文本信息庫建立方法和裝置、以及搜索方法、裝置和系統與流程
本發明涉及人工智能技術領域,具體涉及一種文本信息庫建立方法和裝置、文本信息庫、以及搜索方法、裝置以及系統。
背景技術:
隨著網絡技術和信息技術的不斷發展,很多文本數據都已經上網公開,可供民眾自由查詢。例如,隨著裁判文書的上網公開,民眾也可以很方便的在線查閱歷史裁判文書。對于法院內部來說,法官在判案的過程中,和當前案件相似的已有裁判案例往往有著極高的參考價值,可以基本避免同案不同判的情況的發生。類似案件的裁判查詢對于律師、法官、檢察官、法學教師、學者、學生以及從事法律相關的工作人員等都有重要的參考學習價值。
現有的裁判文書網在線提供了一些搜索方式,但這些搜索方式僅支持案由和關鍵詞等有限的搜索條件,搜索條件有限且簡單,難于進行精準搜索。同時,由于仍需要人工基于個人經驗去尋找判斷搜索結果,搜索效率低下,僅能滿足一般查詢使用,難于滿足律師、法官、檢察官、法學教師、學者、學生以及從事法律相關的工作人員等相對專業的人士的使用要求。由此可見,急需一種可實現智能、高效且精準的搜索的文本信息庫及其建立方式,以及基于這種文本信息庫的搜索方式。
技術實現要素:
有鑒于此,本發明實施例提供了一種文本信息庫建立方法和裝置、文本信息庫、搜索方法、裝置和系統,解決了現有技術中的文本信息難以實現精準搜索以及搜索效率低的問題。
本發明一實施例提供的一種文本信息庫建立方法包括:
提取多個文本數據中的每個所述文本數據所包括的特征因素以及對應的特征因素取值;以及
存儲每個所述文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系。
本發明一實施例提供的一種文本信息庫建立裝置包括:
特征提取模塊,配置為提取多個文本數據中的每個所述文本數據所包括的特征因素以及對應的特征因素取值;以及
存儲模塊,配置為存儲每個所述文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系。
本發明一實施例提供的一種文本信息庫包括:
特征因素信息子庫,配置為存儲多個文本數據中的每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系。
本發明一實施例提供的一種基于如前所述的文本信息庫的搜索方法包括:
識別用戶輸入的搜索信息中的特征信息,其中所述特征信息包括N1個特征因素和N2個特征因素取值,其中N1+N2=N;以及
基于所述特征因素信息子庫,獲取與所識別出的特征信息相對應的文本數據;
其中,N、N1和N2均為大于等于0的整數。
本發明一實施例提供的一種基于如前所述的文本信息庫的搜索裝置包括:
特征識別模塊,配置為識別用戶輸入的搜索信息中的特征信息,其中所述特征信息包括N1個特征因素和N2個特征因素取值,其中N1+N2=N;以及
文本獲取模塊,配置為基于所述特征因素信息子庫,獲取與所識別出的特征信息相對應的文本數據;
其中,N、N1和N2均為大于等于0的整數。
本發明一實施例提供的一種搜索系統包括:
如前所述的文本信息庫以及如前所述的搜索裝置;
其中,所述搜索裝置接受用戶輸入的搜索信息,基于所述文本信息庫獲取與所述用戶輸入的搜索信息相對應的文本數據。
本發明實施例提供的一種文本信息庫建立方法和裝置、文本信息庫、搜索方法、裝置和系統,通過提取文本數據中的特征因素以及特征因素取值,建立起了特征因素和特征因素取值與文本數據之間的對應關系。這樣當用戶輸入搜索信息后,通過識別搜索信息中的特征因素和特征因素取值即可直接確定所對應的文本數據,不需要對所有文本數據的完整文本內容進行搜索,可智能高效的自動完成整個搜索過程,且搜索結果精準,提高了用戶體驗。
附圖說明
圖1所示為本發明一實施例提供的一種文本信息庫建立方法的流程示意圖。
圖2所示為本發明一實施例所提供的文本信息庫建立方法中設置特征因素的權重的流程示意圖。
圖3所示為本發明一實施例所提供的文本信息庫建立方法中提取每個領域分類的文本數據中的領域詞的流程示意圖。
圖4所示為本發明一實施例所提供的文本信息庫的結構示意圖。
圖5所示為基于本發明一實施例所提供的文本信息庫的搜索方法的流程示意圖。
圖6所示為本發明一實施例所提供的搜索方法中獲取與所識別出的特征信息相對應的文本數據的流程示意圖。
圖7所示為本發明一實施例所提供的搜索方法中獲取與所識別出的特征信息相對應的文本數據的流程示意圖。
圖8所示為本發明一實施例所提供的搜索方法的流程示意圖。
圖9所示為本發明一實施例提供的一種文本信息庫建立裝置的結構示意圖。
圖10所示為本發明一實施例提供的一種文本信息庫建立裝置的結構示意圖。
圖11所示為基于本發明一實施例提供文本信息庫的搜索裝置的結構示意圖。
圖12所示為基于本發明一實施例提供文本信息庫的搜索裝置的結構示意圖。
圖13所示為本發明一實施例提供的一種搜索系統的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
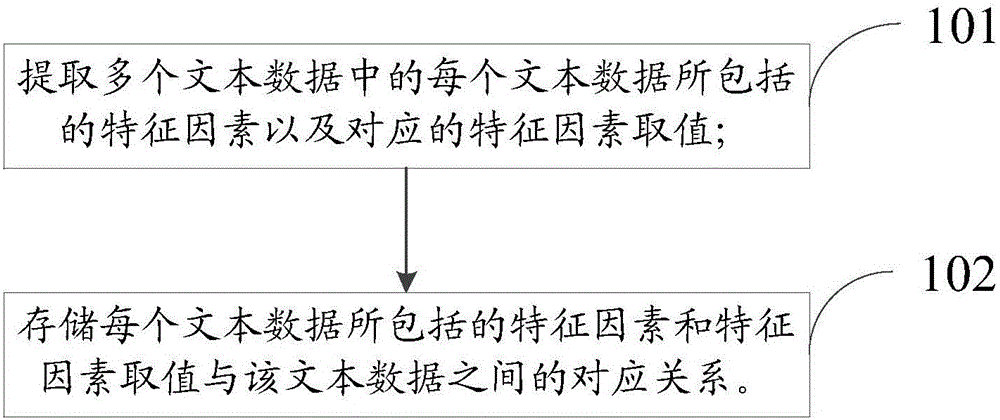
圖1所示為本發明一實施例提供的一種文本信息庫建立方法的流程示意圖。如圖1所示,該文本信息庫建立方法包括如下步驟:
步驟101:提取多個文本數據中的每個文本數據所包括的特征因素以及對應的特征因素取值。
特征因素為用于表征文本數據的特性的標識性信息。例如,當文本數據為裁判文書時,文本數據就可包括以下特征因素中的一種或多種:上訴人/被告姓名、辯護人姓名、辯護人律師事務所、上訴人/被告是否少數民族、上訴人/被告性別、上訴人/被告年齡、當事人出生年月、上訴理由、犯罪情節、犯罪動機、完成形態、犯罪時間、犯罪次數、認罪態度情況、是否如實供述犯罪事實、有無悔罪表現、立功表現、共犯中的犯罪作用、特情引誘、毒品類型、毒品數量、毒品純度、涉案毒資、證人有無主觀意識、對社會危害情況、犯罪事實是否清楚、量刑是否適當、證據是否充分、審判程序是否合法、定罪是否準確、公安機關辦案是否合法、使用法律是否正確和是否維持原判。
應當理解,文本數據的具體內容并不限于裁判文書。同時,根據文本數據的內容不同,所可提取的特征因素的也有所不同,例如當文本數據為專利申請文件時,所可提取的特征因素就可包括“申請日”、“法律狀態”以及“申請人”等專利申請文件的特征信息。本發明對文本數據和特征因素的具體形式不做限定。
特征因素取值為特征因素的具體取值,特征因素取值的具體內容與特征因素本身的含義相關。例如,對于特征因素“毒品類型”,所對應的特征因素取值就可包括“海洛因”、“冰毒”和“大麻”等多種取值;對于特征因素“證人有無主觀意識”,所對應的特征因素取值就可僅包括“是”和“否”兩種取值。特征因素取值的具體內容可以是離散的值也可以是連續的取值區間,例如特征因素“犯罪次數”所對應的取值就可為諸如“初犯”和“再犯”等離散的值,而特征因素“犯罪時間”所對應的取值就可為“2003年11月26日8時至2003年11月26日9時”的取值區間。然而,本發明對特征因素取值的具體內容和形式同樣不做限定。
步驟102:存儲每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系。
由此便形成了存儲有每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系的文本信息庫。通過存儲這種對應關系,使得每個文本數據都可被自身所包括的特征因素和特征因素取值而表征。這樣當基于以上步驟所形成的文本信息庫進行搜索時,通過識別用戶輸入的搜索信息中的特征因素和特征因素取值即可直接確定所對應的文本數據,不需要對所有文本數據的完整文本內容進行搜索,可智能高效的自動完成整個搜索過程,且搜索結果精準,提高了用戶體驗。
在本發明一實施例中,由于文本數據已經利用特征因素和特征因素取值來表征,因此文本數據本身并不一定需要存儲在該文本信息庫中。文本信息庫中可僅存儲所有文本數據的一個列表或索引,以對應這些文本數據在另一個存儲端中的存儲位置。這樣當用戶通過搜索過程獲取到了對應的文本數據時,其實是通過該存儲端獲取到文本數據本身。在本發明另一實施例中,文本數據也可以直接存儲在文本信息庫中。本發明對文本數據本身的存儲位置并不做限定。
基于以上方式所建立的文本信息庫,在根據用戶的搜索信息來搜索文本數據時,其實是將用戶的搜索信息中的特征因素和/或特征因素取值與文本信息庫中不同文本數據的特征因素和/或特征因素取值進行匹配,相似度越高的文本數據則越接近用戶所想要的搜索結果。但由于在文本信息庫建立過程中所提取到的特征因素和特征因素取值有很多,而其中的每個特征因素在體現文本數據的特征時所起到的重要性又有所不同,因此在本發明一實施例中,要在建立文本信息庫時進一步設置并存儲所提取的每個特征因素的權重。這樣權重較低的特征因素及其對應的特征因素取值對于用戶的搜索信息與文本數據之間的相似度貢獻就較少,而權重較高的特征因素及其對應的特征因素取值對于用戶的搜索信息與文本數據之間的相似度貢獻就較大,從而可實現更加智能更加精準的搜索過程。
圖2所示為本發明一實施例所提供的文本信息庫建立方法中設置特征因素的權重的流程示意圖。文本數據進一步包括用于衡量特征因素權重的目標特征信息,如圖2所示,該設置特征因素權重的流程可包括如下步驟:
步驟201:根據多個文本數據各自所包括的目標特征信息將多個文本數據分為多個目標特征分類。
以文本數據為裁判文書為例,目標特征信息就可為裁判文書中的判決結果信息,這樣該目標特征分類的獲取過程其實就是根據判結結果信息的量刑程度將多個文本數據分為多個目標特征分類。
步驟202:統計每個目標特征分類中的文本數據所包括的特征因素以及對應的特征因素取值。
通過該統計過程便可得出每個目標特征分類中所包括的特征因素和特征因素取值,在不同的目標特征分類中可能包括不同的特征因素,出現在多個目標特征分類中的同一個特征因素也可能有不同的特征因素取值。
步驟203:基于統計結果以及多個目標特征分類,通過分類模型計算多個文本數據中所包括的每個特征因素對目標特征信息的影響權重,將該影響權重作為特征因素的權重。
通過向分類模型中輸入該統計結果以及該多個目標特征分類即可得到每個特征因素的權重。例如,當一個特征因素平均地出現在不同目標特征分類中且存在不同取值時,則說明該特征因素的取值變化對于目標特征信息的影響并不大,因此該特征因素的權重就較低。而當一個特征因素的某一個取值集中地出現在某一個目標特征分類時,則說明該特征因素的不同取值會對目標特征信息產生較大影響,因此該特征因素的權重就較高。分類模型可采用softmax分類模型、決策樹分類模型或其他形式的分類模型實現,本發明對分類模型的具體選擇不做限定。
在本發明一實施例中,用于建立文本信息庫的多個文本數據被預先劃分為了至少一個領域分類,那么在建立文本信息庫的同時可進一步提取并存儲每個領域分類的文本數據中的領域詞,以便于在搜索的過程中可通過識別搜索信息中的領域詞而快速地縮小所要搜索的文本數據的范圍,進一步提高搜索效率。
在本發明一實施例中,文本數據為裁判文書,領域分類為案由分類。即,裁判文書預先根據案由的不同被劃分為了至少一個案由分類。該根據案由進行分類的過程一般在法院上網公布裁判文書時就已完成。
圖3所示為本發明一實施例所提供的文本信息庫建立方法中提取每個領域分類的文本數據中的領域詞的流程示意圖。如圖3所示,該提取領域詞的流程可包括如下步驟:
步驟301:基于所接收的多個文本數據獲取通用新詞候選詞串。
在本發明一實施例中,通用新詞候選詞串可采用以下一種或多種方法的結合來獲取:內部構成語法規則方法、前后綴規則方法和特征統計方法。
步驟302:采用統計的方法判斷通用新詞候選詞串是否為領域詞候選詞串。
具體而言,該領域詞候選詞串的判斷過程可包括如下步驟:采用包括通用新詞候選詞串的詞典對所接收的多個文本數據分別進行分詞處理,得到各領域分類的詞語集;計算通用新詞候選詞串在每個領域分類的詞語集中出現的概率,并將最大出現概率對應的領域分類作為該通用新詞候選詞串的目標領域分類;以及計算通用新詞候選詞串在至少部分領域分類的詞語集中分布的信息熵,當信息熵小于或等于信息熵閾值時,通用新詞候選詞串為目標領域分類的領域詞候選詞串。
在本發明一實施例中,信息熵閾值的取值范圍可以為:1.5~2.5,如:1.5、2.0或2.5等。
在本發明一實施例中,設a為通用新詞候選詞串,則該通用新詞候選詞串在至少部分預先設定的領域分類中分布的信息熵H(a)=-p1×log2(p1)-p2×log2(p2)-…-pn×log2(pn),其中,n為至少部分預先設定的領域分類的個數,p1、p2、…、pn為該通用新詞候選詞串a在該n個領域分類的詞語集中的出現概率。
由于垃圾詞串和通用詞均在各個領域分類中出現的頻率相近,而領域詞出現的概率較小,并且領域詞會在不同的領域分類有明顯的偏重,甚至只出現在對應領域分類。本發明實施例根據這一原理,在現有的通用新詞發現方法發現的通用新詞候選詞的基礎上,將得到的通用新詞候選詞串進一步處理,通過計算各個通用新詞候選詞串在所有領域分類中分布上的信息熵,信息熵越大表明該通用新詞候選詞串在各個領域分類上的分布越平衡,反之,表明該通用新詞候選詞串的分布偏重某領域分類。之后,通過確定一個合適的信息熵閾值h過濾掉部分垃圾詞串和通用詞串,若H(a)>h時,則通用新詞候選詞串a為垃圾詞串或通用詞,反之,則通用新詞候選詞串a為對應出現概率最大的領域的領域詞候選詞串,從而篩選出領域詞候選詞串。在一具體實施例中,若H(a)=h,則通用新詞候選詞串a可以為垃圾詞串或通用詞,在另一具體實施例中,若H(a)=h,通用新詞候選詞串a也可以為對應出現概率最大的領域的領域詞候選詞串。
步驟303:當通用新詞候選詞串為領域詞候選詞串時,通過相似度計算判斷領域詞候選詞串是否為領域詞。
具體而言,該領域詞的判斷過程可包括如下步驟:從領域詞候選詞串對應的領域分類的文本數據中選擇全部或部分的其他詞串作為種子詞串;計算領域詞候選詞串與每個種子詞串的相似度;以及當最大相似度大于相似度閾值時,領域詞候選詞串為領域詞。
在本發明一實施例中,上述領域詞候選詞串與種子詞串之間的相似度計算過程可通過word2vec模型實現。具體而言,可將領域詞候選詞串輸入到word2vec模型得到領域詞候選詞串的詞向量,將每個種子詞串輸入到word2vec模型得到相應的每個種子詞串的詞向量,再計算該領域詞候選詞串的詞向量與每個種子詞串的詞向量的之間的語義相似度。
在本發明一實施例中,相似度閾值的取值范圍可以為0.6-0.8,如:0.6、0.7或0.8等。優選的,判定為領域詞的領域詞候選詞串后續也可以作為相應領域的種子詞串,這樣做可以對每個領域分類的語料進行及時的完善。
在本發明一實施例中,由于在領域詞候選詞串的判斷過程中已經通過分詞處理得到了各領域分類的詞語集,因此在領域詞的判斷過程中可直接從領域詞候選詞串對應的領域分類的詞語集中選擇全部或部分的其他詞串作為種子詞串,從而進一步降低了種子詞串選取的工作量,提高了整個領域詞獲取過程的效率。
在本發明一實施例中,在采用統計的方法判斷通用詞候選詞串是否為領域詞候選詞串之前,還要對預先設定的領域分類中的文本數據進行預處理,例如,將預先設定的領域分類中的文本數據的格式統一為文本格式;去除含有敏感詞的文本數據,根據剩余的文本數據料中所含有的斷句標點將剩余的文本數據分割成句。由于已對文本數據統一格式并去除敏感詞和斷句,這樣做便于后續對每個領域的文本數據進行分詞處理,可提高分詞處理的效率和準確率。
由此可見,本發明實施例是先基于統計的思想尋找領域詞候選詞串,而未考慮詞與領域的語義關系;然后為了提高確定領域詞的準確度,再在語義層面進一步篩選出領域詞。即,將利用word2vec模型計算該領域詞候選詞串與某一領域分類的文本數據中的各詞串之間的語義相似度,相似度越大越則越有可能是對應領域分類的領域詞。之后,領域詞逐漸增加,可以逐漸完善領域詞典。
在本發明一實施例中,考慮到用戶輸入的搜索信息中的文本內容可能與文本信息庫中已存儲的特征因素、特征因素取值或領域詞并不完全對應,為了進一步提高搜索結果的準確度,還可在建立文本信息庫時設置并存儲領域詞的同義詞和/或特征因素的同義詞和/或特征因素取值的同義詞。這樣即使搜索信息中的文本內容與文本信息庫中特征因素、特征因素取值或領域詞的不完全對應,只要該文本內容與文本信息庫中的特征因素、特征因素取值或領域詞為同義詞,也可視為匹配到了該特征因素、特征因素取值或領域詞。
應當理解,領域詞的同義詞、特征因素的同義詞或特征因素取值的同義詞可通過人工的方式設置,例如由業務專家根據實際的工作經驗設置文本信息庫中已存儲的領域詞、特征因素和特征因素取值的同義詞,也可采用其他的方式設置。本發明對領域詞的同義詞、特征因素的同義詞以及特征因素取值的同義詞的具體設置方式不做限定。
由此可見,基于以上實施例所述的文本信息庫建立方法,所建立的文本信息庫的結構可如圖4所示。該文本信息庫40可包括:
特征因素信息子庫41,配置為存儲多個文本數據中的每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系。
特征因素權重子庫42,配置為存儲特征因素信息子庫41中每個特征因素的權重。其中,特征因素的權重為特征因素對文本數據中的目標特征信息的影響權重。
領域詞子庫43,配置為存儲至少一個領域分類中每個領域分類的領域詞。其中,用于建立文本信息庫40的多個文本數據被預先劃分為了該至少一個領域分類。
同義詞子庫44,配置為存儲領域詞的同義詞和/或特征因素的同義詞和/或特征因素取值的同義詞。
在本發明一實施例中,文本數據為裁判文書,目標特征信息為判決結果信息,領域分類為案由分類。文本數據可包括以下特征因素中的一種或多種:上訴人/被告姓名、辯護人姓名、辯護人律師事務所、上訴人/被告是否少數民族、上訴人/被告性別、上訴人/被告年齡、當事人出生年月、上訴理由、犯罪情節、犯罪動機、完成形態、犯罪時間、犯罪次數、認罪態度情況、是否如實供述犯罪事實、有無悔罪表現、立功表現、共犯中的犯罪作用、特情引誘、毒品類型、毒品數量、毒品純度、涉案毒資、證人有無主觀意識、對社會危害情況、犯罪事實是否清楚、量刑是否適當、證據是否充分、審判程序是否合法、定罪是否準確、公安機關辦案是否合法、使用法律是否正確和是否維持原判。
基于如圖4所示的文本信息庫40,即可實現智能精準的搜索體驗。具體而言,特征因素信息子庫41的存在使得每個文本數據都可被自身所包括的特征因素和特征因素取值而表征。這樣通過識別用戶輸入的搜索信息中的特征因素和特征因素取值即可直接確定所對應的文本數據,不需要對所有文本數據的完整文本內容進行搜索,可智能高效的自動完成整個搜索過程,且搜索結果精準,提高了用戶體驗。特征因素權重子庫42的存在使得權重較高的特征因素及其特征因素取值可對搜索過程中的相似度計算起到較大的影響作用,從而使得搜索結果更加精準且智能。領域詞子庫43的存在使得在搜索的過程中可通過識別搜索信息中的領域詞而快速地縮小所要搜索的文本數據的范圍,進一步提高搜索效率。同義詞子庫44的存在使得用戶的搜索信息實現了在語義上的擴展,避免了漏檢的情況發生,進一步提高搜索結果的準確度。
但應當理解,盡管在圖4所示的實施例中,文本信息庫40同時具備了特征因素信息子庫41、特征因素權重子庫42、領域詞子庫43以及同義詞子庫44,但其實特征因素信息子庫41、特征因素權重子庫42、領域詞子庫43以及同義詞子庫44之間并不存在依存關系。例如在本發明一實施例中,文本數據的內容比較單一且并不存在領域分類時,所建立的文本信息庫40中就可不包括領域詞子庫43。即,文本信息庫40中具體包括哪些子庫可根據具體的業務場景需求而定,本發明對文本信息庫40中具體包括哪些子庫并不做限定。
圖5所示為基于本發明一實施例所提供的文本信息庫的搜索方法的流程示意圖。該文本信息庫中包括特征因素信息子庫,如圖5所示,該搜索方法可包括如下步驟:
步驟501:識別用戶輸入的搜索信息中的特征信息,其中特征信息包括N1個特征因素和N2個特征因素取值,其中N1+N2=N,N、N1和N2均為大于等于0的整數。
用戶輸入的搜索信息中可能并不完整的包括特征因素及其對應的特征因素取值,例如對于特征因素“毒品類型”,用戶的搜索條件可能就僅為“海洛因”,而并不會刻意地包括“毒品類型”四個字。再例如,用戶輸入的搜索信息為“毒品數量50g海洛因”,那么該搜索信息中就包括了1個特征因素“毒品數量”以及兩個特征因素取值“50g”和“海洛因”。
識別的具體過程可基于特征因素信息子庫實現,例如,以特征因素信息子庫中所包括的特征因素和特征因素取值為識別目標,以字符串匹配的方式識別搜索信息中所包括的特征因素和特征因素取值。
步驟502:基于特征因素信息子庫,獲取與所識別出的特征信息相對應的文本數據。
由于文本信息庫中包括了特征因素信息子庫,而該特征因素信息子庫中又存儲有每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系,因此根據所識別出的特征信息中所包括的特征因素以及特征因素取值便可直接確定匹配的文本數據。
具體而言,如圖6所示,與所識別出的特征信息相對應的文本數據可通過如下步驟獲取:
步驟5021:計算特征因素信息子庫中的M個文本數據各自在特征信息所包括的N1個特征因素和N2個特征因素取值上與特征信息之間的N個特征相似度,其中M為大于等于1的整數。
根據搜索信息所識別出的特征信息中包括N1個特征因素和N2個特征因素取值,因此就要計算文本信息庫中的文本數據在該N1個特征因素和N2個特征因素取值上分別與搜索信息之間的N個特征相似度。
步驟5022:根據M個文本數據各自對應的N個特征相似度確定搜索信息與M個文本數據之間的M個搜索相似度。
由于該N個特征相似度僅為在分立的特征因素和特征因素取值上的相似度,為了獲取搜索信息與文本數據之間的搜索相似度,就需要將這N個特征相似度進行整合。例如,將一個文本數據與搜索信息的特征信息之間的N個特征相似度求平均值,將該平均值作為該文本數據與搜索信息之間的搜索相似度。
步驟5023:將M個文本數據按照M個搜索相似度排序并將排序結果呈現給用戶。
在本發明一實施例中,可按照相似度從高到低的順序呈現文本數據,條目較多時還可支持分頁展示。在一進一步實施例中,每個條目可直接鏈接至文本數據本身。同時該呈現頁面還可支持接收用戶的評價反饋,并根據反饋智能調優。
在本發明一實施例中,文本信息庫進一步包括特征因素權重子庫,特征因素權重子庫中存儲有特征因素信息子庫中每個特征因素的權重。此時,如圖7所示,與所識別出的特征信息相對應的文本數據就可通過如下步驟獲取:
步驟5020:基于特征因素權重子庫獲取所識別出的N1個特征因素的權重以及N2個特征因素取值所分別對應的N2個特征因素的權重。
步驟5021’:計算特征因素信息子庫中的M個文本數據各自在特征信息所包括N1個特征因素和N2個特征因素取值上與特征信息之間的N個特征相似度,其中M為大于等于1的整數。
步驟5022’:基于所獲取的特征因素的權重以及M個文本數據各自對應的N個特征相似度,以加權求和的方式計算出搜索信息與M個文本數據之間的M個搜索相似度。
由于每個特征因素的權重不同,因此在將M個文本數據各自對應的N個特征相似度整合成M個搜索相似度時就要將權重計算進去,例如以加權求和的方式。
步驟5023’:將M個文本數據按照M個搜索相似度排序并將排序結果呈現給用戶。
通過采用這樣的搜索方式,可使得權重較高的特征因素及其特征因素取值可對搜索過程中的相似度計算起到較大的影響作用,從而使得搜索結果更加精準且智能。
在本發明一實施例中,用于建立文本信息庫的多個文本數據被預先劃分為至少一個領域分類,文本信息庫進一步包括了領域詞子庫,領域詞子庫存儲有該至少一個領域分類中每個領域分類的領域詞。此時,如圖8所示,該搜索方法可包括如下步驟:
步驟500:基于領域詞子庫中所包括的領域詞,對搜索信息進行分詞處理,識別搜索信息中的領域詞。
步驟501’:識別用戶輸入的搜索信息中的特征信息,其中特征信息包括N1個特征因素和N2個特征因素取值,其中N1+N2=N,N、N1和N2均為大于等于0的整數。
步驟502’:基于特征因素信息子庫,在識別出的領域詞所對應的領域分類所包括的文本數據中,獲取與所識別出的特征信息相對應的文本數據。
這樣在根據搜索信息來搜索文本信息庫中所涉及到的文本數據時,搜索的范圍就被縮小到了所識別出的領域詞所對應的領域分類的文本數據中,從而減少了整個搜索過程的工作量,進一步提高了搜索效率。
在本發明一實施例中,文本信息庫進一步包括同義詞子庫,同義詞子庫存儲有領域詞的同義詞和/或特征因素的同義詞和/或特征因素取值的同義詞。這樣在識別用戶輸入的搜索信息中的特征信息時,若搜索信息中所包括的特征因素和/或特征因素取值在同義詞子庫中存在同義詞,則可將同義詞也作為識別出的特征因素和/或特征因素取值,由此實現了搜索信息在語義上的擴展,避免了漏檢的情況發生。
同時,在計算特征因素信息子庫中的M個文本數據各自在特征信息所包括N1個特征因素和N2個特征因素取值上與特征信息之間的N個特征相似度時,若識別出的一個特征因素或特征因素取值與特征因素信息子庫中一個文本數據的一個特征因素或特征因素取值屬于同義詞,則直接認為該文本數據在該識別出的特征因素或特征因素取值上的特征相似度為100%。這樣即使搜索信息中的特征因素或特征因素取值與文本數據中的特征因素或特征因素取值不完全對應,只要二者屬于同義詞子庫中的同義詞,就認為在該特征因素或特征因素取值上搜索信息與該文本數據的相似度為100%,由此避免了漏檢的情況發生。
此外,若識別出的領域詞在同義詞子庫中存在同義詞,則基于特征因素信息子庫,在識別出的領域詞以及該同義詞所對應的領域分類所包括的文本數據中,獲取與所識別出的特征信息相對應的文本數據。由于領域詞子庫的建立過程可能存在的局限性,雖然領域詞A和領域詞B對應了不同的領域分類,但其實這些領域分類可能僅是因為領域詞的形式不同而被劃分為了不同的領域分類,這種情況下領域詞A和領域詞B很可能屬于同義詞。通過基于包括領域詞的同義詞的同義詞子庫進行上述搜索步驟,可實現領域分類在語義上的擴展,進一步避免了漏檢的情況發生。
圖9所示為本發明一實施例提供的一種文本信息庫建立裝置的結構示意圖。如圖9所示,該文本信息庫建立裝置90包括:特征提取模塊91和存儲模塊92。特征提取模塊91配置為提取多個文本數據中的每個文本數據所包括的特征因素以及對應的特征因素取值。存儲模塊92配置為存儲每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系。
通過該文本信息庫建立裝置90便形成了存儲有每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系的文本信息庫。通過存儲這種對應關系,使得每個文本數據都可被自身所包括的特征因素和特征因素取值而表征。這樣當基于以上步驟所形成的文本信息庫進行搜索時,通過識別用戶輸入的搜索信息中的特征因素和特征因素取值即可直接確定所對應的文本數據,不需要對所有文本數據的完整文本內容進行搜索,可智能高效的自動完成整個搜索過程,且搜索結果精準,提高了用戶體驗。
在本發明一實施例中,如圖10所示,該文本信息庫建立裝置90可進一步包括:權重設置模塊93,配置為設置所提取的每個特征因素的權重;其中,存儲模塊92進一步配置為存儲所提取的每個特征因素的權重。通過設置每個特征因素的權重,使得權重較高的特征因素及其特征因素取值可對搜索過程中的相似度計算起到較大的影響作用,從而使得搜索結果更加精準且智能。
在本發明一實施例中,文本數據可包括目標特征信息,如圖10所示,權重設置模塊93可包括:分類單元931、統計單元932以及權重獲取單元933。分類單元931配置為根據多個文本數據各自所包括的目標特征信息將多個文本數據分為多個目標特征分類。統計單元932配置為統計每個目標特征分類中的文本數據所包括的特征因素以及對應的特征因素取值。權重獲取單元933配置為基于統計單元932的統計結果以及分類單元931的分類結果,通過分類模型計算多個文本數據中所包括的每個特征因素對目標特征信息的影響權重,將該影響權重作為特征因素的權重。
在本發明一實施例中,文本數據可為裁判文書,目標特征信息可為判決結果信息;其中,分類單元931可進一步配置為根據多個文本數據各自所包括的目標特征信息將多個文本數據分為多個目標特征分類。
在本發明一實施例中,文本數據可包括以下特征因素中的一種或多種:上訴人/被告姓名、辯護人姓名、辯護人律師事務所、上訴人/被告是否少數民族、上訴人/被告性別、上訴人/被告年齡、當事人出生年月、上訴理由、犯罪情節、犯罪動機、完成形態、犯罪時間、犯罪次數、認罪態度情況、是否如實供述犯罪事實、有無悔罪表現、立功表現、共犯中的犯罪作用、特情引誘、毒品類型、毒品數量、毒品純度、涉案毒資、證人有無主觀意識、對社會危害情況、犯罪事實是否清楚、量刑是否適當、證據是否充分、審判程序是否合法、定罪是否準確、公安機關辦案是否合法、使用法律是否正確和是否維持原判。
在本發明一實施例中,多個文本數據預先劃分為至少一個領域分類。如圖10所示,該文本信息庫建立裝置90可進一步包括:領域詞提取模塊94,配置為提取每個領域分類的文本數據中的領域詞;其中,存儲模塊92進一步配置為存儲所提取的每個領域分類的領域詞。通過提取各領域分類的領域詞,使得在搜索的過程中可通過識別搜索信息中的領域詞而快速地縮小所要搜索的文本數據的范圍,進一步提高搜索效率。
在本發明一實施例中,如圖10所示,領域詞提取模塊94包括:通用新詞獲取單元941、第一判斷單元942以及第二判斷單元943。通用新詞獲取單元941配置為基于所接收的多個文本數據獲取通用新詞候選詞串。第一判斷單元942配置為采用統計的方法判斷通用新詞候選詞串是否為領域詞候選詞串。第二判斷單元943配置為當通用新詞候選詞串為領域詞候選詞串時,通過相似度計算判斷領域詞候選詞串是否為領域詞。
在本發明一實施例中,通用新詞獲取單元941可采用以下一種或多種方法的結合來獲取通用新詞候選詞串:內部構成語法規則方法、前后綴規則方法和特征統計方法。在本發明一實施例中,第一判斷單元942可包括:分詞子單元、目標領域獲取子單元以及第一判定子單元。分詞子單元配置為采用包括通用新詞候選詞串的詞典對所接收的多個文本數據分別進行分詞處理,得到各領域分類的詞語集。目標領域獲取子單元配置為計算通用新詞候選詞串在每個領域分類的詞語集中出現的概率,并將最大出現概率對應的領域分類作為該通用新詞候選詞串的目標領域分類。第一判定子單元配置為計算通用新詞候選詞串在至少部分領域分類的詞語集中分布的信息熵,當信息熵小于或等于信息熵閾值時,通用新詞候選詞串為目標領域分類的領域詞候選詞串。
由于垃圾詞串和通用詞均在各個領域分類中出現的頻率相近,而領域詞出現的概率較小,并且領域詞會在不同的領域分類有明顯的偏重,甚至只出現在對應領域分類。本發明實施例根據這一原理,在現有的通用新詞發現方法發現的通用新詞候選詞的基礎上,將得到的通用新詞候選詞串進一步處理,通過計算各個通用新詞候選詞串在所有領域分類中分布上的信息熵,信息熵越大表明該通用新詞候選詞串在各個領域分類上的分布越平衡,反之,表明該通用新詞候選詞串的分布偏重某領域分類。之后,通過確定一個合適的信息熵閾值h過濾掉部分垃圾詞串和通用詞串,若H(a)>h時,則通用新詞候選詞串a為垃圾詞串或通用詞,反之,則通用新詞候選詞串a為對應出現概率最大的領域的領域詞候選詞串,從而篩選出領域詞候選詞串。在一具體實施例中,若H(a)=h,則通用新詞候選詞串a可以為垃圾詞串或通用詞,在另一具體實施例中,若H(a)=h,通用新詞候選詞串a也可以為對應出現概率最大的領域的領域詞候選詞串。
在本發明一實施例中,第二判斷單元943可包括:種子詞獲取子單元、相似度計算子單元以及第二判定子單元。種子詞獲取子單元配置為從領域詞候選詞串對應的領域分類的詞語集中選擇全部或部分的其他詞串作為種子詞串。相似度計算子單元配置為計算領域詞候選詞串與每個種子詞串的相似度。第二判定子單元配置為當最大相似度大于相似度閾值時,領域詞候選詞串為領域詞。
在本發明另一實施例中,第二判斷單元943可包括:種子詞獲取子單元、相似度計算子單元以及第二判定子單元。種子詞獲取子單元配置為從領域詞候選詞串對應的領域分類的文本數據中選擇全部或部分的其他詞串作為種子詞串。相似度計算子單元配置為計算領域詞候選詞串與每個種子詞串的相似度。第二判定子單元配置為當最大相似度大于相似度閾值時,領域詞候選詞串為領域詞。
由此可見,本發明實施例所提供的領域詞提取模塊94是先基于統計的思想尋找領域詞候選詞串,而未考慮詞與領域的語義關系;然后為了提高確定領域詞的準確度,再在語義層面進一步篩選出領域詞。即,將利用word2vec模型計算該領域詞候選詞串與某一領域分類的文本數據中的各詞串之間的語義相似度,相似度越大越則越有可能是對應領域分類的領域詞。之后,領域詞逐漸增加,可以逐漸完善領域詞典。
在本發明一實施例中,種子詞獲取子單元可進一步配置為,將判定為領域詞的領域詞候選詞串也作為相應領域的種子詞串,這樣可以對每個領域分類的語料進行及時的完善。
在本發明一實施例中,如圖10所示,該文本信息庫建立裝置90可進一步包括:同義詞設置模塊95,配置為設置并通過存儲模塊92存儲領域詞的同義詞和/或特征因素的同義詞和/或特征因素取值的同義詞。這樣所建立的文本信息庫,即使搜索信息中的文本內容與文本信息庫中特征因素、特征因素取值或領域詞的不完全對應,只要該文本內容與文本信息庫中的特征因素、特征因素取值或領域詞為同義詞,也可視為匹配到了該特征因素、特征因素取值或領域詞,進一步提高了所建立的文本信息庫的搜索結果的準確度。
在本發明一實施例中,文本數據可為裁判文書,領域分類可為案由分類。
圖11所示為基于本發明一實施例提供文本信息庫的搜索裝置的結構示意圖。如圖11所示,該搜索裝置110包括:特征識別模塊111和文本獲取模塊112。特征識別模塊111配置為識別用戶輸入的搜索信息中的特征信息,其中特征信息包括N1個特征因素和N2個特征因素取值,其中N1+N2=N,N、N1和N2均為大于等于0的整數。文本獲取模塊112配置為基于特征因素信息子庫,獲取與所識別出的特征信息相對應的文本數據。
由于文本信息庫中包括了特征因素信息子庫,而該特征因素信息子庫中又存儲有每個文本數據所包括的特征因素和特征因素取值與該文本數據之間的對應關系,因此根據所識別出的特征信息中所包括的特征因素以及特征因素取值便可直接確定匹配的文本數據。
在本發明一實施例中,特征識別模塊111進一步配置為,以特征因素信息子庫中所包括的特征因素和特征因素取值為識別目標,以字符串匹配的方式識別搜索信息中所包括的特征因素和特征因素取值。
在本發明一實施例中,如圖12所示,文本獲取模塊112包括:特征相似度計算單元1121、搜索相似度計算單元1122以及返回單元1123。特征相似度計算單元1121配置為計算特征因素信息子庫中的M個文本數據各自在特征信息所包括的N1個特征因素和N2個特征因素取值上與特征信息之間的N個特征相似度,其中M為大于等于1的整數。搜索相似度計算單元1122配置為根據M個文本數據各自對應的N個特征相似度確定搜索信息與M個文本數據之間的M個搜索相似度。返回單元1123配置為將M個文本數據按照M個搜索相似度排序并將排序結果呈現給用戶。
在本發明一實施例中,文本信息庫包括特征因素權重子庫,特征因素權重子庫配置為存儲特征因素信息子庫中每個特征因素的權重。此時,如圖12所示,文本獲取模塊112包括:權重識別單元1120、特征相似度計算單元1121、搜索相似度計算單元1122以及返回單元1123。權重識別單元1120配置為基于特征因素權重子庫獲取所識別出的N1個特征因素的權重以及N2個特征因素取值所分別對應的N2個特征因素的權重。特征相似度計算單元1121配置為計算特征因素信息子庫中的M個文本數據各自在特征信息所包括N1個特征因素和N2個特征因素取值上與特征信息之間的N個特征相似度,其中M為大于等于1的整數。搜索相似度計算單元1122配置為基于所獲取的特征因素的權重以及M個文本數據各自對應的N個特征相似度,以加權求和的方式計算出搜索信息與M個文本數據之間的M個搜索相似度。返回單元1123配置為將M個文本數據按照M個搜索相似度排序并將排序結果呈現給用戶。通過采用這樣的搜索方式,可使得權重較高的特征因素及其特征因素取值可對搜索過程中的相似度計算起到較大的影響作用,從而使得搜索結果更加精準且智能。
在本發明一實施例中,多個文本數據預先劃分為至少一個領域分類,文本信息庫包括領域詞子庫,領域詞子庫配置為存儲至少一個領域分類中每個領域分類的領域詞。此時,如圖12所示,該搜索裝置110進一步包括:領域詞識別模塊113,配置為基于領域詞子庫中所包括的領域詞,對搜索信息進行分詞處理,識別搜索信息中的領域詞。其中,文本獲取模塊112進一步配置為:基于特征因素信息子庫,在識別出的領域詞所對應的領域分類所包括的文本數據中,獲取與所識別出的特征信息相對應的文本數據。這樣在根據搜索信息來搜索文本信息庫中所涉及到的文本數據時,搜索的范圍就被縮小到了所識別出的領域詞所對應的領域分類的文本數據中,從而減少了整個搜索過程的工作量,進一步提高了搜索效率。
在本發明一實施例中,文本信息庫包括同義詞子庫,同義詞子庫配置為存儲領域詞的同義詞和/或特征因素的同義詞和/或特征因素取值的同義詞。此時,特征識別模塊111進一步配置為,若搜索信息中所包括的特征因素和/或特征因素取值在同義詞子庫中存在同義詞,則將同義詞也作為識別出的特征因素和/或特征因素取值。這樣在識別用戶輸入的搜索信息中的特征信息時,若搜索信息中所包括的特征因素和/或特征因素取值在同義詞子庫中存在同義詞,則可將同義詞也作為識別出的特征因素和/或特征因素取值,由此實現了搜索信息在語義上的擴展,避免了漏檢的情況發生。
同時,特征相似度計算單元1121可進一步配置為:若特征識別模塊111識別出的一個特征因素或特征因素取值與特征因素信息子庫中一個文本數據的一個特征因素或特征因素取值屬于同義詞,則直接認為該文本數據在該識別出的特征因素或特征因素取值上的特征相似度為100%。這樣即使搜索信息中的特征因素或特征因素取值與文本數據中的特征因素或特征因素取值不完全對應,只要二者屬于同義詞子庫中的同義詞,就認為在該特征因素或特征因素取值上搜索信息與該文本數據的相似度為100%,由此避免了漏檢的情況發生。
此外,文本獲取模塊112進一步配置為:若領域詞識別模塊113識別出的領域詞在同義詞子庫中存在同義詞,則基于特征因素信息子庫,在領域詞識別模塊113識別出的領域詞以及該同義詞所對應的領域分類所包括的文本數據中,獲取與所識別出的特征信息相對應的文本數據。由于領域詞子庫的建立過程可能存在的局限性,雖然領域詞A和領域詞B對應了不同的領域分類,但其實這些領域分類可能僅是因為領域詞的形式不同而被劃分為了不同的領域分類,這種情況下領域詞A和領域詞B很可能屬于同義詞。通過采用基于同義詞子庫的文本獲取模塊112,可實現領域分類在語義上的擴展,進一步避免了漏檢的情況發生。
應當理解,上述實施例所提供的文本信息庫建立裝置90或搜索裝置110中記載的每個模塊或單元都與前述的一個方法步驟相對應。由此,前述的方法步驟描述的操作和特征同樣適用于文本信息庫建立裝置90或搜索裝置110及其中所包含的對應的模塊和單元,重復的內容在此不再贅述。
本發明的教導還可以實現為一種計算機可讀存儲介質的計算機程序產品,包括計算機程序代碼,當計算機程序代碼由處理器執行時,其使得處理器能夠按照本發明實施方式的方法來實現如本文實施方式所述的文本信息庫建立方法或搜索方法。計算機存儲介質可以為任何有形媒介,例如軟盤、CD-ROM、DVD、硬盤驅動器、甚至網絡介質等。
應當理解,雖然以上描述了本發明實施方式的一種實現形式可以是計算機程序產品,但是本發明的實施方式的方法或裝置可以被依軟件、硬件、或者軟件和硬件的結合來實現。硬件部分可以利用專用邏輯來實現;軟件部分可以存儲在存儲器中,由適當的指令執行系統,例如微處理器或者專用設計硬件來執行。本領域的普通技術人員可以理解上述的方法和設備可以使用計算機可執行指令和/或包含在處理器控制代碼中來實現,例如在諸如磁盤、CD或DVD-ROM的載體介質、諸如只讀存儲器(固件)的可編程的存儲器或者諸如光學或電子信號載體的數據載體上提供了這樣的代碼。本發明的方法和裝置可以由諸如超大規模集成電路或門陣列、諸如邏輯芯片、晶體管等的半導體、或者諸如現場可編程門陣列、可編程邏輯設備等的可編程硬件設備的硬件電路實現,也可以用由各種類型的處理器執行的軟件實現,也可以由上述硬件電路和軟件的結合例如固件來實現。
應當理解,盡管在上文的詳細描述中提及了裝置的若干模塊或單元,但是這種劃分僅僅是示例性而非強制性的。實際上,根據本發明的示例性實施方式,上文描述的兩個或更多模塊/單元的特征和功能可以在一個模塊/單元中實現,反之,上文描述的一個模塊/單元的特征和功能可以進一步劃分為由多個模塊/單元來實現。此外,上文描述的某些模塊/單元在某些應用場景下可被省略。
圖13所示為本發明一實施例提供的一種搜索系統的結構示意圖。如圖13所示,該搜索系統包括如圖4所示的文本信息庫以及如圖12所示的搜索裝置。其中,搜索裝置接受用戶輸入的搜索信息,基于文本信息庫獲取與用戶輸入的搜索信息相對應的文本數據。
應當理解,由于文本信息庫中具體包括哪些子庫可根據具體的業務場景需求而定,因此該搜索系統中的文本信息庫并不限定于圖4所示的文本信息庫。同時,搜索裝置也可根據文本信息庫的變化而調整,也并不限于圖12所示的搜索裝置。本發明對此不做限定。
應當理解,為了不模糊本發明的實施方式,說明書僅對一些關鍵、未必必要的技術和特征進行了描述,而可能未對一些本領域技術人員能夠實現的特征做出說明。
以上所述僅為本發明的較佳實施例而已,并不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!