融合時間因素的協同過濾方法和裝置與流程
本發明涉及計算機技術領域,特別是涉及一種融合時間因素的協同過濾方法和裝置。
背景技術:
收集用戶對產品的喜好,通過進行數據分析和挖掘可以有效提高產品信息推送的準確度。在傳統的方式中,用戶某個產品的喜好程度通常是只是利用用戶行為來構建的。例如,用戶行為包括:點擊、收藏和購買等。在對未知的用戶喜好程度值進行預測時也就缺乏了時間因素的考慮。假設,用戶在一年之前購買的某個產品,而在今年未再繼續夠買該產品。如果利用該用戶對該產品在一年前的喜好程度來預測其他用戶在今年對該產品的喜好程度,那么預測結果顯然無法反映出實際狀況。如何結合時間因素對指定產品的用戶喜好程度值進行有效預測成為目前需要解決的一個技術問題。
技術實現要素:
基于此,有必要針對上述技術問題,提供一種融合時間因素對指定產品的用戶喜好程度值進行有效預測的融合時間因素的協同過濾方法和裝置。
一種融合時間因素的協同過濾方法,所述方法包括:
建立指數平滑模型;
獲取對所述指數平滑模型擬定的時間段,所述時間段包括多個時間周期;
獲取多個用戶標識以及用戶標識在多個時間周期內對指定產品的用戶喜好程度值;
利用所述指數平滑模型對所述用戶喜好程度值進行迭代計算,得到與時間周期對應的平滑結果;
利用所述用戶標識和所述與時間周期對應的平滑結果生成稀疏矩陣,所述稀疏矩陣包括多個待預測用戶喜好程度;
獲取協同過濾模型,將所述時間周期對應的平滑結果輸入至所述協同過濾模型;
通過所述協同過濾模型進行訓練,計算得到所述稀疏矩陣中的多個待預測用戶喜好程度的預測值。
在其中一個實施例中,所述平滑模型的公式包括:
Pt+1=a*Pt+(1-a)*Pt-1;
其中,a表示產品標識對應的指數系數;Pt+1表示下一個時間周期對應的用戶喜好程度值;Pt表示當前時間周期對應的用戶喜好程度值;Pt-1表示上一個時間周期對應的用戶喜好程度值。
在其中一個實施例中,在所述計算得到所述稀疏矩陣中的多個待預測用戶喜好程度的預測值的步驟之后,還包括:
獲取用戶喜好程度值對應的維度;
根據用戶標識對多個維度的用戶喜好程度值進行統計;
對統計結果進行正則化處理,得到用戶標識對應的多維向量;
根據所述多維向量計算用戶標識彼此之間的用戶喜好的相似度。
在其中一個實施例中,所述方法還包括:
根據產品標識和用戶標識獲取用戶喜好程度值對應的正樣本和負樣本;
將所述負樣本進行拆分,得到多個拆分后的負樣本,所述拆分后的負樣本的數量與所述正樣本的數量的差值在預設范圍內;
獲取分類模型,利用所述正樣本和所述拆分后的負樣本對所述分類模型進行訓練,得到多個訓練后的分類模型;
對所述多個訓練后的分類模型進行擬合,計算得到每個訓練后的分類模型對應的分類權重。
在其中一個實施例中,在所述計算得到每個訓練后的分類模型對應的分類權重的步驟之后,還包括:
獲取待分類樣本數據;
利用所述訓練后的分類模型和所述分類權重對所述待分類樣本數據進行分類。
一種融合時間因素的協同過濾裝置,所述裝置包括:
模型建立模塊,用于建立指數平滑模型;
獲取模塊,用于獲取對所述指數平滑模型擬定的時間段,所述時間段包括多個時間周期;獲取多個用戶標識以及用戶標識在多個時間周期內對指定產品的用戶喜好程度值;
平滑模塊,用于利用所述指數平滑模型對所述用戶喜好程度值進行迭代計算,得到與時間周期對應的平滑結果;
矩陣生成模塊,用于利用所述用戶標識和所述與時間周期對應的平滑結果生成稀疏矩陣,所述稀疏矩陣包括多個待預測用戶喜好程度;
所述獲取模塊還用于獲取協同過濾模型;
第一訓練模塊,用于將所述時間周期對應的平滑結果輸入至所述協同過濾模型;通過所述協同過濾模型進行訓練,計算得到所述稀疏矩陣中的多個待預測用戶喜好程度的預測值。
在其中一個實施例中,所述平滑模型的公式包括:
Pt+1=a*Pt+(1-a)*Pt-1;
其中,a表示產品標識對應的指數系數;Pt+1表示下一個時間周期對應的用戶喜好程度值;Pt表示當前時間周期對應的用戶喜好程度值;Pt-1表示上一個時間周期對應的用戶喜好程度值。
在其中一個實施例中,所述獲取模塊還用于獲取用戶喜好程度值對應的維度;
所述裝置還包括:
統計模塊,用于根據用戶標識對多個維度的用戶喜好程度值進行統計;
正則化模塊,用于對統計結果進行正則化處理,得到用戶標識對應的多維向量;
相似度計算模塊,用于根據所述多維向量計算用戶標識彼此之間的用戶喜好的相似度。
在其中一個實施例中,所述獲取模塊還用于根據產品標識和用戶標識獲取用戶喜好程度值對應的正樣本和負樣本;
所述裝置還包括:
拆分模塊,用于將所述負樣本進行拆分,得到多個拆分后的負樣本,所述拆分后的負樣本的數量與所述正樣本的數量的差值在預設范圍內;
所述獲取模塊還用于獲取分類模型;
第二訓練模塊,用于利用所述正樣本和所述拆分后的負樣本對所述分類模型進行訓練,得到多個訓練后的分類模型;
擬合模塊,用于對所述多個訓練后的分類模型進行擬合,計算得到每個訓練后的分類模型對應的分類權重。
在其中一個實施例中,所述獲取模塊還用于獲取待分類樣本數據;
所述裝置還包括:
分類模塊,用于利用所述訓練后的分類模型和所述分類權重對所述待分類樣本數據進行分類。
上述融合時間因素的協同過濾方法和裝置,通過建立指數平滑模型,將多個時間周期內的用戶喜好程度值進行迭代計算,得到與時間周期對應的平滑結果,從而使得對指定產品的用戶喜好程度值與時間因素進行了有效融合。當預測下一個時間周期內未知的用戶喜好程度值時,可以利用用戶標識和與時間周期對應的平滑結果生成稀疏矩陣,將與時間周期對應的平滑結果輸入至協同過濾模型,通過協同過濾模型進行訓練,從而計算得到稀疏矩陣中的多個待預測用戶喜好程度的預測值。由于輸入至協同過濾模型的平滑結果是與時間因素進行了融合的,由此能夠預測出對指定產品與時間因素相關的用戶喜好程度值。從而實現了結合時間因素對指定產品的用戶喜好程度進行有效預測。
附圖說明
圖1為一個實施例中融合時間因素的協同過濾方法的流程圖;
圖2為一個實施例中二維空間中記錄點的示意圖;
圖3為一個實施例中服務器的結構示意圖;
圖4為一個實施例中融合時間因素的協同過濾裝置的結構示意圖;
圖5為另一個實施例中融合時間因素的協同過濾裝置的結構示意圖;
圖6為再一個實施例中融合時間因素的協同過濾裝置的結構示意圖;
圖7為還一個實施例中融合時間因素的協同過濾裝置的結構示意圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
在一個實施例中,如圖1所示,提供了一種融合時間因素的協同過濾方法,以該方法應用于服務器為例進行說明,具體包括:
步驟102,建立指數平滑模型。
步驟104,獲取對指數平滑模型擬定的時間段,時間段包括多個時間周期。
用戶喜好程度是指用戶對指定產品的喜好程度。用戶喜好程度可以采用數值來表示。服務器上預先存儲了用戶喜好數據。其中,用戶喜好數據包括用戶標識、產品標識和對應的用戶喜好程度值等。用戶喜好程度值可以是服務器在預設的時間周期內對指定產品采集用戶行為來得到的,用戶行為包括:點擊、購買和收藏等。用戶喜好程度可以是與時間周期相對應的。對于不同的指定產品,用戶喜好程度對應的時間周期可以是相同的,也可以是不同的。例如,游戲產品,用戶喜好程度對應的時間周期可以是一天。保險產品,用戶喜好程度對應的時間周期可以是一個月或者一個月等。
為了將用戶對指定產品的用戶喜好程度與時間因素進行有效結合,服務器建立指數平滑模型。通過指數平滑模型將多個時間周期的用戶喜好程度進行融合。
在其中一個實施例中,平滑模型的公式包括:Pt+1=a*Pt+(1-a)*Pt-1;其中,a表示產品標識對應的指數系數;Pt+1表示下一個時間周期對應的用戶喜好程度值;Pt表示當前時間周期對應的用戶喜好程度值;Pt-1表示上一個時間周期對應的用戶喜好程度值。
服務器可以對指數平滑模型擬定對應的時間段,時間段內可以有多個時間周期。時間段可以根據指定產品特性來擬定,不同的指定產品可以擬定不同的時間段。例如,對理財產品的指數平滑模型所擬定的時間段可以是一個月,該時間段內的時間周期可以是以天為單位。對保險產品的指數平滑模型所擬定的時間段可以是一年,該時間段內的時間周期可以是以月為單位。
不同的指定產品可以對應不同的指數系數。指數系數可以反映時間周期對用戶喜好程度影響的重要性。指數系數越大,時間周期對用戶喜好程度的影響的重要性就越高。時間周期彼此之間越接近,對用戶喜好程度的影響也就越大。
步驟106,獲取多個用戶標識以及用戶標識在多個時間周期內對指定產品的用戶喜好程度值。
服務器對指數平滑模型擬定的時間段中包括多個時間周期,服務器獲取多個用戶標識以及用戶標識在多個時間周期內對指定產品的用戶喜好程度值。其中,多個時間周期內對指定產品的用戶喜好程度值可以是用戶對一個指定產品的用戶喜好程度值,也可以是用戶對多個指定產品的用戶喜好程度值。
步驟108,利用指數平滑模型對用戶喜好程度值進行迭代計算,得到時間周期對應的平滑結果。
服務器將多個時間周期對應的用戶喜好程度值輸入指數平滑模型,對多個時間周期的用戶喜好程度值進行迭代計算,得到多個與時間周期對應的平滑結果。具體的,服務器根據產品標識獲取指數平滑模型對應的指數系數。服務器將擬定的時間段中的第一個時間周期對應的用戶喜好程度值與指數系數相乘,將乘積作為指數平滑模型的初始值,該初始值也可以稱為第一時間周期對應的平滑結果。服務器利用第一時間周期對應的平滑結果、第二時間周期對應的用戶喜好程度值、指數系數輸入指數平滑模型進行迭代計算,得到第二時間周期對應的平滑結果。以此類推,服務器計算得到多個時間周期對應的平滑結果。
假設,指定產品為對產品1,時間周期為一天,平滑指數模型中的指數系數為0.3,擬定的時間段為4天,現在需要預測第5天的用戶喜好程度值,那么首先需要利用指數平滑模型對前面4天的用戶喜好程度值分別進行迭代計算,得到相應的平滑結果可以如表一所示:
表一:
其中,第一天的平滑結果為:0.3*8=2.4;第二天的平滑結果為:0.3*9+(1-0.3)*2.4=4.38;第三天的平滑結果為:0.3*5+(1-0.3)*4.38=4.566;第四天的平滑結果為:0.3*3+(1-0.3)*4.566=4.096。由此通過指數平滑模型將指定產品的用戶喜好程度值與時間因素進行了融合。
步驟110,利用用戶標識和與時間周期對應的平滑結果生成稀疏矩陣,稀疏矩陣包括多個待預測用戶喜好程度。
服務器利用用戶標識和時間周期對應的平滑結果生成用戶標識與產品標識對應的稀疏矩陣。稀疏矩陣中可以包括多個用戶標識和一個產品標識,也可以包括多個用戶標識和多個產品標識。系數矩陣中包括已知的用戶喜好程度值和未知的用戶喜好程度值。其中,未知的用戶喜好程度值也就是待預測用戶喜好程度的預測值。
在稀疏矩陣中,待預測用戶喜好程度的預測值可以用預設字符來表示。例如,用?來表示。舉例,稀疏矩陣中的行表示產品標識,列表示用戶標識,稀疏矩陣中的數值表示用戶對產品的用戶喜好程度值,如下表二所示:
由于稀疏矩陣中的用戶喜好程度值采用的是與時間周期對應的平滑結果,因此稀疏矩陣也與時間因素進行了有效融合。當需要預測下一個時間周期內未知的用戶喜好程度值時,服務器獲取當前時間周期內的產品標識、用戶標識以及用戶喜好程度值在當前時間周期的平滑結果來生成用戶標識與產品標識對應的稀疏矩陣。
步驟112,獲取協同過濾模型,將與時間周期對應的平滑結果輸入至協同過濾模型。
步驟114,通過協同過濾模型進行訓練,計算得到稀疏矩陣中的多個待預測用戶喜好程度的預測值。
協同過濾模型可以采用傳統的協同過濾模型。服務器獲取協同過濾模型,將與時間周期對應的平滑結果輸入至協同過濾模型。通過協同過濾模型進行訓練,計算得到稀疏矩陣中的多個待預測用戶喜好程度的預測值。
具體的,當預測下一個時間周期內未知的用戶喜好程度值時,服務器獲取多個用戶標識在上一個時間周期的平滑結果,將上一個時間周期的平滑處理結果輸入至協同過濾模型。通過協同過濾模型進行訓練,計算出用戶標識與產品標識對應的稀疏矩陣中的待預測用戶喜好程度在下一個時間周期的預測值。
本實施例中,通過建立指數平滑模型,將多個時間周期內的用戶喜好程度值進行迭代計算,得到與時間周期對應的平滑結果,從而使得對指定產品的用戶喜好程度值與時間因素進行了有效融合。當預測下一個時間周期內未知的用戶喜好程度值時,可以利用用戶標識和與時間周期對應的平滑結果生成稀疏矩陣,將與時間周期對應的平滑結果輸入至協同過濾模型,通過協同過濾模型進行訓練,從而計算得到稀疏矩陣中的多個待預測用戶喜好程度的預測值。由于輸入至協同過濾模型的平滑結果是與時間因素進行了融合的,由此能夠預測出對指定產品與時間因素相關的用戶喜好程度值。從而實現了結合時間因素對指定產品的用戶喜好程度進行有效預測。
在一個實施例中,在計算得到稀疏矩陣中的多個待預測用戶喜好程度的預測值的步驟之后,還包括:獲取用戶喜好程度值對應的維度;根據用戶標識對多個維度的用戶喜好程度值進行統計;對統計結果進行正則化處理,得到用戶標識對應的多維向量;根據多維向量計算用戶標識彼此之間的用戶喜好的相似度。
本實施例中,服務器對稀疏矩陣中多個待預測用戶喜好程度計算出相應的預測值之后,還可以對所有已知的和預測出的用戶喜好程度值進行相似度計算,從而得到用戶喜好程序相似的多個用戶標識。
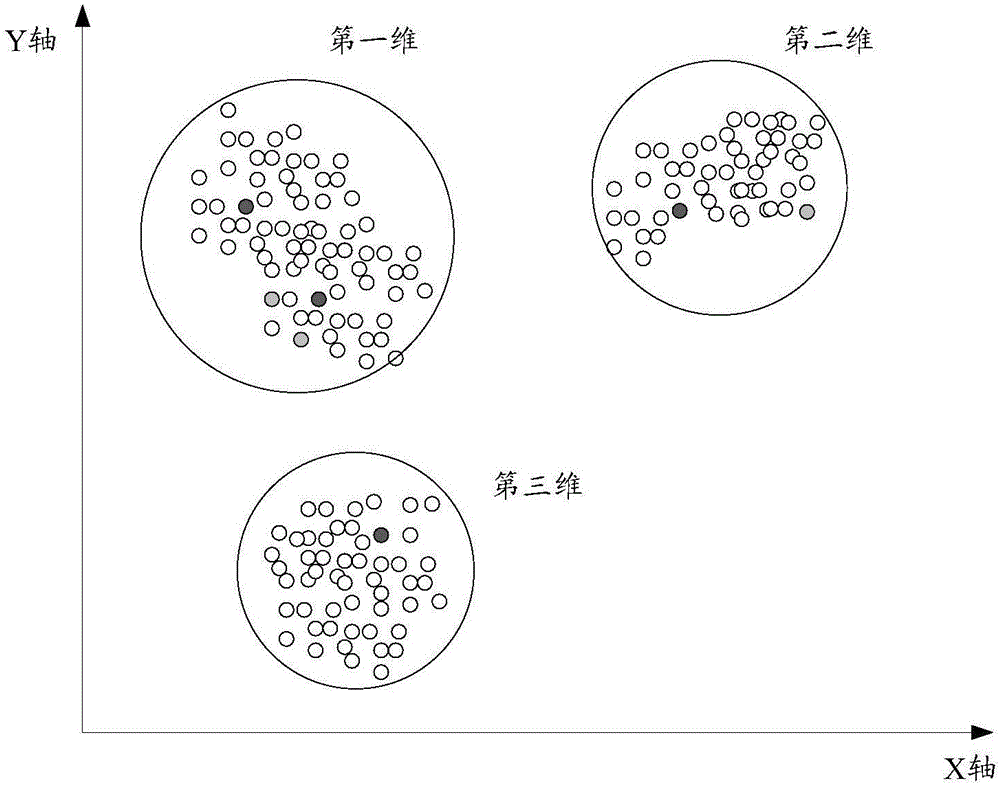
服務器可以將產品標識作為用戶喜好程度值對應的維度。不同的產品標識也就是不同的維度。用戶喜好程度值可以視為空間中散落的記錄點。以空間為二維空間的地圖為例,如圖2所示,每個記錄點可以用經度和緯度來表示。圖2中的X軸可以表示維度,Y軸表示經度。假設,用戶標識1的用戶喜好程度值在圖2中的記錄點采用黑色點來表示,用戶標識2的用戶喜好程度值在圖2中的記錄點采用灰色點來表示。用戶標識1的記錄點有4個,用戶標識2的記錄點有3個。由于每個記錄點的經度和緯度不同,無法直接進行相似度比較。如果利用經度均值和維度均值組成的均值點來進行比較,均值點顯然已經嚴重偏離了用戶的記錄點,不能表達真實的用戶喜好程度值。
為了對用戶喜好程度值進行有效比較,服務器對所有的記錄點進行聚類,例如,服務器可以采用KMeans算法(一種聚類算法)進行聚類得到多個類。每一類都可以有對應的維度。每一類中包括多個用戶標識對應的用戶喜好程度值的記錄點。
服務器根據用戶標識對多個維度的用戶喜好程度值進行統計,得到用戶喜好程度值的統計結果。服務器對統計結果進行正則化處理,得到用戶標識對應的多維向量,根據多維向量計算用戶標識彼此之間的相似距離,將相似距離作為用戶喜好的相似度。
以圖2中的用戶標識1和用戶標識2對應的記錄點為例進行說明。服務器對圖2中的記錄點進行聚類,得到三個維度。其中,用戶標識1在第一維度中有2個記錄點,在第二維度中有1個記錄點,在第三維度中有1個記錄點。用戶標識2在第一維度中有2個記錄點,在第二維度中有1個記錄點,在第三維度中有0個記錄點。服務器統計用戶標識1對應的用戶喜好程度值的記錄點總數為4個,用戶標識2對應的用戶喜好程度值的記錄點總數為3個。服務器對統計結果進行正則化處理,得到用戶標識1對應的多維向量(2/4,1/4,1/4)以及用戶標識2對應的多維向量(2/4,1/4,1/4)。根據多維向量計算用戶標識1與用戶標識2之間的相似距離,將該相似距離作為用戶喜好的相似度。相似距離的計算方法可以有多種,例如采用歐式距離的計算方法等來計算相似距離。
通過計算用戶標識彼此之間用戶喜好的相似度,由此可以在海量的用戶中有效提取出用戶喜好相似的用戶。進而方便對用戶喜好相似的用戶進行消息推薦和消費傾向進行預測。
在一個實施例中,該方法還包括:根據產品標識和用戶標識獲取用戶喜好程度值對應的正樣本和負樣本;將負樣本進行拆分,得到多個拆分后的負樣本,拆分后的負樣本的數量與正樣本的數量的差值在預設范圍內;獲取分類模型,利用正樣本和拆分后的負樣本對分類模型進行訓練,得到多個訓練后的分類模型;對多個訓練后的分類模型進行擬合,計算得到每個訓練后的分類模型對應的分類權重。
本實施例中,服務器還可以根據產品標識和用戶標識獲取用戶喜好程度值對應的正樣本和負樣本。正樣本表示用戶喜歡某產品,負樣本表示用戶不喜歡某產品。例如,正樣本為用戶1喜歡iPhone7(一種手機),負樣本為用戶2不喜歡iPhone7。用戶喜好程度值包括已知的用戶喜好程度值和預測出的用戶喜好程度值。服務器可以采用已知的用戶喜好程度值來進行分類訓練,也可以采用已知的用戶喜好程度值和預測出的用戶喜好程度值進行分類訓練。
正樣本和負樣本可以統稱為樣本。服務器上預先存儲了相應的樣本數據,樣本數據包括用戶特征數據和產品特征數據。其中,用戶特征數據包括用戶的年齡和性別等,產品特征數據包括產品標識和產品類型等。
通常在一個新產品推出時,喜好該新產品的用戶數量要遠遠小于不喜歡該新產品的用戶數量。由此造成用戶對某個產品的正樣本數量要小于負樣本的數量。
傳統的分類訓練方式主要有兩種。傳統的方式一是通過在負樣本進行欠抽樣,得到與正樣本數量相當的負樣本,利用欠抽樣的負樣本與正樣本進行分類訓練。但是由于欠抽樣的負樣本只是負樣本中的一小部分數據,沒有完全利用所有樣本數據,導致分類模型不夠準確。傳統的方式二是通過將正樣本進行復制,使得正樣本的數量與負樣本的數量基本持平。雖然傳統的方式二中沒有增加額外的樣本信息,但是由于負樣本的數量要遠遠大于正樣本的數量,正樣本復制后,導致需要計算的數據量激增,加重了服務器的運算負擔。
為了有效解決傳統方式中出現的樣本數據未充分利用以及樣本數據被全部采用后導致服務器運算負擔加重的問題,本實施例中提供了一種新的分類訓練方式。
具體的,服務器根據產品標識和用戶標識獲取用戶喜好程度值對應的正樣本和負樣本。服務器根據正樣本的數量對負樣本進行拆分。拆分后的負樣本的數量與正樣本的數量的差值在預設范圍內。拆分后的負樣本的數量與正樣本的數量相等或持平。服務器獲取分類模型,其中,分類模型可以采用傳統的分類模型。服務器將每一份拆分后的負樣本和正樣本輸入分類模型進行訓練,得到與拆分后的負樣本數量相同的訓練后的分類模型。
服務器獲取回歸模型,其中,回歸模型可以采用傳統的回歸模型。服務器將多個訓練后的分類模型的輸出結果輸入至回歸模型,通過回歸模型對多個訓練后的分類模型進行擬合,計算得到每個訓練后的分類模型對應的分類權重。在整個過程中,不僅充分利用了所有的樣本數據,而且需要計算的數據來也沒有激增,有效緩解了服務器的運算負擔。
在其中一個實施例中,在計算得到每個訓練后的分類模型對應的分類權重的步驟之后,還包括:獲取待分類樣本數據;利用訓練后的分類模型和分類權重對待分類樣本數據進行分類。
服務器可以獲取待分類的樣本數據,將待分類樣本數據分別輸入至訓練后的分類模型,利用每個訓練后的分類模型和分類權重對待分類樣本數據進行分類。由此可以對待分類樣本數據進行快速有效的分類。
在一個實施例中,如圖3所示,提供了一種服務器300,包括通過系統總線連接的處理器301、內存儲器302、非易失性存儲介質303和網絡接口304。其中,該服務器的非易失性存儲介質303中存儲有操作系統3031和協同過濾裝置3032,協同過濾裝置3032用于實現融合時間因素對用戶喜好程度值進行有效預測。服務器300的處理器301用于提供計算和控制能力,被配置為執行一種融合時間因素的協同過濾方法。服務器300的內存儲器302為非易失性存儲介質中的協同過濾裝置3032的運行提供環境,內存儲器302中可儲存有計算機可讀指令,該計算機可讀指令被處理器執行時,可使得處理器執行一種融合時間因素的協同過濾方法。服務器300的網絡接口304用于據以與外部的終端通過網絡連接通信。服務器300可以用獨立的服務器或者是多個服務器組成的服務器集群來實現。本領域技術人員可以理解,圖3中示出的結構,僅僅是與本申請方案相關的部分結構的框圖,并不構成對本申請方案所應用于其上的服務器的限定,具體的服務器可以包括比圖中所示更多或更少的部件,或者組合某些部件,或者具有不同的部件布置。
在一個實施例中,如圖4所示,提供了一種融合時間因素的協同過濾裝置,包括:模型建立模塊402、獲取模塊404、平滑模塊406、矩陣生成模塊408和第一訓練模塊410,其中:
模型建立模塊402,用于建立指數平滑模型。
獲取模塊404,用于獲取對指數平滑模型擬定的時間段,時間段包括多個時間周期;獲取多個用戶標識以及用戶標識在多個時間周期內對指定產品的用戶喜好程度值。
平滑模塊406,用于利用指數平滑模型對用戶喜好程度值進行迭代計算,得到與時間周期對應的平滑結果。
矩陣生成模塊408,用于利用用戶標識和與時間周期對應的平滑結果生成稀疏矩陣,稀疏矩陣包括多個待預測用戶喜好程度。
獲取模塊404還用于獲取協同過濾模型。
第一訓練模塊410,用于將時間周期對應的平滑結果輸入至協同過濾模型;通過協同過濾模型進行訓練,計算得到稀疏矩陣中的多個待預測用戶喜好程度的預測值。
在一個實施例中,平滑模型的公式包括:
Pt+1=a*Pt+(1-a)*Pt-1;
其中,a表示產品標識對應的指數系數;Pt+1表示下一個時間周期對應的用戶喜好程度值;Pt表示當前時間周期對應的用戶喜好程度值;Pt-1表示上一個時間周期對應的用戶喜好程度值。
在一個實施例中,獲取模塊404還用于獲取用戶喜好程度值對應的維度;如圖5所示,該裝置還包括:統計模塊412、正則化模塊414和相似度計算模塊416,其中:
統計模塊412,用于根據用戶標識對多個維度的用戶喜好程度值進行統計。
正則化模塊414,用于對統計結果進行正則化處理,得到用戶標識對應的多維向量。
相似度計算模塊416,用于根據多維向量計算用戶標識彼此之間的用戶喜好的相似度。
在一個實施例中,獲取模塊404還用于根據產品標識和用戶標識獲取用戶喜好程度值對應的正樣本和負樣本;如圖6所示,該裝置還包括:拆分模塊418、第二訓練模塊420和擬合模塊422,其中:
拆分模塊418,用于將負樣本進行拆分,得到多個拆分后的負樣本,拆分后的負樣本的數量與正樣本的數量的差值在預設范圍內。
獲取模塊404還用于獲取分類模型。
第二訓練模塊420,用于利用正樣本和拆分后的負樣本對分類模型進行訓練,得到多個訓練后的分類模型。
擬合模塊422,用于對多個訓練后的分類模型進行擬合,計算得到每個訓練后的分類模型對應的分類權重。
在一個實施例中,獲取模塊404還用于獲取待分類樣本數據;如圖7所示,該裝置還包括:分類模塊424,用于利用訓練后的分類模型和分類權重對待分類樣本數據進行分類。
本領域普通技術人員可以理解實現上述實施例方法中的全部或部分流程,是可以通過計算機程序來指令相關的硬件來完成,的程序可存儲于一非易失性計算機可讀取存儲介質中,該程序在執行時,可包括如上述各方法的實施例的流程。其中,的存儲介質可為磁碟、光盤、只讀存儲記憶體(Read-Only Memory,ROM)等。
以上實施例的各技術特征可以進行任意的組合,為使描述簡潔,未對上述實施例中的各個技術特征所有可能的組合都進行描述,然而,只要這些技術特征的組合不存在矛盾,都應當認為是本說明書記載的范圍。
以上實施例僅表達了本發明的幾種實施方式,其描述較為具體和詳細,但并不能因此而理解為對發明專利范圍的限制。應當指出的是,對于本領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干變形和改進,這些都屬于本發明的保護范圍。因此,本發明專利的保護范圍應以所附權利要求為準。
- 還沒有人留言評論。精彩留言會獲得點贊!