一種基于搜索引擎的檢索模式生成方法及裝置與流程
本發明涉及互聯網
技術領域:
,尤其涉及一種基于搜索引擎的檢索模式生成方法及裝置。
背景技術:
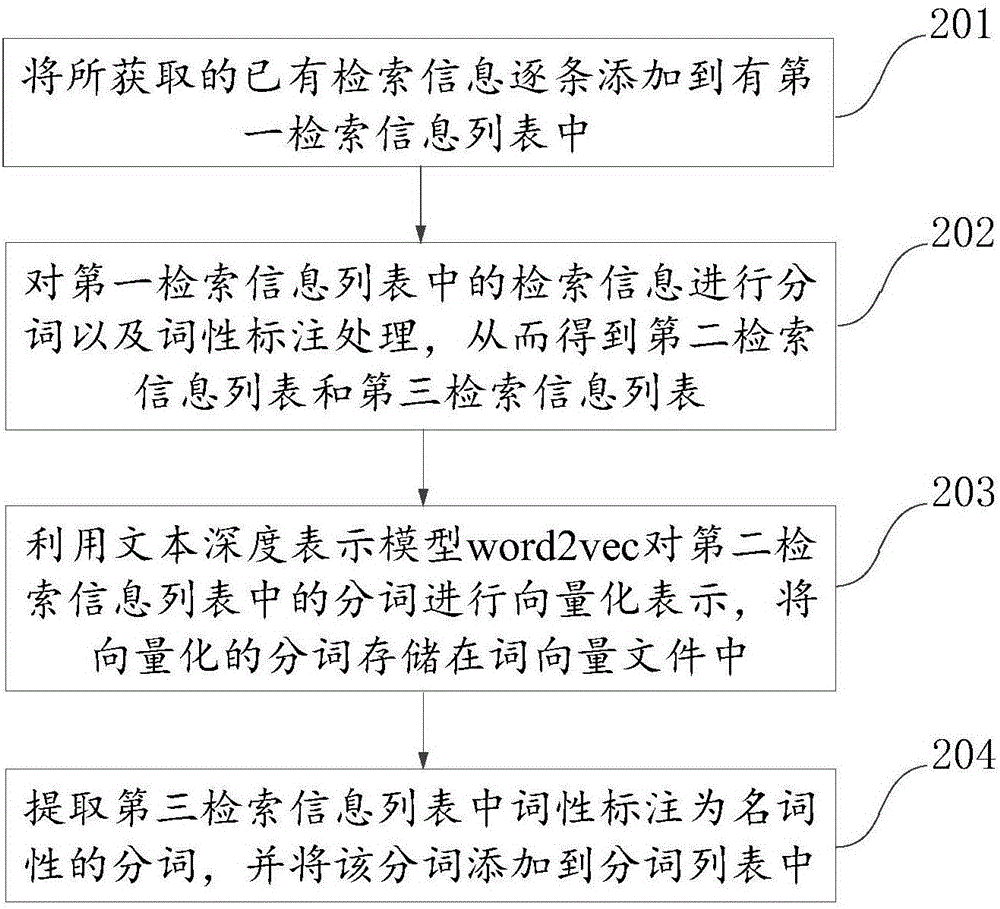
:人們在使用Web搜索引擎,完成某一類檢索需求時,往往依賴日常的生活用語習慣來構造檢索模式,即querypattern。一個querypattern代表著一類檢索信息query的集合,表達相同或相似的用戶意圖,比如詢問距離的一個pattern:從#到#有多遠,具體的檢索信息有“從山西靈石到陜西華陰有多遠”、“從霍山到英山有多遠”、“從洛陽到少林寺有多遠”、“從雙井到牡丹園有多遠”等等實例。這些pattern能夠幫助理解用戶的查詢意圖,pattern“從#到#有多遠”可以用來識別query中的地點實體詞,知道哪一個是起始地點、哪一個是結束地點,從而幫助搜索引擎檢索到滿足用戶意圖的結果。在Web搜索引擎中保存了用戶的檢索日志,積累了海量的用戶歷史檢索信息query,從中挖掘出來表達用戶各類檢索需求的querypattern,可以進一步分析用戶查詢意圖,助益相關性計算,返給用戶最相關的結果,從而改善用戶的搜索體驗。然而目前的querypattern挖掘方法是一種貪婪算法,逐個去掉query中的分詞,再遍歷語料,統計余下部分的共現頻率,共現高頻的就有可能是pattern。但是,這種方法所要求的時間復雜度高,并且所挖掘pattern中有雜質,導致在實際應用中并不能為用戶匹配出最佳的檢索結果。技術實現要素:有鑒于此,本發明提供一種基于搜索引擎的檢索模式生成方法及裝置,通過將具有潛在檢索模式的預料進行聚類,再對其挖掘所含有的檢索模式,得到高純凈度的檢索模式,從而提升用戶的檢索體驗。依據本發明的一個方面,提出了一種基于搜索引擎的檢索模式生成方法,該方法包括:對所獲取的已有檢索信息進行預處理,得到詞向量表示的檢索信息;利用聚類算法將處理后的檢索信息進行聚類,得到多個分類檢索信息列表,所述分類檢索信息列表中記錄有相似上下文信息的檢索信息;從所述分類檢索信息列表中提取對應的檢索模式,所述檢索模式是能夠代表一類檢索信息的模式化信息。依據本發明的另一個方面,提出了一種基于搜索引擎的檢索模式生成裝置,該裝置包括:處理單元,用于對所獲取的已有檢索信息進行預處理,得到詞向量表示的檢索信息;聚類單元,用于利用聚類算法將所述處理單元處理后的檢索信息進行聚類,得到多個分類檢索信息列表,所述分類檢索信息列表中記錄有相似上下文信息的檢索信息;提取單元,用于從所述聚類單元得到的分類檢索信息列表中提取對應的檢索模式,所述檢索模式是能夠代表一類檢索信息的模式化信息。本發明所采用的一種基于搜索引擎的檢索模式生成方法及裝置,通過對搜索引擎保存的已有檢索信息進行詞向量表示,利用聚類算法將具有相似上下文信息的檢索信息進行聚類,再從聚合在一起的檢索信息中提取對應的檢索模式。相對于現有的檢索模式的挖掘方法,本發明所采用的方法通過對檢索信息的預處理,可以有效的減少遍歷語料的次數,通過聚類算法將具有潛在檢索模式的檢索信息進行聚類,在同一類的檢索信息中進行挖掘,大幅提高了檢索模式的純凈度,同時提高的檢索模式的挖掘速率,從而提高到了創建檢索模式的效率,使得搜索引擎在更新檢索模式時能夠快速完成,為使用搜索引擎的用戶提供更佳的檢索服務。上述說明僅是本發明技術方案的概述,為了能夠更清楚了解本發明的技術手段,而可依照說明書的內容予以實施,并且為了讓本發明的上述和其它目的、特征和優點能夠更明顯易懂,以下特舉本發明的具體實施方式。附圖說明通過閱讀下文優選實施方式的詳細描述,各種其他的優點和益處對于本領域普通技術人員將變得清楚明了。附圖僅用于示出優選實施方式的目的,而并不認為是對本發明的限制。而且在整個附圖中,用相同的參考符號表示相同的部件。在附圖中:圖1示出了本發明實施例提出的一種基于搜索引擎的檢索模式生成方法流程圖;圖2示出了本發明實施例提出的對所獲取的已有檢索信息進行預處理的方法流程圖;圖3示出了本發明實施例提出的對檢索信息進行聚類生成分類檢索信息列表的方法流程圖;圖4示出了本發明實施例提出的從分類檢索信息列表中提取對應檢索模式的方法流程圖;圖5示出了本發明實施例提出的一種基于搜索引擎的檢索模式生成裝置的組成框圖;圖6示出了本發明實施例提出的另一種基于搜索引擎的檢索模式生成裝置的組成框圖。具體實施方式下面將參照附圖更詳細地描述本發明的示例性實施例。雖然附圖中顯示了本發明的示例性實施例,然而應當理解,可以以各種形式實現本發明而不應被這里闡述的實施例所限制。相反,提供這些實施例是為了能夠更透徹地理解本發明,并且能夠將本發明的范圍完整的傳達給本領域的技術人員。本發明實施例提供了一種基于搜索引擎的檢索模式生成方法,該方法主要應用搜索引擎中,針對用戶的對某一類信息檢索的需求,以檢索模式為關聯紐帶匹配出相關性較高的網頁作為檢索結果。需要說明的是,本發明實施例中的檢索模式是對已有的檢索信息進行統計分析后得到的能夠代表一類檢索信息的模式化信息。由于搜索引擎中保存有用戶的檢索日志,累積了海量的用戶歷史檢索信息,通過對這些檢索信息進行有效的挖掘,就可以得到用于針對匹配一類信息檢索的檢索模式信息庫中的檢索模式。對于本發明實施例申城檢索模式的具體步驟如圖1所示,包括:101、對所獲取的已有檢索信息進行預處理。通過獲取搜索引擎中保存的用戶歷史檢索信息并對其進行整理,以便于后續步驟的文本分析。其中,預處理主要包括對檢索信息逐條地進行分詞,詞性標注,以及對各個分詞進行向量化表示等。經過處理后的檢索信息是以詞向量表示的檢索信息。通過詞向量的表示,可以實現分詞之間相關或相似的計算,比如,通過歐氏距離來衡量分詞之間的遠近,或者是通過余弦相似度計算兩個分詞之間的相關性。102、利用聚類算法將處理后的檢索信息進行聚類,得到多個分類檢索信息列表。該步驟是將對向量化的檢索信息進行聚類,也就是將可能含有相似檢索模式的檢索信息聚合在一起。進行聚類操作的前提,是出于對檢索模式在同類檢索信息中具有共性的認知,一般的,同義詞、近義詞或同位詞的上下文信息是相似的,而在用戶檢索信息中的上下文信息就包含有所要挖掘的檢索模式,由于檢索模式一般是通過詞向量表示的形式加以保存,那么,相反的,通過分析檢索信息的詞向量表示,就可以總結出對應的檢索模式。因此,本步驟中的核心就是如何將具有相似的上下文信息的檢索信息聚類到一起。一般的,檢索信息都比較短小,因此,絕大所述的檢索信息中都是以名詞性詞項為核心,圍繞該詞就基本可以確定檢索信息中的上下文關系。所以,本發明實施例中,通過提取檢索信息中的名詞性詞項,來分析這些詞項的語義關系,即判斷哪些名詞性分詞具有同義詞、近義詞或同位詞的關系,將含有該關系分詞的檢索信息聚類到一起,再分析其中所具有的相似的上下文關系,即檢索模式。103、從分類檢索信息列表中提取對應的檢索模式。上一步是將已有的檢索信息通過聚類算法分為多個分類檢索信息列表,每一個分類檢索信息列表中存儲有一類的檢索信息。一般的,認為這一類的檢索信息中會包含有同一類的檢索模式,也就是根據檢索信息中的非名詞性分詞的排序方式,來確定對應的檢索模式。而在確定出的檢索模式中含有的名詞性分詞的數量決定了該檢索模式的階數,階數越高,說明用戶檢索的一類信息的關聯計算的維度也就越大,對應得到的檢索結果也就可能越滿足用戶的檢索意圖,從而提高檢索準確性。上述本發明實施例提供的一種基于搜索引擎的檢索模式生成方法,通過對搜索引擎保存的已有檢索信息進行詞向量表示,利用聚類算法將具有相似上下文信息的檢索信息進行聚類,再從聚合在一起的檢索信息中提取對應的檢索模式。相對于現有的檢索模式的挖掘方法,本發明所采用的方法通過對檢索信息的預處理,可以有效的減少遍歷語料的次數,通過聚類算法將具有潛在檢索模式的檢索信息進行聚類,在同一類的檢索信息中進行挖掘,大幅提高了檢索模式的純凈度,同時提高的檢索模式的挖掘速率,從而提高到了創建檢索模式的效率,使得搜索引擎在更新檢索模式時能夠快速完成,為使用搜索引擎的用戶提供更佳的檢索服務。進一步的,為了更加詳細的說明上述的基于搜索引擎的檢索模式生成方法在實際應用中的具體實現,特別是對檢索信息的詞向量表示過程以及檢索模式的挖掘方法,以下實施例中將根據上述實施例中的步驟逐一進行詳細說明,具體包括:步驟101:對所獲取的已有檢索信息進行預處理。本步驟中,對于檢索信息的預處理主要是對所保存的已有檢索信息進行的自然語言處理,其中,主要包括如下環節,如圖2所示,包括:201、將所獲取的已有檢索信息逐條添加到有第一檢索信息列表中。其中,在該第一檢索信息列表中,每一行記錄有一條檢索信息,例如,表中的一行為“從霍山到英山有多遠”。而這些檢索信息都是搜索引擎記錄的用戶曾經檢索過的檢索信息。將該第一檢索信息列表以文件的形式加以保存。需要說明的是,在向第一檢索信息列表中添加檢索信息時,不需要對檢索信息進行去重處理。202、對第一檢索信息列表中的檢索信息進行分詞以及詞性標注處理,從而得到第二檢索信息列表和第三檢索信息列表。其中,將分詞后的檢索信息保存在第二檢索信息列表中,將對分詞標注有詞性信息的檢索信息保存在第三檢索信息列表中。也就是說,第二檢索信息列表所保存的檢索信息與第一檢索信息列表中相對應,而區別在于第二檢索信息列表中的檢索信息進行了分詞處理,例如,在該表中的一行檢索信息為“從霍山到英山有多遠”。與此向類似的,第三檢索信息列表中的檢索信息是在第二檢索信息列表中的內容基礎上進行的詞性標注,每行中記載了檢索信息和詞性標注的分詞結果,例如,在該表中的一行檢索信息為“從霍山到英山有多遠從:p霍山:ns到:p英山:ns有:v多:m遠:a”。下表示出了部分詞性標注的對照表:表1:部分詞性標注對照表n名詞v動詞nd方位詞p介詞nh人名a(adj)形容詞nl處所詞clas量詞ns地名conj連詞nt時間詞ron代詞nz其他專名num數詞b區別詞ques疑問詞i成語,習語adv副詞j簡稱echo擬聲詞203、利用文本深度表示模型word2vec對第二檢索信息列表中的分詞進行向量化表示,將向量化的分詞存儲在詞向量文件中。其中,文本深度表示模型word2vec是Google在2013年年中開源的一款將詞表征為實數值向量的高效工具,其利用深度學習的思想,可以通過訓練,把對文本內容的處理簡化為K維向量空間中的向量運算,而向量空間上的相似度可以用來表示文本語義上的相似度。Word2vec輸出的詞向量可以被用來做很多NLP(Neuro-LinguisticProgramming,神經語言程序學)相關的工作,比如聚類、找同義詞、詞性分析等。在使用word2vec對第二檢索信息列表中的分詞進行向量化表示時,該模型的中的K維向量空間可根據實際需要進行自定義設置,例如,設置K的值為300是,對應的word2vec的參數為“-cbow1-size300-window8-negative25-hs0-sample1e-4-threads24-binary0-iter15”。經過文本深度表示模型word2vec的處理后,第二檢索信息列表中的分詞以詞向量的形式加以表示。同時,將這些分詞的詞向量保存在一個詞向量文件中。204、提取第三檢索信息列表中詞性標注為名詞性的分詞,并將該分詞添加到分詞列表中。其中,分詞列表中記錄有分詞以及所述分詞在第三檢索信息列表中出現的次數。例如,分詞列表中的一行顯示為:“霍山”,有180萬行。此外,具有名詞性的詞性標注主要包括:n、nd、nh、nl、ns、nt、nz、b、i、j,具體的對照請參照上述的表一。通過上述的預處理環節后,可以將所獲取的已有檢索信息處理為第一檢索信息列表、第二檢索信息列表、第三檢索信息列表和分詞列表,以及詞向量文件。步驟102:利用聚類算法將處理后的檢索信息進行聚類,得到多個分類檢索信息列表。本步驟中所執行的聚類操作是創建檢索模式的核心步驟,其執行過程主要是獲取檢索信息中的名詞性分詞,再根據文本深度表示模型word2vec中的歐氏距離,選擇這些詞分詞的鄰近分詞,并將含有這些分詞或鄰近分詞的檢索信息聚類到一起,得到一個分類檢索信息列表。對此,具體的實現需要基于上述步驟中對檢索信息進行的預處理結果,其詳細步驟如圖3所示,包括:301、在詞向量文件中查找分詞列表中分詞的向量值。其中,所查找的分詞是對分詞列表中的每一個分詞逐一地進行提取。302、根據向量值計算分詞列表中任意兩個分詞間的歐氏距離。通過該步驟的計算就可以得到所提取的分詞與該分詞列表中其他分詞的歐氏距離值。其中,歐氏距離是一個通常采用的距離定義,指在m維空間中兩個點之間的真實距離,或者向量的自然長度(即該點到原點的距離)。在二維和三維空間中的歐氏距離就是兩點之間的實際距離。而關于具體的歐氏距離的計算過程本發明實施例不進行具體說明。303、對分詞列表中每個分詞提取預置數量的鄰近分詞,組成分詞組。其中,鄰近分詞是指根據歐氏距離計算后,按照由近至遠的排序選擇的一組距離最近的分詞。而預置數量的大小決定了分類檢索信息列表中所含有的檢索信息的具體數量,數量的大小又會影響到所提取的檢索模式,因此,該預置數量的設定往往需要根據實際檢索信息的數量而確定,一般為經驗值。以上文中的“霍山”為例,與其歐氏距離較近的分詞多為縣級行政單位,如下表:表2:霍山的近鄰詞項,根據word2vec的歐氏距離排序霍山涇縣廣德浦城金寨都昌瑞昌石城桐梓永修宿松渦陽修水繁昌彭澤沅江此外,需要指出的是,所得到的分詞組是對分詞列表中的所有分詞進行的分配。也就是說,一個分詞經過分配后只出現在一個分詞組中。304、在第一檢索信息列表中提取含有分詞組中至少一個分詞的檢索信息。根據得到的分詞組,遍歷第一檢索信息列表中的所有檢索信息,將含有該分詞組中至少一個分詞的檢索信息進行復制并提取出來。305、將提取的檢索信息保存在一個分類檢索信息列表中。執行該步驟后得到的分類檢索信息列表中記錄有一批具有相似上下文的檢索信息,如下表所示:表3:一個分類檢索信息列表中的部分檢索信息內容從青島到徐州有多遠從河南周口到北京有多遠從海口到泰州有多遠從煙臺到鞍山有多遠從碭山到蒙城有多遠從太康到夏邑有多遠從柘城到夏邑有多遠從霍山到英山有多遠從集寧市到興和縣有多遠需要指出的是,通過一組分詞將得到對應的一個分類檢索信息列表,通過對不同的分詞組在第一檢索信息列表中提取對應的檢索信息,就會生成多個分類檢索信息列表。步驟103:從分類檢索信息列表中提取對應的檢索模式。根據上述步驟102中得到的多個分類檢索信息列表,本發明實施例中提取檢索模式的具體流程如圖4所示,包括:401、通過FPGrowth算法逐一計算每個分類檢索信息列表中的頻繁項集合。FPGrowth算法是韓家煒等人在2000年提出的關聯分析算法,它采取如下的分治策略:將提供頻繁項集的數據庫壓縮到一棵頻繁模式樹(FP-tree),但仍保留項集關聯信息。FPGrowth算法主要分為兩個步驟:FP-tree構建、遞歸挖掘FP-tree。FP-tree構建通過兩次數據掃描,將原始數據中的事務壓縮到一個FP-tree樹,該FP-tree類似于前綴樹,相同前綴的路徑可以共用,從而達到壓縮數據的目的。接著通過FP-tree找出每個項目的條件模式基、條件FP-tree,遞歸的挖掘條件FP-tree得到所有的頻繁項集。對于具體的計算過程在本發明實施例中做詳細說明。在該步驟中,由于每個分類檢索信息列表中各條檢索信息中的名詞性分詞都是同義詞、近義詞或同位詞等具有較高關聯關系的分詞,因此,檢索信息具有相似的上下文,所對應提取的檢索模式也屬于同一類的檢索模式。也就是說,針對一個分類檢索信息列表計算出的頻繁項集可能存在多個,對此,將得到的頻繁項集以列表的形式加以保存,就得到了頻繁項集合,該集合中包含有多個頻繁項集,以及每個頻繁項集多出現的頻數。下表示例性地展示了一個分類檢索信息列表經過計算后得到的部分頻繁項集。表4:頻繁項集合中的部分頻繁項集頻繁項集頻數有、和、不同1110到、坐、車、從、去196到、從、遠、多、有2923402、調整頻繁項集中頻繁項的順序,生成分類檢索信息列表對應的檢索模式。首先,由于FPGrowth算法所產生的頻繁項集中的頻繁項是無序的,因此,需要將無序的頻繁項轉換成有序的頻繁項,一個有序的頻繁項集就是一個檢索模式。具體的順序轉換過程包括:提取頻繁項集中的一組頻繁項,將這組頻繁項代入分類檢索信息列表中進行匹配,提取含有這一組頻繁項的檢索信息。需要指出的是,該檢索信息中需要包含這組頻繁項中的所有頻繁項。之后,將所提取的檢索信息中使用通用符替換所有非頻繁項的分詞,將含有通用符和這組頻繁項的信息確定為分類檢索信息列表所對應的檢索模式,其中,含有通用符和這組頻繁項的信息中的分詞順序是按照原檢索信息中分詞的順序排列的。例如,設定通用符為“#”,頻繁集“到、從、遠、多、有”,進過匹配后得到的原始檢索信息之一是“從霍山到英山有多遠”,經過替換后生成的一個檢索模式“從#到#有多遠”,如果還匹配到另一個檢索信息為“坐車從霍山到英山有多遠”,經過替換后生成的另一個檢索模式“#從#到#有多遠”。可見,一個頻繁項集中根據頻繁項排序的不同就可以生成多個不同的檢索模式。其次,當一個頻繁項集中產生過個不同的檢索模式時,為了確保檢索模式的代表性,在得到所有的檢索模式后,將對所有的檢索模式進行統計,將相同的檢索模式進行合并,并累加合并的個數。根據預設的閾值,保留累加個數大于該閾值的檢索模式,確定這些檢索模式為有效、可用的檢索模式。在完成一個分類檢索信息列表中所對應的檢索模式的挖掘后,統計各個分類檢索信息列表對應的檢索模式,將其保存在檢索模式信息庫中,得到的檢索模式以列表的形式加以展示,每個檢索模式根據所替換的通用符的個數確定檢索模式的階數,下表示例性的展示了部分的檢索模式,該表中的檢索模式根據階數的遞增進行排序展示:表5:檢索模式信息庫中的部分檢索模式以上詳細說明了基于搜索引擎的檢索模式生成方法在實際應用中的具體實現,作為實現上述方法的具體裝置,本發明實施例還提供了一種基于搜索引擎的檢索模式生成裝置,如圖5所示,該裝置包括:處理單元51,用于對所獲取的已有檢索信息進行預處理,得到詞向量表示的檢索信息;聚類單元52,用于利用聚類算法將所述處理單元處理后的檢索信息進行聚類,得到多個分類檢索信息列表,所述分類檢索信息列表中記錄有相似上下文信息的檢索信息;提取單元53,用于從所述聚類單元得到的分類檢索信息列表中提取對應的檢索模式,所述檢索模式是能夠代表一類檢索信息的模式化信息。進一步的,如圖6所示,所述處理單元51包括:第一處理模塊511,用于將所獲取的已有檢索信息逐條添加到有第一檢索信息列表中;第二處理模塊512,用于對所述第一處理模塊511得到的第一檢索信息列表中的檢索信息進行分詞以及詞性標注處理,得到第二檢索信息列表和第三檢索信息列表,所述第二檢索信息列表中保存有分詞后的檢索信息,所述第三檢索信息列表中保存有對分詞結果進行詞性標注的檢索信息;第三處理模塊513,用于利用文本深度表示模型word2vec對所述第二處理模塊512得到的第二檢索信息列表中的分詞進行向量化表示,將所述向量化的分詞存儲在詞向量文件中;第四處理模塊514,用于提取所述第二處理模塊512得到的第三檢索信息列表中詞性標注為名詞性的分詞,將所述分詞添加到分詞列表中,所述分詞列表中記錄有分詞以及所述分詞在所述第三檢索信息列表中出現的次數。進一步的,如圖6所示,所述聚類單元52包括:查找模塊521,用于在所述詞向量文件中查找所述分詞列表中分詞的向量值;計算模塊522,用于根據所述查找模塊521查詢到的向量值計算所述分詞列表中任意兩個分詞間的歐氏距離;組合模塊523,用于對所述分詞列表中每個分詞提取預置數量的鄰近分詞,組成分詞組,所述鄰近分詞是根據所述計算模塊522計算的歐氏距離進行由近至遠排序得到的分詞;提取模塊524,用于在所述第一檢索信息列表中提取含有所述組合模塊523組成的分詞組中至少一個分詞的檢索信息;存儲模塊525,用于將所述提取模塊524提取的檢索信息保存在一個分類檢索信息列表中。進一步的,如圖6所示,所述提取單元53包括:計算模塊531,用于利用FPGrowth算法逐一計算每個分類檢索信息列表中的頻繁項集合,所述頻繁項集合含有至少一個頻繁項集;生成模塊532,用于調整所述計算模塊531得到的頻繁項集中頻繁項的順序,生成所述分類檢索信息列表對應的檢索模式。進一步的,如圖6所示,所述生成模塊532包括:提取子模塊5321,用于提取所述頻繁項集中的一組頻繁項;匹配子模塊5322,用于在所述分類檢索信息列表中匹配含有所述提取子模塊5321提取的一組頻繁項的檢索信息;替換子模塊5323,用于將所述匹配子模塊5322得到的檢索信息中非頻繁項的分詞替換為通用符;確定子模塊5324,用于將含有所述替換子模塊5323替換的通用符和所述一組頻繁項且按照所述檢索信息中的分詞排序排列的信息確定為所述分類檢索信息列表對應的檢索模式。進一步的,如圖6所示,所述生成模塊532還包括:計算子模塊5325,用于統計所述確定子模塊5324所生成的檢索模式,計算所生成的相同檢索模式的個數;存儲子模塊5326,用于保留所述計算子模塊5325計算的個數大于預置閾值的檢索模式。綜上所述,本發明實施例所提供的一種基于搜索引擎的檢索模式生成方法及裝置,通過對搜索引擎保存的已有檢索信息進行詞向量表示,利用聚類算法將具有相似上下文信息的檢索信息進行聚類,再從聚合在一起的檢索信息中提取對應的檢索模式。相對于現有的檢索模式的挖掘方法,本發明所采用的方法通過對檢索信息的預處理,可以有效的減少遍歷語料的次數,通過聚類算法將具有潛在檢索模式的檢索信息進行聚類,在同一類的檢索信息中進行挖掘,大幅提高了檢索模式的純凈度,同時提高的檢索模式的挖掘速率,從而提高到了創建檢索模式的效率,使得搜索引擎在更新檢索模式時能夠快速完成,為使用搜索引擎的用戶提供更佳的檢索服務。在上述實施例中,對各個實施例的描述都各有側重,某個實施例中沒有詳述的部分,可以參見其他實施例的相關描述。可以理解的是,上述云端服務器及裝置中的相關特征可以相互參考。另外,上述實施例中的“第一”、“第二”等是用于區分各實施例,而并不代表各實施例的優劣。所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的系統,裝置和單元的具體工作過程,可以參考前述云端服務器實施例中的對應過程,在此不再贅述。在此提供的算法和顯示不與任何特定計算機、虛擬系統或者其它設備固有相關。各種通用系統也可以與基于在此的示教一起使用。根據上面的描述,構造這類系統所要求的結構是顯而易見的。此外,本發明也不針對任何特定編程語言。應當明白,可以利用各種編程語言實現在此描述的本發明的內容,并且上面對特定語言所做的描述是為了披露本發明的最佳實施方式。在此處所提供的說明書中,說明了大量具體細節。然而,能夠理解,本發明的實施例可以在沒有這些具體細節的情況下實踐。在一些實例中,并未詳細示出公知的云端服務器、結構和技術,以便不模糊對本說明書的理解。類似地,應當理解,為了精簡本發明并幫助理解各個發明方面中的一個或多個,在上面對本發明的示例性實施例的描述中,本發明的各個特征有時被一起分組到單個實施例、圖、或者對其的描述中。然而,并不應將該公開的云端服務器解釋成反映如下意圖:即所要求保護的本發明要求比在每個權利要求中所明確記載的特征更多的特征。更確切地說,如下面的權利要求書所反映的那樣,發明方面在于少于前面公開的單個實施例的所有特征。因此,遵循具體實施方式的權利要求書由此明確地并入該具體實施方式,其中每個權利要求本身都作為本發明的單獨實施例。本領域那些技術人員可以理解,可以對實施例中的設備中的模塊進行自適應性地改變并且把它們設置在與該實施例不同的一個或多個設備中。可以把實施例中的模塊或單元或組件組合成一個模塊或單元或組件,以及此外可以把它們分成多個子模塊或子單元或子組件。除了這樣的特征和/或過程或者單元中的至少一些是相互排斥之外,可以采用任何組合對本說明書(包括伴隨的權利要求、摘要和附圖)中公開的所有特征以及如此公開的任何云端服務器或者設備的所有過程或單元進行組合。除非另外明確陳述,本說明書(包括伴隨的權利要求、摘要和附圖)中公開的每個特征可以由提供相同、等同或相似目的的替代特征來代替。此外,本領域的技術人員能夠理解,盡管在此所述的一些實施例包括其它實施例中所包括的某些特征而不是其它特征,但是不同實施例的特征的組合意味著處于本發明的范圍之內并且形成不同的實施例。例如,在下面的權利要求書中,所要求保護的實施例的任意之一都可以以任意的組合方式來使用。本發明的各個部件實施例可以以硬件實現,或者以在一個或者多個處理器上運行的軟件模塊實現,或者以它們的組合實現。本領域的技術人員應當理解,可以在實踐中使用微處理器或者數字信號處理器(DSP)來實現根據本發明實施例的發明名稱(如確定網站內連接等級的裝置)中的一些或者全部部件的一些或者全部功能。本發明還可以實現為用于執行這里所描述的云端服務器的一部分或者全部的設備或者裝置程序(例如,計算機程序和計算機程序產品)。這樣的實現本發明的程序可以存儲在計算機可讀介質上,或者可以具有一個或者多個信號的形式。這樣的信號可以從因特網網站上下載得到,或者在載體信號上提供,或者以任何其他形式提供。應該注意的是上述實施例對本發明進行說明而不是對本發明進行限制,并且本領域技術人員在不脫離所附權利要求的范圍的情況下可設計出替換實施例。在權利要求中,不應將位于括號之間的任何參考符號構造成對權利要求的限制。單詞“包含”不排除存在未列在權利要求中的元件或步驟。位于元件之前的單詞“一”或“一個”不排除存在多個這樣的元件。本發明可以借助于包括有若干不同元件的硬件以及借助于適當編程的計算機來實現。在列舉了若干裝置的單元權利要求中,這些裝置中的若干個可以是通過同一個硬件項來具體體現。單詞第一、第二、以及第三等的使用不表示任何順序。可將這些單詞解釋為名稱。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1