一種推廣關鍵詞的觸發方法及裝置與流程
本發明涉及搜索技術領域,尤其涉及一種推廣關鍵詞的觸發方法及裝置。
背景技術:
搜索引擎是網民獲取信息的主要途徑,而搜索引擎的收入主要來自于搜索推廣,因此搜索引擎公司需要構建復雜的搜索推廣投放系統。而搜索推廣投放系統展現推廣的主要流程為:1)根據用戶的搜索詞找到與之相關的推廣關鍵詞;2)找到購買了這些推廣關鍵詞的廣告并進行點擊率預估;3)根據一定的機制選擇推廣展現給用戶。其中,如何根據用戶的搜索詞觸發出合適的拍賣詞,在很大程度上決定了展現的廣告是否符合用戶的搜索意圖。因此,推廣關鍵詞的觸發技術是搜索推廣投放系統中的核心技術之一。
而目前推廣關鍵詞的觸發技術大多基于搜索關鍵詞的字面變換,例如基于同義詞的變換,這種方式,并不能真正從語義上確定與query相匹配的推廣關鍵詞,導致觸發推廣關鍵詞的準確率和召回率較低。因此亟需提供一種推廣關鍵詞的觸發方法,實現真正從語義上確定與query相匹配的推廣關鍵詞,提升推廣關鍵詞觸發的準確率和召回率。
技術實現要素:
有鑒于此,本發明提供了一種推廣關鍵詞的觸發方法和裝置,實現真正從語義上確定與query相匹配的推廣關鍵詞,提升推廣關鍵詞觸發的準確率和召回率。
本發明為解決技術問題而采用的技術方案是提供一種推廣關鍵詞的觸發方法,所述方法包括:獲取用戶輸入的query;將所述獲取的query對應的輸入序列輸入到翻譯模型,得到輸出序列;利用所述輸出序列確定所述query觸發的推廣關鍵詞;其中,所述翻譯模型是采用如下方式預先訓練得到的:從用戶點擊行為日志中獲取query及其對應的被點擊標題作為訓練數據;利用訓練數據中的query得到輸入序列,利用query對應的被點擊標題得到目標序列,訓練神經網絡模型,得到翻譯模型。
根據本發明一優選實施例,將所述獲取的query對應的輸入序列輸入到翻譯模型包括:對所述獲取的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列輸入到翻譯模型;所述利用訓練數據中的query得到輸入序列包括:將訓練數據中的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列。
根據本發明一優選實施例,,所述翻譯模型利用beam-search技術以及預設的推廣關鍵詞庫,對所述獲取的query對應的輸入序列進行翻譯,得到輸出序列。
根據本發明一優選實施例,所述翻譯模型對所述獲取的query對應的輸入序列翻譯得到的各輸出序列滿足以下條件:輸出序列的數量在beam-size以內,且各輸出序列的概率大于或等于預設的概率閾值Q,且在所述推廣關鍵詞庫中存在與所述輸出序列一致的推廣關鍵詞或者存在以所述輸出序列為前綴的推廣關鍵詞。
根據本發明一優選實施例,所述翻譯模型在對所述輸入序列進行翻譯的過程中,在各層均進行如下處理:在推廣關鍵詞庫中查詢各層翻譯得到的候選詞語;若推廣關鍵詞庫中不存在以之前各層已確定的詞語與該候選詞語構成的序列為前綴的詞語,則將該候選詞語剪枝掉;將剩余的候選詞語依據概率值進行排序,將排在beam-size個之后的詞語剪枝掉;對排在beam-size個以內的詞語中,概率值小于所述Q的詞語剪枝掉。
根據本發明一優選實施例,所述神經網絡模型為:循環神經網絡模型RNN。
根據本發明一優選實施例,利用所述輸出序列確定所述query觸發的推廣關鍵詞包括:判斷推廣關鍵詞庫中是否存在與所述輸出序列一致的推廣關鍵詞,如果是,則將與所述輸出序列一致的推廣關鍵詞作為所述query觸發的推廣關鍵詞。
根據本發明一優選實施例,所述方法還包括:在所述query對應的搜索結果頁中包括所述query觸發的推廣關鍵詞對應的推廣結果。
本發明為解決技術問題提供一種推廣關鍵詞的觸發裝置,所述裝置包括:獲取單元,用于獲取用戶輸入的query;翻譯單元,用于將所述獲取的query對應的輸入序列輸入到翻譯模型,得到輸出序列;確定單元,用于利用所述輸出序列確定所述query觸發的推廣關鍵詞;訓練單元,用于采用如下方式預先訓練得到所述翻譯模型:從用戶點擊行為日志中獲取query及其對應的被點擊標題作為訓練數據;利用訓練數據中的query得到輸入序列,利用query對應的被點擊標題得到目標序列,訓練神經網絡模型,得到翻譯模型。
根據本發明一優選實施例,所述翻譯單元將所述獲取的query對應的輸入序列輸入到翻譯模型時,具體執行:對所述獲取的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列輸入到翻譯模型;所述訓練單元在利用訓練數據中的query得到輸入序列時,具體執行:翻譯單元將訓練數據中的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列。
根據本發明一優選實施例,所述翻譯單元的翻譯模型利用beam-search技術以及預設的推廣關鍵詞庫,對所述獲取的query對應的輸入序列進行翻譯,得到輸出序列。
根據本發明一優選實施例,所述翻譯單元中的翻譯模型對所述獲取的query對應的輸入序列翻譯得到的各輸出序列滿足以下條件:輸出序列的數量在beam-size以內,且各輸出序列的概率大于或等于預設的概率閾值Q,且在所述推廣關鍵詞庫中存在與所述輸出序列一致的推廣關鍵詞或者存在以所述輸出序列為前綴的推廣關鍵詞。
根據本發明一優選實施例,所述翻譯單元中的翻譯模型在對所述輸入序列進行翻譯的過程中,在各層均進行如下處理:在推廣關鍵詞庫中查詢各層翻譯得到的候選詞語;若推廣關鍵詞庫中不存在以之前各層已確定的詞語與該候選詞語構成的序列為前綴的詞語,則將該候選詞語剪枝掉;將剩余的候選詞語依據概率值進行排序,將排在beam-size個之后的詞語剪枝掉;對排在beam-size個以內的詞語中,概率值小于所述Q的詞語剪枝掉。
根據本發明一優選實施例,所述翻譯單元中翻譯模型使用的神經網絡模型為:循環神經網絡模型RNN。
根據本發明一優選實施例,所述確定單元在利用輸出序列確定所述query觸發的推廣關鍵詞包括:判斷推廣關鍵詞庫中是否存在與所述輸出序列一致的推廣關鍵詞,如果是,則將與所述輸出序列一致的推廣關鍵詞作為所述query觸發的推廣關鍵詞。
根據本發明一優選實施例,所述裝置還包括:觸發單元,用于在所述query對應的搜索結果頁中包括所述query觸發的推廣關鍵詞對應的推廣結果。
由以上技術方案可以看出,本發明選取用戶點擊行為日志中的query及其對應的被點擊標題作為訓練數據,訓練神經網絡模型以得到翻譯模型,在獲取用戶輸入的query后,通過預先訓練得到的翻譯模型獲得該query觸發的推廣關鍵詞。這種方式能夠獲取到在語義上與query匹配的推廣關鍵詞,相比較字面變換的方式,準確率和召回率都得到了較大的提升。
【附圖說明】
圖1為本發明一實施例提供的方法流程圖。
圖2為本發明實施例提供的RNN網絡結構圖。
圖3為本發明實施例提供的裝置結構圖。
圖4為本發明實施例提供的設備結構圖。
【具體實施方式】
為了使本發明的目的、技術方案和優點更加清楚,下面結合附圖和具體實施例對本發明進行詳細描述。
在本發明實施例中使用的術語是僅僅出于描述特定實施例的目的,而非旨在限制本發明。在本發明實施例和所附權利要求書中所使用的單數形式的“一種”、“所述”和“該”也旨在包括多數形式,除非上下文清楚地表示其他含義。
應當理解,本文中使用的術語“和/或”僅僅是一種描述關聯對象的關聯關系,表示可以存在三種關系,例如,A和/或B,可以表示:單獨存在A,同時存在A和B,單獨存在B這三種情況。另外,本文中字符“/”,一般表示前后關聯對象是一種“或”的關系。
取決于語境,如在此所使用的詞語“如果”可以被解釋成為“在……時”或“當……時”或“響應于確定”或“響應于檢測”。類似地,取決于語境,短語“如果確定”或“如果檢測(陳述的條件或事件)”可以被解釋成為“當確定時”或“響應于確定”或“當檢測(陳述的條件或事件)時”或“響應于檢測(陳述的條件或事件)”。
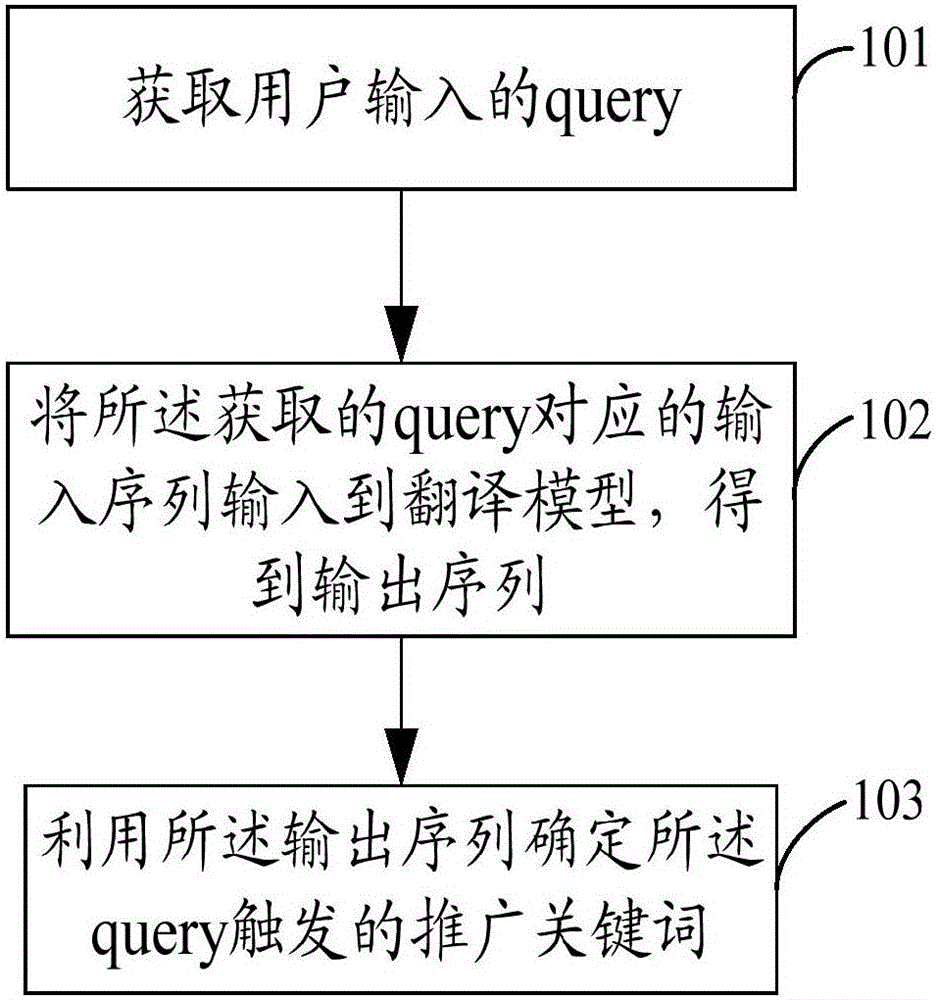
圖1為本發明一實施例提供的方法流程圖,如圖1所示,該方法可以主要包括以下步驟:
在101中,獲取用戶輸入的query。
在本步驟中,用戶輸入的query可以為任意形式,可以為單個詞,也可以為一句話。
在102中,將所述獲取的query對應的輸入序列輸入到翻譯模型,得到輸出序列。
在本步驟中,對所述獲取的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列輸入到翻譯模型中。其中的翻譯模型為預先訓練得到的,通過所獲取的訓練數據對神經網絡模型進行訓練,從而得到翻譯模型。
在對神經網絡模型進行訓練時,所使用的訓練數據為:從用戶點擊行為日志中獲取的query及其對應的被點擊標題所構成的二元組。其中被點擊標題優選被點擊推廣結果的標題。
其中,用戶點擊行為日志來自于搜索引擎的日志系統。搜索引擎的日志系統會記錄用戶的點擊行為,該點擊行為反映了用戶的搜索意圖和搜索結果與推廣之間的相關性。在搜索引擎的日志系統中,會有成熟的算法對用戶的有效性和用戶點擊行為的有效性進行標識,因此本步驟在訓練翻譯模型時所使用的訓練數據為有效用戶產生的有效點擊數據,也可以將該訓練數據稱之為用戶的優質點擊行為數據。利用該訓練數據進行訓練所得到的翻譯模型對輸入query進行翻譯時會更加準確有效。
在使用訓練數據訓練神經網絡模型得到翻譯模型時,將訓練數據中的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列,訓練數據中query對應的被點擊標題作為目標序列進行訓練。
在本步驟中,所使用的神經網絡模型優選循環神經網絡模型(RNN,Recurrent Neural Network),這是因為循環神經網絡模型網絡結構中的隱節點之間連接形成環狀,而其內部狀態則由輸入序列決定,因此循環神經網絡模型的網絡結構非常適合用來處理較長的文本序列,在以下說明中用RNN來表示循環神經網絡模型。
RNN網絡結構如圖2所示,該結構從下到上主要分為5個部分,完成由輸入序列到目標序列的訓練過程,而該訓練過程實際上就是從query到該query所對應被點擊標題的翻譯過程。
其中,RNN網絡結構的第一層為輸入端的詞向量層,該層將query的每個詞表示為詞向量,例如訓練數據中的query為“如何培養孩子的良好習慣”,將分詞后得到的詞匯“如何”、“培養”、“孩子”、“的”、“良好”、“習慣”表示為詞向量的形式,方框內的數字即表示該詞的詞向量,通過計算詞向量之間的余弦相似度來衡量詞語之間的語義相似度;RNN網絡結構的第二層為雙向RNN層,該層從正反兩個方向讀取輸入的詞向量序列,通過迭代的方式將讀到的序列信息編碼成內部狀態,因為訓練數據中的query包含有豐富的語義信息,經過第一層將query表示為詞向量后,不同的詞向量中包含不同的語義信息,雙向RNN層將詞向量序列中的語義信息進行編碼,并將輸入序列的語義信息編碼在RNN的內部狀態中;RNN網絡結構的第三層為對齊層,該層用不同的權重值對雙向RNN的內部狀態進行加權;RNN網絡結構的第四層為RNN層,該層通過迭代的方式,依據對齊層的輸出、上一次迭代的內部狀態及已翻譯出的詞序列,計算出該次迭代中各詞的概率;RNN網絡結構的第五層為輸出端的詞向量層,該層表示了由輸入序列翻譯得到的目標序列中每個詞的詞向量。
舉例來說,訓練數據中的query為“如何培養孩子的良好習慣”,而該query對應被點擊的標題為“兒童好習慣培養”。利用RNN網絡結構對該訓練數據進行訓練,訓練的目標是盡可能通過該RNN網絡結構,在query為“如何培養孩子的良好習慣”時,輸出的目標序列為“兒童好習慣培養”。也就是說以RNN網絡結構進行訓練的目的為:使得訓練數據中的query經過翻譯后盡可能得到該query對應被點擊的標題。
由上面對RNN訓練網絡結構的描述中可以看出,RNN網絡結構在翻譯模型中主要用來對序列數據進行編碼和解碼,雙向RNN層對輸入序列進行編碼,將輸入序列的語義信息編碼在RNN的內部狀態中;而RNN層則將含有語義信息的內部狀態解碼成目標序列,以此完成由輸入序列到目標序列的翻譯過程。
因此在本步驟中,將所述獲取的query對應的輸入序列輸入到翻譯模型后,得到的輸出序列即包含有該query的語義信息。
在103中,利用所述輸出序列確定所述query觸發的推廣關鍵詞。
在本步驟中,在利用訓練數據進行翻譯模型的訓練時,將所獲取的訓練數據中所有的query及標題進行分詞處理,并將所有訓練數據分詞后得到的詞匯組成候選翻譯字符集合。
通過步驟102,得到所述輸入query的語義信息之后,翻譯模型根據所述輸入query的語義信息,對候選翻譯字符集合中的每個字符賦予相應的概率值。也就是說,當所輸入的query不同時,翻譯模型對候選翻譯字符集合中的每個字符所賦予的概率值是不同的。根據所述候選翻譯字符集合中每個字符的概率值,結合beam-search技術以及推廣關鍵詞庫,對所述輸入序列進行翻譯,得到輸出序列。
推廣關鍵詞的觸發可以看作是從query到推廣關鍵詞的翻譯過程,因此可以應用上述翻譯模型完成query到推廣關鍵詞的觸發。但是在這種翻譯過程中還存在一個問題,即使用翻譯模型翻譯的過程是自由的,其輸出序列是一個開放空間,因此并不能保證由所輸入的query經過翻譯模型后就會觸發廣告主所購買的推廣關鍵詞,而且標準機器翻譯只要求返回一個最優解,因此會導致降低推廣關鍵詞觸發的召回率。
針對上述問題,本發明在利用翻譯模型對輸入的query進行翻譯時,采用了改進的beam-search技術,即在對輸入query進行翻譯前,預先設定beam-size和概率閾值Q。其中,概率閾值Q決定了候選序列選擇的最低概率值,該值通過多次實驗觀察得出;beam-size則決定了每一層翻譯時選擇的候選序列數量以及最終候選序列集合的大小,該值需要通過權衡翻譯性能以及翻譯結果相關性來決定。而且本發明在利用翻譯模型對輸入的query進行翻譯時,還需要結合推廣關鍵詞庫進行,該推廣關鍵詞庫包含了廣告主所購買的所有推廣關鍵詞。
因此,在通過翻譯模型翻譯得到的各輸出序列滿足以下條件:輸出序列的數量在beam-size以內,且各輸出序列的概率大于或等于預設的概率閾值Q,且在所述推廣關鍵詞庫中存在與所述輸出序列一致的推廣關鍵詞或者存在以所述輸出序列為前綴的推廣關鍵詞。
在翻譯模型對所輸入的query進行翻譯的過程中,根據輸入query的語義信息,翻譯模型賦予候選翻譯字符集合中每個字符概率值,根據所述候選字符集合中每個字符的概率值,在推廣關鍵詞庫中得到beam-size個候選字符,因此就保證了不在推廣關鍵詞庫中的詞語不會出現在翻譯模型得到的結果中。
并且在使用訓練數據進行翻譯模型的訓練時,在query及其對應的被點擊標題后自動添加一個特殊標記字符,該特殊標記字符用以表示翻譯結束,那么通過對訓練數據進行訓練,翻譯模型就可以學習到在什么時候輸出的那些詞會構成一個完整的句子時結束翻譯過程。
因此,當某個候選字符以該特殊標記字符結尾時,表明本次翻譯過程結束。在翻譯結束時,選取beam-size個大于概率閾值Q的候選字符作為最終候選字符,該最終候選字符即為對所述輸入query翻譯后得到的推廣關鍵詞。
舉例來說,假設翻譯模型采用的候選翻譯字符集合為{a,b,c,d,EOF},即在翻譯過程中目標序列中的各候選字符從該集合中選取。其中EOF代表翻譯結束的特殊標記字符,設定beam-size=2,概率閾值Q=0.3,最終候選序列集合表示為R。
在翻譯輸入query的首字符時,翻譯模型根據該query的語義信息在候選翻譯字符集合中給出每個字符作為首字符的概率值,如p(a)代表字符a作為翻譯結果首字符的概率值,p(b)代表字符b作為翻譯結果首字符的概率值,以此類推。將該字符的概率值從大到小進行排序,假如p(a)最大,則在推廣關鍵詞庫中首先檢索是否有以a為前綴的推廣關鍵詞,若有,則將a作為候選首字符,若沒有,則剪枝掉a;設p(b)僅次于p(a),則在推廣關鍵詞庫中檢索是否有b,若有,則將b作為候選首字符,若沒有,則剪枝掉b。按照該選取規則,最終選取beam-size個候選首字符,其余字符都剪枝掉,且必須保證該beam-size各候選首字符的概率值均大于或等于預設的概率閾值Q,對于概率值小于Q的候選首字符也被剪枝掉。因為設定的beam-size=2,所以選取兩個字符作為候選首字符,假設本次選擇的候選首字符是a和b。
對于翻譯的第二個字符,翻譯模型會計算出以a或b開頭的所有序列{aa,ab,ac,ad,aEOF,ba,bb,bc,bd,bEOF}的概率,同首字符的選取規則一樣,將這些序列依據概率值的大小降序排序,并在推廣關鍵詞庫中檢索是否有以得到的序列為前綴的推廣關鍵詞,若有則選取,若無則剪枝掉。最終選取beam-size個概率值大于或等于Q的候選序列進行繼續翻譯。
重復以上翻譯過程,當某個候選序列以EOF結尾時,則認為該輸入序列的翻譯過程結束,若所得到的候選序列的概率值大于概率閾值Q,則將該序列放入最終候選序列集合R中。當集合R的大小等于beam-size時,翻譯結束。
再舉例來說,用戶輸入的query為“如何選擇北京鮮花速遞”,將該query進行分詞處理后得到“如何”、“選擇”、“北京”、“鮮花”、“速遞”,將分詞處理后得到的詞匯輸入到翻譯模型,通過翻譯模型得知該輸入query的語義后,翻譯模型開始進行翻譯。
翻譯模型首先確定輸出的第一個詞是什么,根據query的語義對候選翻譯字符集合中的每個字符賦予概率值,該概率值代表候選翻譯字符中每個字符作為首字符的概率。假如,“如何”、“哪里”、“北京”這三個詞的概率值較高,但在推廣關鍵詞庫中沒有檢索到以“如何”、“哪里”開頭的推廣關鍵詞,而檢索到以“北京”開頭的推廣關鍵詞,則放棄前兩個詞,選取“北京”作為首字符。然后翻譯模型確定輸出的第二個詞是什么,也就是跟在詞語“北京”后輸出哪個詞合適,翻譯模型同樣對候選翻譯字符集合中每個字符賦予概率值,該概率值代表跟在“北京”之后輸出這個詞匯的可能性,假設第二個字符為“鮮花”和“花卉”的概率值較高,并且在推廣關鍵詞庫中檢索到有以“北京鮮花”或者“北京花卉”開頭的推廣關鍵詞,則將“鮮花”、“花卉”選擇為第二個詞,以此類推。假設翻譯模型選擇了“北京”、“鮮花”、“快遞”這三個詞匯后,在選擇第四個詞匯時,翻譯模型發現第四個字符為“EOF”的概率最大,則結束本次翻譯過程。這時模型會在推廣關鍵詞庫中檢索是否有“北京鮮花快遞”這個推廣關鍵詞,如果有,并且該推廣關鍵詞的概率大于設定的概率閾值Q時,將該詞作為候選推廣關鍵詞輸出。
在利用所述輸出序列確定由所述query觸發的推廣關鍵詞后,便可以利用該推廣關鍵詞得到與該推廣關鍵詞所對應的推廣,在用戶輸入query后所對應的搜索結果頁中便包括由所述query觸發的推廣關鍵詞對應的推廣結果。
利用本發明提供的技術方案,選取用戶點擊行為日志中的query及其對應的被點擊標題作為訓練數據,訓練神經網絡模型以得到翻譯模型,在獲取用戶輸入的query后,通過預先訓練得到的翻譯模型獲得該query觸發的推廣關鍵詞。這種方式能夠獲取到在語義上與query匹配的推廣關鍵詞,相比較字面變換的方式,觸發推廣關鍵詞的準確率和召回率都得到了較大的提升。
下面對本發明實施例提供的裝置結構圖進行詳述。如圖3中所示,所述裝置主要包括:獲取單元31、翻譯單元32、確定單元33、訓練單元34以及觸發單元35。
獲取單元31,用于獲取用戶輸入的query。
在本步驟中,用戶輸入的query可以為任意形式,可以為單個詞,也可以為一句話。
翻譯單元32,用于將所述獲取的query對應的輸入序列輸入到翻譯模型,得到輸出序列。
翻譯單元32需要將所述獲取的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列,然后將該輸入序列輸入到翻譯模型進行翻譯。
翻譯單元32中所使用的翻譯模型由訓練單元34預先訓練得到的,訓練單元34通過所獲取的訓練數據對神經網絡模型進行訓練,從而得到翻譯模型。
訓練單元34對神經網絡模型進行訓練所使用的訓練數據為:從用戶點擊行為日志中獲取的query及其對應的被點擊標題所構成的二元組。其中被點擊標題優選被點擊推廣結果的標題。
其中,用戶點擊行為日志來自于搜索引擎的日志系統。搜索引擎的日志系統會記錄用戶的點擊行為,該點擊行為反映了用戶的搜索意圖和搜索結果與推廣之間的相關性。在搜索引擎的日志系統中,會有成熟的算法對用戶的有效性和用戶點擊行為的有效性進行標識,因此本步驟在訓練翻譯模型時所使用的訓練數據為有效用戶產生的有效點擊數據,也可以將該訓練數據稱之為用戶的優質點擊行為數據。利用該訓練數據進行訓練所得到的翻譯模型對輸入query進行翻譯時會更加準確有效。
訓練單元34在使用訓練數據訓練神經網絡模型得到翻譯模型時,需要將訓練數據中的query進行分詞處理,將分詞處理后得到的詞語序列作為輸入序列,訓練數據中query對應的被點擊標題作為目標序列進行訓練。
在本步驟中,所使用的神經網絡模型優選循環神經網絡模型(RNN,Recurrent Neural Network),這是因為循環神經網絡模型網絡結構中的隱節點之間連接形成環狀,而其內部狀態則由輸入序列決定,因此循環神經網絡模型的網絡結構非常適合用來處理較長的文本序列。
RNN網絡結構如圖2所示,該結構從下到上主要分為5個部分,完成由輸入序列到目標序列的訓練過程,而該訓練過程實際上就是從query到該query所對應被點擊標題的翻譯過程。
其中,RNN網絡結構的第一層為輸入端的詞向量層,該層將query的每個詞表示為詞向量,例如訓練數據中的query為“如何培養孩子的良好習慣”,將分詞后得到的詞匯“如何”、“培養”、“孩子”、“的”、“良好”、“習慣”表示為詞向量的形式,方框內的數字即表示該詞的詞向量,通過計算詞向量之間的余弦相似度來衡量詞語之間的語義相似度;RNN網絡結構的第二層為雙向RNN層,該層從正反兩個方向讀取輸入的詞向量序列,通過迭代的方式將讀到的序列信息編碼成內部狀態,因為訓練數據中的query包含有豐富的語義信息,經過第一層將query表示為詞向量后,不同的詞向量中包含不同的語義信息,雙向RNN層將詞向量序列中的語義信息進行編碼,并將輸入序列的語義信息編碼在RNN的內部狀態中;RNN網絡結構的第三層為對齊層,該層用不同的權重值對雙向RNN的內部狀態進行加權;RNN網絡結構的第四層為RNN層,該層通過迭代的方式,依據對齊層的輸出、上一次迭代的內部狀態及已翻譯出的詞序列,計算出該次迭代中各詞的概率;RNN網絡結構的第五層為輸出端的詞向量層,該層表示了由輸入序列翻譯得到的目標序列中每個詞的詞向量。
舉例來說,訓練數據中的query為“如何培養孩子的良好習慣”,而該query對應被點擊的標題為“兒童好習慣培養”。利用RNN網絡結構對該訓練數據進行訓練,訓練的目標是盡可能通過該RNN網絡結構,在query為“如何培養孩子的良好習慣”時,輸出的目標序列為“兒童好習慣培養”。也就是說以RNN網絡結構進行訓練的目的為:使得訓練數據中的query經過翻譯后盡可能得到該query對應被點擊的標題。
由上面對RNN訓練網絡結構的描述中可以看出,RNN網絡結構在翻譯模型中主要用來對序列數據進行編碼和解碼,雙向RNN層對輸入序列進行編碼,將輸入序列的語義信息編碼在RNN的內部狀態中;而RNN層則將含有語義信息的內部狀態解碼成目標序列,以此完成由輸入序列到目標序列的翻譯過程。
因此在本步驟中,翻譯單元32將所述獲取的query對應的輸入序列輸入到翻譯模型中,得到的輸出序列包含有該query的語義信息。
確定單元33,用于利用所述輸出序列確定所述query觸發的推廣關鍵詞。
在利用訓練數據進行翻譯模型的訓練時,將所獲取的訓練數據中所有的query及標題進行分詞處理,并將所有訓練數據分詞后得到的詞匯組成候選翻譯字符集合。
通過翻譯單元32得到所述輸入query的語義信息之后,翻譯單元32中的翻譯模型根據所述輸入query的語義信息,對候選翻譯字符集合中的每個字符賦予相應的概率值。也就是說,當所輸入的query不同時,翻譯模型對候選翻譯字符集合中的每個字符所賦予的概率值是不同的。根據所述候選翻譯字符集合中每個字符的概率值,結合beam-search技術以及推廣關鍵詞庫,對所述輸入序列進行翻譯,得到輸出序列。
推廣關鍵詞的觸發可以看作是從query到推廣關鍵詞的翻譯過程,因此可以應用上述翻譯模型完成query到推廣關鍵詞的觸發。但是在這種翻譯過程中還存在一個問題,即使用翻譯模型翻譯的過程是自由的,其輸出序列是一個開放空間,因此并不能保證由所輸入的query經過翻譯模型后就會觸發廣告主所購買的推廣關鍵詞,而且標準機器翻譯只要求返回一個最優解,因此會導致降低推廣關鍵詞觸發的召回率。
針對上述問題,本發明在利用翻譯模型對輸入的query進行翻譯時,采用了改進的beam-search技術,即在對輸入query進行翻譯前,預先設定beam-size和概率閾值Q。其中,概率閾值Q決定了候選序列選擇的最低概率值,該值通過多次實驗觀察得出;beam-size則決定了每一層翻譯時選擇的候選序列數量以及最終候選序列集合的大小,該值需要通過權衡翻譯性能以及翻譯結果相關性來決定。而且本發明在利用翻譯模型對輸入的query進行翻譯時,還需要結合推廣關鍵詞庫進行,該推廣關鍵詞庫包含了廣告主所購買的所有推廣關鍵詞。
因此,在通過翻譯模型翻譯得到的各輸出序列滿足以下條件:輸出序列的數量在beam-size以內,且各輸出序列的概率大于或等于預設的概率閾值Q,且在所述推廣關鍵詞庫中存在與所述輸出序列一致的推廣關鍵詞或者存在以所述輸出序列為前綴的推廣關鍵詞。
在翻譯模型對所輸入的query進行翻譯的過程中,根據輸入query的語義信息,翻譯模型賦予候選翻譯字符集合中每個字符概率值,根據所述候選字符集合中每個字符的概率值,在推廣關鍵詞庫中得到beam-size個候選字符,因此就保證了不在推廣關鍵詞庫中的詞語不會出現在翻譯模型得到的結果中。
并且在使用訓練數據進行翻譯模型的訓練時,在query及其對應的被點擊標題后自動添加一個特殊標記字符,該特殊標記字符用以表示翻譯結束,那么通過對訓練數據進行訓練,翻譯模型就可以學習到在什么時候輸出的那些詞會構成一個完整的句子時結束翻譯過程。
因此,當某個候選字符以該特殊標記字符結尾時,表明本次翻譯過程結束。在翻譯結束時,選取beam-size個大于概率閾值Q的候選字符作為最終候選字符,該最終候選字符即為對所述輸入query翻譯后得到的推廣關鍵詞。
舉例來說,假設翻譯模型采用的候選翻譯字符集合為{a,b,c,d,EOF},即在翻譯過程中目標序列中的各候選字符從該集合中選取。其中EOF代表翻譯結束的特殊標記字符,設定beam-size=2,概率閾值Q=0.3,最終候選序列集合表示為R。
在翻譯輸入query的首字符時,翻譯模型根據該query的語義信息在候選翻譯字符集合中給出每個字符作為首字符的概率值,如p(a)代表字符a作為翻譯結果首字符的概率值,p(b)代表字符b作為翻譯結果首字符的概率值,以此類推。將該字符的概率值從大到小進行排序,假如p(a)最大,則在推廣關鍵詞庫中首先檢索是否有以a為前綴的推廣關鍵詞,若有,則將a作為候選首字符,若沒有,則剪枝掉a;設p(b)僅次于p(a),則在推廣關鍵詞庫中檢索是否有b,若有,則將b作為候選首字符,若沒有,則剪枝掉b。按照該選取規則,最終選取beam-size個候選首字符,其余字符都剪枝掉,且必須保證該beam-size各候選首字符的概率值均大于或等于預設的概率閾值Q,對于概率值小于Q的候選首字符也被剪枝掉。因為設定的beam-size=2,所以選取兩個字符作為候選首字符,假設本次選擇的候選首字符是a和b。
對于翻譯的第二個字符,翻譯模型會計算出以a或b開頭的所有序列{aa,ab,ac,ad,aEOF,ba,bb,bc,bd,bEOF}的概率,同首字符的選取規則一樣,將這些序列依據概率值的大小降序排序,并在推廣關鍵詞庫中檢索是否有以得到的序列為前綴的推廣關鍵詞,若有則選取,若無則剪枝掉。最終選取beam-size個概率值大于或等于Q的候選序列進行繼續翻譯。
重復以上翻譯過程,當某個候選序列以EOF結尾時,則認為該輸入序列的翻譯過程結束,若所得到的候選序列的概率值大于概率閾值Q,則將該序列放入最終候選序列集合R中。當集合R的大小等于beam-size時,翻譯結束。
再舉例來說,用戶輸入的query為“如何選擇北京鮮花速遞”,將該query進行分詞處理后得到“如何”、“選擇”、“北京”、“鮮花”、“速遞”,將分詞處理后得到的詞匯輸入到翻譯模型,通過翻譯模型得知該輸入query的語義后,翻譯模型開始進行翻譯。
翻譯模型首先確定輸出的第一個詞是什么,根據輸入query的語義對候選翻譯字符集合中的每個字符賦予概率值,該概率值代表候選翻譯字符中每個字符作為首字符的概率。假如,“如何”、“哪里”、“北京”這三個詞的概率值較高,但在推廣關鍵詞庫中沒有檢索到以“如何”、“哪里”開頭的推廣關鍵詞,而檢索到以“北京”開頭的推廣關鍵詞,則放棄前兩個詞,選取“北京”作為首字符。然后翻譯模型確定輸出的第二個詞是什么,也就是跟在詞語“北京”后輸出哪個詞合適,翻譯模型同樣對候選翻譯字符集合中每個字符賦予概率值,該概率值代表跟在“北京”之后輸出這個詞匯的可能性,假設第二個字符為“鮮花”和“花卉”的概率值較高,并且在推廣關鍵詞庫中檢索到有以“北京鮮花”或者“北京花卉”開頭的推廣關鍵詞,則將“鮮花”、“花卉”選擇為第二個詞,以此類推。假設翻譯模型選擇了“北京”、“鮮花”、“快遞”這三個詞匯后,在選擇第四個詞匯時,翻譯模型發現第四個字符為“EOF”的概率最大,則結束本次翻譯過程。這時模型會在推廣關鍵詞庫中檢索是否有“北京鮮花快遞”這個推廣關鍵詞,如果有,并且該推廣關鍵詞的概率大于設定的概率閾值Q時,將該詞作為候選推廣關鍵詞輸出。
在確定單元33利用所述輸出序列確定由所述query觸發的推廣關鍵詞后,便可以利用該推廣關鍵詞得到與該推廣關鍵詞所對應的推廣,觸發單元35進而在用戶輸入query后所對應的搜索結果頁中包括由所述query觸發的推廣關鍵詞對應的推廣結果。
本發明實施例提供的上述方法和裝置可以以設置并運行于設備中的計算機程序體現。該設備可以包括一個或多個處理器,還包括存儲器和一個或多個程序,如圖4中所示。其中該一個或多個程序存儲于存儲器中,被上述一個或多個處理器執行以實現本發明上述實施例中所示的方法流程和/或裝置操作。例如,被上述一個或多個處理器執行的方法流程,可以包括:
獲取用戶輸入的query;
將所述獲取的query對應的輸入序列輸入到翻譯模型,得到輸出序列;
利用所述輸出序列確定所述query觸發的推廣關鍵詞;
其中,所述翻譯模型是采用如下方式預先訓練得到的:
從用戶點擊行為日志中獲取query及其對應的被點擊標題作為訓練數據;
利用訓練數據中的query得到輸入序列,利用query對應的被點擊標題得到目標序列,訓練神經網絡模型,得到翻譯模型。
利用本發明提供的技術方案,選取用戶點擊行為日志中的query及其對應的被點擊標題作為訓練數據,訓練神經網絡模型以得到翻譯模型,在獲取用戶輸入的query后,通過預先訓練得到的翻譯模型獲得該query觸發的推廣關鍵詞。這種方式能夠獲取到在語義上與query匹配的推廣關鍵詞,相比較字面變換的方式,觸發推廣關鍵詞的準確率和召回率都得到了較大的提升。
而推廣關鍵詞的觸發技術是搜索推廣投放系統中的核心技術之一,將本發明中所公開的推廣關鍵詞的觸發方法應用到搜索推廣投放系統中,便能夠通過用戶輸入的query觸發推廣關鍵詞庫中的與輸入query語義相匹配的推廣關鍵詞,然后搜索推廣投放系統將與該推廣關鍵詞所對應的推廣進行展現,從而使得所展現的推廣更加符合用戶的搜索意圖。
在本發明所提供的幾個實施例中,應該理解到,所揭露的裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以采用硬件的形式實現,也可以采用硬件加軟件功能單元的形式實現。
上述以軟件功能單元的形式實現的集成的單元,可以存儲在一個計算機可讀取存儲介質中。上述軟件功能單元存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)或處理器(processor)執行本發明各個實施例所述方法的部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(Read-Only Memory,ROM)、隨機存取存儲器(Random Access Memory,RAM)、磁碟或者光盤等各種可以存儲程序代碼的介質。
以上所述僅為本發明的較佳實施例而已,并不用以限制本發明,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明保護的范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!