手勢識別方法和系統與流程
本發明涉及圖像識別領域,特別是涉及一種手勢識別方法和系統。
背景技術:
神經網絡是一種基于仿生設計的數學模型,近年來被廣泛應用于圖像識別,語音識別等任務。
神經元的積累的刺激是由其他神經元傳遞過來的刺激量和對應的權重之和,用xj表示這種積累,yi表示某個神經元傳遞過來的刺激量,wi表示鏈接某個神經元刺激的權重,得到公式:xj=(y1*w1)+(y2*w2)+...+(yi*wi)+...+(yn*wn),而當xj完成積累后,完成積累的神經元本身對周圍的一些神經元傳播刺激,將其表示為yj得到如下所示:yj=f(xj),神經元根據積累后xj的結果進行處理后,對外傳遞刺激yj。用f函數映射來表示這種處理,將它稱之為激活函數。
卷積神經網絡是將人工神經網絡和深度學習技術相結合而產生的新型人工神經網絡方法,是為了識別二維形狀而設計的多層感知器,具有局部感知區域、層次結構化、特征抽取和分類過程結合的全局訓練的特點。fukushima提出的基于神經元之間的局部連接型和層次結構組織的neocogition模型是卷積神經網絡的第一個實現網絡。lecun等人設計并采用基于誤差梯度的算法訓練了卷積神經網絡,在一些模式識別領域取得非常好的性能,并且給出了卷積神經網絡公式的推導和證明。
卷積神經網絡已經成功地應用到了文檔分析、人臉檢測、語音檢測、車牌識別、手寫數字識別、視頻中的人體動作識別等各個方面。
技術實現要素:
本發明的主要目的是提供一種手勢識別方法和系統,其能夠準確、快速地識別出待檢測圖像中的手勢。
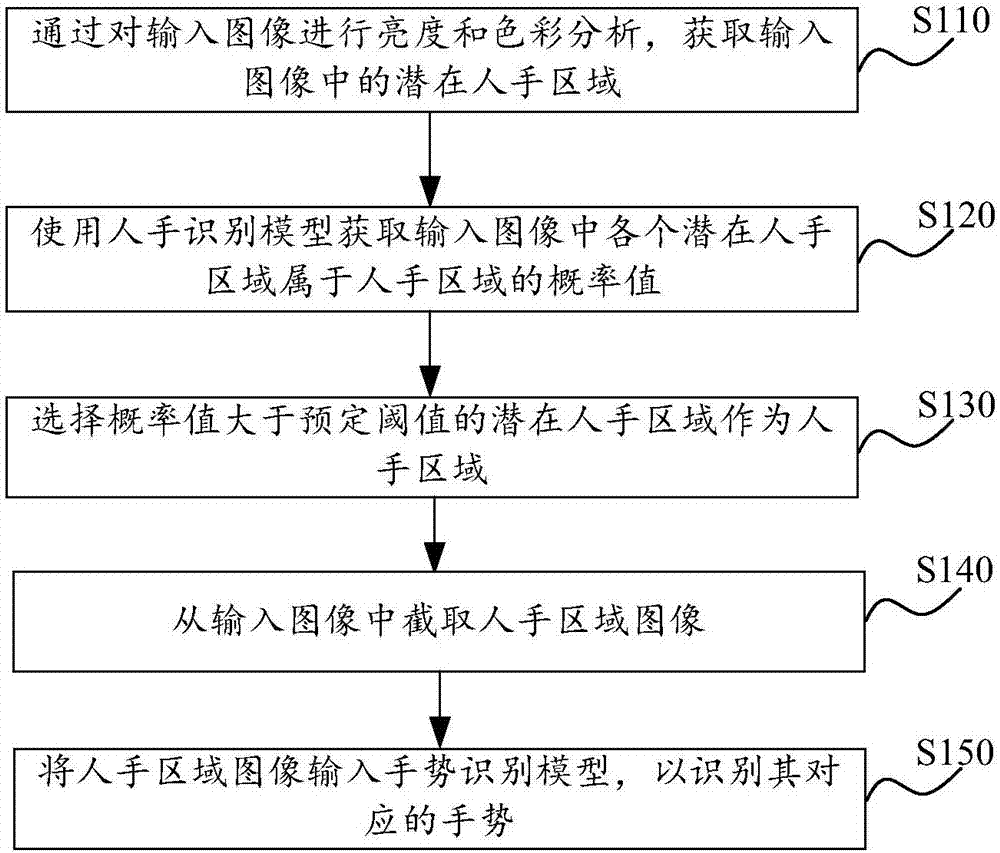
根據本發明的一個方面,提供了一種手勢識別方法,用于從輸入圖像中識別手勢,該方法包括:通過對輸入圖像進行亮度和色彩分析,獲取輸入圖像中的潛在人手區域;使用人手識別模型獲取輸入圖像中各個潛在人手區域屬于人手區域的概率值;選擇概率值大于預定閾值的潛在人手區域作為人手區域;從輸入圖像中截取人手區域圖像;以及將人手區域圖像輸入手勢識別模型,以識別其對應的手勢。
優選地,該方法還可以包括:根據人手區域的長寬比例,計算該人手區域圖像到標準人手圖像的仿射變換矩陣;使用仿射變換矩陣對人手區域圖像進行仿射變換,得到標準化的人手區域圖像,其中,將標準化的人手區域圖像輸入手勢識別模型,以識別其所對應的手勢。
優選地,通過對輸入圖像進行亮度和色彩分析獲取輸入圖像中的潛在人手區域的步驟可以包括:選擇輸入圖像中光流特征絕對值大于預設閾值且色彩屬于預設膚色區間的區域為潛在人手區域。
優選地,該方法還可以包括:在確定人手區域后,計算后續一幀或多幀輸入圖像中對應于人手區域的圖像區域的光流特征值,以確定后續一幀或多幀輸入圖像中的人手區域。
優選地,在對輸入圖像進行亮度和色彩分析之前,該方法還可以包括:對輸入圖像進行檢測,以確定用戶是否發出預定肢體動作;在檢測到用戶發出預定肢體動作的情況下,執行對輸入圖像進行亮度和色彩分析的步驟。
優選地,在獲取輸入圖像中的潛在人手區域之后,該方法還可以包括:基于預定的模型或算法,識別出輸入圖像中的人臉潛在區域和/或人體潛在區域;根據識別出的人臉潛在區域和/或人體潛在區域,刪除處于不合理范圍的潛在人手區域。
優選地,該方法還可以包括:對輸入圖像進行多尺度縮放,以得到不同尺度的輸入圖像;對不同尺度的輸入圖像執行對輸入圖像進行亮度和色彩分析的步驟。
優選地,人手識別模型和手勢識別模型均為卷積神經網絡模型。
根據本發明的另一個方面,還提供了一種手勢識別系統,用于從輸入圖像中識別手勢,該系統包括:存儲器,用于存儲輸入圖像;cpu模塊,用于控制fpga模塊,并對輸入圖像進行亮度和色彩分析,以獲取輸入圖像中的潛在人手區域;fpga模塊,用于在其上實現人手識別模型和手勢識別模型,其中,人手識別模型用于獲取輸入圖像中各個潛在人手區域屬于人手區域的概率值,以便選擇概率值大于預定閾值的潛在人手區域作為人手區域,并從輸入圖像中截取人手區域圖像,手勢識別模型用于從人手區域圖像中識別出對應的手勢。
優選地,cpu模塊根據人手區域的長寬比例,計算該人手區域圖像到標準人手圖像的仿射變換矩陣,該系統還可以包括:幾何變換模塊,用于使用仿射變換矩陣對人手區域圖像進行仿射變換,得到標準化的人手區域圖像,其中,手勢識別模型從標準化的人手區域圖像中識別出對應的手勢。
優選地,cpu模塊選擇輸入圖像中光流特征絕對值大于預設閾值且色彩屬于預設膚色區間的區域為潛在人手區域。
優選地,在確定人手區域后,cpu模塊計算后續一幀或多幀輸入圖像中對應于人手區域的圖像區域的光流特征值,以確定后續一幀或多幀輸入圖像中的人手區域。
優選地,在cpu模塊對輸入圖像進行亮度和色彩分析之前,cpu模塊對輸入圖像進行檢測,以確定用戶是否發出預定肢體動作,在檢測到用戶發出預定肢體動作的情況下,cpu模塊檢測對輸入圖像進行亮度和色彩分析,并控制fpga模塊,以從輸入圖像中識別手勢。
優選地,fpga模塊上還用于實現人臉識別模型和/或人體識別模型,人臉識別模型和/或人體識別模型用于識別出輸入圖像中的人臉潛在區域和/或人體潛在區域,cpu模塊根據識別出的人臉潛在區域和/或人體潛在區域,刪除處于不合理范圍的潛在人手區域,或者cpu模塊基于預定的算法,識別出輸入圖像中人臉潛在區域和/或人體潛在區域,并根據識別出的人臉潛在區域和/或人體潛在區域,刪除處于不合理范圍的潛在人手區域。
優選地,cpu模塊對輸入圖像進行多尺度縮放,以得到不同尺度的輸入圖像,cpu模塊對不同尺度的輸入圖像進行亮度和色彩分析,并控制fpga模塊,以從不同尺度的輸入圖像中識別手勢。
優選地,人手識別模型和手勢識別模型均為卷積神經網絡模型,cpu模塊還用于執行卷積神經網絡模型的全連接層的運算。
綜上,本發明的手勢識別方法首先對輸入圖像進行亮度和色彩分析,初步篩選出潛在人手區域,然后使用人手識別模型進一步篩選,以得到較為準確的人手區域,從而使得手勢識別模型可以快速、準確識別出輸入圖像中的手勢。
附圖說明
通過結合附圖對本公開示例性實施方式進行更詳細的描述,本公開的上述以及其它目的、特征和優勢將變得更加明顯,其中,在本公開示例性實施方式中,相同的參考標號通常代表相同部件。
圖1示出了根據本發明一實施例的手勢識別方法的示意性流程圖。
圖2示出了根據本發明另一實施例的手勢識別方法的示意性流程圖。
圖3示出了根據本發明一實施例的手勢識別系統的結構的示意性方框圖。
圖4示出了幾何變換模塊可以具有的功能模塊的示意性方框圖。
具體實施方式
下面將參照附圖更詳細地描述本公開的優選實施方式。雖然附圖中顯示了本公開的優選實施方式,然而應該理解,可以以各種形式實現本公開而不應被這里闡述的實施方式所限制。相反,提供這些實施方式是為了使本公開更加透徹和完整,并且能夠將本公開的范圍完整地傳達給本領域的技術人員。
隨著智能硬件設備的發展,手勢交互控制越來越多地應用于智能硬件設備中,手勢交互控制使得用戶可以通過在遠處或近處做揮手或者擺手型等手勢向智能硬件設備發出控制信號,智能硬件設備則識別用戶的信號(即識別用戶做出的手勢),根據內存中保存的該信號(即手勢)的定義做出相應的反應。
針對于此,本發明提出了一種能夠快速、準確地識別出待檢測圖像(即下文述及的輸入圖像)中的手勢的識別方案。
本發明的識別方案可以實現為一種手勢識別方法和系統。圖1示出了根據本發明一實施例的手勢識別方法的示意性流程圖。
參見圖1,在步驟s110,通過對輸入圖像進行亮度和色彩分析,獲取輸入圖像中的潛在人手區域。
其中,輸入圖像為待檢測圖像,其可以是靜態圖像,也可以是動態圖像。例如,輸入圖像可以是使用攝像裝置拍攝得到的一幅或多幅照片,也可以是使用攝像裝置拍攝得到的包含多幀圖像的視頻。
通過對輸入圖像進行亮度和色彩分析,可以得到輸入圖像中一個或多個可能屬于人手的潛在人手區域。
其中,這里述及的亮度和色彩分析可以是分析輸入圖像的亮度、色調、飽和度等信息來識別出輸入圖像中可能屬于人手的潛在人手區域。例如,可以根據大量人手圖像的亮度、色調、飽和度等信息,得出一般化人手圖像的亮度和色彩信息,然后再根據輸入圖像的亮度和色彩信息,從輸入圖像中找出與一般化人手圖像的亮度和色彩信息相近的一個或多個區域作為潛在人手區域。
另外,這里述及的亮度和色彩分析還可以是使用光流算法來計算輸入圖像中一個或多個區塊的光流特征值,初步篩選出輸入圖像中可能屬于人手的區域,然后再對其進行色彩分析,從中進一步挑選出色彩屬于預設膚色區間的區域為潛在人手區域。也就是說,可以通過光流計算和色彩分析,選擇輸入圖像中光流特征絕對值大于預設閾值且色彩屬于預設膚色區間的區域為潛在人手區域。其中,光流計算的原理為本領域技術人員公知,這里不再贅述。
需要說明的是,在計算輸入圖像中的一個或多個區塊的光流特征值時,可以讀取前后兩幀圖像,并對相同位置的像素值做差分,然后可以對原圖像或者差分后的圖像做低通濾波,根據光流算法的數學原理,對計算得到的數據進行乘累加操作,計算若干像素組成區域的位移速度向量,以得到光流特征值。其中,光流計算的具體過程為本領域技術人員所公知,這里不再詳述。
由此,正如上文所述,本文述及的輸入圖像可以包含多幀圖像,其可以是多幀靜態圖像,也可以是包含多幀圖像的視頻圖像。這樣,基于步驟s110,可以獲取一幀或多幀輸入圖像中的潛在人手區域。
在步驟s120,使用人手識別模型獲取輸入圖像中各個潛在人手區域屬于人手區域的概率值。
在步驟s130,選擇概率值大于預定閾值的潛在人手區域作為人手區域。
這里的人手識別模型可以是預先訓練得到的卷積神經網絡模型。人手識別模型可以識別出各個潛在人手區域屬于人手區域的概率值。由此,對于步驟s110獲取的潛在人手區域,可以使用人手識別模型進行進一步識別,以篩選出更為準確的潛在人手區域作為人手區域。
在使用人手識別模型對人手潛在區域進行篩選后,就可以執行步驟s140,從輸入圖像中截取人手區域圖像。然后可以執行步驟s150,將人手區域圖像輸入手勢識別模型,以識別其對應的手勢。
其中,卷積神經網絡具有高度非線性,因此手勢識別模型可以是預先訓練得到的卷積神經網絡模型,其可以識別多種預設手勢。其中,這里述及的預設手勢可以是靜態手勢,也可以是動態手勢。例如,手勢識別模型可以是訓練多張圖片到手勢類別的分類函數,以使得其可以識別動態手勢。
作為一個示例,手勢識別模型可以同時計算手勢的類別索引和人手關鍵點的位置,通過類別和位置兩種信息的融合,提高卷積神經網絡對手勢的表達性能。由此,手勢識別模型的全連接層的輸出可以是一個m+2k維向量,其中m維子向量的最大值所在的維度為m種不同手勢的索引,另外2k維子向量為人手k個關鍵點的x軸和y軸坐標。
綜上,本發明的手勢識別方法首先對輸入圖像進行亮度和色彩分析,初步篩選出潛在人手區域,然后使用人手識別模型進一步篩選,以得到較為準確的人手區域,從而使得手勢識別模型可以快速、準確識別出輸入圖像中的手勢。
圖2示出了根據本發明另一實施例的手勢識別方法的示意性流程圖。
參見圖2,首先,可以執行步驟s210的激活步驟:對輸入圖像進行檢測,以確定用戶是否發出預定肢體動作,在檢測到用戶發出預定肢體動作的情況下,執行后續的步驟。
由此,可以利用用戶的肢體動作作為本發明的人手識別方法的激活步驟。在將本發明的手勢識別方法應用于智能硬件設備中時,從設備休眠到工作之間的轉換過程,可以由用戶保持人臉和/或人體在智能硬件設備的鏡頭中,并使用預定的肢體動作(例如揮手動作)激活算法。這樣,在檢測到用戶執行了預定肢體動作后,就可以執行后續的算法步驟。
在步驟s220,獲取潛在人手區域。其中,步驟s220的具體實現可以參照上文圖1中步驟s110的相關描述,這里不再贅述。
在獲取了潛在人手區域后,就可以執行步驟s230和步驟s240,對獲取的潛在人手區域進行篩選,以篩選出更為準確的潛在人手區域作為人手區域。這里,步驟s230和步驟s240的先后執行順序沒有嚴格限定,即可以先執行步驟s230再執行步驟s240,也可以先執行步驟s240再執行步驟s230,還可以同時執行步驟s230和步驟s240。
其中,步驟s230的篩選過程可以參見上文圖1中步驟s120、步驟s130的描述,這里不再贅述。
在步驟s240,基于人體幾何屬性進行篩選。
這里,可以基于預定的模型或算法,識別出輸入圖像中的人臉潛在區域和/或人體潛在區域。
例如,可以使用預先基于卷積神經網絡的人臉識別模型和/或人體識別模型,識別出輸入圖像中的人臉潛在區域和/或人體潛在區域。再例如,還可以使用adaboost算法,計算輸入圖像中人臉和/或人體的概率分布矩陣,將概率值大于預定閾值的區域確定為人臉潛在區域和/或人體潛在區域。
根據識別出的人臉潛在區域和/或人體潛在區域,刪除處于不合理范圍的潛在人手區域。這里主要是從人體的幾何屬性考慮,篩選出處于不合理范圍的潛在人手區域,進行刪除。例如,可以根據人臉/人體和人手可能具有的幾何位置關系,刪除明顯處于不合理范圍內的潛在人手區域。
在對潛在人手區域進行篩選后,可以從輸入圖像中截取人手區域圖像。由于輸入圖像可能是在不同角度拍攝得到的,因此從輸入圖像中截取到的人手區域圖像可能與標準圖像差別較大。例如,在輸入圖像是從側面拍攝或斜向拍攝得到的人手圖像時,截取出的人手區域圖像不便于識別。因此可以對篩選后的潛在人手區域圖像進行仿射變換(步驟s250),以得到標準化的人手區域圖像。
具體地,可以根據人手區域的長寬比例,計算該人手區域圖像到標準人手圖像的仿射變換矩陣。
本發明的獲取仿射變換矩陣的一種可行的實現方式為,可以根據人手區域的長寬比例,選取人手區域多個關鍵點,然后計算將這些關鍵點映射到標準人手圖像中的相應多個標準關鍵點的仿射變換矩陣。其中,關鍵點標準位置是具有預定形狀和尺寸的標準人手圖像上的關鍵點位置,標準人手圖像可以通過對大量的人手圖像進行統計得出。
然后可以使用仿射變換矩陣對人手區域圖像進行仿射變換,以得到標準化的人手區域圖像。
具體地,設經過仿射變換后的人手區域圖像(以下簡稱目標圖像)為q,原始人手區域圖像(以下簡稱原圖像)為i,仿射變換過程的數據表達式為q[u(x,y),v(x,y)]=i[x,y],其中x,y為原圖像的地址,u,v為目標圖像的地址,且u(x,y)=a*x+b*y+c,v(x,y)=d*x+e*y+f,其中a,b,c,d,e,f均為仿射變換矩陣中的對應元素。
因此,可以根據仿射變換矩陣對原圖像中的原始行坐標和原始列坐標進行計算,即計算u(x,y)=a*x+b*y+c,得到目標圖像的目標行坐標,將原始像素的像素值寫入第二緩沖存儲器中,作為中間圖像中以目標行坐標為行坐標且以原始列坐標為列坐標的中間像素的像素值。
然后對第二緩沖存儲器中存儲的中間圖像中的每個中間像素,根據仿射變換矩陣對其目標行坐標和原始列坐標進行計算,即計算v(u,y)=d*u+e*y+f,得到目標圖像的目標列坐標,并將中間像素的像素值寫入第一緩沖存儲器中作為目標圖像中以目標行坐標為行坐標且以目標列坐標為列坐標的目標像素的像素值。由此,就可以計算得到經過仿射變換后的標準化的人手區域圖像的像素分布。
使用上面的方法進行仿射變換時,由于目標圖像的每一個像素可能依賴于原圖像中的多個像素,并且原圖像的每一個像素可能影響到目標圖像中的多個像素,這些像素難以在一個行緩沖中全部存儲。并且計算得出的目標行坐標、目標列坐標有可能不是整數,還需要進行插值計算。針對于此,本發明提出了兩步變形方案。
具體地,可以對第一幀緩沖存儲器中保存的人手區域圖像逐列進行行變換,在行變換中,使用仿射變換矩陣對人手區域圖像中具有相同原始列坐標的一列原始像素進行行變換,得到中間圖像中具有相同原始列坐標和各個目標行坐標的各中間像素的像素值,并將其寫入第二幀緩沖存儲器中,然后清空第一幀緩沖存儲器。至此,完成了兩步變形方案中的第一步,行變換。
對第二幀緩沖存儲器中保存的人手區域圖像逐行進行列變換,在列變換中,從第一幀緩沖存儲器讀取人手區域圖像的一行原始像素,使用仿射變換矩陣對中間圖像中具有相同目標行坐標的一行中間像素進行列變換,得到標準化的人手區域圖像中具有相同目標行坐標和各個目標列坐標的各目標像素的像素值,并將其寫入第一幀緩沖存儲器中,清空第二幀緩沖存儲器。
由此,本發明將仿射變換步驟劃分為行變換和列變換兩步計算。行變形部分,數學表達式為t[u(x,y),y]=i[x,y],列變形部分,數學表達式為q[u,v]=p[u,v(u,y)]=t[u(x,y),y],其中p,t為中間計算結果,本發明中的兩步變形框架很好地避免了生成目標圖像時被迫多次讀取內存的帶寬瓶頸。
其中,本發明的行變換中的一行可以是具有同一橫坐標的行,也可以是具有同一縱坐標的列。相應地,本發明的列變換中的一列可以是具有同一縱坐標的列,也可以是具有同一橫坐標的行。
在得到標準化的人手區域圖像后,就可以將標準化的人手區域圖像輸入手勢識別模型,以識別其所對應的手勢(步驟s260)。
作為本發明的一個可選實施例,在確定人手區域后,對于后續一幀或多幀輸入圖像來說,可以使用光流算法對上一幀輸入圖像中的人手區域圖像進行跟蹤,以確定后續一幀或多幀輸入圖像中的人手區域圖像,這樣可以減少運算量。
具體來說,在確定人手區域后,可以計算后續一幀或多幀輸入圖像中對應于人手區域的圖像區域的光流特征值,以確定后續一幀或多幀輸入圖像中的人手區域。
由此,本發明的手勢識別方法可以在單幀圖像內檢測人手的位置,并形成位置信息提供給后續幀,使得在后續幀計算光流并跟蹤此區域,具有更快的處理速度。
另外,對于步驟s210的激活步驟來說,在預定肢體動作為揮手動作時,可以利用光流算法快速檢測出人手所在位置,并在檢測到人手后快速跟蹤人手運動方向,這樣也減少運算量,從而提高人手的定位速度。
作為本發明的另一個可選實施例,對于輸入圖像來說,還可以對輸入圖像進行多尺度縮放,以得到不同尺度的輸入圖像,然后對不同尺度的輸入圖像執行本發明的手勢識別方法,以識別出不同尺度下的輸入圖像的手勢,這樣可以提高識別的準確度。
至此,結合圖1、圖2詳細說明了本發明的手勢識別方法。圖3示出了根據本發明一實施例的手勢識別系統的結構的示意性方框圖。其中,圖3所示的手勢識別系統可以實現上文述及的手勢識別方法,下面僅就對象識別系統的基本結構及功能進行說明,對于其中涉及的細節部分可以參見上文相關描述。
參見圖3,本發明的手勢識別系統300包括存儲器310、cpu模塊320以及fpga模塊330。
存儲器310用于存儲輸入圖像。
cpu模塊320用于控制fpga模塊330,并對輸入圖像進行亮度和色彩分析,以獲取輸入圖像中的潛在人手區域。
其中,cpu模塊320可以選擇輸入圖像中光流特征絕對值大于預設閾值且色彩屬于預設膚色區間的區域為潛在人手區域。
在確定潛在人手區域后,cpu模塊320可以計算后續一幀或多幀輸入圖像中對應于潛在人手區域的圖像區域的光流特征值,以確定后續一幀或多幀輸入圖像中的潛在人手區域。
fpga模塊330用于在其上實現人手識別模型和手勢識別模型。具體地,人手識別模型用于獲取輸入圖像中各個潛在人手區域屬于人手區域的概率值,以便選擇概率值大于預定閾值的潛在人手區域作為人手區域,并從輸入圖像中截取人手區域圖像,手勢識別模型用于從人手區域圖像中識別出對應的手勢。
其中,人手識別模型和手勢識別模型可以均為卷積神經網絡模型,cpu模塊320還可以執行卷積神經網絡模型的全連接層的運算。使用cpu模塊320計算得到的卷積神經網絡模型的全連接層的輸出可以是一個m+2k維向量,其中m維子向量的最大值所在的維度為m種不同手勢的索引,另外2k維子向量為人手k個關鍵點的x軸和y軸坐標。
另外,cpu模塊320在對輸入圖像進行亮度和色彩分析之前,還可以對輸入圖像進行檢測,以確定用戶是否發出預定肢體動作,在檢測到用戶發出預定肢體動作的情況下,cpu模塊320再對輸入圖像進行亮度和色彩分析,并控制fpga模塊,以從輸入圖像中識別手勢。
如圖3所示,作為本發明一個可選實施例,手勢識別系統300還可以包括圖中虛線框所示的幾何變換模塊340。
cpu模塊320可以根據人手區域的長寬比例,計算該人手區域圖像到標準人手圖像的仿射變換矩陣。
幾何變換模塊340可以使用仿射變換矩陣對人手區域圖像進行仿射變換,得到標準化的人手區域圖像。
這樣,手勢識別模型可以從標準化的人手區域圖像中識別出對應的手勢。
圖4示出了幾何變換模塊340可以具有的功能模塊的示意性方框圖。
參見圖4,幾何變換模塊340可以包括第一幀緩沖存儲器341、一維行變形模塊343、第二幀緩沖存儲器345以及一維列變形模塊347。
第一幀緩沖存儲器341和第二幀緩沖存儲器345分別用于保存一幀圖像。
一維行變形模塊343用于對第一幀緩沖存儲器341中保存的人手區域圖像逐列進行行變換,在行變換中,使用仿射變換矩陣對人手區域圖像中具有相同原始列坐標的一列原始像素進行行變換,得到中間圖像中具有相同原始列坐標和各個目標行坐標的各中間像素的像素值,并將其寫入第二幀緩沖存儲器345中。
一維列變形模塊347用于對第二幀緩沖存儲器345中保存的人手區域圖像逐行進行列變換,在列變換中,從第一幀緩沖存儲器341讀取人手區域圖像的一行原始像素,使用仿射變換矩陣對中間圖像中具有相同目標行坐標的一行中間像素進行列變換,得到對象標準化圖像中具有相同目標行坐標和各個目標列坐標的各目標像素的像素值,并將其寫入第一幀緩沖存儲器341中,
其中,在開始向第二幀緩沖存儲器345中寫入中間像素的像素值之前,清空第二幀緩沖存儲器345,在開始向第一幀緩沖存儲器341中寫入目標像素的像素值之前,清空第一幀緩沖存儲器341。
作為本發明一個可選實施例,fpga模塊上還可以用于實現人臉識別模型和/或人體識別模型,人臉識別模型和/或人體識別模型用于識別出輸入圖像中的人臉潛在區域和/或人體潛在區域,cpu模塊根據識別出的人臉潛在區域和/或人體潛在區域,刪除處于不合理范圍的潛在人手區域。
或者,cpu模塊基于預定的算法,識別出輸入圖像中人臉潛在區域和/或人體潛在區域,并根據識別出的人臉潛在區域和/或人體潛在區域,刪除處于不合理范圍的潛在人手區域。
作為本發明另一個可選實施例,cpu模塊320還可以對輸入圖像進行多尺度縮放,以得到不同尺度的輸入圖像,并且對不同尺度的輸入圖像進行亮度和色彩分析,并控制fpga模塊330,以從不同尺度的輸入圖像中識別手勢。
上文中已經參考附圖詳細描述了根據本發明的手勢識別方法和系統。
此外,根據本發明的方法還可以實現為一種計算機程序,該計算機程序包括用于執行本發明的上述方法中限定的上述各步驟的計算機程序代碼指令。或者,根據本發明的方法還可以實現為一種計算機程序產品,該計算機程序產品包括計算機可讀介質,在該計算機可讀介質上存儲有用于執行本發明的上述方法中限定的上述功能的計算機程序。本領域技術人員還將明白的是,結合這里的公開所描述的各種示例性邏輯塊、模塊、電路和算法步驟可以被實現為電子硬件、計算機軟件或兩者的組合。
附圖中的流程圖和框圖顯示了根據本發明的多個實施例的系統和方法的可能實現的體系架構、功能和操作。在這點上,流程圖或框圖中的每個方框可以代表一個模塊、程序段或代碼的一部分,所述模塊、程序段或代碼的一部分包含一個或多個用于實現規定的邏輯功能的可執行指令。也應當注意,在有些作為替換的實現中,方框中所標記的功能也可以以不同于附圖中所標記的順序發生。例如,兩個連續的方框實際上可以基本并行地執行,它們有時也可以按相反的順序執行,這依所涉及的功能而定。也要注意的是,框圖和/或流程圖中的每個方框、以及框圖和/或流程圖中的方框的組合,可以用執行規定的功能或操作的專用的基于硬件的系統來實現,或者可以用專用硬件與計算機指令的組合來實現。
以上已經描述了本發明的各實施例,上述說明是示例性的,并非窮盡性的,并且也不限于所披露的各實施例。在不偏離所說明的各實施例的范圍和精神的情況下,對于本技術領域的普通技術人員來說許多修改和變更都是顯而易見的。本文中所用術語的選擇,旨在最好地解釋各實施例的原理、實際應用或對市場中的技術的改進,或者使本技術領域的其它普通技術人員能理解本文披露的各實施例。
- 還沒有人留言評論。精彩留言會獲得點贊!