一種基于瀏覽器內核的網絡爬蟲系統的制作方法
本發明是關于網頁搜索引擎技術領域,特別涉及一種基于瀏覽器內核的網絡爬蟲系統。
背景技術:
網絡爬蟲有著廣泛的應用場景,它是網頁搜索引擎的重要組成部分,也被用來獲取網絡中的特定信息。網絡爬蟲最核心的功能就是從一個頁面中發現其他頁面的URL。
目前常見的網絡爬蟲,都是基于對頁面的靜態分析的——在分析頁面時,不會去動態的執行頁面中的Javascript腳本,也不會加載頁面中的圖片、腳本等資源。靜態分析頁面時,主要提取頁面中的<a>標簽、<form>標簽等可能含有指向其他頁面URL的內容。
隨著互聯網技術飛速發展,網頁的實現方式也越來越多樣化,各種前端技術手段層出不窮,傳統的對頁面進行靜態分析的方法要想分析這些頁面,就變得越來越難,比如:
1.頁面中的按鈕在被點擊時,向服務器的另一個頁面發送一個Ajax請求;
2.頁面中的<a>標簽是在頁面中的Javascript腳本執行時動態生成的。
在例子1中,Ajax請求被發到哪里只有執行過Javascript腳本才知道。Ajax請求的目的URL可能指向一個新的頁面。如果用靜態分析的方法來分析頁面,就可能漏掉這個頁面了。在例子2中,<a>標簽是在瀏覽器中執行Javascript腳本才會產生并顯示給用戶的,如果只是靜態分析,根本無法在頁面的源碼中找到該標簽。
技術實現要素:
本發明的主要目的在于克服現有技術中的不足,提供一種能夠抓取Ajax請求中的URL以及動態構建的DOM節點中含有的URL的系統。為解決上述技術問題,本發明的解決方案是:
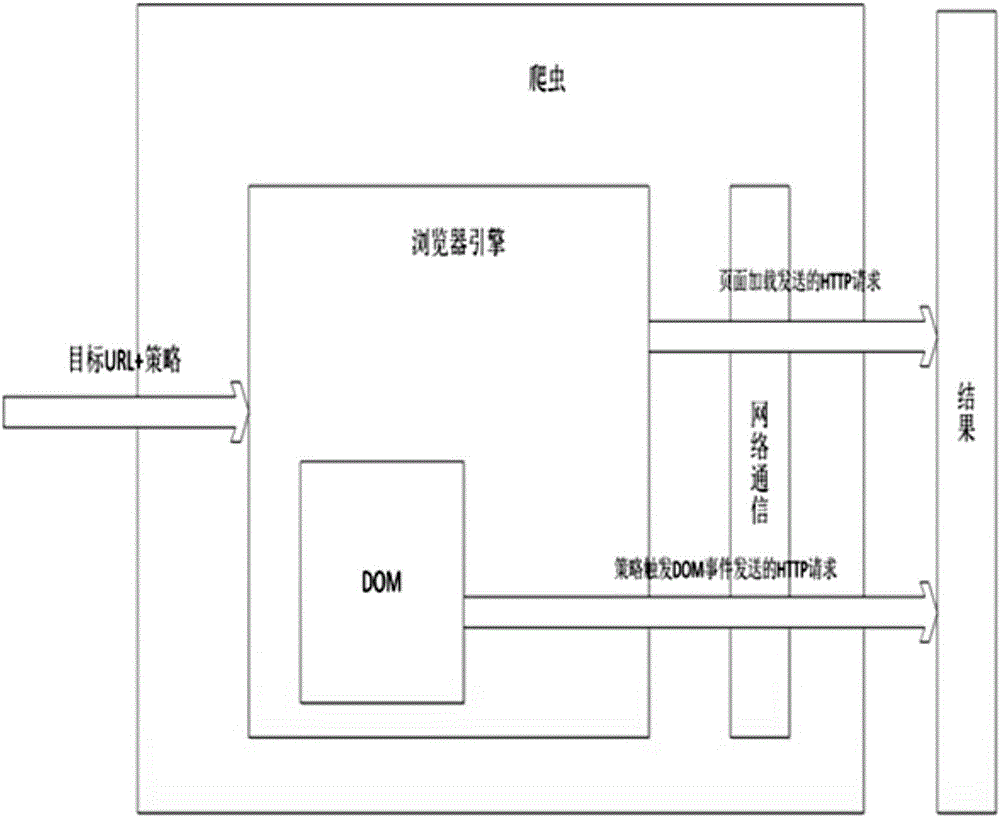
提供一種基于瀏覽器內核的網絡爬蟲系統,用于進行頁面分析并發現其他頁面的URL,所述基于瀏覽器內核的網絡爬蟲系統包括瀏覽器引擎模塊、網絡通信模塊、策略模塊;
所述瀏覽器引擎模塊用于接收一個網頁的URL作為輸入,加載該頁面以及對頁面進行分析,并動態執行頁面中的腳本;瀏覽器引擎模塊在加載完一個頁面之后,能形成一個DOM樹,DOM樹中的需要通過事件觸發JS操作的DOM節點會綁定事件(如點擊、雙擊、鍵盤按鍵等事件);
所述網絡通信模塊是瀏覽器引擎模塊與網絡服務器進行交互的模塊,用于發送和接收網絡數據包,從而獲取URL;網絡通信模塊能處理http請求、ftp通信,并抓取瀏覽器引擎模塊發送的網絡數據包,用于通過抓取的網絡數據包來獲取和本頁面有關的所有其他URL;
所述策略模塊能在瀏覽器引擎模塊一個頁面加載完成后,觸發頁面中的DOM節點綁定的事件,用于執行頁面中只有通過觸發才能執行到的Javascript代碼。
在本發明中,所述瀏覽器引擎模塊能采用webkit、blink、Trident或者Gecko實現。
在本發明中,所述網絡通信模塊能利用瀏覽器引擎模塊中原有的網絡通信接口實現(瀏覽器內核中包含有發送接收網絡數據包的接口,可以通過直接修改該接口將需要的URL數據以一定格式輸出方便獲取),或者使用HOOK技術實現。
在本發明中,所述策略模塊是使用Javascript編寫的腳本文件,用于觸發DOM事件。
提供所述基于瀏覽器內核的網絡爬蟲系統的使用方法,使用基于瀏覽器內核的網絡爬蟲系統處理一個頁面,具體步驟為:
1)輸入一個初始URL地址給瀏覽器引擎;
2)瀏覽器引擎會加載該URL地址的網頁,并加載該網頁內的所有資源,在加載過程中,會發送一些HTTP請求,這些HTTP請求都會被網絡通信部分獲得并保存起來;
3)加載完畢之后,逐個觸發DOM樹中節點所有綁定的事件,有些事件在觸發時,會在DOM中增加新的節點,這部分節點中綁定了事件的,也要逐個觸發事件并注意處理不停產生新節點而導致程序無法結束的問題;在該過程中,瀏覽器引擎又會發送一些HTTP請求,這些HTTP請求同樣都會被網絡通信部分獲得并保存起來;
4)把步驟2)和步驟3)的HTTP請求匯總,根據需求提取所有或部分HTTP請求的URL部分、Method部分、Body部分等,作為輸出的結果。
與現有技術相比,本發明的有益效果是:
本發明使用動態分析技術,通過內置的瀏覽器內核,去動態的加載頁面依賴的資源,并執行Javascript腳本,對DOM節點進行動態的操作如模擬鼠標點擊、雙擊、回車等事件,以發現新的頁面,彌補了傳統爬蟲的不足。
附圖說明
圖1為本發明的工作示意圖。
具體實施方式
首先需要說明的是,本發明涉及網頁搜索引擎技術,是計算機技術在互聯網技術領域的一種應用。在本發明的實現過程中,會涉及到多個軟件功能模塊的應用。申請人認為,如在仔細閱讀申請文件、準確理解本發明的實現原理和發明目的以后,在結合現有公知技術的情況下,本領域技術人員完全可以運用其掌握的軟件編程技能實現本發明。前述軟件功能模塊包括但不限于:瀏覽器引擎模塊、網絡通信模塊、策略模塊等,凡本發明申請文件提及的均屬此范疇,申請人不再一一列舉。
下面結合附圖與具體實施方式對本發明作進一步詳細描述:
如圖1所示的一種基于瀏覽器內核的網絡爬蟲系統包括瀏覽器引擎模塊、網絡通信模塊、策略模塊,用于進行頁面分析并發現其他頁面的URL。
所述瀏覽器引擎用于接收一個網頁的URL作為輸入,加載該頁面以及對頁面進行分析,并動態執行頁面中的腳本,瀏覽器引擎能夠發送網絡數據包。瀏覽器引擎可以是webkit、blink、Trident、Gecko等,也可以是自己實現的一個瀏覽器引擎。
在程序中集成一個瀏覽器引擎之后,可以自己實現網絡通信模塊來處理http請求、ftp通信等,這樣就可以在這部分代碼中抓取瀏覽器引擎的所有網絡數據包。如果不自己實現網絡通信模塊,也可以通過在原有的網絡通信模塊插入代碼,或者直接調用瀏覽器引擎的接口來實現抓取網絡數據包的功能。
瀏覽器引擎在加載一個頁面完畢之后,會形成一個DOM樹,DOM樹中的某些節點會綁定事件(如點擊、雙擊、鍵盤按鍵等事件)。為了讓頁面中的所有的Javascript代碼都執行到,需要逐個觸發DOM樹中節點綁定的事件。如果一個事件的處理函數中有發起Ajax請求的行為,則數據包會被網絡通信模塊抓取到。
使用該基于瀏覽器內核的網絡爬蟲系統處理一個頁面,其具體流程為:
1、輸入一個初始URL地址給瀏覽器引擎。
2、瀏覽器引擎會加載該URL地址的網頁,并加載該網頁內的所有資源(如Javascript,CSS,圖片等),在加載過程中,會發送一些HTTP請求,這些HTTP請求都會被網絡通信部分獲得并保存起來。
3、加載完畢之后,逐個觸發DOM樹中節點所有綁定的事件,有些事件在觸發時,會在DOM中增加新的節點,這部分節點中綁定了事件的,也要逐個觸發事件并注意處理不停產生新節點而導致程序無法結束的問題;在該過程中,瀏覽器引擎又會發送一些HTTP請求,這些HTTP請求同樣都會被網絡通信部分獲得并保存起來。
4、爬蟲程序把步驟2和步驟3的HTTP請求匯總,根據需求提取所有或部分HTTP請求的URL部分、Method部分、Body部分等,作為程序輸出的結果。
最后,需要注意的是,以上列舉的僅是本發明的具體實施例。顯然,本發明不限于以上實施例,還可以有很多變形。本領域的普通技術人員能從本發明公開的內容中直接導出或聯想到的所有變形,均應認為是本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!