一種基于相似度比較的URL去重方法和系統與流程
本發明涉及一種網絡信息排序技術,具體地說涉及一種基于相似度比較的URL去重方法和系統。
背景技術:
隨著互聯網信息爆炸式增長,每一天互聯網中的數據都呈現幾何式的堆加。用戶需要的信息往往會淹沒于大量無關信息中,利用搜索引擎獲取感興趣的信息已經成為人們獲取信息較為便捷的方式。作為搜索引擎的基礎構件之一的網絡爬蟲,需要從互聯網上搜集信息,為用戶提供數據來源。搜索結果是否豐富、獲得的信息是否沒有重合,均與網絡爬蟲的效率緊密相關。海量的數據對網絡爬蟲的設計與實現提出了更高的要求,構建分布式網絡爬蟲系統是一個有效的解決方案。相應地,作為網絡爬蟲核心關鍵技術的URL(統一資源定位符)排重方法對爬蟲系統的性能影響尤為重要。
目前已有的URL去重方法主要有基于內存的去重和基于數據庫的去重。在基于內存的URL去重方式中,爬蟲將系統URL全部放在內存中,并使用一個易于查找的數據結構(如哈希表)進行維護,由于哈希函數僅是將任意長度的二進制值映射為固定長度的較小二進制的一個簡單換算,而URL所包含網頁內容較多時,僅憑哈希值可能有較大誤差。
技術實現要素:
為此,本發明所要解決的技術問題在于現有技術中采用哈希函數的布隆過濾器去重存在較大誤差,去重效率低。
為解決上述技術問題,本發明所采用的技術方案:
一種基于相似度比較的URL去重方法,包含以下步驟:
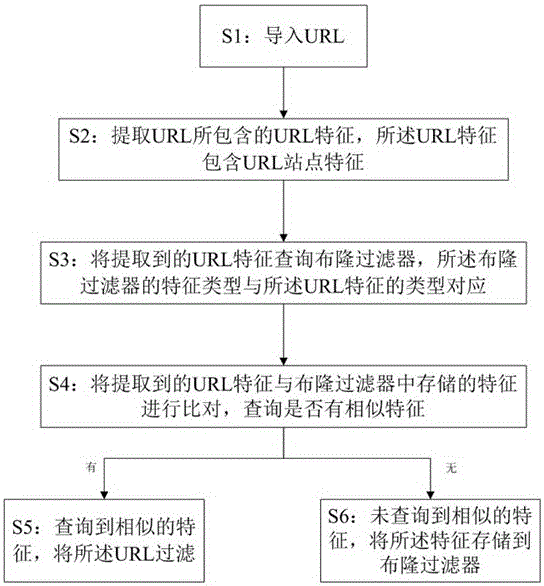
S1:導入URL;
S2:提取URL所包含的URL特征,所述URL特征包含URL站點特征;
S3:將提取到的URL特征查詢布隆過濾器,所述布隆過濾器的特征類型與所述URL特征的類型對應;
S4:將提取到的URL特征與布隆過濾器中存儲的特征進行比對,查詢是否有相似特征,若有,則進行S5步驟;若無,則進行S6步驟;
S5:查詢到相似的特征,將所述URL過濾;
S6:未查詢到相似的特征,將所述特征存儲到布隆過濾器。
所述URL特征還包含URL目錄深度特征。
所述URL特征還包含URL一級目錄特征。
所述URL特征還包含URL尾頁特征。
步驟S4中將提取到的URL特征分別做換算操作,得到其在布隆過濾器中對應的bit位信息,查詢布隆過濾器中對應類型的特征的bit位信息,若二者均為1,則認為二者為相似特征。
一種基于相似度比較的URL去重系統,包含以下模塊:
接收模塊:導入URL;
提取模塊:提取URL所包含的URL特征,所述URL特征包含URL站點特征;
布隆過濾器模塊:將提取到的URL特征查詢布隆過濾器,所述布隆過濾器的特征類型與所述URL特征的類型對應;
特征比對模塊:將提取到的URL特征與布隆過濾器中存儲的特征進行比對,查詢是否有相似特征,若有,則轉入過濾模塊;若無,則轉入更新模塊;
過濾模塊:查詢到相似的特征,將所述URL過濾;
更新模塊:未查詢到相似的特征,將所述特征存儲到布隆過濾器。
所述URL特征還包含URL目錄深度特征。
所述URL特征還包含URL一級目錄特征。
所述URL特征還包含URL尾頁特征。
特征比對模塊將提取到的URL特征分別做換算操作,得到其在布隆過濾器中對應的bit位信息,查詢布隆過濾器中對應類型的特征的bit位信息,若二者均為1,則認為二者為相似特征。
本發明的上述技術方案相比現有技術具有以下優點。
本發明的一種基于相似度比較的URL去重方法和系統,通過導入URL并提取URL的特征,將URL特征與布隆過濾器進行比對,如果查詢到布隆過濾器中存儲有該URL特征對應的特征,則過濾該URL,所述URL特征包括一種以上的特征,代替了現有技術中的哈希函數,可以匹配更準確的URL網頁數據。通過相似度比較并過濾可以快速、準確解決網頁頁面重復或相似的重復爬行或掃描工作,可以提高爬蟲以及掃描的有效性和效率。
附圖說明
為了使本發明的內容更容易被清楚的理解,下面根據本發明的具體實施例并結合附圖,對本發明作進一步詳細的說明,其中,
圖1為本發明一種基于相似度比較的URL去重方法的流程圖;
圖2為本發明一種基于相似度比較的URL去重系統的結構框圖。
圖中附圖標記表示為:1-接收模塊;2-提取模塊;3-布隆過濾器模塊;4-特征比對模塊;5-過濾模塊;6-更新模塊。
具體實施方式
一種基于相似度比較的URL去重方法,包含以下步驟:
S1:導入URL。建立存放URL的數據庫URL_DB,一條記錄即以字符串方式存放的URL,其格式為:url = u1/u2/u3/…/un,n ≥ 1。
S2:提取URL所包含的URL特征,所述URL特征包含URL站點特征。提取URL中的站點字符節u1。用MD5算法分別計算該URL的各個字符節的特征值。即輸入站點字符節u1,輸出URL站點特征值m1每個特征值為128位唯一的二進制數字。
S3:將提取到的URL特征查詢布隆過濾器,所述布隆過濾器的特征類型與所述URL特征的類型對應。將URL特征的特征值,如m1做模N操作,得到其在布隆過濾器中對應的bit位信息。所述布隆過濾器在內存建立。針對采集URL數量的不同,在保證沖突率的基礎上,確定布隆過濾器和模N的大小,用于URL排重的布隆過濾器構建如下:
(1)通過數據規模及期望的誤判率計算所需的內存大小:
用戶輸入需要排重的URL的數據量k,以及期望的誤判率P,這也是構建布隆過濾器需要用戶輸入的僅有的兩個參數。通過公式計算所需內存的大小M bit:
(2)根據M值確定模N操作的N值大小:
S4:將提取到的URL特征與布隆過濾器中存儲的特征進行比對,例如將m1做模N操作,得到其在布隆過濾器中對應的bit位信息,并查詢布隆過濾器中站點特征值對應的bit位,兩者bit位的值是否均為1,若是則認為是具有相似特征。查詢是否有相似特征,若有,則進行S5步驟;若無,則進行S6步驟。
S5:查詢到相似的特征,則認為該URL已經在數據庫URL_DB中,將所述URL過濾。
S6:未查詢到相似的特征,即若有任意一個URL特征的值為0;則認為URL_DB中不存在該URL,將其存入URL_DB中,并將布隆過濾器中對應的bit位置為1。將所述URL特征存儲到布隆過濾器。
所述URL特征還包含URL目錄深度特征,值為n。
所述URL特征還包含URL一級目錄特征,值為m2。
所述URL特征還包含URL尾頁特征,值為mn。
步驟S4中將提取到的URL特征(n、m1、m2、mn)分別做換算(模N)操作,得到其在布隆過濾器中對應的bit位信息,查詢布隆過濾器中對應類型的特征的bit位信息,若二者均為1,則認為二者為相似特征,認為該URL已經在數據庫URL_DB中,將其廢棄。若有任一URL特征的值為0,則認為URL_DB中不存在該URL,將其存入URL_DB中,并將布隆過濾器中對應的4個bit位信息為1。還可以定義和增加更多的URL特征,并在方法的實現中選擇使用其中的特征來識別URL。
本發明所述的一種基于相似度比較的URL去重方法結合了URL的結構特征及傳統布隆過濾器的結構特征,提取URL具有代表性的多個特征屬性,通過這些屬性來代表相似的URL,并用這些不同的特征計算出特征值來映射布隆過濾器中的對應位,代替了布隆過濾器中所需的多個哈希函數。
一種基于相似度比較的URL去重系統,如圖2所示,包含以下模塊:
接收模塊1:導入URL。建立存放URL的數據庫URL_DB,一條記錄即以字符串方式存放的URL,其格式為:url = u1/u2/u3/…/un,n ≥ 1。
提取模塊2:提取URL所包含的URL特征,所述URL特征包含URL站點特征。提取URL中的站點字符節u1。用MD5算法分別計算該URL的各個字符節的特征值。即輸入站點字符節u1,輸出URL站點特征值m1每個特征值為128位唯一的二進制數字。
布隆過濾器模塊3:將提取到的URL特征查詢布隆過濾器,所述布隆過濾器的特征類型與所述URL特征的類型對應。將URL特征的特征值,如m1做模N操作,得到其在布隆過濾器中對應的bit位信息。所述布隆過濾器在內存建立。針對采集URL數量的不同,在保證沖突率的基礎上,確定布隆過濾器和模N的大小,用于URL排重的布隆過濾器構建如下:
(1)通過數據規模及期望的誤判率計算所需的內存大小:
用戶輸入需要排重的URL的數據量k,以及期望的誤判率P,這也是構建布隆過濾器需要用戶輸入的僅有的兩個參數。通過公式計算所需內存的大小M bit:
(2)根據M值確定模N操作的N值大小:
特征比對模塊4:將提取到的URL特征與布隆過濾器中存儲的特征進行比對,例如將m1做模N操作,得到其在布隆過濾器中對應的bit位信息,并查詢布隆過濾器中站點特征值對應的bit位,兩者bit位的值是否均為1,若是則認為是具有相似特征。查詢是否有相似特征,若有,則轉入過濾模塊;若無,則轉入更新模塊。
過濾模塊5:查詢到相似的特征,則認為該URL已經在數據庫URL_DB中,將所述URL過濾。
更新模塊6:未查詢到相似的特征,即若有任意一個URL特征的值為0;則認為URL_DB中不存在該URL,將其存入URL_DB中,并將布隆過濾器中對應的bit位置為1。將所述URL特征存儲到布隆過濾器。
所述URL特征還包含URL目錄深度特征,值為n。
所述URL特征還包含URL一級目錄特征,值為m2。
所述URL特征還包含URL尾頁特征,值為mn。
特征比對模塊4將提取到的URL特征(n、m1、m2、mn)分別做換算(模N)操作,得到其在布隆過濾器中對應的bit位信息,查詢布隆過濾器中對應類型的特征的bit位信息,若二者均為1,則認為二者為相似特征,認為該URL已經在數據庫URL_DB中,將其廢棄。若有任一URL特征的值為0,則認為URL_DB中不存在該URL,將其存入URL_DB中,并將布隆過濾器中對應的4個bit位信息為1。還可以定義和增加更多的URL特征,并在方法的實現中選擇使用其中的特征來識別URL。
本發明所述的一種基于相似度比較的URL去重系統結合了URL的結構特征及傳統布隆過濾器的結構特征,提取URL具有代表性的多個特征屬性,通過這些屬性來代表相似的URL,并用這些不同的特征計算出特征值來映射布隆過濾器中的對應位,代替了布隆過濾器中所需的多個哈希函數。
本發明的一種基于相似度比較的URL去重方法和系統,通過導入URL并提取URL的特征,將URL特征與布隆過濾器進行比對,如果查詢到布隆過濾器中存儲有該URL特征對應的特征,則過濾該URL,所述URL特征包括一種以上的特征,代替了現有技術中的哈希函數,可以匹配更準確的URL網頁數據。通過相似度比較并過濾可以快速、準確解決網頁頁面重復或相似的重復爬行或掃描工作,可以提高爬蟲以及掃描的有效性和效率。
顯然,上述實施例僅僅是為清楚地說明所作的舉例,而并非對實施方式的限定。對于所屬領域的普通技術人員來說,在上述說明的基礎上還可以做出其它不同形式的變化或變動。這里無需也無法對所有的實施方式予以窮舉。而由此所引伸出的顯而易見的變化或變動仍處于本發明創造的保護范圍之中。
- 還沒有人留言評論。精彩留言會獲得點贊!