一種基于投票方式的數據融合方法與流程
本發明涉及數據管理與數據分析領域,尤其是一種基于投票方式的數據融合方法。
背景技術:
對于絕大部分數據庫及數據應用而言,用戶是希望數據庫(或數據集)中的數據是具備唯一性的,包括唯一表述,亦即沒有冗余數據。然而,現實情況中,數據冗余無可避免的會產生。產生數據冗余的原因眾多,例如多源數據的拼寫不一致、簡寫與縮寫、詞序顛倒等。數據融合的主要目的之一便是消除數據冗余,并將多源數據合并為一個整體。
消除數據冗余的過程可以理解為判斷一個數據對是否表示的是同一個實體,若是同一實體,則可進行融合操作。現在已經有若干(類)算法解決這個問題,例如基于編輯距離的算法、基于語音的算法、基于令牌的算法、基于對照表的方法等。然而,不同類的算法只對某些特定的情形起作用,而無法普遍使用。例如,基于編輯距離求近似度的算法可以有效的發現由于拼寫錯誤造成的冗余,但對于縮寫、詞序顛倒等情形則無能為力。
技術實現要素:
發明目的:為解決現有消除數據冗余的算法只能對某些特定的情形起作用,而無法普遍使用的技術問題,本發明提出一種基于投票方式的數據融合方法。
技術方案:為實現上述技術效果,本發明提出的技術方案為:
一種基于投票方式的數據融合方法,包括步驟:
(1)將現有的用于判斷一個數據對是否表示同一實體的經典算法分劃為四個集合:G1、G2、G3、G4;其中,G1表示基于編輯距離的算法集合,G2表示基于語音的算法集合,G3表示基于令牌的算法集合,G4表示基于對照表的算法集合;
(2)各算法集合分別給出關于待判定數據對的投票結果;對于任意一個算法集合Gi,其對待判定數據對的投票結果Si的計算方法為:
其中,Ji表示算法集合Gi中算法的總數,Sij表示采用算法集合Gi中第j個算法計算出的給定數據對的相似度值;
(3)給定閾值θ,0<θ<1;根據步驟(2)的計算結果,判斷是否存在Si滿足:Si>θ;若存在,則判定給出的待判定數據對為同一實體,對待判定數據對進行融合;若不存在,則執行步驟(4);
(4)將待比較的兩個數據項A和B分別以單詞為單位進行分解,形成兩個待比較集合RA和RB;RA={A1,A2,…,Am,…AM},RB={B1,B2,…,Bn,…BN};
(5)定義集合算法G12,G12=G1∪G2;從G12中任意選取一個算法,并執行以下步驟:
(5-1)以RA和RB作為頂點集構建完全二部圖;構建出的完全二部圖中,每條邊的權值為采用選出的算法計算出的該邊連接的兩個單詞之間的相似度值;
(5-2)為步驟(5-1)構建的完全二部圖中的每條邊分配一個權值系數;求出完全二部圖的所有最大匹配,并求出每一個最大匹配的權值和為:
式中,Sx為所構建的完全二部圖第x個最大匹配的權值和,k為第x個最大匹配中的邊的總數,wi為第x個最大匹配中第i條邊的權值,f(wi)為第x個最大匹配中第i條邊分配到的權值系數;
(5-3)找出最大的權值和,并將該權值和賦值給S0;
(5-4)定義閾值τ;判斷是否滿足S0>τ,若滿足,則判定給出的待判定數據對為同一實體,對待判定數據對進行融合;若不滿足,則從G12中刪除算法p,并轉入步驟(5-5);
(5-5)判斷G12是否為空集,若G12為空集,則停止迭代,并判定數據項A和B為不同實體;若G12不為空集,則從G12中任意選取一個算法,并返回步驟(5-1)。
進一步的,所述現有的用于判斷一個數據對是否表示同一實體的經典算法包括:Edit Distance算法,Q-Grams算法,Jaro-Winkler Distance算法,Smith-Waterman Distance算法,Atomic String算法,WHIRL算法,Q-Grams with tf.idf算法,Soundex算法,Metaphone算法。
進一步的,計算近似度值時,判斷待比較的兩個數據對是滿足以下條件:
①等價;
②規則等價;
③一個數據為另一個數據的前綴;
若滿足條件①至③中任意一個條件,則令兩個數據對的相似度值為1;否則,兩個數據對的相似度值為采用對應算法計算出的實際相似度值。
進一步的,所述步驟(5-2)中權值系數f(wi)的表達式為:f(wi)=wi。
有益效果:與現有技術相比,本發明針對多源數據可能造成的數據冗余問題,首先,按照算法的基本原理與適用類型,對現有去冗余算法進行分析并分組;再將所有算法以投票的方式對數據對是否表示同一實體進行判斷,最后得出綜合分析結果。采用本發明提供的方法能夠擴大現存算法的適用范圍,并提高數據融合的效率與精度。
附圖說明
圖1為實施例的流程原理圖;
圖2為實施例中第一部分所述每種算法單獨投票的流程圖;
圖3為實施例中第二部分所述基于多種算法融合的近似度計算流程圖;
圖4為實施例中構建的完全二部圖示意圖;
圖5為實施例中給出的對照表示意圖。
具體實施方式
本發明針對數據對的融合問題,提出了一種基于投票方式的數據融合方法,下面結合附圖對本發明作更進一步的說明。
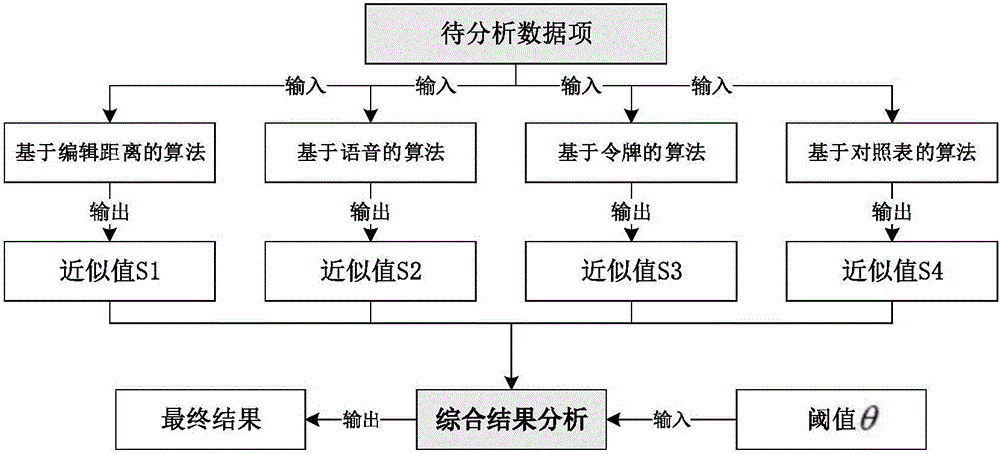
本發明的原理如圖1所示,包括以下步驟:
1)對現存算法進行原理與適用性分析,并將算法分成若干組;
2)對于給定的數據對,每種算法獨立給出判斷或近似度,即每種算法單獨投票過程;
3)判斷數據對是否表示同一實體。若是,則結束;否則,執行下一步。
4)執行基于多種算法融合的近似度計算,計算出數據對的近似度。
5)根據步驟4)的計算結果判斷數據是否表示同一實體。
由上述原理流程可知,本發明提供的方法可以分為兩部分,第一部分為每種算法單獨投票,第二部分為基于多種算法融合的近似度計算。
第一部分每種算法單獨投票的流程圖如圖2所示,包括步驟:
(1)對現存經典算法進行原理與適用性分析,并將算法分成若干組。
所討論的經典算法包括:Edit Distance,Q-Grams,Jaro-Winkler Distance,Smith-Waterman Distance,Atomic String,WHIRL,Q-Grams with tf.idf,Soundex,Metaphone等。將算法分成四大類:基于編輯距離的算法、基于語音的算法、基于令牌的算法、基于對照表的算法,分別用G1、G2、G3和G4表示。例如,若G1包含Edit Distance,Jaro-Winkler Distance,Smith-Waterman Distance三個算法,可表示為G1={G11,G12,G13},其中G1=Edit Distance,G12=Jaro-Winkler Distance,G3=Smith-Waterman Distance。若某一算法對待分析數據行進行運算并給出近似度的值,將該值以Sij的形式表示;例如S12表示Jaro-Winkler Distance算法給出的近似值,即該算法的投票結果。
此外,對于基于對照表的算法,應該給出一個附件的對照表,以表示表中成對的單詞是等效的。對照表為領域知識的體現,根據不同使用場景,由用戶自行提供。例如,若是對人名進行分析是,則DANNY和DANIEL是等價的;在考慮簡寫時,NUAA和Nanjing University of Aeronautics and Astronautics是等價的。總之,依據領域知識給出可擴展的對照表,圖5給出了一個對照表的示例,該對照表中,每一行的數據項均表示同一個實體。
(2)對于給定的數據對(單詞對),每種算法獨立給出判斷或近似度,即投票過程。
對于G1、G2、G3和G4四個分組中的每一類算法,分別針對待分析數據對進行計算,并給出投票結果,這一結果為近似度值。在計算近似度時,一般包括這幾種情形:等價(指字符串等價);規則等價(由于特定規則,如對照表等,而確定的等價);前綴(某數據項是另一個數據項的前綴,如Prof和Professor);一般近似度(如編輯距離或基于發音計算的距離)。前面三種情況可以判斷其近似度為1.0,最后一種情況則是根據上述9種算法計算所得出的近似度值。
(3)分析投票結果,判斷數據對是否表示同一實體。
在已知各算法給出的近似度的情況下,分別求出每一組算法的近似度均值,分別表示為S1、S2、S3和S4;例如:
定義一個閾值θ,θ介于0到1之間。若某一分組的近似度均值大于閾值θ,則認為當前的數據對表示同一實體,可以進行融合,操作結束;否則,執行第二部分基于多種算法融合的近似度計算。
第二部分基于多種算法融合的近似度計算流程如圖3所示,包括步驟:
將基于編輯距離(Edit-based)的算法或基于語音的算法與基于令牌(Token-based)的算法進行組合,基于編輯距離的算法在計算單個詞匯時具有較高的精確度,而無法處理較復雜的組合結構;而基于令牌的算法則在處理復雜結構時具有一些優勢。其基本思想為對數據項A和B的每對詞條按照基于編輯距離的算法給出一個近似度值,然后根據基于令牌的算法思想找出總近似度最大的一種有效組合。具體為:
假定待分析的兩個數據項為A和B;其中,數據項A可以分成詞條:A1,A2,…,Am,…AM,數據項B可以分成詞條:B1,B2,…,Bn,…BN,Am、Bn為基本單詞(字符串)。
基于對數據項A和B的分解,計算每一對Am和Bn的近似度值。計算近似度值時,仍然考慮等價、規則等價和前綴等情形。
在上述近似度值的基礎上,找出一種使得近似度值最大的一種組合。其基本原理為:將數據項A和B的基本單詞分成兩列形成兩個待比較集合RA和RB;其中,RA={A1,A2,…,Am,…AM},RB={B1,B2,…,Bn,…BN};以RA和RB作為頂點集從而構成一個二部圖,而且是完全二部圖,該完全二部圖如圖4所示。圖中邊是帶權值的,其值即為兩個頂點(單詞)的近似度。
在帶權二部圖的基礎上,找出該二部圖的一個最大匹配,使得這個最大匹配的權值和最大。當這一最大匹配確定時,即可得出數據項A和B的近似度。找最大匹配的過程可以通過匈牙利算法(Hungarian Algorithm)實現。
進一步地,我們希望高相似度以及低相似度的配對在最終判定時起到不同程度決定作用。為了加大高相似度與低相似度的區分程度,我們在計算相似度值之和時為高低相似度賦以不同的權重,即乘以一個系數。于是最終的相似度值之和可以表示為:
式中,Sx為所構建的完全二部圖第x個最大匹配的權值和,k為第x個最大匹配中的邊的總數,wi為第x個最大匹配中第i條邊的權值,f(wi)為第x個最大匹配中第i條邊分配到的權值系數,以區分高低相似度在最終判定時的決定作用。系數的確定可以是一個線性函數或指數函數,例如f=w。組合算法的結果用S0表示。
在上述基于編輯距離的算法和基于令牌的算法進行融合的過程中,在第一步計算兩個詞條近似度時,除了可以采用基于編輯距離的算法,還可以采用基于語音的算法,即將基于語音的算法和基于令牌的算法進行融合。
判斷基于多種算法融合的方法執行結果。
針對基于多種算法融合的方法,在判讀兩個數據項是否表示同一實體時,可以直接計算出其近似度值,定義一個閾值τ,若近似度超過閾值τ則認為該數據項對表示同一實體;否則,不表示同一實體。
以上所述僅是本發明的優選實施方式,應當指出:對于本技術領域的普通技術人員來說,在不脫離本發明原理的前提下,還可以做出若干改進和潤飾,這些改進和潤飾也應視為本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!