一種基于瀏覽器的高性能用戶追蹤方法與流程
本發明屬于信息收集技術領域,尤其涉及一種基于瀏覽器的高性能用戶追蹤方法。
背景技術:
隨著用戶隱私安全意識越來越高,以及Cookie暴漏的安全問題也隨之增長,用戶通過安裝插件或者禁用Cookie等方法來保護個人隱私。Canvas指紋技術是雖然能有效的追蹤一個用戶,由于Canvas渲染技術是基于用戶的硬件設備,所以該技術有一個很高的碰撞率。對于一些惡意攻擊者,通過VPS或者其他加密代理的方式來隱藏自己的信息,使得追蹤和識別變得更加困難。傳統的分析日志的方式只能對攻擊事件進行分析,并不能有效的追蹤惡意攻擊者,用戶的追蹤和識別依舊非常艱難。EFF提出的Browser Fingerprint指紋識別技術能夠有效且唯一地識別用戶的瀏覽器特征信息,但是在追蹤用戶方便并不高效。
技術實現要素:
本發明要解決的技術問題是,提供一種基于瀏覽器的高性能用戶追蹤方法。
為解決上述問題,本發明采用如下的技術方案:
一種基于瀏覽器的高性能用戶追蹤方法包括以下步驟:
步驟1、獲取用戶瀏覽器特征信息,生成相應的Fingerprint指紋值,并將所述用戶瀏覽器特征信息以及相應的Fingerprint指紋值發送到相應的后臺服務器;
步驟S2、根據所述用戶瀏覽器特征信息以及相應的Fingerprint指紋值,依據策略性指紋識別方法對得到的相應數據進行關聯處理;
步驟S3、將關聯后的用戶客戶端信息存儲到Redis數據庫,使用過濾識別方式對新的指紋數據進行處理,判定兩個指紋信息是否相關聯。
作為優選,用戶瀏覽器特征的信息包括瀏覽器本身的特征信息以及瀏覽器所在終端的信息;瀏覽器本身的特征信息包括:瀏覽器UA、語言Language、使用字體Font、安裝插件Plugins、Cookie和Canvas信息、瀏覽器所屬的平臺Platform、HTML5的本地存儲機制Local_stroage和Session_stroage、是否允許追蹤Do Not Track等;瀏覽器所在終端的信息包括:公網和內網IP;色彩深度Color_depth;時區Time_zone;屏幕分辨率Resolution等。
作為優選,步驟S2中通過fingerprint值、cookie和canvas、內網IP和外網IP三組唯一標識用戶的方式來對指紋信息進行關聯性的比對判斷。
作為優選,步驟S3中,當出現新的指紋信息,先將其與redis數據庫中已被識別的指紋進行比對,若存在則可直接存入相應的數據庫,若不存在則重新與所有指紋進行策略性識別關聯比對。
作為優選,如果不能通過fingerprint值、cookie和canvas、內網IP和外網IP三組唯一標識用戶的方式來對指紋信息進行關聯性的比對判斷,則需要對剩余的特征信息進行進一步的判別分析,具體為:對于特征信息值長度較短的直接進行字符串比對;使用Difflib庫對特征信息值長度較長的進行字符串相似比較,通過Difflib庫的ratio()函數求得特征信息值的相似度值,若該相似度值在特征對應的閾值范圍內,則認為特征信息相同;結合計算比較的結果與對應權重值相乘,可得出兩條指紋最終的指紋相似度值;將所述指紋相似度值與瀏覽器指紋的相似度閾值進行比對,在閾值范圍內的指紋相似度值則表明其所代表的兩條指紋來自于同一瀏覽器。
作為優選,利用德爾菲方法給每個瀏覽器特征信息設定權重,得出最終的權重值。
本發明為了實現有效追蹤用戶,收集用戶瀏覽器特征的信息,并在大批量的用戶瀏覽器特征信息中高效地識別出因瀏覽器特征信息改變生成的不同的Fingerprint值,同時采用策略性的識別方法,依托于一個搭建在公網服務器上的一個站點,主要負責收集用戶的瀏覽器特征信息,對不同階段的有改變的指紋進行有效的關聯和識別,以實現高性能用戶追蹤。
本發明用戶追蹤方法,通過網站收集中用戶的瀏覽器特征信息,并發送至網站后臺;使用策略性識別算法對收集到的數據進行關聯分析,本發明的策略性識別算法使用德爾菲方法給每個瀏覽器特征設定權重;在特征信息的比對中,對特征信息值較短的字符串進行直接比對,通過Difflib對較長的特征信息值字符串進行相似性比對,針對同一瀏覽器在比較的特征信息值上可能有的范圍內的變化進行定性測試,以此求得每一項對應的閾值,通過Difflib庫的ratio()函數求得特征信息值的相似度值,若該相似度值在特征對應的閾值范圍內,則認為特征信息相同;結合計算比較的結果與對應權重值相乘,可得出兩條指紋最終的指紋相似度值;最后針對所有的瀏覽器特征信息項,界定兩個以下(包含兩個)的特征信息值不一致為同一瀏覽器指紋,并對所有的瀏覽器信息值進行定性的升級或偽造測試,對所有測得的指紋相似度值求平均值,設定為整個瀏覽器指紋的相似度閾值;將上一步求得的指紋相似度值與得到的相似度閾值進行比對,在閾值范圍內的指紋相似度值則表明其所代表的兩條指紋來自于同一瀏覽器;當收集到新的指紋時,通過在已識別出的指紋中進行過濾識別,若沒有匹配,則繼續使用策略性識別算法與所有的指紋進行相似關聯分析。本發明能夠實現高效地判定兩個指紋信息是否相關聯。
附圖說明
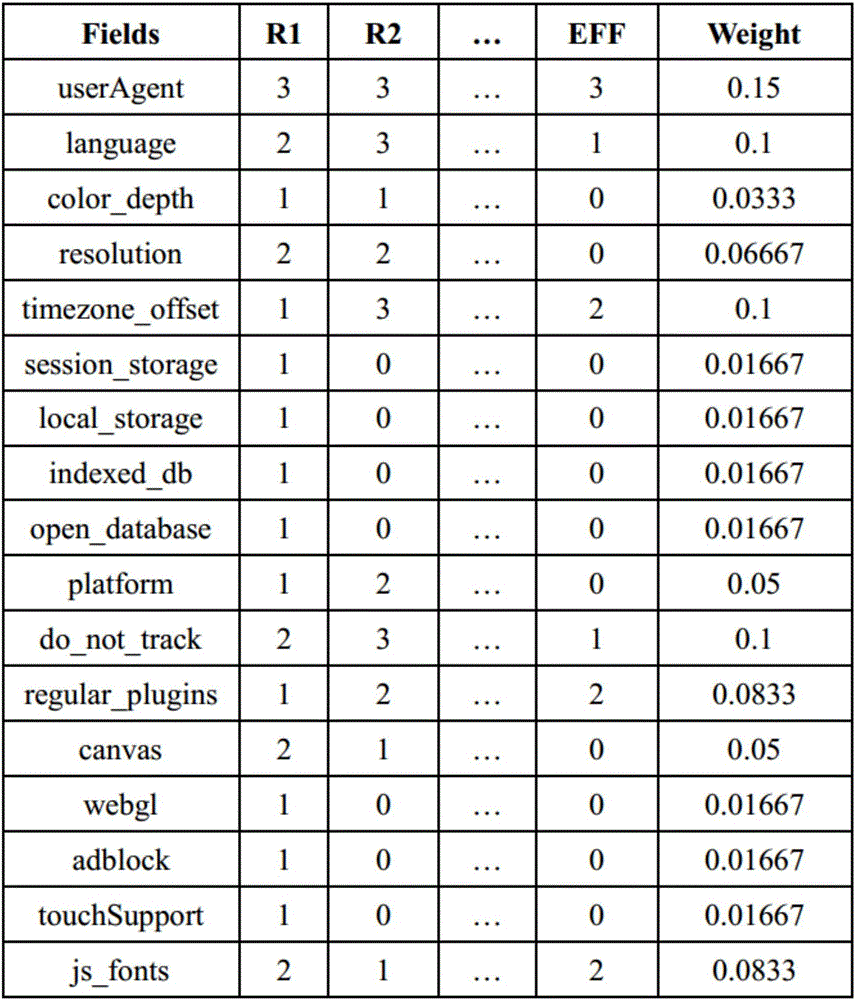
圖1是本發明實施方式中基于德爾菲方法計算權重的結果示意圖;
圖2是本發明實施方式中的一些瀏覽器特征項信息的展示示意圖;
圖3是本發明實施方式中策略性識別算法中的核心比對算法;
圖4是本發明實施方式中用戶追蹤的框架示意圖。
具體實施方式
以下將結合附圖所示的具體實施方式對本發明作進一步詳細說明。
本發明實施例提供一種基于瀏覽器的高性能用戶追蹤方法,包括以下步驟:
步驟1、獲取用戶瀏覽器特征信息,生成相應的Fingerprint指紋值,并將所述用戶瀏覽器特征信息以及相應的Fingerprint指紋值發送到相應的后臺服務器;
步驟S2、根據所述用戶瀏覽器特征信息以及相應的Fingerprint指紋值,依據策略性指紋識別方法對得到的相應數據進行關聯處理;
步驟S3、將關聯后的用戶客戶端信息存儲到Redis數據庫,使用過濾識別方式對新的指紋數據進行處理,判定兩個指紋信息是否相關聯。
步驟1具體為:
采用JavaScript語言技術獲取用戶瀏覽器的特征信息。用戶瀏覽器特征的信息包括瀏覽器本身的特征信息以及瀏覽器所在終端的信息;瀏覽器本身的特征信息包括:瀏覽器UA、語言Language、使用字體Font、安裝插件Plugins、Cookie和Canvas信息、瀏覽器所屬的平臺Platform、HTML5的本地存儲機制Local_stroage和Session_stroage、是否允許追蹤Do Not Track等;瀏覽器所在終端的信息包括:公網和內網IP;色彩深度Color_depth;時區Time_zone;屏幕分辨率Resolution等。關于瀏覽器特征信息的收集功能都被寫在Fingerprint.js腳本中。
通過在VPS上搭建測試網站,將信息收集功能腳本加載到網站上。當用戶瀏覽該網站的時候,JavaScript腳本對瀏覽器特征信息進行收集,使用murmurhash算法對特征信息進行哈希生成一個指紋值,即瀏覽器指紋。網站前端將所有信息回傳到后臺服務器,并存入數據庫。
步驟2具體為:
在后臺服務器對接收到的所有用戶瀏覽器指紋信息進行關聯分析,整個關聯處理包括:
利用德爾菲法設定權重
因瀏覽器的不同特征對指紋處理造成的影響不一,因此需要給每一個參與后續相似比較的瀏覽器特征設定權重,對這些項的重要程度進行定量分配,本發明利用德爾菲方法給每個瀏覽器特征信息設定權重,具體為:根據Web安全專家對瀏覽器的特征進行打分,并在第一輪打分完成后對每個進行反饋和探討,然后再進行下一輪的打分,通過幾輪打分后,將幾輪打分得到的平均值與EFF對采集到的用戶數據的統計信息結合進行求平均值計算,得到最終的值即為權重值。
策略性識別算法
對兩條指紋信息進行關聯分析,首先對由特征信息生成的fingerprint值進行比對,fingeprint值具有唯一性,如果兩個值相等,則認定兩條指紋屬于同一個用戶。如果fingerprint值不相等,利用Cookie和Canvas,內網IP和外網IP兩個組合對指紋進行判定,因為兩個組合的值均具有唯一性,由此可以判斷兩條指紋是否來自同一個客戶端。如果以上均不能判別成功,則需要對剩余的特征信息進行進一步的判別分析。
對每兩條比對的指紋信息新建一個列表,對于瀏覽器特征中信息值長度較短項(例如圖2中的Platform項),使用直接字符串比較的方法進行比對,若相等,則列表中的相應位置放數值1,若不等,則為0。對長度較長的特征信息值(例如圖2中的User Agent項),Regular Plugins和Fonts等,則利用Difflib庫來進行比對,針對同一瀏覽器在比較的特征信息值上可能有的范圍內的變化進行定性測試,以此求得每一項對應的閾值,如果兩個特征信息比較的值,即Difflib庫的ratio()函數值小于該特征信息的相應的閾值則認為不相等,列表中相應位置放0,反之為1;最后得到的列表形式為[1,0,1,1,…]。結合計算比較的結果與對應權重值相乘,可得出兩條指紋最終的指紋相似度值;最后針對所有的瀏覽器特征信息項,界定兩個以下(包含兩個)的特征信息值不一致為同一瀏覽器指紋,并對所有的瀏覽器信息值進行定性的升級或偽造測試,對所有測得的指紋相似度值求平均值,設定為整個瀏覽器指紋的相似度閾值;將上一步求得的指紋相似度值與得到的相似度閾值進行比對,在閾值范圍內的指紋相似度值則表明其所代表的兩條指紋來自于同一瀏覽器。
步驟S3具體為:
將所有已經關聯的指紋信息存儲到redis數據庫中,并按fingerprint值,cookie值以及IP等幾個分類進行存儲。當出現新的指紋信息,先將其與redis中已被識別的指紋進行比對,若存在則可直接存入相應的數據庫,若不存在則重新與所有指紋進行比對。
如圖1所示,在本發明的實施方式中,收集的用戶瀏覽器特征表中Fields所示。通過使用murmurhash方法對瀏覽器特征項進行哈希運算,生成唯一的fingerprint值。
利用德爾菲方法,由特定的專家按照既定的程序對所有瀏覽器的特征進行打分,在第一輪打分完成后,對每一個專家進行交流反饋。然后進行第二輪的特征打分,如此往復幾輪,使專家小組的意見趨于集中。結合電子前哨基金會(EFF)的關于用戶更改瀏覽器特征的數據分析,求得專家評分與EFF數據評定的平均值,得出最后特征的權重值。
圖2展示了瀏覽器指紋中的幾個特征項的信息,可以利用這些信息對不同的指紋信息進行關聯分析。
首先對兩條指紋信息的fingerprint值進行比較,因為fingerprint值是唯一的,如果兩者相等,則認為兩條指紋是同一個客戶端。否則繼續對cookie進行比較,cookie也具有唯一性,可以作為用戶的唯一標識來進行判斷,如果兩個cookie值相等則認為指紋來自同一個客戶端。在用戶禁用cookie的前提下,使用canvas作為唯一標識進行比較,canvas指紋雖然有高碰撞率,但結合cookie的狀態依舊可以作為唯一標識來進行比對。
如果以上兩項唯一標識的比較依舊不同,則結合內外網IP進行比對,即publicIP和intranetIP。用戶可能通過配置VPN或者加密代理瀏覽網站,所以publicIP不能作為用戶的唯一識別標識。WebRTC漏洞可暴漏用戶的內網IP,其功能相當于ipconfig/all命令。用戶的網絡環境大不相同,所以內外網IP的組合具有唯一性。
圖3展示了在以上判定均失敗的情況下,利用剩余的特征(即圖1中的特征項)對兩條指紋進行相似關聯分析的偽代碼。
在比較之前新建一個列表存儲比較后的結果,對于特征的信息字符串長度比較短的項,使用直接字符串比較的方法。如果兩個字符串相等,則將值1放到列表中相應的位置,否則該位置我0。對于特征的信息字符串較長的項,對其使用difflib模塊進行比較,每項特征會有自己的閾值,如果兩條指紋的項difflib求得的值小于相應的閾值,則相應位置為0,否則為1。
如圖4所示,本發明的實驗環境為搭建在公網的網站,用戶在瀏覽網站的時候,其瀏覽器特征信息被收集并發送到網站后臺存入到MySQL數據庫,通過策略性識別算法關聯分析的指紋信息按特征存入到Redis數據庫,當新的指紋信息被傳到后臺時,新信息會先和存放在Redis中的指紋進行比較,即過濾識別。如果不存在相等的項,則與MySQL數據庫中所有的指紋信息進行關聯判斷。
以上實施例僅為本發明的示例性實施例,不用于限制本發明,本發明的保護范圍由權利要求書限定。本領域技術人員可以在本發明的實質和保護范圍內,對本發明做出各種修改或等同替換,這種修改或等同替換也應視為落在本發明的保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!