一種政務數據采集共享系統與方法與流程
本發明涉及數據采集領域,具體涉及一種政務數據采集系統及其方法。
背景技術:
隨著電子辦公化的普及,各政府部門也加入了此行列。由于政府部門常常需要通過網絡發布各種與人們日常生活息息相關的信息,因此,與政府部門相關的政務數據采集成為政府部門有效開展工作的重要工作。
目前,各級地方政府的數據不是統一開放的,政務數據的采集存在多源頭、多類型和多渠道等問題,難以有效的進行政務數據的采集。
技術實現要素:
針對上述技術問題,本發明提供一種能夠有效進行政務數據采集的政務數據采集系統及其方法。
本發明采用的技術方案為:
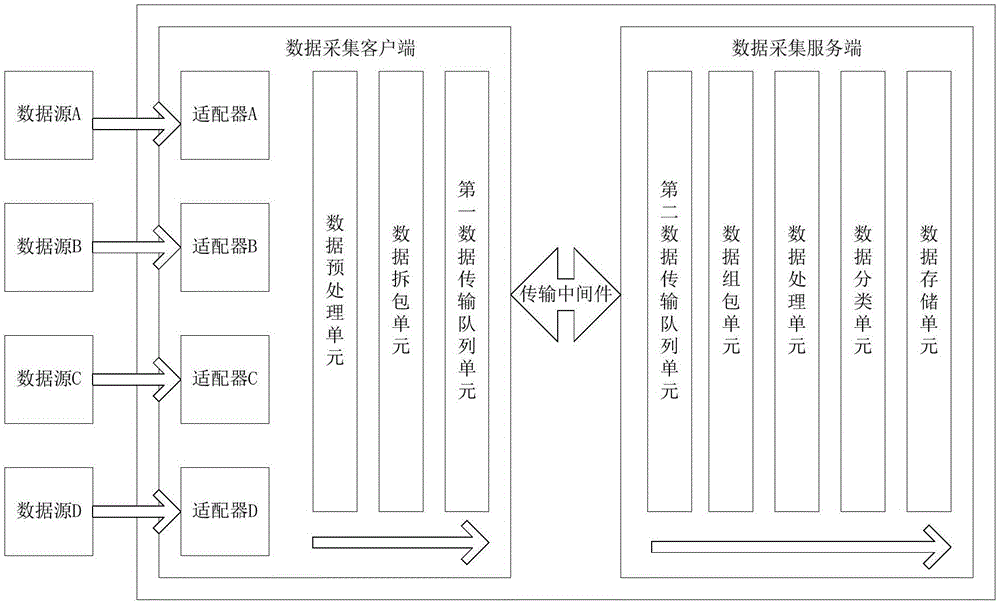
本發明的一實施例提供一種政務數據采集系統,包括數據采集客戶端、傳輸中間件和數據采集服務端,數據采集客戶端設置有多個具有不同接入方式的適配器、數據預處理單元、數據拆包單元和第一數據傳輸隊列單元;數據采集服務端包括第二數據傳輸隊列單元、數據組包單元、數據處理單元、數據分類單元和數據存儲單元,其中,多個適配器用于同時采集具有不同的數據傳輸協議的多種數據源,采集的數據源依次經過數據預處理單元、數據拆包單元和第一數據傳輸隊列單元處理后,由傳輸中間件發送給數據采集服務端的第二數據傳輸隊列單元,并依次通過數據組包單元、數據處理單元、數據分類單元和數據存儲單元進行處理。
可選地,數據預處理單元用于過濾掉采集的數據源中的無效數據和臟數據并將有效數據進行緩存;數據拆包單元用于將經數據預處理單元處理后的數據按照預設拆包協議格式進行拆分,拆分成多個個體較小的的數據包,并記錄整個數據包的描述信息以及每個拆分后小數據包的描述信息,最終將這些描述信息與拆分后的數據包一并發送到第一數據傳輸隊列單元;第一數據傳輸隊列單元用于將經數據拆包單元處理后的數據進行排隊并發送到傳輸中間件。
可選地,整個數據包的描述信息包括數據標識、數據名稱、數據內容描述、數據發布時間、數據所屬分類信息、數據關鍵字信息、數據定義版本、數據更新版本、數據提供單位、數據提供機構信息和數據定義信息、唯一ID值和整個數據包的MD5值;小數據包的描述信息包括所屬整個數據包的UUID值、小數據包的MD5值、小數據包所屬整個數據包的順序、小數據包的名稱、小數據包的大小。
可選地,傳輸中間件通過多線程的異步非阻塞方式將數據采集客戶端的第一數據傳輸隊列單元中的數據包發往數據采集服務端的第二數據傳輸隊列單元中。
可選地,第二數據傳輸隊列單元用于接收由傳輸中間件傳輸過來的數據包;數據組包單元用于將第二數據傳輸隊列單元接收的零散的數據包按照預設組包協議格式進行組裝成原數據包;數據處理單元用于將數據組包單元組裝的原數據包進行數據業務關聯,形成價值數據;數據分類單元用于將經數據處理單元處理后的數據分為結構化數據、半結構化數據和非結構化數據;數據存儲單元用于將不同類型的數據分類進行分布式異構存儲,其中,結構化數據采用關系型數據庫,半結構化數據采用Mongodb和NFS方式進行存儲,非結構化數據采用Hadoop集群的方式進行存儲。
本發明的另一實施例提供一種政務數據采集方法,包括以下步驟:
S100:數據采集客戶端通過具有多種接入方式的適配器同時采集具有不同數據傳輸協議的多種數據源,并將采集的數據源依次經歷數據預處理、數據拆包和數據傳輸隊列,并將處理后的數據源發送給傳輸中間件發進行發送;S200:數據采集服務端接收傳輸中間件發送的數據源,并將接收的數據源依次經歷數據傳輸隊列、數據組包、數據處理、數據分類和數據存儲。
可選地,數據預處理用于過濾掉采集的數據源中的無效數據和臟數據并將有效數據進行緩存;數據拆包用于將經數據預處理單元處理后的數據按照預設拆包協議格式進行拆分,拆分成多個個體較小的的數據包,并記錄整個數據包的描述信息以及每個拆分后小數據包的描述信息,最終將這些描述信息與拆分后的數據包一并發送到數據傳輸隊列單元;數據采集客戶端的數據傳輸隊列用于將經數據拆包單元處理后的數據進行排隊并發送到傳輸中間件。
可選地,整個數據包的描述信息包括數據標識、數據名稱、數據內容描述、數據發布時間、數據所屬分類信息、數據關鍵字信息、數據定義版本、數據更新版本、數據提供單位、數據提供機構信息和數據定義信息、唯一ID值和整個數據包的MD5值;小數據包的描述信息包括所屬整個數據包的UUID值、小數據包的MD5值、小數據包所屬整個數據包的順序、小數據包的名稱、小數據包的大小。可選地,傳輸中間件通過多線程的異步非阻塞方式將數據采集客戶端的數據傳輸隊列中的數據包發往數據采集服務端的數據傳輸隊列中。
可選地,數據采集服務端的數據傳輸隊列用于接收由傳輸中間件傳輸過來的數據包;數據組包用于將數據采集服務端的數據傳輸隊列接收的零散的數據包按照預設組包協議格式進行組裝成原數據包;數據處理用于將經數據組包組裝的原數據包進行數據業務關聯,形成價值數據;數據分類用于將經數據處理后的數據分為結構化數據、半結構化數據和非結構化數據;數據存儲用于將不同類型的數據分類進行分布式異構存儲,其中,結構化數據采用關系型數據庫,半結構化數據采用Mongodb和NFS方式進行存儲,非結構化數據采用Hadoop集群的方式進行存儲。
本發明提供的政務數據采集系統及其方法,能夠高效率的采集政務數據,可同時針對多種數據源的多種數據類型進行并發采集,并自動校驗數據,生成數據的描述信息,打包存儲轉發,適合大規模進行數據采集。
附圖說明
圖1為本發明實施例提供的政務數據采集系統的結構示意圖。
圖2為本發明實施例提供的政務數據采集方法的流程示意圖。
具體實施方式
以下結合附圖對本發明的具體實施方式進行描述。
【實施例1】政務數據采集系統
圖1為本發明實施例提供的政務數據采集系統的結構示意圖。如圖1所示,本發明提供的數據采集系統包括數據采集客戶端、傳輸中間件和數據采集服務端。數據采集客戶端用于采集政務數據并對采集的處理進行預處理、拆包和排隊,然后將拆分處理后的數據發送給傳輸中間件,傳輸中間件將數據發送給數據采集服務端,數據采集服務端將接收的數據進行排隊、組包、處理、分類和存儲。
具體地,數據采集客戶端針對不同的數據傳輸協議,如Http、FTP、TCP/IP以及WebService等提供多個具有不同接入方式的適配器,并設置有數據預處理單元、數據拆包單元和數據傳輸隊列單元。多個適配器中的每個適配器適用于采集一種數據傳輸協議的數據,因此,通過多個適配器進行并發同時采集,能夠將不同渠道、不同類型的數據源采集到數據采集客戶端中來,可通過網絡爬蟲來采集相關數據。數據預處理單元用于過濾掉采集的數據源中的無效數據和臟數據并將有效數據進行緩存,例如,可使用大數據算法,如使用多重插補、單重插補、隨機森林和多元回歸算法等,針對匯集的數據進行去除無效性、刪除重復性、糾正錯誤性等“臟數據”等。數據拆包單元用于將經數據預處理單元處理后的數據按照預設拆包協議格式進行拆分,拆分成多個個體較小的的數據包,并記錄整個數據包的描述信息以及每個拆分后小數據包的描述信息,最終將這些描述信息與拆分后的數據包一并發送到數據傳輸隊列單元,例如,客戶端在啟動的時候通過配置項設置相應參數,如拆分小包大小、拆分小包名稱細則、拆分小包的順序等,拆包時可采用多線程技術對文件按配置參數中的小包大小進行二進制拆分,將拆分的小包按配置參數中的名稱細則進行命名,并按配置參數中的順序細則進行存儲。整個數據包的描述信息可包括數據標識、數據名稱、數據內容描述、數據發布時間、數據所屬分類信息、數據關鍵字信息、數據定義版本、數據更新版本、數據提供單位、數據提供機構信息和數據定義信息,如數據名字規則、填寫規則、數據文件類型和規格等,以及數據唯一Id值(采用UUID生成)、整個數據包的MD5值等。小數據包的描述信息包括所屬整個數據包的UUID值、小包的MD5值、小包所屬整個數據包的順序(int值)、小包的名稱、小包的大小等。數據傳輸隊列單元用于將經數據拆包單元處理后的數據進行排隊并發送到傳輸中間件。一般,數據傳輸隊列按照時間順序將拆分后的數據包進行發送,然而,數據傳輸隊列也可根據接收int類型的優先級參數來按照優先級來發送數據。可通過Netty技術、非阻塞IO技術等將數據發送給傳輸中間件,但并不局限于此。
傳輸中間件可通過多線程的異步非阻塞方式將數據采集客戶端的數據傳輸隊列單元中的數據包發往數據采集服務端的數據傳輸隊列單元中,并保證數據的唯一準確的發送,同時支持斷點續傳以及錯誤補傳等功能。由于整個數據包的描述信息中存有整個數據包的MD5,如果數據采集服務端接收到的數據的MD5在服務端數據庫中已存在,則數據不會再次接收;如果不存在,則通知數據采集客戶端發送拆分后的小數據包,每個小數據包被數據采集服務端接收后都有各自的MD5校驗,驗證完整性,如果中途傳輸失敗,則數據采集服務端會在數據庫中記錄標記,同時要求數據采集客戶端重傳些小數據包,并支持斷點續傳,直到所有小數據包都傳輸完成并校驗通過,通過數據組包單元完成組包操作,形成整個數據包,進而保證了數據的為準確的發送。數據采集客戶端發送的小數據包在數據采集服務端會進行臨時存儲,并且在傳輸結束或中斷的時候數據采集服務端會在服務器記錄傳完的小數據包的大小,及傳輸校驗標志。當校驗失敗后,數據采集服務端會通知數據采集客戶端重傳此小數據包,同時會將此小數據包的相關描述信息以及當前的大小傳輸到客戶端,數據采集客戶端通過描述信息定位到此小數據包,并跳過數據采集服務端傳過來的字節數,繼續傳輸。補發有兩種方式,第一種為,數據采集服務端會定時輪循數據庫中檢驗失敗的小包然后發送給數據采集客戶端,如果三次還沒有成功則放棄此小包的再次傳輸;第二種方式為,數據采集客戶端可以通過頁面檢索到失敗的小數據包的相關信息,然后手動出發此小數據包的再次補發傳輸,進而實現支持斷點續傳以及錯誤補傳的功能。
數據采集服務端可包括數據傳輸隊列單元、數組組包單元、數據處理單元、數據分類單元和數據存儲單元。數據傳輸隊列單元用于接收由傳輸中間件傳輸過來的數據包。數據組包單元對應于數據采集客戶端中的數據拆包單元,執行數據拆包的逆過程,用于將數據傳輸隊列單元接收的零散的數據包按照預設組包協議格式進行組裝成原數據包,例如,當所有小數據包傳輸按MD5校驗成功后,根據每個小數據包所攜帶的描述信息中的所屬整個數據包的順序以二進制的方式通過IO流進行拼接。數據處理單元用于將數據組包單元組裝的原數據包進行數據業務關聯,形成價值數據,例如,針對整個數據包描述文件中的數據所屬分類信息(指定了行業細分)、數據關鍵字信息、數據提供單位、數據提供機構等相應參數進行相關業務數據匯集,形成有價值的數據集合;數據分類單元用于將經數據處理單元處理后的數據分為結構化數據、半結構化數據和非結構化數據,例如,可通過手動操作來將數據劃分為不同類型的數據,其中,非結構化數據是指沒有固定結構的數據,例如,所有格式的辦公文檔、文本、圖片、各類報表、圖像和音頻、視頻信息;半結構化數據是指數據具有隱含結構但又不是以二維表之類的形式存在的,介于結構化和非結構化知識源之間的一種知識源,例如,存儲員工的簡歷、類似XML、HTML、JSON等文件;結構化數據是指傳統的關系數據模型、行數據,存儲于數據庫,可用二維表結構表示的數據,例如,存儲于csv,excel的數據、二維表等。數據存儲單元用于將不同類型的數據分類進行分布式異構存儲,其中,結構化數據可采用關系型數據庫,半結構化數據可采用Mongodb和NFS(Network File System:網絡文件系統)方式進行存儲,非結構化數據可采用Hadoop集群的方式進行存儲,但并不局限于此。
在數據采集后,相關政務部門可通過發送相應的數據請求指令來從數據采集服務端的數據存儲單元中獲取相應的數據。
【實施例2】政務數據采集方法
圖2為本發明實施例提供的政務數據采集方法的流程示意圖。如圖2所示,本發明的另一實施例提供一種政務數據采集方法,包括以下步驟:
S100:數據采集客戶端通過具有多種接入方式的適配器同時采集具有不同數據傳輸協議的多種數據源,并將采集的數據源依次經歷數據預處理、數據拆包和數據傳輸隊列,并將處理后的數據源發送給傳輸中間件發進行發送。
在S100步驟中,針對不同的數據傳輸協議,如Http、FTP、TCP/IP以及WebService等提供多個具有不同接入方式的適配器,即每個適配器采集數據傳輸協議與其接入方式相適配的數據源,可通過網絡爬蟲來采集相關數據。數據預處理用于過濾掉采集的數據源中的無效數據和臟數據并將有效數據進行緩存;數據拆包用于將經數據預處理單元處理后的數據按照預設拆包協議格式進行拆分,拆分成多個個體較小的的數據包,并記錄整個數據包的描述信息以及每個拆分后小數據包的描述信息,最終將這些描述信息與拆分后的數據包一并發送到數據傳輸隊列單元,例如,客戶端在啟動的時候通過配置項設置相應參數,如拆分小包大小、拆分小包名稱細則、拆分小包的順序等,拆包時可采用多線程技術對文件按配置參數中的小包大小進行二進制拆分,將拆分的小包按配置參數中的名稱細則進行命名,并按配置參數中的順序細則進行存儲。整個數據包的描述信息可包括數據標識、數據名稱、數據內容描述、數據發布時間、數據所屬分類信息、數據關鍵字信息、數據定義版本、數據更新版本、數據提供單位、數據提供機構信息和數據定義信息,如數據名字規則、填寫規則、數據文件類型和規格等,以及數據唯一Id值(采用UUID生成)、整個數據包的MD5值等。小數據包的描述信息包括所屬整個數據包的UUID值、小包的MD5值、小包所屬整個數據包的順序(int值)、小包的名稱、小包的大小等。數據采集客戶端的數據傳輸隊列用于將經數據拆包單元處理后的數據進行排隊并發送到傳輸中間件。一般,數據傳輸隊列按照時間順序將拆分后的數據包進行發送,然而,數據傳輸隊列也可根據接收int類型的優先級參數來按照優先級來發送數據。可通過Netty技術、非阻塞IO技術等將數據發送給傳輸中間件,但并不局限于此。
傳輸中間件可通過多線程的異步非阻塞方式將數據采集客戶端的數據傳輸隊列中的數據包發往數據采集服務端的數據傳輸隊列中。由于整個數據包的描述信息中存有整個數據包的MD5,如果數據采集服務端接收到的數據的MD5在服務端數據庫中已存在,則數據不會再次接收;如果不存在,則通知數據采集客戶端發送拆分后的小數據包,每個小數據包被數據采集服務端接收后都有各自的MD5校驗,驗證完整性,如果中途傳輸失敗,則數據采集服務端會在數據庫中記錄標記,同時要求數據采集客戶端重傳些小數據包,并支持斷點續傳,直到所有小數據包都傳輸完成并校驗通過,通過數據組包單元完成組包操作,形成整個數據包,進而保證了數據的為準確的發送。數據采集客戶端發送的小數據包在數據采集服務端會進行臨時存儲,并且在傳輸結束或中斷的時候數據采集服務端會在服務器記錄傳完的小數據包的大小,及傳輸校驗標志。當校驗失敗后,數據采集服務端會通知數據采集客戶端重傳此小數據包,同時會將此小數據包的相關描述信息以及當前的大小傳輸到客戶端,數據采集客戶端通過描述信息定位到此小數據包,并跳過數據采集服務端傳過來的字節數,繼續傳輸。補發有兩種方式,第一種為,數據采集服務端會定時輪循數據庫中檢驗失敗的小包然后發送給數據采集客戶端,如果三次還沒有成功則放棄此小包的再次傳輸;第二種方式為,數據采集客戶端可以通過頁面檢索到失敗的小數據包的相關信息,然后手動出發此小數據包的再次補發傳輸,進而實現支持斷點續傳以及錯誤補傳的功能。
S200:數據采集服務端接收傳輸中間件發送的數據源,并將接收的數據源依次經歷數據傳輸隊列、數據組包、數據處理、數據分類和數據存儲。
具體地,數據采集服務端的數據傳輸隊列用于接收由傳輸中間件傳輸過來的數據包。數據組包對應于數據采集客戶端中的數據拆包,執行數據拆包的逆過程,用于將數據傳輸隊列接收的零散的數據包按照預設組包協議格式進行組裝成原數據包,例如,當所有小數據包傳輸按MD5校驗成功后,根據每個小數據包所攜帶的描述信息中的所屬整個數據包的順序以二進制的方式通過IO流進行拼接。數據處理用于將數據組包組裝的原數據包進行數據業務關聯,形成價值數據,例如,針對整個數據包描述文件中的數據所屬分類信息(指定了行業細分)、數據關鍵字信息、數據提供單位、數據提供機構等相應參數進行相關業務數據匯集,形成有價值的數據集合。數據分類用于將經數據處理處理后的數據分為結構化數據、半結構化數據和非結構化數據,例如,可通過手動操作來將數據劃分為不同類型的數據,其中,非結構化數據是指沒有固定結構的數據,例如,所有格式的辦公文檔、文本、圖片、各類報表、圖像和音頻、視頻信息;半結構化數據是指數據具有隱含結構但又不是以二維表之類的形式存在的,介于結構化和非結構化知識源之間的一種知識源,例如,存儲員工的簡歷、類似XML、HTML、JSON等文件;結構化數據是指傳統的關系數據模型、行數據,存儲于數據庫,可用二維表結構表示的數據,例如,存儲于csv,excel的數據、二維表等。數據存儲用于將不同類型的數據分類進行分布式異構存儲,其中,結構化數據可采用關系型數據庫,半結構化數據可采用Mongodb和NFS方式進行存儲,非結構化數據可采用Hadoop集群的方式進行存儲,但并不局限于此。
在數據采集后,相關政務部門可通過發送相應的數據請求指令來從數據采集服務端中獲取相應的數據。
本領域內的技術人員應明白,本申請的實施例可提供為方法、系統、或計算機程序產品。因此,本申請可采用完全硬件實施例、完全軟件實施例、或結合軟件和硬件方面的實施例的形式。而且,本申請可采用在一個或多個其中包含有計算機可用程序代碼的計算機可用存儲介質(包括但不限于磁盤存儲器、CD-ROM、光學存儲器等)上實施的計算機程序產品的形式。
盡管已描述了本申請的優選實施例,但本領域內的技術人員一旦得知了基本創造性概念,則可對這些實施例作出另外的變更和修改。所以,所附權利要求意欲解釋為包括優選實施例以及落入本申請范圍的所有變更和修改。
顯然,本領域的技術人員可以對本申請實施例進行各種改動和變型而不脫離本申請實施例的精神和范圍。這樣,倘若本申請實施例的這些修改和變型屬于本申請權利要求及其等同技術的范圍之內,則本申請也意圖包含這些改動和變型在內。
- 還沒有人留言評論。精彩留言會獲得點贊!