用于基于庫的臨界尺寸CD計量的精確和快速的神經網絡訓練的制作方法
本申請是優先權日為2011年3月4日,申請日為2012年2月28日,申請號為“201280010987.4”,而發明名稱為“用于基于庫的臨界尺寸cd計量的精確和快速的神經網絡訓練”的申請的分案申請。
本發明的實施方式為光學計量領域,更具體地,涉及用于基于庫的臨界尺寸(cd)計量的精確和快速的神經網絡訓練。
背景技術:
光學計量技術一般是指如散射測量一樣在制造過程中提供表征工件參數的可能性。在實踐中,將光直接照射在形成于工件的周期光柵上并且測量和分析反射光的光譜來表征該光柵參數。特征化參數可以包括影響材料的反射率和折射率的臨界尺寸(cd),側壁(sidewall)角(swa)和特性高度(ht)等。光柵的特征化因而可以表征工件也可以具有在光柵和工件的形成中利用的制造過程的特征。
在過去的幾年,嚴格耦合波方法(rcwa)和類似算法已廣泛用于衍射結構的研究和設計。在rcwa方法中,周期性結構的輪廓由給定數量的足夠薄的平面光柵板來近似。具體來說,rcwa包含三個主要操作,即,光柵內的場的傅里葉展開、表征衍射信號的恒定系數矩陣的特征值和特征向量的計算,以及由邊界匹配條件推斷出的線性系統的解決方案。rcwa將問題分為三個不同的空間區域:1)支持入射面波場及所有反射的衍射級的總和的周圍區域,2)光柵結構以及下面的非圖案(pattern)層,其中波場被視為與每個衍射級相關聯的模式的疊加,以及3)包含所傳送的波場的基底。
rcwa解決方案的精確度部分依賴于在波場的空間諧波展開中保留的項數,一般滿足能量守恒。保留的項數是在計算過程中考慮到的衍射級數的函數。針對給定的假定輪廓的仿真衍射信號的有效產生包括為衍射信號的橫向磁(tm)分量和/或橫向電(te)分量二者在每個波長處選擇衍射級的最佳集合。在數學上,選擇的衍射級越多,仿真的精確度越高。但是,衍射級數越高,計算仿真的衍射信號所需的計算量也越大。此外,計算時間是所使用的級數的非線性函數。
技術實現要素:
本發明的實施方式包括用于基于庫的cd計量的精確和快速的神經網絡訓練的方法。
在實施方式中,一種用于基于庫的臨界尺寸(cd)計量的精確神經網絡訓練的方法,包括:優化頻譜數據集合的主成分分析(pca)的閾值以提供主成分(pc)值。估計一個或多個神經網絡的訓練目標。基于所述訓練目標及基于從優化所述pca的閾值中提供的所述pc值,訓練所述一個或多個神經網絡。基于一個或多個訓練后的神經網絡提供光譜庫。
在另一實施方式中,一種具有存儲在其上的指令的機器可存取存儲介質,該指令使數據處理系統執行用于基于庫的臨界尺寸(cd)計量的精確神經網絡訓練的方法。該方法包括:優化頻譜數據集合的主成分分析(pca)的閾值以提供主成分(pc)值。估計一個或多個神經網絡的訓練目標。基于所述訓練目標及基于從優化所述pca的閾值中提供的所述pc值,訓練所述一個或多個神經網絡。基于一個或多個訓練后的神經網絡提供光譜庫。
在實施方式中,一種用于基于庫的臨界尺寸(cd)計量的快速神經網絡訓練的方法,該方法包括:為第一神經網絡提供訓練目標。訓練所述第一神經網絡。該訓練包括以預訂數量的神經元開始并迭代增加神經元的數量直至達到優化的神經元的總數量。基于所述訓練和所述優化的神經元的總數量,產生第二神經網絡。基于所述第二神經網絡提供光譜庫。
在另一實施方式中,一種具有存儲在其上的指令的機器可存取存儲介質,該指令使數據處理系統執行用于基于庫的臨界尺寸(cd)計量的快速神經網絡訓練的方法。該方法為第一神經網絡提供訓練目標。訓練所述第一神經網絡。該訓練包括以預訂數量的神經元開始并迭代增加神經元的數量直至達到優化的神經元的總數量。基于所述訓練和所述優化的神經元的總數量產生第二神經網絡。基于所述第二神經網絡提供光譜庫。
附圖說明
圖1描述了根據本發明實施方式的表示用于基于庫的cd計量的精確神經網絡訓練的示例性操作序列的流程圖;
圖2a是展示了與處于off狀態的動態增加的樣本庫相匹配的庫回歸方法的曲線圖;
圖2b是根據本發明實施方式展示了與處于on狀態的動態增加的樣本庫相匹配的庫回歸方法的曲線圖;
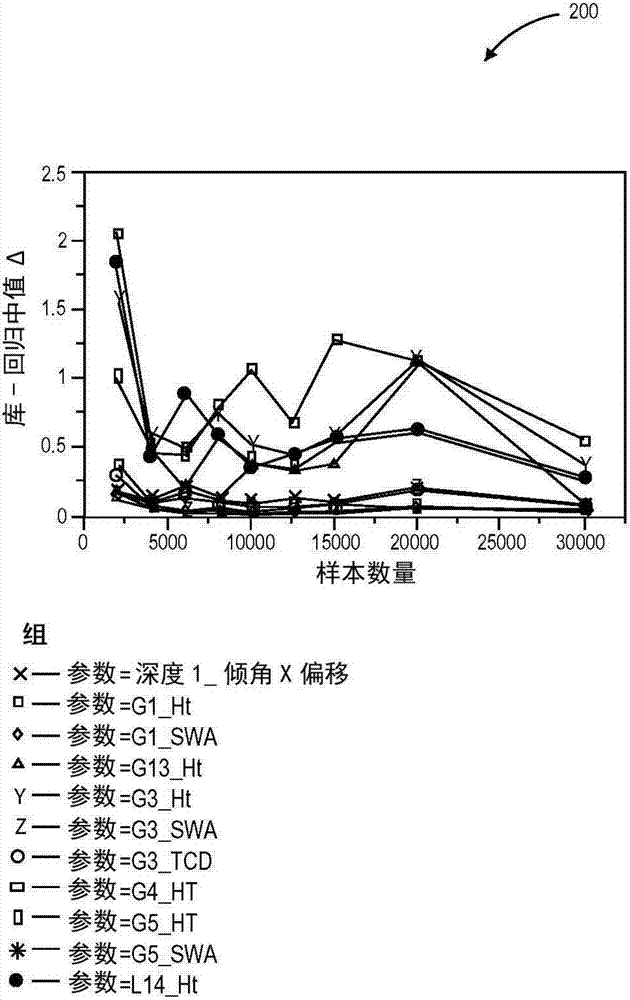
圖2c包括3σ誤差范圍與根據本發明實施方式對比傳統的增加庫樣本大小比較的一對曲線圖;
圖3描述了根據本發明實施方式的表示用于基于庫的cd計量的快速神經網絡訓練的示例性操作序列的流程圖;
圖4a示出了根據本發明實施方式的雙隱藏層神經網絡;
圖4b示出了根據本發明實施方式的用于基于庫的cd計量的快速神經網絡訓練的實際響應曲面的matlab曲線圖;
圖4c是比較根據本發明實施方式的增量算法和單穩態levenberg-marquardt算法的收斂歷史的曲線圖;
圖4d是示出了根據本發明實施方式用于基于庫的cd計量的快速神經網絡訓練的性能比較的曲線圖;
圖4e包括比較根據本發明實施方式用于基于庫的cd計量的快速神經網絡訓練的一個頻譜(spectrum)的結果的一對曲線圖;
圖4f包括比較根據本發明實施方式用于基于庫的cd計量的快速神經網絡訓練的第二頻譜的結果的一對曲線圖;
圖5描述了根據本發明實施方式的用于產生光譜信息的庫的示例性神經網絡的選擇元素;
圖6a描述了根據本發明實施方式的具有在x-y平面改變的輪廓的周期性光柵;
圖6b描述了根據本發明實施方式的具有在x方向改變但不在y方向改變的輪廓的周期性光柵;
圖7描述了根據本發明實施方式的表示用于確定和利用用于自動化處理和設備控制的結構參數的示例性操作序列的流程圖;
圖8是根據本發明實施方式的用于確定和利用用于自動化處理和設備控制的結構參數的系統的示例性框圖;
圖9是根據本發明實施方式示出利用光學計量來確定在半導體晶片上的結構輪廓的體系結構圖;
圖10示出了根據本發明實施方式的示例性計算機系統的框圖;
圖11是根據本發明實施方式表示用于建立參數化模型和以樣本光譜開始的光譜庫的方法中的操作的流程圖。
具體實施方式
于此描述了用于基于庫的cd計量的精確和快速的神經網絡訓練的方法。在以下描述中,為了提供對本發明實施方式的深入理解,提出了許多特定的細節,諸如神經網絡的示例。對本領域技術人員顯而易見的是,本發明實施方式可以在沒有這些特定細節的情況下實施。在其他示例中,為了避免造成本發明實施方式不清楚,沒有具體描述諸如涉及制造光柵結構的操作的已知的處理操作。此外,應當理解的是附圖中顯示的各種實施方式為示意性表示并且沒有必要按比例繪制。
隨著半導體和相關結構的復雜性的增加,用于光學臨界尺寸仿真的庫信息面臨著針對許多最近的應用獲得良好精確度的挑戰。例如,用戶可以花費幾個星期來建立不同的庫,而僅在用于引入計量的實現良好的庫回歸匹配和良好的總計量不確定度(tmu)有困難。本發明的方面可以提供高精確度庫,以及小的庫大小和針對用于的快速解決方案。用于不需要花費幾個星期來建立過多的不同庫但還可以獲得良好的精確度。
許多具有迭代性質的訓練方法已經實施用于庫開發和比較。這些方法包括levenberg-marquardt(列文伯格-馬夸爾特)、反向傳播和n2x算法的改變。這類方法的問題可能是他們非常耗時。如果神經元的數量的推測是正確的,那么算法將用大量迭代進行收斂。如果神經元的數量太少,那么將無法收斂并停止直至神經元的數量命中迭代的最大數量。
在本發明的一個方面,提供了精確的神經網絡訓練方法。圖1描述了根據本發明實施方式的表示用于基于庫的cd計量的精確神經網絡訓練的示例性操作序列的流程圖100。
參照流程圖100的操作102,方法包括優化用于頻譜數據集的主成分分析(pca)的閾值。在實施方式中,該優化即將提供主成分(pc)值。在實施方式中,優化即將最小化pca引入的誤差。以下具體描述了頻譜數據集可以基于從光柵結構的衍射測量中獲得的測量的或仿真的頻譜。
根據本發明的實施方式,pca閾值被自動優化。該優化可以最小化pca引入到隨后的神經網絡訓練的誤差。例如,傳統的方法通常利用恒定值來用于pca閾值,如,pca引入的誤差具有大約10-5的量級。在一個實施方式中,優化pca的閾值包括確定最小級的頻譜域。在一個特定的這類實施方式中,pca引入的誤差具有低于10-5的量級,如,大約10-8至10-9的量級。
在實施方式中,優化pca的閾值包括確定第一pca閾值。例如,給定的pca閾值或分數值可以被設定在t=10-5的閾值。該pca被應用于頻譜數量集。例如,pca被應用于頻譜數據集s以獲得pc值p=t*s,其中t為矩陣。計算通過應用pca引入的頻譜誤差。例如,δs=s-t’*p,其中t’為t的轉置。頻譜誤差然后與頻譜噪聲級進行比較。在一個實施方式中,頻譜誤差級基于光學臨界尺寸(ocd)硬件規格信息。硬件規格信息可以與硬件相關聯,諸如以下與圖9相關聯描述的系統。
在將頻譜誤差與頻譜噪聲級進行比較時,可以應用以下標準:ε為給定標準或默認的頻譜噪聲級,如果δs<ε則輸出t,否則t=t/10且優化被重復。因而,在一個實施方式中,如果頻譜誤差小于頻譜噪聲級,那么第一pca閾值被設定為pc值。在另一實施方式中,如果頻譜誤差大于或等于頻譜噪聲級,則確定第二pca閾值,并且重復應用、計算和比較。
在實施方式中,優化pca的訓練目標包括使用mueller(穆勒)域誤差公差。例如,對于庫訓練中的當前技術,每個pca的誤差目標可以被設定為10-5。對于將誤差目標設定在這個值沒有明確的原因,并且在pca10-5的誤差目標與相關的頻譜誤差之間沒有關系。并且,將每個pca設定為相同的誤差目標未必是有利的,因為他們對頻譜的貢獻可能不同。在以下示例性方法中,mueller域誤差公差被轉換為每個pca域誤差公差并設定作為pca訓練目標。
在訓練之前,神經網絡訓練輪廓被轉換為mueller。根據mueller元素(me),基于訓練樣本數據執行標準化用于每個波長。接著,pca根據標準化mueller元素(nme)被執行以獲得用于訓練的pc信號。因此,在第j個波長的第i個樣本的mueller元素(mij)可以被記為如下:
pc#:總pc數
stdj,meanj:第j個波長標準偏差和平均值
對于每個樣本i,pcip一直與相同的因子相乘以形成mueller元素。如果mij誤差公差被設定為0.001,那么第p個pc將具有以下誤差預算:
其中etp為第p個主成分值的誤差公差。在訓練期間,每個pc將具有其自身的訓練目標,并且為了滿足訓練誤差目標,用于網絡的神經元數量會增加。
參照流程圖100的操作104,方法還包括估計用于一個或多個神經網絡的訓練目標。
根據本發明的實施方式,更加精確的訓練目標被用于每個神經網絡。在一個這類實施方式中,pca和標準化被考慮以估計用于每個神經網絡的訓練目標。在實施方式中,訓練目標基于pca轉換和硬件信號噪聲級而被估計。
參照流程圖100的操作106,方法還包括基于訓練目標和基于pc值來訓練一個或多個神經網絡。
根據本發明的實施方式,過度訓練檢測和控制被執行。方法還可以被用于在levenberg-marquardt(lm)迭代期間增加神經元數量和過度訓練的情況下,檢測和控制過度訓練。在實施方式中,訓練還基于以上操作104的訓練目標。應當理解的是訓練可以基于一個以上的優化的pc值,并且可能基于許多個優化的pc值。未優化的和優化的pc值的組合也可以被使用。
參照流程圖100的操作108,方法還包括基于一個或多個訓練后的神經網絡提供光譜庫。在實施方式中,光譜庫為高精確度的光譜庫。
根據本發明的實施方式,提供了具有良好泛化能力的高精確度庫。在一個這類實施方式中,基于用于每個訓練輸出域的個別誤差目標,動態增加神經元數量的方法通過檢查訓練設定誤差和校驗設定誤差二者的方法而被開發以具有基于高精確度和良好泛化能力的神經元網的庫。之前的神經元數量迭代權值可以被用作用于當前神經網絡結構的初始權值以加速訓練。
在示例性實施方式中,方法已經被開發以改善在用于cd計量的整個庫訓練方法中的多個不同區域中的神經元網的訓練。根據測試,已經獲得了在庫回歸匹配上的實質的改善。例如,庫誤差范圍(諸如3σ誤差范圍)可以比從以前的訓練方法中產生的庫小10倍以上。在實施這樣更小的訓練集的情況下,誤差的范圍可以接近精密級別。使用動態增加的樣本庫的方法可以提供與傳統方法相比改善了的收斂行為,并可能僅需要更小的樣本集來用于建立改善的庫。動態增加的樣本庫的方法的益處在于針對精密級別、更小的庫大小和快速解決方案的高精確度以使用戶獲得非常好的庫以作為最終解決方案。
圖2a是展示了與處于off狀態的動態增加的樣本庫相匹配的庫回歸方法的曲線圖。圖2b是根據本發明實施方式展示了與處于on狀態的動態增加的樣本庫相匹配的庫回歸方法的曲線圖。參照圖2a和2b,采用動態增加的樣本庫的方法on,需要非常少的樣本(如,8000對比30000)來獲得良好的匹配。
圖2c包括比較的3σ(西格瑪)誤差范圍與根據本發明實施方式增加庫樣本大小的一對曲線220和230的圖。參照圖2c,3σ誤差范圍改變以響應樣本大小(如,傳統的方法,動態增加的樣本庫的方法off,5小時;比較本發明實施方式中,動態增加的樣本庫的方法on,3小時)。因而,使用動態增加的樣本庫的方法,實現想要的結果的時間明顯減少了。
在實施方式中,再次參照流程圖100,高精確度光譜庫包括仿真光譜,以及與流程圖100相關描述的方法還包括將仿真光譜與樣本光譜進行比較的操作。在一個實施方式中,仿真光譜從空間諧波級的集合中獲得。在一個實施方式中,樣本光譜從結構中收集,該結構諸如但不限于實體參照樣本或實體生產樣本。在實施方式中,通過使用回歸計算來執行比較。在一個實施方式中,一個或多個非差分信號被同時用于計算中。該一個或多個非差分信號諸如可以為但不限于方位角、入射的角度、偏振器/分析儀角,或額外的測量目標。
在本發明的另一方面,提供了快速神經網絡訓練方法。圖3描述了根據本發明實施方式的表示用于基于庫的cd計量的快速神經網絡訓練的示例性操作序列的流程圖。圖4a-4f還示出了圖3中描述的方法的方面。
參照流程圖300中的操作302,方法包括提供用于第一神經網絡的訓練目標。參照流程圖300中的操作304,該第一神經網絡被訓練,該訓練包括以預定數量的神經元開始并迭代增加神經元的數量直至達到神經元的優化后的總數量。參照流程圖300中的操作306,基于訓練和神經元的優化后的總數量而產生第二神經網絡。應當理解的是,許多這類迭代可以被執行以達到優化后的神經元的總數量。參照流程圖300中的操作308,基于第二神經網絡而提供光譜庫。
在實施方式中,關于“快速”訓練、前饋神經網絡被用于實施非線性映射函數f,因此y≈f(p)。非線性映射函數f被用作確定頻譜或光譜與給定輪廓相關聯的元模型。考慮到計算時間和代價(cost),該確定可以而相當迅速地被執行。在一個實施方式中,該函數在具有訓練數據的集合(pi,yi)的訓練過程中被確定。神經網絡可以被用于近似這類任意非線性函數。例如,圖4a示出了根據本發明實施方式的雙隱藏層神經網絡。
參照圖4a,從輸入p至輸出y的真正的映射函數ftrue(p)能夠以數學方式近似具有雙隱藏層神經網絡400,根據等式1:
y=ftrue(p)≈f(p)=vt*g1[h*g2(w*p+d)+e]+q(1)
其中g1和g2為非線性函數。給定訓練數據的集合(pi,yi),查找w、h、d、e、vt和q的集合,這樣使得f(p)最好地表示ftrue(p)被稱作訓練。該訓練可以被視為求解最優化問題以用于最小化均方誤差,根據等式2:
后續的問題或確定包括,(1)多少隱藏層的神經元應該被使用?,以及(2)神經網絡應該怎樣被訓練以具有規定的精確度?
關于神經元數量的確定,有兩個方法來應對以上第一個問題。第一種方法是試探法。試探法包括設定兩個數,18和30,用于待使用的神經元的最小數量和最大數量。在用于訓練數據的主成分的數量小于或等于25時,使用18個神經元。在主成分的數量大于或等于80時,使用30個神經元。在主成分的數量在二者之間時,線性插值被用于決定神經元的合適數量。試探法的一個潛在的問題可能在于主成分的數量與應使用的神經元的數量無關。
確定應對以上第一個問題的第二種方法為與各種訓練方法相結合的方法。首先,可以使用的神經元的最大數量被估計,如,將數量表示為mmax。然后,以下迭代過程被用于決定神經元的數量及訓練對應的網絡:設定m=10,那么(1)訓練具有m個神經元的網絡;如果該方法收斂,則停止,否則(2)如果(m+5)大于mmax,則停止,否則(3)m增加5,進行操作1。但是,以上的方法可能非常耗時。
推測前饋神經網絡中神經元的最優數量以適合非線性函數是np完全問題(即,沒有具有多項時間復雜度的已知解決方案的一類問題)。因而,根據本發明的實施方式,并如以下更具體的描述,優化的快速方法包括在訓練期間逐漸增加網絡中神經元的數量,直至將提供特定精確度的神經元的最優數量被確定。
關于算法描述,在實施方式中,增量訓練算法是利用算法來訓練神經網絡的復合方法。在一個實施方式中,改進的levenberg-marquardt算法被使用。針對該問題的初始的levenberg-marquardt算法簡要描述如下:表示jacobian(雅克比)
(jtj+μi)δω=jte,
其中i為單位矩陣,μ為每次迭代中調整的縮放常數。用wi+1=wi+δw更新w。用新的w’s估計代價;如果代價低于規定的值(如10-5),則停止。否則,繼續下一次迭代直至迭代的數量大于預定的數量(如,200)。換句話說,算法將停止迭代的可能的情況有兩種。第一種是代價函數低于規定的值。第二種是迭代的數量大于迭代的最大數量。一個觀察為levenberg-marquardt算法在降低迭代的第一10’s中的代價(均方值)中非常有效。在此之后,降低率明顯減慢。
可替代的,在實施方式中,在停止標準處進行于此應用的以上levenberg-marquardt算法的改進。也就是說,一個以上的標準被增加:如果與之前的對于“r”連續迭代的迭代代價相比,代價沒有減少x%,則停止。額外的標準被執行以檢測欠擬合。增量訓練算法接著被提出:給定的訓練集(pi,yi)提供為輸入,以及神經元的數量n、2隱藏層網絡的權值提供為輸出。從此,以下操作被執行:(1)估計神經元的最大數量,如,表示為nmax,(2)神經元的數量n被設定為4,(3)nguyen-widrow算法被用于初始化權值w’s,(4)在(n<nmax)時,(a)網絡使用改進的levenberg-marquardt方法進行訓練,(b)如果代價小于規定的值,那么確定過程停止,(c)如果與之前的具有“r”次連續實驗的代價相比,代價沒有減少x%,那么確定過程停止,(d)視情況,使用校驗數據設定:如果對于t次連續實驗的校驗數據的誤差增加,那么確定過程停止,(e)n被設定為n+2,且新的神經網絡通過使用舊的神經網絡中的訓練權值來構造。然后將隨機數分配給新的權值,并且重復操作4a-e。
應當理解的是levenberg-marquardt的改進可能對于快速訓練方法來說是重要的。改進可以使算法在減少率小的情況下停止并增加所替代的神經元的數量。也就是,改進相當于檢測欠擬合。實際上,一個實施方式中,x=10和r=4被發現為一個好的選擇。除了levenberg-marquardt,還可以使用算法,提供了合適的改進。關于操作4e,諸如levenberg-marquardt的操作通過那些基于梯度的最優化算法使查找跳出經常導致的局部極小。levenberg-marquardt方法提供了權值的初始值的良好集合。以上操作4c和4d為防止具有大量神經元的過度訓練的方法。
在實施方式中,增量算法的進一步擴展可以實施如下,為簡單而假定原始數據被訓練,該原始數據包括不同輪廓的mueller元素,而不是主成分。進一步擴展在以下操作的集合中進行描述:(1)給定的輪廓集合,稱為np,神經網絡使用以上新的算法進行訓練以表示輪廓至一個mueller元素的非線性映射,(2)np+=δnp方法被用于訓練定義了np輪廓的網絡,(a)如果np+=δnp方法停滯,那么神經元的數量增加以更精確地表示非線性映射,(b)如果np+=δnp方法收斂,那么當前網絡被使用,(3)當前神經網絡模型的精確度被估計以用于非線性映射,(a)如果滿足了需要的精確度,那么方法在此停止,(b)否則,輪廓的數量增加δnp,以及方法包括再次返回操作2。
圖4b示出了根據本發明實施方式的用于基于庫的cd計量的快速神經網絡訓練的實際響應曲面的matlab曲線圖410。參照圖4b,具有兩個未知數的函數使用halton擬隨機數量產生器而用于產生1000個訓練樣本及100個校驗樣本。
圖4c是比較根據本發明實施方式的增量算法和單穩態levenberg-marquardt算法的收斂歷史的曲線圖420。參照圖4c,增量訓練算法的收斂歷史與原始levenberg-marquardt算法(標記為單穩態方法,因為該方法提供了具有估計的神經元數量的單穩態訓練,如,每個隱藏層中12個神經元)進行比較。曲線圖420的增量訓練部分因為在4e中的操作而顯示出尖脈沖,但算法在降低回到以前級別的代價中是非常有效的。單穩態方法停滯并未在200次迭代內收斂。levenberg-marquardt的一次迭代的計算復雜度為o(n6),其中n為雙隱藏層網絡中神經元的數量。對于增量算法,擴展時間有神經元數量的最大值的訓練控制。因而,通過比較最后階段的增量訓練中的迭代數量與用于單穩態方法中的迭代數量,所設計的增量算法的性能可以為比單穩態方法更好的數量級。
圖4d是示出了根據本發明實施方式用于基于庫的cd計量的快速神經網絡訓練的性能比較的曲線圖430。參照圖4d,在二維測試示例中,具有四個自由度,一個為頂部尺寸,一個為底部尺寸,以及兩個為高度。這些參數的范圍也被示出了。自動截斷級被用于rcwa仿真。具有251波長。動態增加的樣本庫的方法被啟動,并且有為了建立庫而產生的多于14000個輪廓。
圖4e包括比較根據本發明實施方式用于基于庫的cd計量的快速神經網絡訓練的一個頻譜的結果的一對曲線圖440和450。參照圖4e,為了清楚起見,僅繪制了每個階段的末端處的代價值。采用增量訓練,該應用收斂于127次總迭代且神經元的最終數量為22。應當注意的是在控制部分的最后階段僅有7次迭代。采用使用動態增加的樣本庫的訓練算法,該方法收斂于712次迭代,且神經元的最終數量為25。應當注意的是該方法利用最后階段的111次迭代。
圖4f包括比較根據本發明實施方式用于基于庫的cd計量的快速神經網絡訓練的第二頻譜的結果的一對曲線圖460和470。參照圖4f,如圖4e的在相同測試示例中用于另一頻譜的結果被表示。采用增量訓練,對于最終數量為40的神經元,該方法需要240次總迭代,其中最后階段僅使用9次迭代。采用傳統的訓練方法,該方法在1200次迭代之后并未收斂。
更一般地,至少屬于本發明的一些實施方式,已經找到了新的用于神經網絡的訓練方法。在算法執行期間,隱藏層神經元的優化數量被確定。該算法可以為比單穩態levenberg-marquardt更快的數量級,特別在能夠估計神經元的正確數量的情況下。該算法可以為比傳統方法更快的數量級。在一個實施方式中,隱藏層中神經元的優化數量被確定。在一個實施方式中,以上方法以非常快的方式來訓練網絡。
在實施方式中,再次參照流程圖300,所產生的光譜庫包括仿真頻譜,且與流程圖300相關的描述的方法還包括比較仿真光譜和樣本光譜的操作。在一個實施方式中,仿真光譜從空間諧波級的集合中獲得。在一個實施方式中,樣本光譜從結構中收集,該結構諸如但不限于實體參照樣本或實體生產樣本。在實施方式中,通過使用回歸計算來執行比較。在一個實施方式中,一個或多個非差分信號被同時用于計算中。該一個或多個非差分信號諸如可以為但不限于方位角、入射的角度、偏振器/分析儀角,或額外的測量目標。
任何適合的神經網絡都可以被用于執行與流程圖100和300相關聯的描述的一個或多個方法。作為示例,圖5描述了根據本發明實施方式的用于產生光譜信息的庫的示例性神經網絡的選擇元素。
參照圖5,神經網絡500使用反向傳播算法。神經網絡500包括輸入層502、輸出層504和在輸入層502與輸出層504之間的隱藏層506。輸入層502和隱藏層506使用鏈路508連接。隱藏層506和輸出層504使用鏈路510連接。但是應當理解的是,該神經網絡500可以包括在通常在神經網絡技術中已知的各種配置中連接的任何數量的層。
如在圖5中所描述的,輸入層502包括一個或多個輸入節點512。在本示例性實施方式中,輸入層502中的輸入節點512對應于輪廓模型的輪廓參數,該參數被輸入至神經網絡500。因而,輸入節點512的數量對應于用于描述輪廓模型特征的輪廓參數的數量。例如,如果輪廓模型使用兩個輪廓參數(如頂部臨界尺寸和底部臨界尺寸)被表征,那么輸入層502包括兩個輸入節點512,其中第一輸入節點512對應于第一輪廓參數(如,頂部臨界尺寸),以及第二輸入節點512對應于第二輪廓參數(如,底部臨界尺寸)。
在神經網絡500中,輸出層504包括一個或多個輸出節點514。在本示例性實施方式中,每個輸出節點514均為線性函數。但是應當理解的是,該每個輸出節點514可以為各種類型的函數。此外,在本示例性實施方式中,輸出層504中的輸出節點514對應于從神經網絡500輸出的仿真衍射信號的尺寸。因而,輸出節點514的數量對應于用于表征仿真衍射信號的尺寸的數量。例如,如果仿真衍射信號使用五個尺寸被表征,該五個尺寸例如對應于五個不同的波長,那么輸出層504包括五個輸出節點514,其中第一輸出節點514對應于第一尺寸(如,第一波長),第二輸出節點514對應于第二尺寸(如,第二波長),等等。此外,對于增加的性能,神經網絡500可以基于仿真衍射信號的單獨部分和/或仿真衍射信號的尺寸部分而被劃分為多個子網絡。
在神經網絡500中,隱藏層506包括一個或多個隱藏節點516。在本示例性實施方式中,每個隱藏節點516為s形(sigmoidal)轉移函數或徑向基函數。但是應當認識到,每個隱藏節點516可以為各種類型的函數。此外,在本示例性實施方式中,隱藏節點516的數量基于輸出節點514的數量而被確定。更具體地,隱藏節點516的數量(m)通過預定比率(r=m/n)與輸出節點514的數量(n)相關聯。例如,當r=10時,對于每個輸出節點514有10個隱藏節點516。但是應當認識到,預定比率可以為輸出節點514的數量與隱藏節點516的數量的比率(即,r=n/m)。此外,應當認識到神經網絡500中的隱藏節點516的數量可以在隱藏節點516的初始數量被確定之后基于預定比率進行調整。此外,神經網絡500中的隱藏節點516的數量可以基于經驗和/或試驗而不是基于預定比率來確定。
在實施方式中,以上描述的庫可以包括二維或三維光柵結構中個體特征的一個或多個參數。這里使用的術語“三維光柵結構”是指除了z方向上的深度之外還具有在二維中變化的x-y輪廓的結構。例如,圖6a描述了根據本發明實施方式的具有在x-y平面上變化的輪廓的周期性光柵600。該周期性光柵的輪廓在z方向的變化是x-y輪廓的函數。
這里使用的術語“二維光柵結構”是指除了z方向上的深度之外還具有僅在一個維度變化的x-y輪廓的結構。例如,圖6b描述了根據本發明實施方式的具有在x方向變化但在y方向不變化的輪廓的周期性光柵602。該周期性光柵的輪廓在z方向的變化是x輪廓的函數。可以理解的是,二維結構在y方向上沒有變化不必是無限的,但是在圖案中的任何破壞都被視為長范圍的,如y方向上圖案中的任何破壞基本上進一步與x方向上圖案中的破壞隔開。
在個體特征為二維或三維光柵結構的個體特征的實施方式中,第一參數諸如但不限于個體特征的寬度、高度、長度、上圓角、底部基礎或者側壁角。在晶片結構中諸如折射率索引和消光系數(n和k)的材料的光學性能也可以被模仿以在光學計量中使用。
關于從流程圖100和300的方法中提供的對光譜庫的使用,在實施方式中,這類方法包括基于與光譜庫中的仿真參數一致或不一致來改變處理工具的參數。通過使用諸如但不限于反饋技術、前饋技術和原位控制技術的技術可以執行改變處理工具的參數。在實施方式中,光譜庫可以被用于更精確地建立裝置結構輪廓和cd計量工具配方(recipe)中的幾何結構。在實施方式中,光譜庫被用作cd計量工具校驗、診斷和特征的一部分。
如上所述,光譜庫的使用可以包括將仿真光譜與樣本光譜進行比較。在一個實施方式中,衍射級的集合被仿真以表示來自二或三維光柵結構的由橢圓偏振(ellipsometric)光學計量系統產生的衍射信號。這類光學計量系統以下參照圖9被描述。但是,應當理解的是相同的概念和原理同樣適用于其他光學計量系統,諸如反射測量系統。所表示的衍射信號可以說明諸如但不限于輪廓、尺寸或材料組成物的二維或三維光柵結構的特征。
基于計算的仿真衍射級可以指示有圖案的膜(諸如有圖案的半導體膜或光阻層)的輪廓參數,并可以被用于校準自動過程或設備控制。圖7描述了根據本發明實施方式的表示確定和使用用于自動過程和設備控制的結構參數(諸如輪廓參數)的操作的示例性序列的流程圖700。
參考流程圖700的操作702,光譜庫或訓練的機器學習系統(mls)被開發用于從測量的衍射信號的集合中提取輪廓參數。在操作704中,使用光譜庫或訓練的mls來確定結構的至少一個輪廓參數。在操作706中,至少一個輪廓參數被傳送至制造群(fabricationcluster),該制造群被配置成執行處理操作,其中處理操作可以在完成測量操作704之前或之后在半導體加工過程中執行。在操作708中,使用至少一個所傳送的輪廓參數來修改由制造群執行的處理操作的過程變量或設備設置。
對于機器學習系統和算法的更加具體的描述,參見2003年6月27日提交的名稱為opticalmetrologyofstructuresformedonsemiconductorwafersusingmachinelearningsystems的美國專利申請no.7,831,528,該申請的全部以引用的方式結合于此。對于用于二維重復結構的衍射級優化的描述,參見2006年3月24日提交的名稱為optimizationofdiffractionorderselectionfortwo-dimensionalstructures的美國專利申請no.7,428,060,該申請的全部以引用的方式結合于此。
圖8是根據本發明實施方式確定和利用用于自動化處理和設備控制的結構參數(諸如輪廓參數)的系統800的示例性框圖。系統800包括第一制造群802和光學計量系統804。系統800還包括第二制造群806。雖然在圖8中將第二制造群806描述成在第一制造群802之后,但是應當理解的是,在系統800中(以及如在加工過程流中),第二制造群806可以位于第一制造群802前面。
光刻工藝,諸如曝光并顯影施加在晶片上的光阻層,可以使用第一制造群802來執行。在一個示例性實施方式中,光學計量系統804包括光學計量工具808和處理器810。光學計量工具808被配置成測量從結構中獲得的衍射信號。如果測量到的衍射信號和仿真衍射信號相匹配,則將輪廓參數的一個或多個值確定為與仿真衍射信號相關聯的輪廓參數的一個或多個值。
在一個示例性實施方式中,光學計量系統804還可以包括光譜庫812,該光譜庫812具有多個仿真衍射信號和與多個仿真衍射信號相關聯的一個或多個輪廓參數的多個值。如上所述,可以預先產生光譜庫。計量處理器810可以將從結構中獲得的測量到的衍射信號與光譜庫中的多個仿真衍射信號進行比較。當找到匹配的仿真衍射信號時,與光譜庫中的匹配的仿真衍射信號相關聯的輪廓參數的一個或多個值被認為是在制造結構的晶片應用中使用的輪廓參數的一個或多個值。
系統800還包括計量處理器816。在一個示例性實施方式中,處理器810可以將一個或多個輪廓參數的一個或多個值傳送到計量處理器816。計量處理器816然后可以基于使用光學計量系統804確定的一個或多個輪廓參數的一個或多個值來調整第一制造群802的一個或多個過程參數或設備設置。計量處理器816還可以基于使用光學計量系統804確定的一個或多個輪廓參數的一個或多個值來調整第二制造群806的一個或多個過程參數或設備設置。以上應當注意的是,制造群806可以在制造群802之前或之后對晶片進行處理。在另一個示例性實施方式中,處理器810被配置成使用作為機器學習系統814的輸入的測量到的衍射信號的集合和作為機器學習系統814的期望輸出的輪廓參數來訓練機器學習系統814。
圖9是根據本發明實施方式示出利用光學計量來確定在半導體晶片上的結構輪廓的體系結構圖。光學計量系統900包括在晶片908的目標結構906處投射計量光束904的計量光束源902。計量光束904以入射角θ向目標結構906投射。計量光束接收器912測量衍射光束910。衍射光束數據914被傳送到輪廓應用服務器916。輪廓應用服務器916將測量到的衍射光束數據914與仿真衍射光束數據的光譜庫918進行比較,該仿真衍射光束數據表示目標結構的臨界維度和分辨率的變化的組合。
根據本發明的實施方式,仿真衍射光束數據的至少一部分基于對兩個或更多個方位角確定的差。根據本發明的另一個實施方式,仿真衍射光束數據的至少一部分基于對兩個或更多個入射角確定的差。在一個示例性實施方式中,選擇與測量到的衍射光束數據914最佳匹配的光譜庫918實例。可以理解的是,雖然衍射光譜的光譜庫或信號以及相關聯的假定的輪廓被頻繁用于闡釋概念和原理,但是本發明同樣應用于包括仿真衍射信號和相關聯的輪廓參數的集合(諸如在用于輪廓提取的回歸、神經網絡以及類似的方法中)的光譜數據空間。所選的光譜庫916實例的假定輪廓和相關聯的臨界維度被視為對應于目標結構906的特征的臨界維度和實際截面輪廓。光學計量系統900可以利用反射儀、橢偏儀(ellipsometer)或其他光學計量設備來測量衍射光束或信號。
存儲在光譜庫918中的輪廓模型的集合可以由使用輪廓參數集合來表征輪廓模型以及改變輪廓參數集合以產生變化的形狀和尺寸的輪廓模型來產生。使用輪廓參數集合表征輪廓模型的過程被稱為參數化。例如,假定輪廓模型可以分別由定義其高度和寬度的輪廓參數h1和w1表征。輪廓模型的其他形狀和特征可以通過增加輪廓參數的數量來進行表征。例如,輪廓模型可以通過分別定義其高度、底部寬度和頂部寬度的輪廓參數h1、w1和w2來進行表征。應當注意的是,輪廓模型的寬度可以被稱為臨界尺寸(cd)。例如,輪廓參數w1和w2可以被描述為分別定義了輪廓模型的底部cd和頂部cd。應當理解的是各種類型的輪廓參數可以被用于表征輪廓模型,包括但不限于入射角(aoi)、傾角(pitch)、n&k、硬件參數(如,極化角)。
如上所述,存儲在光譜庫918中的輪廓模型的集合可以通過改變表征輪廓模型的輪廓參數而產生。例如,通過改變輪廓參數h1、w1和w2,可以產生變化的形狀和尺寸的輪廓模型。應當注意的是,輪廓參數中的一者、二者或所有三個輪廓參數可以相對于另一個而改變。同樣地,與匹配的仿真衍射信號相關聯的輪廓模型的輪廓參數可以被用于確定正在被檢查的結構特征。例如,對應于底部cd的輪廓模型的輪廓參數可以被用于確定正在被檢查的結構的底部cd。
本發明的實施方式還可以適用于各種膜堆棧(filmstack)。例如,在實施方式中,膜堆棧包括單個層或多個層。并且,在實施方式中,分析或測量的光柵結構包括三維組件和二維組件二者。例如,基于仿真衍射數據的計算效率可以通過利用二維組件對整個結構的更簡單的貢獻及其衍射數據而被優化。
為了便于描述本發明的實施方式,橢偏度量(ellipsometric)光學計量系統被用于說明上述概念和原理。應當理解的是,相同的概念和原理同樣應用于其他光學計量系統,諸如反射度量系統。以類似的方式,半導體晶片可以被利用于說明概念的應用。此外,方法和過程同等地應用于具有重復結構的其他工件。在實施方式中,光學散射測量是諸如但不限于光學橢圓偏振光譜測量(se)、光束輪廓反射測量(bpr)和增強型紫外線反射測量(euvr)的技術。
本發明可以被提供為計算機程序產品或軟件,其可以包括在其上存儲有指令的機器可讀介質,所述指令可以用于對計算機系統(或其他電子設備)進行編程以執行根據本發明的過程。機器可讀介質包括用于以機器(如計算機)可讀的方式存儲或傳送信息的任意機制。例如,機器可讀(如計算機可讀)介質包括機器(如計算機)可讀存儲介質(如,只讀存儲器(“rom”)、隨機存取存儲器(“ram”)、磁盤存儲介質、光存儲介質、閃存設備等)、機器(如計算機)可讀傳輸介質(電、光、聲或其他形式的傳播信號(如,載波、紅外信號、數字信號等))等。
圖10示出了以計算機系統1000的示例性形式的機器的圖形描述,在該計算機系統1000中可以執行指令集合,該指令集合用于使機器執行于此所討論的方法中的任意一種或多種。在可替換的實施方式中,機器可以連接(如網絡連接)到局域網(lan)、內聯網、外聯網或因特網中的其他機器。機器可以在客戶端-服務器網絡環境中的服務器或客戶機的容量(capacity)中進行操作,或作為端對端(或分布式)網絡環境中的對等機器進行操作。機器可以是個人計算機(pc)、平板pc、機頂盒(stb)、個人數字助理(pda)、蜂窩電話、網絡設備、服務器、網絡路由器、交換機或網橋、或能夠執行機器采取的指定動作的指令集合(按順序或其他)的任意機器。此外,雖然僅示出了單個機器,但是術語“機器”也包括獨自或聯合執行指令集合(或多個集合)以執行于此所述的方法中的任意一種或多種方法的機器(如計算機)的任意集合。
示例性計算機系統1000包括處理器1002、主存儲器1004(如,只讀存儲器(rom)、閃存、動態隨機存取存儲器(dram)(諸如同步dram(sdram)或內存總線dram(rdram)等))、靜態存儲器1006(如,閃存、靜態隨機存取存儲器(sram)等)以及輔助存儲器1018(如,數據存儲設備),它們經由總線1030彼此通信。
處理器1002表示一個或多個通用處理設備,諸如微處理器、中央處理單元等。更特別地,處理器1002可以是復雜指令集計算(cisc)微處理器、精簡指令集計算(risc)微處理器、超長指令字(vliw)微處理器、執行其他指令集的處理器或執行指令集的組合的處理器。處理器1002還可以是一個或多個專用處理設備,諸如應用程序專用集成電路(asic)、現場可編程門陣列(fpga)、數字信號處理器(dsp)、網絡處理器等。處理器1002被配置成執行用于執行這里所述的操作的處理邏輯1026。
計算機系統1000還可以包括網絡接口設備1008。計算機系統1000還可以包括視頻顯示單元1010(如液晶顯示器(lcd)或陰極射線管(crt))、字母數字輸入設備1012(如鍵盤)、光標控制設備814(如鼠標)以及信號產生設備1016(如,揚聲器)。
輔助存儲器1018可以包括機器可訪問存儲介質(或更具體地計算機可讀存儲介質)1031,在其上存儲有體現這里描述的方法或功能的任意一者或多者的一個或多個指令集(如軟件1022)。在計算機系統1000執行該軟件1022的過程中,軟件1022還可以完全地或至少部分地位于主存儲器1004內和/或處理器1002內,主存儲器1004和處理器1002也構成機器可讀存儲介質。軟件1022還可以經由網絡接口設備1008在網絡1020上被傳送或接收。
雖然在示例性實施方式中將機器可訪問存儲介質1031示為單個介質,但術語“機器可讀存儲介質”應當被認為包括存儲一個或多個指令集的單個介質或多個介質(如,集中式或分布式數據庫,和/或相關聯的緩存和服務器)。術語“機器可讀存儲介質”還應當被認為包括能夠存儲或編碼由機器執行并使機器執行本發明的方法的任意一者或多者的指令集的任意介質。術語“機器可讀存儲介質”因此應當被認為包括但不限于固態存儲器及光和磁性介質。
根據本發明的實施方式,機器可訪問存儲介質具有存儲在其上的指令,該指令使數據處理系統執行用于基于庫的cd計量的精確的神經網絡訓練的方法。該方法包括優化用于頻譜數據集合的主成分分析(pca)的閾值以提供主成分(pc)值。一個或多個神經網絡的目標基于該pc值進行估計。一個或多個神經網絡基于訓練目標和pc值進行訓練。光譜庫基于一個或多個訓練后的神經網絡而提供。
在實施方式中,優化pca的閾值包括確定最低級別的頻譜域。
在實施方式中,優化pca的閾值包括確定第一pca閾值、將pca應用至頻譜數據集合、計算通過應用pca引入的頻譜誤差,以及比較頻譜誤差和頻譜噪聲級別。在一個這類實施方式中,如果頻譜誤差小于頻譜噪聲級別,那么第一pca閾值被設定為pc值。在另一個這類實施方式中,如果頻譜誤差大于或等于頻譜噪聲級別,則確定第二pca閾值,并且重復應用、計算和比較過程。
在實施方式中,優化pca的閾值包括使用mueller域誤差公差。
在實施方式中,高精確度光譜庫包括仿真頻譜,以及該方法還包括比較仿真頻譜與樣本頻譜。
根據本發明的另一實施方式,機器可訪問存儲介質具有存儲在其上的指令,該指令使數據處理系統執行用于基于庫的cd計量的快速神經網絡訓練的方法。該方法包括提供第一神經網絡的訓練目標。訓練第一神經網絡。該訓練包括以預定數量的神經元開始,并迭代地增加神經元的數量直至達到優化的神經元的總數。基于訓練和優化的神經元的總數產生第二神經網絡。基于第二神經網絡而提供光譜庫。
在實施方式中,迭代地增加神經元的數量直至達到優化的神經元的總數包括使用改進的levenberg-marquardt方法。
在實施方式中,迭代地增加神經元的數量包括增加第一神經網絡的隱藏層中的神經元的數量。
在實施方式中,光譜庫包括仿真頻譜,并且該方法還包括比較仿真頻譜與樣本頻譜。
對測量到的光譜的分析一般包括將測量到的樣本光譜與仿真光譜進行比較以推導出最佳地描述測量到的樣本的模型參數值。圖11是根據本發明實施方式表示用于建立參數化模型和以樣本光譜開始(如,源于一個或多個工件)的光譜庫的方法中的操作的流程圖。
在操作1101,由用戶定義一組材料文檔來指定形成測量到的樣本特征的材料的特征(如n,k值)。
在操作1102,散射測量用戶通過選擇一個或多個材料文檔來集成對應于待測量的當前在周期性光柵特征中的材料堆來定義預期的樣本結構的標稱模型。該用戶定義的模型可以進一步通過模型參數的標稱值的定義而被參數化,諸如表征正在被測量的特性的形狀的厚度、臨界尺寸(cd)、側壁角(swa)、高度(ht)、邊緣粗糙度、圓角半徑等。根據2d模型(即輪廓)或者3d模型是否被定義,具有30-50或者更多的這種模型參數并不罕見。
根據參數化模型,針對給定的光柵參數值的集合的仿真光譜可以使用諸如嚴格耦合波分析(rcwa)的算法的嚴格衍射建模算法進行計算。然后回歸分析在操作1103處被執行直至參數化的模型收斂于表征最終輪廓模型(針對2d)的模型參數值的集合,該最終輪廓模型對應于仿真光譜,該仿真光譜將測量到的衍射光譜與預定的匹配標準匹配。假定與匹配的仿真衍射信號相關聯的最終輪廓模型表示產生模型的結構的實際輪廓。
接著在操作1104處,匹配的仿真光譜和/或相關的優化的輪廓模型可以被利用以通過擾動參數化的最終輪廓模型的值來產生仿真衍射光譜的庫。接著在生產環境中操作的散射測量系統可以使用仿真衍射光譜的最終庫以確定隨后測量到的光柵結構是否已經根據規格被制造。庫的產生1104可以包括諸如神經網絡的機器學習系統為多個輪廓中的每個輪廓產生仿真光譜信息,每個輪廓包括一個或多個模型化的輪廓參數的集合。為了產生庫,機器學習系統本身可能必須經歷一些基于光譜信息的訓練數據集合的訓練。這種訓練可以是密集型計算和/或可能必須針對不同模型和/或輪廓參數域被重復。產生庫的計算負載中非常低的效率可能通過用戶對訓練數據集合的大小的決定而引起。例如,選擇極大的訓練數據集合可能導致不必要的訓練計算,同時用大小不足的訓練數據集合可能需要重新訓練來產生庫。
在此描述的一些實施方式包括自動確定在訓練機器學習系統中使用的訓練數據集合的大小。一般地,訓練數據集合基于數據集合特征度量標準的收斂程度依大小排列,并且可以進一步基于對最終解的誤差的估計依大小排列。訓練數據集合逐漸被擴展和測試以識別收斂,并且在一些實施方式中,可以提供估計這種樣本大小的最終解誤差。逐漸擴展和測試被執行直到收斂標準被滿足和/或最終解誤差的估計達到域值。
因為在此描述的確定訓練矩陣大小的方法不需要單獨的訓練,用于神經網絡訓練的良好的訓練數據樣本集合被快速、有效地識別,并且能夠很好地控制最終解誤差。隨著訓練數據樣本集合被識別,機器學習系統可以接著被訓練以產生期望的目標函數信息。在一個特定的實施方式中,機器學習系統被訓練以產生仿真光譜信息(如衍射信號)的庫,該庫可以被用來減少用散射測量系統測量的未知樣本(如衍射光柵或晶片周期結構)的參數。
應當理解的是在本發明實施方式的思想和范圍之內以上方法可以在各種環境情況下被應用。例如,在實施方式中,以上描述的方法在半導體、太陽能、發光二極管(led)或相關的制造過程中被執行。在實施方式中,以上描述的方法被用于單獨的或集成的計量工具中。在實施方式中,以上描述的方法被用于單個或多個測量目標回歸中。
從而,于此已經公開了用于基于庫的cd計量的精確和快速的神經網絡訓練的方法。根據本發明的實施方式,用于基于庫的cd計量的精確神經網絡訓練的方法包括優化頻譜數據集合的主成分分析(pca)的閾值以提供主成分(pc)值。該方法還包括估計一個或多個神經網絡的訓練目標。該方法還包括基于pc值和訓練目標來訓練一個或多個神經網絡。該方法還包括基于一個或多個訓練后的神經網絡來提供光譜庫。在一個實施方式中,優化pca的閾值包括確定最低級別的頻譜域。根據本發明的實施方式,用于基于庫的cd計量的快速神經網絡訓練的方法包括提供用于第一神經網絡的訓練目標。該方法還包括訓練該第一神經網絡,該訓練包括以神經元的預訂數量開始并迭代地增加神經元的數量直至達到優化的神經元的總數量。該方法還包括基于訓練和優化的神經元的總數量來產生第二神經網絡。該方法還包括基于第二神經網絡來提供光譜庫。在一個實施方式中,迭代地增加神經元的數量直至達到優化的神經元的總數量包括使用改進的levenberg-marquardt方法。
- 還沒有人留言評論。精彩留言會獲得點贊!