用于風險評估的方法、系統及構建風險評估系統的方法與流程
本發明涉及計算機科學
技術領域:
,具體而言,涉及一種用于風險評估的方法、系統及構建風險評估系統的方法。
背景技術:
:隨著社會經濟的不斷發展,人們越來越意識到保險的重要性。保險是指投保人根據合同約定,向保險人支付保險費,保險人對于合同約定的可能發生的風險所造成的損失承擔賠償保險金的行為。因此,保險人對于保險業務的風險評估極為重要。現有技術中的核保核賠等保險業務審核及風險控制,通常是利用既往經驗,通過設定包括地區、人群、客戶年齡、保險金額、保險費等維度的組合判斷標準與規則,進行日常投保、理賠業務的自動審核和人工審核的篩選。因此,需要一種新的用于風險評估的方法、系統及構建風險評估系統的方法。在所述
背景技術:
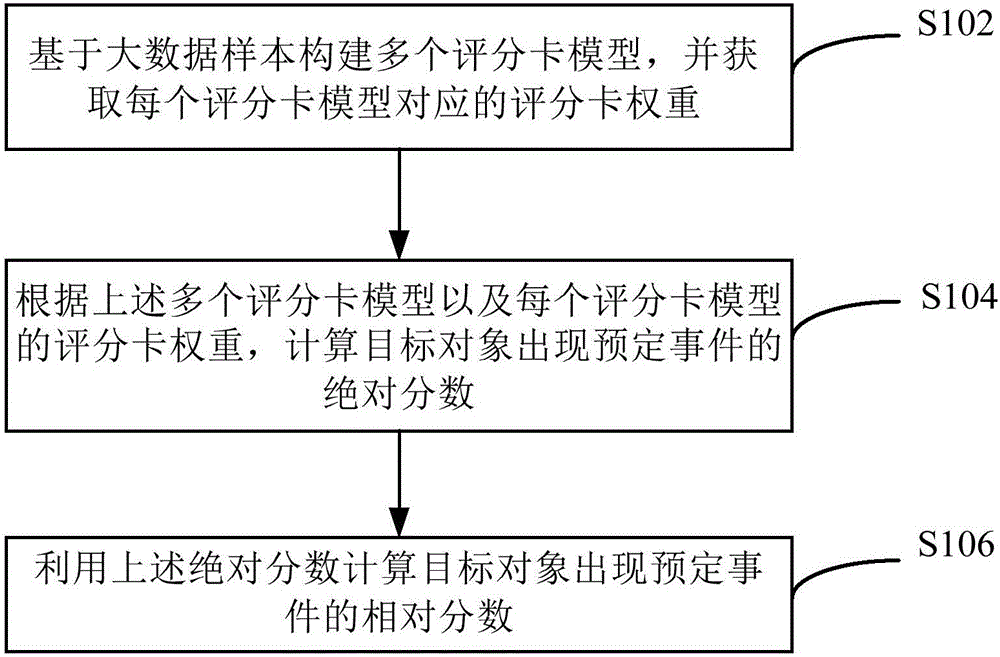
部分公開的上述信息僅用于加強對本發明的背景的理解,因此它可以包括不構成對本領域普通技術人員已知的現有技術的信息。技術實現要素:有鑒于此,本發明提供一種用于用于風險評估的方法、系統及構建風險評估系統的方法,能夠通過多個評分卡模型進行風險評分,提高了風險評估的精準度。本發明的其他特性和優點將通過下面的詳細描述變得顯然,或部分地通過本發明的實踐而習得。根據本發明的一方面,提供一種用于風險評估的方法,所述方法包括:基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重;根據所述多個評分卡模型以及所述每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數;利用所述絕對分數計算所述目標對象出現預定事件的相對分數。在本發明的一種示例性實施例中,所述基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重,包括:重復執行以下操作,直到構建的多個評分卡模型的組合模型的AUC系數滿足預設條件:根據所述大數據樣本的權重,通過logistic算法構建當前權重對應的評分卡模型;根據所述評分卡模型計算每個樣本出現預定事件的概率;根據所述概率以及所述每個樣本出現預定事件的實際值,更新所述大數據樣本的權重,并獲取所述評分卡模型對應的評分卡權重。在本發明的一種示例性實施例中,所述方法還包括:預設所述大數據樣本的初始權重。在本發明的一種示例性實施例中,所述獲取所述評分卡模型的評分卡權重,包括:根據所述每個樣本出現預定事件的概率獲取每個樣本出現預定事件的預測值;根據所述預測值以及所述每個樣本出現預定事件的實際值,計算所述評分卡模型的錯誤率;根據所述評分卡模型的錯誤率獲取所述評分卡模型的評分卡權重。在本發明的一種示例性實施例中,所述根據所述評分卡模型的錯誤率獲取所述評分卡模型的評分卡權重,包括:通過以下公式獲取所述評分卡模型的評分卡權重:其中,αm表示第m個評分卡模型的評分卡權重,εm表示第m個評分卡模型的錯誤率,m為大于或者等于1的整數。在本發明的一種示例性實施例中,所述預設條件包括:所述多個評分卡模型的組合模型的AUC系數,與下一次更新所述大數據樣本的權重構建的評分卡模型所組成的多個評分卡模型的組合模型的AUC系數的差值在預設范圍之內。在本發明的一種示例性實施例中,所述根據所述多個評分卡模型以及所述每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數,包括:通過以下公式計算所述目標對象出現預定事件的絕對分數:其中,Sm,j表示目標對象出現預定事件的絕對分數,αm表示第m個評分卡模型的評分卡權重,Pm,j表示目標對象在第m個評分卡出現預定事件的概率。在本發明的一種示例性實施例中,所述利用所述絕對分數計算所述目標對象出現預定事件的的相對分數,還包括:在預設的映射表中查找所述絕對分數,獲取所述絕對分數對應的所述目標對象出現預定事件的的相對分數。根據本發明的另一方面,提供一種用于構建風險評估系統的方法,所述方法包括:重復執行以下操作,直到構建的多個評分卡模型的組合模型的AUC系數滿足預設條件,利用所述多個評分卡模型的組合模型構建風險評估系統:根據所述大數據樣本的權重,通過logistic算法構建當前權重對應的評分卡模型;根據所述評分卡模型計算每個樣本出現預定事件的概率;根據所述概率以及所述每個樣本出現預定事件的實際值,更新所述大數據樣本的權重,并獲取所述評分卡模型對應的評分卡權重。在本發明的一種示例性實施例中,所述方法還包括:預設所述大數據樣本的初始權重。在本發明的一種示例性實施例中,所述獲取所述評分卡模型的評分卡權重,包括:根據所述預測值以及所述每個樣本出現預定事件的實際值,計算所述評分卡模型的錯誤率;根據所述評分卡模型的錯誤率獲取所述評分卡模型的評分卡權重。在本發明的一種示例性實施例中,所述根據所述評分卡模型的錯誤率獲取所述評分卡模型的評分卡權重,包括:通過以下公式獲取所述評分卡模型的評分卡權重:其中,αm表示第m個評分卡模型的評分卡權重,εm表示第m個評分卡模型的錯誤率,m為大于或者等于1的整數。在本發明的一種示例性實施例中,所述預設條件包括:所述多個評分卡模型的組合模型的AUC系數,與下一次更新所述大數據樣本的權重構建的評分卡模型所組成的多個評分卡模型的組合模型的AUC系數的差值在預設范圍之內。根據本發明的另一方面,提供一種用于風險評估的系統,所述系統包括:構建模塊,用于基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重;第一計算模塊,用于根據所述多個評分卡模型以及所述每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數;第二計算模塊,用于利用所述絕對分數計算所述目標對象出現預定事件的相對分數。在本發明的一種示例性實施例中,所述構建模塊,配置為用于重復執行以下操作,直到構建的多個評分卡模型的組合模型的AUC系數滿足預設條件:根據所述大數據樣本的權重,通過logistic算法構建當前權重對應的評分卡模型;根據所述評分卡模型計算每個樣本出現預定事件的概率;根據所述概率以及所述每個樣本出現預定事件的實際值,更新所述大數據樣本的權重,并獲取所述評分卡模型對應的評分卡權重。本發明實施例中,基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重;根據所述多個評分卡模型以及所述每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數;利用所述絕對分數計算所述目標對象出現預定事件的相對分數。通過多個評分卡模型進行風險評分,避免了單一的評分卡模型造成的風險評估不精準的問題,提高了風險評估的精準度。附圖說明通過參照附圖詳細描述其示例實施例,本發明的上述和其它目標、特征及優點將變得更加顯而易見。圖1是根據一示例性實施例示出的用于風險評估的方法的流程圖。圖2是根據一示例性實施例示出的ROC曲線的示意圖。圖3是根據一示例性實施例示出的用于構建風險評估系統的方法的流程圖。圖4是根據一示例性實施例示出的一種用于風險評估的系統的結構圖。具體實施方式現在將參考附圖更全面地描述示例實施例。然而,示例實施例能夠以多種形式實施,且不應被理解為限于在此闡述的實施例;相反,提供這些實施例使得本發明將全面和完整,并將示例實施例的構思全面地傳達給本領域的技術人員。在圖中相同的附圖標記表示相同或類似的部分,因而將省略對它們的重復描述。此外,所描述的特征、結構或特性可以以任何合適的方式結合在一個或更多實施例中。在下面的描述中,提供許多具體細節從而給出對本發明的實施例的充分理解。然而,本領域技術人員將意識到,可以實踐本發明的技術方案而沒有特定細節中的一個或更多,或者可以采用其它的方法、組元、裝置、步驟等。在其它情況下,不詳細示出或描述公知方法、裝置、實現或者操作以避免模糊本發明的各方面。附圖中所示的方框圖僅僅是功能實體,不一定必須與物理上獨立的實體相對應。即,可以采用軟件形式來實現這些功能實體,或在一個或多個硬件模塊或集成電路中實現這些功能實體,或在不同網絡和/或處理器裝置和/或微控制器裝置中實現這些功能實體。附圖中所示的流程圖僅是示例性說明,不是必須包括所有的內容和操作/步驟,也不是必須按所描述的順序執行。例如,有的操作/步驟還可以分解,而有的操作/步驟可以合并或部分合并,因此實際執行的順序有可能根據實際情況改變。需要說明的是,現有技術的技術方案中,在風險評估的精準程度和對經驗數據的深度挖掘方面仍有較大的改善空間,而且評分系統在模型構建的過程中如果樣本信息量很少,造成風險評估不精準。圖1是根據一示例性實施例示出的用于風險評估的方法的流程圖。如圖1所示,在S102中,基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重。需要說明的是,本發明實施例中提供的用于風險評估的方法可以用于多種場景,例如:對保險業務進行風險評估,對信用進行信用評估,對安全系數進行評估,對電話接通情況進行評估等。本發明實施例中以對保險業務進行風險評估為例,則預定事件可以為出險,出現概率可以為出險概率。根據示例實施例,可以重復執行以下操作,直到構建的多個評分卡模型CARD的組合模型的AUC系數滿足預設條件,獲取多個評分卡模型CARD。需要說明的是,重復執行一次S1021-S1023,就是一次循環迭代。根據示例實施例,需要為所有大數據樣本預設初始權重,例如,大數據樣本的總數為N,實際沒有出險的樣本的個數為a,實際出險的樣本個數為b為例,預設實際不會出險的樣本的初始權重為1,實際出險的樣本的初始權重設置為a/b。從而使實際出險和實際不出險的總體權重相等。S1021、根據大數據樣本的權重,通過logistic算法構建當前權重對應的評分卡模型。需要說明的是,可以通過logistic利用極大似然估計得到當前大數據樣本的權重對應的評分卡模型,例如,在SAS里可以通過proclogistic過程步得到。評分卡模型給出了各維度因素的估計值,例如,以保險業務的出險概率為例,評分卡模型可以表示維度因素(如,性別和婚姻狀況)的估計值,如表1所示,為本發明實施例提供的一種評分卡模型。維度因素觀測值估計值截距0性別男1性別女0婚姻狀況已婚1婚姻狀況未婚0表1需要說明的是,表1所示的評分卡模型中的觀測值是指樣本的每個維度因素的實際值,可以通過樣本直接得到。對于每個樣本,通過評分卡模型,可以查找其各維度因素的觀測值對應的估計值。S1022、根據該評分卡模型計算每個樣本出現預定事件的概率。可以通過如下公式計算每個樣本出險預定事件的概率。Pm,j表示根據第m個評分卡模型得到的第j個樣本的出險概率,βm0為第m個評分卡模型的截距(intercept),xi,j(i=0,1,2…)為第j個樣本的第i個維度因素對應的觀測值,βm,i(i=0,1,2…)為第j個樣本的第m個評分卡中第i個維度因素對應的估計值。例如,以表1的評分卡模型為例,假設樣本的性別為男,而且未婚,則出險概率計算為這里β0對應截距取值為0,由于第1個維度因素x1對應的取值為男,表1中β1對應的取值為1,由于第2個維度因素x2對應的取值為未婚,表1中β2對應的取值為0。S1023、根據上述概率以及每個樣本出現預定事件的實際值,更新大數據樣本的權重,并獲取上述評分卡模型對應的評分卡權重。當計算出每個評分卡模型的出險概率后,根據每個樣本出現預定事件的概率獲取每個樣本出現預定事件的預測值。評分卡模型可以看作一個分類器,傳統的2分類模型(譬如決策樹),得出的預測結果是樣本是否會出現預定事件(也就是結果只有0或1兩種情況)。本發明實施例中,通過logistic算法構建的每個評分卡模型出現預定事件的概率位于0至1之間。此時,通過設定概率閾值,將計算出的概率大于該閾值的樣本,預測會出現預定事件。將計算出的概率小于或者等于該閾值的樣本,預測不會出現預定事件。例如,本發明上述實施例中,由于實際沒有出險的樣本的個數為a,實際出險的樣本個數為b,預設實際不會出險的樣本的初始權重為1,實際出險的樣本的初始權重設置為a/b。從而使實際出險和實際不出險的總體權重都為a,因此可以選取預設概率閾值為0.5。進一步的,將計算出的每個樣本的出險概率與0.5比較,大于0.5的樣本為預測為會出險的樣本,設置預測值為1。小于或者等于0.5的樣本為預測不會出險的樣本,設置預測值為0。對應設置每個樣本是否出險的實際值(對于實際出險的樣本,設置實際值為1,對于實際沒有出險的樣本,設置實際值為0)。根據每個樣本的預測值以及實際值,更新樣本的權重可以包括多種方式,本發明實施例中示例性提供一種方式。根據每個樣本的預測值以及實際值,計算該評分卡模型的錯誤率,根據該評分卡模型的錯誤率獲取所述評分卡模型的評分卡權重。計算評分卡模型的錯誤率可以通過如下公式:εm表示第m個評分卡模型的錯誤率,yj為第j個樣本的實際值,為第j個樣本的第m個評分卡模型的預測值,ωm,j表示第j個樣本的第m個評分卡模型對應的權重,N表示樣本的總數。進一步的,通過以下公式獲取該評分卡模型的評分卡權重:其中,αm表示第m個評分卡模型的評分卡權重,εm表示第m個評分卡模型的錯誤率,m為大于或者等于1的整數。更進一步的,可以根據如下公式更新樣本的權重。其中,ωm+1,j表示第j個樣本更新的權重,αm表示第m個評分卡模型的評分卡權重。如果第j個樣本的第m個評分卡模型的預測值與該樣本的實際值相同,則ym(Xj)等于1。如果第j個樣本的第m個評分卡模型的預測值與該樣本的實際值不相同,則ym(Xj)等于-1。通過公式(4)可以增加訓練錯誤的樣本權重,減少訓練正確的樣本權重,從而加快了獲取樣本的多個評分卡模型的速率。yj為第j個樣本的實際值,為第j個樣本的第m個評分卡模型獲取的預測值,ωm,j表示第j個樣本的第m個評分卡模型對應的權重,N表示樣本的總數。需要說明的是,根據概率以及每個樣本出現預定事件的實際值,獲取該評分卡模型對應的評分卡權重的方法請參見上文,此處不再贅述。通過重復執行S1021-S1023,獲取到多個評分卡模型,以及每個評分卡模型對應的評分卡權重。當構建的多個評分卡模型的組合模型的AUC系數滿足預設條件,跳出上述循環迭代。該預設條件包括:上述多個評分卡模型的組合模型的AUC系數,與下一次更新上述大數據樣本的權重構建的評分卡模型所組成的多個評分卡模型的組合模型的AUC系數的差值在預設范圍之內。例如,該預設條件可以用以下公式表示:AUCm+1<=AUCm+Z(6)Z表示預設范圍,本發明實施提供一個經驗值0.005。需要說明的是,獲取上述多個評分卡模型的組合模型的AUC系數可以有多種方式,本發明實施例示例性提供一種方式。計算每個樣本在每個評分卡模型的出險概率以及每個評分卡模型對應的評分卡權重后,計算每個樣本在多個評分卡模型的絕對分數,將所有樣本(N個)的絕對分數取值從小到大分100等份,取每一份的最大值作為一個閾值(相當于每百分位數設定為一個閾值,共設定100個閾值),將大于這個閾值而又實際出險的預設樣本占所有出險樣本的比值設為Y軸取值,將大于這個閾值而又實際沒有出險的預定樣本占所有未出險樣本的比值設為X軸取值,得到當前閾值對應的點,這樣形成了100個點,這些點依次連起來就形成了ROC(ReceiverOperatingCharacteristic)曲線。圖2是根據一示例性實施例示出的ROC曲線的示意圖,ROC的主要分析工具是一個畫在二維平面上的曲線——ROCcurve。平面的橫坐標是falsepositiverate(FPR),縱坐標是truepositiverate(TPR)。對某個分類器而言,我們可以根據其在測試樣本上的表現得到一個TPR和FPR點對。這樣,此分類器就可以映射成ROC平面上的一個點。調整這個分類器分類時候使用的閾值,我們就可以得到一個經過(0,0),(1,1)的曲線,這就是此分類器的ROC曲線。AUC系數就是處于ROCcurve下方的那部分面積的大小。通常,AUC的值介于0.5到1.0之間,模型具有越大的AUC系數代表了模型的好壞樣本的區分度越好,模型的精準程度越高。當構建的多個評分卡模型的組合模型的AUC系數滿足預設條件,這多個評分卡模型為構建風險評估系統的多個評分卡模型。在S104中,根據上述多個評分卡模型以及每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數。根據示例實施例,可以通過以下公式計算所述目標對象出現預定事件的絕對分數:其中,Sm,j表示目標對象出現預定事件的絕對分數,αm表示第m個評分卡模型的評分卡權重,Pm,j表示目標對象在第m個評分卡出現預定事件的概率。在S106中,利用上述絕對分數計算目標對象出現預定事件的相對分數。根據示例實施例,在預設的映射表中查找所述該絕對分數,獲取所述該絕對分數對應的所述該目標對象出現預定事件的的相對分數。例如,通過將S102中的N個樣本的絕對分數劃分為連續的100個區間,每一所述區間對應一個相對值分數,因此將可以將絕對分數轉換為相對分數。例如,將1000萬個樣本的絕對分數劃分為100個連續的區間,每個區間10萬個數據,將這1000萬個樣本的絕對分數按照大小劃分到這100個區間內,如,絕對分數最低的10萬個數據劃分到第1個區間,這個區間內絕對分數的最大值為0.5,則當目標對象的絕對分數小于或者等于0.5時,對應的相對分數為1。但本發明不限于此,例如,將大量樣本的絕對分數劃分為連續的10個或50個或1000個區間,每一區間對應一個相對分數,因此可以進行其他精度的評分,本示例實施方式中對此不做特殊限定。本發明實施例中,基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重;根據所述多個評分卡模型以及所述每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數;利用所述絕對分數計算所述目標對象出現預定事件的相對分數。通過多個評分卡模型進行風險評分,避免了單一的評分卡模型造成的風險評估不精準的問題,提高了風險評估的精準度。圖3是根據一示例性實施例示出的用于構建風險評估系統的方法的流程圖,包括:重復執行以下操作,直到構建的多個評分卡模型的組合模型的AUC系數滿足預設條件,利用所述多個評分卡模型的組合模型構建風險評估系統:S302、根據大數據樣本的權重,通過logistic算法構建當前權重對應的評分卡模型;根據示例實施例,預設大數據樣本的初始權重。S304、根據所述評分卡模型計算每個樣本出現預定事件的概率;S306、根據所述概率以及所述每個樣本出現預定事件的實際值,更新所述大數據樣本的權重,并獲取所述評分卡模型對應的評分卡權重。根據示例實施例,根據所述預測值以及所述每個樣本出現預定事件的實際值,計算所述評分卡模型的錯誤率,根據所述評分卡模型的錯誤率獲取所述評分卡模型的評分卡權重。根據示例實施例,通過以下公式獲取所述評分卡模型的評分卡權重:其中,αm表示第m個評分卡模型的評分卡權重,εm表示第m個評分卡模型的錯誤率,m為大于或者等于1的整數。所述預設條件包括:所述多個評分卡模型的組合模型的AUC系數,與下一次更新所述大數據樣本的權重構建的評分卡模型所組成的多個評分卡模型的組合模型的AUC系數的差值在預設范圍之內。本發明實施例中,利用多個評分卡模型構建風險評估系統,避免了單一的評分卡模型造成的風險評估不精準的問題,提高了風險評估的精準度。下述為本發明系統實施例,可以用于執行本發明方法實施例。在下文對系統的描述中,與前述方法相同的部分,將不再贅述。圖4是根據一示例性實施例示出的一種用于風險評估的系統的結構圖。如圖4所示,該系統40包括:構建模塊410,用于基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重;第一計算模塊420,用于根據所述多個評分卡模型以及所述每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數;第二計算模塊430,用于利用所述絕對分數計算所述目標對象出現預定事件的相對分數。根據示例實施例,所述構建模塊410,配置為用于重復執行以下操作,直到構建的多個評分卡模型的組合模型的AUC系數滿足預設條件:根據所述大數據樣本的權重,通過logistic算法構建當前權重對應的評分卡模型;根據所述評分卡模型計算每個樣本出現預定事件的概率;根據所述概率以及所述每個樣本出現預定事件的實際值,更新所述大數據樣本的權重,并獲取所述評分卡模型對應的評分卡權重。本發明實施例中,基于大數據樣本構建多個評分卡模型,并獲取每個評分卡模型對應的評分卡權重;根據所述多個評分卡模型以及所述每個評分卡模型的評分卡權重,計算目標對象出現預定事件的絕對分數;利用所述絕對分數計算所述目標對象出現預定事件的相對分數。通過多個評分卡模型進行風險評分,避免了單一的評分卡模型造成的風險評估不精準的問題,提高了風險評估的精準度。以上具體地示出和描述了本發明的示例性實施例。應可理解的是,本發明不限于這里描述的詳細結構、設置方式或實現方法;相反,本發明意圖涵蓋包含所附權利要求的精神和范圍內的各種修改和等效設置。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1