基于灰理論的電影個性化推薦方法與流程
本發明涉及個性化推薦
技術領域:
,特別涉及一種基于灰理論的電影個性化推薦方法。
背景技術:
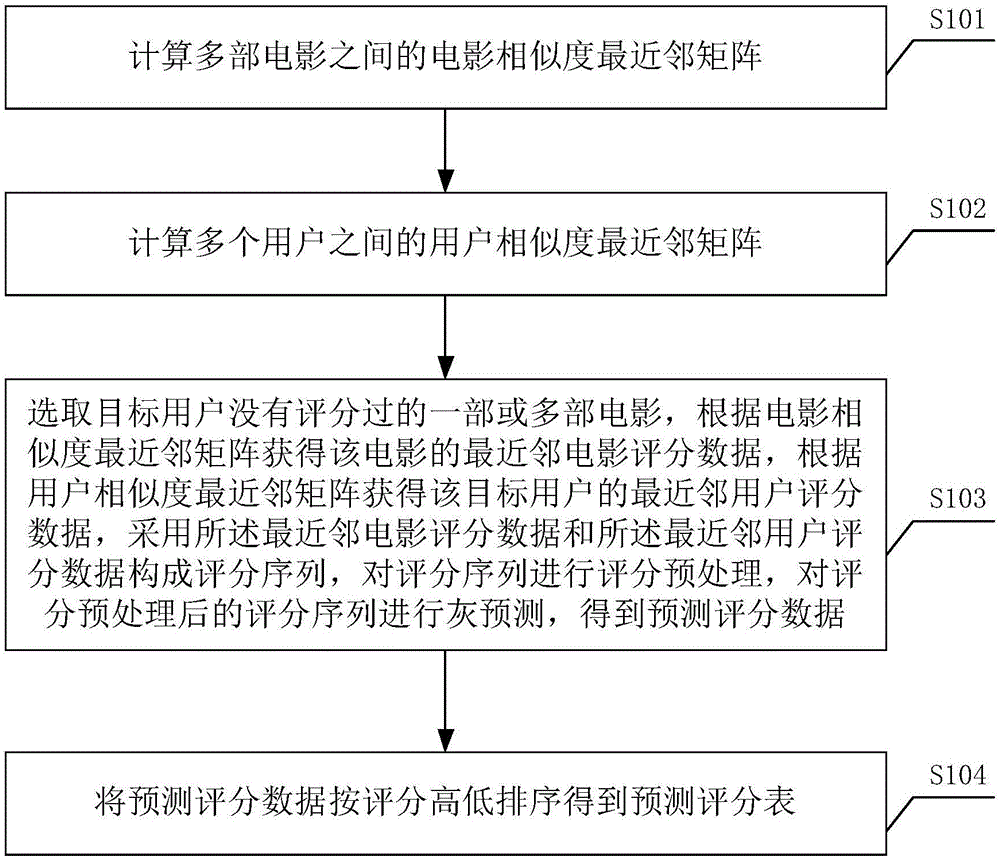
:個性化推薦系統是一種建立在海量數據挖掘基礎上的高級商務智能平臺,它能夠幫助網站從已知的信息中提煉出對用戶有價值的信息,為用戶提供完全個性化的決策支持和信息服務。基于物品的推薦方法是個性化推薦方法的一個重要研究方向。該方法的基本原理是,若同時喜歡A物品的多個用戶也都喜歡B物品,則將B物品推薦給同樣喜歡A物品的其他用戶。該方法需要將共同喜歡同一物品的用戶偏好生成物品最近鄰矩陣部分以計算物品相似度,同時根據用戶偏好生成預測評分部分以計算物品列表,區分物品推薦優先度。因而,選擇恰當的相似度計算方法和預測模型對于物品推薦的準確性就顯得極其重要。相比基于用戶的推薦方法,物品推薦方法處理用戶信息表的工作量小,計算過程也較為容易。基于物品的相似度計算方法主要有三種:Jaccard公式,余弦相似性和Pearson相關系數。Jaccard公式針對矩陣特征屬性值為空的情況,無法發揮出所有特征屬性的價值,使得最終得到的推薦結果不精確;而Pearson相關系數和余弦相似性都只能解決特征屬性值至少有一個不為空的情況,無法計算特征屬性值全為空的情況,使得推薦的結果無法實現多樣性。近年來,陸續有學者提出了一些提高相似度計算結果的方法。針對精確度不高的問題,GaoM等將灰預測模型引入了算法中(參見文獻GaoM,FuY,ChenY,etal.User-WeightModelforItem-basedRecommendationSystems[J].JournalofSoftware,2012,7(9).);LiD等則從算法單獨依賴評分數據的局限性問題入手,提出了一個新的相似性函數,該函數為每個不同的目標項目選擇不同的鄰居(參見文獻LiD,LvQ,ShangL,etal.Item-basedtop-Nrecommendationresilienttoaggregatedinformationrevelation[J].Knowledge-BasedSystems,2014,67(3):290–304.);ChoiK等又從數據稀疏問題著手,提出了基于Bhattacharyya系數的相似性度量稀疏數據,該方法基于鄰域進行相似性度量,所有的評分均由一對用戶產生(參見文獻ChoiK,SuhY.Anewsimilarityfunctionforselectingneighborsforeachtargetitemincollaborativefiltering[J].Knowledge-BasedSystems,2013,37(2):146–153.);此外,ElbadrawyA等結合項目相似度模型FSM捕捉項目和因子模型,了解全球偏好模式之間局部關系的優點,對協同因子FSM模型和非合作用戶建模(參見文獻ElbadrawyA,KarypisG.User-SpecificFeature-BasedSimilarityModelsforTop-nRecommendationofNewItems[J].AcmTransactionsonIntelligentSystems&Technology,2015,9(21).)。但是上述新的計算方法在相似度的計算方面都沒有考慮到矩陣特征屬性值部分為空或者全部為空的情況。當物品的特征屬性值比較稀疏的時候,只是考慮不為空的特征屬性值,往往忽略了為空的屬性特征值所發揮的價值,這樣就會使計算得到的相似度誤差過大,導致推薦的結果不夠精確。技術實現要素:本發明的目的在于解決上述評分數據的稀疏性和現有算法單獨依賴評分數據導致推薦精確度不高的問題,提出一種基于灰理論的電影個性化推薦方法,使得電影推薦的結果更符合用戶的期望。本發明一種基于灰理論的電影個性化推薦方法,從預測評分表中選擇評分高的至少一部電影,所述預測評分表通過以下方式獲取:S101、計算多部電影之間的電影相似度最近鄰矩陣;S102、計算多個用戶之間的用戶相似度最近鄰矩陣;S103、選取目標用戶沒有評分過的一部或多部電影,根據電影相似度最近鄰矩陣獲得該電影的最近鄰電影評分數據,根據用戶相似度最近鄰矩陣獲得該目標用戶的最近鄰用戶評分數據,采用所述最近鄰電影評分數據和所述最近鄰用戶評分數據構成評分序列,對評分序列進行評分預處理,對評分預處理后的評分序列進行灰預測,得到預測評分數據;S104、將預測評分數據按評分高低排序得到預測評分表。本發明一種基于灰理論的電影個性化推薦方法,從預測評分表中選擇評分高的至少一部電影,所述預測評分表通過以下方式獲取:S201、計算多部電影之間的電影相似度最近鄰矩陣;S202、選取目標用戶沒有評分過的一部或多部電影,根據電影相似度最近鄰矩陣獲得該電影的最近鄰電影評分數據,采用所述最近鄰電影評分數據構成評分序列,對評分序列進行評分預處理,對評分預處理后的評分序列進行灰預測,得到預測評分數據;S203、將預測評分數據按評分高低排序得到預測評分表。本發明一種基于灰理論的電影個性化推薦方法,從預測評分表中選擇評分高的至少一部電影,所述預測評分表通過以下方式獲取:S301、計算多個用戶之間的用戶相似度最近鄰矩陣;S302、選取目標用戶沒有評分過的一部或多部電影,根據用戶相似度最近鄰矩陣獲得該目標用戶的最近鄰用戶評分數據,采用所述最近鄰用戶評分數據構成評分序列,對評分序列進行評分預處理,對評分預處理后的評分序列進行灰預測,得到預測評分數據;S303、將預測評分數據按評分高低排序得到預測評分表。優選地,所述對評分預處理后的評分序列進行灰預測包括對預處理后的評分序列用GM(1,1)預測模型進行評分預測,得到預測評分數據,具體包括:X1={X1(1),X1(2),…X1(n)}X(1)(t+1)=(X(0)(1)-u1/a)e-a1t+b/a其中,X0={X0(1),X0(2),…X0(n)}為預處理后的評分序列,a為灰色發展系數,b為灰輸入,n為評分序列所含評分個數。本發明在計算電影相似度的時候,采用灰色關聯度分析方法,對其中電影特征屬性值為零的數據充分的利用。本發明在計算用戶相似度的時候,采用灰色關聯度分析方法,對其中用戶屬性值為零的數據充分的利用。另一個方面,本發明在評分預處理的時候,對評分序列中存在為空值的評分進行填充,填充充分利用用戶之間的相似度;在目標物品的最近鄰為零的時候采用了循環查找,彌補了其他算法直接設為零的不足;對預處理后的評分序列用GM(1,1)預測模型進行評分預測。本發明利于利用數據稀疏性提高了電影推薦的精準度。附圖說明圖1為本發明基于灰理論的電影個性化推薦方法第一優選實施例流程示意圖;圖2為本發明基于灰理論的電影個性化推薦方法第二優選實施例流程示意圖;圖3為本發明基于灰理論的電影個性化推薦方法第三優選實施例流程示意圖;圖4為本發明基于灰理論的電影個性化推薦方法與現有技術對比仿真分析示意圖;具體實施方式下面結合具體實施例以及附圖對本發明基于灰理論的電影個性化推薦方法作進一步闡述。作為其中一種可實現方式,本發明一種基于灰理論的電影個性化推薦方法,從預測評分表中選擇評分高的至少一部電影,其中,如圖1所示,所述預測評分表通過以下方式獲取:S101、計算多部電影之間的電影相似度最近鄰矩陣;S102、計算多個用戶之間的用戶相似度最近鄰矩陣;S103、選取目標用戶沒有評分過的一部或多部電影,根據電影相似度最近鄰矩陣獲得該電影的最近鄰電影評分數據,根據用戶相似度最近鄰矩陣獲得該目標用戶的最近鄰用戶評分數據,采用所述最近鄰電影評分數據和所述最近鄰用戶評分數據構成評分序列,對評分序列進行評分預處理,對評分預處理后的評分序列進行灰預測,得到預測評分數據;S104、將預測評分數據按評分高低排序得到預測評分表。作為另一種可選實施方式,本發明一種基于灰理論的電影個性化推薦方法,還可以采用如下方式實現,從預測評分表中選擇評分高的至少一部電影,其中,如圖2所示,所述預測評分表通過以下方式獲取S201、計算多部電影之間的電影相似度最近鄰矩陣;S202、選取目標用戶沒有評分過的一部或多部電影,根據電影相似度最近鄰矩陣獲得該電影的最近鄰電影評分數據,采用所述最近鄰電影評分數據構成評分序列,對評分序列進行評分預處理,對評分預處理后的評分序列進行灰預測,得到預測評分數據;S203、將預測評分數據按評分高低排序得到預測評分表。作為另一種可選實施方式,本發明一種基于灰理論的電影個性化推薦方法,還可以采用如下方式實現,從預測評分表中選擇評分高的至少一部電影,其中,如圖3所示,所述預測評分表通過以下方式獲取S301、計算多個用戶之間的用戶相似度最近鄰矩陣;S302、選取目標用戶沒有評分過的一部或多部電影,根據用戶相似度最近鄰矩陣獲得該目標用戶的最近鄰用戶評分數據,采用所述最近鄰用戶評分數據構成評分序列,對評分序列進行評分預處理,對評分預處理后的評分序列進行灰預測,得到預測評分數據;S303、將預測評分數據按評分高低排序得到預測評分表。以上幾個實施例之間存在相同步驟(標號可能不同),以下對這些步驟的描述適用于上述所有實施例,為避免贅述,對相同步驟所描述的實施例可以相互引證。所述計算多部電影之間的電影相似度最近鄰矩陣,包括根據電影特征屬性,采用灰色關聯度分析方法計算多個電影之間的電影相似度,選取電影相似度最高的部分電影ID生成電影最近鄰矩陣;所述電影特征屬性是指每個電影所屬的電影類型,如表1所示,對于ID為1的電影,其電影特征屬性序列為(1,1,1,0,0),1表示該電影屬于該類型,0表示該電影不屬于該類型;表1電影特征屬性表電影ID恐怖片劇情片喜劇片動作片111002011031101……………n0101所述采用灰色關聯度分析方法計算多個電影之間的電影相似度包括利用灰色關聯度分析方法計算多部電影特征屬性之間的相似度構成電影相似度,具體包括:S101-1、根據電影特征屬性,采用灰色關聯度分析方法計算多部電影之間的電影相似度;S101-2、根據多部電影特征屬性之間的相似度尋找目標電影的最近鄰電影;S101-3、根據目標電影的最近鄰電影生成目標電影的最近鄰電影矩陣。本發明目標用戶是指通過本推薦方法向其推薦電影的用戶;對于多部電影特征屬性之間的相似度的計算,已有較多現有技術有記載,例如,字鳳芹等2016年在《軟件導刊》第15期提出了通過余弦相似度和KNN算法找到適合的電影的方法,其采用余弦公式計算多部電影特征屬性之間的相似度;朱明2014年在《中國科學技術大學》提出了采用基于Jaccard距離的動態時間規整(DynamicTimeWaring,DTW)度量方法的相似度計算方法,其采用Jaccard公式計算多部電影特征屬性之間的相似度;孔維梁2013年在《華中師范大學》提出了修正的Pearson相關系數,進一步提高了相似度的準確性,其采用Pearson相關系數計算多部電影特征屬性之間的相似度。而作為本發明創新點之一,本發明采用灰色關聯度分析方法計算多部電影特征屬性之間的相似度,所述灰色關聯度分析是指在系統發展過程中,如果兩個因素變化的態勢是一致的,即同步變化程度較高,則可以認為兩者關聯較大;反之,則兩者關聯度較小。本發明所述灰色關聯度分析方法計算如下:設兩部電影特征屬性構成的序列分別為x07和xi8,x07={x07(1),x07(2),...x07(m7)}為電影特征屬性參考序列,xi8={xi8(1),xi8(2),...,xi8(m7)},為電影特征屬性比較序列m7為電影特征屬性序列中所包含的電影特征屬性個數。灰色關聯度定義如下:其中,是兩個序列的最大差,為兩個序列的最小差,1≤k1≤m7,07和i8為電影序列號,ρ7為分辨系數,ρ7∈[0,1],優選地ρ7=0.5。所述電影相似度是指利用上述灰色關聯度分析方法計算得到的電影之間的相似度,如表2所示:表2電影相似度目標電影ID相似電影ID相似度130.8792790.675………n10.783所述選取電影相似度最高的部分電影ID生成電影最近鄰矩陣是:利用表2中的電影相似度,分別設置每個電影ID為目標電影,找到與該目標電影之間的相似度最高的Nc1部(優選10部)電影,這Nc1部電影即就是目標電影的最近鄰電影。根據目標電影的最近鄰電影得到生成目標電影的最近鄰電影矩陣,如表3所示:表3電影相似度最近鄰矩陣電影ID最近鄰ID1最近鄰ID2最近鄰ID3最近鄰ID4…最近鄰ID101511209…3824161819…7638211722…n…………………n10321245…9所述計算多個用戶之間的用戶相似度最近鄰矩陣,包括根據用戶信息,采用灰色關聯度分析方法計算多個用戶之間的用戶相似度,選取用戶相似度最高的部分用戶ID生成用戶相似度最近鄰矩陣;所述用戶信息是用于描述用戶的特征信息,例如年齡、職業、地區、性別等等,如表4所示,對于ID為1的用戶,其用戶序列為(1,20,1,0,0);表4用戶信息表用戶ID年齡職業地區性別1201002431310……………m341291將用戶信息數字化,將用戶的每個特征信息用數字替代,例如年齡,則按照用戶的真實年齡填充;例如職業,每個職業對應一個唯一相應的數字;例如地區,每個地區對應一個唯一相應的數字;例如性別,每種性別對應一個唯一相應的數字;S102-1’、根據用戶信息,采用灰色關聯度分析方法計算多個用戶之間的用戶相似度;S102-2’、根據多個用戶之間的用戶相似度尋找目標用戶的最近鄰用戶;S102-3’、根據目標用戶的最近鄰用戶生成目標用戶的最近鄰用戶矩陣。對于多個用戶之間的用戶相似度的計算,已有較多現有技術有記載,例如,高虎明,趙鳳躍2015年在《現代圖書情報技術》第31期提出項目熱度計算方法并對Pearson相關系數算法進行改進,建立當前用戶與其鄰居的興趣模型,對鄰居用戶進行過濾,由最終得到的可信鄰居對當前用戶進行推薦,用改進的Pearson相關系數計算多個用戶之間的用戶相似度;陳孝文2013年在《華南理工大學》提出一種基于社交網絡的協同過濾推薦算法(SNCF),用一種融合Jaccard系數規范化歐氏距離方法(JNED)來計算多個用戶之間的用戶相似度;任看看、錢雪忠2015年在《計算機工程》第41期提出一種新的用戶相似性度量方法,該方法采用結合修正公式改進的Jaccard相似性系數計算多個用戶之間的用戶相似度。而本發明采用灰色關聯度分析方法計算多個用戶之間的用戶相似度,所述灰色關聯度分析是指在系統發展過程中,如果兩個因素變化的態勢是一致的,即同步變化程度較高,則可以認為兩者關聯較大;反之,則兩者關聯度較小。本發明所述灰色關聯度分析方法計算如下:設兩個用戶的用戶信息序列分別為xs和xj,xs={xs(1),xs(2),...xs(m0)}為用戶信息參考序列,xj={xj(1),xj(2),...,xj(m0)}為用戶信息比較序列,m0為用戶信息序列中所包含的用戶信息條數。灰色關聯度定義如下:其中,是兩個序列的最大差,為兩個序列的最小差,1≤k2≤m0,s和j為用戶序列號,ρt為分辨系數,ρt∈[0,1],優選地ρt=0.5。所述用戶相似度是指利用上述灰色關聯度分析方法計算得到的用戶之間的相似度,如表5所示:表5用戶相似度用戶ID用戶ID相似度130.8792790.675………n10.783所述選取用戶相似度最高的部分用戶ID生成用戶最近鄰矩陣是:利用表2中的用戶相似度,分別設置每個用戶ID為目標用戶,找到與該目標用戶之間的相似度最高的Nc2個(優選10個)用戶,這Nc2個用戶即就是目標用戶的最近鄰用戶。根據目標用戶的最近鄰用戶得到生成目標用戶的最近鄰用戶矩陣,如表6所示:表6用戶相似度最近鄰矩陣用戶ID最近鄰ID1最近鄰ID2最近鄰ID3最近鄰ID4…最近鄰ID101511209…3824161819…7638211722…n…………………n10321245…9所述計算多個用戶之間的用戶相似度最近鄰矩陣,包括根據用戶信息,采用灰色關聯度分析方法計算多個用戶之間的用戶相似度,選取用戶相似度最高的部分用戶ID生成用戶相似度最近鄰矩陣;所述選取目標用戶沒有評分過的一個或多個電影,如表7中,假設用戶ID為2的用戶為目標用戶,目標用戶沒有給出評分的電影ID為1、3、4(因為這些電影ID沒有評分記錄)表7用戶評分信息表用戶ID1(電影ID)2(電影ID)3(電影ID)4(電影ID)…n(電影ID)1425…320…233141……………………m21…3所述根據電影相似度最近鄰矩陣獲得目標用戶沒有評分過電影的最近鄰電影評分數據。目標用戶沒有給出評分的電影ID為1、3、4;首先通過表3尋找電影ID為1的電影的最近鄰電影為(5,11,20,9,...,38),接下來通過表7尋找目標用戶對電影ID為(5,11,20,9,...,38)電影的評分值,得到電影評分(2,,4,5,0,...,1)。目標用戶對于電影ID為3、4的最近鄰電影的評分如上述方法可得到;所述根據用戶相似度最近鄰矩陣獲得該目標用戶的最近鄰用戶對目標用戶未評分電影的評分數據。如,目標用戶的ID為2,通過表6查找用戶ID為2的用戶的最近鄰用戶為(3,15,17,18,...,74),接下來通過表7尋找用戶ID為(3,15,17,18,...,74)的用戶對電影ID為1,3,4電影的評分,對于用戶ID為(3,15,17,18,...,74)的用戶對電影ID為1的電影的評分為(3,0,1,,...,5),目標用戶的最近鄰用戶對于電影ID為3,4的最近老電影的評分如上述方法可得到。所述分別針對目標用戶沒有評分過電影依次將所述最近鄰電影評分數據與所述最近鄰用戶評分數據構成評分序列。如,目標用戶的ID為2,則目標用戶沒有給出評分的電影ID為1,3,4。對于電影ID為1的電影,其最近鄰電影評分數據為(2,,4,5,0,...,1),其最近鄰用戶評分數據為(3,0,1,,...,5),構成的評分序列為(2,,4,5,0,...,1,3,0,1,,...,5)。電影ID為3,4的其評分序列按照上述方法可以得到。所述對評分序列進行評分預處理包括對評分序列中存在為空值的評分進行填充。例如,在上述步驟中獲得的目標用戶沒有給出評分的電影ID為1的評分序列為(2,,4,5,0,...,1,3,0,1,,...,5),則對該評分序列進行評分預處理包括對評分序列中存在為空值的評分進行填充。同樣,電影ID為3,4的評分序列按照下述方法做同樣處理。現有的方法中,對評分序列中存在為空值的評分,一般用零進行填充。當全部用零進行填充時,完全忽略了為空的屬性特征值所發揮的價值,這樣就會使計算得到的相似度誤差過大,導致推薦的結果不夠精確。而本發明采用以下方式進行填充:步驟1:檢查評分序列中是否存在空值的電影評分值。步驟2:對于評分序列中為空的電影評分值,計算其電影評分值;通過公式(3)得到電影評分值。特別地,當用公式(3)得到的電影評分值仍為空時,用當前電影的最近鄰電影的最近鄰電影評分進行替代,如此迭代Nc3次(優選3次)。步驟3:循環步驟(1)-(2),直到評分序列中的電影評分值全不為空。as為電影ys的最近鄰電影,Ris,ys為用戶is對電影ys的評分,為用戶is的最近鄰用戶as對電影ys的評分,sim(as,is)為用戶as和用戶is的灰色關聯度計算的相似度。Ms為ID為is用戶的最近鄰用戶集合。步驟4:得到預處理后的評分序列如:假設用戶ID為2的用戶為目標用戶,目標用戶沒有給出評分的電影ID為1、3、4,通過表6查找ID為2的用戶的最近鄰用戶為(3,15,17,18,...,74);通過表3查找ID為1的電影的最近鄰電影(5,11,20,9,…,38)。通過表7查找用戶ID為(3,15,17,18,...,74)對電影ID為1的電影評分和用戶ID為2的用戶對電影ID為(5,11,20,9,…,38)的電影評分構成的評分序列為(3,0,1,,...,5,2,,4,5,0,...,1)。上述步驟1:此評分序列中存在兩個空值的電影評分值;上述步驟2:對于第一個空值的電影評分值是ID為18的用戶對電影ID為1的電影評分;第二個空值的電影評分值是ID為2的用戶對電影ID為11的電影評分。對于第一個空值的電影評分值:公式(3)中的i為ID為18的用戶,y為ID為1的電影,如果利用公式(3)得到的評分仍為空值,則公式(3)中的M為ID為a用戶的最近鄰用戶的最近鄰用戶的集合。假設最終得到的預處理后的評分序列為(2,0,4,5,0,...,1,3,0,1,,...,5);對評分預處理后的評分序列進行處理存在不同,如現有的方法對預處理后的評分序列進行評分預測是通過對該序列中的評分求均值或者是加權平均得到預測評分;而本發明對評分預處理后的評分序列進行灰預測,即對預處理后的評分序列用GM(1,1)預測模型進行評分預測,得到預測評分數據,也即是說,將上述得到的所有評分序列輸入GM(1,1)預測模型得到相應的預測評分;所述GM(1,1)預測模型進行評分預測,包括:步驟1:設預處理后的評分序列為:其中,k為預處理后的評分序列中的評分個數;步驟2:將處理后的評分序列通過公式(6),(7)得到其累加序列(5):其中,Δt1=t(1),Δti=t(i)-t(i-1),i=2,...,k步驟3:建立灰色微分模型GM(1.1)如下:其中,a,b分別為系數,a為灰色發展系數,b為灰輸入,a,b的值在步驟5給出;是灰色背景數,它的值是連續的序列的總和;步驟4:將上述公式(8)表示如下:步驟5:從步驟4得到的解決方案為:a和b和步驟3中的有相同的定義,v=(a,b)T=(BTB)-1BTY步驟6:將上述得到的參數輸入以下公式,得到預測評分:為檢驗本發明效果,將本發明與現有技術進行對比實驗。為驗證本發明算法,將本發明方法與現有IBC、CBC算法在三個數據集上進行驗證。PRM-Grey是本文提出的算法。IBC是現有的基于電影的協同過濾算法,通過Pearson相關系數計算電影之間的相似度,該方法根據用戶對目標電影的最近鄰電影的評分產生預測評分,然后將評分降序排序,選擇top(n)輸出。CBC同樣也是現有的基于電影的協同過濾算法,該算法通過Cosine相似度來計算電影之間的相似度。該方法根據用戶對目標電影的最近鄰電影的評分產生預測評分,然后將評分降序排序,選擇top(n)輸出。比較和參考以往個性化推薦系統的評價指標,本文在每個數據集上分別進行三個指標的比較:精確度Precision,表示系統檢測到的相關文件數/系統返回的文件總數,其值越高代表算法推薦結果越準確;召回率Recall,表示系統檢測到的相關文件數/相關文件總數,其值越高代表算法推薦結果得覆蓋率越高;宏平均F-Measure,P為精確度,R為召回率,β=1,其值越高代表推薦算法的性能越好。本實驗所采用的數據集如下表:表8數據集詳情數據集表屬性個數記錄數稀疏度GroupLens_MovieLensmovieUser361,265movieType191,623rating32,811,98393.70%Ml-latesttags365,527movie1930,107rating321,622,18899.69%links330,107EachMovie52,811,98397.17%其中,三個數據集分別為:GroupLens_MovieLens評分數據集:包含10w條評分記錄,該數據主要有三個表組成,用戶信息表(用戶ID,年齡,職業);電影所屬類型(電影ID等17個不同的類型,如果屬于此類型,則用1表示,否則用0表示);電影評分表(用戶ID,電影ID,評分,評分從0到5的整數)。Ml-latest數據集:包含了21622187條評分記錄,該數據主要有四個表組成,鏈接表(電影ID,ImdbID(電影標示符),TmdbID(用戶標示符));電影信息表(電影ID,主題,類型);評分信息表(用戶ID,電影ID,評分,時間);標簽信息表(用戶ID,電影ID,標簽,時間)。EachMovie數據集:包含了2,811,983條評分記錄,該數據有一個表組成,鏈接表(PersonID,MovieID,Rating,Weight,TimeStamp)。經過比較,得出驗證的數據見表9所示,將表9中數據用柱狀圖表示如圖4所示。表9不同算法比較從圖4和表9可以得出:在精確度上,本發明的PRM-Grey算法要比IBC和CBC兩種算法在三個數據集上都要高;在召回率上,本發明的PRM-Grey算法在MovieLens數據集上比IBC和CBC兩種算法低,但是在其他的兩個數據集上本發明的PRM-Grey算法要比IBC和CBC兩種算法高;在F-Measure指標上本發明的PRM-Grey算法在三個數據集上要比IBC和CBC兩種算法都要高。但F-Measure指標是推薦算法的綜合指標,其指標越高表示推薦算法的性能越好。綜上所述,本發明PRM-Grey算法的F-Measure指標要比其他兩種算法在上述三種數據集上高,所以說明本發明PRM-Grey算法的性能在上述三個數據集上優于IBC和CBC兩種算法。以上所舉實施例,對本發明的目的、技術方案和優點進行了進一步的詳細說明,所應理解的是,以上所舉實施例僅為本發明的優選實施方式而已,并不用以限制本發明,凡在本發明的精神和原則之內對本發明所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1