一種設備安全等級分類方法與流程
本發明涉及電廠設備安全等級評測分類領域,具體涉及一種設備安全等級分類方法。
背景技術:
火電廠設備的運行狀態,對火電廠的安全運行具有至關重要的作用。實時地實現火電廠設備安全等級分類,可以判斷設備當前安全狀態、輔助預測電廠設備中存在的潛在風險,以及判斷可能導致的危險,從而實施合理可行的安全對策措施,指導事故預防。可見,實現對設備的狀態進行客觀的安全等級分類,是完善設備故障診斷體系的前提,是輔助檢修的重要手段,也是實現設備狀態檢測的重要組成部分。因此,形成一套科學的火電廠設備安全等級評價方法,對火電廠設備狀態進行安全等級分類,具有重要的現實意義。
安全分類屬于安全評價的范疇,常用的安全評價的方法主要有三種:
1、定性評價
定性評價方法,對系統中各種危險因素的嚴重程度進行“定性”、“量化”,實現對系統的危險性進行全面分析。其中量化值表示系統危險的嚴重程度,常用的量化方法例如:逐項賦值評分法,簡稱評分法。評分法根據評價對象,確定安全評價的項目以及各個項的危險重要程度,逐項分析,最終確定總分。
該方法依賴專家的知識和經驗來確定各項的重要程度,在實際應用中具有很大的局限性,一方面各項的權重很難確認,且權重系統很難得到公眾的認可;另一方面各項權重的確認需要大量人力、物力的投入。
2、定量評價
定量評價方法用精確的數學方法求得系統的事故概率,將事故概率與一定的安全指標進行比較評價系統的安全水平。其中一種技術為計算事故概率,典型案例:1972年麻省理工學院拉斯姆教授組織70位專家花費一年時間,耗資300萬美元,對核電站進行安全評價。另一種技術為層次分析法(analytichierarchyprocess,ahp),將復雜決策問題分解成層次結構,通過分析各影響、組成因素的重要程度來進行評價。
通過計算事故概率的技術實現系統定量評價,缺陷顯而易見:投入巨大且廣泛應用性弱。對于使用ahp方法實現系統的定量評價,《關于ahp中判斷矩陣矯正方法的研究》(系統工程理論與時間,1997年第17卷第6期)中提出,在實際應用時該方法依賴經驗和技巧進行修正,缺乏相應的科學理論和方法。
3、模糊評價
模糊評價方法基本思想屬于定性評價,仍要依靠人腦處理模糊概念的能力,依靠專家群體的知識和經驗。采用模糊數學方法,利用模糊矩陣等方式實現對子系統和多因素的綜合評價。
模糊評價方法仍需依靠專家的知識和經驗,在實際應用中具有很大的局限性。
我國電力行業的安全評價工作目前尚處于起步階段。1995年,我國結合電力企業安全管理的經驗,引入安全評價體系制定了針對火電廠的安全檢測表及安全評價標準,《中國華北電力集團公司監察部》(火力發電廠安全性評價,中國電力出版社,1995)。該評價標準現已廣泛應用于火電廠安全評價中,但是此標準體系只針對電廠的大修情況,而對于火電廠實時的評價,目前國內外尚處于起步階段,造成了無法實時實現設備的安全等級分類。
針對以上現象,亟需發明一種新的方法,實時地實現設備的安全等級評價,從而輔助發現設備的潛在風險,預測設備的危險程度,為提前維修提供基礎保障。
技術實現要素:
本發明的目的在于克服現有技術的不足,提供一種智能可靠的設備狀態安全等級分類技術。本發明在smote算法的基礎上,通過多次抽樣技術,改善樣本分布,解決了分類樣本的不平衡問題、降低樣本的不平衡率。本發明基于svm分類器,建立多維指標的特征與設備安全等級的復雜非線性關系,建立設備的安全等級分類模型。由于svm在數據不平衡的情況下效果不理想,本發明在數據處理層面進行改進,降低數據的不平衡率,發揮了支持向量機模型的優勢。
本發明提供了一種設備安全等級分類方法,依次包括如下步驟:
1)訓練安全分類模型,包括如下步驟;
步驟1.1:綜合處理設備在不同時間下已有的專家評價結果,得到設備不同工況下的安全等級,從而建立設備安全等級庫;
步驟1.2:選取訓練數據,提取安全特征;
步驟1.3:對提取完安全特征的訓練數據進行樣本smote抽樣;
步驟1.4:對抽樣處理后的樣本進行預處理;
步驟1.5:采用非線性支持向量機分類模型在預處理后的訓練數據的基礎上建立設備的安全等級分類模型;
2)實時預測設備安全等級,包括如下步驟:
步驟2.1:檢測設備運行,實時獲取設備的實時運行數據;
步驟2.2:提取實時運行數據的安全特征向量y=(y1,y2,...ym),其由m維數指標構成,維數與訓練數據一致;
步驟2.3:對提取的實時運行數據采用與步驟1)中的步驟4一致的數據預處理方式進行預處理,得到預處理后的實時運行數據;
步驟2.4:基于預處理后的實時運行數據,使用訓練好的安全等級多分類器,預測實時數據安全等級分類。
進一步地,步驟1.1具體步驟為:
(1)設定設備安全等級:
每個設備的安全等級分為3個類別,安全類別分別為:a類,b類,c類,其中安全級別大小關系為:
a<b<c
a類代表該設備不安全,b類代表該設備處于基本安全狀態,c類代表該設備非常安全;
(2)獲取設備的安全等級:
獲取設備在各個時刻下由n個專家評定的安全等級,假設時刻t下,設備的安全等級評價結果如下式所示,為安全等級評價向量,其中li代表第i個專家對該設備的評價結果;
l=(l1,l2,...li...ln)(li∈(a,b,c)
將評價結果轉化為數值形式,建立安全等級和數值間的一一映射關系,即
((a->1),(b->2),(c->3))
(3)標記設備的安全類型:
通過如下公式對安全等級評價向量進行計算,將n個專家的評價結果進行平均化并取整,得到時刻t下設備的安全類型數值s',并根據安全等級和數值間的映射關系式得到安全等級標記,然后標記設備在t時刻的安全類型:
其中round函數為對變量進行四舍五入取整;
通過上述步驟(1)-(3)標記各個設備在不同時刻下的安全等級,建立設備的安全等級庫。
進一步地,步驟1.2具體步驟為:
(1)選取訓練數據
查詢設備安全等級庫,選取有安全標記的設備作為研究對象,并獲取相關的歷史數據作為訓練數據;
(2)提取設備安全特征
提取訓練數據的安全特征,構建設備安全特征向量;選取與設備安全運行相關的關鍵參數,通過專家法計算指標,構建表征設備安全的特征空間,其中t時刻下設備的特征向量為:x=(x1,x2,...xm),其代表m維數指標構成的安全特征。
進一步地,步驟1.3具體步驟為:
(1)計算兩類樣本的不平衡率:
計算少數類和多數類樣本的比例,得到樣本的不平衡率imbalancerate,用來衡量樣本的不平衡情況,imbalancerate計算公式如下,num1為少數類樣本數目,num2為多數類樣本數目:
(2)判斷不平衡率是否超過閾值:
設定不平衡率的閾值θ1,判定樣本是否不平衡,若不平衡率大于閾值,說明樣本平衡不需抽樣;否則說明樣本不平衡,需進行抽樣,進行步驟(3);
(3)對樣本中的少數類樣本進行smote抽樣:
選定少數類樣本中的目標樣本,假定某目標為樣本s,搜索其m近鄰樣本,在近鄰中隨機選擇k個樣本n1,n2,...nk,在樣本s與k個樣本間進行隨機插值,構造如下所示的樣本,作為少數類樣本的新樣本,假設隨機選擇的樣本為ni,則新的樣本yi為:
其中
(4)抽樣結束判斷。
進一步地,步驟1.4具體步驟為:
對抽樣處理后的樣本進行預處理為數據集歸一化處理,對于數據集的各個維數數據,采用如下公式進行歸一化處理后將數據統一歸一到[0,1]之間的數據范圍內,消除不同維數數據的數量級差別,避免因數據數量級差別較大而產生的誤差:
其中,x代表原始樣本的某維度,xmin代表該維度數據的最小值,xmax代表該維度數據的最大值,x'為樣本歸一化處理后的數據。
進一步地,步驟1.5中所述建立設備的安全等級分類模型通過一對多方式構建分類器svm1,一對一的方式構建svm2,設備的安全狀態為a、b以及c類型,步驟如下:
(1)構建svm1
通過一對多方式構建分類器svm1區分a與非a類,即將a類樣本作為一類,而b類和c類當做另外一類,構建分類器svm1;
(2)構建svm2
為了區分b類和c類,需要建立b類、c類的二分類器,則直接通過一對一的方式構建svm2;
對于任意給定的設備特征向量,首先使用分類器svm1,判斷是屬于a類還是非a類,若是a類,則得到樣本的預測結果a;否則,則繼續使用分類器svm2,判斷是b類還是c類。
進一步地,步驟2.4的具體步驟為將歸一化后的實時數據代入訓練好的兩個svm分類器,若分類器svm1預測y為a類,則預測y的安全等級結果a,否則,將其帶入svm2進一步分類,若分類器svm2預測y為b類,則得到y的安全等級結果為b類,否則,則得到y的安全等級結果為c類。
本發明的設備安全等級分類方法,可以實現:
1.本發明能實時評估、預測設備的安全狀態,方便追蹤設備的健康運行狀況,實時掌握、知曉設備是否存在危險以及危險程度,輔助設備安全運行、提高設備的可靠性。
2.本發明通過smote方法抽樣避免了樣本不平衡問題帶來的分類器模型性能差、甚至無用的問題,克服了傳統的機械復制樣本帶來的過擬合問題,提高了分類器模型的準確率和實用性。
3.本發明建立的安全等級模型為基于多參數的非線性模型,挖掘了設備指標對設備安全性的影響作用,揭示指標與設備安全之間隱含的復雜因果關系和條件關系,從而實現設備的安全等級分類。
4.本發明降低了人工參與力度,人工只集中在前期建立設備安全等級庫,改變了人工跟蹤設備狀態進行評價以實現安全等級分類的方式,一旦完成建模,便,可實時、自動實現設備安全等級評估。
5.本發明采用多次循環抽樣的方法進行樣本抽樣,在數據處理層面進行改進樣本數目,循環方式抽樣相比單次抽樣,能產生更多新的樣本,且更好地平衡樣本之間的不平衡率。
6.本發明構建的安全分類模型為基于支持向量算法建立的非線性模分類模型的,相比神經網絡算法,準確率、泛華能力以及運算速度等方面具有優勢。
附圖說明
圖1為訓練安全分類模型的步驟流程圖
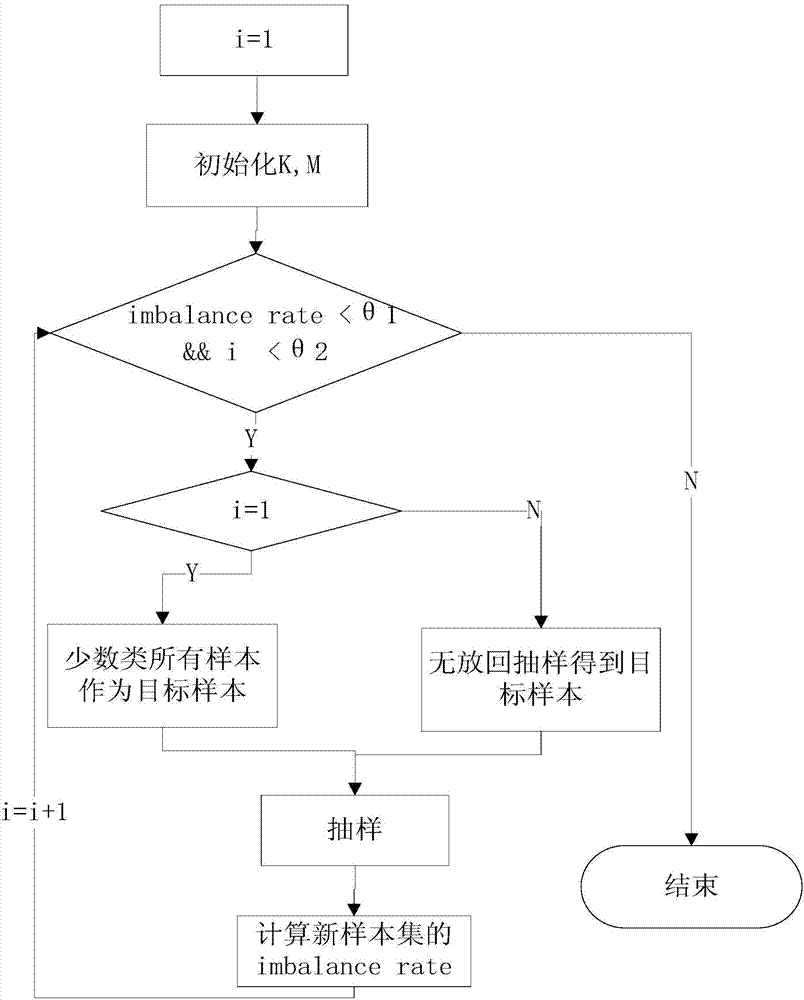
圖2為基于smote的抽樣算法流程圖
圖3為建立多分類器的結構示意圖
圖4為實時預測設備安全等級的流程圖
具體實施方式
下面詳細說明本發明的具體實施,有必要在此指出的是,以下實施只是用于本發明的進一步說明,不能理解為對本發明保護范圍的限制,該領域技術熟練人員根據上述本發明內容對本發明做出的一些非本質的改進和調整,仍然屬于本發明的保護范圍。
本發明是一種實時評估、預測設備安全等級分類的方法,它基于設備歷史數據,結合了smote和svm,建立設備安全等級庫,構建表征設備安全的特征,使用smote循環抽樣的方法改進樣本的不平衡情況,采用svm分類算法建立特征向量與安全等級之間的關系,實現設備的安全分類。該方法主要包括訓練安全分類模型和實時預測設備安全等級兩個過程。
圖1為本發明訓練安全分類模型的流程圖,整個訓練過程主要包括以下步驟:
步驟1:建立設備安全等級庫。
綜合處理設備在不同時間下已有的專家評價結果,得到設備不同工況下的安全等級,從而建立設備安全等級庫。
(1)設定設備安全等級
每個設備的安全等級分為3個類別,安全類別分別為:a類,b類,c類。其中安全級別大小關系為:
a<b<c(1)
a類代表該設備不安全,b類代表該設備處于基本安全狀態,c類代表該設備非常安全。
(2)獲取設備的安全等級
獲取設備在各個時刻下由n個專家評定的安全等級。假設時刻t下,設備的安全等級評價結果如式(2)所示,為安全等級評價向量,其中li代表第i個專家對該設備的評價結果。
l=(l1,l2,...li...ln)(li∈(a,b,c)(2)
為了便于計算,將評價結果轉化為數值形式,建立安全等級和數值間的一一映射關系,即
((a->1),(b->2),(c->3))(3)
(3)標記設備的安全類型
通過如下公式(4)對安全等級評價向量進行計算,將n個專家的評價結果進行平均化并取整,得到時刻t下設備的安全類型數值s',并根據安全等級和數值間的映射關系式(3)得到安全等級標記,然后標記設備在t時刻的安全類型。
其中round函數為對變量進行四舍五入取整。
通過以上過程,標記各個設備在不同時刻下的安全等級,建立設備的安全等級庫。
優選地,設備安全等級分類的方法,采用對專家評價結果平均化的思路,消除不同專家評價結果不一致的現象。
步驟2:選取訓練數據、提取安全特征。
(1)選取訓練數據
查詢設備安全等級庫,選取有安全標記的設備作為研究對象,并獲取相關的歷史數據作為訓練數據。
(2)提取設備安全特征
提取訓練數據的安全特征,構建設備安全特征向量。選取與設備安全運行相關的關鍵參數,通過專家法計算指標,構建表征設備安全的特征空間。t時刻下設備的特征向量為:x=(x1,x2,...xm),其代表m維數指標構成的安全特征。
步驟3:樣本smote。
對提取完特征的訓練數據進行樣本smote抽樣。smote算法的優點是:增加新的不存在的樣本,而非隨機復制樣本,在一定程度上避免分類器過度擬合。對少數類樣本在鄰居樣本中進行線性插值產生新的少數樣本,降低樣本在數量上的不平衡。
圖2為本發明基于smote的抽樣算法流程圖,具體步驟如下:
(1)計算兩類樣本的不平衡率。
計算少數類和多數類樣本的比例,得到樣本的不平衡率imbalancerate,用來衡量樣本的不平衡情況。imbalancerate計算公式如下,num1為少數類樣本數目,num2為多數類樣本數目。
(2)判斷不平衡率是否超過閾值。
設定不平衡率的閾值θ1,判定樣本是否不平衡。若不平衡率大于閾值,說明樣本平衡不需抽樣;否則說明樣本不平衡,需進行抽樣,進行步驟(3)。
優選地,本發明根據設定的樣本不平衡率閾值自動判斷是否進行抽樣,有利于降低人工成本。
(3)對少數類抽樣。
對樣本中的少數類樣本進行smote抽樣。具體方法為:選定少數類樣本中的目標樣本,假定某目標為樣本s,搜索其m近鄰樣本,在近鄰中隨機選擇k個樣本n1,n2,...nk,在樣本s與k個樣本間進行隨機插值,構造如下所示的樣本,作為少數類樣本的新樣本。例如隨機選擇的樣本為ni,則新的樣本yi為:
其中
(4)抽樣結束判斷。
對新的樣本集合采用步驟(1)、步驟(2),計算新樣本集合的不平衡率,并判斷新樣本集合不平衡率是否超閾值。統計抽樣的循環次數,并判斷抽樣次數是否超過閾值θ2。即抽樣結束的條件為:不平衡率超過閾值,且循環次數超過閾值。若滿足以上條件則結束抽樣,否則轉入步驟(3)進行抽樣并不斷循環判斷是否結束抽樣。
優選地,本發明設置了循環進行smote抽樣的設置,根據上一次抽樣的結果,判定是否進行下一次抽樣,使用多次抽樣,有利于產生更多的新樣本,有利于平衡樣本,有利于避免分類器過擬合的風險。
優選地,本發明在對少數類樣本中選擇近鄰與其進行插值時,只搜索與少數類樣本標記相同的樣本作為鄰居樣本,而非搜索所有樣本,目的是避免異類樣本插值帶來的噪聲樣本、“歧義樣本”。
優選地,若第一次抽樣,將少數類中的所有樣本都作為目標樣本,然后進行smote抽樣;非第一次抽樣時,采用無放回抽樣的方式得到目標樣本,有效避免產生重復樣本,且有效避免過多的產生少數類樣本。
步驟4:數據預處理。
對抽樣處理后的樣本進行預處理,本發明中主要的預處理工作為數據集歸一化處理。對于數據集的各個維數數據,歸一化后將數據統一歸一到同一數據范圍內,例如采用如公式(7)所示的方式將數據歸一到[0,1]之間的數。消除不同維數數據的數量級差別,避免因數據數量級差別較大而產生的誤差。
其中,x代表原始樣本的某維度,xmin代表該維度數據的最小值,xmax代表該維度數據的最大值,x'為樣本歸一化處理后的數據。
通過歸一化工作,將訓練數據抽樣后的樣本數據各個維度歸一化到同一數據范圍,便于建立分類模型。
步驟5:訓練安全等級多分類器。
在處理后的訓練數據上建立設備的安全等級分類模型,用來區分設備的安全狀態為a、b以及c類型。由此可見設備的安全等級分類問題屬于多分類問題,因此要建立多分類模型。
支持向量機算法是最基礎的機器學習算法,能有效處理小樣本、非線性等問題,相比神經網路算法,在速度、穩定性以及泛化能力等方面具有優越性。設備安全等級涉及設備的多個指標,指標間關系復雜,由于支持向量機在解復雜問題等方面的一系列的優勢,因此采用支持向量機分類算法來構建分類面,最終實現設備的安全等級分類。
本發明中采用非線性支持向量機分類模型,使用的核函數為高斯核,具體的模型求解和構建過程在本發明中不再詳述。
傳統的svm多分類器構建方法通常有兩種方法:一對多svm分類(one-against-therest),一對一svm分類(one-against-one)。
一對多svm分類方法中:對p類多分類問題,將其中的一類作為一類,其余的p-1類皆看作另外一類,則將p分類問題轉化為二分類問題。
本方法的優點為:訓練的分類器數目少,與類別數目成正比,一般為p個。缺點為:在訓練每個分類器過程中,所有的樣本都要參與分類器的訓練,訓練時間長;除此之外本方法易出現樣本不平衡的情況。
一對一svm分類方法:對p類多分類問題,兩兩組合構建二分類器。該方法的優點為:每個分類器訓練過程中,只有兩類樣本參與,單個分類器的訓練時間短。缺點為:分類器數目多,一般為
由此可見兩種svm解決多分類的方法都存在一定的缺陷,因此為了提高模型的運行效率,本發明中改變了使用傳統的一對多svm分類方法或是一對一svm分類方法的方式,本發明使用兩種方式相互結合的方式,只需要構建兩個分類器,便實現模型訓練功能。本發明中通過一對多方式構建分類器svm1,一對一的方式構建svm2,步驟如下:
(1)構建svm1
由于a類樣本表征與b、c類樣本表征有明顯不同,因此首先構建一個分類器用來區分a類與非a類,通過一對多方式構建分類器svm1區分a與非a類,即將a類樣本作為一類,而b類和c類當做另外一類,構建分類器svm1。
(2)構建svm2
為了區分b類和c類,需要建立b類、c類的二分類器,則直接通過一對一的方式構建svm2。
對于任意給定的設備特征向量,首先使用分類器svm1,判斷是屬于a類還是非a類,若是a類,則得到樣本的預測結果a;否則,則繼續使用分類器svm2,判斷是b類還是c類。
優選地,本發明中采用以上結合一對多、一對一方式的方法實現svm多分類器,既能減少分類器數目,又能降低模型的訓練時間。
傳統的數據處理步驟是先進行數據預處理工作,再進行樣本抽樣。
優選到,本發明先進行數據預處理工作,再進行樣本抽樣。若采用公式(7)對樣本數據預處理,將樣本歸一化到[0,1]范圍后,對樣本進行抽樣,有可能新樣本數據會超出[0,1],需要在新樣本集合上再次進行歸一化,導致了重復工作,因此本發明中先對樣本進行預處理,再進行樣本抽樣工作。
圖4為本發明實時預測設備安全等級的流程圖,實時運行過程包括以下步驟:
步驟1:獲取實時運行數據,提取安全特征。
檢測設備運行,實時獲取設備的實時運行數據。提取實時數據的安全特征向量,y=(y1,y2,...ym),其由m維數指標構成,維數與訓練數據一致。
步驟2:數據預處理。
同訓練數據一樣,對提取完特征的實時運行數據進行相同的歸一化處理工作,采用公式(7)將實時運行數據各個維度的數值進行歸一化。需要特別注意的是,為了保持實時運行數據和訓練數據數值范圍的一致性,各個維度的最大值、最小值統一采用訓練數據歸一化后各個維度的最大值、最小值。
步驟3:使用訓練好的安全等級多分類器,預測實時數據安全等級分類。
將歸一化后的實時數據代入訓練好的兩個svm分類器,若分類器svm1預測y為a類,則預測y的安全等級結果a,否則,將其帶入svm2進一步分類,若分類器svm2預測y為b類,則得到y的安全等級結果為b類,否則,則得到y的安全等級結果為c類。
實施例
本實施例以某火力發電廠7#機組的再熱蒸汽溫度控制為檢測對象。再熱蒸汽溫度控制的安全與否對保證機組安全、有效運行具有重要作用,其相關結構復雜,相關影響因素多,符合本發明所針對的多元非線性、復雜的特點。通過本實施例的詳細闡述,進一步說明本發明的實施過程。
本發明實施例對某電廠再熱蒸汽溫度控制的安全等級分類的步驟如下:
訓練再熱蒸汽溫度控制分類模型的過程:
步驟1:建立再熱蒸汽溫度控制安全等級庫。
綜合處理再熱蒸汽溫度控制已有的專家評價結果,對專家評價結果平均化得到再熱蒸汽溫度控制不同工況下的安全等級標記,共計樣本共4380條,建立再熱蒸汽溫度控制的安全等級庫。
步驟2:選取訓練數據、提取安全特征。
從再熱蒸汽溫度控制安全等級庫中,選取有安全標記的部分樣本作為訓練樣本,隨機選取總樣本的2/3共計22920條作為訓練樣本。與該電廠的再熱蒸汽溫度安全性相關的關鍵參數有60個,例如高溫再熱器出口溫度,過熱器測煙氣擋板輸出,空預期入口煙氣氧量等測點。通過專家知識將測點數據進行加工計算指標得到25維的向量,形成設備的安全特征。
步驟3:對訓練樣本采用smote算法。
對提取特征后的訓練數據進行smote抽樣。其中k=5,m=3,其他閾值參數θ1=0.5,θ2=5。
對于svm1二分類器,用于區分a類和b、c類,a類作為一類,b和c類作為另外一類。對原始樣本集合tsmote抽樣時,要將b類和c類作為一類來處理,抽樣后得到樣本集合t1。
對于svm2二分類器,主要區分b類和c類,對b類和c類樣本上進行smote抽樣。需要注意對b類和c類的原始樣本t抽樣,而非在t1的基礎上進行抽樣,本發明之所以采取此種設計,目的是減輕、避免抽樣帶來的樣本噪聲問題。
由于a類和b、c類有明顯的不同,因此我們重點描述b、c類分類所涉及的工作,樣本抽樣工作亦以b、c類樣本的抽樣工作為主進行描述。b、c類樣本抽樣的具體步驟如下:
(1)分析原始樣本的b、c類樣本,通過使用公式(5)計算得到b、c類樣本的不平衡率imbalancerate=0.11,其中c類樣本為少數類樣本。
(2)判斷樣本是否平衡。imbalancerate小于θ1,則表明樣本存在不平衡,需進行抽樣。
(3)對c類樣本進行抽樣。采用smote算法對c類樣本進行抽樣,計算c類樣本目標樣本的m近鄰,并從m近鄰中選擇符合條件的鄰居進行插值,得到新樣本集合,并計算樣本集合的不平衡率。
其中首次抽樣后的到新樣本集合的不平衡率為imbalancerate=0.33。
(4)抽樣結束判斷。判斷樣本的不平衡率以及抽樣次數均是否符合條件閾值,若不符合則繼續進行循環抽樣。
通過循環抽樣,最終得到新樣本集合t2,計算其平衡率為imbalancerate=0.61,可見其滿足樣本平衡的條件。
步驟4:對訓練數據進行數據預處理工作。
對抽樣后的訓練數據按照公式(7)進行歸一化,將各參數值全部映射到[01]的區間內。
步驟5:訓練安全等級多分類器。
具體的安全等級多分類器的構建參見圖3所示的分類器構建流程圖。建立區分再熱蒸汽溫度安全的分類模型svm1和svm2,其中svm1和svm2分類模型采用高斯核作為核函數。
再熱氣溫控制a類作為一類,b和c類作為一類,對抽樣后樣本t1構建分類器svm1;將b、c類分別作為不同的類,對抽樣后樣本t2構建分類器svm2。
通過以上安全分類器構建,則涵蓋了安全特征與安全分類的復雜關系,可實時地實現預測、評估再熱氣溫控制的安全類型。具體的實時運行過程見實時運行過程的流程圖4。
本發明中為了有效驗證、展示本發明的有效性,從安全等級庫中選擇再熱氣溫控制有安全標記樣本的進行測試。
測試再熱蒸汽溫度控制模型的過程:
測試過程可參照運行過程的流程圖4,測試過程與實時運行最大的不同是,測試樣本具有真實的安全類型標記,可根據模型的預測結果與真實結果對比,統計分類模型的分類準確率。具體過程如下:
步驟1:選取測試數據,提取安全特征。
訓練再熱氣溫控制安全分類模型時使用了有標記樣本的2/3,則使用剩余的1/3樣本共計11460條可作為測試樣本。
對測試樣本采用與訓練樣本相同的處理方式,提取測試樣本的安全特征。樣本的安全特征維數同訓練樣本相同,皆為25維。
步驟2:數據預處理。
對特征提取后的測試樣本進行歸一化處理將數值范圍皆歸一化到[0,1]。
步驟3:預測樣本安全類型。
使用訓練好的再熱氣溫控制安全分類模型,svm1和svm2評估、預測樣本的安全類型。
步驟4:計算分類器的準確率。
通過對比測試樣本的預測安全類標記和真實標記,通過分類器的準確率,包括某一類的分類準確率以及總體測試樣本的分類準確率。分類準確率越高,表明分類器的性能越好。
以下表格展示、對比了不進行抽樣構建分類器的測試結果,以及采用本發明方法的測試結果,結果如表所示。若不進行抽樣,a類和b類樣本的預測準確率均為0%,由此可見所有的測試樣本均被預測為c,這主要是由樣本嚴重不平衡造成的分類器不準確。
本發明中測試得到的a類、b類和c類的準確率分別為97%,92.3%以及94.6%,統計總體樣本的準確率為94.46%,準確率符合業內認可和行業要求。
盡管為了說明的目的,已描述了本發明的示例性實施方式,但是本領域的技術人員將理解,不脫離所附權利要求中公開的發明的范圍和精神的情況下,可以在形式和細節上進行各種修改、添加和替換等的改變,而所有這些改變都應屬于本發明所附權利要求的保護范圍,并且本發明要求保護的產品各個部門和方法中的各個步驟,可以以任意組合的形式組合在一起。因此,對本發明中所公開的實施方式的描述并非為了限制本發明的范圍,而是用于描述本發明。相應地,本發明的范圍不受以上實施方式的限制,而是由權利要求或其等同物進行限定。
- 還沒有人留言評論。精彩留言會獲得點贊!