最優主題數計算方法及裝置與流程
本發明涉及機器學習技術領域,更具體地說,涉及一種最優主題數計算方法及裝置。
背景技術:
在自然語言處理過程中,文檔對于計算機通常被當作是一個無限維度的向量。而這種無限維度的向量對于計算機本身又是不可被計算的,這時就需要對文本進行降維處理,讓它以一定維度的數學向量儲存在計算機中以便計算。主題模型(Topic Model)就是一種常見的文檔降維方法。主題模型的實質是對文檔中隱含主題的一種建模方法。具體的,主題模型就是通過已知的“詞語-文檔”矩陣進行訓練,得到“詞語-主題”矩陣和“主題-文檔”矩陣的過程。其中,“詞語-文檔”矩陣表示每個文檔中每個詞語的詞頻(即出現的概率);“詞語-主題”矩陣表示每個主題中每個詞語出現的概率;“主題-文檔”矩陣表示每個文檔中每個主題出現的概率。
上述訓練過程,需要先獲取若干個主題數,然后基于每一個主題數,通過“詞語-文檔”矩陣進行訓練,得到每一個主題數對應的“詞語-主題”矩陣和“主題-文檔”矩陣,然后從上述若干個主題中選擇一個最優的主題數,將該最優主題數對應的“詞語-主題”矩陣和“主題-文檔”矩陣作為最優結果輸出。
顯然,主題數是主題模型的一個重要參數。如果最優主題數選擇不當(主題數過少或過多)會導致主題模型的輸出結果的質量較差。因此,如何選擇最優主題數成為亟待解決的問題。
技術實現要素:
本發明的目的是提供一種最優主題數計算方法及裝置,以提高主題模型的輸出結果的質量。
為實現上述目的,本發明提供了如下技術方案:
一種最優主題數計算方法,包括:
獲取主題模型中使用的若干個主題數;
對應每一個所述主題數,獲取所述主題數對應的,每個主題中每個詞語出現的第一概率,以及每個文檔中每個主題出現的第二概率;
基于所述第一概率和所述第二概率,計算兩兩主題間的第一相似度,以及兩兩詞語間的第二相似度;
基于所述主題數對應的兩兩主題間的第一相似度、所述主題數對應的兩兩詞語間的第二相似度以及所述主題數,計算所述主題數對應的平衡相似度,所述平衡相似度的大小用于衡量主題數的優劣;
將平衡相似度滿足預設條件時的主題數確定為最優主題數。
通過上述過程可知,本發明實施例中,基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的用于衡量主題數的優劣的平衡相似度;將平衡相似度滿足預設條件時的主題數確定為最優主題數。從而可以基于如下原則獲取最優主題數:主題數盡可能多,以保證最大程度的語義覆蓋,但是卻不能過多;各個主題盡可能表達獨立含義,盡量不存在語義交叉;相同含義的詞語越少越好,以保證用最少的詞語來表示盡可能多的語義。
上述方法,優選的,所述基于所述主題數對應的兩兩主題間的第一相似度、所述主題數對應的兩兩詞語間的第二相似度以及所述主題數,計算所述主題數對應的平衡相似度,包括:
計算所述主題數對應的兩兩主題間的第一相似度的第一和值,以及所述主題數對應的兩兩詞語間的第二相似度的第二和值;
將所述第一和值和所述第二和值的乘積與所述主題數的平方值做商運算,得到所述主題數對應的平衡相似度。
上述方法,優選的,所述將平衡相似度滿足預設條件時的主題數確定為最優主題數,包括:
將平衡相似度最小時的主題數確定為最優主題數。
上述過程中,通過分母主題數的平方來確保主題數不會過大;通過對兩兩主題間的相似度求和,并且通過平衡相似度最小來使得主題數范圍內的主題間語義疊加最小;通過對兩兩詞語間的相似度求和,并且通過平衡相似度最小來使得當前主題數范圍內的主題中所有詞語語義疊加最小。
上述方法,優選的,基于所述第一概率計算兩兩主題間的第一相似度,包括:
獲取與第一主題對應的第一向量,以及與第二主題對應的第二向量;所述第一向量中的元素為所述第一主題中各個詞語出現的第一概率,所述第二向量中的元素為所述第二主題中各個詞語出現的第一概率;
基于所述第一向量和所述第二向量計算所述第一主題和所述第二主題間的第一相似度。
上述方法,優選的,基于所述第一概率和所述第二概率計算兩兩詞語間的第二相似度,包括:
計算不同文檔中同一主題出現的第二概率的第三和值;
對應每一個主題,計算主題對應的所述第三和值與主題中第一詞語出現的第一概率的第一乘積,將第一乘積結果與語料庫中所述第一詞語的詞頻做商運算,得到在所述第一詞語出現的條件下,每一個主題的第三概率;計算主題對應的所述第三和值與主題中第二詞語出現的第一概率的第二乘積,將第二乘積結果與語料庫中所述第二詞語的詞頻做商運算,得到在所述第二詞語出現的條件下,每一個主題的第四概率;
獲取與所述第一詞語對應的第三向量,以及與所述第二詞語對應的第四向量;所述第三向量中的元素為在所述第一詞語出現的條件下,各個主題的第三概率;所述第四向量中的元素為在所述第二詞語出現的條件下,各個主題的第四概率;
基于所述第三向量和所述第四向量計算所述第一詞語和所述第二詞語間的第二相似度。
一種最優主題數計算裝置,包括:
第一獲取模塊,用于獲取主題模型中使用的若干個主題數;
第二獲取模塊,用于對應每一個所述主題數,獲取所述主題數對應的,每個主題中每個詞語出現的第一概率,以及每個文檔中每個主題出現的第二概率;
第一計算模塊,用于基于所述第一概率和所述第二概率,計算兩兩主題間的第一相似度,以及兩兩詞語間的第二相似度;
第二計算模塊,用于基于所述主題數對應的兩兩主題間的第一相似度、所述主題數對應的兩兩詞語間的第二相似度以及所述主題數,計算所述主題數對應的平衡相似度,所述平衡相似度的大小用于衡量主題數的優劣;
確定模塊,用于將平衡相似度滿足預設條件時的主題數確定為最優主題數。
本發明實施例提供的最優主題數計算裝置,基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的用于衡量主題數的優劣的平衡相似度;將平衡相似度滿足預設條件時的主題數確定為最優主題數。從而可以基于如下原則獲取最優主題數:主題數盡可能多,以保證最大程度的語義覆蓋,但是卻不能過多;各個主題盡可能表達獨立含義,盡量不存在語義交叉;相同含義的詞語越少越好,以保證用最少的詞語來表示盡可能多的語義。
上述裝置,優選的,所述第二計算模塊包括:
第一計算單元,用于計算所述主題數對應的兩兩主題間的第一相似度的第一和值,以及所述主題數對應的兩兩詞語間的第二相似度的第二和值;
第二計算單元,用于將所述第一和值和所述第二和值的乘積與所述主題數的平方值做商運算,得到所述主題數對應的平衡相似度。
上述裝置,優選的,所述確定模塊用于,將平衡相似度最小時的主題數確定為最優主題數。
上述最優主題數計算裝置,通過分母主題數的平方來確保主題數不會過大;通過對兩兩主題間的相似度求和,并且通過平衡相似度最小來使得主題數范圍內的主題間語義疊加最小;通過對兩兩詞語間的相似度求和,并且通過平衡相似度最小來使得當前主題數范圍內的主題中所有詞語語義疊加最小。
上述裝置,優選的,所述第一計算模塊用于基于所述第一概率計算兩兩主題間的第一相似度,包括:
第一獲取單元,用于獲取與第一主題對應的第一向量,以及與第二主題對應的第二向量;所述第一向量中的元素為所述第一主題中各個詞語出現的第一概率,所述第二向量中的元素為所述第二主題中各個詞語出現的第一概率;
第三計算單元,用于基于所述第一向量和所述第二向量計算所述第一主題和所述第二主題間的第一相似度。
上述裝置,優選的,所述第一計算模塊用于基于所述第一概率和所述第二概率計算兩兩詞語間的第二相似度,包括:
第四計算單元,用于計算不同文檔中同一主題出現的第二概率的第三和值;
第五計算單元,用于對應每一個主題,計算主題對應的所述第三和值與主題中第一詞語出現的第一概率的第一乘積,將第一乘積結果與語料庫中所述第一詞語的詞頻做商運算,得到在所述第一詞語出現的條件下,每一個主題的第三概率;計算主題對應的所述第三和值與主題中第二詞語出現的第一概率的第二乘積,將第二乘積結果與語料庫中所述第二詞語的詞頻做商運算,得到在所述第二詞語出現的條件下,每一個主題的第四概率;
第二獲取單元,用于獲取與所述第一詞語對應的第三向量,以及與所述第二詞語對應的第四向量;所述第三向量中的元素為在所述第一詞語出現的條件下,各個主題的第三概率;所述第四向量中的元素為在所述第二詞語出現的條件下,各個主題的第四概率;
第六計算單元,用于基于所述第三向量和所述第四向量計算所述第一詞語和所述第二詞語間的第二相似度。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1a為“詞語-文檔”矩陣的一種示例;
圖1b為“詞語-主題”矩陣的一種示例圖;
圖1c為“主題-文檔”矩陣的一種示例圖;
圖2為本發明實施提供的最優主題數計算方法的一種實現流程圖;
圖3為本發明實施提供的基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的平衡相似度的一種實現流程圖;
圖4為本發明實施提供的計算兩兩主題間的第一相似度的一種實現流程圖;
圖5為本發明實施提供的計算兩兩詞語間的第二相似度的一種實現流程圖;
圖6為基于本發明實施例中公式(1)相關實施例提供的,最優主題數計算方法計算過程中平衡相似度的一種變化趨勢圖;
圖7為基于本發明實施例中公式(1)相關實施例提供的,最優主題數計算方法計算過程中平衡相似度的另一種變化趨勢圖;
圖8為利用基于信息熵的困惑度來評價主題模型整體質量的時,困惑度的變化趨勢圖;
圖9為本發明實施提供的最優主題數計算裝置的一種結構示意圖;
圖10為本發明實施提供的第二計算模塊的一種結構示意圖;
圖11為本發明實施提供的第一計算模塊的一種結構示意圖;
圖12為本發明實施提供的第一計算模塊的另一種結構示意圖。
說明書和權利要求書及上述附圖中的術語“第一”、“第二”、“第三”“第四”等(如果存在)是用于區別類似的部分,而不必用于描述特定的順序或先后次序。應該理解這樣使用的數據在適當情況下可以互換,以便這里描述的本申請的實施例能夠以除了在這里圖示的以外的順序實施。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有付出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
為了更好的理解本發明實施例,首先對主題模型的訓練過程進行說明。
在訓練開始之前,需要技術人員根據先驗知識確定若干個主題數,主題數即為主題的個數。為方便敘述,這里將第r個主題數記為Nr(r=1,2,3,4,……,n),n表示主題數的個數。
在啟動訓練過程后,首先,對于語料庫中的一系列文檔,通過對文檔進行分詞,計算各個文檔中每個詞語的詞頻就可以得到“詞語-文檔”矩陣。
“詞語-文檔”矩陣的一種示例如圖1a所示。“詞語-文檔”矩陣表示每個文檔中每個詞語的詞頻(即出現的概率),也就是說,若“詞語-文檔”矩陣中某個元素對應的文檔為d,對應的詞語為w,則該元素的取值為P(w|d)。
主題模型的訓練過程,就是對應每一個主題數,通過圖1a所示的“詞語-文檔”矩陣得到“詞語-主題”矩陣和“主題-文檔”矩陣,然后,根據一定的規則找到最優主題數,輸出與最優主題數對應的“詞語-主題”矩陣和“主題-文檔”矩陣的過程。
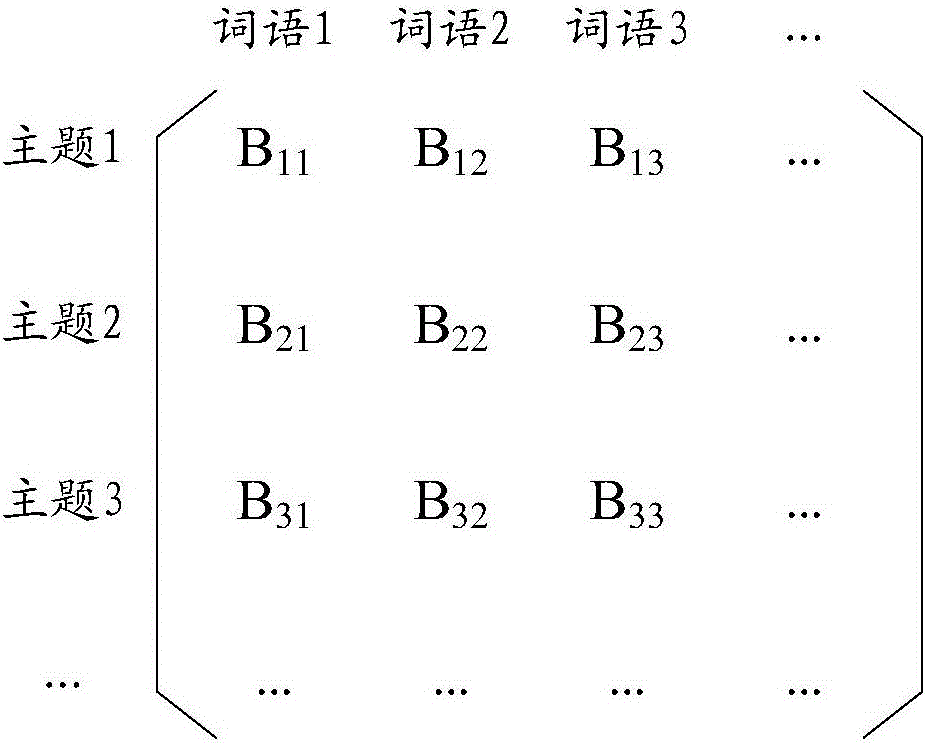
其中,“詞語-主題”矩陣的一種示例圖如圖1b所示,“詞語-主題”矩陣表示每個主題中每個詞語出現的概率,也就是說,若“詞語-主題”矩陣中某個元素對應的主題為t,對應的詞語為w,則該元素的取值為P(w|t)。“主題-文檔”矩陣的一種示例圖如圖1c所示,“主題-文檔”矩陣表示每個文檔中每個主題出現的概率,也就是說,若“主題-文檔”矩陣中某個元素對應的主題為t,對應的文檔為d,則該元素的取值為P(t|d)。
1a-1c三個矩陣滿足如下關系:“詞語-文檔”矩陣等于“主題-文檔”矩陣與“詞語-主題”矩陣的乘積。
本發明實施例就是提供一種確定最優主題數的方法及裝置。
請參閱圖2,圖2為本發明實施提供的最優主題數計算方法的一種實現流程圖,可以包括:
步驟S21:獲取主題模型中使用的若干個主題數。
主題模型使用的若干各主題數即為主題模型訓練開始之前,由技術人員根據先驗知識確定的若干個主題數。
例如,確定了8個主題數,分別為4,20,25,35,37,65,88。若主題數為4,則“詞語-主題”矩陣和“主題-文檔”矩陣中的主題數均為4,即,“詞語-主題”矩陣的行數為4,“主題-文檔”矩陣的列數為4。同理,若主題數為25,則“詞語-主題”矩陣和“主題-文檔”矩陣中的主題數均為25,即,“詞語-主題”矩陣的行數為25,“主題-文檔”矩陣的列數為25。
步驟S22:對應每一個主題數,獲取該主題數對應的,每個主題中每個詞語出現的第一概率,以及每個文檔中每個主題出現的第二概率。
主題數確認后,相對應的“詞語-主題”矩陣和“主題-文檔”矩陣就確定了,而“詞語-主題”矩陣表示每個主題中每個詞語出現的概率,“主題-文檔”矩陣表示每個文檔中每個主題出現的概率,因此,對應每一個主題數,該主題數對應的每個主題中每個詞語出現的第一概率,以及每個文檔中每個主題出現的第二概率是已知的。可以直接從“詞語-主題”矩陣和“主題-文檔”矩陣中讀取每個主題中每個詞語出現的第一概率,以及每個文檔中每個主題出現的第二概率。
步驟S23:基于第一概率和第二概率,計算兩兩主題間的第一相似度,以及兩兩詞語間的第二相似度。
在一可選的實施例中,兩兩主題間的第一相似度可以通過詞語的語義分布來計算。對于一個主題來說,詞語的語義分布即為:不同的詞語在該主題中出現的概率。
兩兩詞語間的第二相似度可以通過主題的語義分布來計算。對于一個詞語來說,主題的語義分布即為:在該詞語出現的情況下,各個主題的概率。例如,“蘋果”出現的時候,會有一定的概率來表示水果,也有一定的概率表示為電子產品。那么,蘋果這個詞的語義分布即為,在蘋果這個詞出現的情況下,主題“水果”的概率,以及主題“電子產品”的概率。其中,主題的語義分布可以基于“詞語-主題”矩陣和“主題-文檔”矩陣計算得到。
為便于區分,可以將通過詞語的語義分布計算兩兩主題間的相似度記為正向相似度;將通過主題的語義分布計算兩兩詞語間的相似度記為反向相似度。
步驟S24:基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的平衡相似度,平衡相似度的大小用于衡量主題數的優劣。
對應每一個主題數,基于該主題數對應的兩兩主題間的第一相似度、該主題數對應的兩兩詞語間的第二相似度以及該主題數,計算該主題數對應的平衡相似度。也就是說,每一個主題數對應一個平衡相似度。
步驟S25:將平衡相似度滿足預設條件時的主題數確定為最優主題數。
本發明實施例提供的計算最優主題數的方法,基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的用于衡量主題數的優劣的平衡相似度;將平衡相似度滿足預設條件時的主題數確定為最優主題數。從而可以基于如下原則獲取最優主題數:主題數盡可能多,以保證最大程度的語義覆蓋,但是卻不能過多;各個主題盡可能表達獨立含義,盡量不存在語義交叉;相同含義的詞語越少越好,以保證用最少的詞語來表示盡可能多的語義。
在一可選的實施例中,基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的平衡相似度的一種實現流程圖如圖3所示,可以包括:
步驟S31:計算主題數對應的兩兩主題間的第一相似度的第一和值,以及主題數對應的兩兩詞語間的第二相似度的第二和值;
假設主題個數為m,則共有m(m-1)/2個兩兩主題間的第一相似度,因此,兩兩主題間的第一相似度的第一和值是指上述m(m-1)/2個第一相似度的和值;同理,若“詞語-文檔”矩陣中,詞語數為q,則共有q(q-1)/2個兩兩詞語間的第二相似度,因此,兩兩詞語間的第二相似度的第二和值是指上述q(q-1)/2個第二相似度的和值。
步驟S32:將第一和值和第二和值的乘積與主題數的平方值做商運算,得主題數對應的平衡相似度。
若用K表示主題數,主題數K對應的平衡相似度為BlanceSimilarity(K),則平衡相似度的計算公式為:
其中,W表示所有詞語的集合,T表示與主題數K對應的所有主題的集合;similarity(wi,wj)表示詞語wi和詞語wj的相似度;similarity(ti,tj)表示主題ti和主題tj的相似度。
基于上述平衡相似度的計算方法,可以將平衡相似度最小時的主題數確定為最優主題數。若用K0表示最優主題數,則K0可以用公式表示為:
其中,argmin是一個數學符號,表示函數BlanceSimilarity(K)取值最小時的自變量K的取值。
本發明實施例中,通過分母K2來確保主題數不會過大,為了讓主題數盡可能的多,在實際使用中可以按照主題數K從小到大的順序進行訓練;為了讓各個主題盡可能表達獨立含義,不存在語義交叉,通過對兩兩主題間的相似度求和,并且通過平衡相似度最小來使得主題數范圍內的主題間語義疊加最小;為了保證相同含義的詞語盡可能少(包括:相同詞語盡可能不在多個主題中存在,并且相同含義的詞語盡可能少),通過對兩兩詞語間的相似度求和,并且通過平衡相似度最小來使得當前主題數范圍內的主題中所有詞語語義疊加最小。
另外,本發明實施例提供的計算最優主題數的方法計算簡單,且計算量小,節省計算資源。
在另一可選的實施例中,在計算主題數對應的兩兩主題間的第一相似度的第一和值,以及主題數對應的兩兩詞語間的第二相似度的第二和值之后,可以計算第一和值和第二和值的乘積,然后將主題數的平方值與乘積結果做商運算,得到主題數對應的平衡相似度。此時,可以將平衡相似度最大時的主題數確定為最優主題數。本實施例中,最優主題數的計算公式為:
其中,argmax是一個數學符號,表示函數BlanceSimilarity(K)取值最大時的自變量K的取值。
與圖3所示實施例不同,本發明實施例中,通過分子K2來確保主題數不會過大,為了讓主題數盡可能的多,在實際使用中可以按照主題數K從小到大的順序進行訓練;為了讓各個主題盡可能表達獨立含義,不存在語義交叉,通過對兩兩主題間的相似度求和,并且通過平衡相似度最大來使得主題數范圍內的主題間語義疊加最小;為了保證相同含義的詞語盡可能少(包括:相同詞語盡可能不在多個主題中存在,并且相同含義的詞語盡可能少),通過對兩兩詞語間的相似度求和,并且通過平衡相似度最大來使得當前主題數范圍內的主題中所有詞語語義疊加最小。
在一可選的實施例中,可以基于第一概率計算兩兩主題間的第一相似度。對于任意兩個主題,分別為第一主題和第二主題,計算這兩個主題間的第一相似度的一種實現流程圖如圖4所示,可以包括:
步驟S41:獲取與第一主題對應的第一向量,以及與第二主題對應的第二向量;其中,第一向量中的元素為第一主題中各個詞語出現的第一概率,第二向量中的元素為第二主題中各個詞語出現的第一概率;
以圖1b為例,主題1對應的向量為(B11,B12,B13,…),主題2對應的向量為(B21,B22,B23,…),主題3對應的向量為(B31,B32,B33,…),依此類推。
步驟S42:基于第一向量和第二向量計算第一主題和第二主題間的第一相似度。
可以計算第一向量和第二向量之間的KL散度,通過KL散度來衡量第一主題和第二主題間的相似度。KL散度越小,表征第一主題和第二主題間越相似,即相似度越大。KL散度越大,表征第一主題和第二主題間越不相似,即相似度越小。
也可以計算第一主題和第二主題間的余弦相似度,即,計算第一向量和第二向量的夾角余弦值,通過夾角余弦值來衡量第一主題和第二主題的相似度。夾角余弦值越小,表征第一主題和第二主題間越相似,即相似度越大。夾角余弦值越大,表征第一主題和第二主題間越不相似,即相似度越小。
還可以計算第一向量和第二向量的歐式距離,通過歐式距離來衡量第一主題和第二主題間的相似度。歐式距離越小,表征第一主題和第二主題間越相似,即相似度越大。歐式距離越大,表征第一主題和第二主題間越不相似,即相似度越小。
當然,本發明實施例中,并不限于以上幾種方式計算第一主題和第二主題間的第一相似度,還可以通過其它方式計算第一主題和第二主題間的第一相似度,例如,計算第一向量和第二向量的皮爾森系數,通過皮爾森系數來衡量第一主題和第二主題間的相似度。
在一可選的實施例中,可以基于第一概率和第二概率計算兩兩詞語間的第二相似度,對于任意兩個詞語,分別為第一詞語和第二詞語,計算這兩個詞語間的第二相似度的一種實現流程圖如圖5所示,可以包括:
步驟S51:計算不同文檔中同一主題出現的第二概率的第三和值;
這里的不同文檔是指語料庫中的各個文檔。第二概率可以從“主題-文檔”矩陣中直接讀取。
以圖1c為例,不同文檔中主題1出現的第二概率的第三和值為:C11+C21+C31+…;不同文檔中主題2出現的第二概率的第三和值為:C12+C22+C32+…;不同文檔中主題3出現的第二概率的第三和值為:C13+C23+C33+…;依此類推。
不同文檔中,主題ti出現的第二概率的第三和值用公式表示為:∑d∈DP(ti|d),其中,d表示文檔,D表示文檔集合。
步驟S52:對應每一個主題,計算主題對應的第三和值與主題中第一詞語出現的第一概率的第一乘積,將第一乘積結果與語料庫中第一詞語的詞頻做商運算,得到在第一詞語出現的條件下,每一個主題的第三概率;計算主題對應的第三和值與主題中第二詞語出現的第一概率的第二乘積,將第二乘積結果與語料庫中第二詞語的詞頻做商運算,得到在第二詞語出現的條件下,每一個主題的第四概率;
下面以第i個主題ti為例進行說明。對應第i個主題ti,計算主題ti對應的第三和值與主題ti中第一詞語(為方便敘述記為w1)出現的第一概率的第一乘積,將第一乘積結果與語料庫中第一詞語的詞頻做商運算,得到在第一詞語出現的條件下,主題ti的概率P(ti|w1),用公式表示為:
其中,∑d∈DP(ti|d)表示不同文檔中,主題ti出現的第二概率的第三和值,d表示文檔,D表示文檔集合,P(w1|ti)表示主題ti中第一詞語w1出現的概率,P(w1)表示在整個語料庫中第一詞語w1的詞頻。
同理,對應第i個主題ti,計算主題ti對應的第三和值與主題ti中第二詞語(為方便敘述記為w2)出現的第一概率的第二乘積,將第二乘積結果與語料庫中第二詞語的詞頻做商運算,得到在第二詞語出現的條件下,主題ti的概率P(w2|ti),用公式表示為:
其中,∑d∈DP(ti|d)表示不同文檔中,主題ti出現的第二概率的第三和值,d表示文檔,D表示文檔集合,P(w2|ti)表示主題ti中第二詞語w2出現的概率,P(w2)表示在整個語料庫中第二詞語w2的詞頻。
上述第一詞語和第二詞語為語料庫中的任意兩個詞語。
同理,對應其它任意一個主題,在第一詞語出現的情況下,該主題的概率的計算方式可以參照前述計算過程,這里不在一一詳述。
步驟S53:獲取與第一詞語對應的第三向量,以及與第二詞語對應的第四向量;其中,第三向量中的元素為在第一詞語出現的條件下,各個主題的第三概率;第四向量中的元素為在第二詞語出現的條件下,各個主題的第四概率;
第一詞語對應的第三向量為(P(t1|w1),P(t2|w1),P(t3|w1),…),第二詞語對應的第四向量為(P(t1|w2),P(t2|w2),P(t3|w2),…)。
步驟S54:基于第三向量和第四向量計算第一詞語和第二詞語間的第二相似度。
可以計算第三向量和第四向量之間的KL散度,通過KL散度來衡量第一詞語和第二詞語間的相似度。KL散度越小,表征第一詞語和第二詞語間越相似,即相似度越大。KL散度越大,表征第一詞語和第二詞語間越不相似,即相似度越小。
也可以計算第一詞語和第二詞語的余弦相似度,即,計算第三向量和第四向量的夾角余弦值,通過夾角余弦值來衡量第一詞語和第二詞語的相似度。夾角余弦值越小,表征第一詞語和第二詞語間越相似,即相似度越大。夾角余弦值越大,表征第一詞語和第二詞語間越不相似,即相似度越小。
還可以計算第三向量和第四向量的歐式距離,通過歐式距離來衡量第一詞語和第二詞語間的相似度。歐式距離越小,表征第一詞語和第二詞語間越相似,即相似度越大。歐式距離越大,表征第一詞語和第二詞語間越不相似,即相似度越小。
當然,本發明實施例中,并不限于以上幾種方式計算第一詞語和第二詞語間的第二相似度,還可以通過其它方式計算第一詞語和第二詞語間的第二相似度,例如,計算第三向量和第四向量的皮爾森系數,通過皮爾森系數來衡量第一詞語和第二詞語間的第二相似度。
下面通過具體的測試實例說明本發明實施例的有效性。
本測試實例中,計算了相同語料條件下,主題數被設定為5,25,35,40,45,47,50,100的主題模型結果。然后通過本發明實施例提供的最優主題數計算方法計算最優主題數,并通過基于信息熵的困惑度來計算最優主題數。
如圖6所示,為基于本發明實施例中公式(1)相關實施例提供的,最優主題數計算方法計算過程中平衡相似度的一種變化趨勢圖,其中,相似度的計算采用了余弦相似度計算方法。圖6中,橫軸表示主題數,縱軸表示平衡相似度。
如圖7所示,為基于本發明實施例中公式(1)相關實施例提供的,最優主題數計算方法計算過程中平衡相似度的另一種變化趨勢圖,其中,相似度的計算采用了KL散度計算方法。圖7中,橫軸表示主題數,縱軸表示平衡相似度。
基于本發明實施例中的公式(2),結合圖6和圖7所示的平衡相似度的變化趨勢,可以看出,不管是圖6所示示例,還是圖7所示示例,最優主題數均為40。
困惑度是LDA(Latent Dirichlet Allocation,隱含狄利克雷分布)的作者Blei在LDA原論文中通過利用主題模型去擬合原文本時的信息熵來評價主題模型整體質量的方法。該方法將困惑度最小時的主題數確定為最優主題數。困惑度計算公式如下所示:
其中,perlexity表示困惑度,z表示主題,d表示文檔,D表示文檔集合,即語料庫,w表示詞語,|d|表示文檔d中詞語的個數,∑d∈D|d|表示語料庫中詞語的個數。
如圖8所示,為利用基于信息熵的困惑度來評價主題模型整體質量的時,困惑度的變化趨勢圖。圖8中,橫軸表示主題數,縱軸表示困惑度。
從圖8可以看出,當主題數為40時,困惑度最小。即最優主題數也為40。
將圖6或圖7與圖8進行比較可知,本發明實施例提供的最優主題數計算方法是有效的。而且,圖6和圖7所示示例中,所使用的相似度計算方法為計算向量相似度比較通用的方法,因此,可以看出,本發明實施例中,相似度計算方法并不影響最優主題數的計算結果,本發明實施例提供的最優主題數計算方法可以采用任何相似度算法來進行最優主題數的計算,適用范圍較廣。
與方法實施例相對應,本發明實施例還提供一種最優主題數計算裝置。本發明實施例提供的最優主題數計算裝置的一種結構示意圖如圖9所示,可以包括:
第一獲取模塊91,第二獲取模塊92,第一計算模塊93,第二計算模塊94和確定模塊95;其中,
第一獲取模塊91用于獲取主題模型中使用的若干個主題數;
第二獲取模塊92用于對應每一個主題數,獲取主題數對應的,每個主題中每個詞語出現的第一概率,以及每個文檔中每個主題出現的第二概率;
第一計算模塊93用于基于第一概率和第二概率,計算兩兩主題間的第一相似度,以及兩兩詞語間的第二相似度;
第二計算模塊94用于基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的平衡相似度,平衡相似度的大小用于衡量主題數的優劣;
確定模塊94用于將平衡相似度滿足預設條件時的主題數確定為最優主題數。
本發明實施例提供的最優主題是計算裝置,基于主題數對應的兩兩主題間的第一相似度、主題數對應的兩兩詞語間的第二相似度以及主題數,計算主題數對應的用于衡量主題數的優劣的平衡相似度;將平衡相似度滿足預設條件時的主題數確定為最優主題數。從而可以基于如下原則獲取最優主題數:主題數盡可能多,以保證最大程度的語義覆蓋,但是卻不能過多;各個主題盡可能表達獨立含義,盡量不存在語義交叉;相同含義的詞語越少越好,以保證用最少的詞語來表示盡可能多的語義。
在一可選的實施例中,第二計算模塊94的一種結構示意圖如圖10所示,可以包括:
第一計算單元101和第二計算單元102;其中,
第一計算單元101用于計算主題數對應的兩兩主題間的第一相似度的第一和值,以及主題數對應的兩兩詞語間的第二相似度的第二和值;
第二計算單元102用于將第一和值和第二和值的乘積與主題數的平方值做商運算,得到主題數對應的平衡相似度。
在一可選的實施例中,確定模塊95具體用于,將平衡相似度最小時的主題數確定為最優主題數。
在一可選的實施例中,第一計算模塊93用于基于第一概率計算兩兩主題間的第一相似度,第一計算模塊93的一種結構示意圖如圖11所示,可以包括:
第一獲取單元111和第三計算單元112;其中,
第一獲取單元111用于獲取與第一主題對應的第一向量,以及與第二主題對應的第二向量;第一向量中的元素為第一主題中各個詞語出現的第一概率,第二向量中的元素為第二主題中各個詞語出現的第一概率;
第三計算單元112用于基于第一向量和第二向量計算第一主題和第二主題間的第一相似度。
在另一可選的實施例中,第一計算模塊93用于基于第一概率和第二概率計算兩兩詞語間的第二相似度,第一計算模塊93的另一種結構示意圖如圖12所示,可以包括:
第四計算單元121,第五計算單元122,第二獲取單元123和第六計算單元124;其中,
第四計算單元121用于計算不同文檔中同一主題出現的第二概率的第三和值;
第五計算單元122用于對應每一個主題,計算主題對應的第三和值與主題中第一詞語出現的第一概率的第一乘積,將第一乘積結果與語料庫中第一詞語的詞頻做商運算,得到在第一詞語出現的條件下,每一個主題的第三概率;計算主題對應的第三和值與主題中第二詞語出現的第一概率的第二乘積,將第二乘積結果與語料庫中第二詞語的詞頻做商運算,得到在第二詞語出現的條件下,每一個主題的第四概率;
第二獲取單元123用于獲取與第一詞語對應的第三向量,以及與第二詞語對應的第四向量;第三向量中的元素為在第一詞語出現的條件下,各個主題的第三概率;第四向量中的元素為在第二詞語出現的條件下,各個主題的第四概率;
第六計算單元124用于基于第三向量和第四向量計算第一詞語和第二詞語間的第二相似度。
本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬件、或者計算機軟件和電子硬件的結合來實現。這些功能究竟以硬件還是軟件方式來執行,取決于技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的范圍。
所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的系統(若存在)、裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的系統、裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。
所述功能如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光盤等各種可以存儲程序代碼的介質。
對所公開的實施例的上述說明,使本領域專業技術人員能夠實現或使用本發明。對這些實施例的多種修改對本領域的專業技術人員來說將是顯而易見的,本文中所定義的一般原理可以在不脫離本發明的精神或范圍的情況下,在其它實施例中實現。因此,本發明將不會被限制于本文所示的這些實施例,而是要符合與本文所公開的原理和新穎特點相一致的最寬的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!