點,11條有向弧,設有向弧集合A={a1,a2,…,a11}。其中,7個頂點表示實際交通路網中的7個交叉路口,11條有向弧表示實際交通路網中的11條路段,這里弧a1,a2,a3,a8,a11表示5條單向行駛的路段,弧a4和a5,a6和a7以及a9和a10表示三條雙向行駛的道路,有向弧的指向表示車流方向。其中頂點3處存在轉向限制,即從a3轉向a6是不允許的。根據路段信息建立交通路網數據矩陣,如下:其中r1表示路段所屬的區域功能,如果路段位于工廠等污染區域,則r1=0,否則r1=1;r2表示路段車流量等級,分為5個等級,用1,2,…,5表示車流量從低到高;r3表示路段是否建有天橋,用1表示有天橋,0表示無天橋。然后采用深度優先搜索算法找到交通路網有向圖中的所有有向回路,由于有向回路的搜索算法較復雜,而有向圈的算法易于實現,因此將交通路網有向圖中有向回路的搜索轉換為其線圖中有向圈的搜索。線圖也是一個有向圖,其頂點表示原有向圖的弧,線圖中兩個頂點相鄰當且僅當原有向圖中對應的兩條弧相鄰。有向圖D的線圖用D*表示,則D*的頂點集合為{v1,v2,…,v11},其中vi=ai,i=1,2,…,11。在D*中搜索有向圈的過程如下:1、以v1為初始頂點,沿著不同的頂點尋找有向路徑直到從頂點不存在有向弧到達下一個頂點。2、檢驗是否存在有向弧若存在,判斷路徑長度是否大于設定值L8=2。如是,表明檢測到一個有效圈記為P1。3、退回沿著其他有向弧繼續拓展有向路徑,直到不存在有向弧到達下一個頂點。判斷是否存在有向弧回到初始頂點,若存在,判斷路徑長度是否大于設定值L2。如是,表明檢測到一個有效圈記為P2。4、退回到重復步驟3直到退回到v1。5、依次以為初始頂點,重復步驟1,2,3,4。至此找到了D*中的所有長度大于設定值L8=2的有向圈P1={a4,a10,a9,a5}P2={a4,a10,a7,a6,a9,a5}P3={a4,a10,a7,a2,a1}P4={a4,a10,a7,a6,a11,a8,a3,a2,a1}P5={a4,a10,a11,a8,a3,a2,a1}P6={a6,a9,a10,a7}需要說明的是,為了避免重復,即含有q個頂點的某一有向圈被重復檢測到q次,以vi為初始頂點找圈時無需訪問頂點vj(j≤i)。然后建立城市路網的有向回路超圖模型I=(χatr,F),其中χatr是超圖I的頂點集合,其中的每個元素代表一條路段,F是超圖I的超邊集合,每個超邊代表城市路網中的一個有向回路,即Fi=Pi,i=1,2,..,6,如圖13所示。簡化超圖I:1、令i=1,F′=F。2、令j=i+1,判斷Fi是否含于Fj,如是,將F′-Fj附給F′;否則判斷Fj是否含于Fi,如是,將F′-Fi附給F′。3、j增加1,重復第二步直到j=|F|。4、i增加1,重復第二步和第三步直到i=|F|-1。在本實施例中,簡化后的有向回路超圖I′=(χatr,F′·),其中F′=F-{F2,F4}。然后尋找簡化后的有向回路超圖中加權度最大的頂點,采用貪婪算法求出該簡單超圖的最小橫貫,即為機動車尾氣遙感監測設備的布點路段集合。在本發明例中,有向回路超圖的加權度的數學表達如下:其中,D*(i)表示頂點i的加權度,Rij(i=1,2,…,11,j=1,2,3)為交通路網數據矩陣中的元素,rjmax(j=1,2,3)表示rj(j=1,2,3)的最大值,λj(j=1,2,3)表示各道路信息的權值,權值依據各路段信息的參考價值和重要程度確定為λ1=0.4,λ2=0.4,λ3=0.2,滿足deg(i)表示頂點i的度,degmax表示所有頂點的度的最大值。采用貪婪算法求解I′的最小橫貫:1、令i=1,Tr為空集。2、創建一個空的頂點tr,i,尋找中具有最大的加權度的頂點賦給tr,i。將tr,i添加到集合Tr中。3、i增加1,令圖為刪除了選定頂點及包含該頂點的所有邊的圖重復步驟2直到為空集時結束。則集合Tr即為有向回路超圖的最小橫貫,也就是機動車尾氣遙感監測設備的布點路段。在本發明涉及的基于圖論的機動車尾氣遙測設備布點方法實施例中,最后求出的集合Tr={a4,a9},即為機動車尾氣遙感監測設備的布點路段集合。總之,本發明涉及的基于圖論的機動車尾氣遙測設備布點方法更具可行性,相比于已有的城市路網交通路網機動車尾氣遙感監測設備布點方法,本發明需要的信息更少,只利用了交通路網的拓撲結構和一些容易獲得的交通信息,比如路段的車流量等級,城市的區域功能,路段是否建有天橋等,并且將交通信息數字化,更便于分析、分類和處理,對城市機動車尾氣遙感監測設備布點問題的研究提供了新的思路和方法。五、本發明選址布點層涉及的基于圖論與布爾代數的機動車尾氣遙測設備布點方法,其具體實現方式如下:基于圖論與布爾代數的機動車尾氣遙測設備布點方法以實時高效監測公交車尾氣排放情況為目標,根據圖論與布爾代數相關理論,進行數學建模與求解,進而研究機動車尾氣遙測設備在城市交通路網中的布設問題。如圖14所示,基于圖論與布爾代數的機動車尾氣遙測設備布點方法的具體實施步驟如下:(1)將公交車行駛路線抽象為公交路線超圖。圖論中有如下超圖的定義:設是一個有限集,則上的一個超圖是指上的一個有限子集簇,使得(1)Frou,i≠φ(i=1,2,…,N)(2)其中為超圖的第i個頂點,共Mv個頂點,為頂點集合;Frou,i為超圖的第i個超邊,共Nhy個超邊,φ表示空集,為超邊集合,也就是超圖。結合城市交通路網,將公交車行駛線路中經過的各路段抽象為超圖頂點,將整條線路抽象為超邊,得到公交路線超圖。圖論中超圖橫貫的定義為:設是上的一個超圖,若頂點子集滿足Tr∩Frou,i≠φ(i=1,2,…,Nhy),即Tr與每條邊都相交,則稱Tr是超圖的一個橫貫(集)。如果一個橫貫的任何一個真子集都不是橫貫,則稱這個橫貫為極小橫貫集。所有極小橫貫集中基數最小的極小橫貫集是最小橫貫集。基于以上橫貫、極小橫貫、最小橫貫的定義,將公交線路抽象為超圖模型后,尾氣遙測設備的布點問題便轉化為求公交路線超圖的最小橫貫集問題。(2)求公交路線超圖的極小橫貫集。在前兩步的基礎上,用布爾代數相關理論求公交路線超圖的最小橫貫。首先介紹布爾代數相關理論。布爾變量的值只有0,1兩種情況,用“+”和“·”表示布爾代數中的“布爾加法(邏輯或)”與“布爾乘法(邏輯與)”,也稱為“析取”與“合取”,只含布爾加法的表達式稱為析取式,只含布爾乘法的表達式稱為合取式。下面介紹求公交路線超圖所有極小橫貫集的具體步驟:設是頂點集上的一個公交路線超圖,由公交車行駛路線抽象而得。超圖中頂點為超邊為Frou,j(j=1,2,…,Nhy)。本發明中用表示公交路線超圖,超圖的一個頂點表示公交車線路中經過的一個路段;超圖的一個超邊Frou,j表示一條公交車運行線路。①對每一個頂點設布爾變量χi與之對應,χi表示路段i是否布設尾氣遙感監測設備,若χi=1則表示此路段需要布設監測設備。②對公交路線超圖的每一條邊(j=1,2,…,Nhy)中的頂點進行布爾加法運算,得到每條邊Frou,j對應的布爾析取式ψj表示第j條公交運行路線中包含的路段;③對第②步得到的公交路線超圖中所有邊的布爾析取式ψj進行布爾乘法運算,得到整個公交路線超圖的布爾合取式:表示整個公交線路網中所有線路所含路段的全體;④對先使用布爾分配律展開,再用結合律、交換律、冪等律進行化簡,最終得到最簡的析取式:其中λt對應的頂點集是公交路線超圖的一個極小橫貫集,所有λt構成公交路線超圖的所有極小橫貫集,表示與公交車每條運行線路都相交的路段全體。(3)求公交路線超圖的最小橫貫集。比較橫貫超圖中所有極小橫貫集的基數,基數最小的極小橫貫集是最小橫貫集,即最小監測路段集合,為實際中需要布設機動車尾氣遙感監測設備的路段。圖15為公交路線超圖極小橫貫集、最小橫貫集求解的流程圖。首先,對公交路線超圖中各頂點設布爾變量,變量值取0或1,取1時表示該頂點代表的路段要布設尾氣檢測設備;然后,對公交路線超圖中每條邊,根據該邊所含的頂點進行布爾加法運算,得到對應于每條邊的布爾析取式;接著將所有超邊的布爾析取式進行布爾乘法運算,得到整個公交路線超圖的布爾合取式;之后用布爾運算的性質對所得的合取式整理化簡,得到最簡的析取式,其中每個子式代表超圖的一個極小橫貫集;最后比較各個極小橫貫集的基數,即所含元素的個數,取基數最小的極小橫貫集為最小橫貫集,最小橫貫集中的元素所對應的路段即為需要布設尾氣遙測設備的路段,進而得到了基于圖論與布爾代數的機動車尾氣遙測設備的布點方案。相比于已有的監測器布點方案,本發明涉及的基于圖論與布爾代數的機動車尾氣遙測設備布點方法專門針對城市公交系統,更具獨特性,且求解算法簡單易實現,操作性更強。六、本發明數據處理層涉及的基于重構深度學習的道邊空氣污染物濃度實時預測方法,其具體實施方式如下:如圖16所示,本發明涉及一種基于重構深度學習的道邊空氣污染物濃度實時預測方法具體實現如下:(一)基于道邊空氣污染物濃度的誘發因素的多樣性、以及歷史數據相關性特征,結合限制波爾茲曼機和Elman網絡的特點,構建具有前饋連接和反饋連接結構,含有局部記憶能力,主網絡由輸入層、承接層、中間層和輸出層構成,用于主網絡初始化的次網絡含有一個可視層和一個隱含層,輸入層、輸出層、可視層單元個數分別為14、3、14的深度重構Elman模型。如圖17所示,圖左邊為次網絡,圖右邊為主網絡,N9為次網絡可視層可視單元數量,主網絡輸入層的單元個數與次網絡可視單元數量相同,L9為次網絡隱含層隱含單元的數量、主網絡中間層和承接層單元個數與次網絡隱含層單元個數相同,M9為主網絡輸出單元個數,表示主網絡輸入層的輸入即路網信息、氣象信息、交通信息因素,z-1代表時延,m為迭代次數,yrac(m)為第m次迭代主網絡輸出層的輸出即道邊空氣污染物濃度,H(m)為主網絡中間層第m次迭代輸出,yc(m)為隱含層第m次迭代輸出,pur為激活函數purelin,ζ是承接層的自循環系數,分別為主網絡的中間層、輸入層、承接層第m次迭代的權重參數,ω為次網絡權重參數。(二)對建立的道路濃度數據集進行預處理1)對道路濃度數據集中的數據進行歸一化處理,以提高模型訓練速度和精度,針對數據集中數據的特點,采用min-max標準化方法;2)為提高模型的泛化能力,將道路濃度數據集按照60%、20%、20%的比例劃分為訓練集、驗證集、測試集。(三)對限制玻爾茲曼機訓練,完成輸入層權重的初始化1)對限制玻爾茲曼機設置學習率和合適的重構誤差閾值,學習速率在0.01-0.1之間取值,重構誤差閾值在0.001-0.00001之間取值,用零矩陣對限制玻爾茲曼機的參數矩陣進行初始化。2)利用訓練集中的輸入數據對限制玻爾茲曼機進行訓練,根據下式求解參數的梯度Δωrac,i,j、Δαrac,i、Δβrac,j。其中,prob(xpol,θ)是可視單元的概率,prob(hrac,j=1|xpol,θ)是隱含單元的條件概分布,logprob(xpol,θ)為prob(xpol,θ)的對數似然估計,log表示取對數操作,是求偏導符號,∑為求和符號,Δωrac,i,j、Δαrac,i、Δβrac,j分別是對數似然估計對權重參數、可視單元偏差、隱含單元偏差的偏導數,xpol為影響道邊空氣污染物濃度的因素之一,ωrac,i,j表示可視層的第i個單元與隱含層的第j個單元的連接權重,αrac,i表示可視層的第i個單元的偏差,βrac,j表示隱含層的第j個單元的偏差,θrac={ωrac,i,j,αrac,i,βrac,j}。3)利用下式對Δωrac,i,j、Δαrac,i、Δβrac,j行參數更新:其中,η4是限制玻爾茲曼機學習率,是限制玻爾茲曼機迭代次數,ωrac,i,j表示可視層的第i個單元與隱含層的第j個單元連接權重,αrac,i表示可視層的第i個單元的偏差,βrac,j表示隱含層的第j個單元的偏差。4)根據下式計算重構誤差:err=([xpol]d-[xpol]m)T([xpol]d-[xpol]m)其中,[xpol]d是利用道邊空氣污染物濃度數據集部分輸入初始化的值,[xpol]m是通過限制玻耳茲曼機重構的xpol,T是轉置。5)檢查重構誤差與設置的重構誤差閾值之間的大小,若重構誤差大于設置的閾值,則返回步驟2)繼續,若重構誤差小于設置的閾值,則限制玻耳茲曼機的訓練結束,用ωrac,i,j對Elman網絡輸入層權重進行初始化。(四)初始化Elman網絡1)設置合適的Elman網絡的誤差閾值、最大迭代次數、承接層自循環系數ζ和學習速率η1、η2、η3,誤差閾值在0.001-0.00001之間取值,最大迭代次數一般取1000,學習速率在0.01-0.1之間取值,自循環系數一般設置為0.001。2)用零矩陣初始化Elman網絡中間層權重和承接層權重設置用零向量初始化承接層。3)根據數據集的特點,將輸入層和輸出層單元個數分貝設置為14、3,中間層和承接成單元的個數是由實驗確定的,根據實驗誤差不斷調整中間層和承接層單元個數,找到性能最優的單元個數。(五)采用梯度下降法,結合數據集對Elman網絡進行訓練1)根據下式計算輸出y(p):yc(m)=ζH(m-1)其中,yrac(m)為第m次迭代輸出的道邊空氣污染物濃度,H(m)為中間層第m次迭代輸出,H(m-1)為中間層第m-1次迭代輸出,yc(m)為隱含層第m次迭代輸出,m為迭代次數,pur和sig分別為激活函數purelin和sigmoid,ζ是承接層的自循環系數,分別為深度重構Elman模型的中間層、輸入層、承接層第m次迭代的權重參數,xpol為輸入層輸入即影響道邊空氣污染物濃度的因素。2)根據下式計算目標損失函數:其中,Jrac(m)是道邊空氣污染物濃度損失函數,yd是道邊空氣污染物濃度期望輸出,m是迭代次數,yrac(m)是第m次迭代輸出的道邊空氣污染物濃度,T是轉置符號。若目標損失函數的值小于設置的誤差閾值或者m值大于等于設置的最大迭代次數,則跳過步驟3)直接到步驟4),若目標損失函數的值大于設置的誤差閾值,則進入步驟3)。3)根據下式計算權重的偏導數:其中,Jrac(m)是道邊空氣污染物濃度損失函數,n表示輸入層的第n個單元,l表示中間層的第l個單元,表示隱含層的第個單元,m是迭代次數,是求偏導符號,是道邊空氣污染物濃度損失函數關于的偏導數,η1、η2、η3分別是的學習率,分別是深度重構Elman模型的中間層到輸出層權重參數、輸入層到中間層權重參數、承接層到中間層權重參數。然后,根據權重的偏導數對權重系數進行更新:更新完畢后,返回步驟1)。4)訓練結束,模型的權重參數確定,此時的模型即為能夠對道邊空氣污染物濃度進行實時預測的深度重構Elman模型,將實時的路網信息、氣象信息、交通信息因素輸入到模型中,模型即可輸出預測的實時道邊空氣污染物濃度結果。(六)對訓練得到的深度重構Elman模型進行分析和對比經分析和對比,相比于其他已有的方法,用深度重構Elman模型可以更好地對道邊污染物濃度進行實時預測,且具有很好的遷移性。七、本發明的數據處理層涉及的基于LSTM-RNN模型的空氣污染物濃度預報方法,其具體實施方式如下:1、空氣污染物濃度數據采集:每5分鐘對目標區域的空氣污染物濃度進行一次實時監測記錄,共采集一年內的數據量,預計2×6×24×365=105124條數據記錄,對于其中部分缺失的數據,采用缺失數據前N10個與后N10個數據取平均值的方法進行填補,從而保證原始數據的完備性和充足性,保證預測結果的準確性和可信度,本發明涉及的基于LSTM-RNN模型的空氣污染物濃度預報方法實施例N10采用25個。2、數據預處理:在訓練神經網絡前,需要對采集到的空氣污染物濃度數據進行歸一化處理。所謂歸一化處理,就是將數據映射到[0,1]或[-1,1]區間或更小的區間,保證不同數據范圍的輸入數據發揮相同的作用。本發明涉及的基于LSTM-RNN模型的空氣污染物濃度預報方法中采用min-max歸一化處理方法。之后將歸一化處理后的空氣污染物濃度數據分為訓練、驗證和測試樣本數據,三部分數據所占比例依次為75%、15%、10%,用于之后的LSTM-RNN模型的訓練、驗證和測試。3、網絡模型結構:本發明涉及的基于LSTM-RNN模型的空氣污染物濃度預報方法采用具有一個輸入層、5個隱藏層的LSTM-RNN網絡模型,輸出層使用identity函數來執行回歸(如圖20給出了單隱藏層LSTM-RNN模型結構示意圖)。需要注意的是,與普通的RNN相比,LSTM-RNN模型的隱藏層單元均采用LSTM(長短時記憶)單元,該單元具有三個門:輸入門表示是否允許采集的新的污染物濃度數據信息加入到當前隱藏層節點中,如果為1(門開),則允許輸入,如果為0(門關),則不允許,這樣就可以摒棄掉一些沒用的輸入信息;遺忘門表示是否保留當前隱藏層節點存儲的歷史污染物濃度數據,如果為1(門開),則保留,如果為0(門關),則清空當前節點所存儲的歷史污染物濃度數據;輸出門表示是否將當前節點輸出值輸出給下一層(下一個隱藏層或者輸出層),如果為1(門開),則當前節點的輸出值將作用于下一層,如果為0(門關),則當前節點輸出值不輸出。LSTM單元結構彌補了傳統RNN結構上的不足,即后面的時間節點對前面的時間節點感知力下降。LSTM單元是一種稱作記憶細胞的特殊單元,類似于累加器和門控神經元:它在下一時間步長將擁有一個權值并連接到自身,拷貝自身狀態的真實值和累積的外部信號,但這種自聯接是由另一個單元學習并決定何時清除記憶內容的乘法門控制,具體內容如下:Hair,t=ottanh(ct)其中sig為邏輯sigmoid函數,xair表示LSTM-RNN模型的輸入特征向量,Φ、o、c、Hair分別表示輸入門(inputgate)、遺忘門(forgetgate)、輸出門(outputgate)、單元激活向量(cellactivationvectors),隱藏層,分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與輸入門之間的權重矩陣,Ωair,c,Φ分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與遺忘門之間的權重矩陣,Ωair,c,o分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與輸出門之間的權重矩陣,分別為LSTM-RNN模型的輸入特征向量、隱藏層單元與單元激活向量之間的權重矩陣,所述權重矩陣均為對角陣;βair,Φ、βair,o、βair,c分別為LSTM-RNN模型輸入門、遺忘門、輸出門、單元激活向量的偏差值,t作為下標時表示時刻,tanh為激活函數。Gate使用一個sigmoid激活函數(如圖21所示):其中,xair是LSTM-RNN模型輸入數據。如圖21所示,它能夠把輸入向量值“壓縮”到[0,1]范圍內,特別的,若輸入為非常大的負數時,輸出為0;若輸入為非常大的正數時,輸出為1。而input和cellstate通常會使用tanh激活函數(如圖22所示)來轉換:其中,xair是LSTM-RNN模型輸入數據。如圖22所示,它將一個實數輸入映射到[-1,1]范圍內。當輸入為0時,tanh函數輸出為0。4、網絡訓練:初始化隱藏狀態(hiddenstates)為0,將當前minibatch的最終隱藏狀態作為后續minibatch的初始隱藏狀態(連續的minibatch按順序遍歷整個訓練集),每個minibatch的尺寸均為20。本發明數據處理層涉及的基于LSTM-RNN模型的空氣污染物濃度預報方法中使用的LSTM-RNN模型共包含一個輸入層、五個隱藏層,輸出層使用identity函數來執行回歸,且每個隱藏層均具有650個單元,其參數在區間[-0.05,0.05]范圍內均勻初始化。另外,在非循環連接處應用50%的dropout,如圖23左圖所示為全連接形式,即在模型訓練時所有隱藏層節點均需工作;如圖23右圖所示為采用dropout的連接形式,即在模型訓練時隨即讓網絡某些隱含層節點的權重不工作,不工作的節點可暫時認為不是網絡結構的一部分,但其權重需保留下來(只是暫時不更新),以便下次樣本輸入時重新工作。dropout可以有效防止網絡訓練過程中出現過擬合現象。本發明數據處理層涉及的基于LSTM-RNN模型的空氣污染物濃度預報方法中使用的基于LSTM單元的RNN網絡結構訓練10000epochs,學習速率(learningrate)為1,訓練2500epochs后的每一個epoch開始以系數1.15降低學習速率。在訓練的每一步過程中,依據交叉熵(crossentropy)準則計算誤差向量,根據標準反向傳播算法更新權重:errair(t)=desired(t)-yair(t)其中desired(t)為預測輸出值,yair(t)為實際網絡輸出值,errair(t)為誤差值。訓練樣本數據中的空氣污染物濃度序列作為訓練輸入,驗證樣本數據在訓練網絡的過程中每迭代1000次進行一次測試,最終比較testloss和trainloss。當testloss不再降低時,終止網絡訓練,標志著用于空氣污染物濃度預報的包含LSTM單元的RNN網絡訓練完成。(1)前向傳播過程:輸入門匯集計算的值與經過激活函數計算的值為:遺忘門匯集計算的值與經過激活函數計算的值為:單元(cells)匯集計算的值與單元狀態值為:輸出門匯集計算的值與經過激活函數計算的值為:單元經過激活函數計算的值為:(2)誤差反向傳播更新與為:輸出門輸出值為:狀態(states)為:單元(cells)輸出值為:遺忘門輸出值為:輸入門輸出值為:其中Φ、o、c、Hair分別表示輸入門(inputgate)、遺忘門(forgetgate)、輸出門(outputgate)、單元激活向量(cellactivationvectors),隱藏層,分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與輸入門之間的權重矩陣,Ωair,c,Φ分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與遺忘門之間的權重矩陣,Ωair,c,o分別為LSTM-RNN模型的輸入特征向量、隱藏層單元、單元激活向量與輸出門之間的權重矩陣,分別為LSTM-RNN模型的輸入特征向量、隱藏層單元與單元激活向量之間的權重矩陣,所述權重矩陣均為對角陣。fair,1、fair,2、fair,3、fair,6、f′air,6、f′air,5、g′air,2、f′air,4、f′air,3、gair1,為函數。Jair為損失函數。5、網絡測試(調參和優化):將測試集中的空氣污染物濃度數據輸入到訓練好的LSTM-RNN模型結構中,查看依據歷史數據預測得到的未來某一時刻空氣污染物濃度數據與期望值的差距,從而對LSTM-RNN中的網絡參數進行調整,逐步提高預測精度。6、最終將該訓練、驗證、測試后的LSTM-RNN模型作為空氣污染物濃度預測模型。將預處理后的目標城市較長時間內的空氣污染物濃度數據作為LSTM-RNN模型的輸入數據,通過LSTM-RNN模型對輸入數據進行學習,最終輸出得到當前或未來某一時刻的空氣污染物濃度預報的結果。八、本發明的數據處理層涉及的基于CFD及多數據源的城市實時全局大氣環境估計方法,其具體實施方式如下:如圖24所示,本發明涉及的基于CFD及多數據源的城市實時全局大氣環境估計方法具體實施如下:第一步驟是對城市進行三維建模。本發明涉及的基于CFD及多數據源的城市實時全局大氣環境估計方法首先基于谷歌地球獲取城市三維模型。從谷歌地球中選取待求解城市區域,使用3Dripper分析谷歌地球運行時DirectX數據流,導出帶有地理信息的三維城市建筑模型,保存為*.3dr文件。將3dr文件導入3dMax進行貼圖設置,保存為.obj文件,然后使用DeepExploration生成sketchup模型文件,如圖25所示,該圖為結合了地理信息的城市三維模型。在進行城市尺度流場求解中,低矮建筑物、建筑材質、精細幾何構型等細節數據對城市上方空氣流通情況影響很小。故為減小計算量,對非街道區域低矮建筑物進行模型同化,同化為具有平均高度的單一模型。同時使用合并操作減少模型實體面數,將建筑物簡化為具有簡單幾何構型(長方體,正方體)的剛體,得到簡化城市建筑模型,進一步減小計算量。匹配簡化三維城市建筑模型與地理信息特征點,將地理信息映射到三維城市建筑模型,生成具有地理信息的簡化城市三維模型。將處理后的sketchup模型文件導入CFD計算軟件,本發明涉及的基于CFD及多數據源的城市實時全局大氣環境估計方法選擇fluent作為求解器軟件。第二步驟對模型區域進行網格劃分求解區域:在fluent中設置求解區域高度,根據大氣邊界層理論,在大氣邊界層內空氣流動受下墊面影響隨距離地面高度增加而呈指數衰減,超過該邊界層的大氣運動處于平穩狀態。該層一般厚度在1km之內,分為貼地層、近地層、Ekman層。人類活動,及空氣污染物也主要集中在該氣層。此處將大氣邊界層上界視為求解區域上界,從而求解區域選擇為一包括城市區域的框體。啟動GAMBIT網格劃分器,對待求解區域進行體網格劃分,選用六面體作為網格元素,并檢查網格劃分情況:計算流體力學模型通過將連續流體方程離散化,在空間網格上進行數值計算。可將模型劃分為六面體、四面體、金字塔形等網格單元。六面體單元允許比四面體單元更大的比率,且數值耗散現象較小。考慮到城市區域流動尺度大,模型具有較為簡單的幾何外形,故采用大比率六面體單元,使生成網格單元數量較少,減少計算代價。多尺度網格:使用加密網絡方法,結合環保部污染源監控中心提供的重點污染源自動監控基本信息中企業地理信息,將其映射到城市模型中。對重點污染源及路網周圍區域采用細網格進行網格劃分。第三步驟控制方程設置因大氣邊界層中空氣運動模式主要為湍流,故需要采用湍流模型來刻畫氣流運動過程。常見湍流模型有標準k-ε模型,RNGk-ε模型,Realizablek-ε模型,雷諾應力模型,大渦模擬模型.各種模型所考慮的物理機理逐步深入,但相應計算量也逐步上升.綜合考慮,本方法采用Realizablek-ε模型(RKE模型))對穩態不可壓縮連續性方程進行封閉。RKE模型湍流動能及其耗散率輸運方程為:上述方程中,ρ為流體密度,k為湍動能,ε為耗散率,μt為粘性系數,Θk表示由于平均速度梯度引起的湍流動能;L15是常數,σk,σε分別是湍動能及耗散率的湍流普朗特數,默認值為L15=1.9,σk=1.0,σε=1.2。粘性系數公式為其中Λμ通過如下公式計算得到:模型系數:L14為公式常量,Sij為流體旋量張量,γ為中間過程變量。流體連續性方程:式中Ui為i(i=ξ1,ξ2,ξ3)方向上流體流動速度.湍流動量輸運方程形式為:式中:ρ為流體密度,Ui為i方向流體速度分量,Ttem為流體溫度,Eflu為總能量,keff為有效導熱系數,(τij)eff為偏應力張量,pflu為平均壓力。在fluent湍流模型模型參數面板選擇RKE湍流模型,輸入上述參數L14,L15,Λμ,得到湍流控制方程。對于熱量輸送,通過環境監測點得到當前空氣溫度,太陽輻射數據,代入流動能量方程。RKE模型中能量方程本質就是雷諾動量輸送方程。針對太陽輻射傳熱,有如下方程:式中:為入射輻射強度,為輻射位置向量,為物體表面法向量,為輻射方向向量,κ為輻射表面吸收系數,nsun為輻射折射系數,σs為輻射表面折射系數,Ttem為當地溫度,Φsun為輻射相位函數,Ω′為輻射空間立體角,為輻射散射方向.從環境監測站點獲取當地入射輻射強度數據在fluent中選擇瞬態求解模式,設置輻射模型為太陽輻射模型。假設城市地表下墊面折射系數、反射系數、吸收系數為一恒定值,根據建筑熱工學建筑圍護結構外表面太陽輻射參數附表數值,可設下墊面為漫灰表面,吸收系數0.2,散射系數0。大氣折射率取為1,散射系數0。設定上述參數,聯合RKE湍流模型得到城市大氣流場控制方程組。在fluent中擴散過程用組分輸運過程刻畫,針對污染物組分輸送,本發明涉及的基于CFD及多數據源的城市實時全局大氣環境估計方法結合城市主要污染源數據,空氣質量檢測站點數據,及機動車尾氣檢測系統所得數據,天氣環境情況對污染物擴散過程進行方程建模。城市大氣污染物的主要來源有外界輸送、城市機動車尾氣排放、市內工廠污染源、生活排放。對工廠污染源建模,需要考慮污染源的地理分布、污染物種類數據,利用環保部及省市環保廳提供的國控重點企業監測公開信息中各企業排放數據,如圖26及下表是合肥市重點企業廢氣監測數據。將其模型化為點源分布。在fluent中,編寫UDF腳本,因城市模型具有相對三維,通過指定相應坐標,及源強可定義污染源在模型中的位置及排放量。得到重點企業污染源的時空分布模式Qij(ξ1,ξ2,ξ3,t),其中:i為污染來源種類,此處記企業污染源為i=1,j為污染物種類,Qij為某種污染物的源項。表1針對街道機動車尾氣污染源,本方法使用配套開發的機動車尾氣檢測系統所得污染物數據,使用線性插值公式對介于監測點1,2之間的尾氣濃度進行插值,估計街道峽谷內尾氣成分濃度值。式中Q2j,i為相鄰兩個機動車尾氣檢測點i=1,2所得污染物組分j濃度數據,為插值點,監測點1,監測點2地理坐標值;將街道污染物濃度匹配城市模型對應街道,得到污染物濃度地圖,如圖27,建立城市路道污染源濃度時空分布估計值,并視為線源,Q2j(ξ1,ξ2,t),并將其代入污染物輸送方程。將城市以環境監測點為節點進行區域劃分,并利用環境監測點提供環境數據以監測點為頂點,對內部區域污染物濃度值進行雙線性插值,生成覆蓋城市的污染物濃度預估值Yenv,j。以其作為輸送過程初始場,及計算過程校正場。針對主要污染物如pm2.5,氮氧化物,硫化物等分別建立不同的組分輸送方程。具體某種組分Yj的輸送微分方程為:式中:ρ為流體密度,Yj為組分j的質量分數,Uj,i為組分j擴散速度在i方向的分量,Qj為組分源強,visj為組分擴散系數項,不同組分擴散系數不同。將步驟3.3.1)所得重點企業污染源項Q1j(ξ1,ξ2,ξ3,t)、、步驟3.3.2)所得城市路道污染源項Q2j(ξ1,ξ2,t)、步驟3.3.3)所得城市污染物濃度預估值Yenv,j代入上述組分輸送微分方程,通過計算實時生成污染物輸送模型。第四步驟為設置求解器邊界條件時,本發明涉及的基于CFD及多數據源的城市實時全局大氣環境估計方法實施例采用歐洲中期天氣數值預報中心(ECMWF)提供的ERA-40再分析資料,該資料是利用四維同化方法(4Var)同化了地面觀測、高空觀測、衛星反演等資料而得到的全球天氣數據,時間分辨率為3h,空間分辨率0.25°×0.25°,高度分層60層,頂層高度為65km,每層大約1km。設置求解區域上界邊界條件,根據大氣邊界層理論,將ECMWF數據中高度第一層的溫度、氣壓、風速數據作為上界邊界條件。在fluent中選擇導入邊界數據,將上邊界數據導入求解器。建筑物及地面設置為固壁邊界條件(U1,U2,U3)=0。式中Ui,t=(1,2,3)為ξi(i=1,2,3)方向上流體流動速度.求解區域側界邊界條件,通過ECMWF數據確定求解區域風速流入面及出流面。綜合地面氣象站點溫度數據Tg,及ECMWF給出大氣邊界層氣溫數據Ttem,e,初步判斷大氣氣溫直減率大小Ttem,g-Ttem,e,及粗略風速大小.大氣邊界層內風速隨高度變化呈指數分布:其中u0為峽谷上方平行街道方向風速,ξ3為離地高度,ξ3,0為街道峽谷高度,以入口大氣邊界層高度作為基準高度,對應ECMWF風速數據作為基準高度風速。loss為邊界層內速度損失指數,也稱為穩定度參數,將大氣氣溫直減率分為不同等級,從而可得對應穩定度與loss值。我國國家標準GB50009-2012”建筑結構載荷規范”給出不同下墊面條件下loss值及大氣速度邊界層厚度的關系出流面邊界條件:假定出流面流動充分發展,可將其設置為相對壓力為零。其中U1,U2,U3分別為坐標ξ1,ξ2,ξ3方向上流體流動速度,k為湍動能,為耗散率,Sur為出流面。第五步驟:實時計算結果施加沉降作用。降水等過程對污染物具有清洗作用。清洗的強度與降水量及降水時長有關。如果遇到降水氣象則需要對污染物組分分布施加沉降作用,得到沖洗后污染物濃度值:Yj=Y0,je-phi(Rf)其中:Y0,j為降水前污染物濃度值,為沖洗系數,為降水量Rf的函數。沖洗系數參數L12,L13為經驗系數,與降水類型(如降雪、降雨)及污染物類型相關。編寫UDF腳本,實時對計算結果結合國家氣象中心實時氣象數據,針對不同降水氣象(如降雪、降雨),使用相應沉降模型,對污染物組分空間分布Yj隨時迭代更新,得到城市實時全局環境質量分布。第六步驟:實時更新計算結果。機動車尾氣檢測系統采集到實時街道污染物濃度數值,使用上文街道機動車尾氣污染源建模方法生成街道污染物線源釋放強度,采樣周期為實時。環保部及省市環保部門污染源排放數據,采樣周期24小時,使用第三步驟控制方程設置中工廠污染源建模方法,生成重點污染源排放模型。將ECMWF氣象預測數據(采樣周期為6小時)及國家氣象局氣象數據(采樣周期0.5小時)用作模型入口邊界條件數據,及區域校正場,對求解結果進行校正,同時更新邊界數據,進行下一輪計算。將上述數據代入求解器,使用Realizablek-ε模型得到城市實時全局環境質量分布動態估計。圖28為融合了街道尾氣污染物數據,重點污染源數據,瞬時風向為東北向時,城市地面上方25米處pm2.5濃度的瞬時分布計算結果。九、本發明數據處理層涉及的基于MLP神經網絡的機動車尾氣排放因子估計方法,如圖29所示,其具體實施方式如下:步驟1:利用機動車尾氣遙感監測設備采集的實際道路上的機動車尾氣排放數據,即機動車行駛時排放的CO2、CO、HC及NO的體積濃度,以及其他相關數據,包括:機動車的車型、速度與加速度,以及當前溫度、濕度、壓強、風向與風速;機動車尾氣遙感監測設備的尾氣探測器檢測機動車尾氣中污染物氣體的原理如下:位于道路一側的光源發出特定波長的紅外光和紫外光光束,道路另一側的紅外線和紫外光反光鏡又將其反射回設備的光源檢測器,當道路上有機動車通過時,機動車排放的尾氣會對紅外光和紫外光產生吸收,使得設備接收到的光強減弱,通過分析接收光光譜的變化情況便可計算出車輛行駛排放CO2、CO、HC及NO的體積濃度。同時,機動車尾氣遙感監測設備的速度加速度檢測器利用車輪通過兩條對射光路的時間間隔測量機動車的速度與加速度;機動車尾氣遙感監測設備的圖像采集設備可獲取機動車的車型,我們將機動車分為四類,即輕型汽油車、重型汽油車、輕型柴油車和重型柴油車;利用其他輔助設備可獲取當前時間、天氣、溫度、濕度、壓強、風向與風速。步驟2:對步驟1中采集到的機動車的尾氣排放數據進行預處理,并建立機動車尾氣CO、HC及NO的排放因子數據庫;根據機動車尾氣遙感監測設備采集到的機動車行駛時排放的CO2、CO、HC及NO的體積濃度數據計算機動車尾氣CO、HC及NO的排放因子,方法如下:其中,CO(gL-1)、HC(gL-1)和NO(gL-1)分別指機動車尾氣CO、HC及NO的排放因子,單位是gL-1;Rat為機動車尾氣遙感監測設備采集到的CO與CO2體積濃度的比值;Rat′為機動車尾氣遙感監測設備采集到的HC與CO2體積濃度的比值;Rat″為機動車尾氣遙感監測設備采集到的NO與CO2體積濃度的比值;Mfuel為機動車燃油的摩爾質量;Dfuel為機動車燃油的密度。在上式中帶入汽油的摩爾質量和密度的相應數據,得到下面的針對汽油車的排放因子計算公式:步驟3:基于步驟2所得到的機動車尾氣CO、HC及NO的排放因子數據庫,以及步驟1中采集到的其他相關數據分別建立針對于CO、HC和NO的MLP神經網絡模型,據此即可實現機動車尾氣排放因子的實時在線估計。CO、HC及NO的排放因子數據和速度、加速度、溫度、濕度、壓強、風向與風速數據,均通過下面的公式進行min-max歸一化。標準化之后,將所有數據先按照車型分為四個數據集,即分別針對于輕型汽油車、重型汽油車、輕型柴油車和重型柴油車的數據集。每個數據集分為訓練集、驗證集和測試集,其中驗證集用來在訓練過程中檢查MLP神經網絡的性能,當性能達到最大值或開始減小的時候訓練就可以終止,測試集可用來評估訓練出的MLP神經網絡的性能。訓練集、驗證集和測試集數據所占比例分別為50%、25%、25%。使用的MLP神經網絡模型的結構為:一個輸入層、一個隱藏層和一個輸出層的三層結構。MLP神經網絡模型的輸入為速度、加速度、溫度、濕度、壓強、風向與風速,輸出為CO、HC或NO的排放因子,因此輸入層神經元數目為7個,輸出層神經元數目為1個。隱藏層第i個神經元的輸出ymlp,i具有以下形式:其中,xmlp,j是輸入層第j個神經元的輸出;Nmlp為輸入層神經元數目;wmlp,ji是輸入層第j個神經元與隱藏層第i個神經元之間的連接權重,j=0,1,2,…Nmlp;bmlp,i為第i個偏離常數;f表示激活函數。將標準化的速度、加速度、溫度、濕度、壓強、風向和風速數據作為MLP神經網絡模型的輸入,CO、HC或NO的排放因子作為輸出。隱藏層神經元的個數可以由實驗確定;示例性的,隱藏層神經元個數分別取2~25,建立相應的MLP神經網絡模型,基于訓練集對模型進行訓練,基于驗證集和測試集分別對訓練所得一系列模型進行對比分析,使得模型性能最佳的隱藏層神經元數目即為最終確定的MLP神經網絡模型的隱藏層神經元數目。在本發明實施例中,經過性能比較和反復試驗,所建立的針對輕型汽油車排放的CO、HC和NO的排放因子的三個MLP神經網絡模型中隱藏層神經元數目分別為13、11和16個。根據本發明所建立的針對不同車型的CO、HC和NO排放因子的MLP神經網絡模型,對于無法實時監測尾氣排放狀況的機動車,也可根據其行駛工況和氣象條件實現尾氣排放因子的實時在線估計。十、本發明的數據處理層涉及的基于聚類分析的車輛尾氣排放特征分析處理方法,如圖30所示,其具體實施方式如下:(一)抽取機動車尾氣遙測數據從車輛檢測數據庫中獲取尾氣檢測表和車輛基本信息表,包括的數據項有:檢測設備編號,檢測時間,檢測的車牌號碼,車速,車輛加速度,車輛長度,CO2、CO、HC、NO濃度,煙度值,風速,風向,氣溫,濕度,氣壓,動態/靜態測量,數據有效性,抓拍照片等29個屬性。(二)機動車尾氣遙測數據預處理對尾氣遙測數據進行預處理,主要包括缺失值處理,數據構造。1.缺失值處理:如果缺失值的遙測記錄占總記錄數比例超過60%,則舍棄該類記錄;如果缺失值的遙測記錄所占總數比例不超過20%,而該屬性是非連續值特征屬性,那就把NaN作為一個新類別,加到類別特征中;若屬性為連續值特征屬性,會給定一個步長,然后把它離散化,之后把NaN作為一個類型加到屬性類目中。2.數據構造:由于車型數據是以圖像格式保存在數據庫中,為便于分析,首先人工對車型圖像數據進行標注,將車型分為無法識別車輛、客車、公交車、出租車、小轎車、輕型卡車、重型卡車,屬性值分別記為0,1,2,3,4,5,6。根據車輛的燃料類型分為汽油、柴油、天然氣,屬性值分別記為0,1,2。根據車輛登記日期以及車輛檢測時間,得到車輛使用年限分級。字段名字段說明年限分級使用年限1<=121~535~848~10根據車輛基準質量得到基準質量分級,(三)尾氣污染物排放影響因素關聯特征選擇機動車排放污染物的排放特性復雜,受車輛類型、行駛工況(速度、加速度)、燃料類型、車輛使用年限、風速、氣溫等諸多因素影響。采用灰色關聯分析方法找出影響尾氣排放的主要影響因素特征。灰色關聯度采用如下算法來判斷影響因素:(1)記原始數列xref,1為污染物數值屬性,依次為車輛類型,車輛行駛速度,加速度,燃料類型,車輛使用年限等屬性列。構造初始化數列i=1,2,…N17,N18為數據記錄數。(2)選取尾氣污染物濃度作為參考數列i=2,…N17為比較數列。(3)計算比較數列ycomp,i對參考數列ycomp,1,在第m點的關聯系數N19為分辨系數,取值范圍0~1,典型值為0.5。(4)綜合各比較序列點的關聯系數,可以得出整個序列ycomp,i與參考序列ycomp,1的關聯度按上述步驟(1)~(4)對CO、HC、NO濃度,煙度值的影響因素進行關聯度分析,按關聯度大小進行排序。從車輛類型、行駛工況(速度、加速度)、燃料類型、車輛使用年限、風速、氣溫等屬性中選取前N20個屬性作為車輛尾氣排放特征分析處理的核心維度特征參數,分別記為(四)構建車輛尾氣排放特征分析處理模型對步驟(三)得到的N20個屬性特征構造數據集S,采用基于密度的聚類算法對檢測車輛提取N20個屬性特征構成的數據集進行分類。具體實現算法如下:(1)輸入聚類數Ncluster,屬性數據集Ncluster為屬性數據集大小,密度參數N21,倍率參數N22;(2)從屬性數據集S中計算所有對象距離數據表distTable={dist(si,sj)},i=1,2,…Ndata,j=1,2,…Ndata;i≠j;對距離數據表從小到大排序得到距離排序數組Array;(3)通過Array的percent范圍內出現最多的數據點標記,得到初始點init,Array(percent)記為序列中值最小的percent比例部分,按式:Array(percent)={distArray1,distArray1,…,distArrayroughNum}得到,每一個distArray對應兩個不同數據點,其中,roughNum=percent×Ndata×(Ndata-1)/2(4)根據初始點init計算出當前簇的Eps和初始MinPts,得到當前簇的以init為圓心的初始簇點。Eps和初始MinPts的計算方法如下:其中epsNum記為與初始點與數據集其他各點之間距離小于等于的數據點的個數。初始(5)計算當前簇的每一個點的密度,若大于MinPts,則標記為簇心點,簇心點的Eps范圍內的點標記為當前簇類。(6)根據當前簇心點的平均MinPts,更新MinPts,重復步驟(5)直到當前簇點個數不再增加。按下式計算更新MinPts,更新當第i個數據點為當前第kcur簇點中心點時coreNumi=kcur,當不是中心點時,coreNumi=0。(7)從屬性數據集S去掉當前簇的點,當前簇類加1,重復(2)~(6)直到當前簇標為Ncluster+1(8)給每一個未被標記的數據點標記為與其相近最近標記點的簇標,最終聚類出Ncluster個數據簇,從而得到分群類別。車輛尾氣排放特征分析處理模型通過對每個檢測車輛分群的N20個屬性的均值與總的N20個屬性均值相比,來區分檢測車輛排放分級。每類分群的單個屬性值大于該屬性總體均值記為1,反之記為0,則一共有個排放水平分級。利用層次分析法得到每個特征屬性權重,按下式計算每個排放分群組別的排放得分,然后根據排放得分對分群組別排序。i=1,…Ncluster第i組分群的排放得分記為scorei,wscore,j是由層次分析法得到的各特征屬性權重,為第i組分群聚類中心各特征屬性標準化后的值。根據總得分大小對排放分群進行排序分級,對車輛尾氣排放的不同分級采取不同整治措施。本發明具體實施方式提高機動車尾氣遙測執法的效率和可靠性,為機動車尾氣執法監管提供科學決策支持。以上顯示和描述了本發明的基本原理和主要功能。本行業的技術人員應該了解,本發明不受上述實例的限制,上述實例和說明書中的描述只是說明本發明的原理,在不脫離本發明精神和范圍的前提下,本發明還會有各種變化和改進,這些變化和改進都落入要求保護的發明范圍內。本發明要求保護范圍由所附權利要求書及其等效物界定。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1