一種基于深度學習的短文本聚類方法與流程
本發明涉及深度學習和文本挖掘技術領域,尤其涉及一種基于深度學習的短文本聚類方法。
背景技術:
文本聚類是數據挖掘和自然語言處理領域中聚類分析算法的一大主題。隨著因特網的高速普及和信息技術的飛速發展,數據總量越來越龐大,數據之間的關系也變得越來越復雜;同時,又因為社交媒體的發展使得文本數據飛速增長,且通常以短文本的形式出現:比如微博、產品評論以及地理位置信息等,如何準確且快速的從規模龐大的短文本數據集中抽取出有價值的信息成為了一個新的挑戰。
通常的做法是使用文本聚類等方法對短文本信息進行有效的組織,但傳統的聚類算法在文本特征表示方面的做法基本相同,都是通過短文本中每個單詞的詞頻組合成向量的方式來表示每個短文本,這種方式有著很明顯的優點,就是模型簡單,易于構造。但是缺點是并沒有考慮到短文本之間語義上的聯系,使得聚類的效果不理想。
技術實現要素:
本發明的目的在于通過一種基于深度學習的短文本聚類方法,來解決以上背景技術部分提到的問題。
為達此目的,本發明采用以下技術方案:
一種基于深度學習的短文本聚類方法,其包括如下步驟:
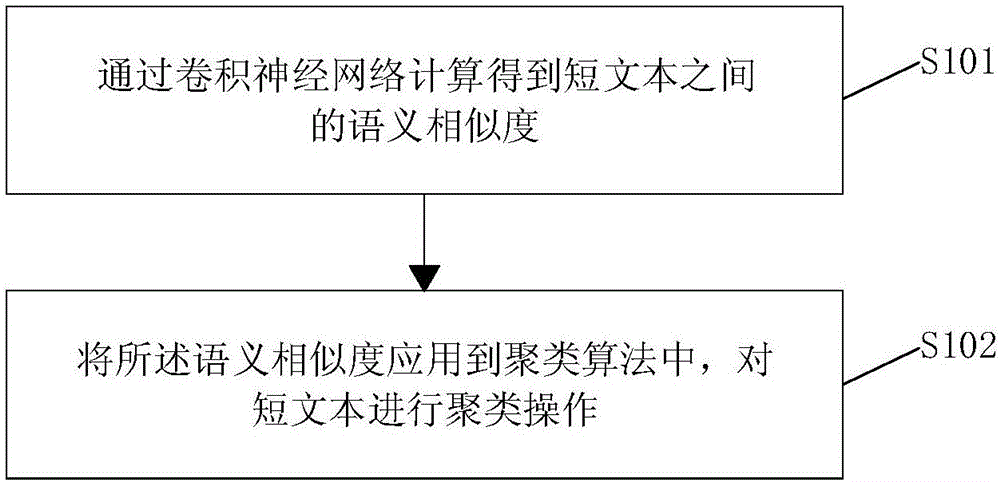
S101、通過卷積神經網絡計算得到短文本之間的語義相似度;
S102、將所述語義相似度應用到聚類算法中,對短文本進行聚類操作。
特別地,所述步驟S101包括:
S1011、選取訓練短文本,短文本的形式是“文本A文本B相似度”;
S1012、從短文本A與短文本B中各抽取連續的K個單詞,并將兩者按照原有的順序組成新的短文本段;獲取所述新的短文本段中每一個詞的詞向量表示并組成映射矩陣;利用所述映射矩陣與相同大小的卷積核進行卷積,獲得一個標量;
S1013、重復執行步驟S1012,完成所有的文本組合以及一維卷積操作;將得到的所有標量按照原有的順序組合起來,形成能夠表達文本A與文本B語義信息的局部特征矩陣;
S1014、對所述局部特征矩陣進行二維池化操作,得到全局特征矩陣;
S1015、對所述全局特征矩陣交替進行二維卷積操作和二維池化操作,并把最終的全局特征矩陣通過一個全連接層變換成一個特征向量;把特征向量輸入到一個多層感知機中,并通過多層感知機的處理輸出兩個文本的語義相似度;
S1016、將通過所述步驟S1011-S1015訓練好的用來計算兩個短文本語義相似度的卷積神經網絡模型存儲到磁盤。
特別地,所述步驟S102包括
S1021、執行聚類算法,選取好聚類中心;將所要進行聚類操作的短文本集合中的每一個短文本與選取好的聚類中心進行兩兩組合得到文本對;從所述磁盤中載入訓練好的卷積神經網絡模型;將組合得到的所述文本對輸入卷積神經網絡模型中,得到文本對中兩個短文本的語義相似度;
S1022、根據獲得的短文本與每個聚類中心的相似度,將短文本分到相似度最高的聚類簇中;
S1023、更新聚類中心,繼續執行步驟S1021-S1022對短文本進行聚類,得到聚類結果。
特別地,所述步驟S102中聚類算法選用K均值聚類算法。
特別地,所述步驟S1012中從短文本A與短文本B中各抽取連續的K個單詞時,對于短的文本采取填充的方式使得兩個文本的長度一致。
特別地,所述步驟S1012中獲取所述新的短文本段中每一個詞的詞向量表示并組成映射矩陣;利用所述映射矩陣與相同大小的卷積核進行卷積,獲得一個標量,具體包括:
對所述新的短文本段,通過查表的方式得到每個詞的詞向量表示,形成映射矩陣,滑動窗口將在兩個文本上進行滑動直至得到所有可能的組合情況;所述映射矩陣的形式如公式(1)的數學表達式所示:
其中,是對短文本x第i個單詞開始與短文本y中第j個單詞開始的連續的k個詞進行組合得到的映射矩陣,Dε表示詞向量的維度;
對于從短文本A中抽取的連續k個單詞和從短文本B中抽取的連續k個單詞組合得到的映射矩陣進行一維形式的卷積操作得到特征值,該特征值是一個單一的標量值。
特別地,所述步驟S1013中將得到的所有標量按照原有的順序組合起來,形成能夠表達文本A與文本B語義信息的局部特征矩陣,具體包括:
將得到的所有的特征值進行組合得到一個能夠表達文本A與文本B語義信息的局部特征矩陣一個局部特征矩陣,該局部特征矩陣的數學計算式如公式(2):
其中,(l,f)表示在第l個卷積層對特征矩陣f進行操作;zi,j(l,f)表示得到的新的特征矩陣,σ()是激活函數,W(l,f)是與等大的卷積核,b(l,f)是偏置項;g(z)是一個閾值函數,當組合的矩陣z都是填充單詞的時候就令g(z)=0,否則g(z)=1。
特別地,所述步驟S1014具體包括:對所述局部特征矩陣按照如下公式(3)進行計算,得到k最大池化之后的全局特征矩陣:
zi,j(l,f)=max({z2i-1,2j-1(l,f),z2i-1,2j(l,f),z2i,2j-1(l,f),z2i,2j(l,f)}) (3)。
特別地,所述步驟S102中所述聚類算法具體包括如下步驟:
讀取短文本數據集,并將其轉化成詞向量的形式,然后存成矩陣的形式;
選取初始聚類中心;
從短文本數據集中選取一個文本;
從聚類中心中選取一個文本;
將兩個文本組合成文本對;
載入基于卷積神經網絡計算文本語義相似度的卷積神經網絡模型;
將文本對輸入所述卷積神經網絡模型中,并計算兩個文本語義上的相似度;
如果相似度大于閾值則將文本放入此聚類中心,并繼續載入所述卷積神經網絡模型,否則繼續選取其余的初始聚類中心,并重復上述操作;
如果程序收斂或達到停止條件則停止程序,否則繼續重復上述操作。
本發明提出的基于深度學習的短文本聚類方法通過卷積神經網絡計算出不同文本之間的語義相似度,并根據計算得出的相似度來進行聚類,提高了現有的短文本聚類準確度,進而能夠更加快速和準確的對海量短文本數據進行聚類分析,可廣泛應用于短文本聚類任務、情感分析、推薦系統等領域,同時本發明利用卷積神經網絡計算短文本相似度部分和短文本聚類部分都不需要對輸入的短文本數據進行預處理,且輸入短文本的長度可以是變長的。
附圖說明
圖1為本發明實施例提供的基于深度學習的短文本聚類方法流程圖;
圖2為本發明實施例提供的用來計算兩個短文本語義相似度的卷積神經網絡模型架構示意圖;
圖3為本發明實施例提供的基于卷積神經網絡計算得到的語義相似度的K均值聚類算法流程圖。
具體實施方式
下面結合附圖和實施例對本發明作進一步說明。可以理解的是,此處所描述的具體實施例僅僅用于解釋本發明,而非對本發明的限定。另外還需要說明的是,為了便于描述,附圖中僅示出了與本發明相關的部分而非全部內容,除非另有定義,本文所使用的所有技術和科學術語與屬于本發明的技術領域的技術人員通常理解的含義相同。本文中所使用的術語只是為了描述具體的實施例,不是旨在于限制本發明。
請參照圖1所示,圖1為本發明實施例提供的基于深度學習的短文本聚類方法流程圖。
本實施例中基于深度學習的短文本聚類方法包括如下步驟:
S101、通過卷積神經網絡計算得到短文本之間的語義相似度。
S102、將所述語義相似度應用到聚類算法中,對短文本進行聚類操作。
下面對步驟S101,S102的具體過程進行詳細說明:
如圖2所示,圖2為本發明實施例提供的用來計算兩個短文本語義相似度的卷積神經網絡模型架構示意圖。
選取訓練短文本,短文本的形式是“文本A文本B相似度”。
在網絡的第一層,由于需要從短文本A與短文本B中各抽取連續的K個單詞,所以就要求短文本A與短文本B的長度相同,為了對兩者順利的進行組合,對于短的文本采取填充的方式使得兩個文本的長度一致即對較短的句子進行填充單詞,直到兩者的單詞數目相等。
接著,對短文本A與短文本B進行組合操作,這里假設詞向量的維度是De。組合的方式是采用類似滑動窗口的形式,分別從兩個短文本A與短文本B中選取連續的k個單詞,并且按照單詞的原有順序組合起來形成新的短文本段。
對新的短文本段,通過查表的方式得到每個詞的詞向量表示,形成映射矩陣,滑動窗口將在兩個文本上進行滑動直到得到所有可能的組合情況。映射矩陣的形式如公式(1)的數學表達式所示:
其中,是對短文本x第i個單詞開始與短文本y中第j個單詞開始的連續的k個詞進行組合得到的映射矩陣,Dε表示詞向量的維度;
對于從短文本A中抽取的連續k個單詞和從短文本B中抽取的連續k個單詞組合得到的映射矩陣進行一維形式的卷積操作得到特征值,該特征值是一個單一的標量值。將得到的所有的特征值進行組合得到一個能夠表達文本A與文本B語義信息的局部特征矩陣一個局部特征矩陣,該局部特征矩陣的數學計算式如公式(2):
其中,(l,f)表示在第l個卷積層對特征矩陣f進行操作;zi,j(l,f)表示得到的新的特征矩陣,σ()是激活函數,W(l,f)是與等大的卷積核,b(l,f)是偏置項;g(z)是一個閾值函數,當組合的矩陣z都是填充單詞的時候就令g(z)=0,否則g(z)=1。
在網絡的第二層,對所述局部特征矩陣按照如下公式(3)進行計算,得到k最大池化之后的全局特征矩陣:
zi,j(2,f)=max({z2i-1,2j-1(2,f),z2i-1,2j(2,f),z2i,2j-1(2,f),z2i,2j(2,f)}) (3)。
通過第一層的一維卷積與第二層的二維池化操作,算法得到了一種兩個文本之間交互信息的低級表示形式,接著把二維池化得到的特征矩陣作為一個圖片的方式來進行處理,就獲得了特征的更高階的表示zi,j,接下來的二維卷積操作的數學計算式可以表示為公式(4)的形式:
其中表示在第l-1層經過二維卷積和二維池化后得到的特征矩陣。比如,在第三層算法接著用大小為k1×k2的卷積核對二維池化操作得到的特征矩陣進行二維卷積操作:
接下來,網絡可以有更多的二維卷積層和二維池化層,并對之前二維池化得到的全局特征矩陣進行操作。
這種逐層交替進行二維卷積和二維池化的操作借鑒了用于圖像處理的卷積神經網絡的思想,相對于傳統的只進行一維卷積得到特征向量的方式,這種做法能夠的保持文本中詞的位置信息,也能更好的保持文本的語義信息。
本實施例中所述聚類算法選用K值聚類算法,如圖3所示,具體包括如下步驟:圖中文本用x表示,聚類中心用C表示。
讀取短文本數據集,并將其轉化成詞向量的形式,然后存成矩陣的形式;
選取初始聚類中心;
從短文本數據集中選取一個文本;
從聚類中心中選取一個文本;
將兩個文本組合成文本對;
載入基于卷積神經網絡計算文本語義相似度的卷積神經網絡模型;
將文本對輸入所述卷積神經網絡模型中,并計算兩個文本語義上的相似度;
如果相似度大于閾值則將文本放入此聚類中心,并繼續載入所述卷積神經網絡模型,否則繼續選取其余的初始聚類中心,并重復上述操作;
如果程序收斂或達到停止條件則停止程序,否則繼續重復上述操作。
對于本實施例中所采用的環境參數和模型參數,說明如下:
本實施例中,所采用的硬件環境為但不限于此:Ubuntu 14、64為操作系統,Intel Core i7處理器、CPU主頻3.5GHz,內存32G,GPU為GTX 980、顯存4G。在所述用于計算短文本對的語義相似度的卷積神經網絡中,卷積層采用的卷積核寬度為3,模型訓練時學習率為λ=0.001。
實驗說明及結果:
本發明的方法可以分為兩個部分,第一個部分是用卷積神經網絡計算不同文本之間語義相似度,第二個部分是把第一部分計算得到的相似度用于文本聚類算法。下面分別對兩個部分用的數據集進行說明。
用卷積神經網絡計算不同文本之間語義相似度這一部分用了兩個不同的短文本數據集對網絡進行訓練,分別是MSRP(Microsoft Research Paraphrase Corpus)數據集和SICK(Sentences Involving Compositional Knowledge)數據集。
MSRP數據集來源于新聞,總共有5801個句子對。其中4076個句子對用于卷積神經網絡模型的訓練,1725個句子對用于模型準確度的測試。每一個句子對都有一個標簽來表征它們的語義相關性:0表示兩個句子不相關,1則表示兩個句子相關。
SICK數據集是對圖片和視頻的文字描述,總共有9927個句子對。其中4500對用于卷積神經網絡模型的訓練,500對用于模型訓練情況的驗證,而剩下的4927對用于模型準確度的測試。由于原數據集用了5種標簽來表征句子對的語義相關性,與本論文提出的卷積神經網絡模型不匹配,故本論文對此數據集進行了預處理,使其標簽與上面相同只用0或1表示相似與否。
文本聚類算法部分用的是StackOverflow數據集。
StackOverflow數據集是一個由Kaggle整理并開源的短文本數據集,總共有20000個句子,可以分為20種不同的類別標簽,每個句子都有一個標簽來表示它所屬的類別。
本發明使用公開的GloVe在大規模語料庫中預先通過無監督的方式訓練好的詞向量。它是在Wikipedia 2014、Gigaword 5數據集上訓練得到的,總共有400000個詞匯,且都已經轉化為小寫的形式,其中詞向量的維度為50維。
為了驗證本發明提出的文本聚類模型在短文本上的聚類效果,本發明實驗分別使用另外2種不同的聚類算法在同一個短文本數據集上進行了聚類操作,并對實驗結果進行對比分析。本發明實驗中采用以下對比聚類方法:
對比方法一:K均值聚類算法,該方法直接在原始特征上采用K均值方法,而原始特征分別采用詞頻(TF)和詞頻-逆文檔頻率(TF-IDF)進行加權。
對比方法二:譜聚類(Spectral Clustering)算法,該算法首先用拉普拉斯映射計算出特征向量,然后把這些特征向量作為聚類中心,并應用K均值方法進行聚類。
實驗對具有20000個短文本的數據集迭代了10次,實驗結果表明,本發明提出的聚類算法的效果比基于TF的K均值算法的聚類效果有著明顯的提升。
綜上所述,本發明的技術方案通過卷積神經網絡計算兩個文本之間語義相似度,并根據計算得出的相似度來進行聚類的方法,在可行性上是可以肯定的。它能夠在一定程度上比較充分的挖掘利用短文本的語義信息,并結合預訓練的詞的語義向量表示對所述短文本進行語義擴展,有效解決短文本在進行語義向量表示時遇到的數據稀疏性和語義敏感性問題,從而改善聚類算法的準確度。
本領域普通技術人員可以理解實現上述實施例方法中的全部或部分流程,是可以通過計算機程序來指令相關的硬件來完成,所述的程序可存儲于一計算機可讀取存儲介質中,該程序在執行時,可包括如上述各方法的實施例的流程。其中,所述的存儲介質可為磁碟、光盤、只讀存儲記憶體(Read-Only Memory,ROM)或隨機存儲記憶體(Random Access Memory,RAM)等。
以上結合具體實施例描述了本發明的技術原理。這些描述只是為了解釋本發明的原理,而不能以任何方式解釋為對本發明保護范圍的限制。基于此處的解釋,本領域的技術人員不需要付出創造性的勞動即可聯想到本發明的其它具體實施方式,這些方式都將落入本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!