一種大數據協同分析工具平臺的制作方法
本發明涉及大數據分析技術領域,具體來說,涉及一種大數據協同分析工具平臺。
背景技術:
現有大數據分析技術,涉及數據的從數據導入、數據存儲、數據檢索、數據分析、數據可視化的全流程大數據處理分析技術領域。隨著大數據技術近年不斷發展,也涌現了許多基于大數據的分析工具和分析平臺,但由于針對業務領域不同,各家產品專攻技術差異等因素,現有大數據分析工具、BI分析工具等,仍舊存在諸多問題和缺陷。
現有技術產品大多針對商企數據提供功能技術服務,面向行業研究、科研領域的數據分析產品匱乏,現有TDA(Thomson Data Analyzer)可以面向行研數據領域,但由于不是基于大數據技術的產品,在海量數據處理、大數據分析、大數據可視化等方面功能欠缺。且大多針對單一數據源或有限數據源作為處理對象進行處理,不能兼容所有數據格式。大多支持數據導入時的ETL數據清洗處理,缺乏對數據導入ETL處理完成后的,基于業務需求的數據定制化加工標引標注。且現有技術產品不支持團隊協同協作的協同數據標引和協同分析功能。只支持有限的分析算法和可視化圖表來進行數據分析計算和展現數據分析結果,不支持算法包的定制化擴展以及可視化圖表的模板化和插件化。
且現有技術產品的分析模式更適用于專業技術人員,不適用于真正有分析需求的業務人員,使用門檻高。且大多針對全流程的一個或幾個技術領域做數據服務,缺少針對全數據流程的工具產品和數據分析技術。
針對相關技術中的問題,目前尚未提出有效的解決方案。
技術實現要素:
本發明的目的是提供一種大數據協同分析工具平臺,能夠解決現有數據服務技術領域缺乏針對全數據流程的工具產品和數據分析技術的問題,填補了該領域缺乏一體化分析流程的空白。
本發明的目的通過以下技術方案來實現:
一種大數據協同分析平臺,包括:
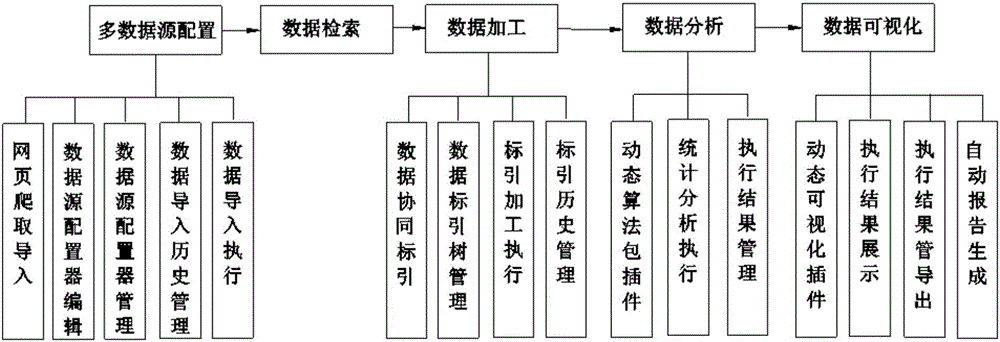
多數據源配置模塊,用于實現任意數據的配置導入和爬取,建立容數據源配置XML腳本語言,或者通過容數據源配置XML腳本語言,實現各種數據源的編程配置和映射配置;
數據檢索模塊,用于對導入的數據建立全文分詞索引,提供主題檢索和條件檢索,支持海量數據的高速搜索引擎;
數據加工模塊,用于實現團隊協同協作的協同數據標引和協同分析功能,通過標引樹技術,實現標引內容的統一協同管理和數據定制化標引加工;
數據分析模塊,用于定制算法模板,分析算法自由選擇,量身定制數據建模和算法實現,通過算法包插件,提供專享專用算法包;
數據可視化模塊,用于實現分析結果的可視化展示和自動報表,包括動態可視化插件、執行結果展示、執行結果導出和自動報告生成。
進一步的,所述多數據源配置模塊包括:
網頁爬取導入子模塊,用于實現爬取配置、爬取規則和爬取導入的一體化處理流程,使用自主研發網絡爬蟲技術,對指定網站、網頁進行規則化數據爬取,爬取數據根據爬蟲導入配置器自動導入數據庫;
數據源配置器編輯子模塊,用于數據源配置器配置規則項的新建和編輯;
數據源配置器管理子模塊,用于各個數據源配置器的查詢和管理,包括配置器的摘要信息,詳細編輯入口和刪除功能;
數據導入歷史管理子模塊,用于針對當前任務下的數據導入歷史信息列表查詢,包括數據的導入名稱、大小、時間、所用配置器和導入狀態;
數據導入執行子模塊,用于選擇配置器和導入數據源執行數據導入。
進一步的,所述數據加工模塊包括:
數據協同標引子模塊,用于實現數據標引、加工和分析的多人團隊協同
同步作業,提供在線、團隊、實時、協作分析加工標引功能,各成員標引加工內容實時同步呈現,通過顏色區分不同成員的加工標引內容并相互可見,實現團隊標引加工作業的操作實時協同、進度清晰可見、內容同步共享;
數據標引樹管理子模塊,用于提供協同標引加工時的標引數據字典功能,實現標引內容的統一協同管理和數據定制化標引加工;
標引加工執行子模塊,用于數據標引、加工和分析的執行;
標引歷史管理子模塊,用于對標引樹技術儲進行管理,或者通過CSV(Comma-Separated Values,逗號分隔值)格式文件進行導入導出管理,使標引樹字典信息實現線上線下的映射導出和集中管理。
進一步的,所述數據分析模塊包括:
動態算法包插件,用于實現定制化擴展算法包的動態替換擴展和算法熱插拔;實現算法包的模板化管理,通過參數模板,規范管理算法輸入輸出標準,前端通過參數模板解析,識別所需參數類型;
統計分析執行子模塊,用于參數采集,通過人機交互采集參數后,將采集到的參數列表經過格式化統一傳遞給算法包,進行算法執行;
執行結果管理子模塊,用于數據分析結果的管理。
進一步的,所述數據可視化模塊包括:
動態可視化插件,用于實現可視化圖表的組件化、模板化和插件化,提供可視化圖表的動態組件化,通過后臺管理可視化模板,并通過可視化模板的動態插拔實現前端可視化圖表組件的動態替換和擴展;
執行結果展示,用于展示動態可視化的結果;
執行結果導出,用于導出動態可視化的結果;
自動報告生成,用于根據事先定義的報告模板,結合分析結果數據和圖表,自動生成統計分析報告,支持Word、PDF多種輸出格式,支持人工輔助評論補正,實現自動化報告制作和生成。
一種大數據協同分析方法,包括:
S1:建立研究主題:以研究主題為單位、創建研究任務組、管理研究數據和制定研究方向,線下科研團隊直接平移至線上,團隊成員協同共享研究成果,不同研究任務之間數據保密隔離;
S2:數據搜索引擎:導入數據建立全文分詞索引,提供主題檢索和條件檢索,支持海量數據的高速搜索引擎;
S3:建模統計分析:定制算法模塊,分析算法自由選擇,量身定制數據建模和算法實現,通過算法包插件,提供專享專用算法包,讓建模統計分析隨需而用,快速高效;
S4:數據配置導入:海量數據批量并行導入和爬取,針對各種數據源定制專有數據解析配置器,通過配置器插件服務,實現所有格式文本文獻的定向字段提取和定制化導入,實現數據源的自定義智能解析、數據項智能提取分離、數據字段智能映射存儲;
S5:協同分析標引:實現研究團隊內數據加工云協作,團隊成員分析加工標引結果實時共享可見,實時在線溝通,支持基于標引樹的統一標引數據字典,針對各種標引內容定制專有標引規則配置器,實現批量自動化標引;
S6:結果可視化:提供分析結果的可視化展示和自動報表,可視化圖表根據需求量身定制,通過可視化插件,提供專享專用可視化模板,提供交互式可視化和自動報告。
本發明的有益效果:立足于信息計量分析和行業研究領域,并致力于打造提供面向大數據的全鏈條全領域全受眾的整體數據服務及解決方案平臺。解決了傳統企業行業信息研究工作在專業專、技術難、成本高和效率低上的痛點,提供功能集成的信息研究大數據作業平臺。提供大數據的多數據源可配置化數據導入,大數據存儲,大數據搜索引擎,大數據在線協同分析,大數據在線實時統計分析挖掘和大數據可視化等多維度大數據服務。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是根據本發明實施例所述的一種大數據協同分析平臺整體結構示意圖;
圖2是根據本發明實施例所述的一種大數據協同分析平臺操作流程示意圖;
圖3是根據本發明實施例所述的一種大數據協同分析平臺技術架構示意圖;
圖4是根據本發明實施例所述的一種大數據協同分析平臺基于Hadoop的分布式體系架構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員所獲得的所有其他實施例,都屬于本發明保護的范圍。
1.如圖1-2所示,一種大數據協同分析平臺,包括:
1.1多數據源配置模塊,通過數據源配置技術,實現任意數據源的配置導入和爬取,支持各種格式的結構化、非結構化的文本數據源,包括數據庫表、行研文獻等,實現數據源的自定義智能解析、數據項智能提取分離、數據字段智能映射存儲。
本發明首創性建立容數據數據源配置XML腳本語言,除了從圖形交互界面進行數據源配置外,還支持通過容數據數據源配置XML腳本語言,實現各種數據源的編程配置和映射配置。
容數據數據源配置XML腳本,關鍵字設計如下所示:
1.2數據檢索模塊,用于對導入的數據建立全文分詞索引,提供主題檢索和條件檢索,支持海量數據的高速搜索引擎。
1.3多數據源配置模塊包括:
1.3.1網頁爬取導入子模塊,用于實現爬取配置、爬取規則和爬取導入的一體化處理流程,使用自主研發網絡爬蟲技術,對指定網站、網頁進行規則化數據爬取,爬取數據根據爬蟲導入配置器自動導入數據庫;
1.3.2數據源配置器編輯子模塊,用于數據源配置器配置規則項的新建和編輯;
1.3.3數據源配置器管理子模塊,用于各個數據源配置器的查詢和管理,包括配置器的摘要信息,詳細編輯入口和刪除功能;
1.3.4數據導入歷史管理子模塊,用于針對當前任務下的數據導入歷史信息列表查詢,包括數據的導入名稱、大小、時間、所用配置器和導入狀態;
1.3.5數據導入執行子模塊,用于選擇配置器和導入數據源執行數據導入。
1.4數據加工模塊,用于實現團隊協同協作的協同數據標引和協同分析功能,通過標引樹技術,實現標引內容的統一協同管理和數據定制化標引加工。
所述數據加工模塊包括:
1.4.1數據協同標引子模塊,通過實時在線協同同步技術,實現針對數據標引、加工和分析的多人團隊協同同步作業。提供在線、團隊、實時、協作分析加工標引功能,各成員標引加工內容實時同步呈現,通過顏色區分不同成員的加工標引內容并相互可見,實現團隊標引加工作業的操作實時協同、進度清晰可見、內容同步共享。每個人可以實時看到團隊內成員的數據加工、標引內容,識別他人作業軌跡,同時可以實現加工、標引和分析結果的實時共享,實現團隊在線協同分析。
從根本上解決,行業研究等數據分為業務需要多人小組協同分工,共同完成數據科研分析、數據挖掘分析的作業需求。
協同加工、標引、分析通過不同顏色識別不同用戶,達到多用戶同步協調作業。
1.4.2數據標引樹管理子模塊,通過使用標引樹技術,提供協同標引加工時的標引數據字典功能,一方面滿足團隊作業時標引內容的統一管理規范和數據字典標準,另一方面為數據標引提供方便快捷的可選數據集。
標引樹技術儲通過人機交互界面進行管理外,還可以通過CSV格式文件進行導入導出管理,使標引樹字典信息實現線上線下的映射導出和集中管理。
1.4.3標引加工執行子模塊,用于數據標引、加工和分析的執行;
1.4.4標引歷史管理子模塊,用于對標引樹技術儲進行管理,或者通過CSV
格式文件進行導入導出管理,使標引樹字典信息實現線上線下的映射導出和集中管理。
1.5數據分析模塊,用于定制算法模板,分析算法自由選擇,量身定制數據建模和算法實現,通過算法包插件,提供專享專用算法包。
所述數據分析模塊包括:
1.5.1動態算法包插件,基于專業建模算法包的動態擴展,實現算法包的模板化管理,通過參數模板,規范管理算法輸入輸出標準,前端通過參數模板解析,識別所需參數類型,并通過人機交互進行參數采集,采集到的參數列表經過格式化統一傳遞給算法包,進行算法執行。
整個過程通過json模板進行管理編輯,實現對于定制化擴展算法包的動態替換擴展和算法熱插拔。
具體模板json設計如下:
1.5.2統計分析執行子模塊,用于參數采集,通過人機交互采集參數后,將采集到的參數列表經過格式化統一傳遞給算法包,進行算法執行;
1.5.3執行結果管理子模塊,用于數據分析結果的管理。
1.6數據可視化模塊,用于實現分析結果的可視化展示和自動報表,包括動態可視化插件、執行結果展示、執行結果導出和自動報告生成。
所述數據可視化模塊包括:
1.6.1動態可視化插件,基于大數據可視化D3技術,實現可視化圖表的組件化、模板化和插件化。提供可視化圖表的動態組件化,通過后臺管理可視化模板,并通過可視化模板的動態插拔實現前端可視化圖表組件的動態替換和擴展。
基于動態可視化插件技術,可以為可視化圖表的定制化擴展提供技術支撐。可視化插件模板基于H5構建,實現基于WEB端和移動端的動態圖表熱插拔擴展。
1.6.2執行結果展示,用于展示動態可視化的結果;
1.6.3執行結果導出,用于導出動態可視化的結果;
1.6.4自動報告生成,用于根據事先定義的報告模板,結合分析結果數據和圖表,自動生成統計分析報告,支持Word、PDF多種輸出格式,支持人工輔助評論補正,實現自動化報告制作和生成。
本大數據協同分析平臺,首創性將大數據分析的全技術環節和處理流程進行梳理整合,形成從數據導入到數據存儲、從數據檢索到數據加工、從數據分析到數據可視化的全流程大數據處理引擎,為用戶提供全套功能解決方案。
本大數據協同分析平臺,首創性建立“容數據模式”的大數據分析服務模式,摒棄了傳統大數據分析模式的高門檻、高成本、跨專業、難度高等的弊病,通過面向用戶建立統一直接的容數據平臺,實現大數據的無縫接入和分析作業的簡單自如。
為了方便理解本發明的上述技術方案,以下通過具體使用方式對本發明的上述技術方案進行詳細說明。
如圖3所示,大數據協同分析平臺基于Web3.0的數據網絡體系架構,搭建大數據應用服務平臺。整體技術架構基于主流B/S(Browser/Server,瀏覽器/服務器模式)架構,底層大數據分布式體系架構作為平臺支撐,上層采用主流J2EE(Java 2Platform,Enterprise Edition)企業級應用框架和基于H5的動態頁面技術,實現從數據網絡到服務應用的整體技術架構。
底層采用自主分布式混合持久化技術,構建大數據技術核心框架。架構采用主流Hadoop生態圈大數據技術,搭載HDFS分布存儲文件系統,提供基于Yarn的大數據分布計算資源管理框架,配合Spark實時計算框架,提供大數據實時分析計算引擎能力。基于列式數據庫的HBase數據庫,稀疏矩陣存儲和高性能吞吐量支撐,為后續警務異構大數據存儲提供技術支撐。
如圖4所示,另一方面,在大數據分布存儲基礎上,搭配關系型存儲MySQL集群、非結構化媒體數據網絡存儲,通過高效緩存和索引技術實現混合類型數據的高效索引聯動,提供高速搜索引擎和數據訪問接口。
邏輯層采用J2EE企業級框架,搭配Spring、SpringMVC和MyBatis的SSM應用服務技術框架組合,提供業務邏輯層的精準構建和靈活應用擴展,通過使用豐富的前端技術組件,包括Ajax、JQuery、H5等,為前端瀏覽器和手機移動端擴展提供豐富人機界面和人性化交互體驗。
整體架構采用面向服務體系架構(SOA),開放標準的RESTful API接口,以提供系統平臺的對外WebService服務功能。
產品的應用服務流程如下:
建立研究主題,以研究主題為單位,創建研究任務組、管理研究數據和制定研究方向。線下科研團隊直接平移至線上,團隊成員協同共享研究成果,不同研究任務之間,數據保密隔離。
數據配置導入,海量數據批量并行導入和爬取,針對各種數據源定制專有數據解析配置器。通過配置器插件服務,實現所有格式文本文獻的定向字段提取和定制化導入。
數據搜索引擎,導入數據建立全文分詞索引,提供主題檢索和條件檢索。支持海量數據的告訴搜索引擎。
協同分析標引:實現研究團隊內數據加工云協作,團隊成員分析加工標引結果實時共享可見,實時在線溝通,支持基于標引樹的統一標引數據字典,針對各種標引內容定制專有標引規則配置器,實現批量自動化標引。
建模統計分析,可定制化算法模板,分析算法自由選擇,量身定制數據建模和算法實現,通過算法包插件,提供專享專用算法包。讓建模統計分析隨需而用,快速高效。
結果可視化:提供分析結果的可視化展示和自動報表,可視化圖表根據需求量身定制,通過可視化插件,提供專享專用可視化模板,提供交互式可視化和自動報告。
本發明的有益效果:立足于信息計量分析和行業研究領域,并致力于打造提供面向大數據的全鏈條全領域全受眾的整體數據服務及解決方案平臺。解決了傳統企業行業信息研究工作在專業專、技術難、成本高和效率低上的痛點,提供功能集成的信息研究大數據作業平臺。提供大數據的多數據源可配置化數據導入,大數據存儲,大數據搜索引擎,大數據在線協同分析,大數據在線實時統計分析挖掘和大數據可視化等多維度大數據服務。
以上所述僅為本發明的較佳實施例而已,并不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!