基于分布式防噪聲干擾的社交網絡推薦方法及系統與流程
本發明屬于計算機技術領域,涉及通過計算機來完成的信息推薦技術,尤其涉及基于分布式集群的推薦方法。
背景技術:
自十二五大數據戰略提出,面對信息化高度膨脹、海量數據的低價值密度行業背景,社交系統商業推薦面臨信息過載愈現突出。隨著云計算、人工智能與大數據的行業融合,基于社交網路的商業推薦應用愈現重要,商業推薦系統的出現極大程度上緩解了數據冗余、信息過載難題。
但傳統單機的推薦算法運算能力有限,日益膨脹的網絡數據量逐漸超出傳統推薦算法的承受極限。隨著IDC分布式集群的深入化,基于分布式集群的推薦算法破除了傳統社交網絡推薦算法的運算瓶頸,大大提升商業推薦的計算性能。
如申請號為CN2011101256632的中國專利申請(發明人:邱飛、陳國慶)提出的一種基于云計算的推薦系統構建方法。該方法首先構建多個節點的Hadoop云平臺,然后采用MapReduce作為分布式并行計算模型,在Hadoop上構建Mahout中間件,再根據業務需求定制Mahout算法庫,在Mahout中間件上實現傳統推進算法、偽分布式推進算法和分布式算法,最后根據用戶需求,通過設置Mahout算法庫中算法的相關參數大小或調用不同算法構建推薦應用框架。該方法將串行推薦算法與MapReduce結合實現并行算法,有效地提高了處理的效率,能完成單機下無法處理的大量數據,解決了傳統社交網絡推薦算法的運算瓶頸問題。
然而,不論是傳統社交網絡推薦算法,還是后來提出的基于云分布式集群的推薦算法,其設計基礎都基于相對理想化的網絡環境,而忽略了噪聲干擾對推薦結果的影響。現實中,不可避免地會有用戶出于不正當的目的,利用社交網絡推薦的漏洞,采用批量植入虛假用戶等方法,達到低評分或高評分的惡意攻擊或虛假宣傳的目的。
例如電商平臺,其中也會存在大量的噪聲評分,而現有行業推薦的算法并未能將這一因素考慮在內。其結果是虛假用戶的植入在很大程度上影響、阻礙物聯網社區用戶的購買可信度。
申請號為201510186307X的中國專利申請公開的基于協同過濾推薦算法的手機機型推薦方法中,提出了去除噪聲的概念,但是其給出的去除噪聲的方法基于正規手機均帶有唯一串號這一特點,將串號重復的山寨機做為噪聲排除在推薦目標之外。其去除噪聲的方法不具有普遍適用性。
技術實現要素:
本發明目的是在上述現有商業化推薦結果受噪聲影響較大的現實背景下,提出一種基于分布式防噪聲干擾的社交網絡推薦策略,以實現更真實、更具有粘性的推薦系統。
為實現上述目的,本發明采用的技術方案是:
一種用于網絡推薦的防噪聲干擾方法,包括如下步驟:
步驟S1,獲取網絡服務器中用戶對商品的評分ru,i;
步驟S2,甄別噪聲評分,并對噪聲評分進行校正;
步驟S3,將經過校正的評分ru,i=nu,i用于推薦。
進一步地,步驟S2所述甄別噪聲評分的方法為:設定最高評分閾值β和最低評分閾值γ,將ru,i≥βu或ru,i≤γu的評分判斷為噪聲評分。
進一步地,步驟S2所述對噪聲評分進行校正的方法為:基于步驟S1獲取的用戶對商品的評分構建觀測評分矩陣R=[r1,r2,...,rn],ru,i∈R,利用觀測評分矩陣R,通過協同過濾算法預測對商品給出噪聲評分的用戶對該商品的評分,將預測評分值作為校正評分。
本發明進一步提出一種基于分布式防噪聲干擾的社交網絡推薦方法,包括如下步驟:
步驟S1,獲取網絡服務器中用戶對商品的評分ru,i;
步驟S2,甄別其中的噪聲評分,并對其中的噪聲評分進行校正;
步驟S3-1,將校正過噪聲評分的評分存儲于Hadoop分布式集群中;
步驟S3-2,Hadoop分布式集群將其存儲的評分分發至實時推薦集群中;
步驟S3-3,實時推薦集群判斷目標用戶可能感興趣的商品,并推薦給目標用戶。
進一步地,步驟S2中甄別噪聲評分的方法為:設定最高評分閾值β和最低評分閾值γ,將ru,i≥βu或ru,i≤γu的評分判斷為噪聲評分。
進一步地,步驟S2中對噪聲評分進行校正的方法為:基于步驟S1獲取的用戶對商品的評分構建觀測評分矩陣R=[r1,r2,...,rn],ru,i∈R,利用觀測評分矩陣R,通過協同過濾算法預測對商品給出噪聲評分的用戶對該商品的評分,將預測評分值作為校正評分。
進一步地,步驟S3-3中,采用非負矩陣分解算法對經噪聲校正的評分矩陣進行降維處理,采用協同過濾算法預測目標用戶對商品的評分,根據預測評分判斷目標用戶可能感興趣的商品。
本發明還提出一種基于分布式防噪聲干擾的社交網絡推薦系統,包括評分處理系統、Hadoop分布式集群、實時推薦集群,所述評分處理系統包括噪聲甄別系統、噪聲校正系統;
所述評分處理系統獲取網絡服務器中用戶對商品的評分ru,i;
所述噪聲甄別系統甄別評分處理系統所獲取的評分中的噪聲評分;
所述噪聲校正系統對甄別的噪聲評分進行校正;
所述評分處理系統將校正過噪聲評分的評分數據存儲于Hadoop分布式集群中;
所述Hadoop分布式集群將其存儲的評分數據分發至實時推薦集群中;
所述實時推薦集群根據評分數據判斷目標用戶可能感興趣的商品,并推薦給目標用戶。
進一步地,噪聲甄別系統中設定有最高評分閾值β和最低評分閾值γ,噪聲甄別系統將ru,i≥βu或ru,i≤γu的評分判斷為噪聲評分。
進一步地,噪聲校正系統基于評分處理系統獲取的用戶對商品的評分構建觀測評分矩陣R=[r1,r2,...,rn],ru,i∈R,利用觀測評分矩陣R,通過協同過濾算法預測對商品給出噪聲評分的用戶對該商品的評分,將預測評分值作為校正評分。
本發明解決了商業推薦中噪聲干擾問題,很好的剔除大量作弊網絡評分提高推薦行業的置信度;并且與行業發展方向接軌,具有普適性,為商業推薦提供一致的方法論。
附圖說明
圖1為本發明防噪聲推薦系統服務器框架示意圖。
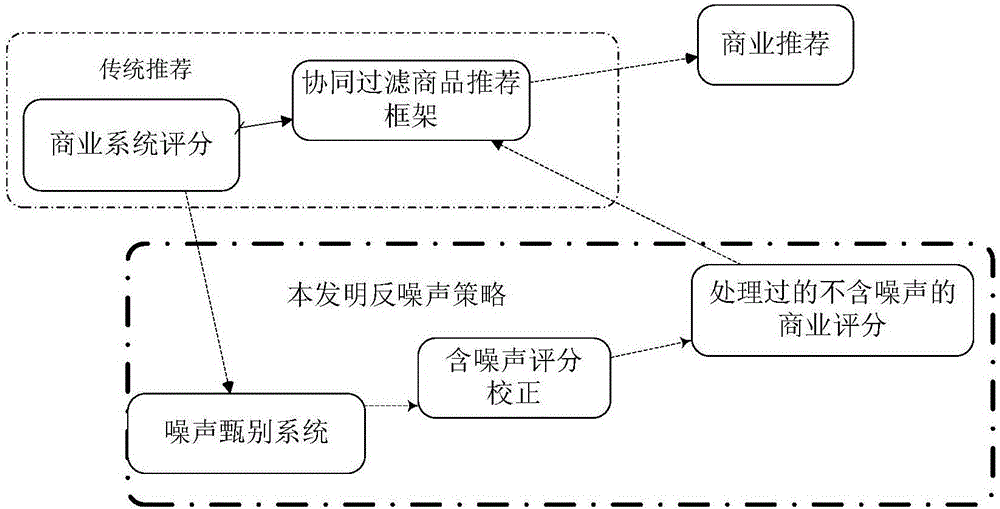
圖2為本發明防噪聲推薦系統原理框圖。
圖3為本發明噪聲甄別過程流程圖。
具體實施方式
下面結合附圖對本發明的技術方案做進一步的解釋說明。
參照圖1,本發明提出的網絡推薦方法基于分布式集群實現,本發明將推薦系統完全構建于分布式集群中,通過多臺服務器完成數據的計算過程,其計算能力具有巨大的擴展空間,尤其適于大數據背景下的網絡推薦。在本發明防噪聲的社交網絡推薦構架中將清洗過的ETL商業數據存儲于Hadoop分布式集群中,將集群處理后的數據分發至實時推薦集群中供進行處理完成對用戶的推薦。
參照圖2,本發明在傳統推薦方法中引入噪聲處理機制,在對于系統評分采用協同過濾算法進行處理之前,先對系統評分逐一進行噪聲甄別,篩選出其中的噪聲評分,并對噪聲評分進行校正,最后將其中噪聲評分經過校正的評分集用于推薦。
以下為實現噪聲甄別的技術說明
一、甄別噪聲干擾源機制
為甄別自然噪聲的評論干擾,我們將噪聲源分為、基于用戶評論的噪聲、基于商品的噪聲。下面分別給出技術定義。
基于用戶評分的噪聲甄別技術定義:
A、正向評價:給予商品過高評分;
B、平均水平:用戶給予一般評分;
C、偏激:給予極低評分;
D、跟風:持續保持一貫風格評分。
基于商品評分的噪聲甄別技術定義:
A、火熱化:被大量用戶給予高評分;
B、平均水平:一般評分;
C、偏激:不被大多數用戶接受;
D、遲疑性:懷有矛盾意見的評分。
二、噪聲甄別技術層框架:
1、本發明與傳統社交網絡推薦相比,引入惡意廣告甄別系統
2、并對含噪聲的評分進行技術校正,將處理后的不含噪聲的評分采用協同過濾推薦框架進行推薦;
3、本發明添加的防噪聲干擾系統采用非負矩陣分解策略,將超高維的系統評分降維至低維,并建立用戶無物品圖。
三、噪聲甄別技術實現層:
(1)模型轉換層:給定商業ETL數據的用戶集U及物品集合I,那么最原始的用戶商品矩陣R=[r1,r2,...,rn],ru,i∈R,為用戶u對物品i的評分。基于矩陣分解的協同過濾模型旨在利用觀測評分矩陣R,構造預測矩陣R=PQ,顯然,R由兩個低秩的因子P,Q構成,特征維數為f。其數學模型即最小化目標函數使觀測矩陣與預測矩陣的最小方差最小,其目標函數數學形式如下:
其中,b為評分線性偏置相,mu為常數校準。
(2)用戶甄別系統數學定義:根據前述節一的甄別機制,給出用戶技術層數學定義:
(a).偏激集其中γ為最低評分閾值
(b).平均水平集:其中β為最高評分閾值
(c).正向集:
(3)用戶甄別系統技術實現層:
讀取評分值ru,i,對比ru,i和γu,若ru,i≤γu,則將ru,i置于集合Weak,若否,則對比ru,i和βu,若ru,i≥βu,將ru,i置于集合Pos,若否,則將ru,i置于集合Aver。如圖3所示。
(4)含噪聲評分系統實現層偽代碼:
本發明創造性地提出噪聲評分校正機制,而不是簡單粗暴地將判斷為噪聲的評分剔除,不僅有效消除噪聲對網絡推薦結果的影響,還進一步避免了因為數據缺失而導致的結果失真,下面舉例說明本發明的防噪聲干擾的社交網絡推薦具體過程。
實施例1
步驟1,從網絡服務器獲取一組用戶u作為用戶集U,再獲取一組商品對象i作為商品集I,獲取用戶集U中各用戶u分別對商品集I中各商品i的評分r。
步驟2,根據獲取的評分r建立一個用戶-商品的評分矩陣R=[r1,r2,...,rn],ru,i∈R,為用戶u對物品i的評分。在該矩陣中,橫向排列的是同一用戶針對不同商品的評分,縱向排列的是不同用戶針對同一商品的評分,若用戶對某商品未評分,則取數值0。
步驟3,分別對用戶集U中各用戶u設置最高評分閾值β和最低評分閾值γ。
步驟4,逐一讀取評分值ru,i,對比ru,i和γu,若ru,i≤γu,則將ru,i置于集合Weak,若否,則對比ru,i和βu,若ru,i≥βu,將ru,i置于集合Pos,若否,則將ru,i置于集合Aver。
步驟5,通過下式逐一計算集合Weak和Pos中的評分的預測評分。
步驟6,以步驟5計算獲得的預測評分與集合Aver中的評分重新組成評分矩陣。
步驟7,基于步驟6的評分矩陣,通過下式逐一計算目標用戶到其他用戶間的相似度。
式中,和分別表示用戶ui和uj在評分矩陣中所對應的向量。
步驟8,選擇與目標用戶相似度大于預設閾值的n個用戶,計算該n個用戶對同一商品的評分的平均值。
步驟9,將平均值最高的一個或幾個商品推薦給目標用戶。
本實施例直接將評分矩陣中用戶對各商品的評分集作為一用戶特征向量。邏輯簡單直接,當評分矩陣維數較低時,計算效率高。
實施例2
步驟1,從網絡服務器獲取一組用戶u作為用戶集U,再獲取一組商品對象i作為商品集I,獲取用戶集U中各用戶u分別對商品集I中各商品i的評分r。
步驟2,根據獲取的評分r建立一個用戶-商品的評分矩陣R=[r1,r2,...,rn],ru,i∈R,為用戶u對物品i的評分。在該矩陣中,橫向排列的是同一用戶針對不同商品的評分,縱向排列的是不同用戶針對同一商品的評分,若用戶對某商品未評分,則取數值0。
步驟3,分別對用戶集U中各用戶u設置最高評分閾值β和最低評分閾值γ。
步驟4,逐一讀取評分值ru,i,對比ru,i和γu,若ru,i≤γu,則將ru,i置于集合Weak,若否,則對比ru,i和βu,若ru,i≥βu,將ru,i置于集合Pos,若否,則將ru,i置于集合Aver。
步驟5,通過下式逐一計算集合Weak和Pos中的評分的預測評分。
步驟6,以步驟5計算獲得的預測評分與集合Aver中的評分重新組成評分矩陣。
步驟7,對步驟6的評分矩陣,采用非負矩陣分解算法進行降維處理,獲得用戶特征向量。
步驟8,通過下式逐一計算目標用戶到其他用戶間的相似度。
式中,和分別表示用戶ui和uj的特征向量。
步驟9,選擇與目標用戶相似度大于預設閾值的n個用戶,計算該n個用戶對同一商品的評分的平均值。
步驟10,將平均值最高的一個或幾個商品推薦給目標用戶。
本例在計算用戶相似度之前,先采用非負矩陣分解算法對評分矩陣進行降維處理,當評分矩陣維數高,數據量龐大時,效率提高顯著。
實施例3
步驟1,從網絡服務器獲取一組用戶u作為用戶集U,再獲取一組商品對象i作為商品集I,獲取用戶集U中各用戶u分別對商品集I中各商品i的評分r。
步驟2,根據獲取的評分r建立一個用戶-商品的評分矩陣R=[r1,r2,...,rn],ru,i∈R,為用戶u對物品i的評分。在該矩陣中,橫向排列的是同一用戶針對不同商品的評分,縱向排列的是不同用戶針對同一商品的評分,若用戶對某商品未評分,則以一預設值作為假定的評分,例如預設值取最高評分與最低評分的平均值。
步驟3,分別對用戶集U中各用戶u設置最高評分閾值β和最低評分閾值γ。
步驟4,逐一讀取評分值ru,i,對比ru,i和γu,若ru,i≥γu,則將ru,i置于集合Weak,若否,則對比ru,i和βu,若ru,i≥βu,將ru,i置于集合Pos,若否,則將ru,i置于集合Aver。
步驟5,通過下式逐一計算集合Weak和Pos中的評分的預測評分。
步驟6,以步驟5計算獲得的預測評分與集合Aver中的評分重新組成評分矩陣。
步驟7,對步驟6的評分矩陣,采用非負矩陣分解算法進行降維處理,獲得用戶特征向量。
步驟8,通過下式逐一計算目標用戶到其他用戶間的相似度。
式中,和分別表示用戶ui和uj的特征向量。
步驟9,選擇與目標用戶相似度大于預設閾值的n個用戶,計算該n個用戶對同一商品的評分的平均值。
步驟10,將平均值最高的一個或幾個商品推薦給目標用戶。
如果簡單地以0作為未評分用戶的假定評分,則會拉低平均評分,尤其對于評分總量較少的新的商品來說,預測的評分將失真嚴重,本實施例中,對此預設一個假定評分,例如最高分與最低分的平均值,可以避免因未評分導致的預測偏差。
以上三個實施例相對較為典型,然而在具體實踐過程中,實施者可以根據實際情況做出調整,以靈活應用,例如:可以用基于商品相似度的預測評分算法替代上述實施例中的基于用戶相似度的預測評分算法。再例如,采用基于模型的評分預測方法預測評分,針對評分矩陣建立訓練模型,采用交替最小二乘法對訓練模型進行處理。再例如,采用Pearson相似度算法替代以上實施例中的余弦相似度算法,等等。
本發明技術所具有的有益效果有如下幾點:
1.針對傳統商業推薦的噪聲難題的性能,部署分布式集群;
2.解決商業推薦中噪聲干擾,很好的剔除大量作弊網絡評分提高推薦行業的置信度;
3.與行業發展方向接軌,具有普適性,為商業推薦提供一致的方法論;
4.提出了具有創造性的方法甄別惡意評分。
本文中所描述的優選實施例僅僅是對本發明精神作舉例說明。本發明所屬技術領域的技術人員可以對所描述的具體實施例做各種的修改或補充或采用類似的方式替代,但并不會偏離本發明的精神或者超越所附權利要求書所定義的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!