一種VR頭戴設備的手勢跟蹤方法和VR頭戴設備與流程
本發明涉及虛擬現實技術領域,尤其涉及一種VR頭戴設備的手勢跟蹤方法以及VR頭戴設備。
背景技術:
虛擬現實技術是仿真技術的一個重要分支方向。虛擬現實技術使用計算機,利用相關技術和軟、硬件工具生成實時動態的、三維立體而且紋理逼真的圖像和場景,并使其可以模仿人類的各種感知,并利用傳感器與用戶進行交互。從1963年虛擬現實技術萌芽至今,虛擬現實技術的理論已經比較完善,而且近年來,虛擬現實技術在軍事仿真、娛樂游戲、醫療、建筑等多個行業中得到廣泛和深入的研究和使用。
在現有的虛擬現實設備的人機交互過程中,除了傳統的按鍵操作之外,還有手勢識別功能,VR頭戴設備通過設置在設備中的攝像頭采集視野中的圖像,并從圖像中分離識別手部圖像,對手部圖像進行模型匹配來判別手勢類別或者跟蹤手勢坐標。其中分離識別動作建立模型訓練的基礎上且通常采用卷積神經網絡進行手勢數據訓練。
在現有的虛擬現實設備跟蹤手勢坐標的過程中,通常是采集手勢深度數據并利用CNN進行回歸訓練得到模型。而現有CNN網絡的訓練核心是對二維圖卷積提取特征,僅僅利用手勢深度數據進行訓練,所獲得的信息可以說是從二維平面上提取的信息,手部的三維空間立體結構基本沒有得到有效利用,由于CNN采集到的信息是平面信息,所以CNN的訓練難度大,得到的數據誤差大、跟蹤的手勢坐標也不夠準確。
技術實現要素:
為解決現有VR頭戴設備圖像采集時,手部的三維空間立體結構基本沒有得到有效利用,導致數據誤差大、跟蹤手勢坐標不準確的問題,本發明公開了一種VR頭戴設備的手勢跟蹤方法。
一種VR頭戴設備的手勢跟蹤方法,包括以下步驟:
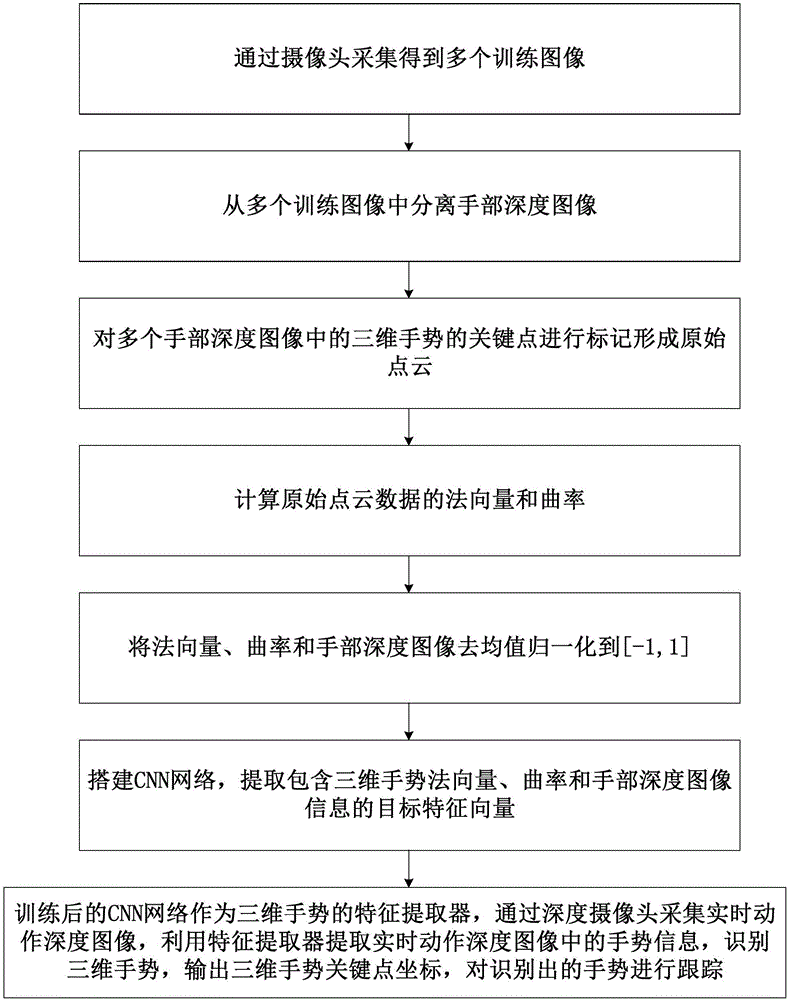
通過攝像頭采集得到多個訓練圖像;
從多個所述訓練圖像中分離多個手部深度圖像;
對多個所述手部深度圖像中的三維手勢的關鍵點進行標記,利用手部深度圖像形成原始點云數據,所述關鍵點包括掌心和多個手部關節;
計算根據手部深度圖像形成的原始點云數據的法向量和曲率;
將法向量、曲率和手部深度圖像去均值歸一化到[-1,1];
搭建CNN網絡,所述CNN網絡的輸入端分別輸入根據多個訓練圖像生成并歸一化后的法向量、曲率和手部深度圖像三路數據,輸出端輸出包括掌心在內的多個關節點的三維坐標;
訓練完成的CNN網絡作為三維手勢的特征提取器,通過深度攝像頭采集實時動作深度圖像,所述特征提取器提取所述實時動作深度圖像中的法向量、曲率和手部深度圖像信息,輸出實時動作深度圖像中三維手勢的三維坐標,所述處理器對識別出的三維手勢進行跟蹤。
進一步的,計算所述原始點云數據的法向量和曲率時,使用kd-tree算法構建所述原始點云的樹結構,并利用原始點云的樹結構查找計算手部深度圖像原始點云數據的法向量和曲率。
進一步的,利用隨機森林算法將通過攝像頭采集得到的多幅訓練圖像中的手部深度圖像與背景深度數據分離;對所述手部深度圖像進行降噪。
進一步的,將降噪后的手部深度圖像歸一化降維,生成256×256的二維圖像;
將降噪后的手部深度圖像中的關鍵點進行標記,所述關鍵點包括多個關節點和掌心;
生成手部深度圖像中任一點的圖像坐標m=(x,y)T;
利用手部深度圖像中任一點的圖像中坐標m=(x,y)T和相機坐標系下的空間坐標的關系求解所述手部深度圖像中任一點的相機坐標系中的空間坐標xc,yc和zc,圖像坐標和相機坐標系下空間坐標的關系如下:
其中zc為相機的光軸;
在相機坐標系下建立對應所述手部深度圖像且包括多個關節點和掌心坐標的原始點云;利用kd-tree算法構建對應原始點云數據的樹結構,并分別利用原始點云數據的樹結構查找計算法向量和曲率。
為了提高處理效率,并盡可能的保存圖像特征,搭建CNN網絡之前,利用PCA算法對手部深度圖像降維到96×96。
進一步的,所述CNN網絡包括卷積層、池化層和全連接層,其中所述卷積層包括并行的第一卷積通道、第二卷積通道和第三卷積通道,所述第一卷積通道、第二卷積通道和第三卷積通道的輸入端分別輸入法向量、曲率和手部深度圖像。
進一步的,所述第一卷積通道、第二卷積通道和第三卷積通道均包括三級卷積,且每一級卷積層后均跟隨一層池化層,第一卷積通道、第二卷積通道和第三卷積通道輸出至全連接層,所述全連接層包括三級全連接層。
優選的,所述CNN網絡的激活函數為Relu函數。
優選的,所述卷積層的卷積核為5×5,所述池化層的池化核為2×2。
本發明在對原始手勢深度數據的預處理過程中對數據的法向量、曲率這兩種三維空間特征信息進行了提取,并在橫向尺度和縱向層深上做了改進。通過對采集數據三維空間描述信息的提取和利用,彌補了手部深度圖像特征紋理單一的不足,強化了手勢深度數據所具有的三維空間特征,三維手勢無需做分類,因此本發明所提供的方法可以適用于對連續變動手勢的追蹤,同時,由于在采集數據中增加了三維空間的描述信息,因此可以最大可能的排除相機采集角度帶來的誤差。本發明提高了CNN訓練模型的精確度,進而提高了VR頭戴設備對手勢跟蹤的精確度。
一種VR頭戴設備,采用VR頭戴設備的手勢跟蹤方法控制,所述VR頭戴設備的手勢跟蹤方法包括以下步驟:
通過攝像頭采集得到多個訓練圖像;
從多個所述訓練圖像中分離多個手部深度圖像;
對多個所述手部深度圖像中的三維手勢的關鍵點進行標記,利用手部深度圖像形成原始點云數據,所述關鍵點包括掌心和多個手部關節;
計算根據手部深度圖像形成的原始點云數據的法向量和曲率;
將法向量、曲率和手部深度圖像去均值歸一化到[-1,1];
搭建CNN網絡,所述CNN網絡的輸入端分別輸入根據多個訓練圖像生成并歸一化后的法向量、曲率和手部深度圖像三路數據,輸出端輸出包括掌心在內的多個關節點的三維坐標;
訓練完成的CNN網絡作為三維手勢的特征提取器,通過深度攝像頭采集實時動作深度圖像,所述特征提取器提取所述實時動作深度圖像中的法向量、曲率和手部深度圖像信息,輸出實時動作深度圖像中三維手勢的三維坐標,所述處理器對識別出的三維手勢進行跟蹤。
本發明所公開的VR頭戴式設備,所采用的手勢跟蹤方法中提取融合的三維手勢的空間特征,并且通過CNN網絡充分利用手部三維信息,提升了卷積神經網絡的訓練效果,足以滿足高精確度的仿真場景,擴大了VR頭戴式設備的使用范圍。同時由于本發明可以對連續變化的手勢實現識別,因此可以脫離實體控制按鍵,實現遠距離多種手部命令控制。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作一簡單地介紹,顯而易見地,下面描述中的附圖是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動性的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明所公開的VR頭戴設備手勢跟蹤方法一種實施例的流程圖;
圖2為圖1所公開的VR頭戴設備手勢跟蹤方法中所搭建的CNN網絡的網絡架構圖。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
參見圖1所示為本發明所公開的VR頭戴設備的手勢跟蹤方法一種實施例的流程示意圖。具體來說,本實施例所公開的跟蹤方法包括圖像預處理、三維特征提取、搭建卷積神經網絡、卷積神經網絡訓練、識別、利用識別結果操控等幾個步驟,以下按照上述過程分別詳細描述。
首先為建立卷積神經網絡進行前期準備。通過攝像頭采集多個訓練樣本圖像。訓練樣本圖像優選在5000張左右,也可以根據實際識別精度的要求調整訓練樣本圖像的數量,訓練樣本圖像中均包含一個三維手勢圖像。攝像頭可以選擇使用設置在VR頭戴設備上的攝像頭,也可以選擇其它獨立設置的高清攝像頭。對訓練樣本圖像預處理時,假定三維手勢是距離攝像頭最近的目標物體,考慮到VR頭戴設備的應用場景,對于VR頭戴式設備會采集到的圖像數據來說,圖像背景中人體數據較多,其它因素基本可以忽略。利用隨機森林算法將訓練圖像中的手部深度圖像塊和背景物體的深度圖像分離,提取出對應每一個三維手勢圖像的手部深度圖像塊作為手部深度圖像,并進一步對手部深度圖像進行去噪處理,去除手部深度圖像上的噪點,完成圖像分離預處理。
將降噪后的手部深度圖像圖像歸一化降維,獲得分辨率為256×256的二維圖像。256×256的像素選擇是基于長期對VR生成圖像的處理經驗,這一分辨率可以盡可能保持圖像信息的完整并降低后續圖像處理系統的信息處理量。在本實施例中,識別手勢的最終目的是可以自動判定三維手勢,并利用三維手勢圖像特征的變化產生的控制信號進行VR頭戴設備的下一步操作。在本方法中,識別的基準在于形成不同手勢變化時手部各個指關節會產生對應的變化以及各個指關節會出現不同位置的組合,所以在對手部深度圖像預處理時,對手部各個指關節的圖像坐標進行標記,同時標記圖像中掌心的圖像坐標,生成每一個關鍵點的二維圖像坐標。
標記完成后,通過計算機系統記錄手部深度圖像中任一點的圖像坐標m=(x,y)T,利用手部深度圖像中任一點的圖像坐標m=(x,y)T和相機坐標系下的空間坐標的關系求解所述手部深度圖像中任一點的相機坐標系中的空間坐標xc,yc和zc,圖像坐標和相機坐標系下空間坐標的關系如下:
其中zc為相機的光軸;
在zc已知的條件下,可以求出每一點對應xc和yc,利用相機坐標系下的空間坐標建立對應每一幅手部深度圖像且包括關節點和掌心坐標的原始點云。
為了在彌補手部深度圖像特征紋理單一的缺點,在本實施例中,對訓練樣本的預處理重點增加了手勢的三維空間特征。具體來說,三維空間特征優選包括根據手部深度圖像生成的原始點云數據中包含的法向量和曲率。在獲得對應每一幅手部深度圖像且包括關節點和掌心坐標的原始點云后,首先計算根據手部深度圖像形成的原始點云數據的法向量和曲率。原始點云數據的法向量可以通過擬合法計算,曲率可以通過拋物面擬合法計算。在擬合計算的過程中,為了提高運算的速率,使用kd-tree算法構建原始點云的樹結構,并利用原始點云的樹結構查找計算原始點云數據的法向量和曲率。
在得到原始點云數據的法向量和曲率后,對手部深度圖像、對應每一幅手部深度圖像的法向量和曲率進一步進行去均值,利用方差歸一化至[-1,1],并進一步利用PCA算法將手部深度圖像降維到96×96,減少后續卷積神經網絡的數據處理量,同時保證有效特征保留充分。
獲得歸一化后的曲率、法向量和降維到96×96的手部深度圖像后,基本完成了對訓練圖像的預處理。
下一步利用預處理后的圖像和數據訓練CNN網絡。在本實施例中,參見圖2所示,搭建的CNN網絡包括并行的第一卷積通道,第二卷積通道和第三卷積通道,其中第一卷積通道、第二卷積通道和第三卷積通道的輸入端分別輸入預處理生成的對應手部深度圖像的原始點云的法向量、曲率和手部深度圖像,在并行的第一卷積通道、第二卷積通道和第三卷積通道中均包括三級卷積,如圖2所示C1,C2,C3,在每一級卷積層后均跟隨一層池化層,如圖2所示P1,P2,P3,即采樣層,第一卷積通道、第二卷積通道和第三卷積通道輸出至全連接層。全連接層包括三級全連接層,如圖2所示f1,f2,f3,其中優選第一級全連接層f1包括1024個神經元,第二級全連接層f2包括1024個神經元,第三級全連接層f3包括512個神經元。第三級全連接層f3輸出包、對應手部深度圖像中多個關節點,包括掌心在內的三維坐標3J,其中J代表關節數。如圖2所示,在本實施例中,優選每一級卷積層的卷積核為5×5,優選選擇8個卷積核,池化層的池化核為2×2。在CNN網絡中,激活函數為Relu函數。
通過訓練得到的CNN網絡作為三維手勢的特征提取器存儲在VR頭戴式設備的存儲單元中。當VR頭戴式設備運行時,通過VR頭戴式及設備本身帶有的深度攝像頭采集含有三維手勢的實時動作深度圖像,對實時動作深度圖像進行預處理,將實時動作深度圖像中的手部深度圖像和背景深度圖像區分開,提取前部的手部深度圖像,并對手部深度圖像進行去噪。對手部深度圖像進行降維,將圖像分辨率降為256×256,根據實時動作深度圖像建立點云數據,利用點云數據計算法向量和曲率,并將實時動作深度圖像、法向量和曲率輸入至CNN網絡的三個卷積通道的輸入端,利用特征提取器識別實時動作深度圖像中的三維手勢,并生成識別出的三維手勢中關節點和掌心的坐標,定位三維手勢動作,并將識別結果輸出至處理器,處理器對識別出的手勢進行跟蹤。
本發明在對原始手勢深度數據的預處理過程中對數據的法向量、曲率這兩種三維空間特征信息進行了提取,并在橫向尺度和縱向層深上做了改進。通過對采集數據三維空間描述信息的提取和利用,彌補了手部深度圖像特征紋理單一的不足,強化了手勢深度數據所具有的三維空間特征,三維手勢無需做分類,因此本發明所提供的方法可以適用于對連續變動手勢的追蹤,同時,由于在采集數據中增加了三維空間的描述信息,因此可以最大可能的排除相機采集角度帶來的誤差。本發明提高了CNN訓練模型的精確度,進而提高了VR頭戴設備對手勢跟蹤的精確度。
本發明同時公開了一種VR頭戴式顯示設備,采用如上述實施例所詳細描述的VR頭戴式顯示設備的手勢跟蹤方法。手勢跟蹤方法的具體數據采集、處理和識別過程參見上述實施例,在此不再贅述,本發明所公開的VR頭戴式顯示設備具有同樣的技術效果。
最后應說明的是:以上實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的精神和范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!